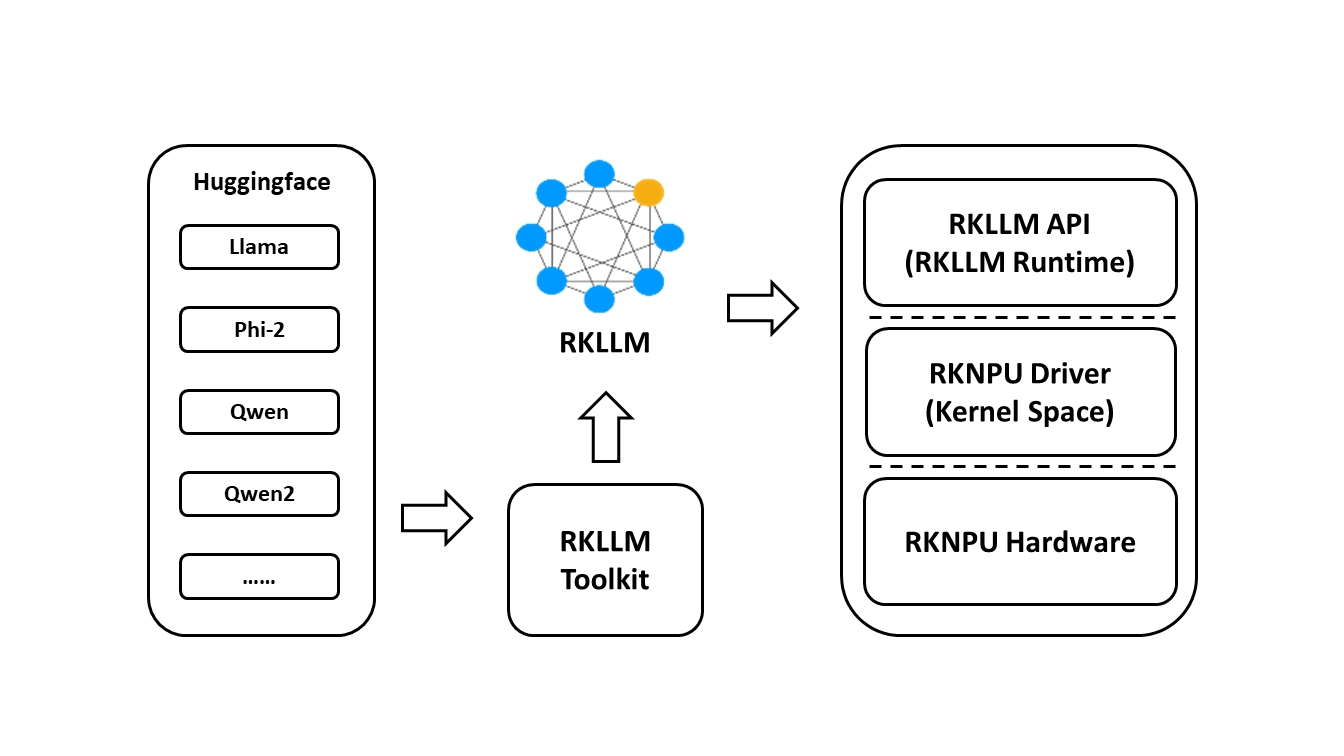
RKLLM
写在前面:建议去阅读官方提供的RKLLM doc,本文基于官方的RKLLM doc制作而成(没有将flask相关内容添加进来),仅仅添加了完整流程的执行过程截图和在做这以流程过程中遇到的问题
RKLLM可以帮助用户快速将人工智能模型部署到Rockchip芯片上。
仓库:https://github.com/airockchip/rknn-llm
RKLLM 工具链介绍
RKLLM-Toolkit 功能介绍
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件,目前实python实现。通过该工具提供的 Python 接口可以便捷地完成以下功能:
- 模型转换:支持将 Hugging Face 格式的大语言模型(Large Language Model, LLM)转换为RKLLM 模型,目前支持的模型包括 LLaMA, Qwen, Qwen2, Phi-2, Phi-3, ChatGLM3, Gemma,InternLM2 和 MiniCPM,转换后的 RKLLM 模型能够在 Rockchip NPU 平台上加载使用。
- 量化功能:支持将浮点模型量化为定点模型,目前支持的量化类型包括 w4a16 和 w8a8。
RKLLM Runtime 功能介绍
RKLLM Runtime 主 要 负 责 加 载 RKLLM-Toolkit 转 换 得 到 的 RKLLM 模 型 , 并 在RK3576/RK3588 板端通过调用 NPU 驱动在 Rockchip NPU 上实现 RKLLM 模型的推理,目前实C++实现。在推理RKLLM 模型时,用户可以自行定义 RKLLM 模型的推理参数设置,定义不同的文本生成方式,并通过预先定义的回调函数不断获得模型的推理结果。
RKLLM 整体开发流程介绍
RKLLM 的整体开发步骤主要分为 2 个部分:模型转换和板端部署运行。
- 模型转换是使用RKLLM-Toolkit将Hugging Face格式的大语言模型将会被转换为RKLLM格式。
- 板端部署运行是调用RKLLM Runtime库加载RKLLM模型到Rockchip NPU平台,然后进行推理等操作。
用户需要首先在PC计算机上(一般为Linux)运行RKLLM-Toolkit工具,将训练后的模型转换为RKLLM格式模型,然后在嵌入式开发板上使用RKLLM C API进行推理。
RKLLM Toolkit - 模型转换
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件,通过该 工具提供的接口可以便捷地完成模型转换和模型量化。使用RKLLM Toolkit一般在PC计算机上完成(一般为PC Ubuntu);
在模型转换这一阶段,用户提供的 Hugging Face 格式的大语言模型将会被转换为 RKLLM 格式,以便在 Rockchip NPU 平台上进行高效的推理。这一步骤包括:
- 获取原始模型:获取 Hugging Face 格式的大语言模型;或是自行训练得到的大语言模型,要求模型保存的结构与 Hugging Face 平台上的模型结构一致。
- 模型加载:通过 rkllm.load_huggingface()函数加载原始模型。
- 模型量化配置:通过 rkllm.build() 函数构建 RKLLM 模型,在构建过程中可选择是否进行模型量化来提高模型部署在硬件上的性能,以及选择不同的优化等级和量化类型。
- 模型导出:通过 rkllm.export_rkllm() 函数将 RKLLM 模型导出为一个.rkllm 格式文件,用于后续的部署。
RKLLM Toolkit安装
拉取RKLLM源码以及目录文件说明:
sh
# 拉取源码
git clone https://github.com/airockchip/rknn-llm.git使用conda创建一个RKLLM环境:
sh
# 创建RKLLM_Toolkit环境
conda create -n RKLLM python=3.8 -y
# 激活环境
conda activate RKLLM
# 切换到rkllm-toolkit目录
cd rknn-llm/rkllm-toolkit/
# 安装rkllm_toolkit(文件请根据具体版本修改),会自动下载RKLLM-Toolkit工具所需要的相关依赖包。
pip install packages/rkllm_toolkit-1.0.1-cp38-cp38-linux_x86_64.whlRKLLM-Toolkit测试
目前支持的模型有TinyLLAMA 1.1B、Qwen 1.8B、Qwen2 0.5B、Phi-2 2.7B、Phi-3 3.8B、 ChatGLM3 6B、Gemma 2B、InternLM2 1.8B、MiniCPM 2B,最新支持情况请查看 rknn-llm。这里以Qwen1.5-0.5B-Chat为例,先去huggingface下载Qwen1.5-0.5B-Chat下载到rknn-llm/rkllm-toolkit/examples/huggingface目录下面,获取的方法参考
sh
# 切换到前面拉取仓库的rknn-llm/rkllm-toolkit/example目录
cd rknn-llm/rkllm-toolkit/examples/huggingface- 修改代码中的modelpath路径(必须要修改)
- 修改模型导出名称等等
test.py代码如下所示:
python
from rkllm.api import RKLLM
# 模型路径
modelpath = './Qwen-1_8B-Chat'
# 初始化RKLLM对象
llm = RKLLM()
# 模型加载
ret = llm.load_huggingface(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)
# 模型的量化构建
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8', target_platform='rk3588')
if ret != 0:
print('Build model failed!')
exit(ret)
# 导出rkllm模型
ret = llm.export_rkllm("./qwen.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)执行:
sh
python test.py
最终就会在当前目录下生成一个qwen.rkllm模型文件

模型转换代码解析
RKLLM 初始化
在模型转换时需要先初始化 RKLLM 对象,这是整个工作流的第一步。在代码中可以使用 RKLLM()构造函数来初始化 RKLLM 对象:
python
# 初始化RKLLM对象
rkllm = RKLLM()模型加载
在 RKLLM 初始化完成后,用户需要调用 rkllm.load_huggingface()函数来传入模型的具体路径,RKLLM-Toolkit 即可根据对应路径顺利加载 Hugging Face 格式的大语言模型,从而顺利完成后续的转换、量化操作:
python
# 模型加载
ret = llm.load_huggingface(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)load_huggingface函数的接口说明:
参数
- model:存放 LLM 模型文件的文件夹路径;
返回值
- ret: 0 表示模型加载正常, -1 表示模型加载失败;
RKLLM 模型的量化构建
用户在通过 rkllm.load_huggingface()函数完成原始模型的加载后,下一步就是通过 rkllm.build()函数实现对 RKLLM 模型的构建。构建模型时,用户可以选择是否进行量化,量化有助于减小模型的大小和提高在 Rockchip NPU 上的推理性能。
python
# 模型的量化构建
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8', target_platform='rk3588')
if ret != 0:
print('Build model failed!')
exit(ret)rkllm.build()函数说明:
参数:
- do_quantization: 该参数控制是否对模型进行量化操作,建议设置为 True进行量化;
- optimization_level: 该参数用于设置是否进行量化精度优化,可选择的设置为{0, 1},0 表示不做任何优化,1 表示进行精度优化,精度优化有可能会造成模型推理性能下降;
- quantized_dtype: 该参数用于设置量化的具体类型,目前支持的量化类型包括"w4a16"和"w8a8","w4a16"表示对权重进行 4bit 量化而对激活值不进行量
化;"w8a8"表示对权重和激活值均进行 8bit 量化;目前 rk3576 平台支持"w4a16"和"w8a8"两种量化类型,rk3588 仅支持"w8a8"量化类型; - target_platform: 模型运行的硬件平台, 可选择的设置包括"rk3576"或"rk3588";
返回值:
- 0 表示模型转换、量化正常;
- -1 表示模型转换失败;
导出 RKLLM 模型
用户在通过 rkllm.build()函数构建了 RKLLM 模型后,可以通过 rkllm.export_rkllm()函数将RKNN 模型保存为一个.rkllm 文件,以便后续模型的部署。
python
# 导出rkllm模型
ret = llm.export_rkllm("./qwen.rkllm") # export_path = "./qwen.rkllm"
if ret != 0:
print('Export model failed!')
exit(ret)rkllm.export_rkllm()函数说明:
参数:
- export_path: 导出 RKLLM 模型文件的保存路径;
返回值:
- 0 表示模型成功导出保存;
- -1 表示模型导出失败;
完整代码
模型转换的整体代码如下:
sh
from rkllm.api import RKLLM
modelpath = './Qwen'
# 初始化RKLLM对象
llm = RKLLM()
# 模型加载
ret = llm.load_huggingface(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)
# 模型的量化构建
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8', target_platform='rk3588')
if ret != 0:
print('Build model failed!')
exit(ret)
# 导出rkllm模型
ret = llm.export_rkllm("./qwen.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)注意:如果你在模型转换的过程中出现下面的问题
sh
Error while deserializing header: HeaderTooLarge
Load model failed!说明你的modelpath指定的模型有问题,要么损坏,要么没下载完全;
参考:https://github.com/airockchip/rknn-llm/issues/15
RKLLM Runtime - 板端部署
交叉编译
这一过程在PC计算机上去完成
解压编译器
使用tat提取XZ压缩版本到家目录下面:
sh
$ tar -xJf gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu.tar.xz -C ~构建
确保"build-linux.sh"脚本中的"GCC_COMPILER_PATH"选项配置正确:
sh
#workspace rknn-llm/rkllm-runtime/examples/rkllm_api_demo
GCC_COMPILER_PATH=/path/to/your/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu要执行,请运行:
bash
#workspace rknn-llm/rkllm-runtime/examples/rkllm_api_demo
bash build-linux.sh
交叉编译完成后就会在rknn-llm/rkllm-runtime/examples/rkllm_api_demo目录下生成一个build_linux_aarch64_Release在其下面就是llm_demo 可执行文件

传输
生成完成后需要将llm_demo 可执行文件 和 rknn-llm\rkllm-runtime\runtime\Linux\librkllm_api\aarch64下面的librkllmrt.so库文件传输到嵌入式设备上;
这里推荐两种方式:
连扳adb(推荐)
将编译后的"llm_demo"文件和"librkllmrt.so"文件推送到设备:
bash
# 确保安装了 adb 连扳推理工具 如果未安装使用:sudo apt-get install adb -y
# 注意:要去到llm_demo 和 librkllmrt.so所在的目录下去执行
adb push llm_demo ~ # 将llm_demo使用ssh传输到开发板的家目录
adb push librkllmrt.so ~SSH scp
连扳推理不能用的时候,
sh
# zip -q -r llm.zip * 压缩(可选)
# 注意:要去到llm_demo 和 librkllmrt.so所在的目录下去执行
scp llm_demo arm64@192.168.6.17:~ # 将llm_demo使用ssh传输到开发板的家目录
scp librkllmrt.so arm64@192.168.6.17:~ 运行前准备
内核驱动更新
这个是运行前的内存准备,但是我发现0.9.3版本的驱动 依然可以正常运行,用户手册说明需要v0.9.6版本以上
sh
# 板端执行以下命令,查询NPU内核版本
cat /sys/kernel/debug/rknpu/version驱动更新请另寻资料
我没有更新驱动,在运行的时候会提示
sh
rkllm-runtime version: 1.0.1, rknpu driver version: 0.9.3, platform: RK3588
Warning: Your rknpu driver version is too low, please upgrade to 0.9.6.动态库设置
将运行的动态库拷贝到目标板的/usr/lib/中,这样可执行文件可以直接找到动态库,不需要设置环境变量
如果不拷贝到/usr/lib/下面的话,需要设置export
bash
cd librkllmrt.so所在的目录
export LD_LIBRARY_PATH=./libRKLLM模型推理运行
运行的命令如下所示:
sh
# 修改最大可打开文件的数量 必须加否则会出现 can not create share memory Segmentation fault
ulimit -HSn 10240
# 进入到llm_demo所在的目录下执行
./llm_demo /path/qwen.rkllm
# 或者运行绑定cpu运行测试
# taskset f0 ./llm_demo /path/qwen.rkllm
注意:测试发现目前Qwen的0.5B出现了乱回答 乱说的问题,而Qwen的8B则正使用正常
板端推理的实现流程
RKLLM Runtime为Rockchip NPU平台提供了C/C++编程接口,帮助用户部署RKLLM模型,加速LLM应用程序的实现。
在板端部署推理的这个阶段涵盖了模型的实际部署和运行。它通常包括以下步骤:
- 模型初始化:加载 RKLLM 模型到 Rockchip NPU 平台,进行相应的模型参数设置来定义所需的文本生成方式,并提前定义用于接受实时推理结果的回调函数,进行推理前准备。
- 模型推理:执行推理操作,将输入数据传递给模型并运行模型推理,用户可以通过预先定义的回调函数不断获取推理结果。
- 模型释放:在完成推理流程后,释放模型资源,以便其他任务继续使用 NPU 的计算资源。
板端推理的代码解析
使用 C++构建代码,在板端实现对 RKLLM 模型的推理,获取推理结果。RKLLM 板端推理实现的调用流程如下:
- 定义回调函数 callback();
- 定义 RKLLM 模型参数结构体 RKLLMParam;
- rkllm_init()初始化 RKLLM 模型;
- rkllm_run()进行模型推理;
- 通过回调函数 callback()对模型实时传回的推理结果进行处理;
- rkllm_destroy()销毁 RKLLM 模型并释放资源;
回调函数callback()
回调函数是用于接收模型实时输出的结果。在初始化 RKLLM 时回调函数会被绑定,在模型推理过程中不断将结果输出至回调函数中,并且每次回调只返回一个 token。示例代码如下,该回调函数将输出结果实时地打印输出到终端中:
cpp
void callback(RKLLMResult *result, void *userdata, LLMCallState state)
{
if (state == LLM_RUN_FINISH)
{
printf("\n");
}
else if (state == LLM_RUN_ERROR)
{
printf("\\run error\n");
}
else
{
printf("%s", result->text); // 打印答案
}
}这里要特别强调 RKLLMResult *result 和 LLMCallState state
-
LLMCallState是一个状态标志,用于表示当前 RKLLM 的运行状态,用户在回调函数的设计过程中,可以根据 LLMCallState 的不同状态设置不同的后处理行为;LLMCallState 有三个不同状态设置:
-
0, LLM_RUN_NORMAL, 表示 RKLLM 模型当前正在推理中;
-
1, LLM_RUN_FINISH, 表示 RKLLM 模型已完成当前输入的全部推理;
-
2, LLM_RUN_ERROR, 表示 RKLLM 模型推理出现错误;
-
这个三个不同的状态设置在上面的callback函数中分别对应了三个情况,当状态为LLM_RUN_NORMAL时,表示 RKLLM 模型当前正在推理中,此时打印换行;当状态为LLM_RUN_ERROR时,表示 RKLLM 模型推理出现错误,此时打印 \ \ run error 并换行;当状态为LLM_RUN_FINISH时,表示 RKLLM 模型已完成当前输入的全部推理,此时打印模型的根据用户的输入得到的答案;
- RKLLMResult 是返回值结构体,用于返回当前推理生成结果。其有三个返回值0, 1, 2
- 0, text, 表示当前推理生成的文本内容; 上面代码的result->text 就是大模型推理生成的文本内容
- 1, tokens, 表示当前推理生成的 token 位置上概率最大的前 top 个 token,其中每个token 包含 id 和 logprob 两个属性;
- 2, num, 表示 tokens 中的数量;
参数结构体RKLLMParam定义
结构体 RKLLMParam 用于描述、定义 RKLLM 的详细信息以及各项参数信息
在实际的代码构建中,RKLLMParam 需要调用 rkllm_createDefaultParam()函数来初始化定义,并根据需求设置相应的模型参数。示例代码如下:
cpp
//设置参数
RKLLMParam param = rkllm_createDefaultParam();
param.model_path = rkllm_model.c_str(); // 指定llm模型路径
param.num_npu_core = 2; // 设置NPU的核 rk3588有三个npu的核 这里可以设置为1 - 3
param.top_k = 1; // 文本生成方法,从前k个最有可能的Token中选择下一个Token 这里设置为1即选择一个最有可能的
param.max_new_tokens = 256;
param.max_context_len = 512;
param.logprobs = false;
param.top_logprobs = 5;
param.use_gpu = false;RKLLMParam的参数如下:
- const char* model_path: 模型文件的存放路径;
- int32_t num_npu_core: 模型推理时使用的 NPU 核心数量,若芯片平台为"rk3576"可配置的范围为1, 2,若为"rk3588"可配置的范围则为1, 3;
- bool use_gpu: 是否使用 GPU 进行 prefill 加速,该选项默认为 false;
- int32_t max_context_len: 设置 prompt 的上下文大小;
- int32_t max_new_tokens: 用于设置模型推理时生成 token 的数量上限;
- int32_t top_k: top-k 采样是一种文本生成方法,它仅从模型预测的概率最高的 k 个token 中选择下一个 token。这种方法有助于减少生成低概率或无意义 token 的风险。更高的 top-k 值(如 100)将考虑更多的 token 选择,导致文本更加多样化;而更低的值(如 10)将聚焦于最可能的 token,生成更加保守的文本。默认值为 40;
- float top_p: top-p 采样,也被称为核心采样,是另一种文本生成方法,从累计概率至少为 p 的一组 token 中选择下一个 token。这种方法通过考虑 token 的概率和采样的 token 数量在多样性和质量之间提供平衡。更高的 top-p 值(如 0.95)使得生成的文本更加多样化;而更低的值(如 0.5)将生成更加集中和保守的文本。默认值为 0.9;
- float temperature: 控制生成文本随机性的超参数,它通过调整模型输出 token 的概率分布来发挥作用;更高的温度(如 1.5)会使输出更加随机和创造性,当温度较高时,模型在选择下一个 token 时会考虑更多可能性较低的选项,从而产生更多样和意想不到的输出;更低的温度(例 0.5)会使输出更加集中、保守,较低的温度意味着模型在生成文本时更倾向于选择概率高的 token,从而导致更一致、更可预测的输出;温度为 0 的极端情况下,模型总是选择最有可能的下一个 token,这会导致每次运行时输出完全相同;为了确保随机性和确定性之间的平衡,使输出既不过于单一和可预测,也不过于随机和杂乱,默认值为 0.8;
- float repeat_penalty: 控制生成文本中 token 序列重复的情况,帮助防止模型生成重复或单调的文本。更高的值(例如 1.5)将更强烈地惩罚重复,而较低的值(例如0.9)则更为宽容。默认值为 1.1;
- float frequency_penalty: 单词/短语重复度惩罚因子,减少总体上使用频率较高的单词/短语的概率,增加使用频率较低的单词/短语的可能性,这可能会使生成的文本更加多样化,但也可能导致生成的文本难以理解或不符合预期。设置范围为-2.0,2.0,默认为 0;
- int32_t mirostat: 在文本生成过程中主动维持生成文本的质量在期望的范围内的算法,它旨在在连贯性和多样性之间找到平衡,避免因过度重复(无聊陷阱)或不连贯(混乱陷阱)导致的低质量输出;取值空间为{0, 1, 2}, 0 表示不启动该算法,1表示使用 mirostat 算法,2 则表示使用 mirostat2.0 算法;
- float mirostat_tau: 选项设置 mirostat 的目标熵,代表生成文本的期望困惑度值。调整目标熵可以让你控制生成文本中连贯性与多样性的平衡。较低的值将导致文本更加集中和连贯,而较高的值将导致文本更加多样化,可能连贯性较差。默认值是5.0;
- float mirostat_eta: 选项设置 mirostat 的学习率,学习率影响算法对生成文本反馈的响应速度。较低的学习率将导致调整速度较慢,而较高的学习率将使算法更加灵敏。默认值是 0.1;
- bool logprobs: 选项设置是否返回输出 token 的对数概率值和 token_id;
- int32_t top_logporbs: 选项设置返回概率最高的 token 数量,每个 token 附带对应的对数概率和 token_id,使用此参数时 logprobs 必须设置为 True;
初始化模型
在进行模型的初始化之前,需要提前定义 LLMHandle 句柄,该句柄用于模型的初始化、推理和资源释放过程。注意,只有统一这 3 个流程中的 LLMHandle 句柄对象,才能够正确完成模型的推理流程。
在模型推理前,用户需要通过 rkllm_init()函数完成模型的初始化,示例代码如下:
cpp
rkllm_init(&llmHandle, param, callback); // 初始化大模型 并注册callback反馈函数
printf("rkllm init success\n");rkllm_init的各项参数为:
- LLMHandle* handle: 将模型注册到相应句柄中,用于后续推理、释放调用;
- RKLLMParam param: 模 型 定 义 的 参 数 结 构 体 , 详 见 3.2.2 参 数 结 构 体RKLLMParam 定义;
- LLMResultCallback callback: 用于接受处理模型实时输出的回调函数,详见 3.2.1回调函数定义;
返回值为:
- 0 表示初始化流程正常;
- -1 表示初始化失败;
模型推理
用户在完成 RKLLM 模型的初始化流程后,即可通过 rkllm_run()函数进行模型推理,并可以通过初始化时预先定义的回调函数对实时推理结果进行处理;rkllm_run()使用示例如下:
cpp
// 提前定义 prompt 前后的文本预设值
#define PROMPT_TEXT_PREFIX "<|im_start|>system You are a helpful
assistant. <|im_end|> <|im_start|>user"
#define PROMPT_TEXT_POSTFIX "<|im_end|><|im_start|>assistant"
// 定义输入的 prompt 并完成前后 prompt 的拼接
string input_str = "把这句话翻译成英文:RK3588 是新一代高端处理器,具有高算力、低功耗、超强多媒体、丰富数据接口等特点";
input_str = PROMPT_TEXT_PREFIX + input_str + PROMPT_TEXT_POSTFIX;
// 调用模型推理接口,其中 llmHandle 为模型初始化时传入的句柄
rkllm_run(llmHandle, input_str.c_str(), NULL);在使用的时候对于prompt的前后文设置也可以不去添加,对于某些场景化的使用,例如:具身智能机械臂,加prompt可以帮助大模型更好的进行身份代入
rkllm_run的餐宿:
- LLMHandle handle: 模型初始化注册的目标句柄,可见 3.2.3 初始化模型;
- const char* prompt: 模型推理的输入 prompt,即用户的"问题",注意需要在问题前后加上预设的 prompt,保证推理正确性,详见示例代码;
- void* userdata: 用户自定义的函数指针,默认设置为 NULL 即可;
返回值:
- 0 表示模型推理正常运行;
- -1 表示调用模型推理失败;
模型中断
在进行模型推理时,用户可以调用 rkllm_abort()函数中断推理进程,示例代码如下:
cpp
// 其中 llmHandle 为模型初始化时传入的句柄
rkllm_abort(llmHandle);参数:
- LLMHandle handle: 模型初始化注册的目标句柄,可见 3.2.3 初始化模型;
返回值:
- 0 表示 RKLLM 模型中断成功;
- -1 表示模型中断失败;
释放模型资源
在完成全部的模型推理调用后,用户需要调用 rkllm_destroy()函数进行 RKLLM 模型的销毁,并释放所申请的 CPU、NPU 计算资源,以供其他进程、模型的调用。示例代码如下:
cpp
// 其中 llmHandle 为模型初始化时传入的句柄
rkllm_destroy(llmHandle);参数:
- LLMHandle handle: 模型初始化注册的目标句柄,可见 3.2.3 初始化模型;
返回值:
- 0 表示 RKLLM 模型正常销毁、释放;
- -1 表示模型释放失败;
完整代码
完整的板端推理代码:
代码为rknn-llm\rkllm-runtime\examples\rkllm_api_demo\src\main.cpp
cpp
#include <string.h>
#include <unistd.h>
#include <string>
#include "rkllm.h"
#include <fstream>
#include <iostream>
#include <csignal>
#include <vector>
#define PROMPT_TEXT_PREFIX "<|im_start|>system You are a helpful assistant. <|im_end|> <|im_start|>user"
#define PROMPT_TEXT_POSTFIX "<|im_end|><|im_start|>assistant"
using namespace std;
LLMHandle llmHandle = nullptr;
// exit_handler函数 当我们按ctrl + c的时候便会 "打印程序即将退出" 后面释放大模型rkllm的资源
void exit_handler(int signal)
{
if (llmHandle != nullptr)
{
{
cout << "程序即将退出" << endl;
LLMHandle _tmp = llmHandle;
llmHandle = nullptr;
rkllm_destroy(_tmp);
}
exit(signal);
}
}
void callback(RKLLMResult *result, void *userdata, LLMCallState state)
{
if (state == LLM_RUN_FINISH)
{
printf("\n");
}
else if (state == LLM_RUN_ERROR)
{
printf("\\run error\n");
}
else
{
printf("%s", result->text); // 正确打印答案
}
}
int main(int argc, char **argv)
{
// 在使用时候的命令./llm_demo qwen.rkllm
if (argc != 2)
{
printf("Usage:%s [rkllm_model_path]\n", argv[0]);
return -1;
}
signal(SIGINT, exit_handler); // 注册中断信号量 当我们在Linux上运行demo的时候 按ctrl+c便会执行exit_handler这个函数的内容
string rkllm_model(argv[1]);
printf("rkllm init start\n");
//设置参数及初始化
RKLLMParam param = rkllm_createDefaultParam();
param.model_path = rkllm_model.c_str(); // 指定llm模型路径
param.num_npu_core = 2; // 设置NPU的核 rk3588有三个npu的核 这里可以设置为1 - 3
param.top_k = 1; // 文本生成方法,从前k个最有可能的Token中选择下一个Token 这里设置为1即选择一个最有可能的
param.max_new_tokens = 256;
param.max_context_len = 512;
param.logprobs = false;
param.top_logprobs = 5;
param.use_gpu = false;
rkllm_init(&llmHandle, param, callback); // 初始化大模型 并注册callback反馈函数
printf("rkllm init success\n");
vector<string> pre_input;
pre_input.push_back("把下面的现代文翻译成文言文:到了春风和煦,阳光明媚的时候,湖面平静,没有惊涛骇浪,天色湖光相连,一片碧绿,广阔无际;沙洲上的鸥鸟,时而飞翔,时而停歇,美丽的鱼游来游去,岸上与小洲上的花草,青翠欲滴。");
pre_input.push_back("以咏梅为题目,帮我写一首古诗,要求包含梅花、白雪等元素。");
pre_input.push_back("上联: 江边惯看千帆过");
pre_input.push_back("把这句话翻译成中文:Knowledge can be acquired from many sources. These include books, teachers and practical experience, and each has its own advantages. The knowledge we gain from books and formal education enables us to learn about things that we have no opportunity to experience in daily life. We can also develop our analytical skills and learn how to view and interpret the world around us in different ways. Furthermore, we can learn from the past by reading books. In this way, we won't repeat the mistakes of others and can build on their achievements.");
pre_input.push_back("把这句话翻译成英文:RK3588是新一代高端处理器,具有高算力、低功耗、超强多媒体、丰富数据接口等特点");
cout << "\n**********************可输入以下问题对应序号获取回答/或自定义输入********************\n"
<< endl;
for (int i = 0; i < (int)pre_input.size(); i++)
{
cout << "[" << i << "] " << pre_input[i] << endl;
}
cout << "\n*************************************************************************\n"
<< endl;
string text;
while (true)
{
std::string input_str;
printf("\n");
printf("user: ");
std::getline(std::cin, input_str); // input_str为用户输入的内容
if (input_str == "exit")
{
break;
}
for (int i = 0; i < (int)pre_input.size(); i++)
{
if (input_str == to_string(i))
{
input_str = pre_input[i];
cout << input_str << endl;
}
}
// string text = PROMPT_TEXT_PREFIX + input_str + PROMPT_TEXT_POSTFIX;
string text = input_str;
printf("robot: ");
rkllm_run(llmHandle, text.c_str(), NULL); // 使用大模型进行推理
}
rkllm_destroy(llmHandle); // 释放模型资源
return 0;
}