摘要
本文深入探讨了 C++ 标准库中的两大无序容器------unordered_set 和 unordered_map,从底层实现、核心操作、性能优化、实际应用等多个方面进行了全面分析。首先,文章介绍了这两种容器的基本概念,说明了它们基于哈希表实现的特点,尤其是在查找、插入和删除操作上具备常数时间复杂度的优势。接着,文章对比了有序容器和无序容器,指出了在不同应用场景下的适用性。
通过对哈希表封装的分析,文章详细讲解了插入、查找和删除操作的底层实现,并阐述了如何通过优化哈希函数、负载因子和重哈希机制来提升容器性能。高阶话题部分讨论了并发哈希表的使用、自定义哈希函数的实现等内容,为更复杂的工程场景提供了技术支持。
此外,本文通过实际案例展示了 unordered_set 和 unordered_map 在邮箱去重、快速键值对查询和 IP 过滤等应用中的具体使用,进一步增强了理论与实践的结合。最后,文章总结了读者通过此博客可以学习到的知识点,帮助读者从基础到高级掌握这两种容器的设计、优化与应用。
本篇博客所涉及的所有代码均可从 CSDN 下载区下载
1、引言
在现代 C++ 编程中,容器类库提供了各种强大而灵活的数据结构,帮助开发者高效地管理和处理数据。在这些容器中,unordered_set 和 unordered_map 凭借其基于哈希表的实现方式,成为解决查找、去重、数据存储等问题的利器。与传统的有序容器如 set 和 map 不同,unordered_set 和 unordered_map 以其常数时间复杂度 (O(1)) 进行查找、插入和删除操作,在处理大量数据时表现得尤为出色。
1.1、unordered_set 和 unordered_map 简介
unordered_set 和 unordered_map 是 C++ 标准库中基于哈希表的数据结构。与传统的有序容器 set 和 map 不同,unordered_set 和 unordered_map 并不保持元素的顺序,而是通过哈希函数将元素分配到内存中合适的位置,实现快速查找、插入和删除操作。
-
unordered_setunordered_set是一个无序集合容器,旨在存储不重复的元素,并提供快速的插入、查找和删除操作。由于底层使用了哈希表,元素之间没有顺序性,但可以确保每个元素的唯一性。这种容器在需要快速查找和去重时,能够展现出优越的性能,特别是在需要对大量数据进行去重操作时,unordered_set是首选。 -
unordered_mapunordered_map则是一个无序键值对容器,类似于字典或映射。它允许存储键-值对,并且同样基于哈希表实现,能够提供常数时间复杂度的查找和插入操作。与unordered_set类似,unordered_map的键没有顺序要求,能够快速定位特定的键,并返回其对应的值。其常见的应用场景包括构建缓存、快速查找索引、构建哈希映射等,特别是在需要高效键值查询的场景中,unordered_map是开发者的理想选择。
1.2、与 set 和 map 的区别
set 和 map 是基于平衡二叉树(如红黑树)实现的有序容器,元素按一定顺序排列,并且支持有序遍历。而 unordered_set 和 unordered_map 并不关注元素的顺序,而是依赖于哈希表来实现常数时间复杂度的操作。他都可以实现 key 和 key/value 的搜索场景,并且功能和使用基本一样。相比于 set 和 map,这两种无序容器虽然牺牲了数据的顺序性,但通过牺牲排序换来了更高效的查找速度。
在典型的有序容器 中,查找、插入和删除操作的时间复杂度为 O(log n) ,这是由于其内部使用了平衡二叉树(如红黑树)实现,降重+排序,遍历结果有序 。而 unordered_set 和 unordered_map 使用了哈希表结构,降重不排序,遍历结果无序 ,理论上可以在常数时间 O(1) 内完成这些操作,极大提高了效率。这使得它们在处理大规模数据集、需要频繁查找或插入的场景中表现得非常优越。
然而,哈希表的高效性并非无代价。由于哈希表的实现依赖于哈希函数,性能的优劣在很大程度上取决于哈希函数的质量。当哈希函数设计不当或发生哈希冲突时,性能可能会下降至 O(n) 级别。此外,unordered_set 和 unordered_map 的内存使用通常高于 set 和 map,因为哈希表需要额外的空间来处理哈希冲突及动态扩容。
最后,在迭代器方面,map 和 set 是双向迭代器,unordered_map 和 unordered_set 是单向迭代器
如果你对 map 和 set 还不够了解,我的这篇关于 map 和 set 的三万字详解博客请一定不要错过:《 C++ 修炼全景指南:十二 》用红黑树加速你的代码!C++ Set 和 Map 容器从入门到精通
1.3、为什么选择无序容器?
-
时间复杂度的优势
无序容器的最大优势在于其常数时间复杂度
O(1),这是通过哈希表实现的。相比于有序容器的O(log n)查找和插入操作,unordered_set和unordered_map能够大幅降低处理大量数据时的时间成本。尤其是在元素查找、删除、插入的频率较高时,O(1)的复杂度意味着这些操作几乎可以在恒定的时间内完成,不会随着数据规模的增加而显著变慢。 -
常数时间复杂度的意义
在典型的应用场景中,如数据库索引、数据查重、实时数据处理等,快速响应的需求非常高。
unordered_set和unordered_map在查找和插入方面几乎不受数据量的影响,能够保证始终如一的性能表现。这使得它们在需要大规模数据存取、高性能数据处理的应用中成为开发者的首选。此外,哈希表的特性使得冲突的处理(如链地址法、开放地址法)仍能保证较为高效的操作时间,虽然在极端情况下,最坏的情况时间复杂度可能退化为O(n),但这通常可以通过设计良好的哈希函数来避免。 -
常见应用场景中的价值
-
缓存(Cache):通过哈希映射实现快速缓存数据访问,能够有效缩短查找时间。
-
快速查找:无序容器由于常数时间复杂度的查找性能,适用于频繁查询的应用场景,如词典查找、用户信息检索等。
-
去重 :
unordered_set在需要去重操作的场景中表现出色,因为它能够快速检测并存储唯一元素。
-
在本文中,我们将深入探讨 unordered_set 和 unordered_map 的技术细节,从其底层实现原理、哈希函数设计,到如何应对哈希冲突和优化性能。我们还会通过代码示例,详细讲解这些容器的常见用法,以及如何在实际项目中合理应用它们。通过对这些内容的深入剖析,本文将帮助读者全面理解这两种无序容器的优势与局限,提供性能分析与优化的建议,并探讨其未来发展方向。
对于 C++ 开发者来说,掌握 unordered_set 和 unordered_map 的使用和优化技巧,不仅能够提升代码的性能,还能更好地应对实际开发中的数据管理问题。因此,无论是日常开发还是系统优化,这两种容器都是不可忽视的关键工具。希望通过本文的介绍,读者能够在未来的项目中更加高效、灵活地运用这些容器,编写出更加健壮和高效的 C++ 代码。
2、unordered_set 和 unordered_map 的使用与API详解
2.1、unordered_set 使用与 API 详解
unordered_set 是一个集合,它存储唯一值,并且这些值是无序的。它的底层实现是哈希表,因此具有常数时间复杂度 O(1) 的插入、删除和查找操作。
2.1.1、初始化与创建
unordered_set 可以通过多种方式初始化:
#include <unordered_set>
std::unordered_set<int> uset1; // 默认构造一个空的 unordered_set
std::unordered_set<int> uset2 = {1, 2, 3, 4}; // 使用列表初始化
std::unordered_set<int> uset3(uset2.begin(), uset2.end()); // 使用迭代器初始化
std::unordered_set<int> uset4(10); // 初始化时指定 bucket 数量2.1.2、插入元素
使用 insert() 来向集合插入元素,insert() 返回一个 pair,其中 first 是指向插入元素的迭代器,second 是一个布尔值,表示是否插入成功(当元素已存在时,插入失败)。
std::unordered_set<int> uset = {1, 2, 3};
auto result = uset.insert(4); // 插入成功, result.second == true
result = uset.insert(3); // 插入失败, result.second == false, 因为 3 已存在2.1.3、查找元素
通过 find() 来查找元素,返回值是一个指向该元素的迭代器。如果未找到,返回 end() 迭代器。
auto it = uset.find(2); // 找到 2, 返回指向它的迭代器
if (it != uset.end()) {
// 元素存在
} else {
// 元素不存在
}2.1.4、删除元素
使用 erase() 可以通过值或者迭代器删除元素:
uset.erase(2); // 删除值为 2 的元素
auto it = uset.find(3);
uset.erase(it); // 通过迭代器删除
uset.clear(); // 清空整个集合2.1.5、查询元素个数
size() 和 empty() 可以用来查询集合的大小和是否为空。
std::cout << uset.size(); // 输出元素个数
std::cout << uset.empty(); // 检查集合是否为空2.1.6、其他常用 API
count():返回元素是否存在(0 或 1)。bucket_count():返回哈希表的 bucket 数量。load_factor():返回集合的负载因子,用于衡量元素数量和 bucket 的比例。rehash():手动调整 bucket 数量以减少哈希冲突。
2.1.7、测试
#include <iostream>
#include <set>
#include <unordered_set>
int main()
{
std::unordered_set<int> us; // Java里面取名叫 HashSet
us.insert(4);
us.insert(2);
us.insert(1);
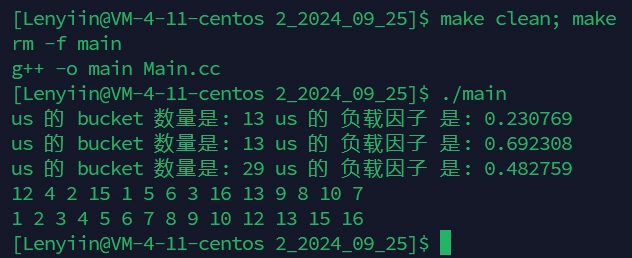
std::cout << "us 的 bucket 数量是: " << us.bucket_count()
<< "\tus 的 负载因子 是: " << us.load_factor() << std::endl;
us.insert(5);
us.insert(6);
us.insert(3);
us.insert(5);
us.insert(6);
us.insert(3);
us.insert(15);
us.insert(16);
us.insert(13);
std::cout << "us 的 bucket 数量是: " << us.bucket_count()
<< "\tus 的 负载因子 是: " << us.load_factor() << std::endl;
us.insert(15);
us.insert(16);
us.insert(13);
us.insert(9);
us.insert(8);
us.insert(10);
us.insert(7);
us.insert(12);
std::cout << "us 的 bucket 数量是: " << us.bucket_count()
<< "\tus 的 负载因子 是: " << us.load_factor() << std::endl;
// 会去重,但是不会自动排序
std::unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
std::set<int> s; // Java里面取名叫TreeSet
s.insert(4);
s.insert(2);
s.insert(1);
s.insert(5);
s.insert(6);
s.insert(3);
s.insert(5);
s.insert(6);
s.insert(3);
s.insert(15);
s.insert(16);
s.insert(13);
s.insert(15);
s.insert(16);
s.insert(13);
s.insert(9);
s.insert(8);
s.insert(10);
s.insert(7);
s.insert(12);
// set会去重,会自动排序
std::set<int>::iterator its = s.begin();
while (its != s.end())
{
std::cout << *its << " ";
++its;
}
std::cout << std::endl;
return 0;
}运行结果:
2.2、unordered_map 使用与 API 详解
unordered_map 是一个哈希表结构的键值对容器,每个键 (key) 唯一映射到一个值 (value)。它也提供了 O(1) 复杂度的插入、删除和查找操作。
unordered_map是存储<key, value>键值对的关联式容器,其允许通过 keys 快速的索引到与其对应的value- 在
unordered_map中,键值通常用于唯一的标识元素,而映射值是一个对象,其内容与次键关联。键和映射值得类型可能不同- 在内部,
unordered_map没有对<key, value>按照任何特定得顺序排序,为了能在常熟范围内找到key所对应得value,unordered_map将相同哈希值得键值对放在相同的桶中unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低unordered_map实现了直接访问操作(operator[]),它允许使用key作为参数直接访问value
2.2.1、初始化与创建
unordered_map 允许使用键值对或迭代器初始化:
#include <unordered_map>
std::unordered_map<int, std::string> umap1; // 默认构造空的 unordered_map
std::unordered_map<int, std::string> umap2 = {{1, "one"}, {2, "two"}}; // 列表初始化
std::unordered_map<int, std::string> umap3(umap2.begin(), umap2.end()); // 迭代器初始化
std::unordered_map<int, std::string> umap4(10); // 指定 bucket 数量2.2.2、插入元素
unordered_map 提供多种方式插入键值对:
-
insert():插入键值对。 -
operator[]:通过键直接插入或更新值。umap1.insert({3, "three"}); // 使用 insert 插入键值对
umap1[4] = "four"; // 使用 [] 插入或修改值
2.2.3、查找元素
可以使用 find() 或者 operator[] 来查找键对应的值:
auto it = umap1.find(2); // 查找键为 2 的元素
if (it != umap1.end()) {
std::cout << it->second; // 输出值
}
std::cout << umap1[1]; // 如果键不存在,使用 [] 会插入默认值注意: 使用 operator[] 如果键不存在,会默认插入一个元素,而 find() 则不会。
2.2.4、删除元素
erase() 可以通过键或者迭代器删除键值对:
umap1.erase(2); // 删除键为 2 的元素
auto it = umap1.find(3);
umap1.erase(it); // 通过迭代器删除
umap1.clear(); // 清空整个 map2.2.5、查询元素个数
和 unordered_set 类似,unordered_map 也提供 size() 和 empty() 来获取大小信息。
std::cout << umap1.size(); // 输出 map 中的键值对个数
std::cout << umap1.empty(); // 检查 map 是否为空2.2.6、其他常用 API
count():判断键是否存在,返回 0 或 1。bucket_count()和load_factor():与unordered_set一样,用于获取 bucket 信息和负载因子。rehash():重新调整 bucket 数量。
2.2.7、测试
#include <iostream>
#include <map>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, std::string> dict;
dict.insert(std::make_pair("hello", "你好"));
dict.insert(std::make_pair("world", "世界"));
dict.insert(std::make_pair("apple", "苹果"));
dict.insert(std::make_pair("orange", "橘子"));
dict.insert(std::make_pair("banana", "香蕉"));
dict.insert(std::make_pair("peach", "桃子"));
dict.insert(std::make_pair("peach", "桃子"));
dict.insert(std::make_pair("peach", "桃子"));
dict.insert(std::make_pair("sort", "排序"));
dict["string"] = "字符串";
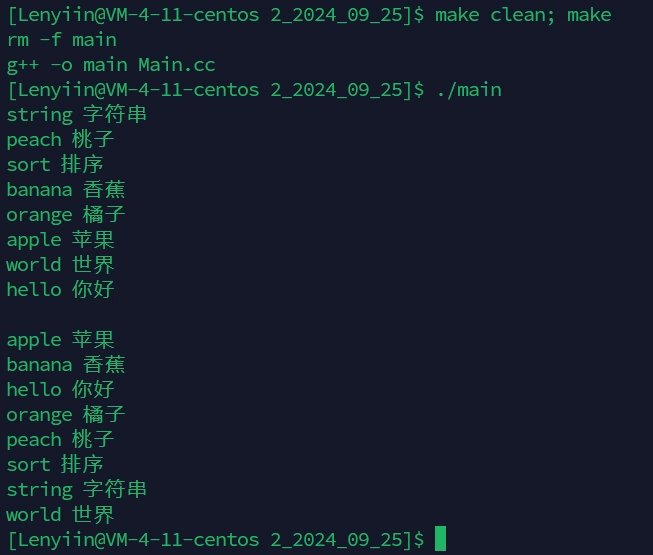
std::unordered_map<std::string, std::string>::iterator it = dict.begin();
while (it != dict.end())
{
std::cout << it->first << " " << it->second << std::endl;
++it;
}
std::cout << std::endl;
std::map<std::string, std::string> mdict;
mdict.insert(std::make_pair("hello", "你好"));
mdict.insert(std::make_pair("world", "世界"));
mdict.insert(std::make_pair("apple", "苹果"));
mdict.insert(std::make_pair("orange", "橘子"));
mdict.insert(std::make_pair("banana", "香蕉"));
mdict.insert(std::make_pair("peach", "桃子"));
mdict.insert(std::make_pair("peach", "桃子"));
mdict.insert(std::make_pair("peach", "桃子"));
mdict.insert(std::make_pair("sort", "排序"));
mdict["string"] = "字符串";
std::map<std::string, std::string>::iterator mit = mdict.begin();
while (mit != mdict.end())
{
std::cout << mit->first << " " << mit->second << std::endl;
++mit;
}
return 0;
}运行结果:
2.3、深入 API 与使用技巧
2.3.1、使用 emplace()
emplace() 是 C++11 引入的一个高效插入元素的方式,它避免了临时对象的创建:
umap1.emplace(5, "five"); // 在 map 中插入键值对
uset.emplace(6); // 在 set 中插入元素2.3.2、定制哈希函数
如果需要存储用户自定义的类型,可以通过自定义哈希函数来确保性能。unordered_set 和 unordered_map 支持传递自定义哈希器:
struct MyHash
{
std::size_t operator()(const std::pair<int, int>& p) const
{
return std::hash<int>()(p.first) ^ std::hash<int>()(p.second);
}
};
std::unordered_set<std::pair<int, int>, MyHash> customSet;2.3.3、遍历与迭代
unordered_set 和 unordered_map 都提供迭代器,支持范围 for 循环和迭代器遍历:
for (const auto& elem : uset)
std::cout << elem << " "; // 遍历 unordered_set 中的元素
for (const auto& pair : umap1)
std::cout << pair.first << ": " << pair.second << " "; // 遍历 unordered_map 中的键值对2.4、小结
unordered_set 和 unordered_map 都是基于哈希表的无序容器,能够在常数时间 O(1) 内进行插入、删除、查找等操作。通过熟练掌握它们的 API 以及性能特征,我们可以在需要高效查找和管理数据的场景中最大化地利用它们的优势。无论是在缓存管理、去重操作还是快速数据查询中,unordered_set 和 unordered_map 都是重要的工具。在实际应用中,选择合适的哈希函数、合理设置负载因子可以有效提高性能并减少哈希冲突,使程序更加高效和稳定。同时,结合自定义哈希函数和高级 API,我们还能够扩展它们的功能,为不同的应用场景提供更优的解决方案。
3、哈希表的基本概念
在C++标准库中,unordered_set 和 unordered_map 都是基于 哈希表(Hash Table) 的数据结构。这种数据结构通过将数据 "哈希化",即将键通过一个哈希函数映射到一个数组中的某个位置,从而实现常数时间复杂度的查找、插入和删除操作。为了更好地理解 unordered_set 和 unordered_map 的底层工作原理,以下将详细讲解它们的每个关键细节。
3.1、哈希表核心概念
顺序结构以及平衡树 中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为 O(N) ,平衡树中为数的高度,即 O(log2N) ,搜索的效率取决于搜索过程中元素的比较次序。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数 (hashFunc) 使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
哈希表的核心 在于将键值对映射到一个数组中的固定位置。这个映射是通过一个 哈希函数 实现的。哈希函数接收一个输入(即键),并根据某种算法生成一个整数,这个整数对应于哈希表的索引位置。
该方式即为哈希 (散列) 方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
- 哈希函数:哈希函数的目标是将键值对尽量均匀地分布到哈希表中,避免 "哈希冲突"(即不同的键映射到同一个数组位置)。
- 哈希桶(Bucket):哈希表的底层结构是一个包含多个 "桶" 的数组,每个桶存放一个或多个键值对。理想情况下,每个键通过哈希函数被映射到唯一的桶中,但实际情况下不可避免地会发生哈希冲突。
3.2、哈希冲突 (Hash Collision)
哈希冲突 是指多个不同的键在经过哈希函数计算后,生成了相同的哈希值。当不同的键映射到同一个哈希桶时,称之为哈希冲突。哈希冲突是不可避免的,特别是在哈希表的容量有限的情况下。因此,C++ 标准库提供了两种常见的解决哈希冲突的方法:
- 链地址法(Chaining):在每个桶内存储一个链表,当多个键被映射到同一个桶时,将这些键都插入到该桶对应的链表中。插入和查找时,会遍历链表中的元素,找到所需的键值对。
- 开放地址法(Open Addressing):当发生哈希冲突时,使用某种探测方法(如线性探测、二次探测等)寻找下一个空桶存放冲突的键值对。这种方法通过改变元素的存储位置来解决冲突,而不是在每个桶内使用链表。
C++ 标准库的 unordered_set 和 unordered_map 采用的是 链地址法,即每个桶存储一个链表。当发生哈希冲突时,冲突的元素会被追加到相应桶的链表中。
由于哈希表依赖于哈希函数将键分散到不同的桶中,避免冲突是优化哈希表性能的关键之一。例如:对于两个数据元素的关键字 ki 和 kj (i != j) ,有 ki != kj ,但有:Hash(ki) == Hash(kj) ,即:不同关键字通过相同哈系计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。 把具有不同关键码而具有相同哈希地址的数据元素称为"同义词"。
发生哈希冲突该如何处理呢?其中一个可能的原因:哈希函数
3.3、哈希函数与等价性判断
哈希函数和键的等价性判断是 unordered_set 和 unordered_map 的关键组件。
- 哈希函数(Hash Function) :默认情况下,
C++标准库为基本类型(如整数、浮点数、指针等)提供了标准的哈希函数。例如,std::hash<int>为整数类型提供哈希支持。如果使用用户定义类型作为键,用户需要提供自己的哈希函数,或者重载std::hash函数模板。 - 等价性判断(Equality Comparator) :即使两个键的哈希值相同,哈希表也需要通过 等价性判断函数 确认它们是否真的是相同的键。
unordered_set和unordered_map使用==操作符判断键是否相等。如果使用自定义类型作为键,用户也需要重载等价性判断操作符。
引起哈希冲突的一个原因是:哈希函数设计的不够合理。哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有 m 个地址时,其值域必须在 0 到 m-1 之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
哈希函数和等价性判断的工作流程如下:
-
哈希表根据键调用哈希函数,计算出对应的桶索引。
-
如果桶内有多个元素(即发生哈希冲突),则通过等价性判断函数依次检查键是否相等,直到找到匹配的键值对或确定没有该键。
3.4、unordered_set 和 unordered_map 的扩展和负载因子
为了保持哈希表的性能,必须控制哈希表的 负载因子(Load Factor) ,即哈希表中存储的元素个数与桶的数量之比。当负载因子过高时,哈希冲突会变得频繁,导致查找、插入、删除操作的效率下降。因此,哈希表需要在元素数量达到一定阈值时,进行 扩展(Rehashing)。
- 扩展(Rehashing) :当负载因子超过某个预定值(默认情况下,
C++标准库的负载因子阈值为 1.0,即桶的数量等于元素数量),哈希表会进行扩展。扩展的过程是:- 创建一个新的、更大的桶数组。
- 重新计算所有现有元素的哈希值,并将它们移动到新的桶中。
扩展是一个相对耗时的操作,但它可以确保哈希表的长期性能不受负载因子增加的影响。
3.5、unordered_set 和 unordered_map 的存储结构
虽然 unordered_set 和 unordered_map 都是基于哈希表实现的,但它们存储的内容有所不同:
unordered_set:存储的是不重复的键。每个键只在哈希表中出现一次,且只进行键的存储和查找操作。unordered_map:存储的是键-值对(key-value pairs)。每个键关联一个值,可以通过键来查找对应的值。unordered_map提供的 API 如operator[]能够轻松通过键访问或修改其关联的值。
3.6、性能优化:哈希函数的选择
unordered_set 和 unordered_map 的性能在很大程度上取决于哈希函数的质量。一个好的哈希函数应该具备以下几个特性:
- 均匀分布:哈希函数应尽量将键均匀分布到各个桶中,避免某些桶过于集中,从而减少哈希冲突。
- 计算效率高:哈希函数的计算应该足够高效,以保证查找、插入和删除操作的整体性能。
- 稳定性:哈希函数的输出应稳定,确保相同的键在不同的操作系统、编译器或运行时环境中生成相同的哈希值。
如果哈希函数设计不当,哈希冲突会频繁发生,导致链表过长,查找性能从 O(1) 退化为 O(n)。因此,在选择或自定义哈希函数时,需要综合考虑分布性和效率。
常见哈希函数:
1、直接定制法(常用)
取关键字的某个线性函数为散列地址:Hash(key) = A*key + B 。优点:简单,均匀。缺点:需要事先知道关键字的分布情况。使用场景:适合查找比较小且连续的情况。
面试题:字符串中第一个只出现一次的字符
class Solution {
public:
int firstUniqChar(string s) {
// 使用映射的方式统计次数
int count[26] = {0};
for (auto ch : s)
{
count[ch - 'a']++;
}
for (size_t i = 0; i < s.size(); i++)
{
if (count[s[i]-'a'] == 1)
{
return i;
}
}
return -1;
}
};2、除留余数法(常用)
设散列表中允许地址为 m ,取一个不大于 m ,但最接近或者等于 m 的质数 p 作为除数,按照哈希函数:
Hash(key) = key % p (p <= m) ,将关键码转换成哈希地址
3、平方取中法(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址。平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4、折叠法(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5、随机数法(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即 H(key) = random(key) ,其中 random 为随机数函数。
通常应用于关键字长度不等时采用此法
6、数学分析法(了解)
设有 n 个 d 位数,每一位可能有 r 种不同的符号,这 r 种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
例如:假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现冲突,还可以对抽取出来的数字进行反转 (如1234改成4321) 、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加 (如1234改成12+34=46) 等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
注意:哈系数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
3.7、unordered_set 和 unordered_map 在并发环境下的表现
在多线程环境中,unordered_set 和 unordered_map 并不是线程安全的。这意味着当多个线程同时对同一个容器进行读写操作时,可能会导致数据竞争或不一致。因此,在并发环境下使用时,需要额外的同步机制(如锁)来保证操作的安全性。
不过,现代C++标准库提供了一些支持并发操作的容器(如 concurrent_unordered_map),可以更高效地在多线程环境下处理无序数据。
4、哈希冲突解决方法及实现
在unordered_set和unordered_map中,哈希冲突是一个至关重要的技术问题,直接影响到容器的效率和性能。哈希冲突的详细机制以及如何应对它们,对于理解哈希表的底层实现至关重要。
什么是哈希冲突:
- 哈希冲突是指多个不同的键在经过哈希函数计算后,生成了相同的哈希值。当不同的键映射到同一个哈希桶时,称之为哈希冲突。由于哈希表依赖于哈希函数将键分散到不同的桶中,避免冲突是优化哈希表性能的关键之一。
解决哈希冲突的常见方法:
- 常见的解决哈希冲突的技术主要包括开放地址法(Open Addressing)和链地址法(Chaining) ,又叫闭散列和开散列。
4.1、开放地址法(Open Addressing)
开放地址法,又叫做闭散列 ,是解决哈希冲突的主要方法之一,它的核心思想是,当哈希表发生哈希冲突,哈希表中某个位置已经被占用时,如果哈希表未被装满,说明在哈希表种必然还有空位置,通过一系列规则把 key 存放到冲突位置中的 "下一个" 空闲的桶中去。通过一系列规则寻找下一个空闲的桶,而不是使用链表或其他数据结构来存储冲突的元素。与链地址法相比,开放地址法将所有的元素都存储在哈希表的桶内,不使用外部存储,能够节省内存,但对于装载因子的要求比较严格。
那么如何寻找下一个空闲的桶呢?开放地址法的三种常见策略:
- 线性探测(Linear Probing)
- 二次探测(Quadratic Probing)
- 双重哈希(Double Hashing)
4.1.1、基本结构
首先,我们定义了一个哈希表中的状态枚举类:
enum State
{
EMPTY, // 槽位为空
EXIST, // 槽位已经存在一个元素
DELETE // 槽位中元素被删除
};其次定义一个函数对象 SetKeyOfT ,用于从模板类型中提取键值:
template <class K>
struct SetKeyOfT
{
const K &operator()(const K &key)
{
return key;
}
};每个哈希表的槽位用结构体 HashData<T> 表示,它包含了数据 _data 和槽位状态 _state:
template <class T>
struct HashData
{
T _data;
State _state;
};HashTable<K, T, KeyOfT> 是模板类,其中 K 是键类型,T 是存储的元素类型,KeyOfT 是一个函数对象,用于从 T 类型中提取键值。
namespace Lenyiin
{
template <class K>
struct SetKeyOfT
{
const K &operator()(const K &key)
{
return key;
}
};
enum State
{
EMPTY,
EXIST,
DELETE
};
template <class T>
struct HashData
{
T _data;
State _state;
};
template <class K, class T, class KeyOfT>
class HashTable
{
private:
typedef struct CLOSE_HASH::HashData<T> HashData;
public:
bool Insert(const T &data);
HashData *Find(const K &key);
bool Erase(const K &key);
private:
vector<HashData> _tables;
size_t _num = 0; // 存了几个有效数字
};
}4.1.2、扩容
在哈希表的开放地址法(也称为闭散列)中,由于所有元素都存储在同一个数组中,当数组变得接近满时,哈希冲突的概率会显著增加,导致性能下降。因此,扩容(Rehashing or Resizing) 是解决这种问题的重要步骤。扩容可以在哈希表的负载因子达到某个临界值时进行,它能够降低冲突的频率,从而提升哈希表的性能。
1、什么是负载因子?
负载因子是衡量哈希表中元素的占用情况的指标,定义为:
负载因子 = 表中的元素个数 / 表的总大小- 负载因子越大,说明哈希表越满,冲突的可能性越高。
- 一般情况下,当负载因子超过一定阈值(通常为 0.7),我们就需要进行扩容。
在开放地址法中,扩容的关键步骤是:
- 创建一个新的、更大的数组(通常是原数组的 2 倍大小)。
- 重新计算每个元素的哈希值,并将它们插入新数组中。
- 释放旧数组的空间,切换到新数组。
接下来,我们将详细讨论如何在开放地址法中实现扩容。
2、扩容的步骤
2.1 判断何时进行扩容
在哈希表中,通常通过检查负载因子来决定是否需要扩容。一个常见的扩容条件是:当负载因子超过某个阈值(如 0.7)时,进行扩容。
if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7) {
// 触发扩容逻辑
}_num 是当前哈希表中有效元素的数量,_tables.size() 是哈希表的容量。
2.2、创建新的哈希表
扩容的第一步是创建一个新的、更大的哈希表(数组),通常是原哈希表容量的两倍。
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
std::vector<HashData> newtables(newsize);- 如果原哈希表大小为 0,则初始化为 10 个槽位;
- 如果哈希表已有数据,则将容量扩展为当前大小的两倍。
3、重新哈希并插入数据
在开放地址法中,由于数组的大小发生了变化,旧表中每个元素的哈希值也会发生变化。因此,扩容后需要重新计算每个元素的哈希值,并将它们插入新表中。
-
计算新位置:通过哈希函数重新计算元素在新数组中的位置。
-
处理冲突:由于是开放地址法,如果新位置被占用,则需要使用探测法(如线性探测、二次探测或双重哈希)来寻找新的空槽位。
for (size_t i = 0; i < _tables.size(); i++) {
if (_tables[i]._state == EXIST) {
// 重新计算新表中的位置
size_t index = koft(_tables[i]._data) % newtables.size();
size_t step = SecondHash(koft(_tables[i]._data), newtables.size());// 处理冲突:双重哈希探测 while (newtables[index]._state == EXIST) { index = (index + step) % newtables.size(); } // 插入元素到新表 newtables[index] = _tables[i]; }}
在这个过程中,旧哈希表中的所有有效元素都会根据新表的大小重新计算位置,并插入到新的哈希表中。我们使用了双重哈希策略来处理冲突,确保每个元素都能够正确地插入。
4、释放旧表并切换到新表
完成数据迁移后,我们使用 swap 函数来释放旧表,并将 _tables 指向新的哈希表。
_tables.swap(newtables);swap 函数通过交换内存地址,能够高效地完成旧表与新表的切换,旧表在此操作后自动释放内存。
4.1.3、扩容的代码实现
下面是完整的扩容实现代码,结合了线性探测法、二次探测法和双重哈希策略。
1、version 1 使用线性探测处理冲突
// 负载因子 = 表中数据/表的大小 衡量哈希表满的程度
// 表越接近满, 插入数据越容易冲突, 冲突越多, 效率越低
// 哈希表并不是满了才增容, 开放定制法中, 一般负载因子到 0.7 左右就开始增容
// 负载因子越小, 冲突概率越低, 整体效率越高, 但是负载因子越小, 浪费的空间越大, 所以负载因子一般取一个折中的值
void CheckCapacity()
{
KeyOfT koft;
// version 1
if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
{
// 增容
// 1. 开 2倍大小的新表
// 2. 遍历旧表的数据,重新计算在新表中位置
// 3. 释放旧表
std::vector<HashData> newtables;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
// 计算在新表中的位置, 并处理冲突
size_t index = koft(_tables[i]._data) % newtables.size();
while (newtables[index]._state == EXIST)
{
++index;
if (index == _tables.size())
{
index = 0;
}
}
newtables[index] = _tables[i];
}
}
_tables.swap(newtables);
}
}2、version 2 使用双重探测处理冲突
void CheckCapacity()
{
KeyOfT koft;
// version 2
if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
{
// 增容
// 1. 开 2倍大小的新表
// 2. 遍历旧表的数据,重新计算在新表中位置
// 3. 释放旧表
std::vector<HashData> newtables;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
// 重新计算新表中的位置
size_t index = koft(_tables[i]._data) % newtables.size();
size_t step = SecondHash(koft(_tables[i]._data), newtables.size());
// 处理冲突:双重哈希探测
while (newtables[index]._state == EXIST)
{
index = (index + step) % newtables.size();
}
// 插入元素到新表
newtables[index] = _tables[i];
}
}
_tables.swap(newtables);
}
}3、version 3 复用插入函数:
void CheckCapacity()
{
KeyOfT koft;
// version 3
// 另一种增容思路
if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
{
Close_HashTable<K, T, KeyOfT> newht;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
newht._tables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
newht.Insert(_tables[i]._data);
}
}
_tables.swap(newht._tables);
}
}4.1.4、扩容的重要性
在哈希表中,扩容是维持哈希表效率的重要手段。负载因子越高,意味着哈希表越满,冲突越频繁。适时扩容不仅可以减少冲突的发生,还能够提高查找和插入的效率。
- 空间与时间的平衡:虽然扩容会占用更多的内存空间,但它能够显著提高哈希表的操作效率,避免由于过多冲突导致的性能下降。
- 动态扩容:动态扩容的实现保证了哈希表可以根据实际数据量的增加而自动调整大小,适应不同规模的数据存储需求。
开放地址法中的扩容是提升哈希表性能的关键步骤。通过适时调整哈希表的大小,能够有效避免冲突,确保查找、插入、删除操作的高效性。在实际应用中,扩容往往和负载因子的控制紧密结合,以实现空间和时间性能的平衡。
在实际代码实现中,我们使用了负载因子作为扩容的触发条件,并通过双重哈希策略处理冲突。在扩容后,我们需要将所有数据重新哈希并插入新的哈希表,以保证哈希表的正确性和效率。
4.1.5、线性探测(Linear Probing)
线性探测的策略是,当哈希冲突发生时,按固定的步长(通常为1)逐步向后查找下一个空闲的桶。
插入中的线性探测:
-
通过哈希函数获取待插入元素在哈希表中的位置
-
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
代码示例:
KeyOfT koft;
// 线性探测
// 计算 data 中的 key 在表中映射的位置
size_t index = koft(data) % _tables.size();
while (_tables[index]._state == EXIST)
{
// 如果存在重复键值,插入失败
if (koft(_tables[index]._data) == koft(data))
{
return false;
}
// 线性探测:当前槽位被占用,尝试下一个
++index;
if (index == _tables.size())
{
index = 0; // 回到表头,形成环
}
}技术细节:
- 优点:线性探测的实现简单,插入、查找和删除操作的步骤非常清晰。
- 缺点 :容易出现集群现象(clustering)。一旦发生哈希冲突,所有的冲突连在一起,容易产生数据"堆积",即当哈希表中的连续桶已经被占用时,冲突的概率急剧上升,从而导致大量的连续探测操作,使得寻找某关键码的位置需要许多次比较,导致性能下降。
- 最坏情况 :在装载因子较高的情况下,时间复杂度可能退化为
O(n),其中n为桶的数量。
4.1.6、二次探测(Quadratic Probing)
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找到空位置的方式就是挨着往后逐个去找。为了解决线性探测中的集群问题,二次探测通过增加探测序列的距离来避免过度集群。其核心思想是,每次探测时,移动的步长不是固定的,而是根据探测次数的平方来增长。
例如:探测序列为i, i + 1^2, i + 2^2, i + 3^2, ...,避免线性探测中的连续探测问题。
代码示例:
KeyOfT koft;
// 二次探测
// 计算 d 中的 key 在表中映射的位置
size_t start = koft(data) % _tables.size();
size_t index = start;
int i = 1;
while (_tables[index]._state == EXIST)
{
if (koft(_tables[index]._state) == koft(data))
{
return false;
}
index = start + i * i;
i++;
index %= _tables.size();
}
_tables[index]._data = data;
_tables[index]._state = EXISTS;
_num++;技术细节:
-
优点:二次探测通过探测距离的变化,减少了线性探测中的集群问题,因此在哈希表装载因子较高时仍能保持较高的性能。
-
缺点:由于探测距离逐渐增加,二次探测在装载因子接近 1 时,可能导致一些桶永远无法被探测到。因此,容量需要保持为质数或采取其他措施,确保探测过程中不会遗漏桶。
研究表明:当表的长度为质数,且表装载因子 a 不超过 0.5 时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但是在插入时必须确保表的装在因子 a 不超过 0.5 ,如果超过必须考虑增容。
-
最坏情况 :与线性探测类似,在极端情况下,时间复杂度仍可能退化为
O(n)。
4.1.7、双重哈希(Double Hashing)
双重哈希是开放地址法中最有效的冲突解决方案之一。它利用两个不同的哈希函数来确定探测序列,从而最大限度地减少冲突和集群问题。双重哈希的策略是:首先用一个哈希函数确定初始位置,如果发生冲突,则通过另一个哈希函数来决定步长。
双重哈希(Double Hashing) 是另一种开放定址法中用于解决哈希冲突的策略。它不同于线性探测和二次探测,双重哈希利用两个不同的哈希函数来确定探测序列,从而最大限度地减少冲突和集群问题,重哈希的策略是:首先用一个哈希函数确定初始位置,如果发生冲突,则通过第二个哈希函数来确定探测的步长(step size)。双重哈希的优点是减少了线性探测和二次探测中容易产生的**群集效应(clustering)**问题。
在双重哈希策略中,插入时我们会先计算哈希表的主位置(index),然后通过一个辅助哈希函数 计算探测步长,当发生冲突时,探测下一个位置为: index = (index + i * step) % table_size,其中 step 是由第二个哈希函数计算出来的步长,i 是探测的次数。
辅助哈希函数
首先,我们需要定义一个辅助哈希函数 。这个辅助哈希函数通常是一个简单的函数,例如:
step = 1 + (key % (table_size - 1))
确保步长不为 0,且与表大小互质,从而保证探测序列覆盖整个表。
size_t SecondHash(const K& key, size_t table_size)
{
return 1 + (key % (table_size - 1));
}插入操作中的双重哈希
在插入操作中,如果初次插入的哈希槽位已经被占用,我们就会使用双重哈希函数计算探测步长,并根据步长进行冲突解决。
双重哈希插入的逻辑如下:
size_t index = koft(data) % _tables.size();
size_t step = SecondHash(koft(data), _tables.size());
while (_tables[index]._state == EXIST)
{
if (koft(_tables[index]._data) == koft(data))
{
return false; // 如果找到相同的 key,插入失败
}
index = (index + step) % _tables.size(); // 使用双重哈希计算下一个位置
}在这个例子中,step 是通过 SecondHash 计算的,它决定了每次探测时的位置偏移量。这样可以避免线性探测或二次探测中较为集中的冲突问题。
查找和删除中的双重哈希
在查找和删除操作中,双重哈希的探测过程和插入类似。我们会首先计算哈希的初始位置,然后通过辅助哈希函数计算探测步长,直到找到空槽或匹配的元素。
HashData *Find(const K &key)
{
KeyOfT koft;
size_t index = key % _tables.size();
size_t step = SecondHash(key, _tables.size()); // 计算步长
while (_tables[index]._state != EMPTY)
{
if (koft(_tables[index]._data) == key)
{
if (_tables[index]._state == EXIST)
{
return &_tables[index];
}
else if (_tables[index]._state == DELETE)
{
return nullptr;
}
}
index = (index + step) % _tables.size(); // 使用双重哈希探测下一个位置
}
return nullptr;
}删除操作与查找类似,先调用 Find 找到对应的槽位,然后将状态标记为 DELETE。
技术细节:
- 优点 :避免一次探测集群问题 :双重哈希法在冲突解决方面非常高效,因其探测序列由两个不同的哈希函数决定,几乎完全消除了集群现象,表现接近理想情况。更均匀的探测:与线性探测和二次探测相比,双重哈希能够更均匀地分布探测序列,减少由于冲突引发的效率下降。
- 缺点:实现相对复杂,需要设计两个有效的哈希函数。如果第二个哈希函数设计不当,可能导致探测序列重复,影响效率。
4.1.8、小结
- 线性探测适合简单的哈希表实现,但容易受到集群问题的困扰。
- 二次探测在探测序列上进行优化,适用于中等规模的哈希表,且比线性探测更高效。
- 双重哈希提供了最佳的冲突解决方案,减少了集群现象,适用于高性能需求的哈希表。
对于开放地址法来说,装载因子对性能影响显著,较高的装载因子会导致大量的探测操作。因此,合理的装载因子(一般建议不超过 0.7)和适当的扩容策略是确保哈希表性能的关键。
4.2、开放地址法(Open Addressing)的完整实现及测试
4.2.1、HashTable.hpp
#pragma once
#include <iostream>
#include <vector>
#include <string>
namespace Lenyiin
{
template <class K>
struct SetKeyOfT
{
const K &operator()(const K &key)
{
return key;
}
};
enum State
{
EMPTY, // 槽位为空
EXIST, // 槽位已经存在一个元素
DELETE // 槽位中元素被删除
};
template <class T>
struct HashData
{
T _data;
State _state;
HashData()
: _data(T()), _state(EMPTY)
{
}
};
template <class K, class T, class KeyOfT>
class Close_HashTable
{
private:
typedef struct HashData<T> HashData;
size_t SecondHash(const K &key, size_t table_size)
{
return 1 + (key % (table_size - 1));
}
public:
// 负载因子 = 表中数据/表的大小 衡量哈希表满的程度
// 表越接近满, 插入数据越容易冲突, 冲突越多, 效率越低
// 哈希表并不是满了才增容, 开放定制法中, 一般负载因子到 0.7 左右就开始增容
// 负载因子越小, 冲突概率越低, 整体效率越高, 但是负载因子越小, 浪费的空间越大, 所以负载因子一般取一个折中的值
void CheckCapacity()
{
KeyOfT koft;
// // version 1
// if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
// {
// // 增容
// // 1. 开 2倍大小的新表
// // 2. 遍历旧表的数据,重新计算在新表中位置
// // 3. 释放旧表
// std::vector<HashData> newtables;
// size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// newtables.resize(newsize);
// for (size_t i = 0; i < _tables.size(); i++)
// {
// if (_tables[i]._state == EXIST)
// {
// // 计算在新表中的位置, 并处理冲突
// size_t index = koft(_tables[i]._data) % newtables.size();
// while (newtables[index]._state == EXIST)
// {
// ++index;
// if (index == _tables.size())
// {
// index = 0;
// }
// }
// newtables[index] = _tables[i];
// }
// }
// _tables.swap(newtables);
// }
// // version 2
// if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
// {
// // 增容
// // 1. 开 2倍大小的新表
// // 2. 遍历旧表的数据,重新计算在新表中位置
// // 3. 释放旧表
// std::vector<HashData> newtables;
// size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// newtables.resize(newsize);
// for (size_t i = 0; i < _tables.size(); i++)
// {
// if (_tables[i]._state == EXIST)
// {
// // 重新计算新表中的位置
// size_t index = koft(_tables[i]._data) % newtables.size();
// size_t step = SecondHash(koft(_tables[i]._data), newtables.size());
// // 处理冲突:双重哈希探测
// while (newtables[index]._state == EXIST)
// {
// index = (index + step) % newtables.size();
// }
// // 插入元素到新表
// newtables[index] = _tables[i];
// }
// }
// _tables.swap(newtables);
// }
// version 3
// 另一种增容思路
if (_tables.size() == 0 || _num * 10 / _tables.size() >= 7)
{
Close_HashTable<K, T, KeyOfT> newht;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
newht._tables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
newht.Insert(_tables[i]._data);
}
}
_tables.swap(newht._tables);
}
}
bool Insert(const T &data)
{
KeyOfT koft;
CheckCapacity();
// 闭散列中线性探测有什么问题?
// 线性探测思路就是我的位置被占了, 我就挨着往后去占别人的位置, 可能会导致一片一片的冲突, 洪水效应
// version 1
// 线性探测
// 计算 data 中的 key 在表中映射的位置
// size_t index = koft(data) % _tables.size();
// while (_tables[index]._state == EXIST)
// {
// if (koft(_tables[index]._data) == koft(data))
// {
// return false; // 已经存在
// }
// ++index;
// if (index == _tables.size())
// {
// index = 0;
// }
// }
// version 2
// 二次探测
// 计算 data 中的 key 在表中映射的位置
// size_t start = koft(data) % _tables.size();
// size_t index = start;
// int i = 0;
// while (_tables[index]._state == EXIST)
// {
// if (koft(_tables[index]._data) == koft(data))
// {
// return false; // 已经存在
// }
// index = start + i * i;
// i++;
// index %= _tables.size();
// }
// version 3
// 双重哈希
size_t index = koft(data) % _tables.size();
size_t step = SecondHash(koft(data), _tables.size());
while (_tables[index]._state == EXIST)
{
if (koft(_tables[index]._data) == koft(data))
{
return false; // 如果找到相同的 key,插入失败
}
index = (index + step) % _tables.size(); // 使用双重哈希计算下一个位置
}
_tables[index]._data = data;
_tables[index]._state = EXIST;
++_num;
// 我么可以看到闭散列-开放定制法不是一种好的解决方式, 因为它是一种我的位置被占了, 我就去抢占别人的位置的思路
// 也就是说他的哈希冲突会相互影响, 我冲突占你的, 你冲突占他的, 他冲突了... , 没完没了, 整体的效率都变低了
// 开散列的哈希桶可以解决上面的问题
return true;
}
// 线性探测
// HashData *Find(const K &key)
// {
// KeyOfT koft;
// // 计算 data 中的 key 在表中映射的位置
// size_t index = key % _tables.size();
// while (_tables[index]._state != EMPTY)
// {
// if (koft(_tables[index]._data) == key)
// {
// if (_tables[index]._state == EXIST)
// {
// return &_tables[index];
// }
// else if (_tables[index]._state == DELETE)
// {
// return nullptr;
// }
// }
// ++index;
// if (index == _tables.size())
// {
// index = 0;
// }
// }
// return nullptr;
// }
// 双重哈希
HashData *Find(const K &key)
{
KeyOfT koft;
size_t index = key % _tables.size();
size_t step = SecondHash(key, _tables.size()); // 计算步长
while (_tables[index]._state != EMPTY)
{
if (koft(_tables[index]._data) == key)
{
if (_tables[index]._state == EXIST)
{
return &_tables[index];
}
else if (_tables[index]._state == DELETE)
{
return nullptr;
}
}
index = (index + step) % _tables.size(); // 使用双重哈希探测下一个位置
}
return nullptr;
}
bool Erase(const K &key)
{
HashData *ret = Find(key);
if (ret)
{
ret->_state = DELETE;
--_num;
return true;
}
else
{
return false;
}
}
HashData &getHashData(int pos)
{
return _tables[pos];
}
void Print()
{
int size = _tables.size();
for (int i = 0; i < size; i++)
{
std::cout << i << "\t";
}
std::cout << std::endl;
for (int i = 0; i < size; i++)
{
auto cur = _tables[i];
if (cur._state == EXIST)
{
std::cout << cur._data << "\t";
}
else
{
std::cout << "*\t";
}
}
std::cout << "\n\n";
}
private:
std::vector<HashData> _tables;
size_t _num = 0; // 存储了几个有效数据
};
}4.2.2、Main.cc
#include "HashTable.hpp"
void Test_Close_HashTable()
{
Lenyiin::Close_HashTable<int, int, Lenyiin::SetKeyOfT<int>> ht;
ht.Insert(4);
ht.Insert(14);
ht.Insert(24);
ht.Insert(5);
ht.Insert(15);
ht.Insert(25);
ht.Insert(6);
ht.Insert(16);
ht.Print();
ht.Erase(14);
ht.Erase(24);
ht.Print();
std::cout << "是否存在 5 ? " << (ht.Find(5) ? "true" : "false") << std::endl;
}
int main()
{
Test_Close_HashTable();
return 0;
}4.2.3、测试结果

4.3、链地址法(Chaining)
链地址法(Separate Chaining),又叫开散列 ,是一种处理哈希冲突的经典方法,与开放地址法(如线性探测法、二次探测法、双重哈希法)不同的是,链地址法在哈希表的每个槽位上都维护一个链表,每当发生冲突时,新的数据会被追加到链表的末尾。这种方式极大减少了由于哈希冲突带来的性能问题,并避免了开放地址法中的 "探测" 过程。
在本章中,我们将基于 C++ 的实现,深入探讨链地址法的基本原理、实现细节、优缺点,以及如何高效地进行增删查操作。并通过代码示例来帮助理解。
4.3.1、 什么是哈希冲突?
哈希表的核心在于将键值映射到一个有限的数组中,当不同的键值经过哈希函数计算后映射到相同的位置时,便产生了哈希冲突。链地址法通过在每个槽位上使用链表来解决冲突,即:多个映射到同一个位置的元素都存储在该位置的链表中。
链地址法的基本思想可以简单总结为:
- 每个哈希表的槽位存储的是一个链表。
- 如果一个新元素与某个元素冲突(哈希到相同的位置),它将被插入到链表的末尾。
4.3.2、基本结构
链地址法的核心思想是:每个哈希表的桶(bucket)不仅存储单一元素,还可以存储一个链表(通常是单链表)的节点。每个链表的头节点位于桶中,当多个元素发生冲突时,将新元素添加到该链表中。这样,冲突的元素不再需要重新寻找存储位置,而是直接插入链表,避免了地址冲突的问题。
1、哈希桶节点结构
template <class T>
struct HashNode
{
T _data; // 存储数据
HashNode<T> *_next; // 存储下一个节点
// 如果想要实现迭代顺序为插入顺序, 可以加两个指针组成一个链表
// HashNode<T>* _linknext;
// HashNode<T>* _linkprev;
HashNode(const T &data)
: _data(data), _next(nullptr)
{
}
};2、哈希表的结构
哈希表是一种键值对(Key-Value)结构,其中每个键(Key)通过哈希函数映射到特定的索引位置。该位置存储了一个链表的头节点(即哈希桶)。通过链表的方式,可以处理多个具有相同哈希值的键值对。
template <class K, class T, class KeyOfT, class Hash>
class Open_HashTable {
private:
typedef HashNode<T> Node; // 链表节点
// 存储哈希桶的数组,数组中的每个元素是一个指向链表头节点的指针
std::vector<Node *> _tables;
size_t _num = 0; // 记录哈希表中实际存储的数据个数
};3、哈希函数
哈希函数用于将键(Key)转换为哈希值,并通过取模运算映射到表的索引位置。哈希函数的设计直接影响哈希表的性能。常用的哈希函数设计有许多种,例如 BKDR Hash,其作用是尽量减少哈希冲突。
template <class K>
struct _Hash
{
const K& operator()(const K& key)
{
return key;
}
};
// 特化
template <>
struct _Hash<std::string>
{
size_t operator()(const std::string &key)
{
// BKDR Hash算法
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
hash *= 131; // 选择131作为乘数
hash += key[i]; // 将字符转换为整数并累加
}
return hash;
}
};4.3.3、链地址法的插入操作
在链地址法中,插入操作的步骤为:
-
计算哈希值:通过哈希函数计算键对应的槽位位置。
-
遍历链表:检查该槽位对应的链表,看看是否有相同的键存在。如果存在,更新其值。
-
冲突处理:如果链表中没有相同的键,直接将新元素插入到链表的末尾。
bool Insert(const T &data) {
KeyOfT koft;// 计算数据在表中映射的位置 size_t index = HashFunc(koft(data)) % _tables.size(); // 查找是否已经存在相同的值 Node *cur = _tables[index]; while (cur) { if (HashFunc(koft(cur->_data)) == HashFunc(koft(data))) { return false; } cur = cur->_next; } // 头插法插入新节点 Node *newnode = new Node(data); newnode->_next = _tables[index]; _tables[index] = newnode; ++_num; // 更新存储的数据个数 return true;}
链地址法通过链表处理冲突,这意味着即使多个元素映射到同一个槽位,它们也可以共存于该槽位的链表中。
4.3.4、链地址法的查找操作
查找操作的步骤类似于插入:
-
计算哈希值:通过哈希函数计算键的槽位位置。
-
遍历链表 :在槽位对应的链表中查找目标键,如果找到,返回指向该节点的指针;如果找不到,返回
nullptr。。Node *Find(const K &key) {
KeyOfT koft;// 计算 key 对应的哈希值 size_t index = HashFunc(key) % _tables.size(); Node *cur = _tables[index]; // 遍历链表查找对应的值 while (cur) { if (HashFunc(koft(cur->_data)) == HashFunc(key)) { return cur; } cur = cur->_next; } return nullptr;}
如果目标键在链表中存在,则返回对应的值;如果不存在,则返回 nullptr。
4.3.5、链地址法的删除操作
删除操作的步骤是:
-
计算哈希值:通过哈希函数计算键的槽位位置。
-
遍历链表:在链表中查找目标键,找到后,将该节点从链表中移除,并释放其内存。
bool Erase(const K &key) {
KeyOfT koft;
size_t index = HashFunc(key) % _tables.size();
Node *prev = nullptr;
Node *cur = _tables[index];while (cur) { if (HashFunc(koft(cur->_data)) == HashFunc(key)) { if (prev == nullptr) { _tables[index] = cur->_next; // 删除头节点 } else { prev->_next = cur->_next; // 删除非头节点 } delete cur; return true; } prev = cur; cur = cur->_next; } return false;}
4.3.6、扩容(Rehashing)
链地址法的性能与负载因子密切相关,负载因子定义为:
负载因子 = 哈希表中存储的元素个数 哈希桶的个数 负载因子= \frac{\text{哈希表中存储的元素个数}}{\text{哈希桶的个数}} 负载因子=哈希桶的个数哈希表中存储的元素个数
为了保证查找效率,通常将负载因子限制在一定范围内(例如,控制在1以下)。当负载因子超过阈值时,哈希表会进行扩容。扩容的方式通常是将表的大小翻倍,并将旧表的元素重新哈希到新的位置。扩容的步骤为:
-
创建一个更大的哈希表:通常是原表的 2 倍大小。
-
重新计算哈希值:将旧表中每个元素的哈希值重新计算,并插入到新表中。
-
释放旧表:将旧表的内存释放,切换到新表。
// 如果负载因子等于 1 , 则增容, 避免大量的哈希冲突
if (_tables.size() == _num)
{
// 1. 开两倍大小的新表(不一定是两倍)
// 2. 遍历旧表的数据, 重新计算在新表中的位置
// 3. 释放旧表
std::vector<Node *> newtables;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// size_t newsize = GetNextPrime(_tables.size());
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
// 将旧表中的节点取下来, 重新计算在新表中的位置, 并插入进去
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
size_t index = HashFunc(koft(cur->_data)) % newtables.size();
cur->_next = newtables[index];
newtables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
4.3.7、链地址法的优点与缺点
1、优点
- 冲突局部化:链地址法将冲突局限在某个槽位的链表中,避免了开放地址法中的 "洪水效应" ,即大量冲突导致的全局性能下降。
- 空间利用率高:链表的动态结构意味着可以灵活扩展存储空间,不像开放地址法那样需要为每个插入预留大量空间。
- 删除操作简单:在开放地址法中,删除操作需要特别处理已删除的槽位(标记为删除),而链地址法则可以直接通过链表删除节点,不会影响其他元素。
2、缺点
- 额外的空间开销:链表的每个节点都需要额外的指针空间,增加了内存开销。
- 链表操作时间复杂度较高 :在最坏的情况下,如果所有元素都哈希到同一个槽位,则链地址法的查找、插入、删除操作会退化为
O(n)。
4.3.8、链地址法的扩展
链地址法的基础实现非常有效,但在实际应用中,仍有一些需要优化和扩展的地方,以提升其性能和适用性。我们将在以下几个方面进一步深入:
1、除留余数法,最好模一个素数,如何每次快速取一个类似两倍关系的素数?
size_t GetNextPrime(size_t num)
{
const int PrimeSize = 28;
static const unsigned long PrimeList[PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i < PrimeSize; ++i)
{
if (PrimeList[i] > num)
{
return PrimeList[i];
}
}
return PrimeList[PrimeSize - 1]; // 如果已经是最后一个数的,则不增容
}2、使用动态数组替代链表
在链地址法的实现中,我们通常使用链表(如 std::list)来存储同一个槽位的多个元素。然而,链表虽然插入和删除操作高效,但查找的时间复杂度为 O(n)。为了提高查找性能,我们可以使用动态数组 (如 std::vector)代替链表。
优点:
- 局部性好:动态数组的元素存储在连续的内存块中,因此查找时的缓存局部性更好,可以提高性能。
- 二分查找的可能性 :如果链地址法的槽位链表较长且有序,我们可以在数组上实现二分查找,从而将查找时间复杂度降低为
O(log n)。
实现要点:
-
由于动态数组在插入和删除操作时的性能较差,我们可以结合有序插入 和二分查找来平衡查找与插入的效率。
// 使用 std::vector 替代 std::list std::vector<std::pair<K, V>> bucket; // 插入时保持有序 auto it = std::lower_bound(bucket.begin(), bucket.end(), key, [](const auto& node, const K& key) { return node.first < key; }); if (it == bucket.end() || it->first != key) { bucket.insert(it, std::make_pair(key, value)); } else { it->second = value; // 更新已有键的值 }
缺点:
- 动态数组在插入和删除操作时需要进行元素的移动,因此在高频插入的场景下性能不如链表。
- 当冲突发生频繁时,数组长度过长,二分查找的优势会被冲突消耗掉。
3、使用自平衡二叉搜索树
为了进一步提升冲突处理的性能,我们可以使用自平衡二叉搜索树(如红黑树、AVL树)替代链表或动态数组。自平衡二叉搜索树的特点是:
- 查找、插入、删除的时间复杂度均为 O(log n),这使得链地址法在高冲突场景下依然能保持较好的性能。
- 有序性:自平衡树可以自然保持槽位中的元素有序,对于某些需要范围查询的场景特别适合。
实现要点:
在每个槽位的链表位置,使用 STL 中的 std::map 或者 std::set 来实现。
// 使用 std::map 替代链表
std::map<K, V> bucket;
// 插入操作
bucket[key] = value; // 插入或者更新键值对
// 查找操作
auto it = bucket.find(key);
if (it != bucket.end()) {
return it->second; // 找到对应的值
}优缺点:
- 优点:在高冲突的情况下,自平衡树能够保证查找和插入操作的时间复杂度稳定在 O(log n),性能表现优异。
- 缺点:自平衡树的节点需要维护额外的平衡信息,内存开销较大,且在元素较少或冲突较少的场景中,其复杂度略高于链表或动态数组。
4、扩展到多重哈希表
在某些应用中,链地址法的哈希表可以扩展为多重哈希表(Multiple Hash Tables),即维护多个哈希表,每个表有独立的哈希函数和冲突处理机制。
多重哈希的优势:
- 降低冲突 :通过多个哈希函数映射,可以有效降低冲突的发生概率。例如,元素
key1和key2如果在第一个哈希表中发生冲突,可能在第二个哈希表中不会冲突。 - 查询加速:通过并行查询多个哈希表,可以加速查找过程,尤其在多个哈希表分散存储时。
实现要点:
我们可以维护一个包含多个哈希表的数组,在插入和查找时,分别在多个哈希表中进行。
template <class K, class V>
class MultipleHashTables
{
public:
MultipleHashTables(size_t numTables = 3, size_t capacity = 10)
: _numTables(numTables)
{
for (size_t i = 0; i < _numTables; ++i)
{
_tables.push_back(HashTable<K, V>(capacity));
}
}
bool Insert(const K &key, const V &value)
{
for (auto &table : _tables)
{
if (table.Insert(key, value))
return true;
}
return false;
}
V *Find(const K &key)
{
for (auto &table : _tables)
{
V *result = table.Find(key);
if (result)
return result;
}
return nullptr;
}
private:
size_t _numTables;
std::vector<HashTable<K, V>> _tables; // 多个哈希表
};通过维护多个哈希表,我们能够更好地分散数据,减少冲突,提高查找性能。
4.3.9、链地址法在实际中的应用
链地址法是实际工程中常用的哈希冲突解决方案,广泛应用于各类数据库系统、缓存系统、以及编程语言的标准库中。下面列举一些典型的应用场景:
1、STL 中的 unordered_map 和 unordered_set
C++ 标准库中的 unordered_map 和 unordered_set 使用了链地址法作为其冲突解决策略。每个槽位对应的是一个链表(或动态数组),当发生冲突时,新元素会被插入到链表中。
为了提高性能,C++ STL 中的链地址法实现通常结合负载因子和自动扩容策略,确保哈希表的槽位总是足够多,以减少冲突的发生。
2、数据库系统中的哈希索引
在数据库系统中,哈希索引(Hash Index) 也是广泛采用链地址法的。哈希索引通过哈希函数将数据键映射到不同的桶中,桶中的数据通过链表来存储相同哈希值的数据项。链地址法在数据库中能够有效地支持等值查询(即通过键值精确查找某一记录)。
3、缓存系统中的哈希表
缓存系统(如 Memcached)中,哈希表是核心数据结构之一。链地址法为缓存中的哈希表提供了高效的冲突处理和数据查找机制,尤其在大规模缓存数据时,链地址法能保证系统的稳定性和高效性。
4.3.10、链地址法的优化策略
尽管链地址法提供了一种简单而有效的冲突解决方案,但在实际应用中,仍然可以通过以下几种优化策略来提升其性能:
1、负载因子的控制
负载因子(Load Factor)是指哈希表中元素的数量与槽位数量的比值。通常,当负载因子达到一定阈值(如 1)时,哈希表将进行扩容以减少冲突。
在链地址法中,我们可以通过调整负载因子来控制冲突的发生频率。负载因子越低,冲突发生的概率越低,但也意味着哈希表的空间利用率较低;反之,负载因子过高,则会增加链表的长度,影响查找性能。
2、优化链表结构
在链地址法的基础上,我们可以对链表结构进行优化,如使用跳表(Skip List)或动态平衡树来替代传统的链表。这种优化能够在高冲突场景下保持较高的查找性能。
3、哈希函数的优化
哈希函数的设计对链地址法的性能有着至关重要的影响。一个好的哈希函数应该尽可能均匀地将数据分布到哈希表的不同槽位,减少冲突的发生。
常用的哈希函数包括乘法散列法、模数散列法、和多重哈希等。在实际应用中,我们可以根据数据的分布特征,选择合适的哈希函数来提高性能。如 MurmurHash、CityHash 等,可减少冲突概率。
4、预留足够的哈希桶
根据数据规模合理设计初始容量,减少扩容次数。
5、分离链表节点的存储
将链表节点与哈希表分离存储,减少缓存失效。
4.3.11、小结
链地址法作为一种经典的哈希冲突解决方案,具有实现简单、扩展性好、查找效率高等优点。在本章中,我们详细讨论了链地址法的基本结构和实现细节,包括插入、查找、删除和扩容操作。同时,我们还探讨了如何通过负载因子控制和哈希函数优化来提高性能。
对于实际应用中的大规模数据处理,链地址法依然是一个非常有效的选择。通过合理设计哈希函数和扩展机制,可以大幅减少冲突,从而提升哈希表的整体性能。
4.4、链地址法(Chaining)的完整实现及测试
4.4.1、HashTable.hpp
namespace Lenyiin
{
template <class T>
struct HashNode
{
T _data; // 存储数据
HashNode<T> *_next; // 存储下一个节点
// 如果想要实现迭代顺序为插入顺序, 可以加两个指针组成一个链表
// HashNode<T>* _linknext;
// HashNode<T>* _linkprev;
HashNode(const T &data)
: _data(data), _next(nullptr)
{
}
};
template <class K>
struct _Hash
{
const K &operator()(const K &key)
{
return key;
}
};
// 特化
template <>
struct _Hash<std::string>
{
size_t operator()(const std::string &key)
{
// BKDR Hash
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
hash *= 131;
hash += key[i];
}
return hash;
}
};
struct _HashString
{
size_t operator()(const std::string &key)
{
// BKDR Hash
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
hash *= 131;
hash += key[i];
}
return hash;
}
};
template <class K, class T, class KeyOfT, class Hash>
// template <class K, class T, class KeyOfT, class Hash = _Hash<K>>
class Open_HashTable
{
private:
typedef HashNode<T> Node;
public:
void Clear()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
size_t HashFunc(const K &key)
{
Hash hash;
return hash(key);
}
size_t GetNextPrime(size_t num)
{
const int PrimeSize = 28;
static const unsigned long PrimeList[PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul};
for (size_t i = 0; i < PrimeSize; i++)
{
if (PrimeList[i] > num)
{
return PrimeList[i];
}
}
return PrimeList[PrimeSize - 1]; // 如果已经是最后一个数的, 则不增容
}
// 当大量的数据冲突, 这些哈希冲突的数据就会挂在同一个链式桶中, 查找时效率就会降低, 所以开散列-哈希桶也是要控制哈希冲突的。
// 如何控制呢? 通过控制负载因子, 不过这里就把空间利用率提高一些, 负载因子也可以高一些, 一般开散列把负载因子控制到1, 会比较好一点
bool Insert(const T &data)
{
KeyOfT koft;
// 如果负载因子等于 1 , 则增容, 避免大量的哈希冲突
if (_tables.size() == _num)
{
// 1. 开两倍大小的新表(不一定是两倍)
// 2. 遍历旧表的数据, 重新计算在新表中的位置
// 3. 释放旧表
std::vector<Node *> newtables;
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// size_t newsize = GetNextPrime(_tables.size());
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
// 将旧表中的节点取下来, 重新计算在新表中的位置, 并插入进去
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
size_t index = HashFunc(koft(cur->_data)) % newtables.size();
cur->_next = newtables[index];
newtables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
// 计算数据在表中映射的位置
size_t index = HashFunc(koft(data)) % _tables.size();
// 1. 先查找这个值在不在表中
Node *cur = _tables[index];
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(koft(data)))
{
return false;
}
else
{
cur = cur->_next;
}
}
// 2. 头插挂到链表中(尾插也是可以的)
Node *newnode = new Node(data);
newnode->_next = _tables[index];
_tables[index] = newnode;
++_num;
return true;
}
Node *Find(const K &key)
{
KeyOfT koft;
// 计算 data 中的 key 在表中映射的位置
size_t index = HashFunc(key) % _tables.size();
Node *cur = _tables[index];
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
return cur;
}
else
{
cur = cur->_next;
}
}
return nullptr;
}
bool Erase(const K &key)
{
KeyOfT koft;
size_t index = HashFunc(key) % _tables.size();
Node *prev = nullptr;
Node *cur = _tables[index];
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
if (prev == nullptr)
{
// 表示要删除的值在第一个节点
_tables[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
void Print()
{
int size = _tables.size();
for (int i = 0; i < size; i++)
{
std::cout << i << "\t";
Node *cur = _tables[i];
while (cur)
{
std::cout << cur->_data << "\t";
cur = cur->_next;
}
std::cout << std::endl;
}
std::cout << std::endl;
}
private:
std::vector<Node *> _tables;
size_t _num = 0; // 记录着存储的数据个数
};
}4.4.2、Main.cc
#include "HashTable.hpp"
void Test_Open_HashTable_1()
{
Lenyiin::Open_HashTable<int, int, Lenyiin::SetKeyOfT<int>, Lenyiin::_Hash<int>> ht;
ht.Insert(4);
ht.Insert(14);
ht.Insert(24);
ht.Insert(5);
ht.Insert(15);
ht.Insert(25);
ht.Insert(6);
ht.Insert(16);
ht.Insert(26);
ht.Insert(36);
ht.Insert(33);
ht.Insert(37);
ht.Insert(32);
ht.Print();
ht.Erase(4);
ht.Erase(14);
ht.Print();
}
void Test_Open_HashTable_2()
{
Lenyiin::Open_HashTable<std::string, std::string, Lenyiin::SetKeyOfT<std::string>, Lenyiin::_Hash<std::string>> ht;
ht.Insert("sort");
ht.Insert("string");
ht.Insert("left");
ht.Insert("right");
std::cout << ht.HashFunc("abcd") << std::endl;
std::cout << ht.HashFunc("aadd") << std::endl;
}
int main()
{
Test_Open_HashTable_1();
Test_Open_HashTable_2();
return 0;
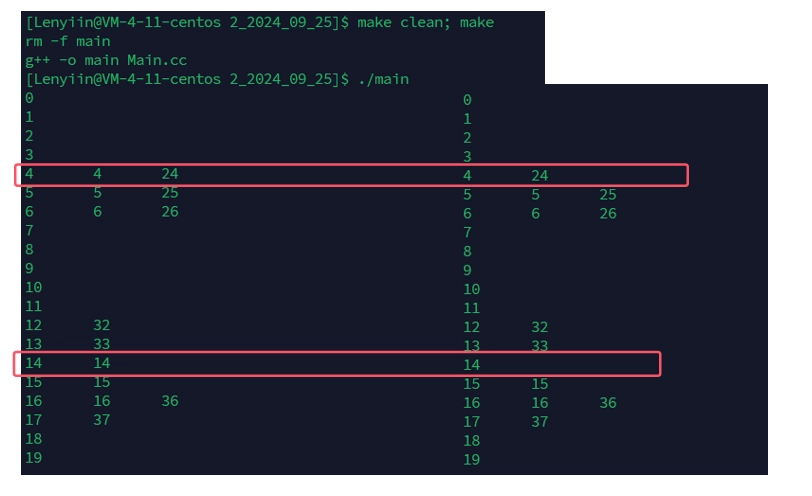
}4.4.3、测试结果
删除 4 和 14 前后对比
5、unordered_set 和 unordered_map 的实现
5.1、容器的迭代器设计
5.1.1、为什么需要迭代器?
迭代器在哈希表(如 Open_HashTable)中的设计与实现是非常重要的,它带来了许多好处。
1、抽象与统一接口
迭代器提供了一个统一的接口,使得不同类型的容器(如数组、链表、哈希表等)可以通过相同的方式进行访问。这样,用户可以使用标准的遍历方式来操作哈希表,而无需了解其内部实现细节。
例子: 使用迭代器遍历哈希表就像遍历其他 STL 容器一样:
for (auto it = hashTable.begin(); it != hashTable.end(); ++it) {
std::cout << *it << " ";
}这种一致性使得代码更易于理解和使用。
2、简化遍历操作
使用迭代器可以简化遍历哈希表的操作。用户不需要手动管理索引或当前节点,迭代器会处理这些细节。这样可以减少出错的可能性,降低代码复杂性。
3、支持 STL 算法
哈希表的迭代器使其能够与 STL 的算法兼容。许多 STL 算法(如 std::find、std::for_each 等)都需要迭代器作为参数。通过提供迭代器,哈希表可以轻松与这些算法结合使用。
例子:
std::for_each(hashTable.begin(), hashTable.end(), [](const auto& value) {
std::cout << value << " ";
});4、提升代码可维护性
当使用迭代器时,代码的可读性和可维护性会提高。迭代器使得代码的意图更加明确,用户能够快速理解代码的功能,而不必深入了解哈希表的实现。
5、减少直接操作的需求
使用迭代器,可以减少对容器内部结构的直接操作。用户不需要知道哈希表内部如何存储数据(如链式存储或开放寻址),而是通过迭代器与数据进行交互。这种封装提高了数据结构的安全性和灵活性。
6、提供灵活性
迭代器可以设计成不同类型(如常量迭代器、双向迭代器等),以支持更多的使用场景。例如,可以为哈希表添加只读的常量迭代器,以防止对数据的意外修改。
7、优化与性能
在迭代器内部实现中,可以使用一些优化技术(如缓存最近访问的节点)来提高遍历效率。这种优化可以在不改变用户代码的情况下提升性能。
综上所述,哈希表的迭代器设计不仅简化了遍历操作,还提供了统一的接口,增强了与 STL 算法的兼容性,提高了代码的可维护性和安全性。通过使用迭代器,用户可以更方便地操作哈希表,专注于业务逻辑,而不是容器的具体实现细节。
下面我会详细讲解迭代器的设计以及如何封装它。我们这里主要针对哈希表(Open_HashTable)的迭代器设计展开,该迭代器是单向的,只能进行++操作,即只能前向迭代,不能反向迭代。以下是迭代器的详细设计步骤与要点。
5.1.2、迭代器类的定义
哈希表的迭代器类定义如下:
template <class K, class T, class KeyOfT, class Hash>
struct __HashTableIterator {
typedef __HashTableIterator<K, T, KeyOfT, Hash> Self;
typedef Open_HashTable<K, T, KeyOfT, Hash> HT;
typedef HashNode<T> Node;
Node* _node; // 当前迭代器指向的节点
HT* _pht; // 指向哈希表的指针
// 构造函数
__HashTableIterator(Node* node, HT* pht)
: _node(node), _pht(pht)
{}
// 解引用操作
T& operator*() {
return _node->_data;
}
// 访问成员操作
T* operator->() {
return &_node->_data;
}
}迭代器类的核心成员变量包括:
_node:指向当前哈希节点的数据。_pht:指向哈希表的指针,用于在迭代器操作时访问哈希表。
5.1.3、++ 前缀运算符实现
迭代器前缀++运算符用于让迭代器向下一个有效元素移动。当当前元素有后继节点时,直接指向后继节点。如果当前桶的链表已经遍历完了,则查找下一个非空的桶继续遍历。
Self& operator++() {
if (_node->_next) {
_node = _node->_next;
} else {
// 当前桶遍历完,寻找下一个非空桶
KeyOfT koft;
size_t index = _pht->HashFunc(koft(_node->_data)) % _pht->_tables.size();
++index;
while (index < _pht->_tables.size()) {
Node* cur = _pht->_tables[index];
if (cur) {
_node = cur;
return *this;
}
++index;
}
_node = nullptr;
}
return *this;
}5.1.4、++ 后缀运算符实现
后缀++运算符返回当前迭代器的拷贝,然后调用前缀++来完成移动。
Self operator++(int) {
Self tmp(*this);
++*this;
return tmp;
}5.1.5、迭代器比较操作
迭代器之间的比较操作用于判断两个迭代器是否相等或不相等,这在遍历哈希表时很重要。迭代器相等的条件是它们的_node指针相等。
bool operator==(const Self& s) const {
return _node == s._node;
}
bool operator!=(const Self& s) const {
return _node != s._node;
}5.1.6、迭代器的使用
迭代器的设计可以让你像遍历其他容器一样去遍历哈希表中的数据。哈希表类中包含两个用于支持迭代的函数:begin() 和 end()。
-
begin()返回指向第一个非空桶中第一个节点的迭代器。 -
end()返回一个空迭代器,表示遍历的终止。iterator begin() {
for (size_t i = 0; i < _tables.size(); ++i) {
if (_tables[i]) {
return iterator(_tables[i], this);
}
}
return end();
}iterator end() {
return iterator(nullptr, this);
}
5.1.7、迭代器完整代码及示例
迭代器完整代码:
namespace Lenyiin
{
// 前置声明
template <class K, class T, class KeyOfT, class Hash>
class Open_HashTable;
// 哈希表只有单向迭代器, 只有 ++, 没有--
template <class K, class T, class KeyOfT, class Hash>
struct __HashTableIterator
{
typedef __HashTableIterator<K, T, KeyOfT, Hash> Self;
typedef Open_HashTable<K, T, KeyOfT, Hash> HT;
typedef HashNode<T> Node;
Node *_node;
HT *_pht;
__HashTableIterator(Node *node, HT *pht)
: _node(node), _pht(pht)
{
}
T &operator*()
{
return _node->_data;
}
T *operator->()
{
return &_node->_data;
}
Self &operator++()
{
if (_node->_next)
{
_node = _node->_next;
}
else
{
// 如果一个桶走完了, 找到下一个桶继续便利
KeyOfT koft;
size_t index = _pht->HashFunc(koft(_node->_data)) % _pht->_tables.size();
++index;
while (index < _pht->_tables.size())
{
Node *cur = _pht->_tables[index];
if (cur)
{
_node = cur;
return *this;
}
++index;
}
_node = nullptr;
}
return *this;
}
Self operator++(int)
{
Self tmp(*this);
++*this;
return tmp;
}
bool operator!=(const Self &s)
{
return _node != s._node;
}
bool operator==(const Self &s)
{
return _node == s._node;
}
};
}我们可以通过一个简单的遍历哈希表的例子来展示迭代器的实际使用:
void PrintHashTable() {
for (iterator it = _hashTable.begin(); it != _hashTable.end(); ++it) {
std::cout << *it << " ";
}
}5.1.8、迭代器封装的意义
迭代器的封装为用户提供了统一的接口,让用户可以方便地遍历、访问哈希表中的元素。通过标准的迭代器接口,用户可以像操作 STL 容器一样操作哈希表,从而提升代码的可读性和可维护性。
5.2、容器的插入封装
哈希表中的插入操作是核心功能之一,下面将详细讲解哈希表插入的封装,包括操作步骤、关键技术点以及代码实现。
5.2.1、插入的基本流程
哈希表的插入操作主要分为以下几个步骤:
- 计算哈希值:通过哈希函数将给定的键转换为哈希值,确定该元素在哈希表中的存储位置。
- 检查负载因子:判断当前哈希表的负载因子是否超过设定阈值。如果超过,则进行扩容。
- 查找冲突:在计算得出的索引位置上查找是否已有元素。如果存在元素且键相同,则更新该元素;如果不同,则采用链式存储或开放寻址等方法解决冲突。
- 插入新元素:将新元素插入到相应的位置。
5.2.2、关键技术点
- 哈希函数:决定了键的分布效果,好的哈希函数能够有效减少冲突。常见的方法有除法法、乘法法和中间平方法等。
- 负载因子:负载因子是已存储元素的数量与哈希表大小的比值。一般情况下,负载因子过高会导致冲突增加,影响查找和插入效率。通常设定负载因子上限为1。
- 冲突处理:可以采用链式存储(将冲突的元素链接在一起)或开放寻址(在哈希表中寻找下一个空位)来解决冲突。
- 动态扩容:当负载因子超过一定阈值时,通过重新分配更大的哈希表并重新插入已有元素来进行扩容。
5.2.3、代码实现
以下是哈希表的插入操作封装示例:
// 重新哈希
void Rehash(size_t newsize)
{
KeyOfT koft;
std::vector<Node *> newtables;
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
// 将旧表中的节点取下来, 重新计算在新表中的位置, 并插入进去
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
size_t index = HashFunc(koft(cur->_data)) % newtables.size();
cur->_next = newtables[index];
newtables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
// 插入操作
// 当大量的数据冲突, 这些哈希冲突的数据就会挂在同一个链式桶中, 查找时效率就会降低, 所以开散列-哈希桶也是要控制哈希冲突的。
// 如何控制呢? 通过控制负载因子, 不过这里就把空间利用率提高一些, 负载因子也可以高一些, 一般开散列把负载因子控制到1, 会比较好一点
std::pair<iterator, bool> Insert(const T &data)
{
KeyOfT koft;
// 1. 检查负载因子
// 如果负载因子等于 1 , 则增容, 避免大量的哈希冲突
if (_tables.size() == _num)
{
// 1. 开两倍大小的新表(不一定是两倍)
// 2. 遍历旧表的数据, 重新计算在新表中的位置
// 3. 释放旧表
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// size_t newsize = GetNextPrime(_tables.size());
Rehash(newsize);
}
// 2. 计算数据在表中映射的位置
size_t index = HashFunc(koft(data)) % _tables.size();
// 3. 先查找这个值在不在表中, 是否有冲突
Node *cur = _tables[index];
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(koft(data)))
{
// 如果已经存在该键,返回失败
return std::make_pair(iterator(cur, this), false);
}
else
{
// 查找下一个节点
cur = cur->_next;
}
}
// 4. 头插挂到链表中(尾插也是可以的)
Node *newnode = new Node(data);
newnode->_next = _tables[index];
_tables[index] = newnode;
++_num; // 更新已存储元素数量
return std::make_pair(iterator(newnode, this), true);
}通过上述插入操作的封装,哈希表能够高效地存储和管理元素。插入操作不仅涵盖了基础的元素存储,还考虑了负载因子、冲突处理和动态扩容等方面,确保了哈希表在面对大量数据时的性能和稳定性。封装后的插入操作简化了用户的调用接口,使得用户能够更加专注于业务逻辑,而无需过多关注内部实现细节。
5.3、容器的查找封装
哈希表中的查找操作是检索元素的核心功能,以下将详细讲解哈希表查找的封装,包括操作步骤、关键技术点及代码实现。
5.3.1、查找的基本流程
哈希表的查找操作主要包括以下几个步骤:
- 计算哈希值:使用哈希函数计算给定键的哈希值,以确定在哈希表中的索引位置。
- 定位索引:根据哈希值确定元素存储的桶(或链表)位置。
- 遍历链表:如果在该位置上存在元素,遍历链表查找匹配的键。
- 返回结果:如果找到相应的元素,则返回该元素;如果未找到,则返回空或特定标识。
5.3.2、关键技术点
- 哈希函数:好的哈希函数能够均匀分布元素,减少冲突,从而提高查找效率。
- 冲突处理:常见的冲突处理方式包括链式存储和开放寻址。链式存储通过在同一个索引下存储多个元素来解决冲突,而开放寻址则在哈希表中寻找下一个可用位置。
- 查找效率:在理想情况下,查找的时间复杂度为O(1),但由于哈希冲突的存在,实际查找复杂度可能变为O(n),因此保持适当的负载因子和使用良好的哈希函数至关重要。
5.3.3、代码实现
以下是哈希表的查找操作封装示例:
// 查找操作
Node *Find(const K &key)
{
KeyOfT koft;
// 1. 计算键在表中映射的位置
size_t index = HashFunc(key) % _tables.size();
Node *cur = _tables[index];
// 2. 遍历链表查找匹配的键
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
// 如果找到匹配的元素,返回其指针
return cur;
}
// 继续查找下一个节点
cur = cur->_next;
}
// 如果未找到,返回空指针
return nullptr;
}通过上述查找操作的封装,哈希表能够高效地检索存储的元素。查找操作结合了哈希函数、冲突处理机制和链表遍历等多个关键技术,确保在大多数情况下能够快速定位元素。封装后的查找操作简化了用户的调用接口,使得用户能够方便地获取所需数据,而无需深入了解内部实现细节。
这种设计不仅提高了代码的可读性和可维护性,也使得用户能够专注于业务逻辑而非底层实现,从而提升开发效率。
5.4、容器的删除封装
哈希表的删除操作与插入和查找同样重要。删除时需要确保正确移除元素,同时保持哈希表的结构完整,并妥善处理冲突链的调整。下面详细讲解哈希表的删除操作的封装,包括删除操作的步骤、关键技术点及代码实现。
5.4.1、删除的基本流程
删除操作涉及以下几个主要步骤:
- 计算哈希值:根据要删除元素的键,通过哈希函数计算其哈希值。
- 定位索引:通过哈希值确定键在哈希表中的桶(或链表)位置。
- 遍历链表:在桶中的链表结构中查找需要删除的元素。
- 调整链表:找到目标元素后,调整链表结构,删除节点,避免破坏哈希表的链式存储。
- 释放内存:移除节点后,释放相应的内存,防止内存泄漏。
5.4.2、关键技术点
- 链表的调整:由于哈希冲突可能导致多个元素存储在同一个桶中,因此删除元素时需要保持链表的完整性。在找到目标元素时,要确保正确处理前后节点的链接关系,避免链表断裂。
- 冲突处理机制:在删除元素时,特别是在存在冲突的桶中,必须确保不会影响其他元素的查找路径。
- 内存管理:在 C++ 中,手动管理内存是必须的,因此删除节点时一定要注意释放被删除节点的内存,以避免内存泄漏。
5.4.3、代码实现
以下是封装哈希表删除操作的详细实现:
bool Erase(const K &key)
{
KeyOfT koft;
// 1. 计算要删除元素的哈希值
size_t index = HashFunc(key) % _tables.size();
Node *prev = nullptr;
Node *cur = _tables[index];
// 2. 遍历链表, 查找匹配的元素
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
// 3. 找到元素后, 调整链表结构
if (prev == nullptr)
{
// 如果要删除的元素是链表的第一个节点, 直接让桶指向下一个节点
_tables[index] = cur->_next;
}
else
{
// 否则,将前一个节点的 next 指向当前节点的下一个节点
prev->_next = cur->_next;
}
// 4. 释放节点内存
delete cur;
--_num; // 元素数量减少
return true;
}
else
{
// 继续遍历链表
prev = cur;
cur = cur->_next;
}
}
// 如果未找到该元素,返回 false
return false;
}- 时间复杂度 :哈希表的删除操作通常在
O(1)时间内完成(不考虑哈希冲突的情况)。即使在发生哈希冲突时,删除的时间复杂度为O(k),其中 k 是冲突链表的长度,链表的长度通常较短。 - 内存管理:通过合理的链表结构调整和显式内存释放,避免了内存泄漏问题,确保程序运行稳定。
哈希表的删除封装通过简化接口,实现了高效的删除操作。其内部结合了哈希函数、链表遍历和内存管理等多个技术点,确保了在高效删除元素的同时,不破坏哈希表的结构完整性。通过封装,用户可以轻松调用删除操作,保持代码的简洁性与可读性。
这套封装设计充分考虑了哈希表的核心原理,并通过合理的链表操作实现了高效、稳定的删除功能。在大规模数据操作时,删除的性能能够得到有效保障,同时避免了内存管理的复杂问题。
5.5、完整的哈希底层实现
namespace Lenyiin
{
template <class K>
struct _Hash
{
const K &operator()(const K &key)
{
return key;
}
};
// 特化
template <>
struct _Hash<std::string>
{
size_t operator()(const std::string &key)
{
// BKDR Hash
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
hash *= 131;
hash += key[i];
}
return hash;
}
};
struct _HashString
{
size_t operator()(const std::string &key)
{
// BKDR Hash
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
hash *= 131;
hash += key[i];
}
return hash;
}
};
template <class K, class T, class KeyOfT, class Hash>
// template <class K, class T, class KeyOfT, class Hash = _Hash<K>>
class Open_HashTable
{
private:
typedef HashNode<T> Node;
public:
friend struct __HashTableIterator<K, T, KeyOfT, Hash>;
typedef __HashTableIterator<K, T, KeyOfT, Hash> iterator;
iterator begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return iterator(_tables[i], this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
Open_HashTable()
{
}
Open_HashTable(size_t bucket_count)
: _tables(bucket_count), _num(0)
{
}
~Open_HashTable()
{
Clear();
}
void Clear()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
size_t HashFunc(const K &key)
{
Hash hash;
return hash(key);
}
size_t GetNextPrime(size_t num)
{
const int PrimeSize = 28;
static const unsigned long PrimeList[PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul};
for (size_t i = 0; i < PrimeSize; i++)
{
if (PrimeList[i] > num)
{
return PrimeList[i];
}
}
return PrimeList[PrimeSize - 1]; // 如果已经是最后一个数的, 则不增容
}
// 重新哈希
void Rehash(size_t newsize)
{
KeyOfT koft;
std::vector<Node *> newtables;
newtables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
// 将旧表中的节点取下来, 重新计算在新表中的位置, 并插入进去
Node *cur = _tables[i];
while (cur)
{
Node *next = cur->_next;
size_t index = HashFunc(koft(cur->_data)) % newtables.size();
cur->_next = newtables[index];
newtables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
// 插入操作
// 当大量的数据冲突, 这些哈希冲突的数据就会挂在同一个链式桶中, 查找时效率就会降低, 所以开散列-哈希桶也是要控制哈希冲突的。
// 如何控制呢? 通过控制负载因子, 不过这里就把空间利用率提高一些, 负载因子也可以高一些, 一般开散列把负载因子控制到1, 会比较好一点
std::pair<iterator, bool> Insert(const T &data)
{
KeyOfT koft;
// 1. 检查负载因子
// 如果负载因子等于 1 , 则增容, 避免大量的哈希冲突
if (_tables.size() == _num)
{
// 1. 开两倍大小的新表(不一定是两倍)
// 2. 遍历旧表的数据, 重新计算在新表中的位置
// 3. 释放旧表
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// size_t newsize = GetNextPrime(_tables.size());
Rehash(newsize);
}
// 2. 计算数据在表中映射的位置
size_t index = HashFunc(koft(data)) % _tables.size();
// 3. 先查找这个值在不在表中, 是否有冲突
Node *cur = _tables[index];
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(koft(data)))
{
// 如果已经存在该键,返回失败
return std::make_pair(iterator(cur, this), false);
}
else
{
// 查找下一个节点
cur = cur->_next;
}
}
// 4. 头插挂到链表中(尾插也是可以的)
Node *newnode = new Node(data);
newnode->_next = _tables[index];
_tables[index] = newnode;
++_num; // 更新已存储元素数量
return std::make_pair(iterator(newnode, this), true);
}
// 查找操作
Node *Find(const K &key)
{
KeyOfT koft;
// 1. 计算键在表中映射的位置
size_t index = HashFunc(key) % _tables.size();
Node *cur = _tables[index];
// 2. 遍历链表查找匹配的键
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
// 如果找到匹配的元素,返回其指针
return cur;
}
// 继续查找下一个节点
cur = cur->_next;
}
// 如果未找到,返回空指针
return nullptr;
}
bool Erase(const K &key)
{
KeyOfT koft;
// 1. 计算要删除元素的哈希值
size_t index = HashFunc(key) % _tables.size();
Node *prev = nullptr;
Node *cur = _tables[index];
// 2. 遍历链表, 查找匹配的元素
while (cur)
{
if (HashFunc(koft(cur->_data)) == HashFunc(key))
{
// 3. 找到元素后, 调整链表结构
if (prev == nullptr)
{
// 如果要删除的元素是链表的第一个节点, 直接让桶指向下一个节点
_tables[index] = cur->_next;
}
else
{
// 否则,将前一个节点的 next 指向当前节点的下一个节点
prev->_next = cur->_next;
}
// 4. 释放节点内存
delete cur;
--_num; // 元素数量减少
return true;
}
else
{
// 继续遍历链表
prev = cur;
cur = cur->_next;
}
}
// 如果未找到该元素,返回 false
return false;
}
void Print() const
{
int size = _tables.size();
for (int i = 0; i < size; i++)
{
std::cout << i << "\t";
Node *cur = _tables[i];
while (cur)
{
std::cout << cur->_data << "\t";
cur = cur->_next;
}
std::cout << std::endl;
}
std::cout << std::endl;
}
private:
std::vector<Node *> _tables; // 哈希表存储桶
size_t _num; // 记录着存储的数据个数
};
}5.6、unordered_set 实现
unordered_set 是 C++ 标准库中的无序集合,它使用哈希表作为底层数据结构来存储唯一的元素,并且不保持元素的顺序。相较于 set,unordered_set 通过哈希表提供了 O(1) 的插入、删除和查找时间复杂度,而不是 set 中的 O(log n)(基于平衡二叉树)。
我们可以在之前封装的哈希表基础上,设计一个简化的 unordered_set,并详细讲解其中的实现原理。
5.6.1、基本概念和设计思路
unordered_set 的核心是哈希表,因此它内部的操作都依赖于哈希函数和哈希冲突的处理。主要功能包括:
- 插入:将元素添加到集合中。
- 查找:检查集合中是否包含某个元素。
- 删除:从集合中移除某个元素。
这些操作都基于哈希表的基本操作,因此我们可以直接使用先前封装好的哈希表操作进行实现。
5.6.2、类设计
我们定义一个简化版的 unordered_set,它支持基础的插入、查找和删除功能。底层使用我们之前设计的哈希表结构。
#pragma once
#include "HashTable.hpp"
namespace Lenyiin
{
template <class K, class Hash = _Hash<K>>
class Unordered_Set
{
public:
struct SetKOfT
{
const K &operator()(const K &key)
{
return key;
}
};
typedef typename Open_HashTable<K, K, SetKOfT, Hash>::iterator iterator;
iterator begin()
{
return _hashTable.begin();
}
iterator end()
{
return _hashTable.end();
}
// 构造函数: 指定哈希表的初始大小
Unordered_Set(size_t bucket_count = 10)
: _hashTable(bucket_count)
{
}
// 析构
~Unordered_Set()
{
}
// 插入元素
std::pair<iterator, bool> Insert(const K &key)
{
return _hashTable.Insert(key);
}
// 查找元素
bool Find(const K &key)
{
return _hashTable.Find(key);
}
// 删除元素
bool Erase(const K &key)
{
return _hashTable.Erase(key);
}
// 打印
void Print() const
{
_hashTable.Print();
}
private:
// 使用哈希表作为底层数据结构
Open_HashTable<K, K, SetKOfT, Hash> _hashTable;
};
}5.6.3、功能封装的详细讲解
1、插入元素
unordered_set 的插入操作通过哈希表将元素存储到适当的桶中。由于 unordered_set 只需要存储唯一的元素,因此我们需要在插入前检查元素是否已经存在。
bool Insert(const K &key) {
return _hashTable.Insert(key);
}- 插入操作流程:
- 计算键的哈希值并定位对应的桶。
- 检查桶中是否已经存在相同的键,如果不存在,则插入该元素。
- 如果元素已存在,插入失败(哈希表不允许重复键)。
插入操作依赖于我们之前封装的 Open_HashTable::Insert 方法。由于哈希表本质上只允许唯一键,因此 unordered_set 的插入也能自动满足唯一性要求。
2、查找元素
unordered_set 的查找功能通过哈希表来检查某个元素是否存在。查找操作根据哈希值定位到对应的桶,然后遍历桶中的链表进行查找。
bool Find(const K &key) {
return _hashTable.Find(key);
}- 查找操作流程:
- 通过哈希函数计算元素的哈希值,并定位到相应的桶。
- 在该桶中遍历链表查找目标元素。
- 如果找到该元素,则返回
true;否则返回false。
查找操作也是基于哈希表的 Find 方法,查找效率为 O(1)(理想情况下),即便有冲突时,查找性能也较为稳定。
3、删除元素
unordered_set 的删除功能用于从集合中移除某个元素。删除时,同样先计算元素的哈希值并找到相应的桶,再在桶中的链表中查找并移除该元素。
bool Erase(const K &key) {
return _hashTable.Erase(key);
}- 删除操作流程:
- 计算元素的哈希值,定位到对应的桶。
- 在桶中遍历链表查找目标元素。
- 找到目标元素后,调整链表结构,并释放相应的内存。
- 更新哈希表中元素的个数。
删除操作依赖于哈希表的 Erase 方法,它通过链表的调整和内存的释放,保证删除后的哈希表结构不受影响,并且不会导致内存泄漏。
5.6.4、迭代器设计(可选)
unordered_set 也可以通过迭代器来遍历集合中的所有元素。实现迭代器需要遍历哈希表的每一个桶,并且在每个桶中依次访问链表的每个节点。
iterator begin()
{
return _hashTable.begin();
}
iterator end()
{
return _hashTable.end();
}通过迭代器,用户可以方便地遍历 unordered_set 中的所有元素。
5.6.5、测试
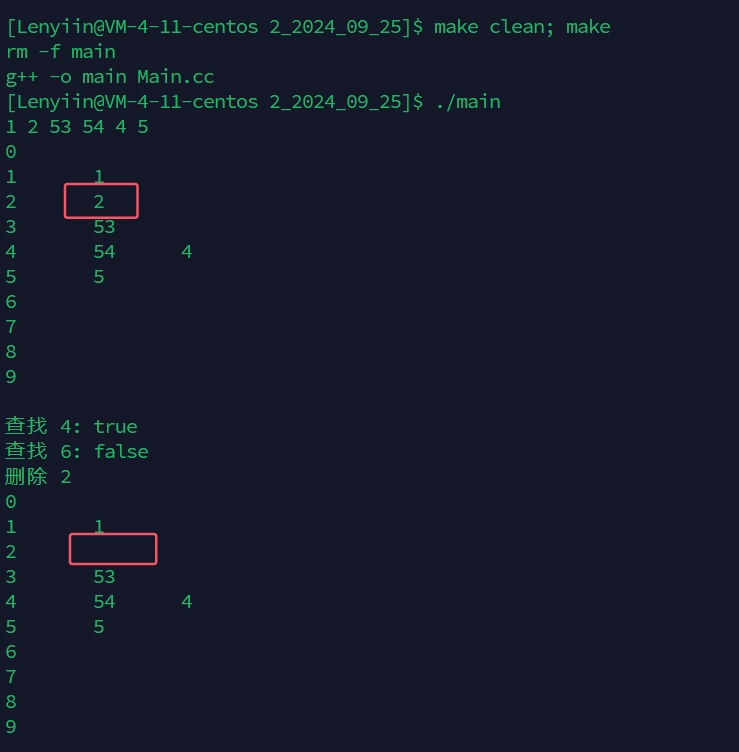
void Test_Unordered_Set()
{
Lenyiin::Unordered_Set<int> s;
s.Insert(1);
s.Insert(5);
s.Insert(4);
s.Insert(2);
s.Insert(5);
s.Insert(5);
s.Insert(53);
s.Insert(54);
Lenyiin::Unordered_Set<int>::iterator it = s.begin();
while (it != s.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
s.Print();
std::cout << "查找 4: " << (s.Find(4) ? "true" : "false") << std::endl;
std::cout << "查找 6: " << (s.Find(6) ? "true" : "false") << std::endl;
std::cout << "删除 2" << std::endl;
s.Erase(2);
s.Print();
}
int main()
{
Test_Unordered_Set();
return 0;
}5.6.6、测试结果
5.6.7、小结
基于哈希表的封装,我们设计了一个简化版的 unordered_set,其核心功能包括插入、查找和删除操作。通过使用哈希表作为底层数据结构,我们可以实现高效的 O(1) 时间复杂度的基本操作。尽管这里的 unordered_set 是简化版,但通过合理的封装和设计,它能很好地展现 C++ 标准库中 unordered_set 的核心思想。
在实际开发中,标准库提供的 std::unordered_set 封装了更多高级功能,如负载因子调整、迭代器支持、哈希函数和相等函数的自定义等。而我们的实现展示了底层哈希表的基本工作原理,帮助开发者更好地理解 unordered_set 的背后机制。
5.7、unordered_map 实现
unordered_map 是 C++ 标准库中的无序关联容器,它使用哈希表作为底层数据结构来存储键值对,允许根据键高效地查找对应的值。相较于有序关联容器如 map,unordered_map 通过哈希表提供了 O(1) 的查找、插入和删除时间复杂度。
基于之前封装的哈希表操作,我们可以设计一个简化版的 unordered_map,并详细讲解其中的实现原理。
5.7.1、基本概念和设计思路
unordered_map 的底层使用哈希表存储键值对 (key-value pair),它的核心操作包括:
- 插入:将键值对存储到哈希表中。
- 查找:通过键来查找对应的值。
- 删除:从哈希表中移除指定的键值对。
与 unordered_set 不同的是,unordered_map 需要存储键值对,而不仅仅是存储键。因此,在哈希表中,我们需要将 key 和 value 一起存储。
5.7.2、类设计
我们可以设计一个简化的 unordered_map,并利用之前的哈希表结构封装键值对存储的逻辑。
#pragma once
#include "HashTable.hpp"
namespace Lenyiin
{
template <class K, class V, class Hash = _Hash<K>>
class Unordered_Map
{
public:
struct MapKOfT
{
const K &operator()(const std::pair<K, V> &kv)
{
return kv.first;
}
};
typedef typename Open_HashTable<K, std::pair<K, V>, MapKOfT, Hash>::iterator iterator;
iterator begin()
{
return _hashTable.begin();
}
iterator end()
{
return _hashTable.end();
}
// 构造函数: 指定哈希表的初始大小
Unordered_Map(size_t bucket_count = 10)
: _hashTable(bucket_count)
{
}
// 析构
~Unordered_Map()
{
}
std::pair<iterator, bool> Insert(const std::pair<K, V> &kv)
{
return _hashTable.Insert(kv);
}
V &operator[](const K &key)
{
std::pair<iterator, bool> ret = _hashTable.Insert(std::make_pair(key, V()));
return ret.first->second;
}
// 查找元素
bool Find(const K &key)
{
return _hashTable.Find(key);
}
// 删除元素
bool Erase(const K &key)
{
return _hashTable.Erase(key);
}
// 打印
void Print() const
{
_hashTable.Print();
}
private:
Open_HashTable<K, std::pair<K, V>, MapKOfT, Hash> _hashTable;
};
}5.7.3、功能封装的详细讲解
1、插入键值对
unordered_map 的插入操作将键值对存储在哈希表中。在插入前,我们需要根据键计算哈希值,并检查是否已经存在该键。如果不存在,则将键值对插入到哈希表中。
bool Insert(const K &key, const V &value) {
return _hashTable.Insert(std::make_pair(key, value));
}- 插入操作流程:
- 使用哈希函数计算键的哈希值,找到对应的桶。
- 在桶中检查是否存在相同的键,如果不存在,则插入新的键值对。
- 如果键已存在,插入失败(哈希表中不允许重复键)。
在这里,我们使用 std::make_pair 将键和值打包成一个 std::pair<K, V>,并插入到哈希表中。unordered_map 的 Insert 操作基于之前封装的 Open_HashTable::Insert,且保证键的唯一性。
2、查找键对应的值
unordered_map 的查找功能通过哈希表来定位键对应的值。查找时,先根据键计算哈希值找到对应的桶,然后在桶中的链表中查找键值对。
bool Find(const K &key, V &value) const {
auto result = _hashTable.Find(key);
if (result) {
value = result->second;
return true;
}
return false;
}- 查找操作流程:
- 使用哈希函数计算键的哈希值,定位到相应的桶。
- 在桶中遍历链表查找键值对。
- 如果找到对应的键,则将值赋给
value,并返回true。 - 如果未找到键,则返回
false。
Find 操作依赖于哈希表的 Find 方法,该方法返回一个指向 std::pair<K, V> 的指针,通过该指针可以访问键对应的值。
3、删除键值对
unordered_map 的删除操作用于从哈希表中移除指定的键值对。删除时,先根据键计算哈希值找到对应的桶,然后在桶中查找并删除键值对。
bool Erase(const K &key) {
return _hashTable.Erase(key);
}- 删除操作流程:
- 计算键的哈希值,定位到对应的桶。
- 在桶中遍历链表查找键值对。
- 找到键值对后,调整链表结构,删除该元素。
- 删除成功后,返回
true;如果键不存在,则返回false。
删除操作依赖于哈希表的 Erase 方法,负责处理链表结构的调整和内存的释放,保证哈希表删除后结构的完整性。
5.7.4、底层封装的具体实现
我们通过模板参数 KeyOfPair 来提取键值对中的键,并使用它作为哈希表的查找依据。可以为 KeyOfPair 封装一个结构体,它能够从 std::pair<K, V> 中提取键:
template <class K, class V>
struct KeyOfPair {
const K& operator()(const std::pair<K, V> &pair) const {
return pair.first;
}
};这样,在哈希表中,当我们传入一个 std::pair<K, V> 时,KeyOfPair 会提取 pair.first 作为键,用于哈希计算和查找。
5.7.5、迭代器设计(可选)
与 unordered_set 类似,unordered_map 也可以支持迭代器,用于遍历哈希表中的所有键值
对。迭代器能够让用户方便地遍历 unordered_map 中的所有键值对。我们可以设计一个迭代器类,它遍历哈希表中的每个桶,并在每个桶中遍历键值对链表。
迭代器的设计可以参考以下代码:
typedef typename Open_HashTable<K, std::pair<K, V>, MapKOfT, Hash>::iterator iterator;
iterator begin()
{
return _hashTable.begin();
}
iterator end()
{
return _hashTable.end();
}这个迭代器类允许遍历整个哈希表中的键值对,支持标准的迭代器操作,如前置 ++ 操作符、解引用操作符 * 以及比较操作符 == 和 !=。
通过迭代器,用户可以方便地使用范围 for 循环遍历 unordered_map:
for (auto it = map.begin(); it != map.end(); ++it) {
std::cout << it->first << ": " << it->second << std::endl;
}5.7.6、测试
void Test_Unordered_Map()
{
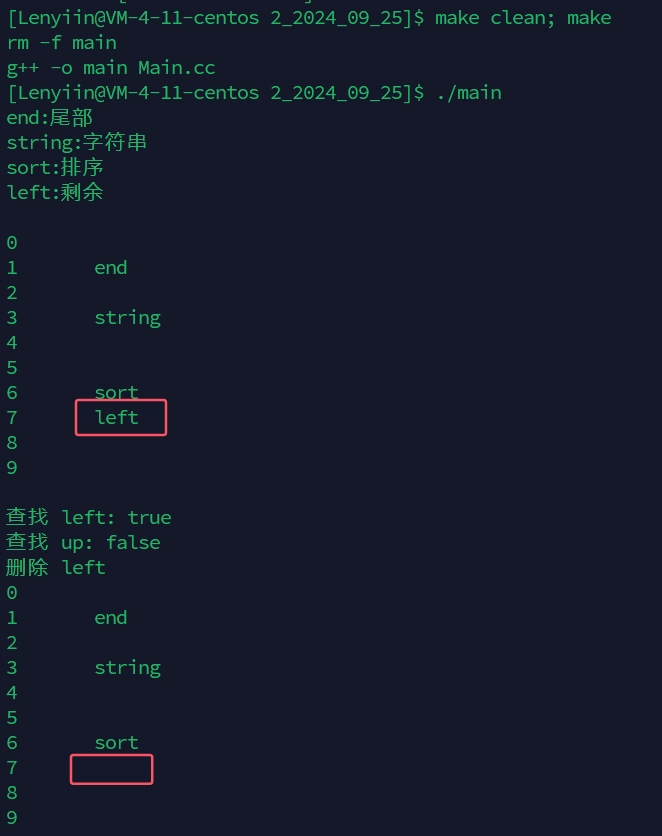
Lenyiin::Unordered_Map<std::string, std::string> dict;
dict.Insert(std::make_pair("sort", "排序"));
dict.Insert(std::make_pair("left", "左边"));
dict.Insert(std::make_pair("string", "字符串"));
dict["left"] = "剩余"; // 修改
dict["end"] = "尾部"; // 插入 + 修改
// Unordered_Map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
// cout << it->first << ":" << it->second << endl;
std::cout << (*it).first << ":" << (*it).second << std::endl;
++it;
}
std::cout << std::endl;
dict.Print();
std::cout << "查找 left: " << (dict.Find("left") ? "true" : "false") << std::endl;
std::cout << "查找 up: " << (dict.Find("up") ? "true" : "false") << std::endl;
std::cout << "删除 left" << std::endl;
dict.Erase("left");
dict.Print();
}
int main()
{
Test_Unordered_Map();
return 0;
}5.7.7、测试结果
5.7.8、小结
我们基于之前封装的哈希表,实现了一个简化版的 unordered_map,其核心功能包括插入、查找和删除键值对。unordered_map 使用哈希表存储键值对,并通过自定义的 KeyOfPair 提取键进行哈希计算和查找。
这个实现展示了 unordered_map 的底层原理,帮助理解 C++ 标准库中无序关联容器的高效性。在实际开发中,标准库的 std::unordered_map 提供了更多功能,如自定义哈希函数、负载因子调整等,这些功能可以进一步提升哈希表的性能与可扩展性。
6、有序容器和无序容器对比
在 C++ 中,有序容器和无序容器是两类重要的数据结构,它们在实现机制、操作性能和适用场景上存在显著差异。以下将从多个方面详细对比有序容器和无序容器。
6.1、set 和 unordered_set 增删查性能测试
测试代码:
#include <iostream>
#include <set>
#include <unordered_set>
#include <time.h>
int main()
{
std::unordered_set<int> us;
std::set<int> s;
const size_t n = 100000;
std::vector<int> v;
v.reserve(n); // reserve()函数是vector预留空间的,但是并不真正创建元素对象。
// resize()函数是开空间+初始化
srand(time(0));
for (size_t i = 0; i < n; ++i)
{
v.push_back(rand());
}
// 插入
clock_t begin = clock();
for (size_t i = 0; i < n; ++i)
{
us.insert(v[i]);
}
clock_t end = clock();
std::cout << "unordered_set insert time:\t" << end - begin << std::endl;
begin = clock();
for (size_t i = 0; i < n; ++i)
{
s.insert(v[i]);
}
end = clock();
std::cout << "set insert time:\t\t" << end - begin << std::endl;
// 查找
begin = clock();
for (size_t i = 0; i < n; ++i)
{
us.find(v[i]);
}
end = clock();
std::cout << "unordered_set find time:\t" << end - begin << std::endl;
begin = clock();
for (size_t i = 0; i < n; ++i)
{
s.find(v[i]);
}
end = clock();
std::cout << "set find time:\t\t\t" << end - begin << std::endl;
// 删除
begin = clock();
for (size_t i = 0; i < n; ++i)
{
us.erase(v[i]);
}
end = clock();
std::cout << "unordered_set erase time:\t" << end - begin << std::endl;
begin = clock();
for (size_t i = 0; i < n; ++i)
{
s.erase(v[i]);
}
end = clock();
std::cout << "set erase time:\t\t\t" << end - begin << std::endl;
}测试结果:
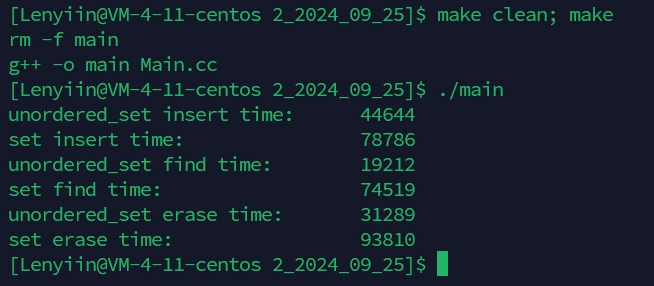
6.2、容器类型
- 有序容器:
- 包括
std::set、std::map、std::multiset、std::multimap。 - 这些容器中的元素根据键的顺序进行排序(通常使用
operator<比较),因此容器中的元素总是保持排序状态。
- 包括
- 无序容器:
- 包括
std::unordered_set、std::unordered_map、std::unordered_multiset、std::unordered_multimap。 - 无序容器使用哈希表存储元素,元素的存储顺序并不是有序的,而是由哈希值决定,因此遍历时元素的顺序是不可预测的。
- 包括
6.3、底层数据结构
- 有序容器 :
- 基于平衡二叉搜索树(如红黑树)实现。
- 二叉树保证在插入、查找和删除操作后,树的平衡性得以维护,使得这些操作的时间复杂度为 O(log n)。
- 无序容器 :
- 基于哈希表实现。
- 哈希表通过哈希函数将键映射到一个桶(bucket)中,元素插入、查找和删除的平均时间复杂度为 O(1),但最坏情况下可能会退化为 O(n),当所有元素哈希到同一个桶中时会出现这种情况。
6.4、时间复杂度
- 有序容器:
- 查找 :
O(log n) - 插入 :
O(log n) - 删除 :
O(log n) - 遍历 :
O(n),元素按升序或降序排列。
- 查找 :
- 无序容器:
- 查找 :
O(1)(平均情况下) - 插入 :
O(1)(平均情况下) - 删除 :
O(1)(平均情况下) - 遍历 :
O(n),元素存储顺序无序。
- 查找 :
无序容器在查找、插入、删除操作上的平均性能优于有序容器,但在最坏情况下,哈希冲突可能导致性能下降。此外,由于无序容器不保证元素顺序,因此如果需要有序遍历,必须使用有序容器。
6.5、顺序保证
- 有序容器:
- 元素按键值顺序排列。例如,对于
std::set<int>,插入的整数会根据大小排序,遍历时从小到大输出。
- 元素按键值顺序排列。例如,对于
- 无序容器:
- 元素没有顺序。哈希表存储元素时不保证顺序,遍历顺序也无法预测。例如,
std::unordered_map<int, int>中的键值对存储顺序是哈希值决定的。
- 元素没有顺序。哈希表存储元素时不保证顺序,遍历顺序也无法预测。例如,
6.6、内存占用
- 有序容器:
- 由于基于树结构实现,有序容器通常需要额外的内存来维护树节点和指针。
- 无序容器:
- 无序容器依赖于哈希表实现,需要为哈希表的桶(bucket)分配额外的空间。无序容器在不同负载因子下会进行哈希表的重新哈希(rehashing),这时内存使用会显著增加。
6.7、使用场景
- 有序容器 :
- 适用于需要频繁有序遍历的场景,例如在需要保持数据排序状态的情况下,使用
std::map可以确保键值对按照键顺序排列。 - 适用于需要查找某范围内 元素的场景,诸如
std::set和std::map提供了lower_bound和upper_bound接口,方便查找特定范围内的元素。
- 适用于需要频繁有序遍历的场景,例如在需要保持数据排序状态的情况下,使用
- 无序容器 :
- 适用于不需要排序,但需要高效插入、查找和删除的场景。比如存储数据量大且不关心顺序的情况,
std::unordered_map比std::map更适合。 - 无序容器的查找性能通常更快,因此在键值对多且需要频繁查找的情况下,无序容器更优。
- 适用于不需要排序,但需要高效插入、查找和删除的场景。比如存储数据量大且不关心顺序的情况,
6.8、遍历性能
- 有序容器 :
- 有序容器支持按顺序遍历,时间复杂度为
O(n),并且遍历的顺序由键值的比较函数决定。
- 有序容器支持按顺序遍历,时间复杂度为
- 无序容器 :
- 无序容器支持遍历,但遍历顺序不可预测,元素存储顺序取决于哈希函数的计算结果。遍历的时间复杂度也是
O(n)。
- 无序容器支持遍历,但遍历顺序不可预测,元素存储顺序取决于哈希函数的计算结果。遍历的时间复杂度也是
6.9、额外功能
- 有序容器 :
- 支持范围查询、区间操作等。例如,
std::map提供的lower_bound和upper_bound操作可以轻松获取特定范围内的元素。
- 支持范围查询、区间操作等。例如,
- 无序容器 :
- 不支持有序遍历和范围查询,但可以通过
bucket和bucket_count接口访问哈希表的底层信息。
- 不支持有序遍历和范围查询,但可以通过
6.10、最坏情况分析
- 有序容器:
- 平衡二叉树的数据结构保证最坏情况下操作的时间复杂度为
O(log n),因此其性能较为稳定。
- 平衡二叉树的数据结构保证最坏情况下操作的时间复杂度为
- 无序容器:
- 哈希表在哈希冲突严重时可能退化为
O(n)时间复杂度的操作。通过使用合适的哈希函数和合理的负载因子,可以减少哈希冲突的发生,从而保持O(1)的性能。
- 哈希表在哈希冲突严重时可能退化为
6.11、小结
| 特性 | 有序容器 (std::set, std::map) |
无序容器 (std::unordered_set, std::unordered_map) |
|---|---|---|
| 底层数据结构 | 平衡二叉树 | 哈希表 |
| 时间复杂度(查找、插入、删除) | O(log n) |
O(1)(平均情况),O(n)(最坏情况) |
| 元素顺序 | 有序 | 无序 |
| 内存占用 | 较少的额外内存 | 需要为桶和重新哈希分配更多的内存 |
| 适用场景 | 需要有序、范围查询的场景 | 高效查找、插入和删除,不关心顺序的场景 |
| 最坏情况性能 | 稳定的 O(log n) |
可能退化为 O(n) |
| 遍历 | 按元素顺序遍历 | 无序遍历 |
| 额外功能 | 范围查询、上下界操作等 | 不支持有序操作,但提供哈希表相关的底层信息访问 |
有序容器适合需要按顺序存储和访问元素的场景,提供较为稳定的性能;无序容器则更适合需要高效查找、插入、删除且不关心顺序的场景。选择合适的容器可以显著提高程序的效率,减少不必要的性能开销。
7、进阶拓展
在第四章讨论了 unordered_set 和 unordered_map 的底层基本实现和性能优化后,接下来,我们可以进一步挖掘它们背后的高级主题,包括哈希表的设计策略、如何处理并发操作、在大规模分布式系统中的应用,以及内存管理和 cache 局部性等更为复杂的技术细节。了解这些高级话题将有助于开发者在面对复杂场景时,充分利用这些容器的优势,并有效规避潜在的性能瓶颈。
7.1、哈希表的设计策略
unordered_set 和 unordered_map 基于哈希表设计,而哈希表本身的设计涉及多个关键决策。哈希表的设计不仅影响性能,还决定了容器在特定场景下的适用性。
7.1.1、哈希函数的选择
一个好的哈希函数是 unordered_set 和 unordered_map 高效运行的关键。我们在之前的讨论中提到,理想的哈希函数应当具备均匀分布、高效计算和确定性三个特性。但在高级应用中,哈希函数的选择不仅仅关乎性能,还涉及安全性和冲突回避。
安全性
某些应用场景需要防止哈希碰撞攻击(Hash Collision Attack)。例如,网络应用程序中的恶意用户可能构造出大量哈希值相同的输入数据,导致哈希表中的元素全部集中在一个桶中,进而使查找、插入和删除的时间复杂度退化为 O(n)。为应对这种攻击,现代哈希表实现中引入了随机哈希(Randomized Hashing)。在这种方法中,哈希函数会基于程序的启动时间或系统状态等随机因素生成独特的哈希值,从而使得攻击者难以预测哈希值。
std::unordered_map<int, std::string, MySecureHash> secure_map;7.1.2、哈希表扩展策略
哈希表的扩展(即重新哈希)直接影响到 unordered_set 和 unordered_map 的性能表现。每当元素数目超过桶数量乘以负载因子时,哈希表会进行扩容,并将现有元素重新分布到新的哈希表中。这一过程是计算昂贵的,需要考虑扩展策略的选择:
2.1、指数增长 vs 渐进增长
多数标准库实现采用指数增长策略,即每次扩容时桶的数量倍增。这种方法能够有效减少扩容的频率,使得元素的分布更加均匀。然而在某些特定的高性能计算场景下,渐进增长策略可能更加合适,即在需要扩展时逐步增加桶数量,以避免单次大规模的重新分配操作所带来的性能抖动。
2.2、扩展时机优化
在高级设计中,一些实现还会考虑将扩容时机延迟到元素插入后的空闲时间段(如在后台线程中进行扩容操作),以平滑扩展过程的计算开销。此外,通过对常见访问模式的分析,系统还可以预估未来的数据增长趋势,提前进行扩容。
7.1.3、冲突处理策略的比较
在常见的哈希表实现中,冲突处理通常采用链地址法(Chaining)或开放寻址法(Open Addressing)。每种策略都有其适用场景和优劣势。在高级设计中,冲突处理的策略选择需根据实际应用场景的需求权衡性能和空间复杂度。
链地址法 vs 开放寻址法
链地址法的优点在于其处理高负载因子的能力较强,在哈希表负载较高时依然能够较好地维持性能。然而,由于每个桶中存储的是指针,链地址法在内存使用上通常较开放寻址法更高。另一方面,开放寻址法通过将冲突的元素存储在相邻的桶中,能够有效减少指针的开销,但在高负载因子下性能下降显著。
高级应用中可以根据不同场景选择适合的策略。例如:
-
链地址法适合负载因子较高、空间不敏感的场景。
-
开放寻址法更适合空间敏感但对性能有较高要求的场景。
// Example: 使用开放寻址法的哈希表
std::unordered_set<int, MyOpenAddressingHashFunction> my_open_addressing_set;
7.2、并发处理与线程安全
在多线程环境中使用 unordered_set 和 unordered_map 时,线程安全性是一个重要考虑因素。标准库中的哈希表并非线程安全的,多个线程同时修改同一个哈希表会导致未定义行为。因此,在多线程应用中,开发者需要额外的机制来确保安全性。
7.2.1、读写锁与分片锁
为了避免全局锁带来的性能瓶颈,可以采用分片锁(Shard Locking)技术。将哈希表分为多个独立的子表,每个子表对应一个锁,允许多个线程同时访问不同的子表,从而提升并发性。特别是在高并发场景下,这种设计能够显著提高容器的吞吐量。
class ThreadSafeUnorderedMap {
std::vector<std::unordered_map<int, std::string>> shards;
std::vector<std::mutex> shard_mutexes;
public:
ThreadSafeUnorderedMap(size_t shard_count) {
shards.resize(shard_count);
shard_mutexes.resize(shard_count);
}
void insert(int key, const std::string& value) {
size_t shard_index = key % shards.size();
std::lock_guard<std::mutex> lock(shard_mutexes[shard_index]);
shards[shard_index][key] = value;
}
};7.2.2、哈希表的无锁实现
为进一步优化并发性能,可以研究无锁哈希表(Lock-free Hash Table)的实现。无锁数据结构通过 CAS(Compare-And-Swap)等原子操作保证线程间的数据一致性,避免传统锁机制带来的性能开销。这种设计通常用于对并发性能要求极高的场景,但实现复杂度较高,且需要处理内存管理等额外问题。
7.3、内存管理与缓存局部性
在 unordered_set 和 unordered_map 的高性能设计中,内存管理和缓存局部性也是必须考虑的重要因素。
7.3.1、内存碎片化问题
链地址法中,每个桶的元素链表通常存储在堆上,频繁的插入和删除操作可能导致内存碎片化问题,进而影响性能。为了缓解这一问题,可以采用内存池(Memory Pool)技术,预先分配一大块连续的内存区域供哈希表使用,从而减少内存分配和释放的开销。
// Example: 使用内存池管理哈希表元素的内存
std::unordered_set<int, MyCustomAllocator> my_set;7.3.2、缓存局部性优化
缓存局部性对性能的影响不容忽视。在链地址法中,元素存储在链表中,链表节点通常位于不同的内存地址上,访问时会导致频繁的缓存未命中(cache miss),从而降低访问性能。
为了提高缓存命中率,可以考虑使用连续的内存布局,例如平坦哈希表(Flat Hash Table)。这种哈希表将元素直接存储在连续的数组中,大幅提升缓存命中率,尤其适合在大量查询和插入操作的场景中使用。
7.4、分布式哈希表(DHT)与 unordered_map 的大规模扩展
在大规模分布式系统中,单台机器无法承载所有数据,此时需要使用分布式哈希表(Distributed Hash Table, DHT)将数据分布到多个节点上。DHT 是 unordered_map 在分布式环境中的扩展形式,采用一致性哈希(Consistent Hashing)将数据均匀分布到不同节点。
一致性哈希与负载均衡
一致性哈希通过将哈希值映射到一个环上,节点和数据都映射到环的不同位置,数据存储在离它最近的节点上。当新节点加入或节点故障时,只需重新分配少量数据即可实现负载均衡。对于需要水平扩展的应用场景,DHT 是一种高效的分布式解决方案。
// Example: 分布式哈希表的一致性哈希环
class ConsistentHashRing {
std::map<size_t, Node> hash_ring;
// Implementation details omitted for brevity
};7.5、小结
unordered_set 和 unordered_map 背后的设计涉及多个高级话题,如哈希函数选择、扩展策略、冲突处理、并发优化、内存管理和缓存优化等。通过深入理解这些设计决策,开发者能够根据实际场景需求灵活调整容器的实现与使用策略,从而获得最佳的性能表现。在未来的高性能和分布式计算应用中,这些容器的设计与优化仍然会是一个重要的研究方向。
8、unordered_set 和 unordered_map 的实际案例与应用场景
unordered_set 和 unordered_map 是 C++ 标准库中两个非常重要的无序关联容器。由于它们基于哈希表的实现,能够提供平均 O(1) 的插入、查找和删除性能,因此在需要快速查找、存储和访问数据的应用中非常有用。本章将深入探讨它们在实际项目中的应用场景及其背后的技术细节。
8.1、高效的数据查重与去重
应用场景: 在很多数据处理中,去重是常见的需求。例如,在处理一大批用户提交的数据时,系统需要快速去除重复项,以保证数据的唯一性。
案例:去重操作
假设我们有一个网站用户注册系统,需要保证每个用户的电子邮件是唯一的。我们可以使用 unordered_set 存储已注册的电子邮件地址,并在用户提交注册时快速检查电子邮件的唯一性:
#include <unordered_set>
#include <string>
std::unordered_set<std::string> registered_emails;
bool is_email_unique(const std::string& email) {
// 如果邮件已存在,则返回 false,否则插入并返回 true
auto result = registered_emails.insert(email);
return result.second; // 如果插入成功,则返回 true,否则为 false
}技术细节:
unordered_set的底层是哈希表,其查找复杂度为O(1)。相比于有序集合(如std::set的O(log n)),unordered_set在处理大规模数据时能显著提升性能。- 当新用户注册时,我们只需
O(1)的时间查找现有的电子邮件地址,确保唯一性,这在高并发的注册系统中尤为重要。
8.2、快速键值对查询
应用场景: 键值对查询是 unordered_map 最常见的应用场景之一。它可以用于实现缓存、查表映射、以及任何基于键的快速访问需求。
案例:DNS 解析缓存
在 DNS 系统中,域名到 IP 地址的映射需要频繁查询。为了减少对上游 DNS 服务器的请求量,DNS 解析器会将查询结果缓存一段时间。我们可以用 unordered_map 来实现一个简单的 DNS 缓存系统。
#include <unordered_map>
#include <string>
#include <iostream>
// 模拟的 DNS 缓存
std::unordered_map<std::string, std::string> dns_cache;
std::string resolve_dns(const std::string& domain) {
// 查询缓存是否有记录
if (dns_cache.find(domain) != dns_cache.end()) {
return dns_cache[domain]; // 如果找到,返回 IP
} else {
// 模拟从 DNS 服务器解析,假设所有域名解析为 "1.1.1.1"
std::string ip = "1.1.1.1";
dns_cache[domain] = ip; // 将结果存入缓存
return ip;
}
}
int main() {
std::cout << resolve_dns("example.com") << std::endl;
std::cout << resolve_dns("example.com") << std::endl; // 第二次查询会直接从缓存返回
}技术细节:
unordered_map提供O(1)的查找性能,使得域名的查询速度非常快。- 与
std::map不同,unordered_map并不维护元素的顺序,但其查找速度在大多数场景下更快,适合需要频繁查询的应用。 - 通过这种缓存机制,可以显著减少对上游 DNS 服务器的请求次数,提升整个系统的性能。
8.3、实时分析与监控系统
应用场景: 在实时监控系统中,系统会收到大量的日志、事件数据等信息。需要根据这些数据对特定关键指标进行快速统计。例如,我们可以跟踪每个 IP 地址的访问次数,以便在一段时间内发现异常流量。
案例:实时流量监控
假设我们正在设计一个系统,记录每个 IP 地址的访问频率。通过 unordered_map,我们可以高效地维护每个 IP 地址的访问计数:
#include <unordered_map>
#include <string>
#include <iostream>
std::unordered_map<std::string, int> ip_access_count;
void log_access(const std::string& ip) {
ip_access_count[ip]++; // 增加该 IP 的访问计数
}
void report_access() {
for (const auto& entry : ip_access_count) {
std::cout << "IP: " << entry.first << ", Access Count: " << entry.second << std::endl;
}
}
int main() {
log_access("192.168.1.1");
log_access("192.168.1.2");
log_access("192.168.1.1"); // 第二次访问相同的 IP
report_access(); // 输出访问报告
}技术细节:
unordered_map适合频繁插入、查找、更新操作。每当有新 IP 访问时,系统可以在 O(1) 时间内更新计数。- 在此类高频率、实时监控的场景中,性能至关重要,而
unordered_map通过哈希表提供了快速的访问性能。 - 此外,还可以在系统中添加基于时间的过期策略,定期清理访问次数较少的 IP 地址以节省内存。
8.4、关系型数据库的索引优化
应用场景: 数据库中的索引用于加速数据查询。对于非顺序的字段,哈希索引(即基于哈希表实现的索引)可以极大提高查询速度。unordered_map 可以模拟哈希索引的核心实现原理。
案例:模拟数据库的主键索引
假设我们有一个简单的用户表,其中主键是用户 ID。我们可以使用 unordered_map 来模拟一个主键索引,以便快速找到用户的信息。
#include <unordered_map>
#include <string>
#include <iostream>
struct User {
int id;
std::string name;
};
std::unordered_map<int, User> user_table;
void insert_user(int id, const std::string& name) {
user_table[id] = User{id, name}; // 插入或更新用户信息
}
User* find_user(int id) {
auto it = user_table.find(id);
if (it != user_table.end()) {
return &it->second; // 找到用户
} else {
return nullptr; // 未找到
}
}
int main() {
insert_user(1, "Alice");
insert_user(2, "Bob");
User* user = find_user(1);
if (user) {
std::cout << "User Found: " << user->name << std::endl;
} else {
std::cout << "User Not Found" << std::endl;
}
}技术细节:
unordered_map通过 O(1) 的查找能力,能够高效模拟数据库中的哈希索引,尤其适用于那些基于非顺序键值的查询。- 在数据规模较大的情况下,基于哈希表的索引结构能够极大提高查询性能,而其插入和更新操作的效率也非常高。
- 这种基于哈希的索引机制适合主键为随机数、UUID 或者非连续数值的场景。
8.5、大规模数据去重与集合操作
应用场景: 在一些大数据处理场景中,需要对海量数据进行去重或交集、并集、差集等集合操作。unordered_set 的无序、快速插入和查找特性使得其在这种场景下表现出色。
案例:日志去重与交集分析
假设我们有两个来源的日志数据集,分别记录了不同用户的访问记录。我们希望找到两个数据集中共同出现的用户,以分析交集用户的行为。
#include <unordered_set>
#include <string>
#include <iostream>
std::unordered_set<std::string> log_set_1;
std::unordered_set<std::string> log_set_2;
void find_common_users() {
std::unordered_set<std::string> common_users;
for (const auto& user : log_set_1) {
if (log_set_2.find(user) != log_set_2.end()) {
common_users.insert(user);
}
}
std::cout << "Common Users:" << std::endl;
for (const auto& user : common_users) {
std::cout << user << std::endl;
}
}
int main() {
log_set_1.insert("user1");
log_set_1.insert("user2");
log_set_2.insert("user2");
log_set_2.insert("user3");
find_common_users();
}技术细节:
-
unordered_set的高效查找和插入特性,使得在处理大规模数据集时,可以快速找到两个集合中的交集用户。即使数据量非常大,基于哈希表的操作也能保持较低的时间复杂度。 -
在上述示例中,
log_set_1和log_set_2分别存储来自不同来源的用户记录,通过遍历log_set_1和查找log_set_2来确定交集。这种方法在数据量较大时仍能保持 O(1) 的查找性能,确保了效率。
8.6、小结
unordered_set 和 unordered_map 在许多实际应用中展现出了极高的性能和灵活性,尤其是在快速查找、去重、集合操作等场景。它们通过哈希表的实现,提供了平均 O(1) 的插入、查找和删除性能,适合用于处理大规模数据和高频率操作的场合。
无论是在网络应用、实时监控系统、数据库索引,还是在数据分析与处理的场景中,充分利用这两个容器的特性可以有效提升系统性能和响应速度。理解它们的实现机制与优化策略,可以帮助开发者在实际项目中做出更合理的设计决策,进而实现更高效、更可靠的系统。
9、总结
在现代 C++ 开发中,unordered_set 和 unordered_map 是两种广泛应用的哈希表容器,它们提供了高效的插入、查找和删除操作。通过使用哈希函数将键映射到特定的桶,它们能够以近乎常数的时间复杂度(O(1))完成这些操作。相较于传统的有序容器如 set 和 map,unordered_set 和 unordered_map 提供了更快的访问速度,尤其适合大规模数据处理和高频率操作的场景。
通过阅读这篇博客,读者能深入理解 unordered_set 和 unordered_map 的内部实现原理和使用方法。读者不仅会学到如何高效地使用这些容器,还能掌握性能优化技巧如选择适当的哈希函数和控制负载因子。此外,博客还探讨了高级话题如并发处理和自定义哈希函数,帮助读者解决实际工程中的复杂问题。最终,读者将能够更灵活地在不同场景下选择和使用哈希表相关的容器。并根据业务场景进行优化,能够有效提高系统的性能和响应速度,能更好地应对实际开发中的挑战。
希望这篇博客对您有所帮助,也欢迎您在此基础上进行更多的探索和改进。如果您有任何问题或建议,欢迎在评论区留言,我们可以共同探讨和学习。更多知识分享可以访问 我的个人博客网站 。本博客所涉及的代码也可以从 CSDN 下载区下载