
文章目录
前言
在最近的开发工作中,我有机会体验了丹摩智算平台,部署并使用了 Llama 3.1 模型。在人工智能和大模型领域,Meta 推出的 Llama 3.1 已经成为了目前最受瞩目的开源模型之一。今天,我将通过这次实践,分享在丹摩平台上部署 Llama 3.1 的实际操作流程以及我的个人心得。
部署前的准备
Llama 3.1 是一个资源需求较高的模型,因此在部署之前,首先要确保拥有合适的硬件环境。按照文档中的要求,我选择了 Llama 3.1 8B 版本进行测试。8B 模型对 GPU 显存的需求为 16GB,因此我在丹摩平台上选择了 NVIDIA RTX 4090 作为我的实例,并且配置了 60GB 的数据硬盘容量,来满足下载模型和存储相关文件的需求。
在丹摩平台的控制台创建 GPU 云实例非常简单,整个流程仅需几分钟的时间。在实例创建页面中,我能够灵活选择 GPU 的数量和型号,平台还提供了便捷的镜像选择功能,省去了大量的环境配置工作。我选择了预装 PyTorch 2.4.0 的镜像,确保在后续的部署过程中不需要手动安装繁杂的依赖环境。
创建实例
进入控制台-GPU云实例,点击创建实例:
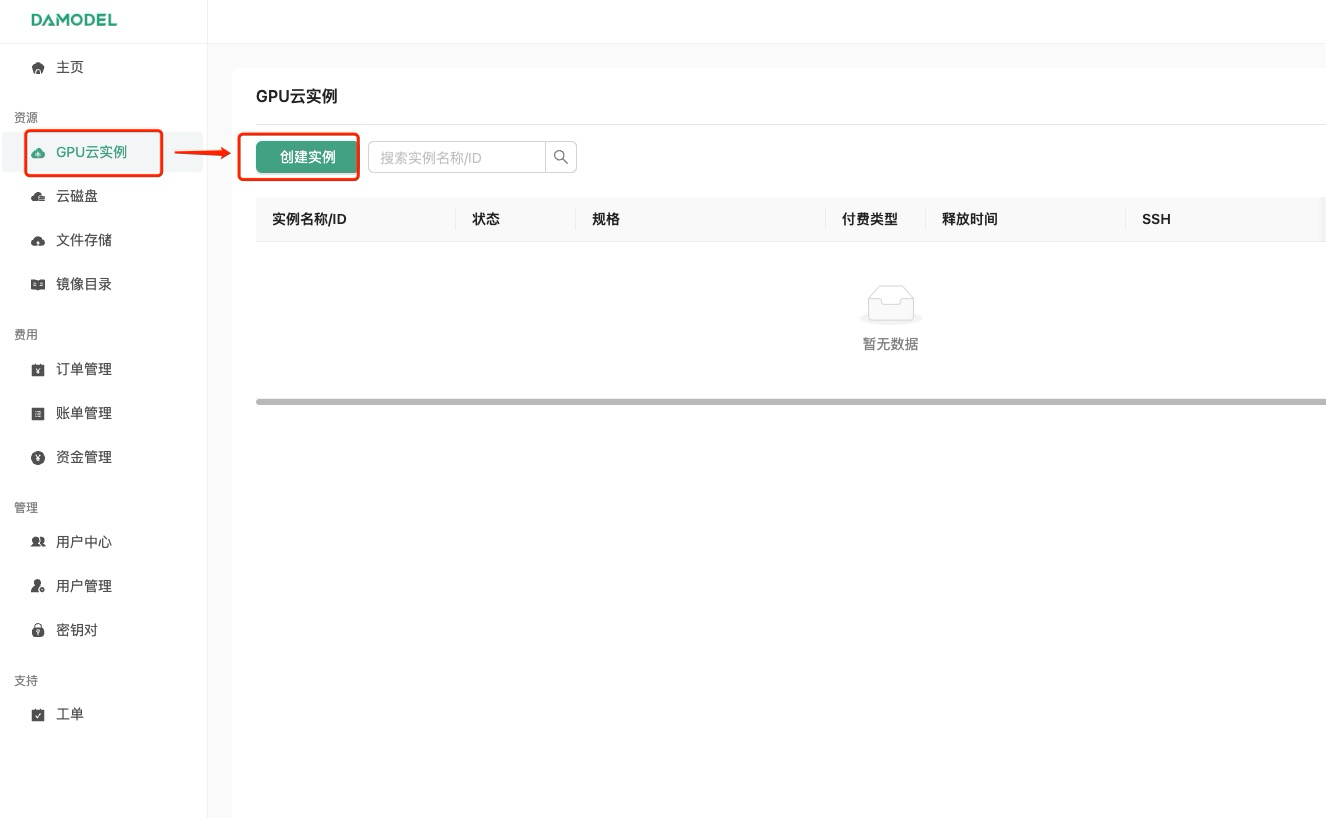
进入创建页面后,首先在实例配置中选择付费类型,一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
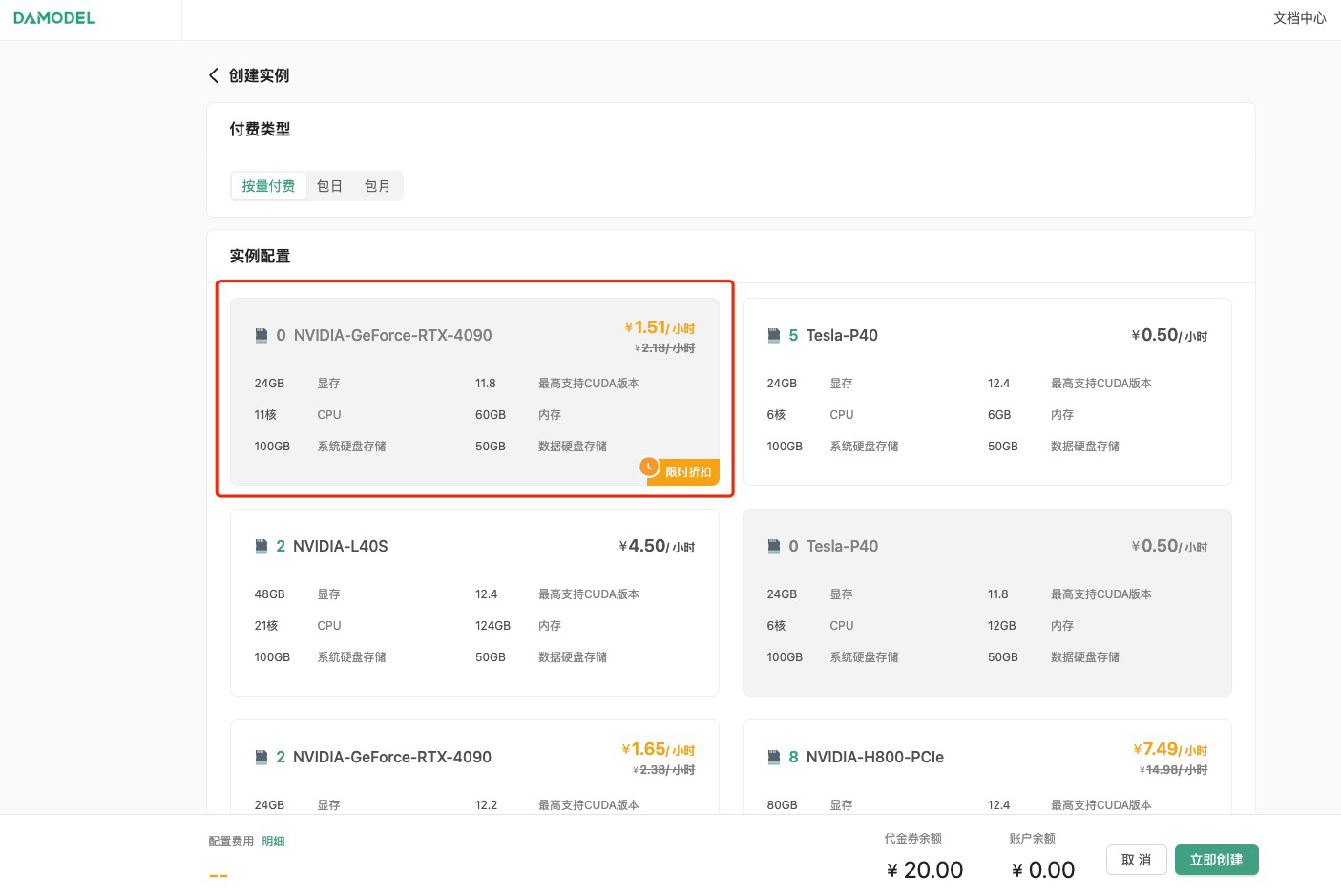
按量付费--GPU数量1--NVIDIA-GeForc-RTX-4090,该配置为60GB内存,24GB的显存(本次测试的LLaMA3.1 8B 版本至少需要GPU显存16G)
接下来配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,首次创建可以就选择默认大小50GB。
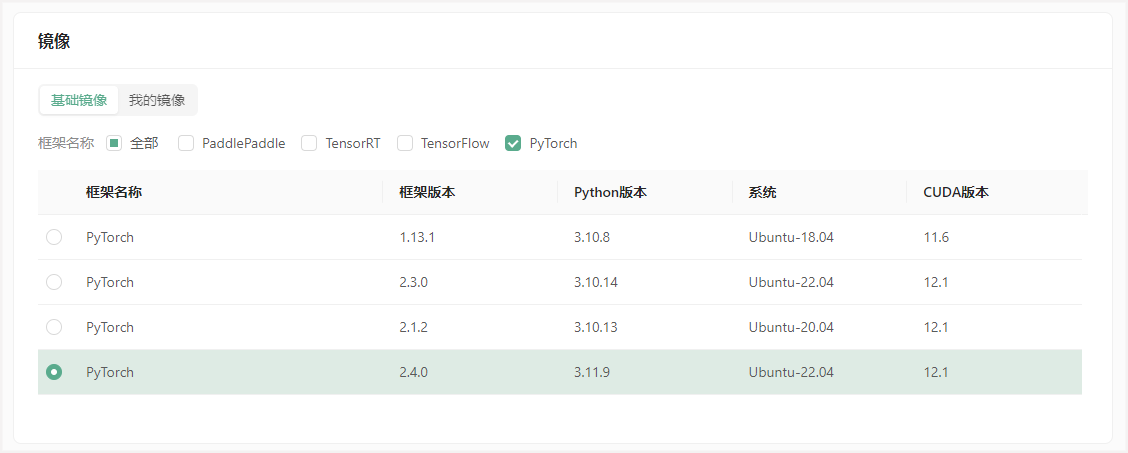
继续选择安装的镜像,平台提供了一些基础镜像供快速启动,镜像中安装了对应的基础环境和框架,可通过勾选来筛选框架,这里筛选PyTorch,选择PyTorch 2.4.0。
为保证安全登录,创建密钥对,输入自定义的名称,然后选择自动创建并将创建好的私钥保存的自己电脑中并将后缀改为.pem,以便后续本地连接使用。
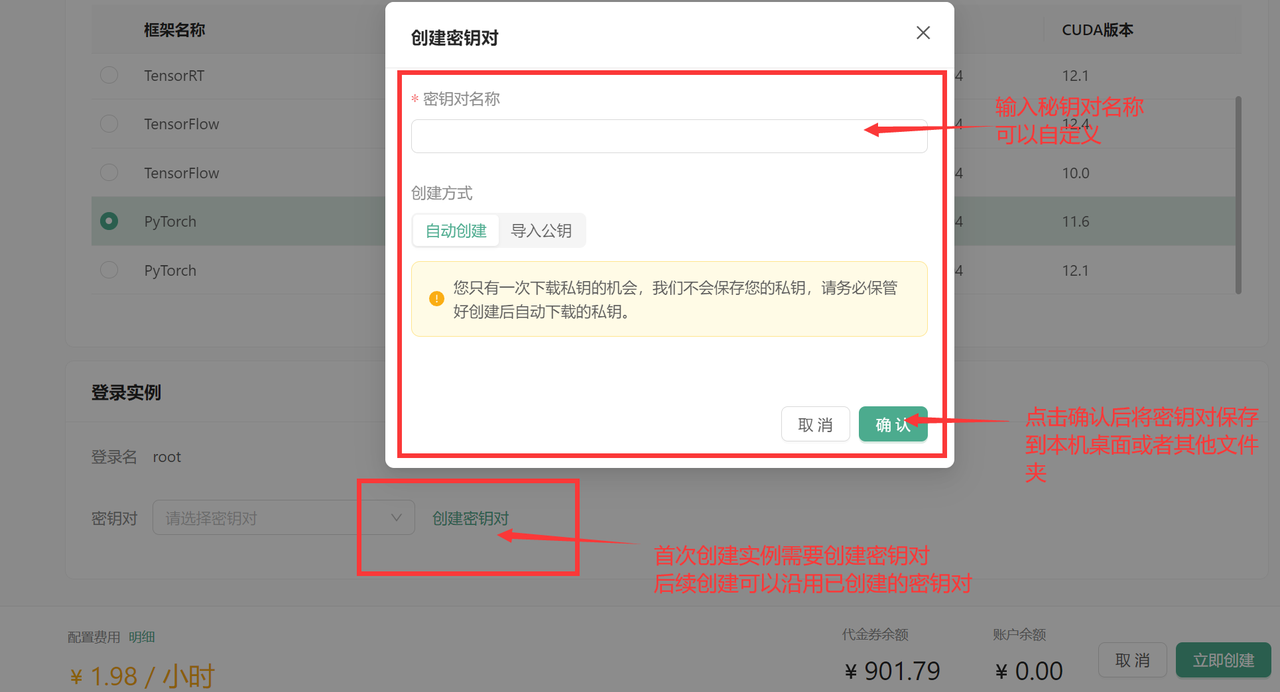
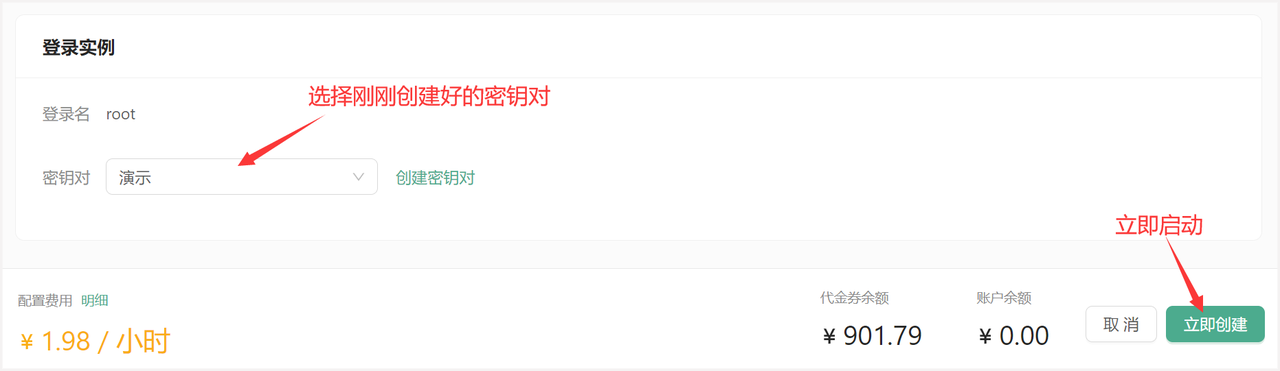
创建好密钥对后,选择刚刚创建好的密钥对,并点击立即创建,等待一段时间后即可启动成功!
部署与配置 Llama 3.1
实例成功创建后,我通过 JupyterLab 的在线登录入口进入了实例的操作界面。在这个环境中,所有的文件路径和资源配置都已经预先设置好,这极大地简化了操作。我通过 conda 创建了一个新的环境,并安装了部署 Llama 3.1 所需的依赖库,包括 LangChain、Streamlit、Transformers 和 Accelerate。
以下是安装依赖的关键命令:
pip install langchain==0.1.15
pip install streamlit==1.36.0
pip install transformers==4.44.0
pip install accelerate==0.32.1依赖安装完成后,平台提供了内网下载 Llama-3.1-8B 模型的功能,下载速度非常快。解压完模型后,我编写了一个简单的 Streamlit 脚本,用于启动 Llama 3.1 模型的聊天界面。Streamlit 的使用非常简便,可以快速搭建一个 Web 服务来和模型进行交互。
我的代码核心部分如下:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 创建标题和副标题
st.title("💬 LLaMA3.1 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 定义模型路径
mode_name_or_path = '/root/workspace/Llama-3.1-8B-Instruct'
# 获取模型和tokenizer
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
tokenizer, model = get_model()
# 聊天逻辑
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
input_ids = tokenizer([prompt], return_tensors="pt").to('cuda')
generated_ids = model.generate(input_ids.input_ids, max_new_tokens=512)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
st.chat_message("assistant").write(response)在终端中运行:
streamlit run llamaBot.py --server.address 0.0.0.0 --server.port 1024启动后,通过丹摩平台提供的端口映射功能,将内部端口映射到公网。通过链接,我成功访问到了我的 Llama 3.1 Chatbot 界面。
使用心得
通过这次实践,我对丹摩智算平台的易用性有了深刻的体会。首先,平台在创建实例、配置环境以及下载模型等环节提供了高度集成化的操作,省去了很多手动配置的麻烦,特别是在处理大模型时,内网高速下载和预装环境镜像极大地提高了工作效率。
在模型部署和使用过程中,我能够明显感受到 Llama 3.1 在生成式对话方面的强大性能,尤其是在自然语言理解和生成方面的表现出色。即便是 8B 版本,响应速度和文本生成质量都让我非常满意。这次实践让我深刻认识到,开源大模型与云端计算资源的结合,可以让开发者以更低的门槛接触到前沿的 AI 技术,快速实现自己的项目和想法。
总结
总体来说,丹摩智算平台提供了一个强大且高效的 AI 开发环境,尤其适合像我这样需要进行大模型部署和实验的开发者。无论是硬件资源的灵活选择,还是内置的环境配置和工具支持,都极大地简化了部署流程。通过这次部署 Llama 3.1 的实践,我不仅学会了如何高效利用云计算平台,也对大模型在实际项目中的应用有了更深刻的理解。