前言
本文分享YOLO11的模型推理,检测任务包括物体分类、目标检测与跟踪、实例分割 、关键点估计、旋转目标检测等。
首先安装YOLO11
官方默认安装方式
通过运行 pip install ultralytics 来快速安装 Ultralytics 包
安装要求:
- Python 版本要求:Python 版本需为 3.8 及以上,支持 3.8、3.9、3.10、3.11、3.12 这些版本。
- PyTorch 版本要求:需要 PyTorch 版本不低于 1.8。
然后使用清华源,进行加速安装
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/一、YOLO11模型推理------目标检测
1、模型推理简洁版
YOLO11模型推理,整体思路流程:
- 加载模型 :使用
YOLO类指定模型的权重文件yolo11m.pt。 - 执行推理 :调用
model.predict()方法对指定输入的数据,可以设置图像大小、置信度阈值,并选择保存推理结果。 - 处理检测结果 :遍历
results,提取每个结果中的边界框和分类概率。 - 显示结果 :通过
result.show()可视化检测到的图像及其标注信息。
示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/test1.jpg", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
boxes = result.boxes # 获取边界框信息
probs = result.probs # 获取分类概率
result.show() # 显示结果执行后能看到检测的结果,如下图所示:

2、模型推理------完成参数版本
由于是直接调用model.predict() 方法进行推理,我们需要知道这个函数有哪些参数;
下面看看这个完整参数示例,里面有所有model.predict() 函数的参数
results = model.predict(
source="test.jpg", # 数据来源,可以是文件夹、图片路径、视频、URL,或设备ID(如摄像头)
conf=0.45, # 置信度阈值
iou=0.6, # IoU 阈值
imgsz=640, # 图像大小
half=False, # 使用半精度推理
device=None, # 使用设备,None 表示自动选择,比如'cpu','0'
max_det=300, # 最大检测数量
vid_stride=1, # 视频帧跳跃设置
stream_buffer=False, # 视频流缓冲
visualize=False, # 可视化模型特征
augment=False, # 启用推理时增强
agnostic_nms=False, # 启用类无关的NMS
classes=None, # 指定要检测的类别
retina_masks=False, # 使用高分辨率分割掩码
embed=None, # 提取特征向量层
show=False, # 是否显示推理图像
save=True, # 保存推理结果
save_frames=False, # 保存视频的帧作为图像
save_txt=True, # 保存检测结果到文本文件
save_conf=False, # 保存置信度到文本文件
save_crop=False, # 保存裁剪的检测对象图像
show_labels=True, # 显示检测的标签
show_conf=True, # 显示检测置信度
show_boxes=True, # 显示检测框
line_width=None # 设置边界框的线条宽度,比如2,4
)
示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m.pt")
# 对指定的图像文件夹进行推理,并设置各种参数
results = model.predict(
source="test_image/test.jpg", # 数据来源,可以是文件夹、图片路径、视频、URL,或设备ID(如摄像头)
conf=0.45, # 置信度阈值
iou=0.6, # IoU 阈值
imgsz=640, # 图像大小
half=False, # 使用半精度推理
device=None, # 使用设备,None 表示自动选择,比如'cpu','0'
max_det=300, # 最大检测数量
vid_stride=1, # 视频帧跳跃设置
stream_buffer=False, # 视频流缓冲
visualize=False, # 可视化模型特征
augment=False, # 启用推理时增强
agnostic_nms=False, # 启用类无关的NMS
classes=None, # 指定要检测的类别
retina_masks=False, # 使用高分辨率分割掩码
embed=None, # 提取特征向量层
show=False, # 是否显示推理图像
save=True, # 保存推理结果
save_frames=False, # 保存视频的帧作为图像
save_txt=True, # 保存检测结果到文本文件
save_conf=False, # 保存置信度到文本文件
save_crop=False, # 保存裁剪的检测对象图像
show_labels=True, # 显示检测的标签
show_conf=True, # 显示检测置信度
show_boxes=True, # 显示检测框
line_width=None # 设置边界框的线条宽度,比如2,4
)
# 处理返回的结果
for result in results:
boxes = result.boxes # 获取边界框信息
probs = result.probs # 获取分类概率
result.show() # 显示推理结果执行后能看到检测的结果,如下图所示:
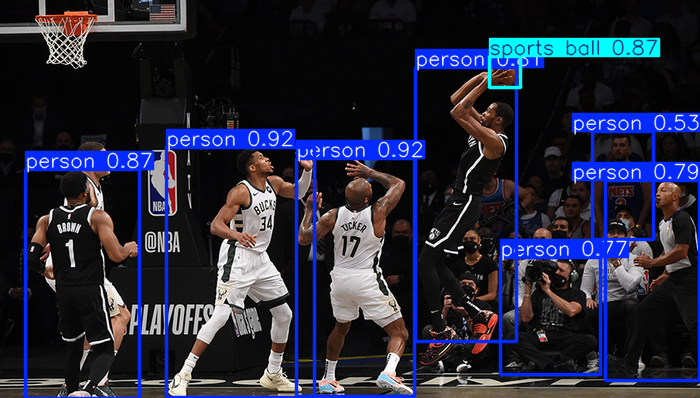
3、模型推理------丰富的返回结果版本
模型推理后的返回信息:
- 原始图像及其形状 :
result.orig_img和result.orig_shape展示原始输入的图像及其形状。 - 边界框、类别置信度及标签 :通过
result.boxes和result.probs获取边界框和分类的置信度信息,并打印类别名称。 - 可选属性 :如果模型检测了
masks、keypoints或 OBB(定向边界框),将其打印出来。 - 速度信息 :
result.speed用于显示每张图像的推理时间。 - 结果展示与保存 :使用
result.show()显示图像,result.save()保存图像 - 结果转换 :将检测结果转换为
numpy数组和 JSON 格式并打印。
示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/test1.jpg", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
# 打印原始图像和形状
print(f"Original Image: {result.orig_img}")
print(f"Original Shape: {result.orig_shape}")
# 打印边界框、置信度、类别标签
print(f"Bounding Boxes: {result.boxes}")
print(f"Class Probabilities: {result.probs}")
print(f"Class Names: {result.names}")
# 如果有 mask、关键点或 OBB(定向边界框),也将其打印出来
if hasattr(result, 'masks'):
print(f"Masks: {result.masks}")
if hasattr(result, 'keypoints'):
print(f"Keypoints: {result.keypoints}")
if hasattr(result, 'obb'):
print(f"Oriented Bounding Boxes (OBB): {result.obb}")
# 打印推理速度信息
print(f"Speed: {result.speed} ms per image")
# 显示结果图像
result.show()
# 保存检测结果
result.save()
# 打印详细的日志字符串
print(result.verbose())
# 转换结果为 numpy 格式
numpy_result = result.numpy()
print(f"Results as Numpy Arrays: {numpy_result}")
# 将结果转换为 JSON 格式
json_result = result.tojson()
print(f"Results as JSON: {json_result}")会打印丰富的返回信息
python
Class Probabilities: None
Class Names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29:
'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup',
42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
Masks: None
Keypoints: None
Oriented Bounding Boxes (OBB): None
Speed: {'preprocess': 1.9345283508300781, 'inference': 493.81542205810547, 'postprocess': 0.0} ms per image
1 person, 1 car, 1 motorcycle, 1 bus, 6 traffic lights,
Results as Numpy Arrays: ultralytics.engine.results.Results object with attributes:
boxes: ultralytics.engine.results.Boxes object
keypoints: None
masks: None
orig_shape: (897, 1381)
path: 'C:\\Users\\liguopu\\Downloads\\ultralytics-main\\test_image\\test1.jpg'
probs: None
save_dir: None
speed: {'preprocess': 1.9345283508300781, 'inference': 493.81542205810547, 'postprocess': 0.0}二、YOLO11模型推理------实例分割
其实和上面检测的代码,基本是一样的,只需改变模型权重就可以了。
实例分割模型推理的简洁版,示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m-seg.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/test2.jpg", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
masks = result.masks # 获取分割信息
# print("masks:", masks)
result.show() # 显示结果打印信息:
image 1/1 C:\Users\liguopu\Downloads\ultralytics-main\test_image\test2.jpg: 288x640 1 car, 1 truck, 426.0ms
Speed: 0.0ms preprocess, 426.0ms inference, 0.0ms postprocess per image at shape (1, 3, 288, 640)
Results saved to runs\segment\predict4
可视化实例分割的结果,如下图所示:

在coco8-seg/images/val/数据集中,看一下分割的效果
示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m-seg.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/coco8-seg/images/val/", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
masks = result.masks # 获取分割信息
# print("masks:", masks)
result.show() # 显示结果打印信息:
image 1/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\coco8-seg\images\val\000000000036.jpg: 640x512 1 person, 1 umbrella, 772.3ms
image 2/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\coco8-seg\images\val\000000000042.jpg: 480x640 (no detections), 656.2ms
image 3/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\coco8-seg\images\val\000000000049.jpg: 640x512 4 persons, 2 horses, 1 potted plant, 718.2ms
image 4/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\coco8-seg\images\val\000000000061.jpg: 512x640 1 elephant, 695.1ms
Speed: 0.5ms preprocess, 710.4ms inference, 13.9ms postprocess per image at shape (1, 3, 512, 640)
Results saved to runs\segment\predict6
可视化实例分割的结果,如下图所示:


三、YOLO11模型推理------关键点估计
其实和上面检测的代码,基本是一样的,只需改变模型权重就可以了。
关键点估计模型推理的简洁版,示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m-pose.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/test.jpg", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
keypoints = result.keypoints # 获取关键点估计信息
result.show() # 显示结果打印信息
image 1/1 C:\Users\liguopu\Downloads\ultralytics-main\test_image\test.jpg: 384x640 8 persons, 426.2ms
Speed: 0.0ms preprocess, 426.2ms inference, 2.1ms postprocess per image at shape (1, 3, 384, 640)
Results saved to runs\pose\predict9
可视化关键点估计的结果,如下图所示:
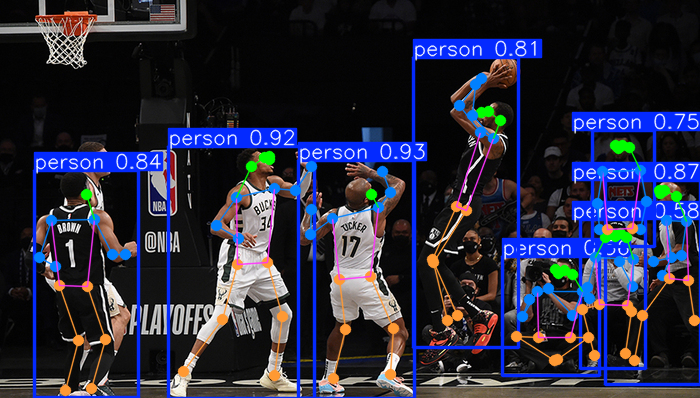
四、YOLO11模型推理------旋转目标检测
其实和上面检测的代码,基本是一样的,只需改变模型权重就可以了。
旋转目标检测模型推理的简洁版,示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m-obb.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/dota8/images/train/", save=True, imgsz=640, conf=0.5)
# 处理返回的结果
for result in results:
obb = result.obb # 获取旋转框信息
result.show() # 显示结果打印信息
image 1/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\dota8\images\train\P0861__1024__0___1648.jpg: 640x640 708.0ms
image 2/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\dota8\images\train\P1053__1024__0___90.jpg: 640x640 662.0ms
image 3/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\dota8\images\train\P1142__1024__0___824.jpg: 640x640 640.9ms
image 4/4 C:\Users\liguopu\Downloads\ultralytics-main\test_image\dota8\images\train\P1161__1024__3296___1648.jpg: 640x640 691.2ms
Speed: 4.8ms preprocess, 675.5ms inference, 10.9ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\obb\predict3
可视化旋转目标检测的结果,如下图所示:
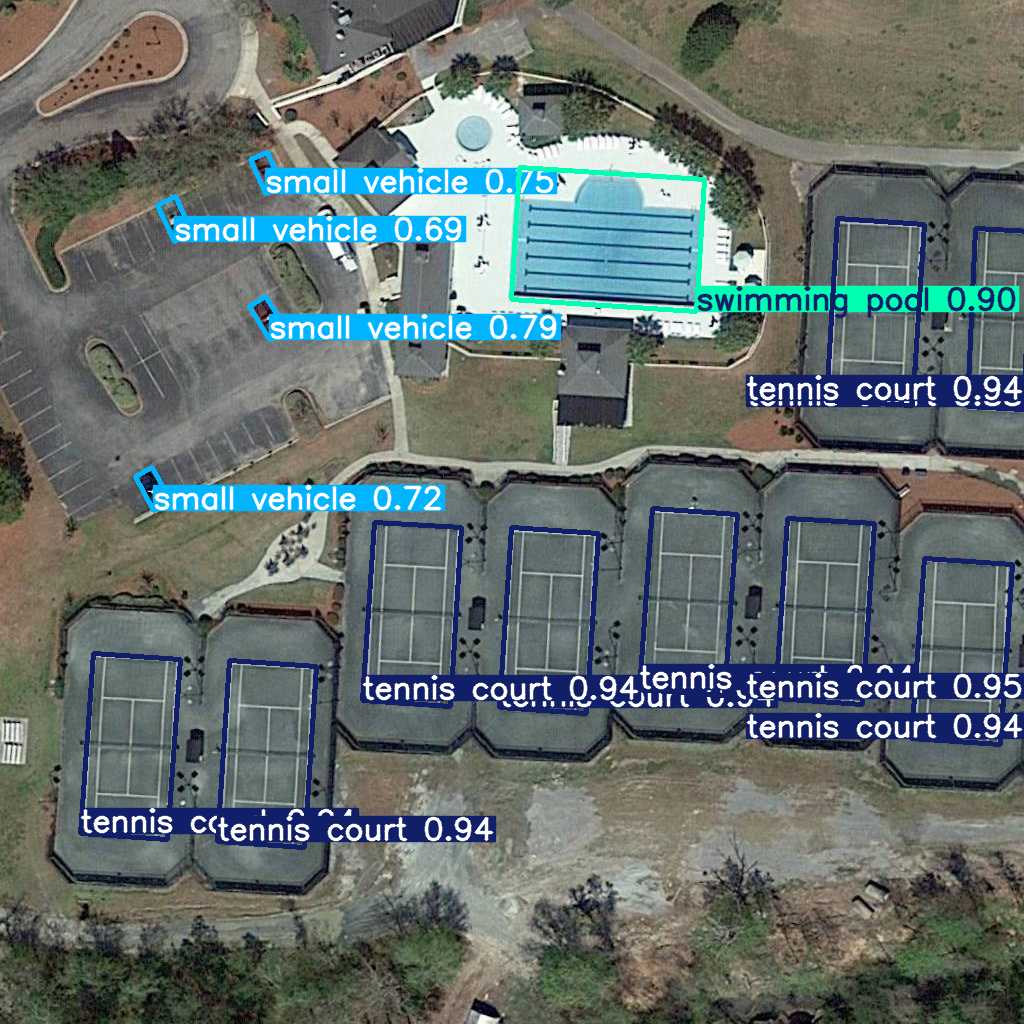
五、YOLO11模型推理------物体分类
其实和上面检测的代码,基本是一样的,只需改变模型权重就可以了。
物体分类模型推理的简洁版,示例代码,如下所示:
python
from ultralytics import YOLO
# 加载预训练的YOLOv11n模型
model = YOLO(r"weights_yolo/yolo11m-cls.pt")
# 对'bus.jpg'图像进行推理,并获取结果
results = model.predict(r"test_image/test.jpg", save=True, conf=0.5)
# 处理返回的结果
for result in results:
probs = result.probs # 获取分类概率
result.show() # 显示结果打印信息
image 1/1 C:\Users\liguopu\Downloads\ultralytics-main\test_image\test.jpg: 224x224 basketball 1.00, ballplayer 0.00, volleyball 0.00, stage 0.00, barbell 0.00, 104.3ms
Speed: 4.7ms preprocess, 104.3ms inference, 0.0ms postprocess per image at shape (1, 3, 224, 224)
Results saved to runs\classify\predict3
可视化分类的结果,如下图所示,识别出来这是篮球(运动)

下面图像中,识别出来是斑马

下面图像中,识别出来多种物体类别

详细模型推理可以参考:https://docs.ultralytics.com/modes/predict/
相关文章推荐:一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理-CSDN博客
分享完成~