在我们的模型库中,经常会发现下载的模型,生成的图片颜色发灰,暗沉:

主要原因就是,我们下载的模型,作者训练时并没有加入VAE色调文件。
为了解决这个问题,我们可以使用 SD 自带额模型融合页面,手动给这个模型添加VAE文件:

单个模型融合
在「模型A」中添加缺少 VAE 文件的模型,并给模型起一个新的名字:
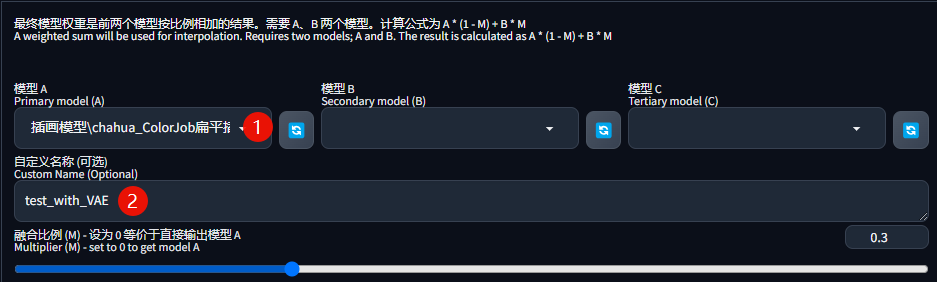
「融合算法」,因为只对一个模型进行融合,选择第一项「原样输出」:
「模型格式」保持默认,对于显存比较小的电脑,勾选☑️「储存半精度模型」(模型融合容量会少一些,但清晰度细节会稍微损失一些):
选择需要嵌入的VAE文件:
其他保持默认,点击「融合」,速度很快,3.7秒就完成融合,融合后的模型文件会直接存放在以下路径中,方便字节调用:

重新回到「文生图」页面,选择融合的模型,锁定种子,重新生成图片:
自定义风格模型融合
使用「darkSushi」2.5D模型生成以下图片:
但我想在它的基础上,融合一些二次元漫画的风格,出图的效果没那么写实。
我们来到「模型融合」页面:
- 在「模型A」与「模型B」中分别选择需要融合的模型
- 调整融合比例
- 「融合算法」选择「加权和」
- 其他的保持不变
完成融合之后,就可以使用得到的模型来生成图片了。
经过以上两个融合的示例,我们可以看到,想要快速得到一个融合的模型非常简单。
但这里也提一个注意事项:
选择融合模型时,一定要选择风格相互匹配的模型进行融合,不然生成出来的图片会比较奇怪
今天先分享到这里~
开启实践: SD绘画 | 为你所做的学习过滤