背景意义
研究背景与意义
随着全球水上交通的快速发展,海洋运输和水上活动的安全性与效率愈发受到重视。水上交通中涉及的多种物体,如商船、渔船、标志浮标以及其他障碍物,常常对航行安全构成威胁。因此,开发高效的物体检测与图像分割系统,能够实时识别和分类这些物体,成为了提升水上交通安全的重要手段。基于改进YOLOv11的海上场景水上交通物体检测图像分割系统,旨在利用深度学习技术,针对复杂的海洋环境,提供一种高效、准确的解决方案。
本研究所使用的数据集包含3600幅图像,涵盖了13个类别,包括商船、渔船、乘客船、标志浮标等。这些类别的多样性使得模型在训练过程中能够学习到丰富的特征,从而在实际应用中提高识别精度。尤其是在海上场景中,光照变化、波浪干扰以及背景复杂性等因素,都会对物体检测造成挑战。因此,改进YOLOv11模型的设计与训练,将为提升系统的鲁棒性和准确性提供可能。
此外,图像分割技术的引入,使得系统不仅能够识别物体的类别,还能精确地定位物体的边界。这对于后续的水上交通管理、事故预警以及自动驾驶等应用具有重要意义。通过对水上交通环境的深入分析与研究,本项目将为智能水上交通系统的建设提供理论支持和技术保障,推动海洋安全管理的智能化进程。总之,本研究不仅具有重要的学术价值,还有助于提升实际应用中的水上交通安全与效率,具有广泛的社会意义。
图片效果
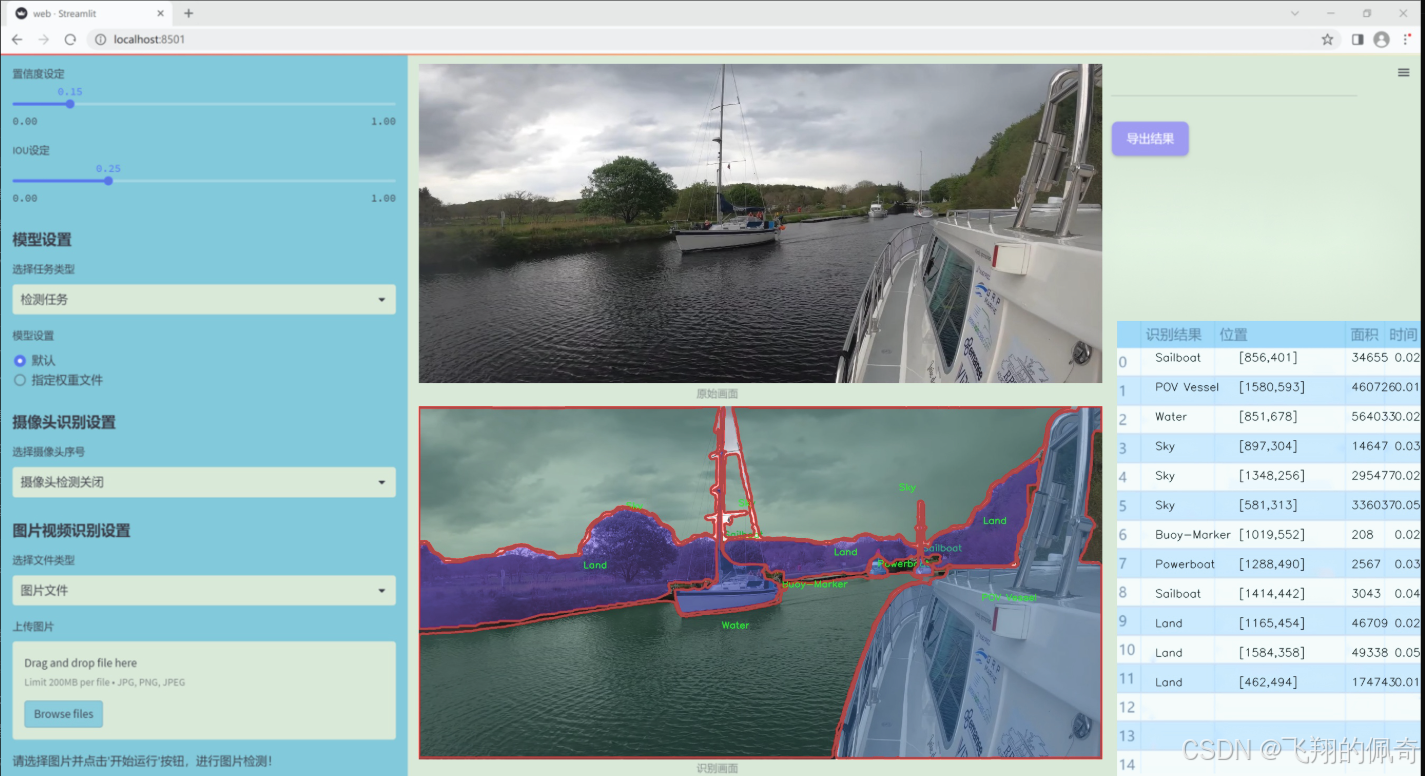
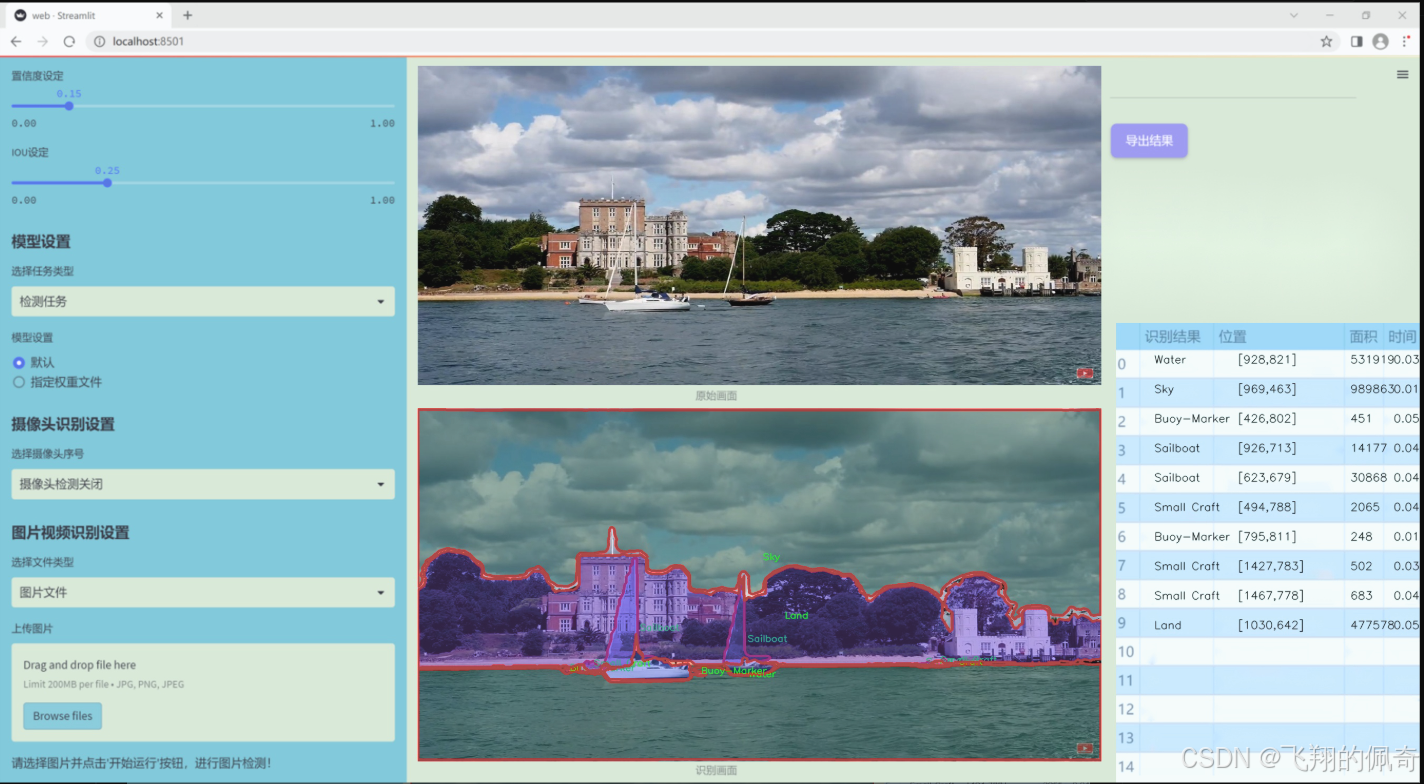
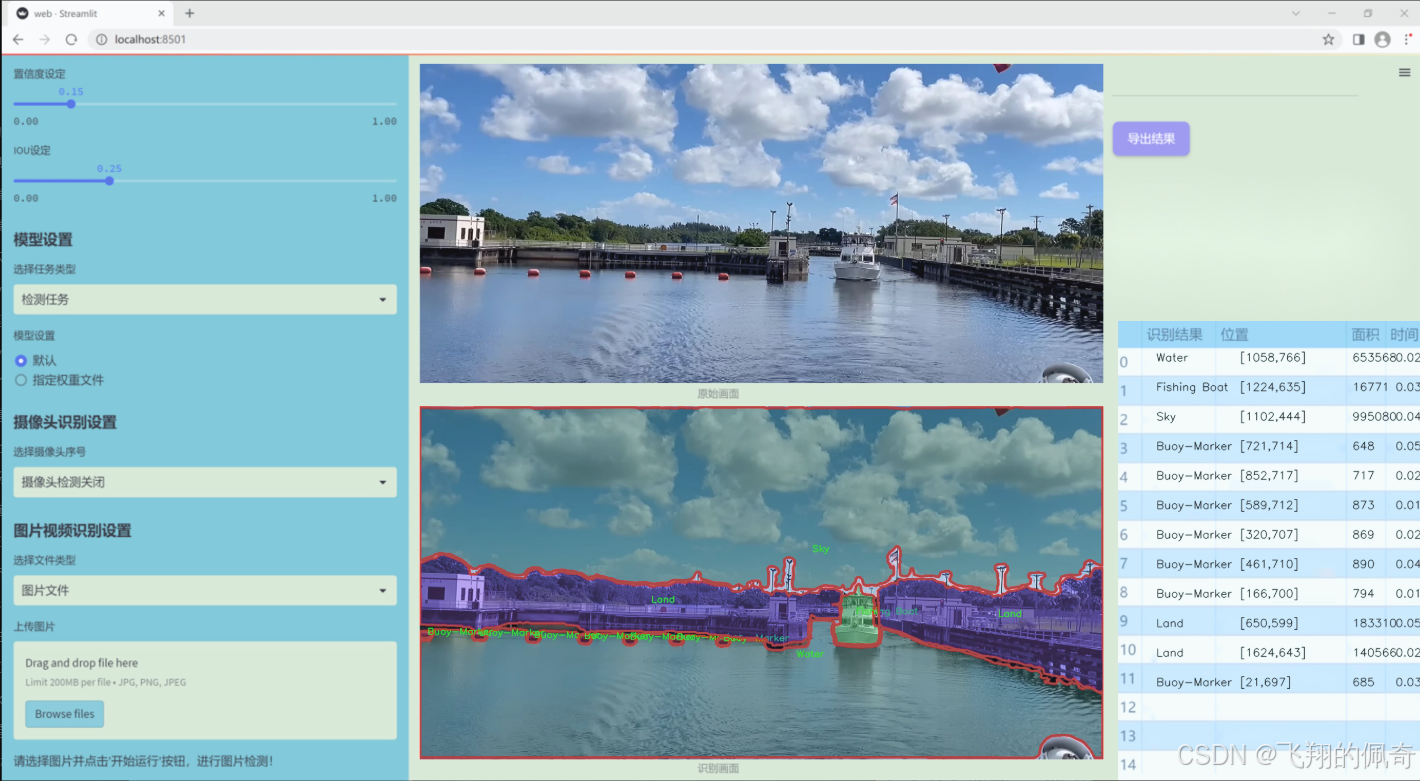
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为"Prototype-Dataset-May",旨在为改进YOLOv11的海上场景水上交通物体检测图像分割系统提供丰富的训练数据。该数据集涵盖了13个类别,具体包括:Buoy-Marker(浮标标记)、Commercial Vessel(商船)、Fishing Boat(渔船)、Land(陆地)、Other Obstacle(其他障碍物)、POV Vessel(视角船只)、Passenger Vessel(客船)、Person(人)、Powerboat(动力艇)、Sailboat(帆船)、Sky(天空)、Small Craft(小型船只)以及Water(水面)。这些类别的多样性确保了模型在不同海上场景中的适应性和准确性。
数据集中的图像均为高分辨率,涵盖了多种天气和光照条件下的海上环境,确保了训练数据的多样性和真实性。每个类别的样本数量经过精心设计,以确保模型在训练过程中能够充分学习到每种物体的特征。此外,数据集还包含了标注信息,提供了每个物体在图像中的精确位置和形状,这对于图像分割任务至关重要。
通过使用"Prototype-Dataset-May"数据集,研究团队能够有效地训练和优化YOLOv11模型,使其在海上交通物体检测中表现出色。该数据集不仅为模型提供了必要的训练基础,还为后续的测试和验证阶段奠定了坚实的基础。随着模型的不断改进,期望能够在实际应用中实现更高的检测精度和更快的响应速度,从而提升海上交通安全和管理效率。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch.nn as nn
import torch
定义一个用于替换BatchNorm层的函数
def replace_batchnorm(net):
for child_name, child in net.named_children():
如果子模块有fuse_self方法,进行融合
if hasattr(child, 'fuse_self'):
fused = child.fuse_self()
setattr(net, child_name, fused)
replace_batchnorm(fused)
如果子模块是BatchNorm2d,替换为Identity层
elif isinstance(child, torch.nn.BatchNorm2d):
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
定义一个函数,用于确保通道数是可被8整除的
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
确保向下取整不会减少超过10%
if new_v < 0.9 * v:
new_v += divisor
return new_v
定义一个包含卷积和BatchNorm的模块
class Conv2d_BN(torch.nn.Sequential):
def init (self, a, b, ks=1, stride=1, pad=0, dilation=1, groups=1, bn_weight_init=1):
super().init ()
添加卷积层
self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))
添加BatchNorm层
self.add_module('bn', torch.nn.BatchNorm2d(b))
初始化BatchNorm的权重
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse_self(self):
# 融合卷积层和BatchNorm层
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m定义残差模块
class Residual(torch.nn.Module):
def init (self, m, drop=0.):
super().init ()
self.m = m # 模块
self.drop = drop # 丢弃率
def forward(self, x):
# 在训练时根据丢弃率决定是否添加残差
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1, device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
@torch.no_grad()
def fuse_self(self):
# 融合残差模块
if isinstance(self.m, Conv2d_BN):
m = self.m.fuse_self()
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
m.weight += identity.to(m.weight.device)
return m
else:
return self定义RepViTBlock模块
class RepViTBlock(nn.Module):
def init (self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(RepViTBlock, self).init ()
assert stride in 1, 2
self.identity = stride == 1 and inp == oup # 判断是否为身份映射
assert(hidden_dim == 2 * inp) # 隐藏层维度为输入维度的两倍
if stride == 2:
# 如果步幅为2,构建token混合和通道混合
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
self.channel_mixer = Residual(nn.Sequential(
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),
))
else:
assert(self.identity)
self.token_mixer = nn.Sequential(
RepVGGDW(inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
self.channel_mixer = Residual(nn.Sequential(
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
))
def forward(self, x):
return self.channel_mixer(self.token_mixer(x))定义RepViT模型
class RepViT(nn.Module):
def init (self, cfgs):
super(RepViT, self).init ()
self.cfgs = cfgs # 配置参数
input_channel = self.cfgs02 # 输入通道数
构建第一个层
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
layers = patch_embed
构建反向残差块
block = RepViTBlock
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.ModuleList(layers)
def forward(self, x):
for f in self.features:
x = f(x)
return x示例:构建RepViT模型
if name == 'main ':
cfgs = [
k, t, c, SE, HS, s
3, 2, 64, 1, 0, 1,
3, 2, 64, 0, 0, 1,
更多配置...
]
model = RepViT(cfgs) # 创建模型实例
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码核心部分解释:
BatchNorm替换:replace_batchnorm函数用于将模型中的BatchNorm层替换为Identity层,以便在推理时加速计算。
可被8整除的通道数:_make_divisible函数确保网络中所有层的通道数都是8的倍数,以符合特定的硬件要求。
卷积和BatchNorm组合:Conv2d_BN类封装了卷积层和BatchNorm层,并提供了融合的方法。
残差连接:Residual类实现了残差连接的逻辑,允许在训练时使用随机丢弃。
RepViTBlock:这是RepViT模型的基本构建块,负责处理输入特征的混合和通道的转换。
RepViT模型:RepViT类构建了整个模型,接受配置参数并按顺序添加各个块。
通过这些核心部分的组合,构建了一个高效的视觉Transformer模型。
这个程序文件 repvit.py 实现了一个基于 RepVGG 架构的视觉模型,结合了深度学习中的卷积神经网络(CNN)和注意力机制。代码中使用了 PyTorch 框架,并且包含了一些特定的模块和功能,以下是对代码的详细讲解。
首先,文件导入了必要的库,包括 PyTorch 的神经网络模块 torch.nn、NumPy 以及 timm 库中的 SqueezeExcite 模块。all 列表定义了可以被外部导入的模型名称。
接下来,定义了一个 replace_batchnorm 函数,用于在模型中替换掉所有的 Batch Normalization 层。这是为了在推理阶段提高模型的效率,通过将卷积层和 Batch Normalization 层融合成一个卷积层来减少计算量。
_make_divisible 函数用于确保模型中所有层的通道数都是可被 8 整除的,这对于某些硬件加速器的优化是必要的。
Conv2d_BN 类继承自 torch.nn.Sequential,它将卷积层和 Batch Normalization 层组合在一起,并提供了一个 fuse_self 方法,用于融合这两个层以提高推理速度。
Residual 类实现了残差连接,允许输入通过一个模块后与原始输入相加,支持在训练时随机丢弃部分输出以增强模型的鲁棒性。
RepVGGDW 类实现了一个特定的卷积块,结合了深度可分离卷积和残差连接,允许通过融合方法优化推理性能。
RepViTBlock 类是模型的基本构建块,包含了通道混合和令牌混合的功能,使用了 SqueezeExcite 模块来增强特征表达能力。
RepViT 类是整个模型的主体,负责构建网络结构。它根据配置列表构建多个 RepViTBlock,并在前向传播中提取特征。
switch_to_deploy 方法用于将模型切换到推理模式,主要是调用 replace_batchnorm 函数来优化模型。
update_weight 函数用于更新模型的权重,确保新权重与模型的结构匹配。
最后,定义了多个函数(如 repvit_m0_9, repvit_m1_0, 等),这些函数用于构建不同配置的 RepViT 模型,并可以选择加载预训练权重。
在 main 部分,示例代码展示了如何实例化一个模型并进行前向传播,输入为一个随机生成的张量,输出则是模型在不同层的特征图的尺寸。
整体来看,这个文件实现了一个灵活且高效的视觉模型,适用于各种计算机视觉任务,并且通过合理的设计和模块化的实现,提高了模型的可维护性和可扩展性。
10.4 activation.py
import torch
import torch.nn as nn
class AGLU(nn.Module):
"""AGLU激活函数模块,来自https://github.com/kostas1515/AGLU。"""
def __init__(self, device=None, dtype=None) -> None:
"""初始化AGLU激活函数模块。"""
super().__init__()
# 使用Softplus作为基础激活函数,beta设置为-1.0
self.act = nn.Softplus(beta=-1.0)
# 初始化lambda参数,并将其设置为可学习的参数
self.lambd = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # lambda参数
# 初始化kappa参数,并将其设置为可学习的参数
self.kappa = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # kappa参数
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""计算AGLU激活函数的前向传播。"""
# 将lambda参数限制在最小值0.0001,以避免数值不稳定
lam = torch.clamp(self.lambd, min=0.0001)
# 计算AGLU激活函数的输出
return torch.exp((1 / lam) * self.act((self.kappa * x) - torch.log(lam)))代码注释说明:
AGLU类:定义了一个自定义的激活函数模块,继承自nn.Module。
初始化方法__init__:
self.act:使用Softplus作为基础激活函数。
self.lambd和self.kappa:这两个参数是可学习的,初始化为均匀分布的随机值,并使用nn.Parameter使其成为模型的一部分。
前向传播方法forward:
lam:对lambd参数进行限制,确保其不小于0.0001,以避免在后续计算中出现数值不稳定。
返回值:计算并返回AGLU激活函数的输出,公式中结合了Softplus激活和参数lambda与kappa的影响。
这个程序文件定义了一个名为 activation.py 的模块,主要用于实现一种统一的激活函数,称为 AGLU(Adaptive Gated Linear Unit)。该模块使用了 PyTorch 框架,包含了一个名为 AGLU 的类,继承自 nn.Module,这是 PyTorch 中所有神经网络模块的基类。
在 AGLU 类的初始化方法 init 中,首先调用了父类的构造函数 super().init(),以确保正确初始化基类。接着,定义了一个激活函数 self.act,使用了 nn.Softplus,其参数 beta 被设置为 -1.0。Softplus 是一种平滑的激活函数,类似于 ReLU,但在零附近更加平滑。
此外,类中还定义了两个可学习的参数 self.lambd 和 self.kappa,它们分别用于控制激活函数的行为。这两个参数通过 nn.Parameter 声明,并使用 torch.init.uniform_ 方法进行初始化,确保它们在给定的设备和数据类型上随机生成。
在 forward 方法中,定义了前向传播的计算过程。输入参数 x 是一个张量,表示神经网络的输入。在方法内部,首先对 self.lambd 进行限制,确保其值不小于 0.0001,以避免在后续计算中出现除以零的情况。然后,使用公式计算激活值:首先计算 self.kappa * x,再减去 torch.log(lam),最后将结果传入 self.act,并根据 lam 的值进行指数运算,得到最终的激活输出。
总体来说,这个模块实现了一种新的激活函数,结合了可学习的参数,旨在提高神经网络的表现。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻