文章目录
- [1 概述](#1 概述)
- [2 模型说明](#2 模型说明)
-
- [2.1 总体架构](#2.1 总体架构)
- [2.2 轻量pixel decoder](#2.2 轻量pixel decoder)
- [2.3 实例激活引导的Query](#2.3 实例激活引导的Query)
- [2.4 双路径更新策略](#2.4 双路径更新策略)
- [2.5 GT掩码引导学习](#2.5 GT掩码引导学习)
- [2.6 损失函数](#2.6 损失函数)
- [3 效果](#3 效果)
1 概述
FastInst是一种基于query的实时实例分割方法,它能以32.5FPS的实时速度在COCO测试集上达到40.5的AP。在实例分割领域,基于query的方法源自Mask2former,FastInst也不例外,它也沿用了MaskFormer的大架构。其核心设计包括:
(1)实例激活引导的Query
(2)双路径更新策略
(3)GT掩码引导学习
这些设计使FastInst能够使用更轻量的像素解码器和更少的 Transformer 解码器层,同时获得更优的性能。
2 模型说明
2.1 总体架构
如图2-1-1所示的左半部分所示,FastInst和MaskFormer一样,网络结构上主要分为三大部分,分别是Backbone、Pixel decoder和Transformer decoder。
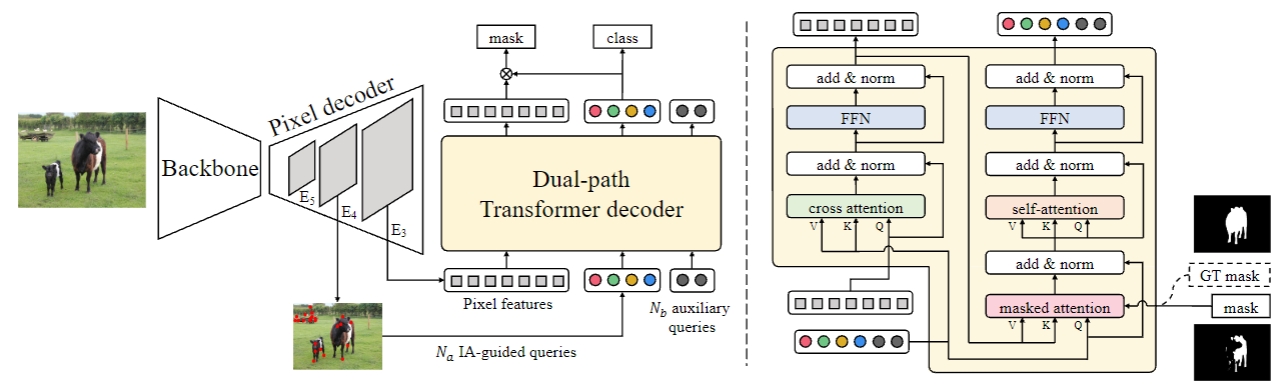
图2-1-1 模型总体架构示意图
假设网络的输入为 I ∈ R H × W × 3 I \in R^{H \times W \times 3} I∈RH×W×3,经过Backbone之后,可以得到下采样8倍、16倍和32倍的特征图 C 3 C_3 C3、 C 4 C_4 C4和 C 5 C_5 C5,此时这三个特征的shape可以表示为 B a t c h S i z e , 2048 , H 8 , W 8 BatchSize, 2048, \\frac{H}{8}, \\frac{W}{8} BatchSize,2048,8H,8W、 B a t c h S i z e , 1024 , H 16 , W 16 BatchSize, 1024, \\frac{H}{16}, \\frac{W}{16} BatchSize,1024,16H,16W和 B a t c h S i z e , 512 , H 32 , W 32 BatchSize, 512, \\frac{H}{32}, \\frac{W}{32} BatchSize,512,32H,32W。
这三个特征就是pixel decoder的输入,输出对应的三个特征图 E 3 E_3 E3、 E 4 E_4 E4和 E 5 E_5 E5。 C 3 C_3 C3、 C 4 C_4 C4和 C 5 C_5 C5经过 1 × 1 1 \times 1 1×1的卷积,统一将通道数变为256,此时的shape仍旧是 B a t c h S i z e , 256 , H 8 , W 8 BatchSize, 256, \\frac{H}{8}, \\frac{W}{8} BatchSize,256,8H,8W、 B a t c h S i z e , 256 , H 16 , W 16 BatchSize, 256, \\frac{H}{16}, \\frac{W}{16} BatchSize,256,16H,16W和 B a t c h S i z e , 256 , H 32 , W 32 BatchSize, 256, \\frac{H}{32}, \\frac{W}{32} BatchSize,256,32H,32W。然后,从 E 4 E_4 E4特征图中选取 N a N_a Na个实例激活引导查询,并于 N b N_b Nb个辅助可学习查询连接,作为最终的总查询 Q ∈ R N × 256 Q \in R^{N \times 256} Q∈RN×256,其中 N = N a + N b N=N_a+N_b N=Na+Nb。
Transformer decoder将 Q Q Q和高分辨率像素特征图 E 3 E_3 E3作为输入,以双路径的方式更新像素特征 Q Q Q和 E 3 E_3 E3,并在每个解码器层预测对象类别和分割掩码。
2.2 轻量pixel decoder
多尺度上下文特征图对于图像分割至关重要。然而,使用复杂的多尺度特征金字塔(FPN)会增加计算负担。与直接采用pixel decoder输出的底层特征图的先前方法不同,FastInst使用 Transformer decoder中经过精炼的像素特征来生成分割掩码。这种设置降低了pixel decoder对大量上下文聚合的需求,因此使用轻量级的pixel decoder模块就够了。换句话说,也就是主力在Transformer decoder了,pixel decoder搞得简单点就行了。
为了在精度和速度之间取得更好的平衡,FastInst使用一种名为 PPM-FPN 的变体来替代普通的 FPN。
pixel decoder的示意图如下图2-2-1所示(假设整个网络的的输入为 I ∈ R 1024 × 1024 × 3 I \in R^{1024 \times 1024 \times 3} I∈R1024×1024×3),PPM只作用于 C 5 C_5 C5的特征,这里的CBR指的就是Conv, BN, Relu。
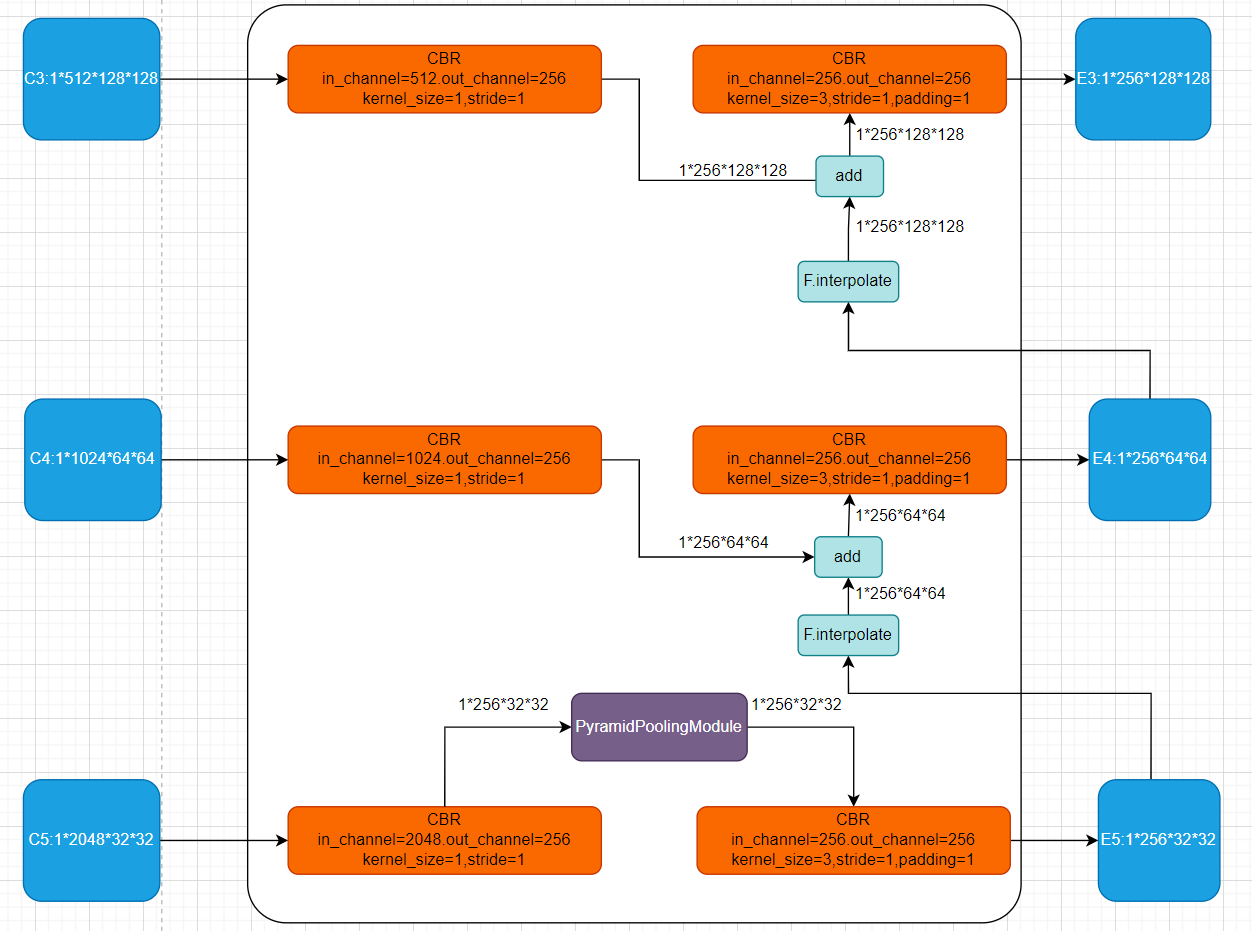
图2-2-1 轻量解码器示意图
2.3 实例激活引导的Query
基于Query的这种方式最初来自于DETR,但是DETR的Query是全零初始化的,所以其收敛速度很慢。收到Deformable DETR的启发,作者提出了一种实例激活引导的Query,直接从多尺度的特征图上选取包含高级语义的Queries。具体来说,给定pixel decoder的输出特征图,在特征图 E 4 E_{4} E4上添加一个辅助分类头,随后进行softmax激活,以生成每个像素的类别概率预测 p i ∈ Δ K + 1 p_{i} \in \Delta^{K+1} pi∈ΔK+1,其中 Δ K + 1 \Delta^{K+1} ΔK+1是 ( K + 1 ) (K+1) (K+1)维概率单纯形, K K K是类别数,为"无目标"(∅)增加了一个类别,i是像素索引,辅助分类头分别由两个内核大小为 3 × 3 3×3 3×3和 1 × 1 1×1 1×1的卷积层组成。通过 p i p_{i} pi,获得每个像素的前景概率 p i , k i p_{i, k_{i}} pi,ki、 k i = a r g m a x k { p i , k ∣ p i , k ∈ p i , k ∈ 1 , ⋯ , K } k_{i}=argmax_{k}\{{p_{i, k} | p_{i, k} \in p_{i}, k \in}{1, \cdots, K}\} ki=argmaxk{pi,k∣pi,k∈pi,k∈1,⋯,K}。这里有点对特征图进行语义分割的味道。
然后,从特征图 E 4 E_{4} E4中选择具有高前景概率的 N a N_{a} Na个像素嵌入作为目标查询。在这里,首先选择在相应类别平面中具有八邻域内局部最大值的那些点,然后在 p i , k i i {p_{i, k_{i}}}_{i} pi,kii中选择具有最高前景概率的那些点。这里默认了特征图上相邻像素点为同一个类别时,他们表示的是同一个实例,这在大部分情况下是成立的,但是对于紧密贴合的同类别小面积实例是有风险的。这样做还有一点好处就是防止最终 N a N_a Na个Queries都集中在某一块置信度较高的前景区域。
在训练过程中,应用基于匹配的匈牙利损失来监督辅助分类头,记作 L I A − q L_{IA-q} LIA−q。与DETR不同,FastInst仅使用类别预测和位置成本 L l o c L_{loc} Lloc来计算分配成本。位置成本 L l o c L_{loc} Lloc被定义为一个指示函数,当像素位于该物体的区域内时为0;否则为1。这种成本背后的直觉是,只有落在物体内部的像素才有理由推断该物体的类别和掩码嵌入。此外,位置成本减少了二分匹配空间并加速了训练收敛。
使用这种匹配方式,就是为了让每个GT掩码只对应于一个特征点。另一种比较直觉的方式是直接对掩码所对应的区域进行交叉熵损失计算,这样每个GT掩码就对应于一片特征点了,不利于后续topk的筛选,可能会被一个概率高的区域主导。所以还是需要二分匹配。
将通过上述策略生成的Queries称为实例激活引导(IA引导)的查询。与零初始化Queries相比,IA引导的查询在初始阶段就包含了关于潜在对象的丰富信息,并提高了Transformer decoder中查询迭代的效率。
其实,这个策略也可以在 E 3 E_{3} E3或者 E 5 E_{5} E5上进行,更大的特征图包含更丰富的实例线索,但计算负担更重。为了权衡,作者使用中等大小的特征图 E 4 E_{4} E4。
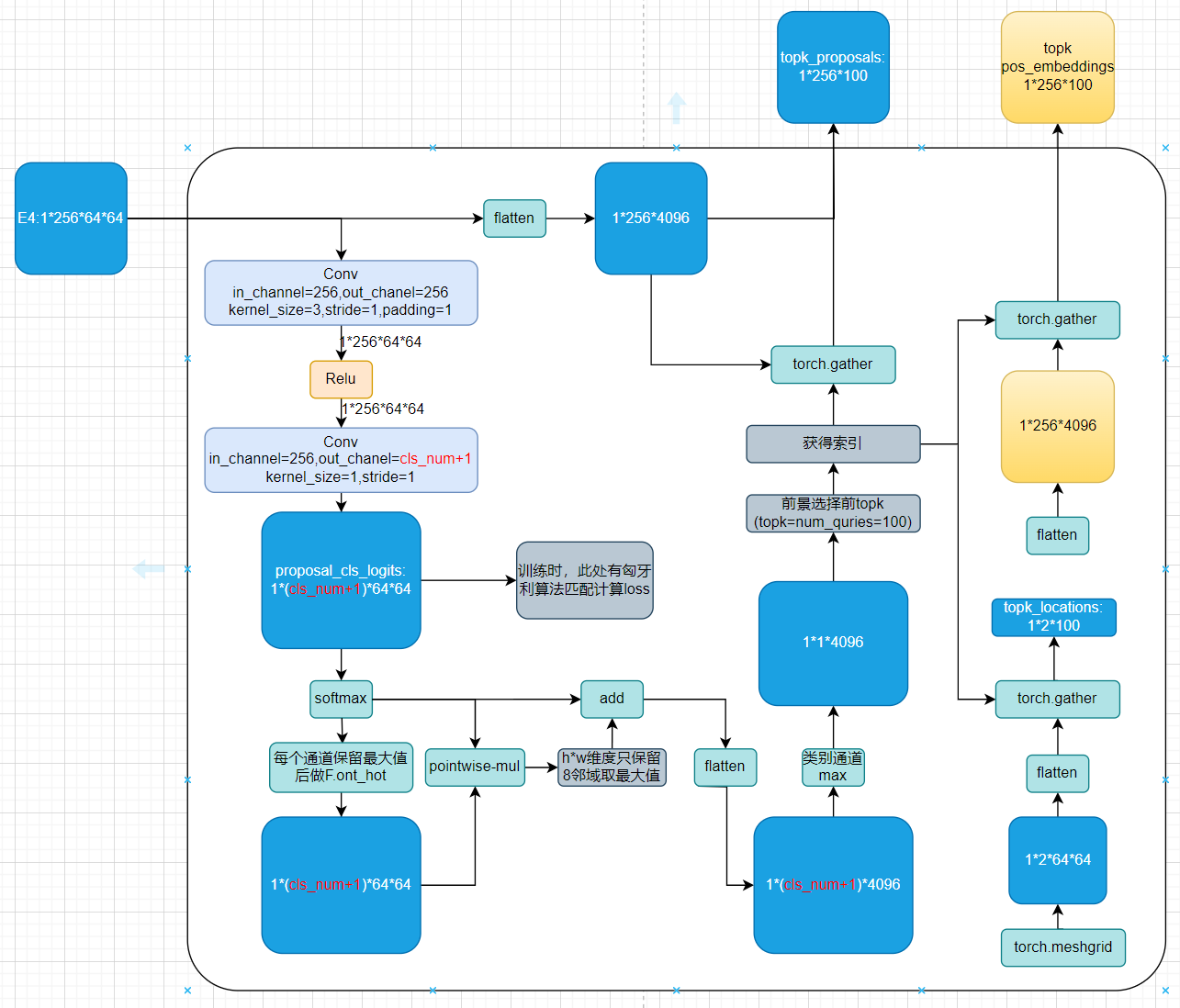
图2-3-1 实例激活引导的Query示意图
2.4 双路径更新策略
在从特征图中选择 N a N_{a} Na个由实例激活引导的Queries后,将它们与 N b N_{b} Nb个辅助可学习Queries连接起来,以获得总查询Q,其中辅助可学习Queries用于在后续的双重更新过程中促进背景像素特征的分组,并提供通用的与图像无关的信息。然后,将总查询Q与展平的1/8高分辨率像素特征 E 3 E_3 E3输入到Transformer decoder中。在Transformer decoder中,为查询Q和像素特征 E 3 E_3 E3添加位置嵌入,随后经过连续的Transformer decoder层对它们进行更新。一个Transformer decoder层包含一次像素特征更新和一次查询更新。整个过程类似于EM(期望最大化)聚类算法。E步:根据像素特征所属的中心(Query)更新像素特征;M步:更新聚类中心(Query)。与单路径更新策略相比,双路径更新策略共同优化像素特征和Query,减少了对重型pixel decoder的依赖,并获得了更细粒度的特征嵌入。最后,使用细化后的像素特征和查询来预测每一层的目标类别和分割掩码。
(1)位置编码
位置编码是非常重要的信息,特别是对于不同位置但类别相同的物体而言。本文使用一个固定尺寸的可学习位置嵌入向量 P ∈ R S × S × 256 P \in R^{S \times S \times 256} P∈RS×S×256,其中 S S S作者根据经验设定为 N a \sqrt{N_a} Na ,比如 N a = 100 N_a=100 Na=100,则 P ∈ R 10 × 10 × 256 P \in R^{10 \times 10 \times 256} P∈R10×10×256。如果某个特征图需要使用位置编码,则将 P P P上采样到对应的尺寸即可。
官方对应的代码为
python
pixel_pos_embeds = F.interpolate(self.meta_pos_embed, size=pixel_feature_size,
mode="bilinear", align_corners=False)
proposal_pos_embeds = F.interpolate(self.meta_pos_embed, size=proposal_size,
mode="bilinear", align_corners=False)其中,self.meta_pos_embed就是 P P P,也就是所有的特征图都共用一个可学习的位置编码。作者认为,这种方式可以在不影响模型效果的前提下,提高模型的推理速度。实际情况下, P P P作用于两种特征,一种是从 E 3 E_3 E3得到的像素特征,也即是图2-1-1中的pixel features;另一种是从 E 4 E_4 E4得到的 N a N_a Na个实例激活引导的Queries,也即是图2-1-1中的 N a N_a Na IA-guided features。
对于 N b N_{b} Nb个辅助可学习Queries而言,使用了额外的可学习位置编码,shape为 N b × 256 N_b \times 256 Nb×256。这是因为 N b N_{b} Nb个辅助可学习Queries学习到的Queries对应的位置,我们并不知道。
(2)像素特征更新
首先更新像素特征。给定展平的像素特征 X X X(最开始就是 E 3 E_3 E3)和查询 Q Q Q,像素特征更新的流程包括一个交叉注意力层和一个前馈层,如图2-1-1右侧所示。在每个交叉注意力层,都会将位置嵌入添加到query和key中。在更新像素特征时,不使用自注意力,因为像素特征的序列较长,自注意力会带来巨大的计算和内存成本。全局特征可以通过对query的交叉注意力进行聚合。
假设输入的 X X X的shape为 N , 256 N, 256 N,256, Q Q Q的shape为 100 + N b , 256 100+N_b, 256 100+Nb,256, N N N要比 100 + N b 100+N_b 100+Nb大得多。像素特征更新是,将 X X X作为query, Q Q Q作为key和value。经过cross attention之后, X X X会被替换更新,输出的shape仍为 N , 256 N, 256 N,256。也就是对于每一个query,都可以通过key对value进行加权求和,换句话说, X X X会被 Q Q Q中与其相似的特征加权求和更新。
看到这里,我们其实可以进一步理解为什么作者要增加 N b N_{b} Nb个辅助可学习Queries,因为 N a N_a Na里的都是前景特征,而 X X X中既有前景,又有背景,在更新 X X X时,不能只使用前景特征的加权求和得到,需要一些反应背景的特征的加权求和,这个反应背景的特征就是 N b N_{b} Nb个辅助可学习Queries。
(3)Query更新
作者像Mask2Former中那样,使用掩码注意力,随后再使用自注意力和前馈网络来进行Query更新。掩码注意力将每个Query的注意力限制在仅关注前一层预测掩码的前景区域内,而上下文信息则被假设通过后续的自注意力来收集。这种设计显著提升了基于Query的模型在图像分割任务中的性能。在此,位置嵌入同样会被添加到每个掩码注意力层和自注意力层的query与key中。
这里的masked attention中使用的mask会在2.5中进一步说明。
(4)预测
作者在每个decoder layer中,使用两个独立的三层MLPs作用于细化后的实例激活引导queries来预测物体的类别和mask embeddings。每个实例激活引导查询(IA-guided query)都需要预测所有目标类别的概率,包括 "无目标"(∅)类别。作者对经过精炼的mask features进行线性投影以获得掩码特征。然后,将mask embeddings与mask features相乘,得到每个query对应的分割掩码。此处,每个 Transformer decoder层中多层感知机(MLPs)和线性投影的参数是不共享的,因为query和pixel features会交替更新,且在不同的解码器层中,它们的特征可能处于不同的表征空间。此外,实例分割需要为每个预测结果提供一个置信度分数用于评估。作者沿用先前的工作的方法,将类别概率分数与掩码分数(即前景区域内掩码概率的平均值)相乘,作为最终的置信度分数。
2.5 GT掩码引导学习
mask attention的方法是以模型之前预测的mask作为先验来对attention进行掩码的,如果这个mask学习的不好,会影响之后的学习效果。为缓解这一问题,作者引入了GT掩码引导学习。首先,使用最后一层的二分匹配GT真值掩码替换第 l l l层掩码注意力中使用的预测掩码。对于在最后一层中未匹配到任何实例的Query(包括辅助可学习查询),采用标准的交叉注意力,即
M i l = { M j g t i f ( i , j ) ∈ σ ∅ o t h e r w i s e (2-5-1) M^l_i = \begin{cases} M^{gt}_j & if (i, j) \in \sigma \\ \empty & otherwise \end{cases} \tag{2-5-1} Mil={Mjgt∅if(i,j)∈σotherwise(2-5-1)
其中, M i l M^l_i Mil是第 i i i个query在第 l l l层的注意力掩码, σ = { ( i , j ) ∣ i ∈ { 1 , . . . , N a } , j ∈ { 1 , . . . , N o b j } } \sigma = \{ (i, j) | i \in \{ 1, ..., N_a \}, j \in \{ 1, ..., N_{obj} \} \} σ={(i,j)∣i∈{1,...,Na},j∈{1,...,Nobj}}是decoder最后一层的匹配关系,并且 M j g t M^{gt}j Mjgt是第 i i i个query在最后一层匹配到的GT掩码。 N o b j N{obj} Nobj表示GT目标的数量。
然后,使用该注意力掩码 M l M^l Ml来进行masked attention。图2-1-1右侧所示的结构会重复多次,每一次都输入是上一次的输出。新的一轮根据固定匹配 σ σ σ对新输出进行监督,也就是 σ σ σ的匹配过程只在第一次进行。这种固定匹配确保了每个Transformer decoder层的预测的一致性,并在训练过程中节省了匹配的计算成本。通过这样的指导学习,允许每个query在训练期间看到其目标的整个区域预测对象,这有助于掩码注意力在更合适的前景区域内进行。
2.6 损失函数
FastInst的整个损失函数可以写作
L = L I A − q + L p r e d + L p r e d ′ (2-6-1) L = L_{IA-q} + L_{pred} + L'_{pred} \tag{2-6-1} L=LIA−q+Lpred+Lpred′(2-6-1)
其中, L I A − q L_{IA-q} LIA−q就是2.3中提到的辅助分类头损失,也就是先使用匈牙利匹配,后进行交叉熵损失。
L p r e d L_{pred} Lpred定义为
L p r e d = ∑ i = 0 D ( λ c e L c e i + λ d i c e L d i c e i ) + λ c l s L c l s i (2-6-2) L_{pred} = \sum^D_{i=0} (\lambda_{ce} L^i_{ce} + \lambda_{dice} L^i_{dice}) + \lambda_{cls} L^i_{cls} \tag{2-6-2} Lpred=i=0∑D(λceLcei+λdiceLdicei)+λclsLclsi(2-6-2)
其中, D D D表示Transformer decoder的层数,并且 i = 0 i=0 i=0表示在进入Transformer decoder之前的prediction损失。 L c e i L^i_{ce} Lcei和 L d i c e i L^i_{dice} Ldicei分别表示分割任务的二元交叉熵损失和dice损失。 L c l s L_{cls} Lcls表示类别交叉熵损失。同样,利用匈牙利算法来寻找目标分配的最佳匹配。对于匹配成本,为每个query添加了额外的位置成本 λ l o c L l o c λ_{loc}L_{loc} λlocLloc。
L p r e d ′ L'{pred} Lpred′表示GT掩码引导的损失,与 L p r e d L{pred} Lpred相似。区别是它不计算第0层的损失,并使用固定的二分匹配结果。 L p r e d L_{pred} Lpred是使用模型预测的掩码引导的, L p r e d ′ L'_{pred} Lpred′是GT掩码引导的。
3 效果
FastInst和其他模型的效果对比可见表3-1。其中,FastInst-D1表示一层transformer decoder层,FastInst-D3表示三层transformer decoder层,层数速度越慢,但是精度越高。
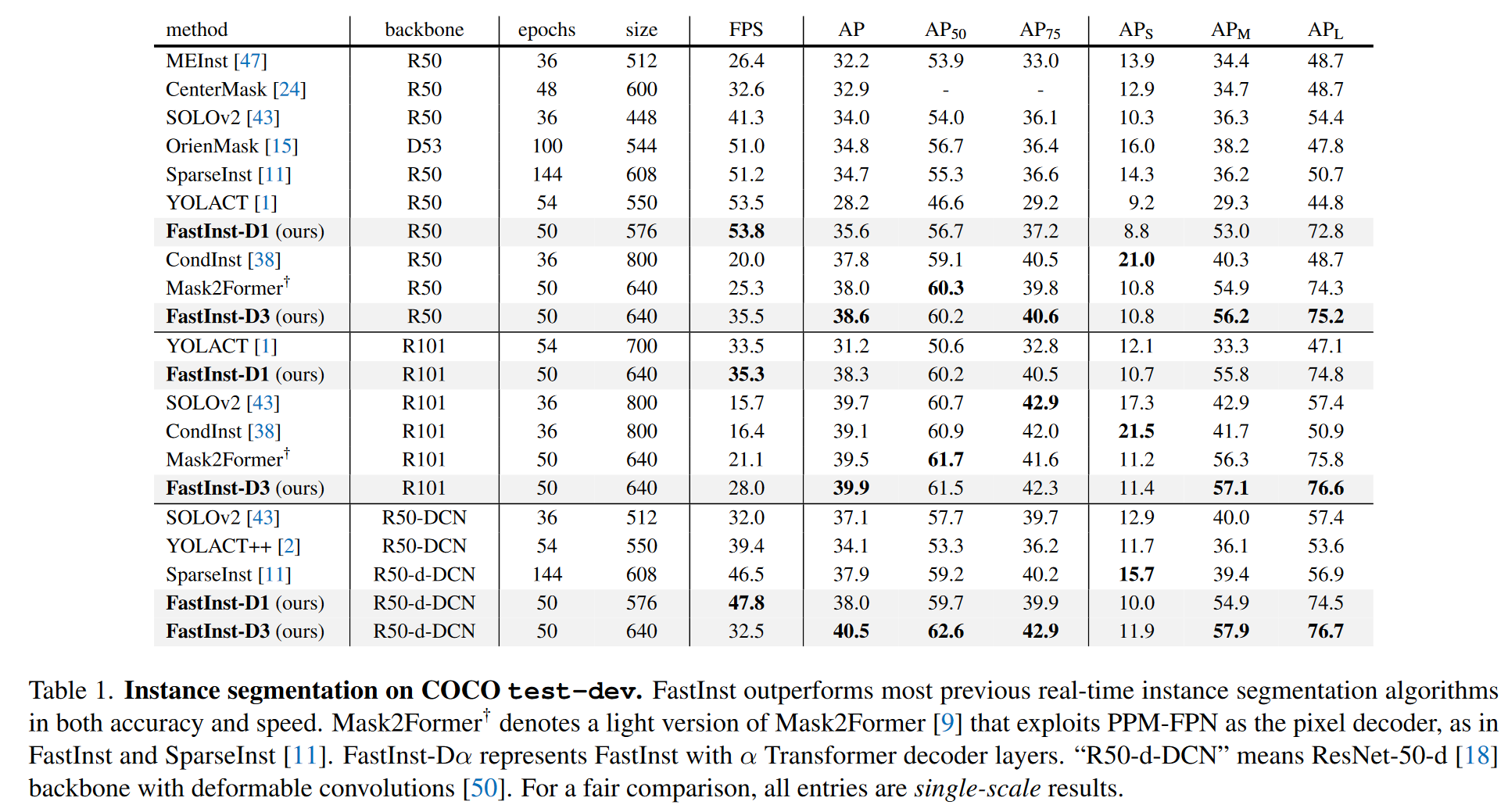
表3-1 FastInst和其他模型效果对比
图3-1是实例激活引导的query的可视化结果。第一行和第二行显示了实例激活引导的query的分布,对辅助分类头部的监督损失不同。
第一列:密集的像素语义分类损失
第二列:基于二分匹配的匈牙利损失,没有位置成本
第三列:基于二分的匹配匈牙利损失,有位置成本
第四列:GT
本文设计的损失(第三列)下的查询点更集中于每个前景对象的区域。最后一行显示四个预测的掩码(蓝色),具有相应的实例激活引导query位置(红色)。

图3-1 实例激活引导的query的可视化结果