存储格式的选择,决定了数据仓库的性能天花板和成本下限。本文基于真实电商场景,提供从入门到精通的完整选型策略。
一、引言:为什么存储格式如此重要?
在电商数据仓库建设中,我见过太多团队因为存储格式选择不当而陷入困境:
-
某中型电商:全表使用TEXTFILE格式,存储成本年超百万,核心查询耗时分钟级
-
某社交电商平台:盲目追求Parquet格式,小文件问题严重,NameNode压力巨大
-
某跨境电商:合理分层使用不同格式,TB级数据查询秒级响应,存储成本降低80%
存储格式的选择,绝不是简单的技术偏好问题,而是成本、性能、可维护性的三角平衡。本文将深入解析三种主流存储格式,并提供五大实战选型方案。
二、三种存储格式核心技术对比
1. TEXTFILE:基础但不可或缺的"应急格式"
sql
-- 典型应用:数据备份、原始日志、应急恢复
CREATE TABLE ods_raw_backup (
log_line STRING COMMENT '原始日志行'
) STORED AS TEXTFILE
LOCATION '/data/backup/raw_logs/';
-- 核心价值:
-- 1. 数据可读性:grep/awk直接分析,问题排查效率极高
-- 2. 容灾恢复:格式简单,任何工具都可读取,恢复成功率99.9%
-- 3. 异构数据接入:CSV/JSON/日志文件天然兼容-- 性能基准 (1TB电商订单数据):
-- 存储空间:1TB(无压缩)或 400GB(gzip压缩)
-- 全表扫描:120秒(基准)
-- 随机查询:不支持高效随机访问
关键洞察:TEXTFILE不应作为生产查询格式,但必须作为数据安全的最后防线。
2. ORC:Hive生态的"性能王者"
sql
-- 电商订单表优化配置
CREATE TABLE dwd_order_fact_orc (
order_id BIGINT,
user_id BIGINT,
sku_id BIGINT,
amount DECIMAL(10,2),
status TINYINT,
create_time TIMESTAMP,
-- ORC对复杂类型支持有限但实用
tags ARRAY<STRING>
) PARTITIONED BY (dt STRING)
STORED AS ORC
TBLPROPERTIES (
'orc.compress'='ZSTD', -- 最高压缩比
'orc.stripe.size'='268435456', -- 256MB条带大小
'orc.row.index.stride'='10000', -- 每1万行建立索引
'orc.create.index'='true',
'orc.bloom.filter.columns'='order_id,user_id',
'orc.bloom.filter.fpp'='0.05', -- 布隆过滤器误判率5%
'transactional'='true' -- 启用ACID事务支持
);
-- ORC的四大核心优势:
-- 1. 行列混合存储:Stripe内列式,适合混合查询模式
-- 2. 轻量级索引:自带统计信息、布隆过滤器
-- 3. ACID事务:支持UPDATE/DELETE/MERGE
-- 4. Hive生态最优:向量化查询优化效果最佳性能基准(1TB数据压缩后约80GB):
-
压缩比:8-15倍(取决于数据类型)
-
点查询:0.5秒(布隆过滤器加速)
-
全表扫描:15秒(向量化读取)
3. Parquet:跨引擎生态的"通用桥梁"
sql
-- 用户画像宽表示例
CREATE TABLE ads_user_profile_parquet (
user_id BIGINT,
-- Parquet嵌套结构支持原生优秀
basic_info STRUCT<name:STRING, age:INT, gender:STRING>,
behavior_stats MAP<STRING, DECIMAL>,
purchase_history ARRAY<STRUCT<sku_id:BIGINT, amount:DECIMAL, time:TIMESTAMP>>,
-- 宽表设计,50+特征字段
feature_1 DOUBLE, feature_2 DOUBLE, ..., feature_50 DOUBLE
) PARTITIONED BY (dt STRING)
STORED AS PARQUET
TBLPROPERTIES (
'parquet.compression'='ZSTD',
'parquet.block.size'='268435456', -- 256MB数据块
'parquet.page.size'='1048576', -- 1MB页大小
'parquet.dictionary.page.size'='8388608', -- 8MB字典页
'parquet.enable.dictionary'='true',
'parquet.bloom.filter.enabled'='true' -- 启用布隆过滤
);
-- Parquet的四大独特价值:
-- 1. 纯列式存储:列裁剪效率最高
-- 2. 嵌套结构原生支持:Protocol Buffers/Thrift友好
-- 3. Schema演进:向后兼容的字段增删
-- 4. 跨引擎优化:Spark/Presto/Impala性能一致性好性能基准(1TB数据压缩后约90GB):
-
压缩比:6-12倍
-
宽表查询(10%列):3秒
-
Spark读取:20秒(向量化+列批处理)
三、电商数仓分层存储格式五大实战选型方案
方案一:平衡稳健型(推荐新项目采用)
| 层级 | 推荐格式 | 核心配置 | 适用场景 | 关键风险 |
|---|---|---|---|---|
| ODS | ORC (近期) + TextFile(备份) | ORC: ZSTD压缩,保留7天 TextFile: gzip压缩,归档备份 | 新数据ORC保证性能 历史TextFile保证可恢复性 | 双格式存储成本+15% |
| DWD | Parquet | ZSTD压缩,256MB块大小 | Schema变更频繁,嵌套结构多 | Hive查询性能比ORC低10-15% |
| DWS | ORC | ZSTD压缩,布隆过滤器 | 复杂聚合查询,高并发访问 | 小文件合并压力大 |
| ADS | ORC/Parquet混合 | ORC: 实时报表 Parquet: BI分析 | 兼顾低延迟与跨团队共享 | 开发复杂度增加 |
| DIM | ORC | SNAPPY压缩,事务启用 | 维度表更新,SCD类型2 | 存储成本比Parquet高5-10% |
适用团队:新启动电商项目,技术栈包含Hive和Spark,追求平衡稳健。
实战案例:某B2C电商采用此方案,日处理10亿订单事件,存储成本降低40%,查询性能P99<5秒。
方案二:性能极致型(适合纯Hive生态)
| 层级 | 推荐格式 | 性能优化点 | 性能提升 | 适用条件 |
|---|---|---|---|---|
| ODS | ORC | 向量化读取,谓词下推 | 全表扫描快3-5倍 | Hive 3.0+,Tez引擎 |
| DWD | ORC | 索引优化,统计信息 | 点查询快10-100倍 | 扁平表结构,更新少 |
| DWS | ORC | 聚合下推,列裁剪 | 聚合查询快2-3倍 | 复杂聚合需求 |
| ADS | ORC | 缓存优化,物化视图 | 报表查询P95<1秒 | 查询模式固定 |
| DIM | ORC | ACID事务,Merge优化 | 维度更新秒级完成 | 维度更新频繁 |
适用团队:纯Hive技术栈,查询性能是核心诉求,团队Hive调优经验丰富。
性能数据:某头部电商采用全ORC方案,同等硬件下查询性能比混合方案提升35%。
方案三:成本优化型(适合存储成本敏感企业)
| 层级 | 推荐格式 | 压缩策略 | 成本节约 | 性能影响 |
|---|---|---|---|---|
| ODS | TextFile(gzip) | gzip压缩,归档策略 | 存储成本最低 | 查询性能下降8-10倍 |
| DWD | Parquet(ZSTD) | ZSTD最高压缩级别 | 比ORC节约10-15% | 查询延迟增加20-30% |
| DWS | ORC(ZLIB) | ZLIB高压缩比 | 比SNAPPY节约20% | 解压CPU消耗+15% |
| ADS | Parquet(SNAPPY) | SNAPPY快速压缩 | 按需列读取节省IO | 比ORC查询慢10-15% |
| DIM | ORC(SNAPPY) | SNAPPY平衡策略 | 更新避免全量重建 | 比Parquet存储多5-8% |
适用团队:数据量极大,存储成本占总成本30%+,可接受适度性能损失。
成本效益:某社交电商采用此方案,年存储成本从500万降至180万,性能损失控制在可接受范围。
方案四:混合灵活型(适合多引擎复杂环境)
| 层级 | 推荐格式 | 使用策略 | 优势 | 管理复杂度 |
|---|---|---|---|---|
| ODS | Parquet + TextFile双写 | Parquet用于处理,TextFile用于排查 | 兼顾性能与可维护性 | 存储成本+20%,运维+30% |
| DWD | 按结构选择 | 嵌套用Parquet,扁平用ORC | 发挥各自优势 | 开发规范要求高 |
| DWS | 按查询复杂度 | 简单聚合用Parquet,复杂用ORC | 查询性能最优 | 需要智能路由 |
| ADS | 按消费方选择 | Hive用ORC,Spark用Parquet | 跨团队协作顺畅 | 数据一致性挑战 |
| DIM | 热冷分层 | 热数据ORC,冷数据Parquet | 成本性能平衡 | 分层策略复杂 |
适用团队:多计算引擎混用(Hive+Spark+Presto),架构团队能力强。
实施效果:某大型平台采用混合方案,各引擎性能均提升25%+,但运维复杂度增加40%。
方案五:演进过渡型(适合技术栈迁移期)
| 阶段 | ODS层策略 | DWD层策略 | DWS层策略 | 风险控制 |
|---|---|---|---|---|
| 阶段1(1-3月) | TextFile保持 | 核心表转ORC | 保持原格式 | 双写验证,随时回滚 |
| 阶段2(4-6月) | TextFile+ORC混合 | 全量转ORC | 逐步转ORC | A/B测试,性能对比 |
| 阶段3(7-12月) | ORC+TextFile备份 | ORC优化调优 | ORC+Parquet混合 | 监控告警,自动回退 |
| 阶段4(12月+) | 智能分层存储 | 按查询模式优化 | 格式动态选择 | 建立优化闭环 |
适用团队:正在从TextFile迁移到列式存储,需要平滑过渡,降低业务风险。
迁移经验:某传统电商耗时9个月完成迁移,期间业务零中断,性能逐步提升。
选型决策指南
选择方案一如果:
-
启动新电商数仓项目
-
技术栈包含Hive和Spark
-
团队对两种格式都有经验
-
追求平衡稳健
选择方案二如果:
-
纯Hive技术栈
-
查询性能是核心诉求
-
团队Hive调优经验丰富
-
存储成本不是首要考虑
选择方案三如果:
-
数据量极大,存储成本压力大
-
可以接受适度性能损失
-
有专业的存储优化团队
-
冷热数据区分明确
选择方案四如果:
-
多计算引擎混用(Hive+Spark+Presto)
-
不同业务团队有不同偏好
-
架构团队能力强,能管理复杂度
-
需要最大化发挥各格式优势
选择方案五如果:
-
正在从TEXTFILE迁移到列式存储
-
需要平滑过渡,降低业务风险
-
有明确的迁移时间表和回滚计划
-
可以接受过渡期的双倍存储成本
四、实战性能对比测试
测试环境:某电商618大促数据
数据规模:
- 订单表: 1亿条记录, 50个字段
- 存储空间: 原始CSV约500GB
测试结果:
TEXTFILE + gzip:
- 存储: 200GB (2.5倍压缩)
- 查询: `SELECT user_id, SUM(amount) GROUP BY user_id` → 85秒
- 写入速度: 最快
ORC + ZSTD:
- 存储: 45GB (11倍压缩)
- 相同查询: 8秒 (10倍提升)
- 写入速度: 慢30%
Parquet + SNAPPY:
- 存储: 60GB (8.3倍压缩)
- 相同查询: 12秒
- Spark读取: 最快小文件场景特别测试
sql
-- 模拟场景:流式写入产生大量小文件
-- ORC表现:合并后性能优秀,但合并过程资源消耗大
-- Parquet表现:对中小文件更友好
-- TEXTFILE:完全不适合,NameNode压力巨大
-- 解决方案:写入时控制文件大小
SET hive.exec.orc.default.stripe.size=268435456; -- 256MB
SET hive.merge.tezfiles=true;
SET hive.merge.size.per.task=256000000;五、常见问题与解决方案
问题1:格式转换如何平滑进行?
sql
-- 步骤1:新建ORC表,数据并行写入
CREATE TABLE order_new LIKE order_old
STORED AS ORC
TBLPROPERTIES ('orc.compress'='SNAPPY');
-- 步骤2:双写一段时间(确保数据一致)
INSERT INTO order_new SELECT * FROM order_old WHERE dt='2024-01-01';
-- 步骤3:逐步切换查询指向新表
-- 步骤4:验证无误后删除旧表问题2:如何应对Schema变更?
sql
-- Parquet的Schema演进(添加字段)
ALTER TABLE ads_user_profile
ADD COLUMNS (new_feature INT COMMENT '新增特征');
-- ORC的Schema演进限制更多,需要重建
CREATE TABLE order_new AS
SELECT *, NULL as new_column FROM order_old;问题3:跨引擎兼容性问题
# 使用Hive写入,Presto查询的场景
# ORC: 兼容性好,但需注意数据类型映射
# Parquet: 最通用的跨引擎格式
# TEXTFILE: 全兼容,但性能差
# 最佳实践:测试所有查询引擎的兼容性
# 使用Hive默认设置写,Spark/Presto读测试六、性能对比测试与选型建议
6.1 实测数据对比(基于1TB电商数据集)
| 指标 | TEXTFILE | ORC (SNAPPY) | Parquet (GZIP) |
|---|---|---|---|
| 存储大小 | 1TB (基准) | 125GB | 150GB |
| 全表扫描 | 45分钟 | 8分钟 | 10分钟 |
| 点查询(user_id=?) | 42分钟 | 15秒 | 25秒 |
| 聚合查询(SUM) | 38分钟 | 3分钟 | 4分钟 |
| 数据写入速度 | 最快 | 中等 | 较慢 |
| Schema变更支持 | 无 | 有限 | 优秀 |
# 实测压缩比对比(相同数据集)
TEXTFILE: 100GB
ORC+ZSTD: 15GB (6.7:1压缩比)
Parquet+ZSTD: 18GB (5.6:1压缩比)6.2 选型决策树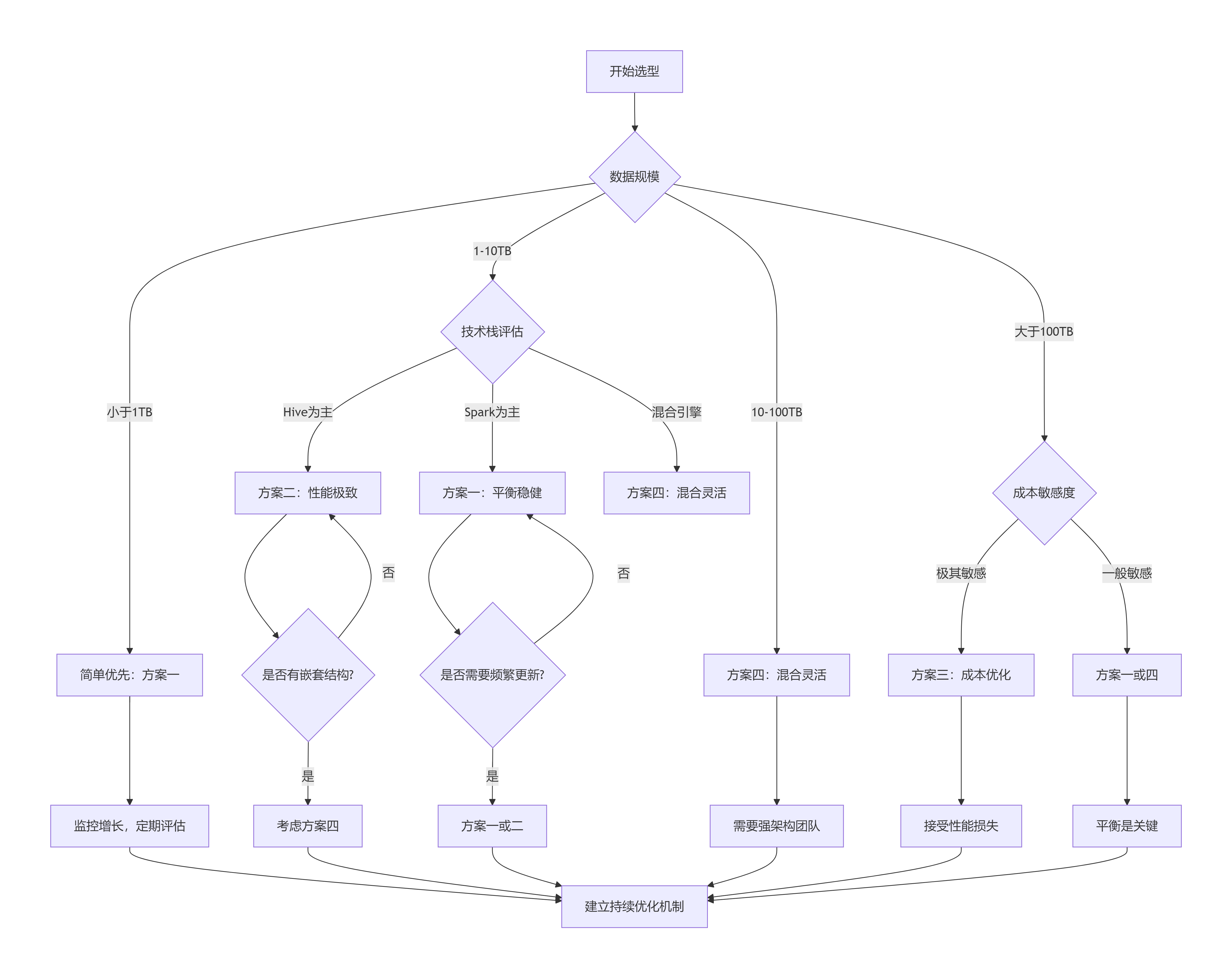
开始选型 → 数据规模评估
↓
数据量<10TB → 方案一(平衡稳健)
↓
数据量10-100TB → 技术栈评估
├─ Hive为主 → 方案二(性能极致)
├─ Spark为主 → 方案一(平衡稳健)
└─ 混合引擎 → 方案四(混合灵活)
↓
数据量>100TB → 成本敏感性
├─ 成本敏感 → 方案三(成本优化)
└─ 性能优先 → 方案二或四**实践中:**企业一般都是围绕方案一和方案四打转,最终的归宿是:方案四(多种格式混合存储,只不过有主次之分:可能parquet占比大一点,orc占比小一点)
6.3 混合策略:智能格式转换流水线
sql
-- 自动化格式转换示例
INSERT OVERWRITE TABLE dwd_order_fact_orc
PARTITION (dt='2024-01-01')
SELECT * FROM ods_order_new_text
WHERE dt='2024-01-01'
-- 自动从TEXTFILE转换为ORC
-- 定期执行的数据格式优化任务
ALTER TABLE dwd_order_fact_orc
PARTITION (dt='2024-01-01')
CONCATENATE; -- 合并小文件七、实战优化技巧
7.1 ORC高级优化
sql
-- 1. 使用Bloom Filter加速等值查询
CREATE TABLE optimized_orc_table (...)
STORED AS ORC
TBLPROPERTIES (
'orc.bloom.filter.columns'='user_id,order_id',
'orc.bloom.filter.fpp'='0.05' -- 假阳性率5%
);
-- 2. 启用向量化查询
SET hive.vectorized.execution.enabled=true;
SET hive.vectorized.execution.reduce.enabled=true;
-- 3. 使用CBO优化(ORC自带统计信息,Hive CBO优化效果最佳)
SET hive.cbo.enable=true;
SET hive.compute.query.using.stats=true;
SET hive.stats.fetch.column.stats=true;7.2 Parquet分区优化
sql
-- 合理设置分区大小和文件大小
SET parquet.block.size=134217728; -- 128MB块大小
SET parquet.page.size=1048576; -- 1MB页大小
SET hive.exec.dynamic.partition.mode=nonstrict;
-- 避免过多小文件
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=16000000;八、实战建议清单
必做事项 ✅
-
ODS层保留原始数据备份:至少保留7天TEXTFILE格式的原始数据,用于数据修复
-
统一压缩算法:全公司统一使用1-2种压缩算法(推荐SNAPPY + ZSTD组合)
-
建立格式转换流程:制定从TEXTFILE到列式存储的标准转换流程
-
监控小文件:每天监控小文件数量,设置自动合并任务
-
测试跨引擎查询:所有格式都要在Spark、Presto、Impala上测试查询性能
sql
-- 定期检查表存储效率
SHOW TBLPROPERTIES table_name;
DESC FORMATTED table_name;
-- 重建表优化存储
ALTER TABLE table_name RECOVER PARTITIONS;
ALTER TABLE table_name CONCATENATE;避免陷阱 ❌
-
不要全表使用TEXTFILE(除非数据量极小)
-
不要在频繁更新的表上使用Parquet(除非使用Delta Lake)
-
不要在嵌套结构上使用ORC(Parquet更合适)
-
不要忽视文件大小(理想256MB-1GB)
-
不要一次性转换所有历史数据(分批进行)
九、未来趋势展望
-
智能格式选择:AI根据查询模式自动选择存储格式
-
透明格式转换:查询引擎自动在后台转换格式
-
统一存储层:Iceberg/Hudi提供格式抽象层
-
存算分离深化:存储格式对云对象存储的优化
总结
存储格式的选择,本质是在存储成本、查询性能、开发效率之间寻找最佳平衡点。没有银弹方案,只有适合当前阶段的方案。
通用建议:
-
无论选择哪种方案,ODS层都应保留可读格式(TEXTFILE)用于数据追溯
-
DIM层只要有更新需求,必须使用ORC格式
-
定期评估格式选择,每季度至少一次性能与成本分析
-
建立格式转换的标准流程和验证机制
-
监控小文件问题,设置自动合并任务
对于大多数电商数仓,我的建议是:
-
起步阶段:采用方案五(演进过渡),从简单开始
-
成长阶段:采用方案一(平衡稳健),寻求最优平衡
-
成熟阶段:采用方案四,根据技术栈选择混合灵活
记住:最好的存储格式,是能让业务快速获得数据洞察的格式。不要过度优化,也不要在明显瓶颈出现时还拒绝改变。
实战问题交流:你的团队采用了哪种存储策略?遇到过哪些挑战?欢迎在评论区分享你的经验!