MySQL事务
- 事务的概念
- 如何使用事务
- 事务隔离级别
-
- [READ UNCOMMITTED](#READ UNCOMMITTED)
- [READ COMMITTED](#READ COMMITTED)
- [REPEATABLE READ](#REPEATABLE READ)
- SERIALIZABLE
事务的概念
事务就是将一组SQL语句打包成一个整体,这组SQL要么全部执行,要么都不执行,不会存在执行一半的问题
例如:此时有张三、李四两个用户,并且账余额都为1000,现在让张三给李四转100块

sql
create table bank_account(
name varchar(20),
balance double );
insert into bank_account(name,account) values ('张三',1000),('李四',1000);
select name,account from bank_account;
update bank_account set balance = balance - 100 where name = '张三';
update bank_account set balance = balance + 100 where name = '李四'; 转账前

转账后

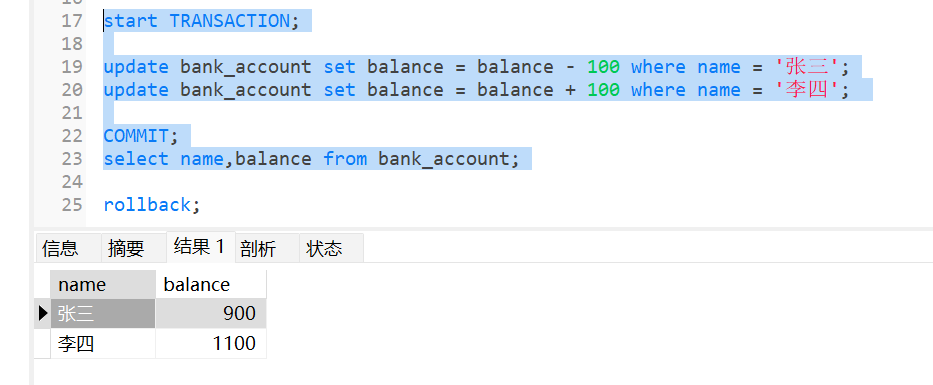
此时这里张三账户减少100变成了900,李四增加100变成1100
这里转账过程中必须得到保证,其余额不会受到其他的干扰,也就是事务的ACID特性
Atomicity (原⼦性) :一个事务中的所有操作,要么全部成功,要么全部失败,不会出现只执行了一半的情况,如果过程中发生错误,会回滚Rollback到事务执行前的状态
Consistency (⼀致性) :事务执行前和执行后都是合理的,符合预期结果,执行过程中不可以破坏数据库的完整性
Isolation (隔离性) :数据库是允许多个客户端并发事务同时对同一个数据进行操作,隔离性是防止这些事务之间相互影响,因此可以指定不同隔离级别平衡性能和安全
Isolation (隔离性):事务对数据库的修改都是持久的,保存在硬盘上,即使系统故障、重启服务器、重启数据库,都不会使数据丢失
如何使用事务
使用事务就要选择支持事务的引擎,MySQL中只有InnoDB支持事务Transactions,并且MySQL中默认的引擎也是InnoDB
sql
show engines;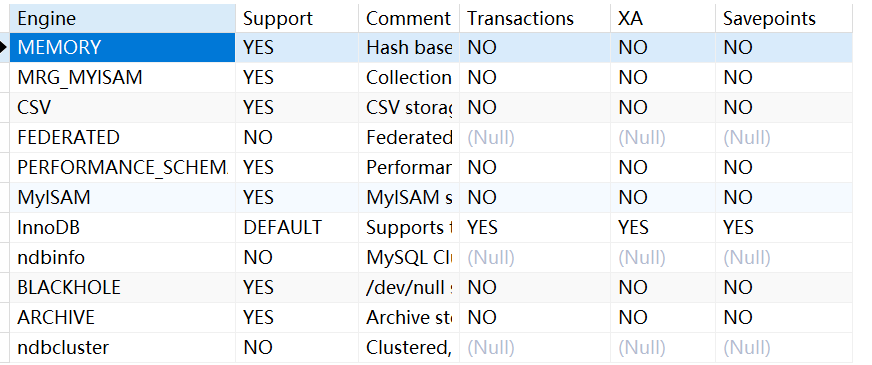
sql
# 方式一开始⼀个新的事务
START TRANSACTION;
# 方式二开始事务
BEGIN;
# 提交当前事务,并对更改持久化保存
COMMIT;
# 回滚当前事务,取消其更改
ROLLBACK;START TRANSACTION 和 BEGIN都是表示开启一个事务
COMMIT提交事务,执行事务提交事务之后,这个事务才会生效
ROLLBACK回滚当前事务,将数据恢复到事务前的样子
这里提交和回滚都会使 事务关闭
使用事务
sql
create table bank_account(
name varchar(20),
balance double );
insert into bank_account(name,balance) values ('张三',1000),('李四',1000);原始数据
现在开始一个事务,让张三给李四转账100
sql
start TRANSACTION;# 开启事务
update bank_account set balance = balance - 100 where name = '张三';
update bank_account set balance = balance + 100 where name = '李四';
COMMIT;#提交事务
select name,balance from bank_account;此时这里数据被正常修改了
回滚事务
sql
start TRANSACTION;
update bank_account set balance = balance - 100 where name = '张三';
update bank_account set balance = balance + 100 where name = '李四';
# 回滚前
select name,balance from bank_account;
rollback;
# 回滚后
select name,balance from bank_account;第一个查询回滚前的查询

第二个回滚后的查询又回到了执行事务前的数据

设置保存点,让其回滚到这个保存点的位置
sql
start TRANSACTION;#开启事务
update bank_account set balance = balance - 100 where name = '张三';
SAVEPOINT point1;# 设置保存点
update bank_account set balance = balance + 100 where name = '李四';
# 回滚前
select name,balance from bank_account;
rollback to point1;# 回滚到保存点位置
# 回滚后
select name,balance from bank_account;回滚前数据
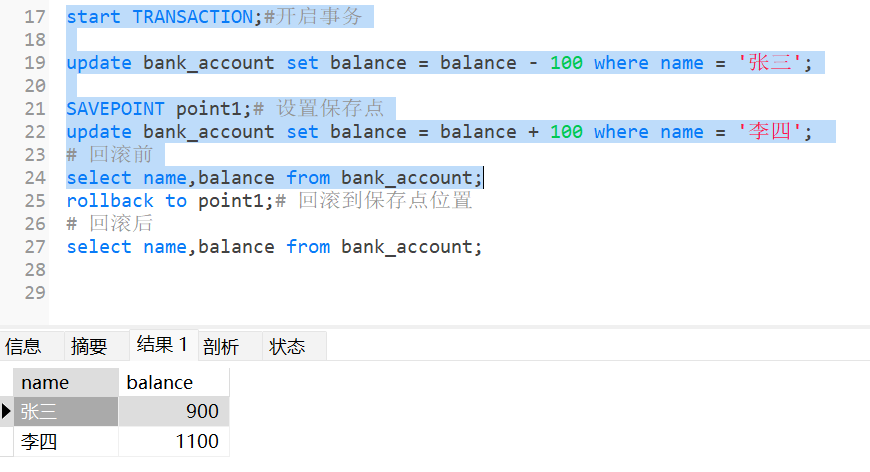
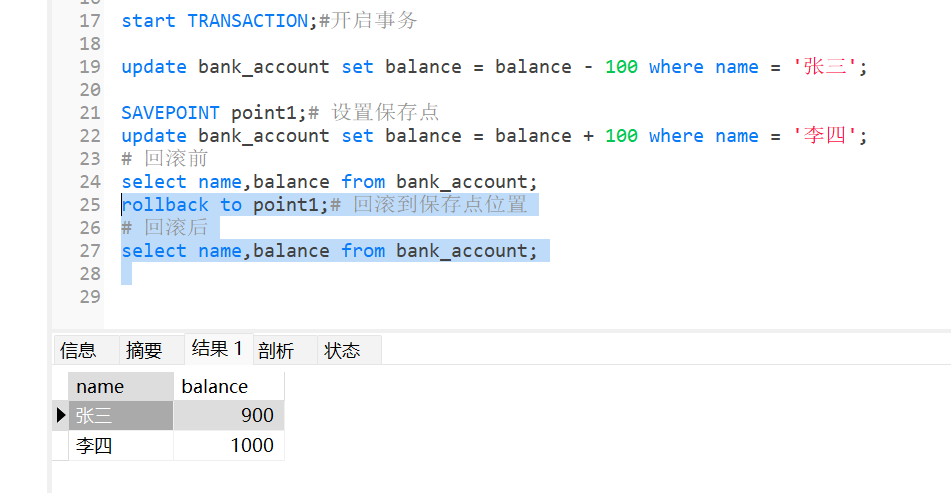
这里回滚到修改李四数据前面,所以此时张三余额-100,因为回滚此时李四余额没变
自动/手动提交事务
sql
show variables like 'autocommit';这里默认是自动提交 比如插入、删除和修改其都会自动开启一个事务完成后自动提交,异常就进行回滚

sql
# 设置自动提交
set autocommit = 1;
set autocommit = ON;
# 设置手动提交
set autocommit = 0;
set autocommit = OFF;但是这里我们START TRANSACTION 或 BEGIN 开启事务 ,就必须使用commit提交或者rollback回滚才会持久,和这里set autocommit设置自动手动提交并没有关系
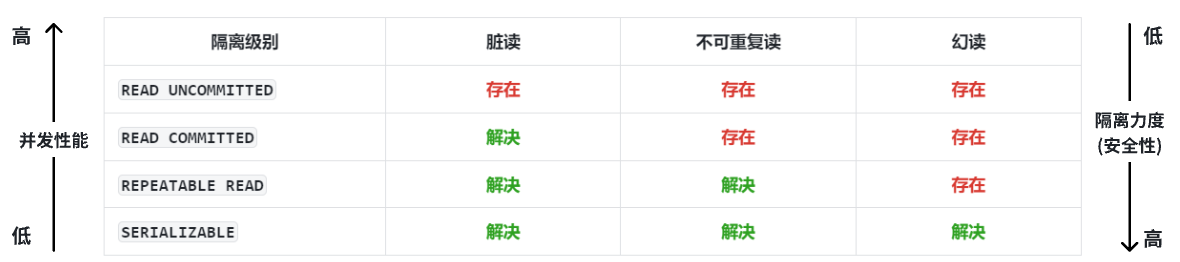
事务隔离级别
事务是具有隔离性的,并且事务间有不同程度的隔离,也就是事务的隔离级别 ,不同隔离级别在性能和安全方面有取舍,需要根据事务的需要,有的是注重安全,有的注重效率
READ UNCOMMITTED 读未提交
READ COMMITTED 读已提交
REPEATABLE READ 不可重复读(默认)
SERIALIZABLE 串行化
sql
# 查询全局
SELECT @@GLOBAL.transaction_isolation;
#会话作用域
SELECT @@SESSION.transaction_isolation;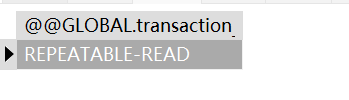

sql
#修改隔离级别
# 方式一
SET GLOBAL transaction_isolation = 'SERIALIZABLE';
SET SESSION transaction_isolation = 'REPEATABLE-READ';
#方式二
SET @@GLOBAL.transaction_isolation='SERIALIZABLE';
SET @@SESSION.transaction_isolation='REPEATABLE-READ';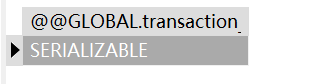
READ UNCOMMITTED
这个隔离级别下,对读取数据时不做任何限制,所以并发性高,效率高,但是安全性较低,出现数据安全问题
脏读问题
例如:事务1执行一条修改UPDATE操作,但是没有执行COMMIT提交
事务2进行读取这条数据 ,但是此时事务1将这条数据进行回滚 ,此时事务2读取的数据就是错误的,这就是"脏读 ",此时事务2可能就会那这个错误的数据进行操作,都是错误的
这里使用Navicat建立两个连接,两个连接分别创建一个查询来表示两个事务
sql
# 开启事务
create table bank_account(
id int primary key auto_increment,
name varchar(20),
balance int);
SELECT @@GLOBAL.transaction_isolation;
SET GLOBAL transaction_isolation = 'READ-UNCOMMITTED';
insert into bank_account(id,name,balance) values(null,'张三',1000),(null,'李四',2000);
start TRANSACTION;
update bank_account set balance = 10000 where name = '张三';
select id,name,balance from bank_account;
rollback;
select id,name,balance from bank_account;
sql
# 开启事务
start TRANSACTION;
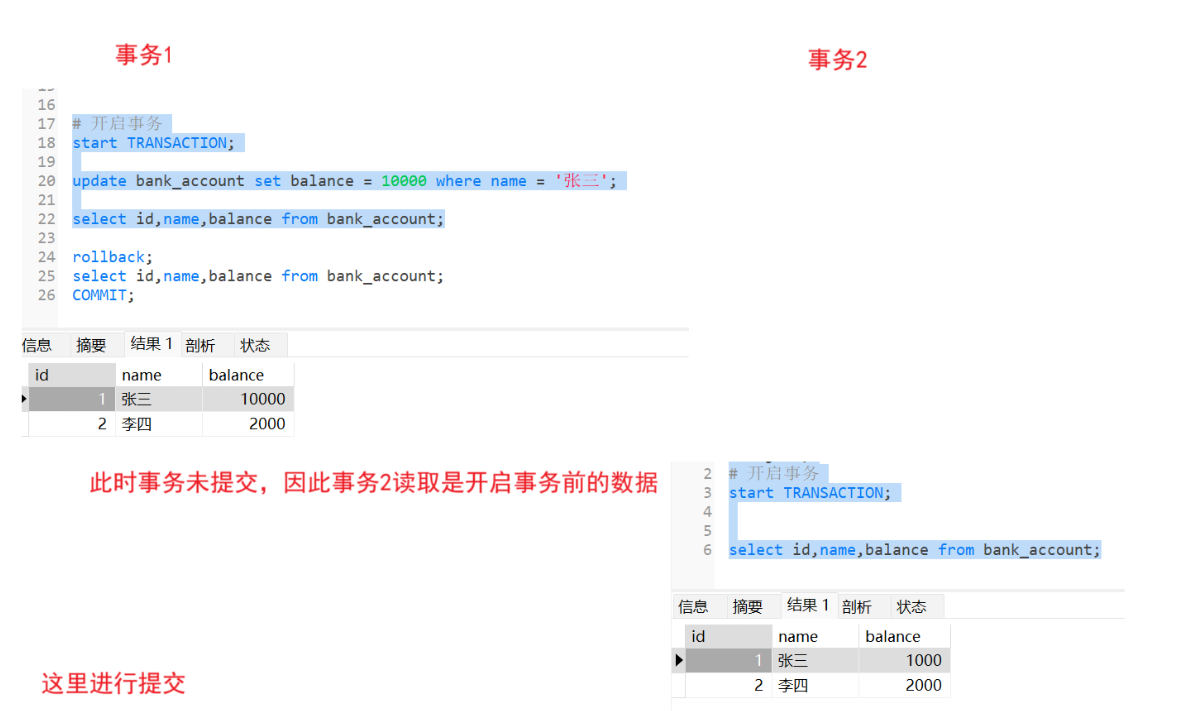
select id,name,balance from bank_account;此时这里将张三余额设置成10000,事务2读取到了这个修改,但是事务1将其回滚,此时事务2那10000这条数据进行后面操作就是错误的

此时这里问题是事务1并没有提交事务,事务2就读取到了,因此需要提高隔离级别
READ COMMITTED
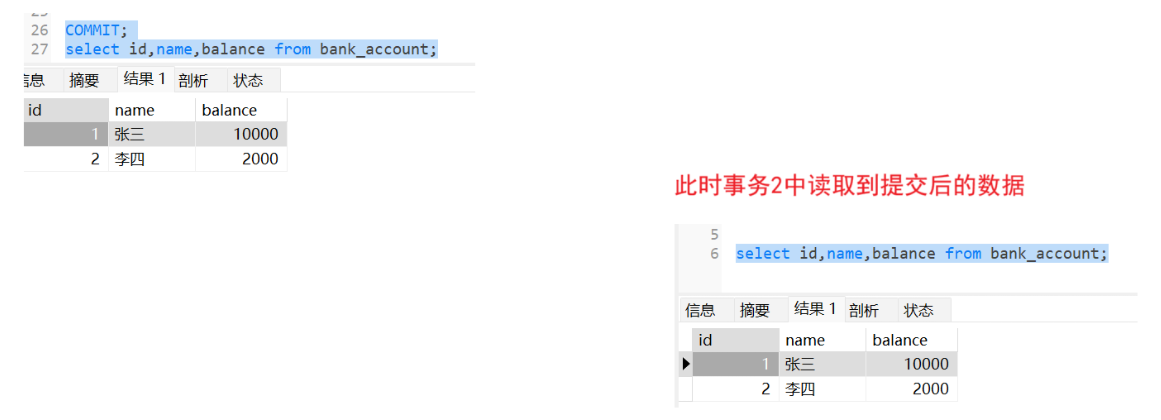
此时这里读取到的数据就会是事务提交之后的数据

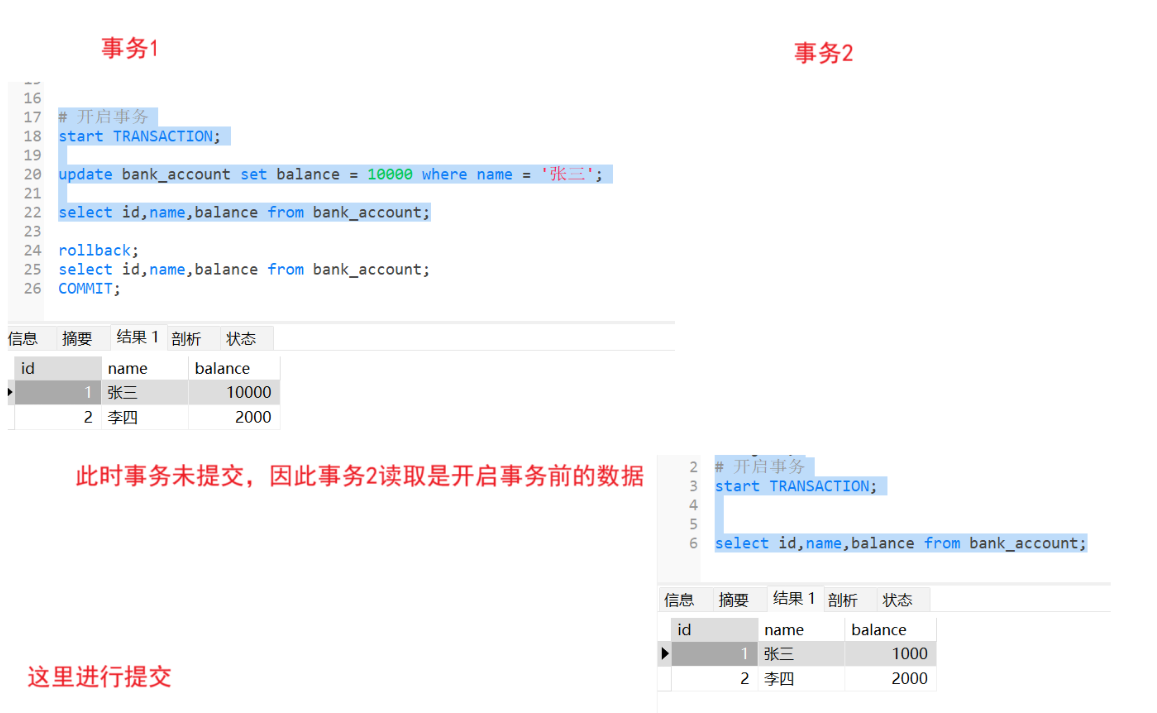
不可以重复读 :这样解决了"脏读 "问题,但是有不可以重复读 问题,此时事务1进行了修改某个数据,但是未提交,事务2此时读取数据是开启事务前的,但是如果事务1提交了这个事务,此时事务2中读取到这条数据又是修改后的数据,此时一个事务2中读取一条数据记录,但是读取的结果却不一样
此时这个问题就需要不可重复读来解决这个问题
REPEATABLE READ
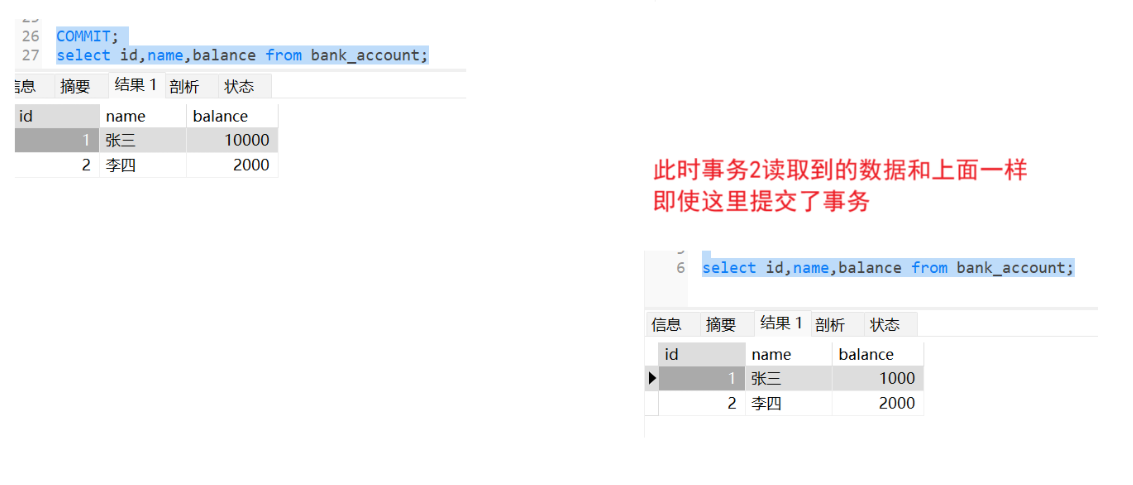
幻读问题 :一个事务内读取到的结果集不同
因为这里同一个事务读取到的结果集是相同的,因此当事务1提交了一个事务 ,事务2进行读取整个数据 ,此时事务2中都是这个数据,但是如果此时事务3对其这个数据进行插入一条数据 ,但是此时无法得到这个新插入数据导致结果集不同 幻读问题


SERIALIZABLE
根本上解决幻读问题,一个事务执行完,才可以执行下一个事务
上面这样,只有事务2提交,此时事务3才可以执行,事务2中不存在幻读问题了

此时事务3就会超时