本期采用2023年瞪羚优化算法优化VMD,并结合Transformer-SVM实现轴承诊断,算是一个小创新方法了。需要水论文的童鞋尽快!
瞪羚优化算法之前推荐过,该成果于2023年发表在计算机领域三区SCI期刊"Neural Computing and Applications"上。GOA方法具有出色的鲁棒性和效率,目前被引258次。

本期轴承诊断思路如下:
①对官方下载的西储大学数据进行处理,划分10种故障类型;
②对第一步处理得到的数据进行特征提取,主要是采用GOA算法优化VMD的两个参数(模态分量和惩罚因子),并将优化后的最佳值回带提取10种状态的特征向量;
③采用Transformer模型对提取的特征进行学习,并采用SVM分类器替代传统的softmax分类器,进一步提升模型分类能力。
内容详解
一、数据处理
对官方下载的西储大学数据进行处理,步骤如下:
-
一共加载10种数据,然后取每个数据的DE_time(%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行)
-
设置滑动窗口w,每个数据的故障样本点个数s,每个故障类型的样本量m
-
将所有的数据滑窗完毕之后,综合到一个data变量中
-
有关西储大学数据的处理之前有文章也讲过,大家可以看这篇文章:西储大学轴承诊断数据处理,matlab免费代码获取
最后得到的数据是一个1000*2048的矩阵,其中1000是样本量,2048是特征。1000又等于100*10,10是指10种故障状态,100是指每种状态有100个样本。在代码中是data_total_1797.mat
二、特征提取
对第一步数据处理得到的数据进行特征提取:
选取五种适应度函数进行优化,这里大家可以自行决定选哪一个!以此确定VMD的最佳k和α参数。五种适应度函数分别是:最小包络熵,最小样本熵,最小信息熵,最小排列熵, 排列熵/互信息熵 ,代码中可以一键切换。 至于应该选择哪种作为自己的适应度函数,大家可以看这篇文章。VMD为什么需要进行参数优化,最小包络熵/样本熵/排列熵/信息熵,适应度函数到底该选哪个
关于特征提取的具体原理,也在这篇文章进行过详细介绍,大家可以跳转阅读。简单来说,就是利用包络熵最小的准则把每个样本的最佳IMF分量提取出来,然后对其9个指标进行计算,分别是:均值,方差,峰值,峭度,有效值,峰值因子,脉冲因子,波形因子,裕度因子。然后用这9个指标构建每个样本的特征向量。
本篇文章采用了2023年一个高被引算法--瞪羚优化器(GOA),对VMD参数进行了优化,找到了每个故障类型的最佳IMF分量,并利用包络熵最小的准则,提取出了最佳的IMF分量。每个状态的优化曲线图我也画出来了:
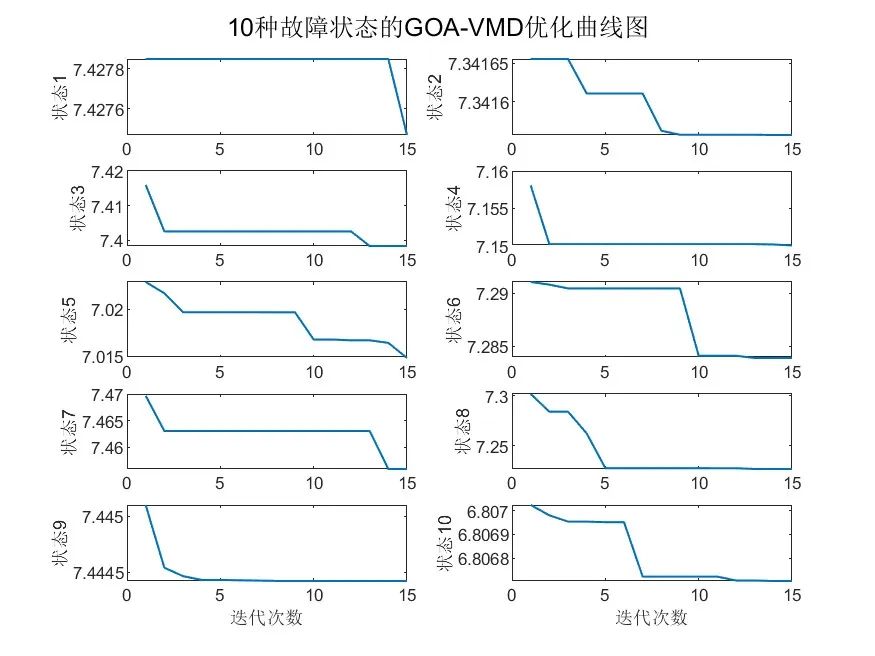
运行程序后会在命令行窗口打印寻优过程如下:
go
正在对第1个故障类型的数据进行VMD优化......请耐心等待!
第1个故障类型数据的最佳VMD参数是:2041 9最佳IMF分量是:IMF6
正在对第2个故障类型的数据进行VMD优化......请耐心等待!
第2个故障类型数据的最佳VMD参数是:626 3最佳IMF分量是:IMF2
正在对第3个故障类型的数据进行VMD优化......请耐心等待!
第3个故障类型数据的最佳VMD参数是:114 9最佳IMF分量是:IMF3
正在对第4个故障类型的数据进行VMD优化......请耐心等待!
第4个故障类型数据的最佳VMD参数是:192 3最佳IMF分量是:IMF3
正在对第5个故障类型的数据进行VMD优化......请耐心等待!
第5个故障类型数据的最佳VMD参数是:427 5最佳IMF分量是:IMF3
正在对第6个故障类型的数据进行VMD优化......请耐心等待!
第6个故障类型数据的最佳VMD参数是:242 10最佳IMF分量是:IMF10
正在对第7个故障类型的数据进行VMD优化......请耐心等待!
第7个故障类型数据的最佳VMD参数是:256 10最佳IMF分量是:IMF6
正在对第8个故障类型的数据进行VMD优化......请耐心等待!
第8个故障类型数据的最佳VMD参数是:510 8最佳IMF分量是:IMF8
正在对第9个故障类型的数据进行VMD优化......请耐心等待!
第9个故障类型数据的最佳VMD参数是:218 3最佳IMF分量是:IMF3
正在对第10个故障类型的数据进行VMD优化......请耐心等待!
第10个故障类型数据的最佳VMD参数是:820 4最佳IMF分量是:IMF4三,采用Transformer-SVM模型实现故障分类
Transformer 作为一种创新的神经网络结构,深受欢迎。采用 Transformer 编码器对数据特征间的复杂关系以及时间序列中的长短期依赖关系进行挖掘,并在模型最后的分类阶段,将传统的softmax分类器替换为SVM分类器,进一步提升模型的分类准确率!
本文所选SVM是从官网下载的libsvm-3.3版本,已编译好,大家可以直接运行。
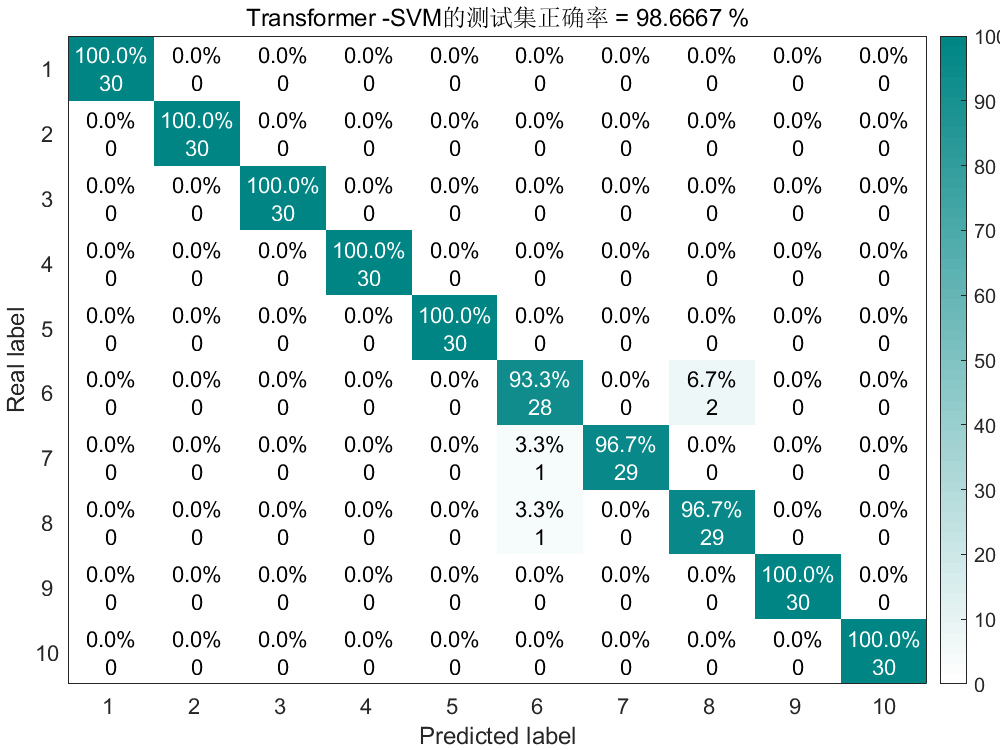
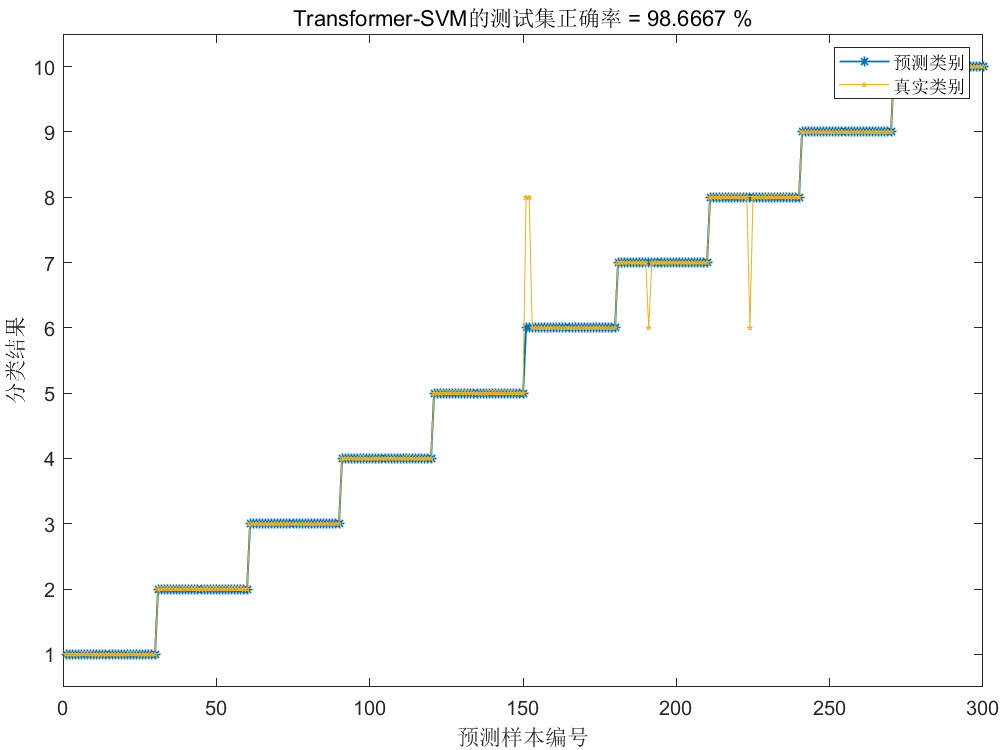
将第二步提取的特征划分训练集与测试集后(3:1),送入Transformer-SVM模型进行训练,结果如下:
结果展示
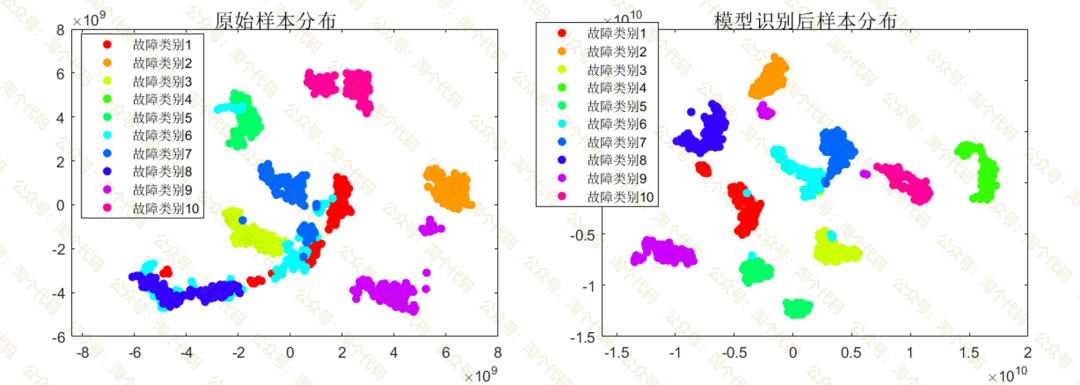
同时还绘制了Transformer模型识别前后的样本分布图,采用tsne降维后绘制二维平面图如下:
代码目录:
最后一个压缩包是有关VMD画图的程序。考虑到大家可能会用到VMD的相关作图,包络谱,频谱图等,作者在这里也一并附在代码中了。这部分大家需要自行更改数据!也就是作者比较火的文章之一,这里边提到的所有代码: VMD分解,matlab代码,包络线,包络谱,中心频率,峭度值,能量熵,样本熵,模糊熵,排列熵,多尺度排列熵,西储大学数据集为例
代码获取
点击下方卡片获取。
已将此代码添加至故障诊断全家桶中