书接上文GaussDB关键技术原理:高弹性(五)从日志多流和事务相关方面对hashbucket扩容技术进行了解读,本篇将从扩容实践方面继续介绍GaussDB高弹性技术。
5 扩容实践
5.1 工具介绍
5.1.1 TPC-C
TPC-C(全称Transaction Processing Performance Council Benchmark C),是一套衡量联机交易处理系统(OLTP系统)的基准测试集。它于1992年8月首次发布,最终取代了早先的TPC-A成为事实上的行业标准。当前的最新版本是5.11, 发布于2010年2月。
TPC-C是以在线零售业公司为例设计的一种数据模型。每个仓库的数据量约为 76.823 MB。TPC-C涉及9张表,包含了新订单的生成(NewOrder)、支付操作(Payment)、订单状态查询(OrderStatus)、配送发货(Delivery)和库存状态查询(StockLevel)5类业务事务模型。5类业务的占比是可以由用户通过配置文件自定义的。
TPC-C的评测指标是每分钟处理的业务量(transactions per minute, tpmC),又称作流量指标(throughput)。本指标越大表示系统性能越高。首次发布的评测记录是1992年11月由IBM AS/400系统创造的,当时的结果是54 tpmC。到2000年左右,高端机器的平均记录是240万tpmC。许多公司为了获得这样的记录而构建了大量机器组合而成的系统。当前的最新记录是在2020年由云计算创造的7.073亿tpmC。
另外,TPC-C还可以通过系统性能价格比(cost-per-tpmC)的方式来体现,即测试系统报价(美元)与流量指标的比值。在获得相同的tpmC值的情况下,系统报价越低越好。当前许多小型本地系统旨在降低系统性能价格比而不懈努力。
BenchmarkSQL是一款基于JDBC实现的类似于OLTP的TPC-C标准测试工具,目前支持的数据库有:PostgreSQL、Oracle、Firebird。由于openGauss的接口与PostgreSQL兼容性较好,所以也可以使用该工具对openGauss数据库进行TPC-C测试。
5.1.2 Sysbench
Sysbench是一款开源的多线程脚本工具,适用于Linux系统。Sysbench是C语言的二进制文件,使用Lua脚本执行基线测试,主要用于测试数据库系统。
Sysbench允许在命令行中指定测试类型,包括:
-
oltp_*.lua: 测试OLTP型数据库性能(使用自定义Lua脚本)
-
cpu: 测试CPU性能
-
fileio: 测试文件输入/输出性能
-
memory: 测试内存函数运行速度
-
threads: 测试多线程子系统性能
-
mutex: 测试互斥锁性能
下面我们主要关注第1种测试类型,即使用用户自定义Lua脚本。
在sysbench执行过程中和结束时,可以查看统计数据。其中,主要关注的是每秒事务执行数量(transactions per second,tps),每秒查询执行数量(queries per second, qps), 时延毫秒数(latency)。其中,每秒查询执行数量又可以细分为读查询(read),写查询(write),其他查询(other)。每秒事务/查询执行数量越高,时延毫秒数越低,说明数据库性能越好。
Sysbench目前已经内置了MySQL和PostgreSQL的驱动,由于GaussDB和PostgreSQL兼容性较好,所以可以通过指定pgsql的变量(包括host, port, user, password, db)来进行测试。
5.2 扩容步骤
5.2.1 安装GaussDB集群
安装GaussDB集群需要使用运维工具集(Operation Manager,OM)和配置集群XML文件。其中,XML文件负责声明GaussDB集群的具体配置情况。本文以3CN3DN集群配置为例,展示安装GaussDB的命令如下:
# root身份执行
sudo [your-location]/script/gs_preinstall -U [username] -G [usergroup] -X [xml-location] --alarm-type=1
# 切换到普通用户
su -- [username]
gs_install -X [xml-location]
# 卸载cluster
gs_uninstall --delete-data图1为分布式3CN3DN集群的架构。
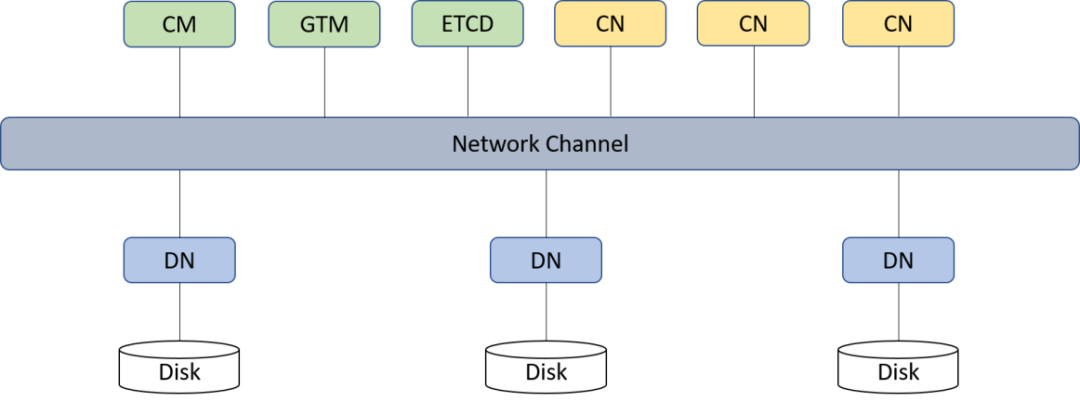
图1 分布式3CN3DN集群架构图
5.2.2 启动GaussDB集群
通过cm_ctl命令,可以有效对GaussDB集群进行管控,命令如下:
# 集群启动
cm_ctl start
# 集群停止
cm_ctl stop
# 查看集群信息
cm_ctl query -Cvdpi
# 查询集群信息
cm_ctl query -Cv5.2.3 扩容GaussDB集群
以3CN6DN集群配置为例,展示扩容GaussDB的命令如下:
# 以root身份运行
sudo [your-location]/script/gs_preinstall -U [username] -G [usergroup] -X [new-xml-location] --alarm-type=1
# 切换到普通用户
su -- [username]
# 扩容阶段1,添加新节点
gs_expand -t dilatation -X [new-xml-location] --parallel-jobs=1
# 扩容阶段2,数据重分布
gs_expand -t redistribute --redis-mode=insert --parallel-jobs=1图2为分布式3CN6DN集群的GaussDB架构。
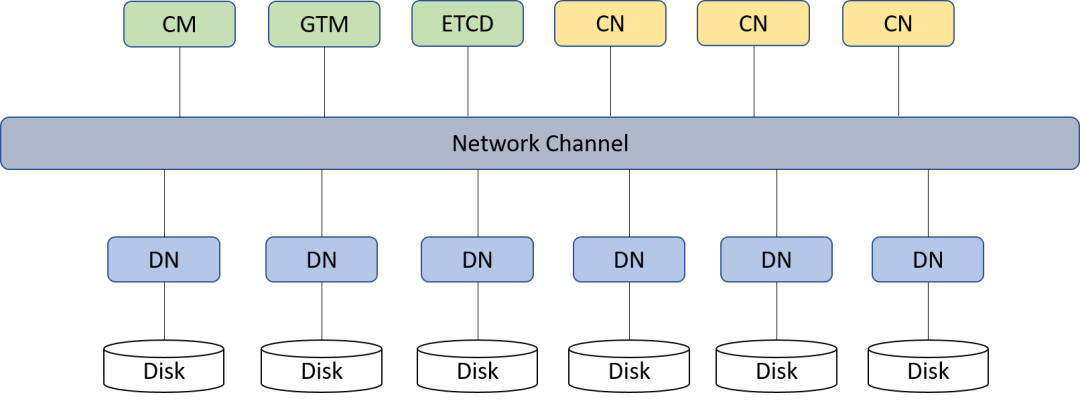
图2 分布式3CN6DN集群架构图
5.3 扩容期间的TPC-C测试
在数据库扩容期间对GaussDB集群使用TPC-C工具同步监控,可以获得hashbucket表在扩容期间对TPCC模型性能的影响。
导入10000 warehorse的数据,3C3D,单DN 800GB数据,运行600并发TPCC,叠加hashbucket扩容(3DN扩6DN),业务运行情况如下图3所示, 可以看出整个扩容过程中,TPCC业务没有出现性能大幅度下降的情况,整体运行平稳。
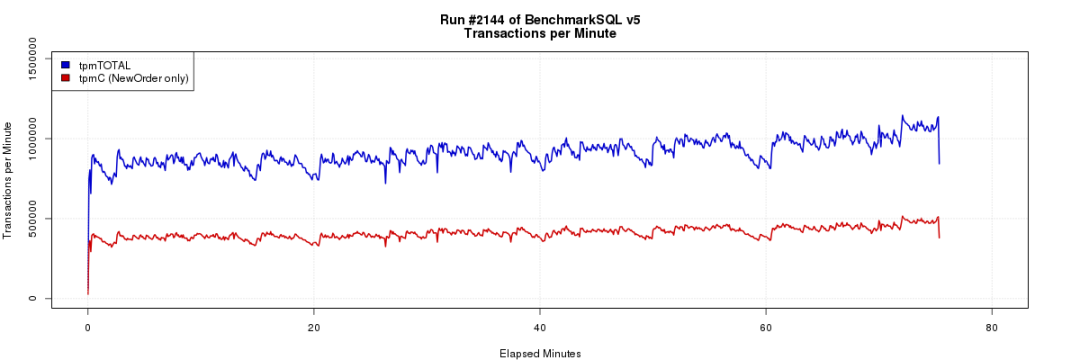
图3 扩容期间TPCC性能测试结果图
5.4 扩容期间的sysbench测试
在数据库扩容期间对GaussDB集群使用sysbench工具同步监控,可以获得普通表和hashbucket表在扩容期间的JOIN操作性能影响,图x为JOIN操作示意图。我们设定Lua脚本的测试场景为等值JOIN。JOIN操作的两张表分别具有Column A, Column B两个int类型。两张表的数据量为1千万条,其中,Column A为随机值,范围1, 100,000;Column B为唯一递增值,范围1, 10,000,000,两者的范围差距为100倍。完整的SQL语句为:
select * from h1 left JOIN h2 on h1.b = h2.b and h1.a = h2.a where h2.a = $1 order by h2.b limit 1;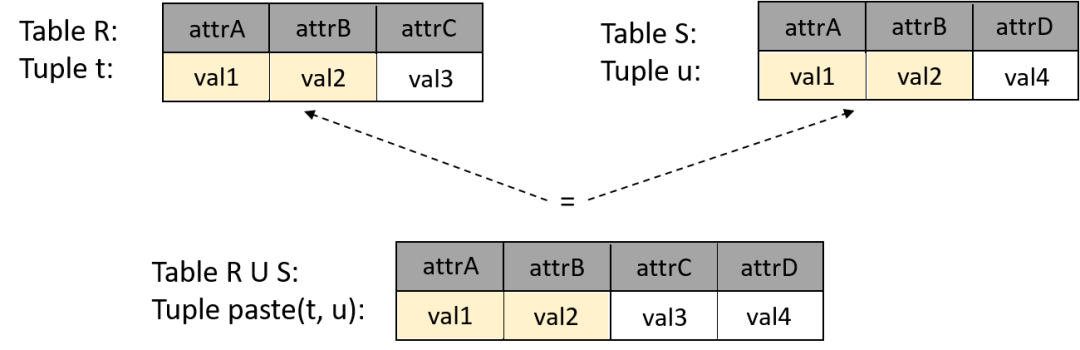
图4 两张表JOIN操作示意图
实验中每个物理节点的配置参数如表1所示:
表1 物理节点的配置参数
|-----------|-----------------------------------------------|
| 软硬件指标 | 型号数值 |
| 处理器 | 64 核Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz |
| 内存 | 256 GB |
| 磁盘 | ssd磁盘 |
| 网卡 | 万兆网 |
| 操作系统 | EulerOS 2.0 (SP5) x86_64 |
普通表执行的是逻辑扩容,遍历所有库依次搬迁每个表。对于同一个库,同一个模式下的两张表:当表1完成扩容而表2未开始扩容时,两个表的位于在不同的组节点(NodeGroup)上,此时对表1,表2执行JOIN操作会造成CN无法利用分布式架构下推JOIN操作到各个DN上执行,而是会生成跨DN的stream计划进行数据重分布后在进行JOIN,大量的跨节点通信导致性能劣化严重,如图5所示。
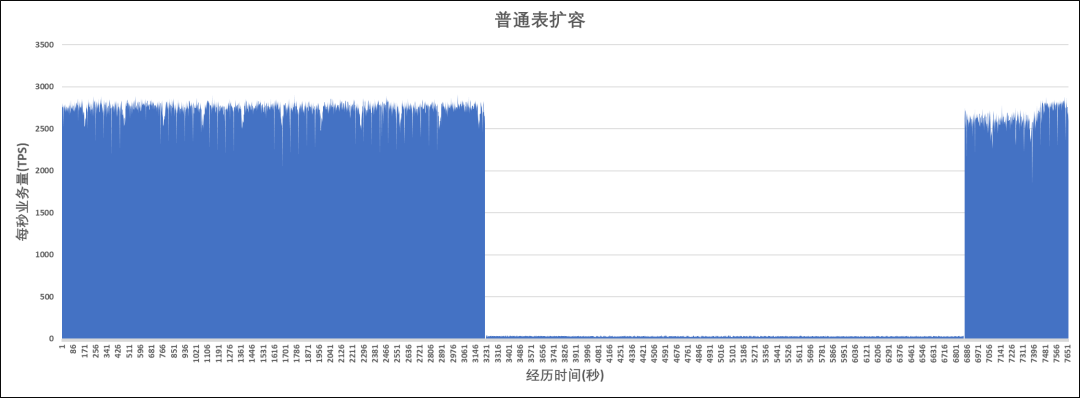
图5 普通表扩容期间的tps
hashbucket表执行的是物理扩容,以库(database)为单位进行库内所有表的bucket搬迁。对于同一个库内的两张表:除了JOIN期间同步上线的bucket之外,其他的绝大多数bucket位于同一个组节点(NodeGroup)上,此时CN可以利用分布式架构分发JOIN操作到各个DN上执行,性能不受影响,如图6所示。
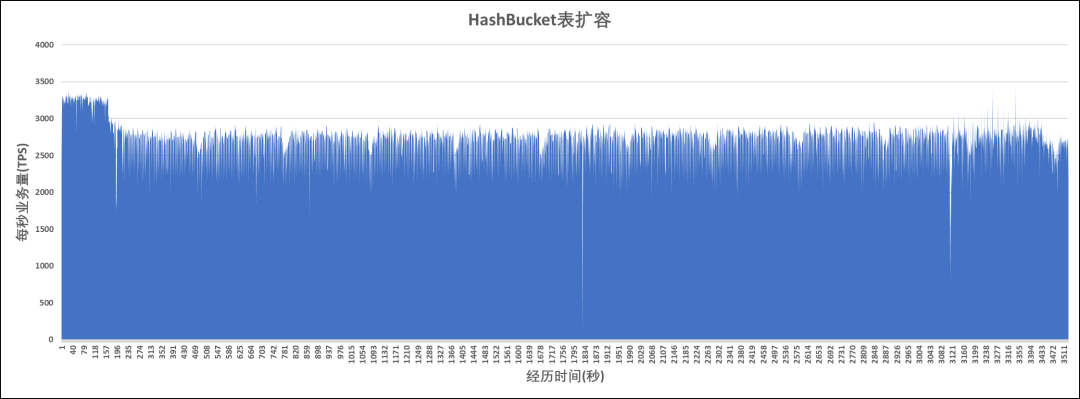
图6 hashbucket表扩容期间的tps
欢迎小伙伴们交流~