1. 数据收集与预处理的任务?
为机器学习模型提供好的"燃料"
2. 数据收集与预处理的分步骤?
收集数据-->数据可视化-->数据清洗-->特征工程-->构建特征集和数据集-->拆分数据集、验证集和测试集
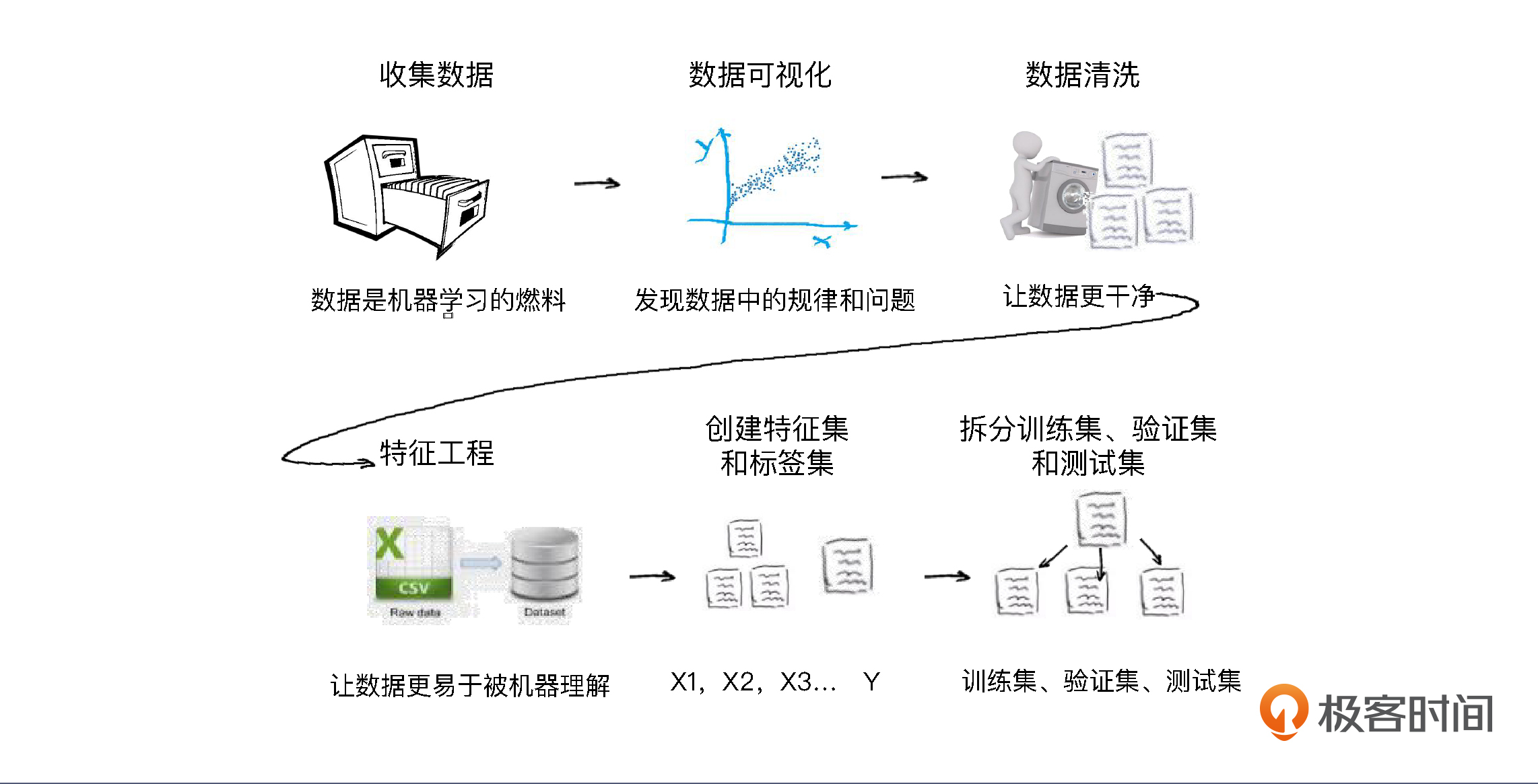
3. 数据可视化工作?
a. **作用:**通过可视化观察一下数据,为选择具体的机器学习模型找找感觉。
b. 具体应用:
可以看一看特征和标签之间可能存在的关系
也可以看看数据里有没有"脏数据"和"离群点"
c. **可视化工具:**Matplotlib,Seaborn
- 散点图:验证线性关系
pythonplt.plot(df_ads['点赞数'],df_ads['浏览量'],'r.', label='Training data') # 用matplotlib.pyplot的plot方法显示散点图 plt.xlabel('点赞数') # x轴Label plt.ylabel('浏览量') # y轴Label plt.legend() # 显示图例 plt.show() # 显示绘图结果!
- 箱线图:检查数据集是否有"离群点".(选择了"热度指数"特征)
pythondata = pd.concat([df_ads['浏览量'], df_ads['热度指数']], axis=1) # 浏览量和热度指数 fig = sns.boxplot(x='热度指数', y="浏览量", data=data) # 用seaborn的箱线图画图 fig.axis(ymin=0, ymax=800000); #设定y轴坐标、
4. 数据清洗工作的任务?
清洗数据的4种情况:
处理缺失值的数据
处理重复值的数据
处理错误的数据
处理不可用的数据
5. 特征工程
以 BMI 特征工程为例,它降低了特征数据集的维度。维度就是数据集特征的个数。
要知道,在数据集中,每多一个特征,模型拟合时的特征空间就更大,运算量也就更大。
摒弃掉冗余的特征、降低特征的维度,能使机器学习模型训练得更快。
6. 构建特征集和数据集
python
X=df.drop('浏览量',axis=1)
Y=df['浏览量']
print(X.head())
print(Y.head())7. 拆分训练集、验证集和测试集
具体的拆分,我们会用机器学习工具包 scikit-learn 里的数据集拆分工具 train_test_split 来完成。
虽然是随机分割,但我们要指定一个 random_state 值,这样就保证程序每次运行都分割一样的训练集和测试集。
python
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0)