随着数据量的爆炸式增长、企业上云速度加快以及数据实时性需求加强,云原生数仓市场迎来了快速发展机遇。
据 IDC、Gartner 研究机构数据显示,到 2025 年,企业 50% 数据预计为云存储,75% 数据库都将运行在云上,全球数据处理预计有 30% 为实时数据处理,80% 数据预计为非结构化数据,这将驱使云原生数仓愈加受到企业青睐。
近期,火山引擎云原生数据仓库 ByteHouse 产品负责人李群受邀出席"CSDI summit 中国软件研发创新科技峰会",围绕"新一代云原生数仓 ByteHouse 关键技术与最佳实践"主题,从云数仓历史和前沿出发,介绍 ByteHouse 整体架构、关键亮点、性能突破、存算分离的关键设计,以及 ByteHouse 在抖音集团内外多样化场景中的业务实践。

基于 ByteHouse 在金融、游戏、泛互联网等多行业的经验总结,李群首先介绍了云原生数据仓库目前面临的难点和挑战。高性能、高并发、高吞吐写入,已经是当今企业对云数仓的基础需求。随着互联网不断发展,数据增长迅速,特别是埋点日志类数据,一些较为活跃的 APP,每天数据达到百亿甚至千亿级别,大规模杀手级应用每天更是产生数千亿事件量。这要求数据平台不仅要支持高吞吐写入、实时去重,面对业务请求还要达到毫秒级响应。
除此之外,企业还面临数据架构复杂、灵活性欠缺、成本控制难的问题。例如,为了实现一个数据分析功能,企业可能需要引入三、四个甚至更多的组件来构建,导致扩容较难、运维压力大,人力维护成本高。
为了解决以上问题,ByteHouse 首先在性能上实现突破。在复杂查询上,ByteHouse 从 RBO(基于规则的优化能力)、CBO(基于代价的优化能力)、分布式计划生成方面推出了自研优化器,能够准确的计算出效率最大化执行路径,大幅度降低用户查询时间。除此之外,ByteHouse 还从 Exchange、Runtime Filter 以及并行化重构等方向进行了优化。针对实时吞吐慢、BI 报表慢、离/在线复杂分析慢、湖+仓联邦分析慢、人群圈选慢、以图搜图慢六大场景,ByteHouse 都推出了定制解决方案,并在客户实际场景中产生实效。
在提升效率同时,ByteHouse 也专注于帮助用户节省成本。基于 ByteHouse 弹性伸缩能力,用户只需基于时间、资源负载等条件就能进行扩容、缩容配置,减轻手动管理的负担,提升资源利用率。在存储层面, ByteHouse 采用 Serverless 架构,具有低成本、无限扩展的能力。在计算层面,ByteHouse 则基于 PaaS 模式,通过容器化实现无状态或弱状态,将整个计算组包装成租户和应用呈现给用户,保证租户之间不会发生资源征用冲突或性能劣化,让计算资源在秒级内实现弹性拉起和弹性扩缩容。
最后,为了给用户提供更便捷的使用体验,ByteHouse 也在一体化、生态兼容性以及全场景引擎方面进一步提升易用性。以全场景引擎为例,ByteHouse 通过构建统一的平台为用户提供更丰富的数据分析能力,实现数据效能最大化,已经推出了全文检索引擎、GIS 引擎、Vector 引擎,让用户在享受 OLAP 极致性能的同时,无需引入其他架构,就能使用文字检索、地理空间分析、向量检索能力。
在应用场景方面,李群则从实时数仓、企业级 OLAP 中台、广告精准营销三个场景,带来 ByteHouse 最佳实践分享。
以广告精准营销场景为例,随着移动互联网的流量红利消退,精细化营销模式随之跃迁为主流。从数以亿计的人群中,优选出最具潜力的目标受众,是精细营销的题中之义,也是作为基础引擎的数据仓库能力所面临的挑战。
从 ByteHouse 曾服务的某个短剧广告营销公司来看,一方面,该公司投放在业务上需要实时调整策略,要求数据分析、更新时效性在 3s 内,并发 QPS 达到 2000;另一方面,在营销场景中,海量数据实时更新会产生大量数据碎片,拉低查询性能、浪费存储空间。
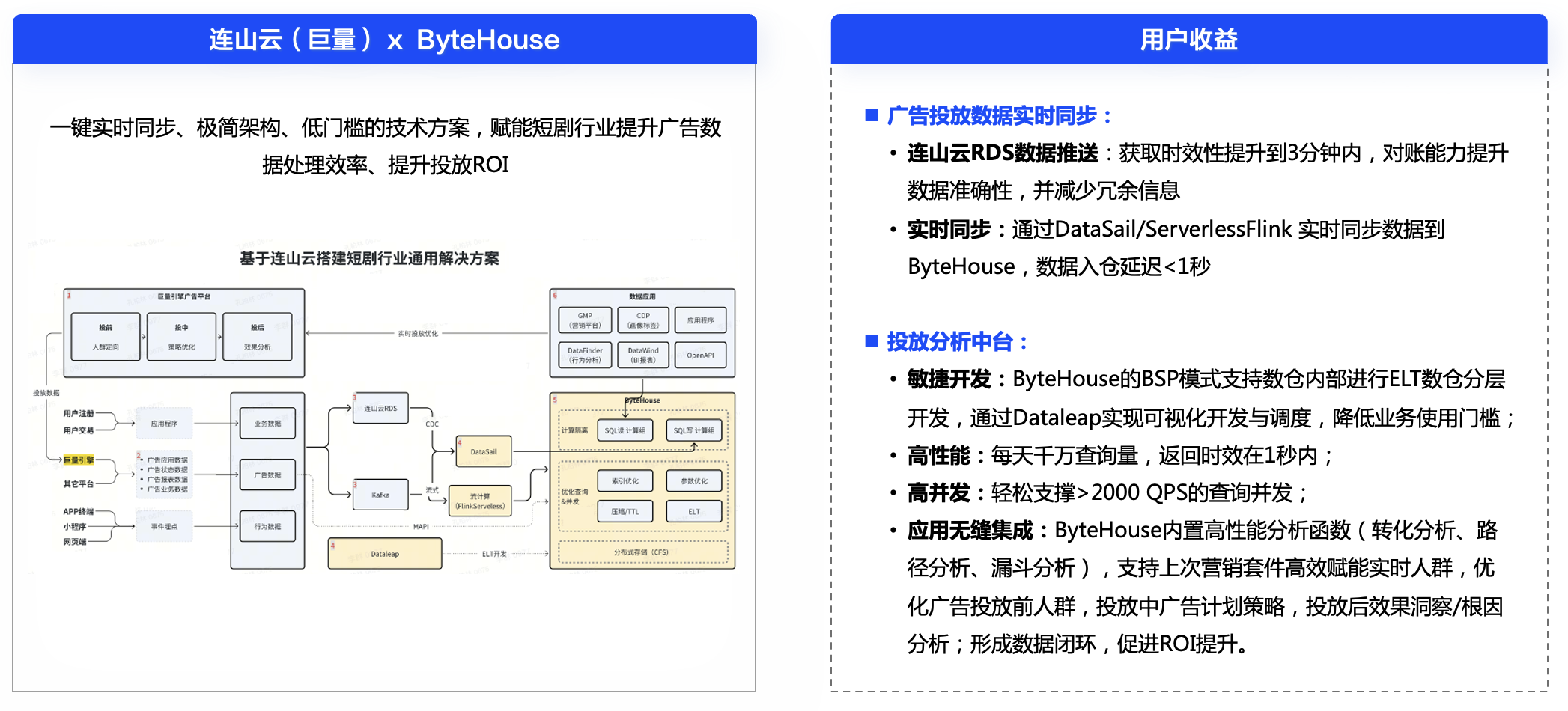
通过引入 ByteHouse、连山云、巨量引擎联合解决方案,该广告营销公司搭建了一套 "一键实时同步、极简架构、低门槛技术" 的短剧行业通用解决方案,提升广告数据处理效率与投放 ROI。
在效果上,通过多级索引,如排序键索引、分区键优化、跳跃索引等,ByteHouse 有效减少了广告营销查询时扫描的数据量,在每天千万查询量的情况下,数据返回时效也能保障在秒级,较之前 5 倍提升。在计算组隔离策略中,ByteHouse 为广告营销场景中的数据读、写分别构建独立的计算资源,再通过灵活的 SQL 分发机制,已可以支持超过 2000 QPS 的查询高并发。
据介绍,ByteHouse 还与中国地震台网中心、莉莉丝游戏、极客邦科技等诸多行业企业达成了深度合作,凭借新一代的云原生架构,高效方便的运维模式,以及高性能更灵活的实时查询能力,为企业抓稳数字化机遇建立了夯实的地基,推动企业的数智化转型升级。