全文链接:https://tecdat.cn/?p=37784
非参数回归为经典(参数)回归方法提供了一种灵活的替代方法。与假定回归关系具有依赖于有限数量的未知参数的已知形式的传统(参数)方法不同,非参数回归模型尝试从数据样本中学习回归关系的形式**(** 点击文末"阅读原文"获取完整代码数据******** )。
相关视频
1.1 动机和目标
所有非参数回归模型都涉及在拟合观察到的数据样本(模型拟合)和"平滑"函数估计(模型精简)之间找到某种平衡。通常,这种平衡是使用某种形式的交叉验证来确定的,交叉验证会尝试找到适合预测新数据的函数估计。因此,非参数回归模型可用于发现变量之间的关系以及开发可推广的预测规则。
在这些说明中,您将学习如何拟合和调整简单的非参数回归模型。您还将学习如何使用非参数回归模型来可视化数据中的关系并为新数据形成预测。
1.2 R 中的简单平滑器
这些说明涵盖了 "简单" 非参数回归的三种经典方法:局部平均、局部回归和核回归。请注意,我所说的 "simple" 是指只有一个 (连续) 预测器。平滑样条曲线以及多元回归和广义回归的扩展将在另一组注释中介绍。
局部平均(弗里德曼的"Super Smoother"):
go
supsmu(x, y, wt =, span = "cv", periodic = FALSE, bass = 0, trace = FALSE)局部回归(克利夫兰 LOESS):
go
loess(formula, data, weights, subset, na.action, model = FALSE,span = 0.75, enp.target, degree = 2,parametric = FALSE, drop.square = FALSE, normalize = TRUE,family = c("gaussian", "symmetric"),method = c("loess", "model.frame"),control = loess.control(...), ...)核回归 (Nadaraya 和 Watson 的核平滑器):
go
ksmooth(x, y, kernel = c("box", "normal"), bandwidth = 0.5,range.x = range(x),n.points = max(100L, length(x)), x.points)1.3 NP 回归的必要性
最初是为了强调将图形与回归模型一起使用的必要性而设计的,但它也为非参数回归提供了很好的动力。
1.4 模型和假设
假设我们观察到 ( n ) 独立点对 ( {(x\_i, y\_i)} ) 并且不失一般性地假设 ( x\_1 \leq x\_2 \leq \ldots \leq x_n )。此外,假设 ( X ) 和 ( Y ) 具有以下关系:
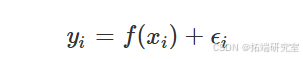
其中 ( f(\cdot) ) 是某个未知的平滑函数,而 ( \epsilon\_i ) 是具有均值零和方差 ( \sigma^2 ) 的独立同分布(IID)误差项。请注意,这些方法实际上并不需要同次误差方差的假设;但是,此假设通常可用于优化和推理。假设均值零误差项是必要的,因为这意味着 ( E(y\_i | x\_i) = f(x\_i) ),这意味着未知的平滑函数 ( f(\cdot) ) 描述了给定 ( X ) 的条件均值 ( Y )。非参数回归估计器(也称为"平滑器")尝试从干扰数据样本中估计未知函数 ( f(\cdot) )。
局部平均
2.1 定义
估计未知函数 ( f(\cdot) ),Friedman (1984) 提出了简单而有力的_局部平均_概念。函数的局部平均估计值 ( f(\cdot) ) 在点 ( x ) 是通过取 ( y\_i ) 值对应于 ( x\_i ) 值,这些值位于 ( x ) 的_给定的_附近。更正式地说,局部平均估计可以写成

其中,权重的定义使得 ( w\_i(x) = 1 ) 如果点 ( x\_i ) 就在 ( x ) 的附近,而 ( w_i(x) = 0 ) 否则。请注意,权重是 ( x ) 的函数,即每个 ( x )。
2.2 邻近有多近?
为了正式化_邻近_的概念,弗里德曼建议使用 ( x_i ) 的最小对称窗口 ( x ) 包含 ( s ) 个观察值,其中 ( s \in (0,1] )。参数 ( s ) 称为 span 参数,该参数控制函数估计的平滑度。随着 ( s \to 0 ),函数估计变得更加锯齿状(即不太平滑),并且随着 ( s \to 1 ),函数估计变得更加平滑。目标是找到 ( s ),它提供了未知平滑函数的"合理"估计 ( f(\cdot) )。
2.3 视觉直觉
为了了解局部平均估计量,我们将看看该点的估计值是如何形成的 ( x^* = 0.3 ) 使用 span 参数的不同值。
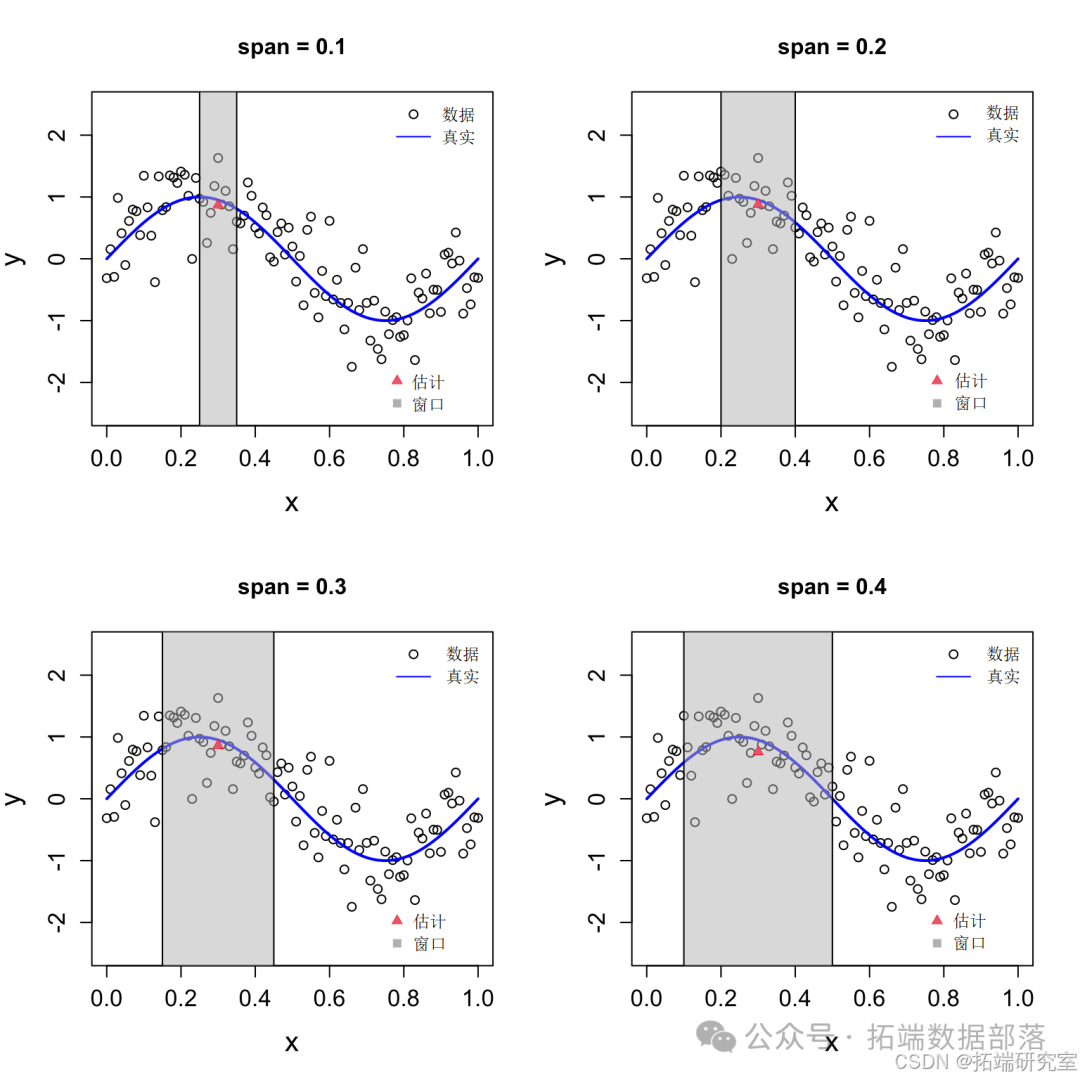
本地平均估计值 ( \hat{f}(0.3) ) 具有不同的 span 值。
点击标题查阅往期内容

高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据

左右滑动查看更多
01

02
03

04
请注意,估计值(由红色三角形表示)是通过将所有 ( y_i ) 本地窗口内的值(由灰色框表示)平均化得到的。上面的示例显示了点的窗口 ( x^* = 0.3 ),但同样的想法也适用于其他点。要在不同的 ( x ) 值,我们只需将平均窗口沿 x 轴向下滑动,使其以新的 ( x ) 值。因此,局部平均估计器有时称为"移动平均"估计器。
2.4 选择 Span
通常,其 ( s ) 使用普通 (Leave-one-out) 交叉验证确定。让 ( \hat{y}\_i(s) ) 表示 ( f(\cdot) ) 在点 ( x\_i ) 通过伸出 ( i )-th 对 ( (x\_i, y\_i) )。请注意,表示法 ( \hat{y}_i(s) ) 表示估计值是 span 参数的函数 ( s )。普通交叉验证方法寻求找到 ( s ) 这最大限度地减少了
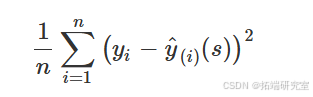
这最大限度地减少了 (平方) 留一法预测误差。这是函数用于选择 span 参数的默认方法。
局部回归
3.1 定义
估计未知函数 ( f(\cdot) ),Cleveland (1979) 提出了_局部回归_的概念。函数的局部回归估计值 ( f(\cdot) ) 在点 ( x ) 是通过将加权最小二乘回归模型拟合到 ( y\_i ) 值对应于 ( x\_i ) 值,这些值位于 ( x ) 的_给定的_附近。更正式地说,局部回归估计可以写成
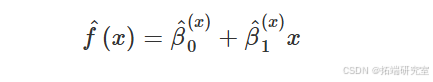
其中 ( \hat{\beta}^0(x) ) 和 ( \hat{\beta}^1(x) ) 是加权最小二乘问题的最小化器
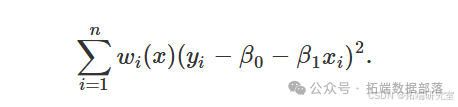
请注意,( \hat{\beta}^0(x) ) 和 ( \hat{\beta}^1(x) ) 是 ( x ) 的函数,鉴于权重 ( {w\i(x)}^n\{i=1} ) 是 ( x ) 的函数。
在这种情况下,权重的定义使得 ( w\_i(x) ) 是 ( |x - x\_i| ) 仅当 ( x\_i ) 就在附近 ( x )。一种流行的权重函数是\_三立方_函数

其中 ( \delta > 0 ) 是一些标量,用于确定哪些点_足够接近_给定的 ( x ) 接收非零权重。
上述公式适用于局部线性回归,其中简单的线性回归模型适合 ( x )。这个想法可以很容易地扩展到包括高阶多项式项。例如,局部二次回归估计值的形式为

其中 ( {\hat{\beta}^0(x), \hat{\beta}^1(x), \hat{\beta}^2(x)} ) 是加权最小二乘问题的最小化器
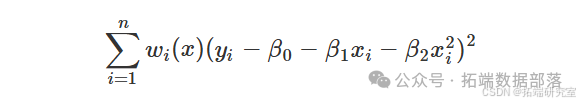
和权重 ( w_i(x) ) 的定义如前所述。
3.2 附近有多近?
Cleveland 提议定义 ( \delta ),以便权重具有非零值 ( s ) 个观察值中,其中 ( s \in (0,1] ) 是 span 参数。假设 ( x\_i ) 均匀分布在 ( a = \min(x\_i) ) 和 ( b = \max(x\_i) ),我们有 ( \delta = s/2 ) 对于积分 ( x\_i ) 距离边界点足够远的一个 ( a ) 和 ( b )。

三立方函数。局部回归问题的权重 ( x = 0.3 ) 具有不同的 delta 值。
3.3 视觉直觉
为了了解局部回归估计器,我们将看看该点的估计是如何形成的 ( x^* = 0.3 ) 使用 span 参数的不同值。我们将首先使用局部线性回归查看 LOESS 估计器,然后我们将查看使用局部二次回归的 LOESS 估计器。
局部线性回归
go
# 定义函数和数据集seed(1)n <- 101x <- seq(0, 1, length.out = n)fx <- sin(2 * pi * x)y <- fx + rnorm(n, sd = 0.5)# 定义x*和窗口的颜色xstar <- 0.3cols <- rgb(190/255,190/255,190/255,alpha=0.5)# 设置2x2的子图par(mfrow = c(2,2))# 遍历跨度(0.1, 0.2, 0.3, 0.4)for(s in c(0.1, 0.2, 0.3, 0.4)){# 绘制数据和真实函数plot(x, y, main = paste0("span = ", s), ylim = c(-2.5, 2.5),cex.lab = 1.5, cex.axis = 1.25)lines(x, fx, col = "blue", lwd = 2)# 绘制窗口window <- c(xstar - s / 2, xstar + s / 2)rect(window\[1\], -3, window\[2\], 3, col = cols)# 定义权重w <- tricube(x - xstar, delta = s / 2)# 绘制估计X.w <- sqrt(w) * cbind(1, x)y.w <- sqrt(w) * ybeta <- solve(crossprod(X.w)) %*% crossprod(X.w, y.w)ystar <- as.numeric(cbind(1, xstar) %*% beta)points(xstar, ystar, pch = 17, col = "red", cex = 1)# 添加回归线abline(beta, lty = 3)# 添加图例legend("topright", legend = c("data", "truth"),pch = c(1, NA), lty = c(NA, 1), col = c("black", "blue"), bty = "n")legend("bottomright", legend = c("estimate", "window"),pch = c(17, 15), col = c("red", "gray"), bty = "n")}
局部线性回归估计值 ( \hat{f}(0.3) ) 具有不同的 span 值。
请注意,估计值(由红色三角形表示)是通过将加权线性回归模型拟合到 ( y_i ) 本地窗口内的值(由灰色框表示)。上面的示例显示了点的窗口 ( x^* = 0.3 ),但同样的想法也适用于其他点。要在不同的 ( x ) 值,我们只需将窗口沿 x 轴向下滑动,使其以新的 ( x ) 值,并相应地重新定义权重。
局部二次回归
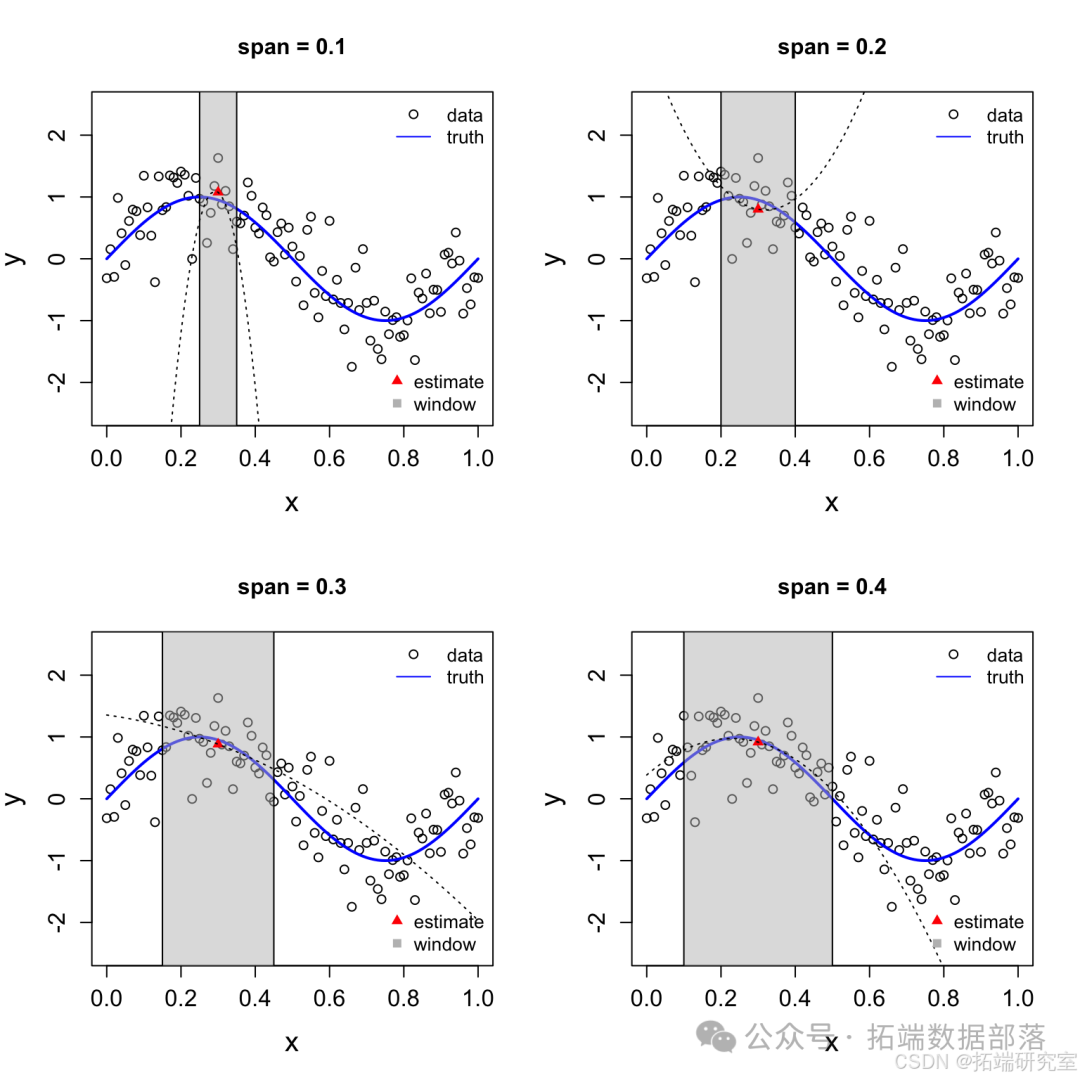
局部二次回归估计值 ( \hat{f}(0.3) ) 具有不同的 span 值。
请注意,估计值(由红色三角形表示)是通过将加权二次回归模型拟合到 ( y_i ) 本地窗口内的值(由灰色框表示)。上面的示例显示了点的窗口 ( x^* = 0.3 ),但同样的想法也适用于其他点。要在不同的 ( x ) 值,我们只需将窗口沿 x 轴向下滑动,使其以新的 ( x ) 值,并相应地重新定义权重。
3.4 选择 Span
您可能已经注意到,该函数不提供任何
用于选择 span 参数的数据驱动方法。因此,该函数的许多用户(在不知不觉中)使用默认的 span 值 loess loess ( s = 0.75 ),它不能保证产生均值函数的合理估计 ( f(\cdot) )。
与其使用 span 参数的任意值,不如使用交叉验证的估计值。请注意,普通的交叉验证标准(来自上一节)可以更高效地写为
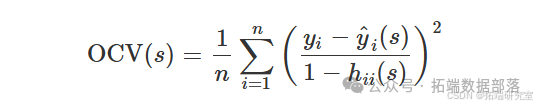
其中 ( h_{ii}(s) ) 是"帽子矩阵" ( H(s) ) 的第 ( i )-th 对角线元素,这是线性变换 ( y = (y\_1, \ldots, y\_n)^T ) 到 ( \hat{y}\_s = (\hat{y}\_1(s), \ldots, \hat{y}\_n(s))^T ),即 ( \hat{y}\_s = H(s)y ) 其中 ( \hat{y}_s ) 是对应于 span 参数的拟合值的向量 ( s )。
OCV 标准可以解释为(均值)平方误差损失函数的加权版本,其中权重的形式为 ( w\i = (1 - h\{ii}(s))^{-2} )。请注意,杠杆分数 ( h_{ii}(s) ),范围介于 0 和 1 之间,则不同观测值之间可能有很大差异,这意味着 OCV 标准可以为不同的观测值分配不同的权重。GCV 标准通过在 OCV 标准的基础上将 ( h_{ii}(s) ) 替换为其计算中的平均值,例如

其中 ( \nu\s = \sum\{i=1}^n h_{ii}(s) ) 是"帽子矩阵"的迹,它是函数估计的自由度的估计值。以下函数提供了使用 GCV 调整 span 参数的函数的简单实现。
核回归
4.1 定义
核回归是核密度估计思想对回归问题的扩展。Nadaraya (1964) 和 Watson (1964) 独立提出了估计 ( f(\cdot) ) 使用响应值的核加权线性组合,例如
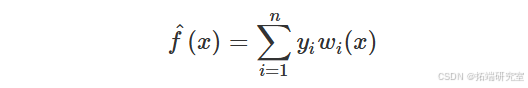
其中,权重定义为
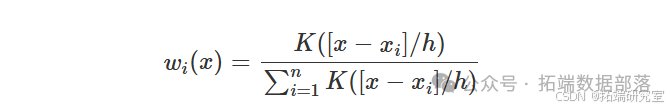
跟 ( K(\cdot) ) 表示一些已知的核函数(通常是高斯核),以及 ( h > 0 ) 表示 bandwidth 参数。请注意,bandwidth 参数控制来自 ( (x\_i, y\_i) ) 对的信息量用于估计函数 ( f(\cdot) ) 在点 ( x )。
4.2 附近有多近?
请记住,bandwidth 参数与核函数的标准差相关,该函数以每个 ( x\_i ) 价值。因此,函数的核回归估计值 ( f(\cdot) ) 在点 ( x ) 是通过采用 ( y\_i ) 值,其中为每个 ( y\_i ) 如果 ( x\_i ) 就在附近 ( x ) 否则相对较小。作为 bandwidth 参数 ( h \to 0 ),则 ( f(x) ) 仅使用来自 ( y\_i ) 的值 ( x\_i ) 非常接近 ( x )。相比之下,作为 ( h \to \infty ),则 ( f(x) ) 使用来自 ( y\_i ) 的值 ( x\_i ) 值 ( x )。在这两种情况下,核回归估计都为 ( y\_i ) 其 ( x\_i ) 值更接近给定点 ( x )。
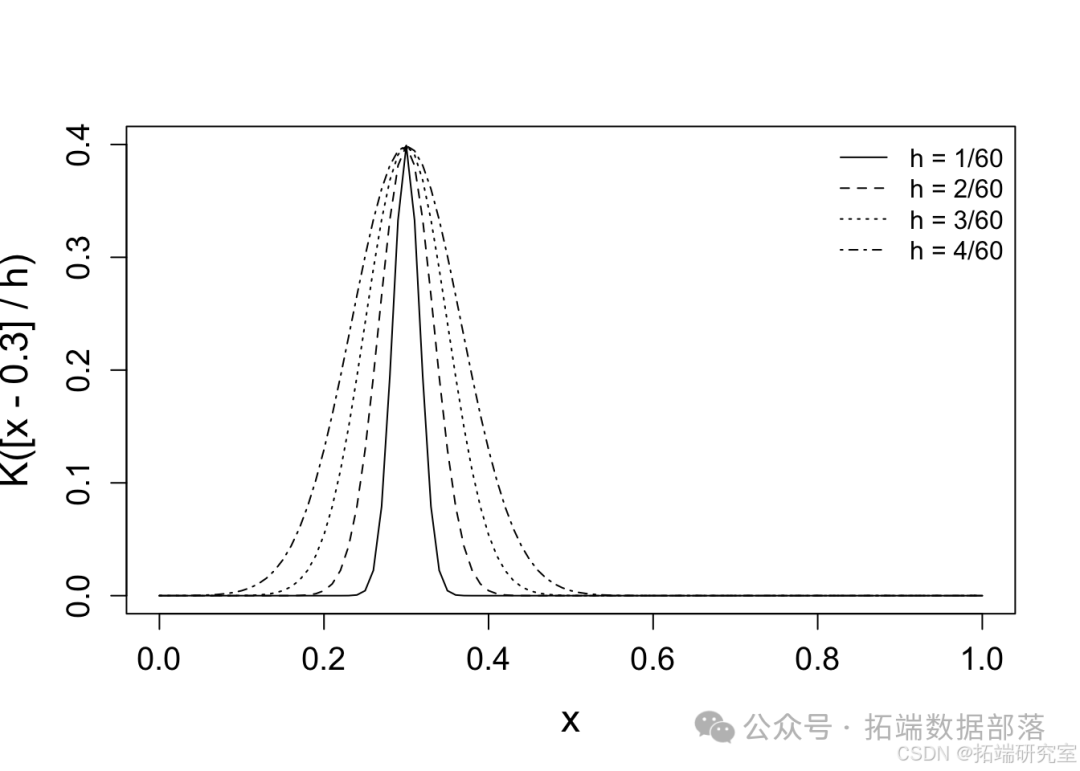
带宽。高斯核回归问题的权重 ( x = 0.3 ) 具有不同的带宽。
4.3 视觉直觉
为了理解核回归估计器,我们将看看该点的估计是如何形成的 ( x^* = 0.3 ) 使用不同的 bandwidth 参数值。

核回归估计值 ( \hat{f}(0.3) ) 具有不同的带宽值。
请注意,估计值(由红色三角形表示)是使用 ( y\_i ) 值。在这种情况下,所有 ( y\_i ) 值具有非零权重,但许多权重实际上为零。对于可视化,灰色框表示相应带宽下 Gaussian 核下 99% 的区域。上面的示例显示了点的窗口 ( x^* = 0.3 ),但同样的想法也适用于其他点。要在不同的 ( x ) 值,我们只需将窗口沿 x 轴向下滑动,使其以新的 ( x ) 值,并相应地重新定义权重。
4.4 选择带宽
与该函数类似,该函数不提供任何用于选择 bandwidth 参数的数据驱动方法。因此,该函数的许多用户(在不知不觉中)使用默认的带宽值 loess ksmooth ( h = 0.5 ),它不能保证产生均值函数的合理估计 ( f(\cdot) )。请注意,R 的函数将问题参数化,以便"对内核进行缩放,以便它们的四分位数(被视为概率密度)处于 +/- 0.25 带宽",因此该函数的_带宽_参数不是内核函数的标准差。ksmooth
以下函数提供了使用 GC
V 调整带宽参数的函数(使用 Gaussian 内核)的简单实现。请注意,此函数在 ksmooth ( r/n,r ) ( r/n,r ) 其中 ( r = \max(x\_i) - \min(x\_i) ) 是观测样本的范围。如果最佳 ( h ) 落在边界点上,即如果 ( \hat{h} = r/n ) 或 ( \hat{h} = r ),则搜索范围应向适当的方向扩展。此外,应该注意的是,对于大型数据样本,该函数将非常缓慢,因为它需要形成 ( ksmooth.gcv ) ( n \times n ) 每个 bandwidth 参数选择的 kernel matrix。
示例 1:收入的声望
5.1 数据概述
数据集包含 职业,以及该职业的平均收入。我们将使用非参数回归方法来探索声望和收入之间的关系。
首先,让我们加载数据并可视化收入 ( ( X ) ) 和声望 ( ( Y ))。

注意:这种关系看起来是非线性的。对于收入低于 10 美元的职业,收入和声望之间存在很强的(正)线性关系。但是,对于收入在 ( 10K) 到 ( 25K ) 之间的职业,这种关系具有明显不同(减弱)的斜率。
5.2 分析和结果
注意:该模型的有效自由度对于局部回归估计器约为 3,对于核回归估计器的有效自由度约为 8。
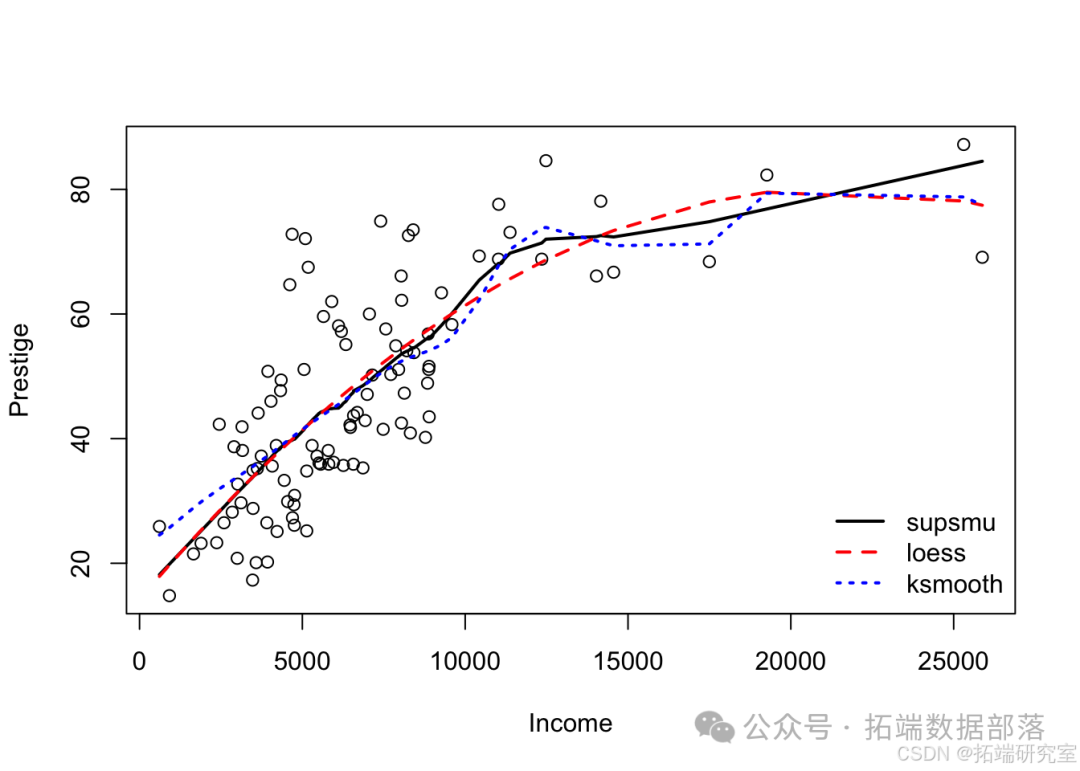
从上图可以看出,GCV 调整的 LOESS 估计值表现最好(即提供拟合度和平滑度的最佳组合),CV 调整的局部平均值表现第二好,而 GCV 调整的核回归估计值表现最差。特别是,GCV 调整的核回归估计对收入和声望之间的关系产生了相当粗略/摇摆不定的估计。
示例 2:摩托车事故
6.1 数据概述
数据集包含 ( n = 133 ) 摩托车事故中记录的时间点对(以毫秒为单位)和观察到的头部加速度(以 G 为单位)。我们将使用非参数回归方法来探索时间和加速度之间的关系。
首先,让我们加载数据并可视化时间 ( ( X ) ) 和加速度 ( ( Y ))。

注意:这种关系看起来是非线性的。头部加速度在 0-15 毫秒之间稳定,从大约 15-20 毫秒下降,从 20-30 毫秒上升,从 30-40 毫秒下降,然后开始稳定。
6.2 分析和结果
拟合局部平均、局部回归和内核回归。
注意:该模型的本地回归估计器的有效自由度约为 10.5,核回归估计器的有效自由度约为 20。
绘制结果

从上图可以看出,GCV 调整的 LOESS 估计值表现最佳(即提供拟合和平滑度的最佳组合)。CV 调整的局部平均值太平滑,错过了 30 毫秒左右的峰值。GCV 调整的核回归估计值比局部平均值更适合数据,但当数据变得更嘈杂时(即,模拟事故发生后 30 毫秒或更长时间),它会产生相当粗略/波动的估计值。

本文中分析的数据、代码**** 分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《R语言非参数回归预测摩托车事故、收入数据:局部回归、核回归可视化》。
点击标题查阅往期内容
【视频讲解】非参数重采样bootstrap逻辑回归Logistic应用及模型差异Python实现
R语言非参数模型厘定保险费率:局部回归、广义相加模型GAM、样条回归
R语言贝叶斯非参数模型:密度估计、非参数化随机效应META分析心肌梗死数据
R语言非参数方法:使用核回归平滑估计和K-NN(K近邻算法)分类预测心脏病数据
R语言对巨灾风险下的再保险合同定价研究案例:广义线性模型和帕累托分布Pareto distributions分析
R语言时变面板平滑转换回归模型TV-PSTR分析债务水平对投资的影响
R语言中的广义线性模型(GLM)和广义相加模型(GAM):多元(平滑)回归分析保险资金投资组合信用风险敞口
R语言预测人口死亡率:用李·卡特(Lee-Carter)模型、非线性模型进行平滑估计
R语言中的多项式回归、B样条曲线(B-spline Curves)回归
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言中使用非凸惩罚函数回归(SCAD、MCP)分析前列腺数据
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计




