场景:时不时群里面会有小伙伴咨询使用kettle连接ms sqlserver 数据库,折腾很久浪费时间,今天刚好有时间把这一块梳理下,希望能让大家节省时间提高效率。
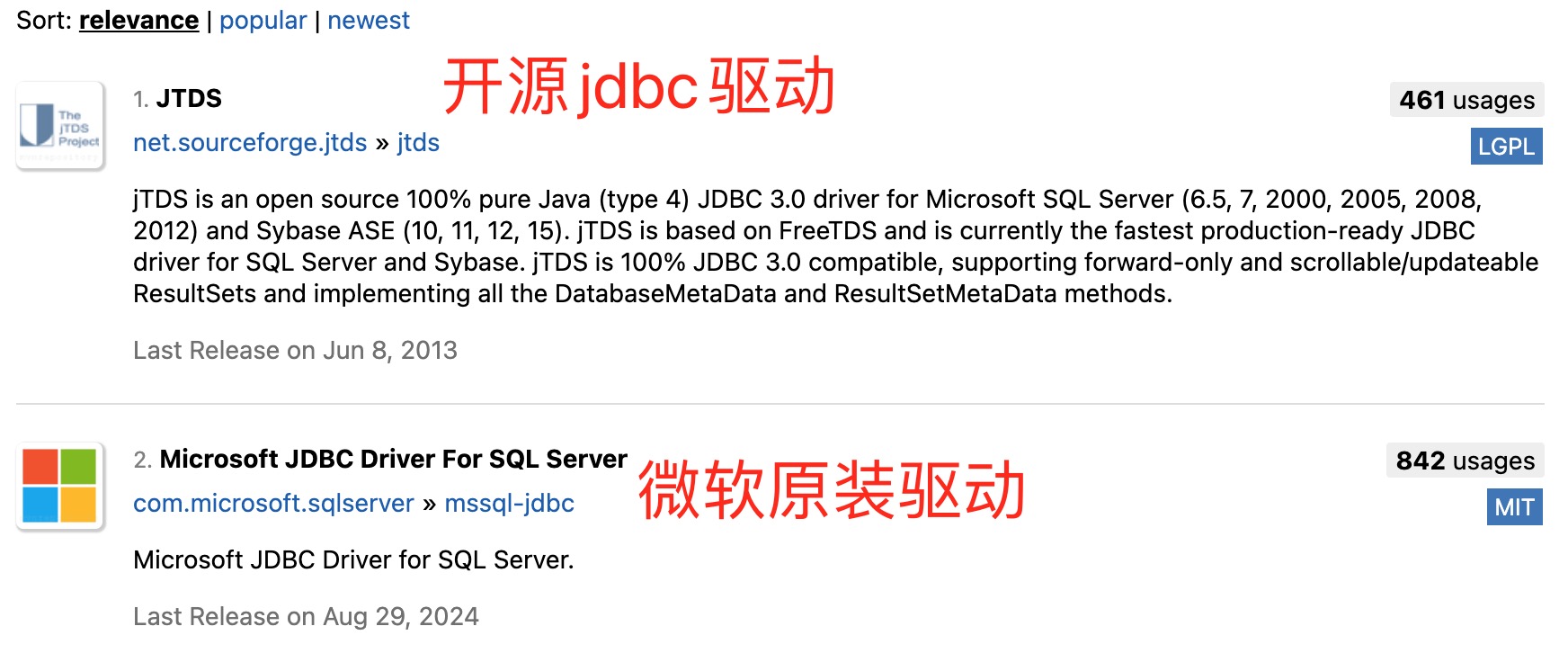
1、首先要知道连接sqlserver 有两种方式,JTDS jdbc驱动和微软的原装驱动,如下图所示:
兼容性:
jTDS: jTDS 兼容旧版本的 SQL Server,支持 ADO.NET 和 JDBC 3.0,所以它能够与较早的 SQL Server 版本(如 6.5、7、2000 等)良好兼容。
mssql-jdbc: mssql-jdbc 驱动程序专为新的 SQL Server 版本(如 2012 及以上)设计,兼容性更好,特别是在遵循最新的 JDBC 规范和 SQL Server 新特性上。
性能
jTDS: 在某些场景下,jTDS 可能会提供更快的性能,特别是在不需要复杂功能时。
mssql-jdbc: 由于是官方驱动,mssql-jdbc 在性能和稳定性上可能更具优势,特别是在高负载和复杂查询中。
特性支持
jTDS: jTDS 对于某些 SQL Server 的新特性可能没有完全支持。它的功能和性能受到 FreeTDS 版本的限制。
mssql-jdbc: mssql-jdbc 支持 SQL Server 的所有新特性,包括最新的身份验证方式、Azure SQL Database 支持、JDBC 4.2 和以上版本的特性等。
建议:选择 jTDS 还是 mssql-jdbc 取决于具体的需求:如果你需要一个开源的、兼容旧版本的驱动,jTDS 可能适合你;但如果你追求性能、兼容性以及最新功能,建议选择 Microsoft 官方的 mssql-jdbc 驱动。
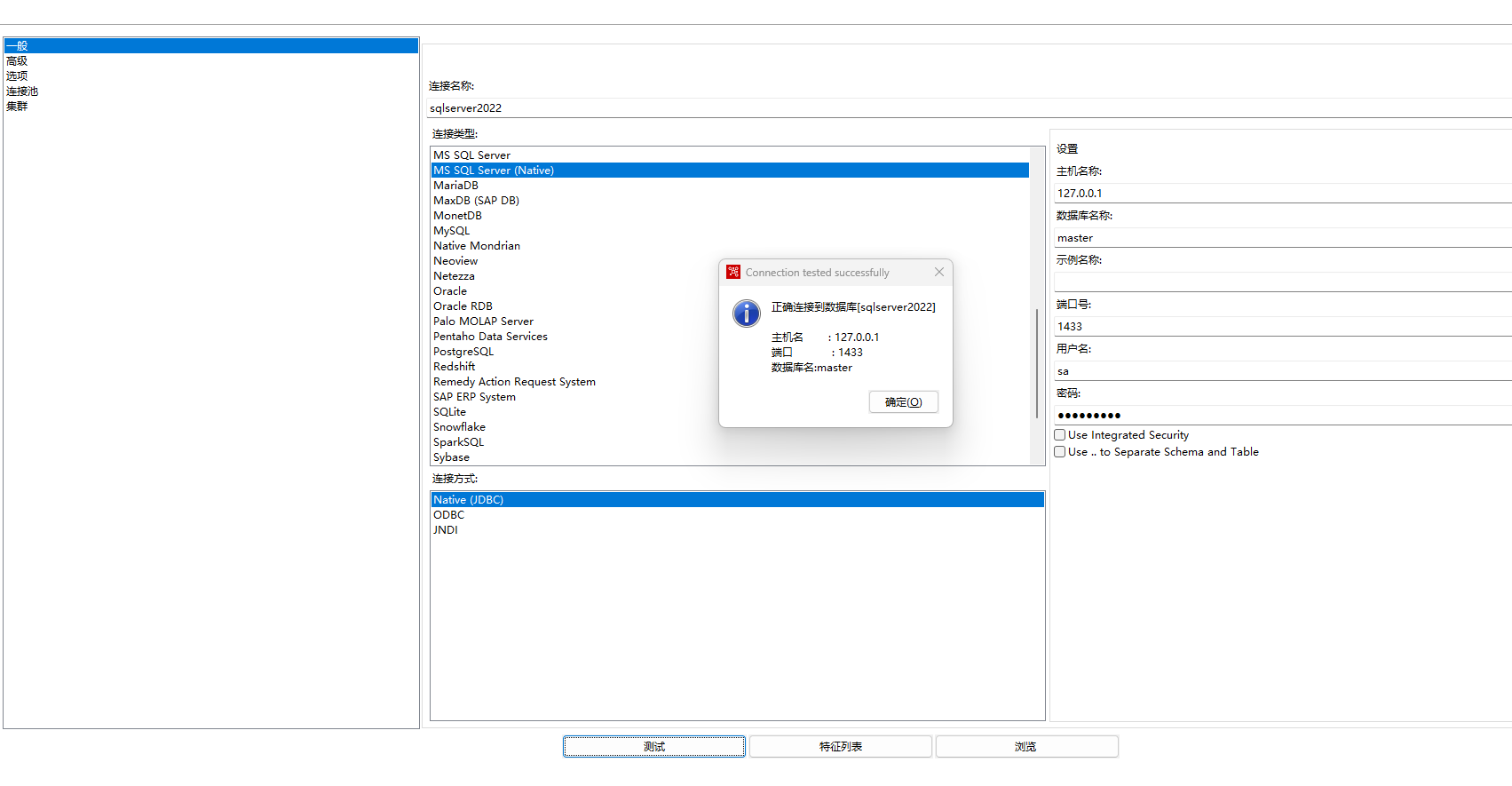
2、MS SQL Server Native 方式连接设置,如下图所示:
将jar文件mssql-jdbc-9.4.0.jre8.jar放到kettle目录下面的lib文件夹下面,然后重启kettle,填写主机名称、数据库名称、端口号、用户名、密码。
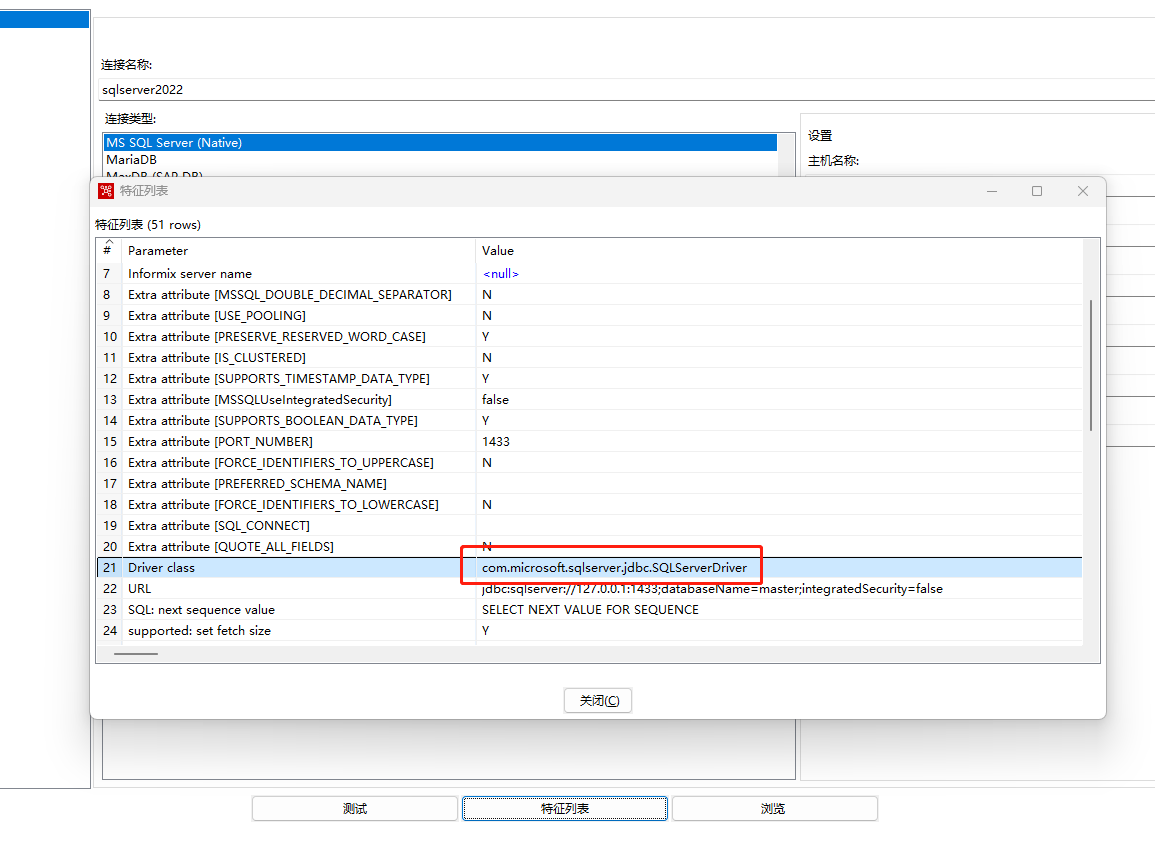
3、点击特征列表按钮可以查看到此数据库连接用到的驱动类,如下图所示:
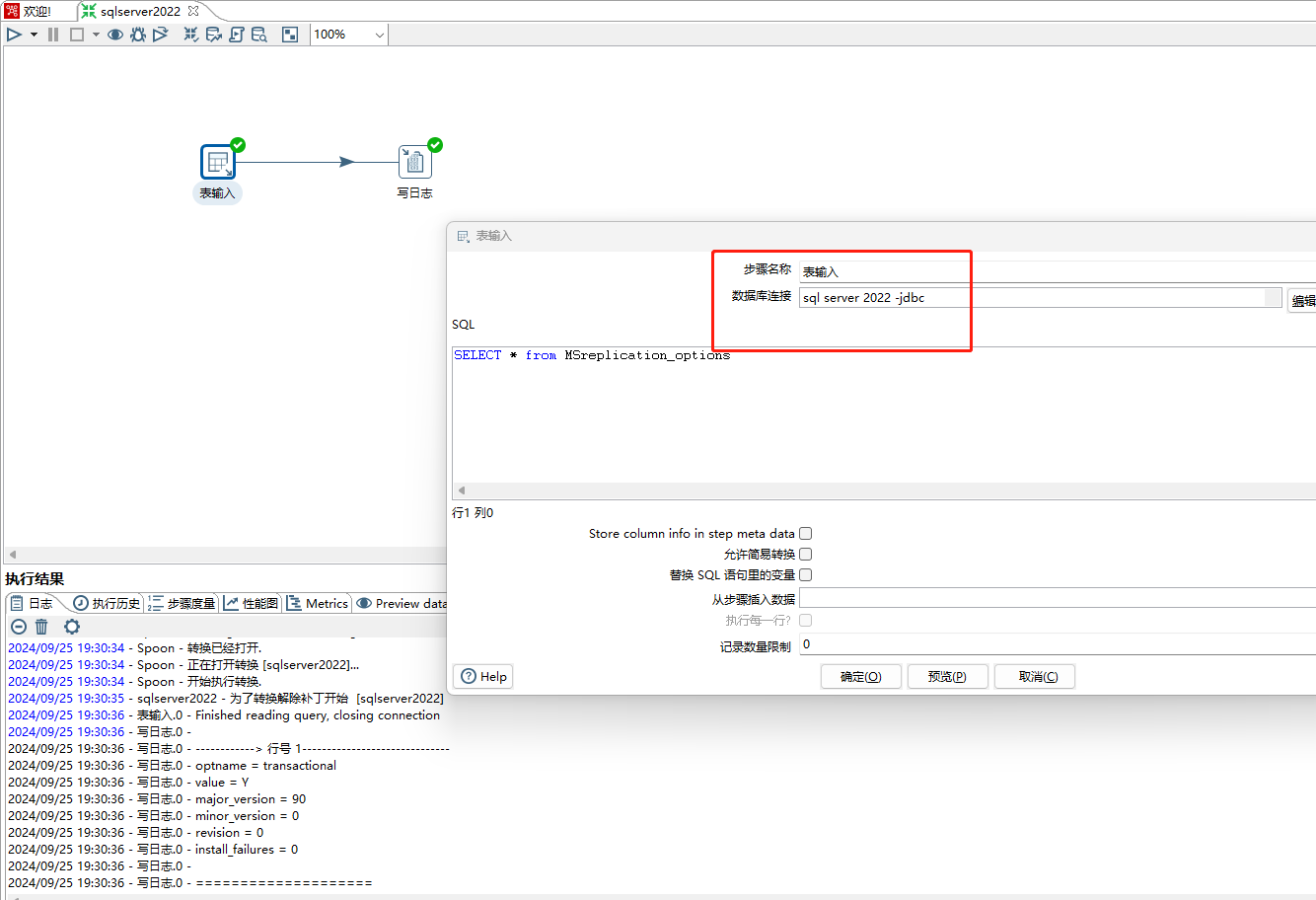
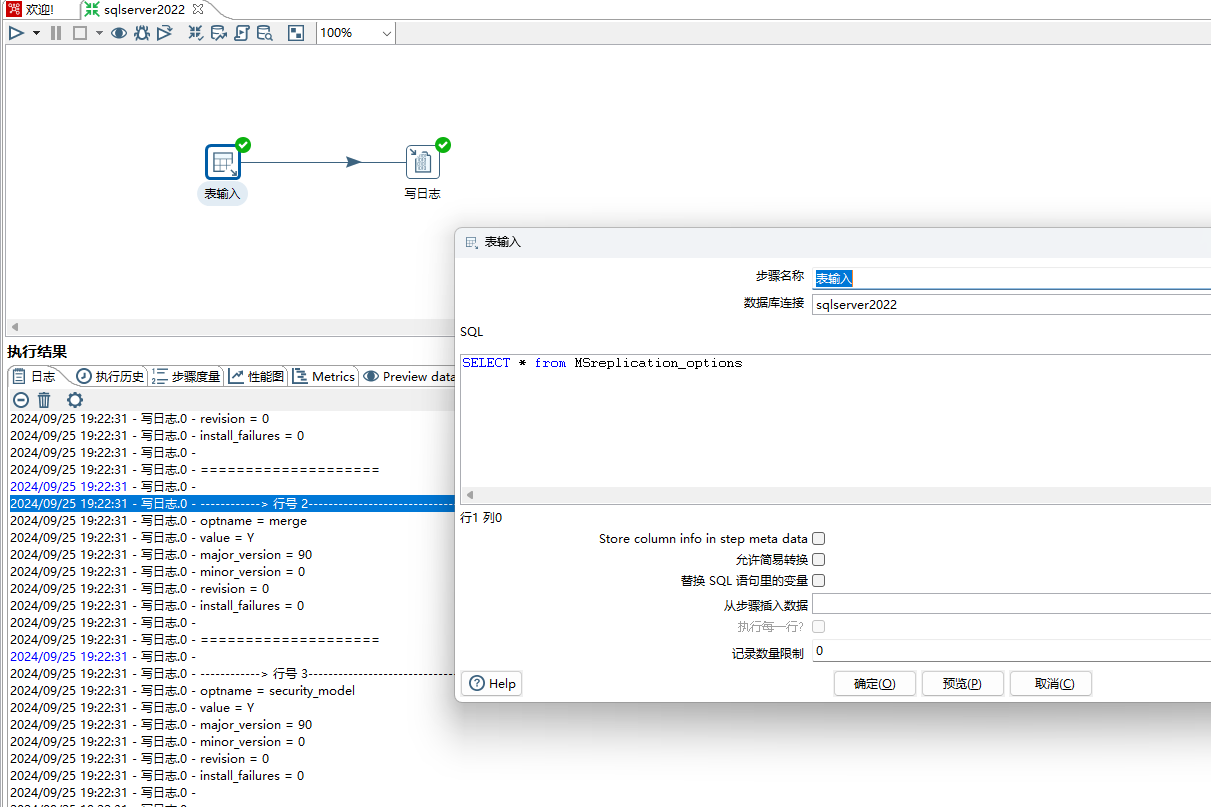
4、使用表输入步骤进行测试可以正常读取表数据,如下图所示:
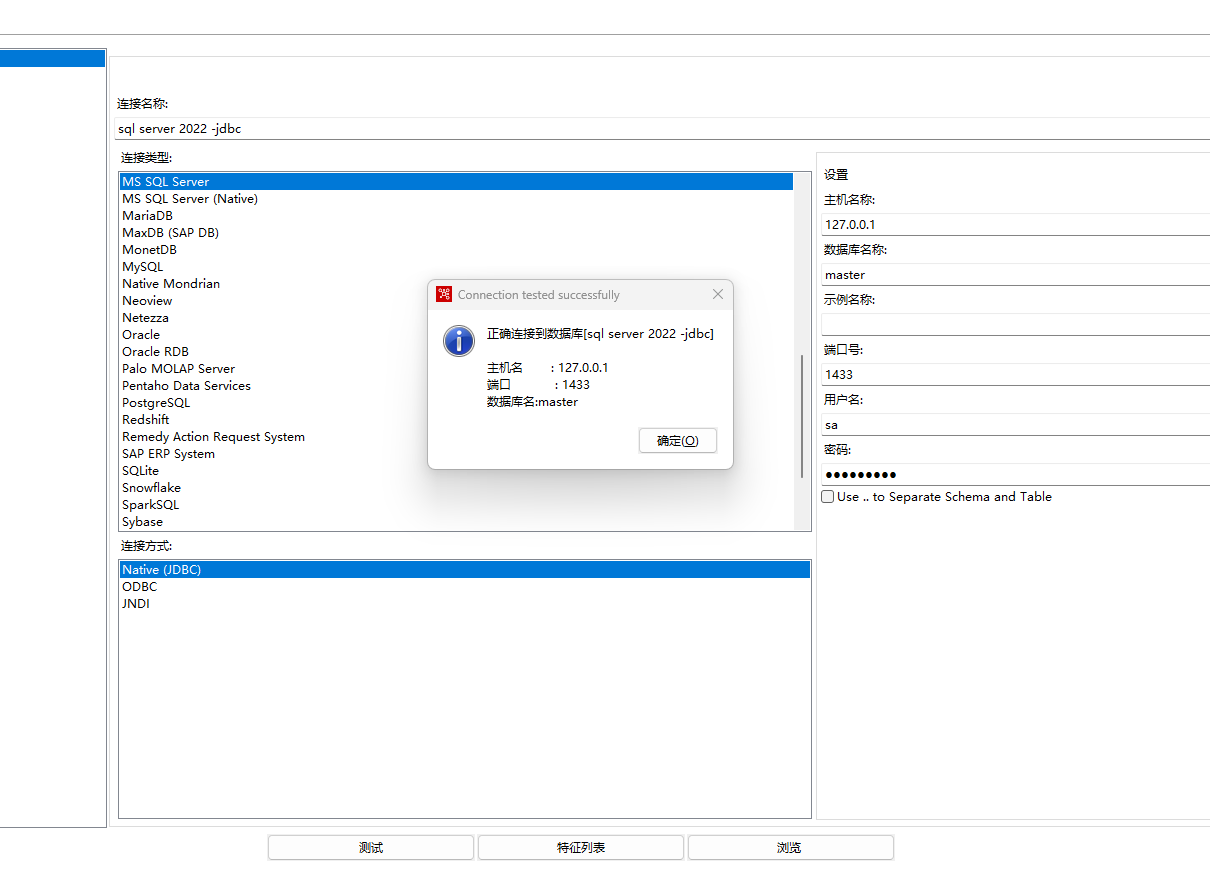
5、JTDS jdbc驱动 方式连接设置,如下图所示:
将jar文件 jtds-1.3.1.jar放到kettle目录下面的lib文件夹下面,然后重启kettle,填写主机名称、数据库名称、端口号、用户名、密码。
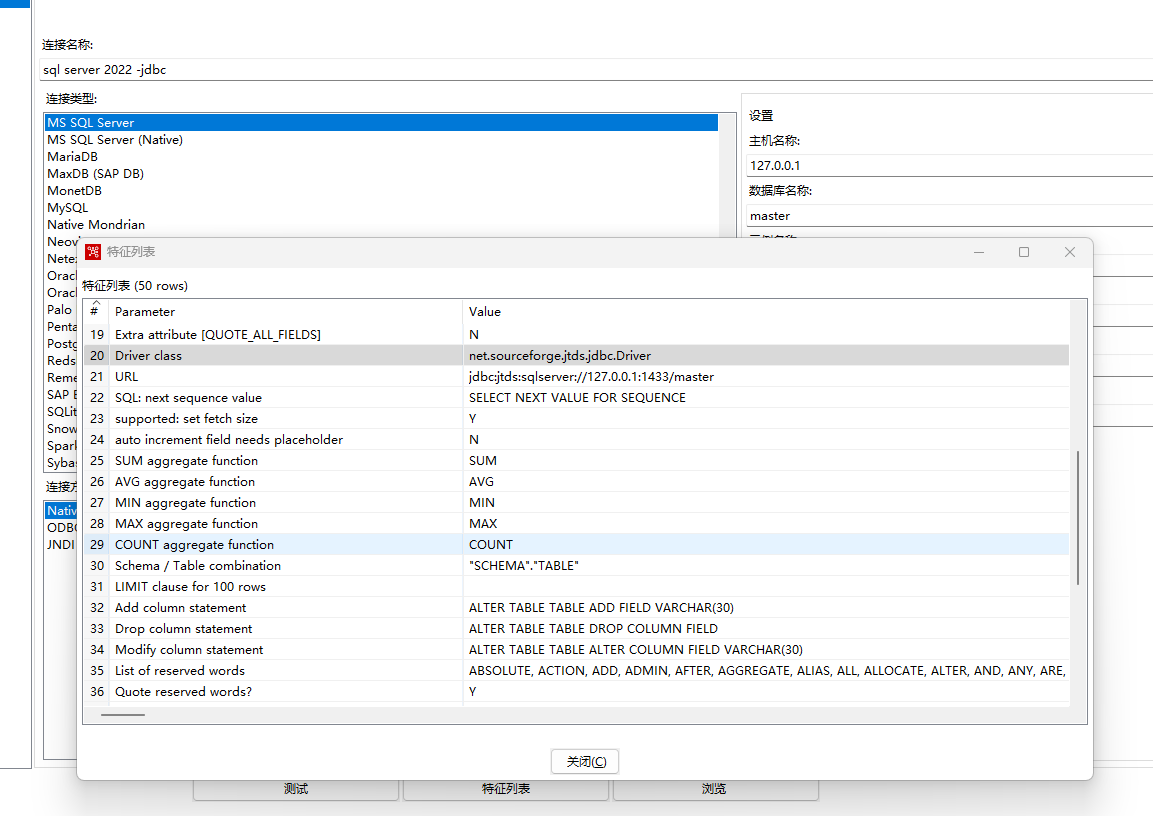
6、点击特征列表按钮可以查看到此数据库连接用到的驱动类,两种连接方式使用的驱动类是不一样的,如下图所示:
7、使用表输入步骤进行测试可以正常读取表数据,如下图所示: