本文内容来自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7396959.html?templateId=1718516
问题现象
yashandb执行带oracle dblink表的sql性能差:

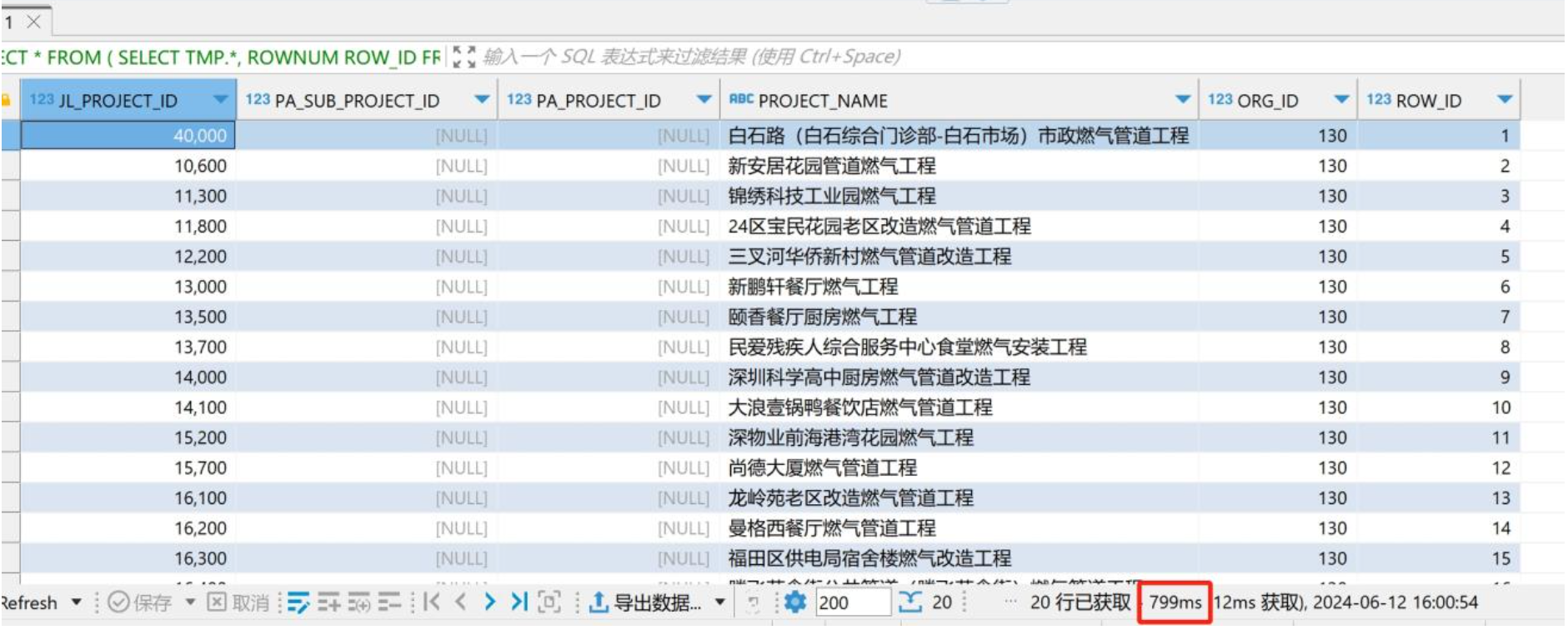
同样的语句,同样的数据,oracle通过dblink访问远端oracle执行,耗时不到1秒钟:

问题的风险及影响
yashandb通过dblink访问oracle性能不佳,影响业务运行效率及客户体验
问题影响的版本
截止目前所有的yashandb版本
问题发生原因
yashandb在访问远端oracle的数据时,拉取了表的所有列。并且每批次只拉取16条数据,在网络有时延时(现场网络时延0.4ms),会有额外的网络传输耗时。
解决方法及规避方式
内核修改代码优化。规避方式为在远端oracle侧创建视图,只查询需要的列。
问题分析和处理过程
使用 sudo tc qdisc add dev bond1 root netem delay 0.45ms 命令模拟网络时延
并将客户的数据导回来,在测试环境模拟重现,yashandb的耗时:
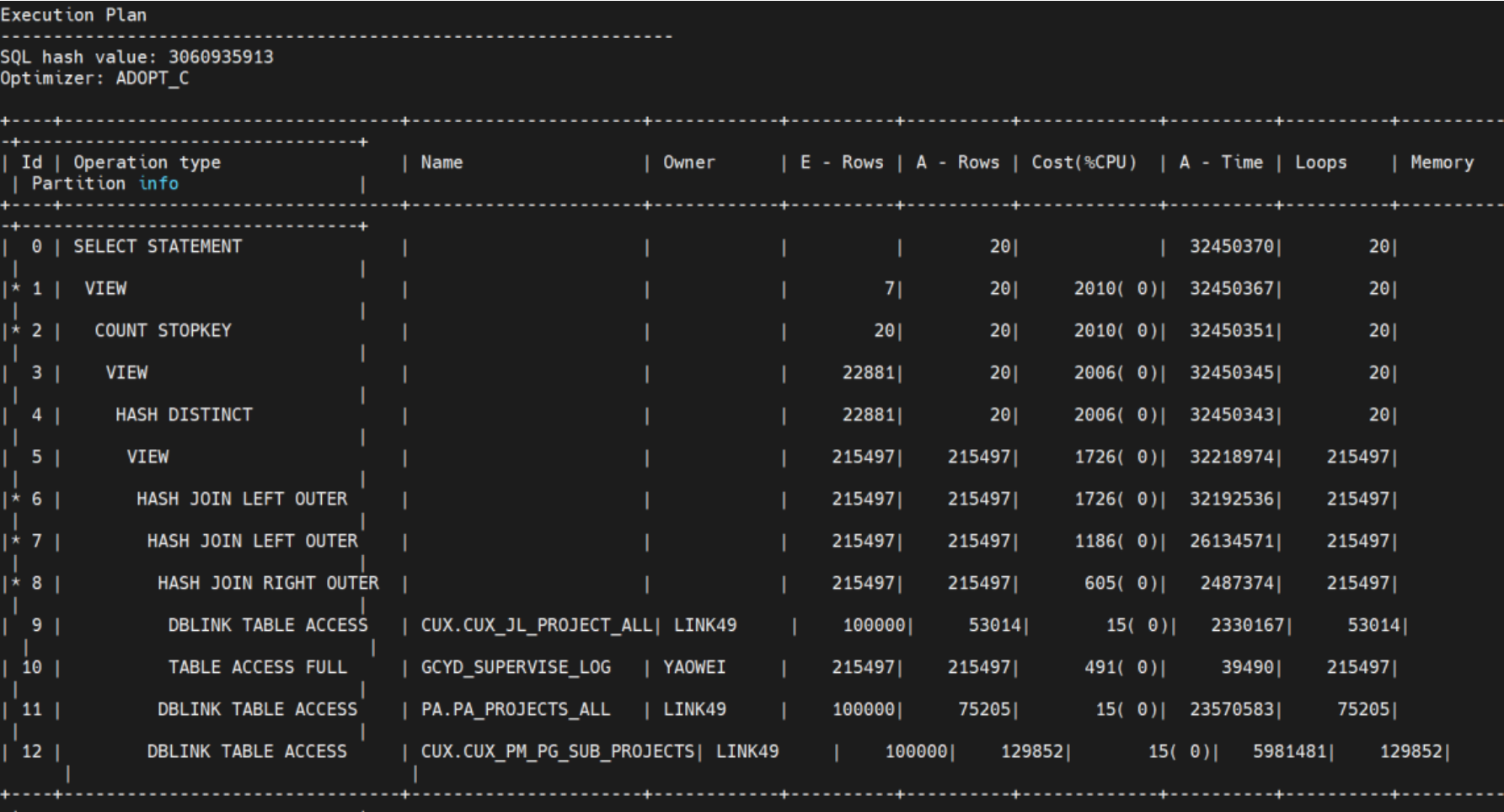
oracle的耗时:

细观察oracle的执行计划,我们可以发现,其访问远端表并不是将所有列的数据拉回来了,而只是拉回来了select查询语句中需要的列:

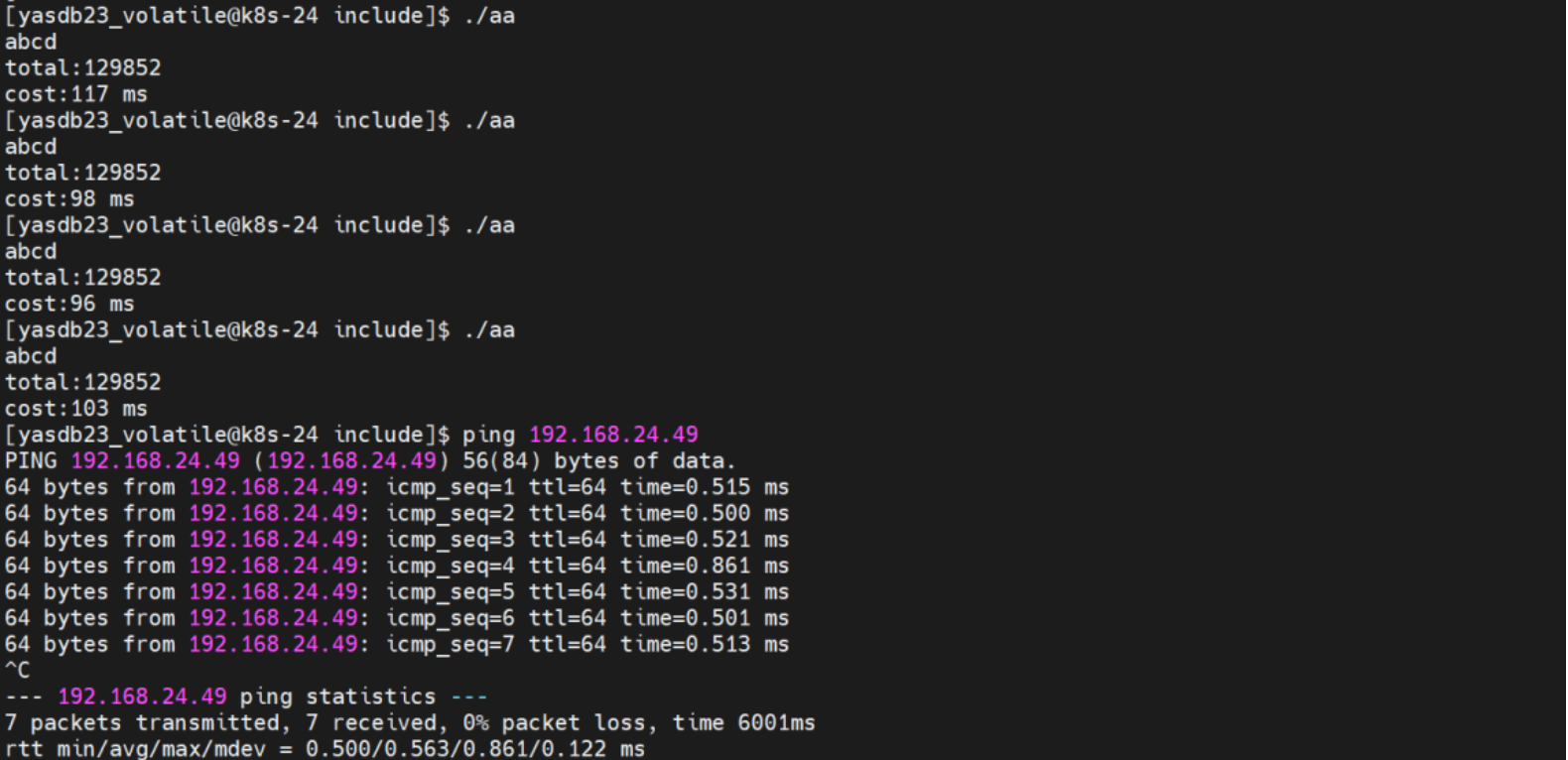
使用OCI驱动编程使用示例 中提供的例子可以分析oci的耗时。
fetch size如果为2000,只从CUX.CUX_PM_PG_SUB_PROJECTS表中查询"SUB_PROJECT_ID","PROJECT_NAME"两列,耗时100ms左右,注意此时的网络时延仍然为0.45ms:
结合以上分析,yashan需要优化的方向为:
1、只从dblink拉取查询需要的列数据
2、设置合理的fetch size,不能太小
经验总结
使用oci编程可以验证yashandb访问oracle dblink远端表在不同情况下的性能表现