Meta 发布了 Llama 3 模型的新版本;这次,有四种模型用于不同的目的:两个多模态模型,Llama 3.2 11B 和 90B,以及两个用于边缘设备的小型语言模型,1B 和 3B。
这些是 Meta AI 的首批多模态模型,基准测试表明它们是小型和中型专有替代品的强大竞争对手。我不太喜欢 LLM 基准测试;它们往往具有误导性,可能无法代表现实世界的表现。但是,你可以在官方博客文章中查看结果。
我想在我每天经常遇到的最常见的视觉任务上测试该模型,并将其性能与我的首选 GPT-4o 进行比较。
我关注的任务包括:
- 基本图像理解
- 医疗处方和报告分析
- 从图像中提取文本
- 财务图表解释

NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、一般图像理解
本节包含一般图像理解、计数和识别对象等的示例。
1.1 Frieren的吃汉堡的图像
因此,我从 Frieren 吃汉堡的著名图像开始。以下是 GPT-4o(左)和 Llama3.2(右)的回应。
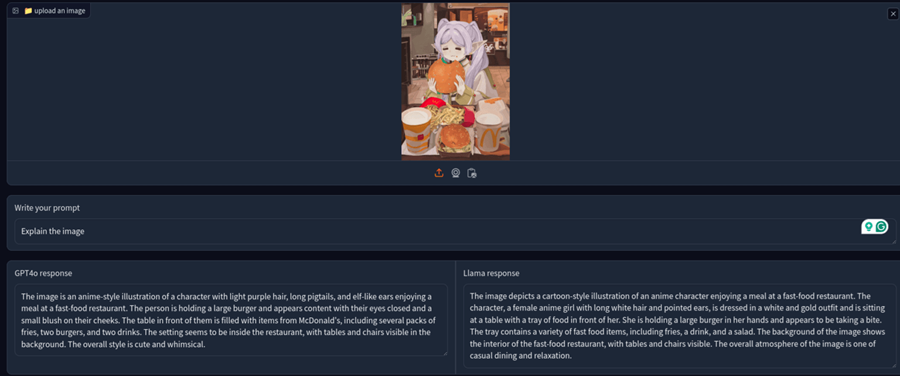
两个回应都同样好,但 GPT4o 可以正确显示麦当劳的标志。
1.2 统计物体的数量
接下来,让我们看看它是否能正确计算图像中的物体数量。让我们从一个简单的图像开始。

两个模型都能够正确回答。
现在,让我们让它变得有点困难。
我要求两个模型计算图像中的叉子数量。

令人惊讶的是,Llama 3.2 可以正确回答,而 GPT4o 忽略了桌子上没有立即可见的叉子。
接下来,我让他们数一数杯子的数量并解释它们的形状。

两者都给出了正确的数字。Gpt4o 的描述要好得多,眼镜的形状得到了正确的解释。另一方面,Llama 3.2 的描述部分正确。
视觉语言模型的一个广泛用例是识别任何架子工具并要求它解释其功能。
所以,我要求模型识别------这个实用工具。
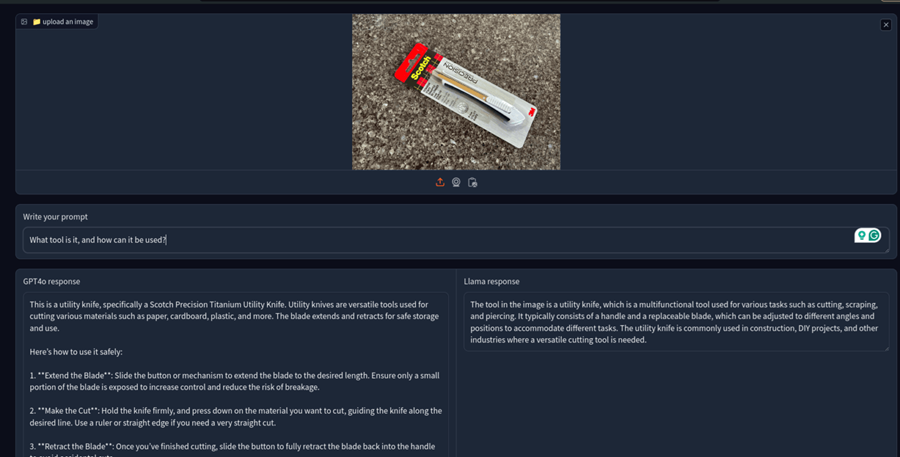
两者都做得很好,但 Gpt-4o 更详细、信息量更大。
1.3 叶病诊断
让我们更进一步,让模型从照片中识别植物疾病。我有一个小种植园,经常使用 GPT-4o 来识别植物疾病。
因此,我提取了一张图片并让模型识别植物疾病。
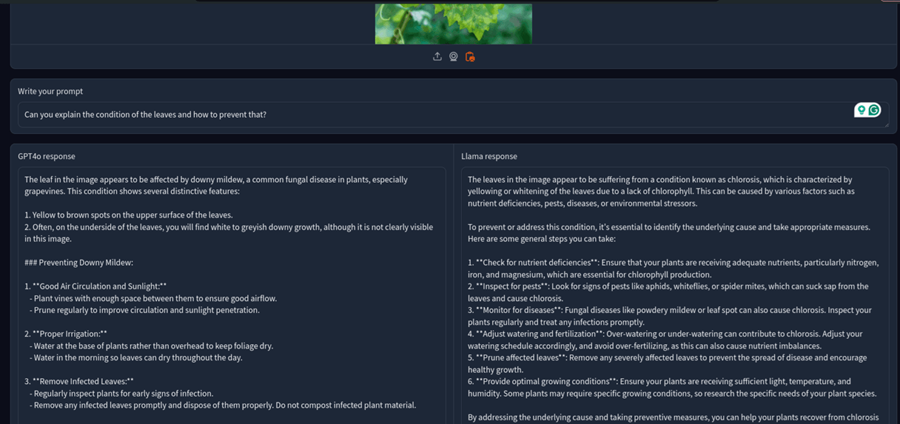
这次 GPT4o 也正确无误。它正确地将植物的疾病识别为霜霉病,而 Llama 3.2 错误地识别为萎黄病。
我再次尝试了它们,两个模型都正确地识别出了疾病。

2、理解处方和医疗报告
我无法强调我有多少次需要帮助才能理解医疗处方。我很确定很多人可能都是这种情况。
所以,我让模型解读这个处方。

GPT 4o 在这里表现更好;它理解了病人的姓名和处方药。Llama 3.2 一点也不费力。
现在让我们在医疗报告上测试它们。这是甲状腺测试的测试报告。
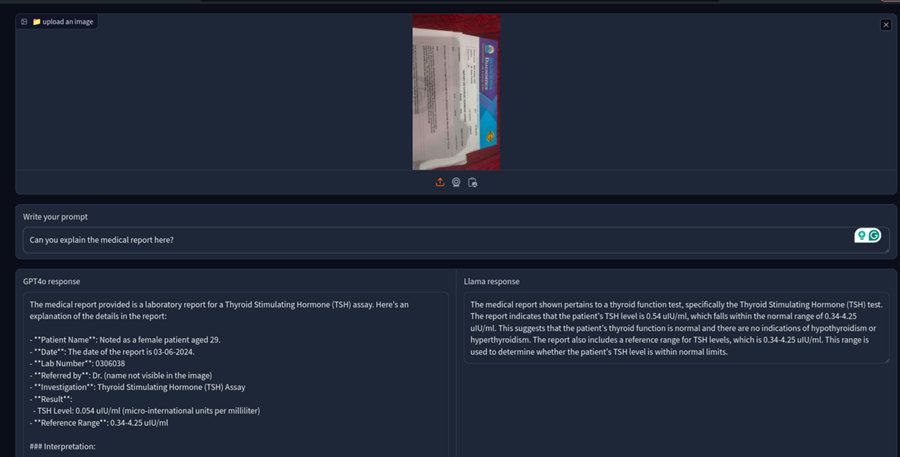
这令人惊讶;即使提到了标准的 TH 水平,GPT-4o 仍然说这是甲状腺功能减退症。另一方面,Llama 3.2 vision是正确的。所以,不要盲目相信 ChatGPT 的医疗建议,
我还要求两个模型理解 X 射线报告。

两者都是正确的。不过,GPT4o 的回应很详细,而 Llama 3.2 vision则直接简洁。
图像理解总结:Llama 3.2 vision无疑是开源社区的福音,它可以完成很多视觉任务,性能接近 GPT-4o,考虑到性价比,这是一个不错的选择。
3、文本提取
从图像中提取重要文本是视觉语言模型的另一个有价值的用例。
以下是我测试图像到文本提取可以受益的模型的几个案例。
3.1 发票处理
从发票中提取实际细节通常很有用。因此,我为这两个模型提供了最近购买的冰箱的发票。

可能存在比通过提示提取文本更好的方法。你可能需要使用 Instructor 等外部工具。无论如何,我想测试这些模型的原始输出,两者似乎都时好时坏。有时,它们做得很好,有时,它们做得很糟糕。
3.2 表格提取
让我们从 JSON 格式的表格图像中提取数据。我为这两个模型提供了随机表格数据,并要求它们以 JSON 格式提取数据。

从我的测试来看,GPT-4o 的表现优于 Llama-3.2。GPT-4o 的提示遵循性比 Meta 的 Llama-3.2 好得多。
文本提取总结:Llama 3.2 是一个强大的模型;但是,如前所述,GPT-4o 更好地遵循提示。因此,使用 GPT-4o 更容易提取所需数据。
4、财务图表分析
现在让我们使用财务图表分析来测试这些模型。由于我不是财务分析师,我将判断哪种解释更好。
我给出了 Reliance Industries 的一个月走势线图。

下面是两个模型的输出:

我不会说这些响应是准确的,但 GPT4o 的解释似乎要好得多------Llama 3.2 似乎产生了很大的幻觉。
财务图表分析总结:GPT-4o 仍然更适合复杂的图表和分析。 Llama 3.2 比 GPT4o 产生更多的幻觉,并且会自行编造东西。
5、最终裁决
以下是我对新 Meta 的 Llama 3.2 视觉模型的看法。
这是第一个原生开源多模态模型,是未来的一个好兆头。 多模态 405B 一定是有可能的。
何时使用 Llama 3.2 Vision?
该模型在理解和分析一般图像方面非常出色。考虑到成本和隐私优势,在不需要复杂分析或深度知识的任务中使用它很有意义。