目录
- 1、创建文件
- 2、启动HDFS
- [3、启动eclipse 创建项目并导入jar包](#3、启动eclipse 创建项目并导入jar包)
- 4、编写Java应用程序
- 5、编译打包应用程序
-
- (1)查看直接运行结果
- (2)打包程序
- [(3)查看 JAR 包是否成功导出](#(3)查看 JAR 包是否成功导出)
- 6、运行程序
- 7、关闭HDFS
1、创建文件


2、启动HDFS
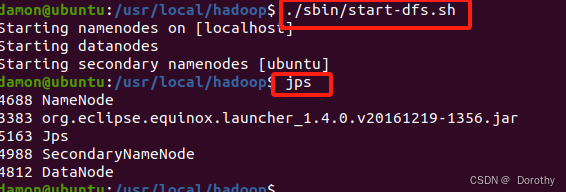
3、启动eclipse 创建项目并导入jar包
file->new->java project
导入jar包




finish
4、编写Java应用程序
在WordCount项目下 new class

java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 程序运行时参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // 解析相关参数
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); // 设置环境参数
job.setJarByClass(WordCount.class); // 设置整个程序的类名
job.setMapperClass(MyMapper.class); // 添加 MyMapper 类
job.setReducerClass(MyReducer.class); // 添加 MyReducer 类
job.setOutputKeyClass(Text.class); // 设置输出键类型
job.setOutputValueClass(IntWritable.class); // 设置输出值类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // 设置输入文件路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // 设置输出文件路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}5、编译打包应用程序
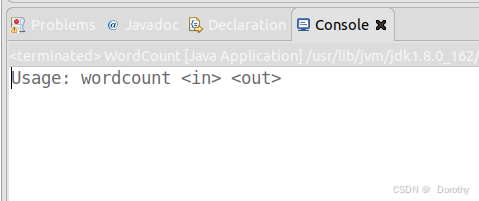
(1)查看直接运行结果
(2)打包程序

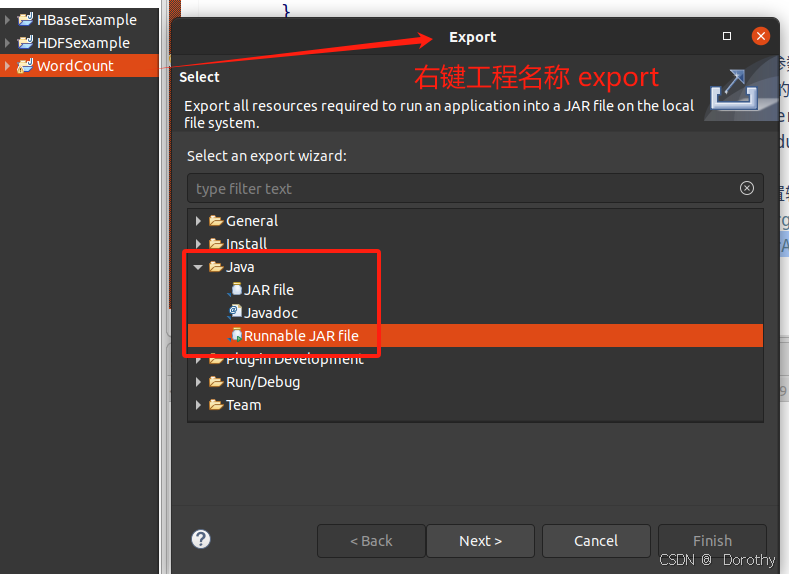
next

(3)查看 JAR 包是否成功导出

6、运行程序
(1)准备文件夹



(2)上传文件
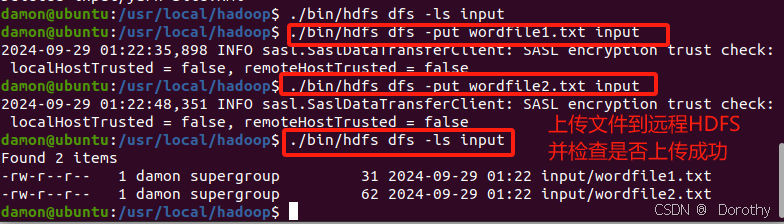
(3)运行程序
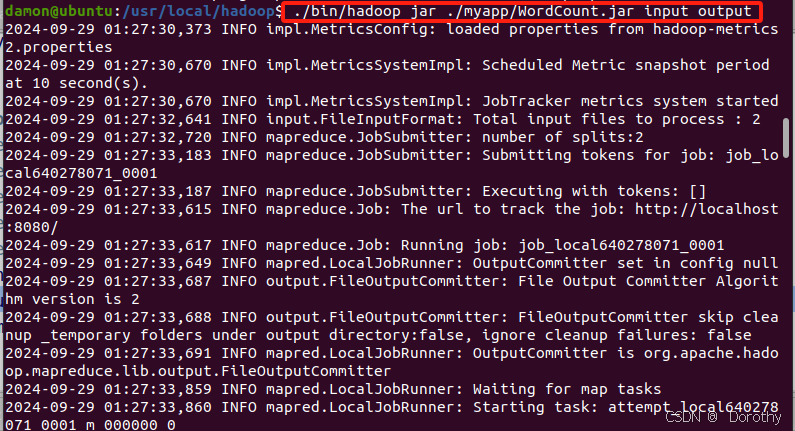
查看运行结果

7、关闭HDFS