Seaborn数据集探索与图表绘制实践
学习目标
通过本课程,你将学习如何使用Seaborn库中的内置数据集,了解如何加载这些数据集,并掌握使用这些数据集绘制图表的基本方法。此外,你还将学习如何导入外部数据集,并在Seaborn中使用它们进行数据可视化。
相关知识点
- Seaborn数据集探索与图表绘制实践
学习内容
1 Seaborn数据集探索与图表绘制实践
1.1 依赖库安装
python
%pip install seaborn
%pip install matplotlib1.2 Seaborn内置数据集的加载与使用
Seaborn是一个基于Matplotlib的高级数据可视化库,它提供了许多内置的数据集,这些数据集非常适合用于学习和测试。Seaborn的数据集涵盖了多种类型的数据,包括但不限于时间序列数据、分类数据和多变量数据等。这些数据集不仅有助于理解Seaborn的功能,还能帮助我们快速上手数据可视化。
加载内置数据集
加载Seaborn的内置数据集非常简单,只需要调用seaborn.load_dataset()函数,并传入数据集的名称作为参数。Seaborn中包含的数据集名称可以通过查看官方文档或直接调用seaborn.get_dataset_names()来获取。
python
import seaborn as sns
# 获取所有可用的数据集名称
print(sns.get_dataset_names())
# 加载'tips'数据集
tips = sns.load_dataset('tips')
print(tips.head())这段代码首先导入了Seaborn库,并使用get_dataset_names()函数获取了所有可用的数据集名称。然后,我们选择了'tips'数据集进行加载,并打印了数据集的前几行,以便查看数据的结构。
使用内置数据集
加载数据集后,我们就可以使用Seaborn的各种绘图函数来探索数据。例如,我们可以使用sns.scatterplot()函数来绘制散点图,使用sns.barplot()函数来绘制条形图等。
python
# 绘制'tips'数据集中的散点图
sns.scatterplot(x='total_bill', y='tip', data=tips)
import matplotlib.pyplot as plt
plt.show()
# 绘制'tips'数据集中的条形图
sns.barplot(x='day', y='total_bill', data=tips)
plt.show()在这段代码中,我们首先使用scatterplot()函数绘制了'tips'数据集中'total_bill'和'tip'之间的关系图。接着,使用barplot()函数绘制了不同日子的'total_bill'平均值的条形图。通过这些图表,我们可以直观地看到数据之间的关系。
使用Seaborn绘制基本图表
Seaborn提供了多种绘图函数,每种函数都针对特定类型的数据和图表。了解这些函数的基本用法,可以帮助我们更有效地进行数据可视化。
绘制散点图
散点图是用于显示两个数值变量之间关系的图表。在Seaborn中,可以使用scatterplot()函数来绘制散点图。
python
# 绘制'tips'数据集中的散点图,添加颜色和大小参数
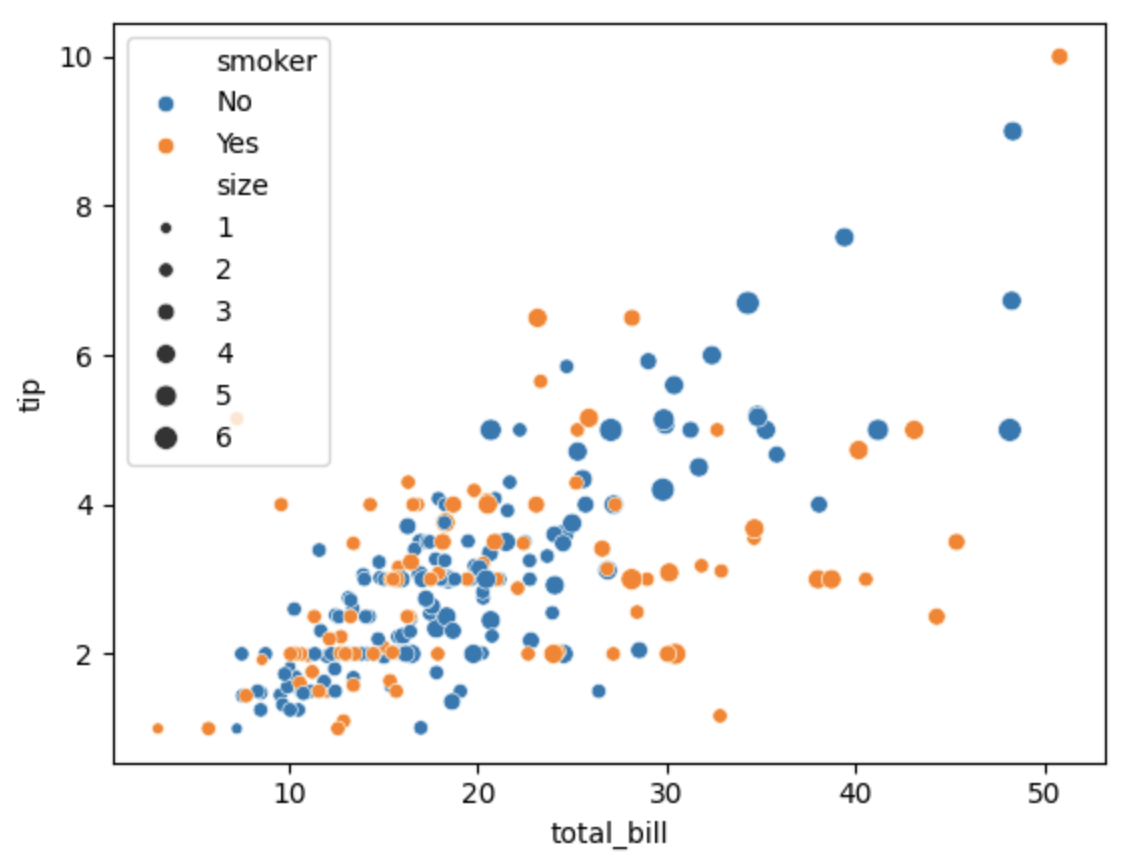
sns.scatterplot(x='total_bill', y='tip', hue='smoker', size='size', data=tips)
plt.show()在这段代码中,我们不仅绘制了'total_bill'和'tip'之间的散点图,还通过hue参数添加了颜色编码,表示是否吸烟,通过size参数调整了点的大小,表示餐桌的人数。这样,图表不仅显示了两个变量之间的关系,还提供了额外的信息。
绘制条形图
条形图用于显示分类数据的分布情况。在Seaborn中,可以使用barplot()函数来绘制条形图。
python
# 绘制'tips'数据集中的条形图,显示不同日子的'total_bill'平均值
sns.barplot(x='day', y='total_bill', data=tips, ci=None)
plt.show()在这段代码中,我们绘制了不同日子的'total_bill'平均值的条形图。通过设置ci=None,我们去除了置信区间,使得图表更加简洁。
1.3 导入外部数据集
虽然Seaborn提供了丰富的内置数据集,但在实际工作中,我们更常用的是自己收集或从其他来源获取的数据。Seaborn支持从CSV、Excel等文件中导入数据。
从CSV文件导入数据
从CSV文件导入数据非常简单,可以使用Pandas库的read_csv()函数。
python
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/d2450e362fd711f0aa39fa163edcddae/tips.csv
python
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 从CSV文件导入数据
data = pd.read_csv('tips.csv')
print(data.head())在这段代码中,我们使用Pandas的read_csv()函数从指定路径读取CSV文件,并将数据加载到一个DataFrame中。然后,我们打印了数据的前几行,以检查数据是否正确加载。
使用外部数据集绘制图表
一旦数据被加载到DataFrame中,我们就可以像使用内置数据集一样使用这些数据来绘制图表。
绘制'tips'数据集中的散点图,添加颜色和大小参数
sns.scatterplot(x='total_bill', y='tip', hue='smoker', size='size', data=data)
plt.show()