一、重要知识点
1.1、生成式(推导式)的用法
python
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
# 用股票价格大于100元的股票构造一个新的字典
prices2 = {key: value for key, value in prices.items() if value > 100}
print(prices2) 说明:生成式(推导式)可以用来生成列表、集合和字典。
说明:生成式(推导式)可以用来生成列表、集合和字典。
1.2、嵌套的列表的坑
python
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
# 录入五个学生三门课程的成绩
# 错误 - 参考http://pythontutor.com/visualize.html#mode=edit
# scores = [[None] * len(courses)] * len(names)
scores = [[None] * len(courses) for _ in range(len(names))]
for row, name in enumerate(names):
for col, course in enumerate(courses):
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)Python Tutor - VISUALIZE CODE AND GET LIVE HELP


1.3、heapq模块(堆排序)
python
"""
从列表中找出最大的或最小的N个元素
堆结构(大根堆/小根堆)
"""
import heapq
list1 = [34, 25, 12, 99, 87, 63, 58, 78, 88, 92]
list2 = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
print(heapq.nlargest(3, list1))
print(heapq.nsmallest(3, list1))
print(heapq.nlargest(2, list2, key=lambda x: x['price']))
print(heapq.nlargest(2, list2, key=lambda x: x['shares'])) 1.4、
1.4、itertools模块
python
"""
迭代工具模块
"""
import itertools
# 产生ABCD的全排列
itertools.permutations('ABCD')
# 产生ABCDE的五选三组合
itertools.combinations('ABCDE', 3)
# 产生ABCD和123的笛卡尔积
itertools.product('ABCD', '123')
# 产生ABC的无限循环序列
itertools.cycle(('A', 'B', 'C'))



1.5、collections模块
常用的工具类:
namedtuple:命令元组,它是一个类工厂,接受类型的名称和属性列表来创建一个类。deque:双端队列,是列表的替代实现。Python中的列表底层是基于数组来实现的,而deque底层是双向链表,因此当你需要在头尾添加和删除元素时,deque会表现出更好的性能,渐近时间复杂度为O(1)。Counter:dict的子类,键是元素,值是元素的计数,它的most_common()方法可以帮助我们获取出现频率最高的元素。Counter和dict的继承关系我认为是值得商榷的,按照CARP原则,Counter跟dict的关系应该设计为关联关系更为合理。OrderedDict:dict的子类,它记录了键值对插入的顺序,看起来既有字典的行为,也有链表的行为。defaultdict:类似于字典类型,但是可以通过默认的工厂函数来获得键对应的默认值,相比字典中的setdefault()方法,这种做法更加高效。defaultdict是内置数据类型dict的一个子类,基本功能与dict一样,只是重写了一个方法missing(key)和增加了一个可写的对象变量default_factory。如果default_factory属性为None,就报出以key作为遍历的KeyError异常;如果default_factory不为None,就会向给定的key提供一个默认值,这个值插入到词典中,并返回;使用list作为default_factory,很容易将一个key-value的序列转换为list字典。
python
"""
找出序列中出现次数最多的元素
"""
from collections import Counter
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around',
'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes',
'look', 'into', 'my', 'eyes', "you're", 'under'
]
counter = Counter(words)
print(counter.most_common(3))
from collections import defaultdict
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
a = d.items() # items()函数以列表返回可遍历的(键, 值)元组数组。
print(a)
b = sorted(d.items())
print(b)
 当字典中没有的键第一次出现时,default_factory自动为其返回一个空列表,list.append()会将值添加进新列表;再次遇到相同的键时,list.append()将其它值再添加进该列表。
当字典中没有的键第一次出现时,default_factory自动为其返回一个空列表,list.append()会将值添加进新列表;再次遇到相同的键时,list.append()将其它值再添加进该列表。
二、数据结构和算法
-
算法:解决问题的方法和步骤
-
评价算法的好坏:渐近时间复杂度和渐近空间复杂度。
-
渐近时间复杂度的大O标记:
-
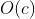
- 常量时间复杂度 - 布隆过滤器 / 哈希存储
-

- 对数时间复杂度 - 折半查找(二分查找)
-
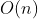
- 线性时间复杂度 - 顺序查找 / 计数排序
-

- 对数线性时间复杂度 - 高级排序算法(归并排序、快速排序)
-

- 平方时间复杂度 - 简单排序算法(选择排序、插入排序、冒泡排序)
-
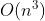
- 立方时间复杂度 - Floyd算法 / 矩阵乘法运算
-
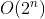
- 几何级数时间复杂度 - 汉诺塔
-

- 阶乘时间复杂度 - 旅行经销商问题 - NPC
-
排序算法(选择、冒泡和归并)和查找算法(顺序和折半)
-


python
# 简单选择排序
def select_sort(items, comp=lambda x, y: x < y):
items = items[:]
for i in range(len(items) - 1):
min_index = i
for j in range(i+1, len(items)):
if comp(items[j], items[min_index]):
j, min_index = min_index, j
items[i], items[min_index] = items[min_index], items[i]
return items
# 冒泡排序
def bubble_sort(items, comp=lambda x, y:x > y):
items = items[:]
for i in range(len(items) - 1):
swapped = False
for j in range(len(items) - 1 - i):
if comp(items[j], items[j + 1]):
items[j], items[j+1] = items[j+1] , items[j]
swapped = True
if not swapped:
break
return items
# 搅拌排序(冒泡排序升级版) - 双向的冒泡排序
def super_bubble_sort(items, comp = lambda x, y: x > y):
items = items[:]
for i in range(len(items) - 1):
swapped = False
for j in range(len(items)- i - 1):
if comp(items[j] , items[j+1]):
items[j], items[j+1] = items[j + 1], items[j]
swapped = True
if swapped:
swapped = False
for j in range(len(items)-i-2, i, -1):
if comp(items[j-1], items[j]):
items[j], items[j - 1] = items[j - 1], items[j]
swapped = True
if not swapped:
break
return items
def merge(items1, items2, comp=lambda x, y: x < y):
"""合并(将两个有序的列表合并成一个有序的列表)"""
items = []
index1, index2 = 0, 0
while index1 < len(items1) and index2 < len(items2):
if comp(items1[index1], items2[index2]):
items.append(items1[index1])
index1 += 1
else:
items.append(items2[index2])
index2 += 1
items += items1[index1:]
items += items2[index2:]
return items
def merge_sort(items, comp=lambda x, y: x < y):
return _merge_sort(list(items), comp)
def _merge_sort(items, comp):
"""归并排序"""
if len(items) < 2:
return items
mid = len(items) // 2
left = _merge_sort(items[:mid], comp)
right = _merge_sort(items[mid:], comp)
return merge(left, right, comp)
python
# 顺序查找
def seq_search(items, key):
for index, item in enumerate(items):
if item == key:
return index
return -1
# 折半查找
def bin_search(items, key):
start, end = 0, len(items) - 1
while start <= end:
mid = (start + end) // 2
if key > items[mid]:
start = mid + 1
elif key < items[mid]:
end = mid - 1
else:
return mid
return -1
常用算法:
- 穷举法 - 又称为暴力破解法,对所有的可能性进行验证,直到找到正确答案。
- 贪婪法 - 在对问题求解时,总是做出在当前看来
- 最好的选择,不追求最优解,快速找到满意解。
- 分治法 - 把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到可以直接求解的程度,最后将子问题的解进行合并得到原问题的解。
- 回溯法 - 回溯法又称为试探法,按选优条件向前搜索,当搜索到某一步发现原先选择并不优或达不到目标时,就退回一步重新选择。
- 动态规划 - 基本思想也是将待求解问题分解成若干个子问题,先求解并保存这些子问题的解,避免产生大量的重复运算。
2.1、穷举法例子:百钱百鸡和五人分鱼。
python
# 公鸡5元一只 母鸡3元一只 小鸡1元三只
# 用100元买100只鸡 问公鸡/母鸡/小鸡各多少只
def shopping():
for i in range(20):
for j in range(33):
k = 100 - i - j
if 5 * i + 3 * j + k // 3 and k % 3 == 0:
print(i, j , k)
# A、B、C、D、E五人在某天夜里合伙捕鱼 最后疲惫不堪各自睡觉
# 第二天A第一个醒来 他将鱼分为5份 扔掉多余的1条 拿走自己的一份
# B第二个醒来 也将鱼分为5份 扔掉多余的1条 拿走自己的一份
# 然后C、D、E依次醒来也按同样的方式分鱼 问他们至少捕了多少条鱼
def fish_allot():
fish = 6 # 第一次出现可以合理分鱼的情况,🐟的个数应为6
# 要从低到高递增找鱼
while True:
total = fish
enough = True
for _ in range(5):
if (total - 1) % 5 == 0: # 确保每一次分鱼都可以保证5份且余一条
total = (total - 1) // 5 * 4 # 代表剩余的鱼数,每次要分为五份且丢掉一条,并把属于自己的拿走
else:
enough = False
break
if enough:
print(fish)
break
fish += 5 # 每次不够分要向上找,而+5是因为起始为6(扔掉多余的一条),次次最少够分的为5(每次将鱼分成五份,五的倍数)
贪婪法例子:假设小偷有一个背包,最多能装20公斤赃物,他闯入一户人家,发现如下表所示的物品。很显然,他不能把所有物品都装进背包,所以必须确定拿走哪些物品,留下哪些物品。
| 名称 | 价格(美元) | 重量(kg) |
|---|---|---|
| 电脑 | 200 | 20 |
| 收音机 | 20 | 4 |
| 钟 | 175 | 10 |
| 花瓶 | 50 | 2 |
| 书 | 10 | 1 |
| 油画 | 90 | 9 |
python
"""
贪婪法:在对问题求解时,总是做出在当前看来是最好的选择,不追求最优解,快速找到满意解。
输入:
20 6
电脑 200 20
收音机 20 4
钟 175 10
花瓶 50 2
书 10 1
油画 90 9
"""
class Thing(object):
"""物品"""
def __init__(self,name,piece,weight):
self.name = name
self.piece = piece
self.weight = weight
@property
def value(self):
"""价格重量比 = 价值"""
return self.piece / self.weight
def input_thing():
"""输入物品信息"""
name_str,piece_str,weight_str = input().split() # split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
return name_str,int(piece_str),int(weight_str)
def main():
"""主函数"""
max_weight,num_of_things = map(int, input().split()) # input().split()接受用户的输入,并将其拆分为一个字符串列表,以空格作为分隔符。
# 然后,map(int, ...)将这个字符串列表作为输入,并将每个字符串转换为整数。
# 最终,你可以通过迭代这个结果来访问每个整数。
all_things = []
for _ in range(num_of_things):
all_things.append(Thing(*input_thing())) # *agrs:将所有参数以元组(tuple)的形式导入;**agrs:双星号(**)将参数以字典的形式导入
all_things.sort(key=lambda x:x.value,reverse=True) # reverse=True代表列表进行降序排序
total_weight = 0
total_piece = 0
for thing in all_things:
if total_weight + thing.weight <= max_weight:
print(f'小偷拿走了{thing.name}')
total_weight += thing.weight
total_piece += thing.piece
print(f'总价值:{total_piece}美元')
all_things.append(Thing(*input_thing()))我们在这里要注意一个小细节,这个类创建传入的是一个元组,平常我们初始化类都是挨个元素分别传入,这次为什么传入元组也可以呢?我们有一个type()函数的应用:type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值)),可以通过这种方式来创建一个我们自己想要的类。函数type实际上是一个元类。type就是Python在背后用来创建所有类的元类。
这里我们就又不得不谈到一个__new__()方法:__new__方法负责创建一个实例对象,在对象被创建的时候调用该方法它是一个类方法。__new__方法在返回一个实例之后,会自动的调用__init__方法,对实例进行初始化。如果__new__方法不返回值,或者返回的不是实例,那么它就不会自动的去调用__init__方法。
而__init__()方法负责将该实例对象进行初始化,在对象被创建之后调用该方法,在__new__方法创建出一个实例后对实例属性进行初始化。__init__方法可以没有返回值。
def new(cls, *args, **kwargs):
#__new__是一个类方法,在对象创建的时候调用
print "excute new"
def init(self,value):
#__init__是一个实例方法,在对象创建后调用,对实例属性做初始化
print "excute __init"
所以,经过这么比对,在初始化类的时候参数传入元组也是可以理解的。
2.2、分治法例子:快速排序。
python
"""
快速排序 - 选择枢轴对元素进行划分,左边都比枢轴小右边都比枢轴大
1、选择基准元素:从待排序的数组中选择一个基准元素,通常选择最后一个元素 (也可以选择第一个元素、随机元素、三数取中等)。
2、分区过程:将数组中的元素重新排列,使得小于基准元素的值位于基准元素的左侧,大于基准元素的值位于右侧。
3、递归排序:对左右两个子数组分别进行递归排序,重复上述两个步骤。
4、合并结果:最后,将左子数组、基准元素和右子数组合并起来,得到排序完成的数组。
"""
def quick_sort(items, comp=lambda x, y: x <= y):
items = list(items)[:]
_quick_sort(items, 0, len(items) - 1, comp)
return items
def _quick_sort(items, start, end, comp):
if start < end:
pos = _partition(items, start, end, comp)
_quick_sort(items, start, pos - 1, comp)
_quick_sort(items, pos + 1, end, comp)
def _partition(items,start,end,comp):
pivot = items[end]
i = start - 1
for j in range(start,end): # j向前遍历的原因就是找到所有符合comp()条件的元素,找到一个就将i++的原因是为了让i处于比pivot大的元素的后面
if comp(items[j],pivot):
i += 1
items[i], items[j] = items[j], items[i]
items[i + 1], items[end] = items[end], items[i + 1]
return i + 1
我们借助python tutor来分析一下:
可以看到j每次都在++,遇到符合comp()的就让i向前移动,而遇到不符合的就j继续向前,i则停留在了"最新一个"比pivot元素大的坐标的后一位。 当我们再次向前走,遇到了最后一个比pivot小的数字时,就进入if,则将i位置的元素与j位置的元素互换。
当我们再次向前走,遇到了最后一个比pivot小的数字时,就进入if,则将i位置的元素与j位置的元素互换。 互换后,此时i(算上i)左侧都是比pivot小的元素,i+1(算上i+1)都是比pivot大的元素,将i+1和pivot元素互换即可,最后在分组递归就好了。
互换后,此时i(算上i)左侧都是比pivot小的元素,i+1(算上i+1)都是比pivot大的元素,将i+1和pivot元素互换即可,最后在分组递归就好了。
我们在回看过程,为什么要将i设置为-1?

第一次若j处元素比pivot小,则会让i和j处于同一起跑线,且元素互换也会不起作用。
接下来,每当j遇见比pivot小的元素,都会推动i向前走,直到最后i是找到大于pivot的元素,j找到最后小于pivot的元素,因为二者位置的元素已然不相连,则将二者互换位置即可。
2.3、回溯法例子:骑士巡逻。
python
"""
递归回溯法:叫称为试探法,按选优条件向前搜索,当搜索到某一步,发现原先选择并不优或达不到目标时,就退回一步重新选择,比较经典的问题包括骑士巡逻、八皇后和迷宫寻路等。
"""
import sys
import time
SIZE = 5
total = 0
def print_board(board):
for row in board:
for col in row:
print(str(col).center(4), end='') # center()返回一个原字符串居中,并使用空格填充至长度width的新字符串。默认填充字符为空格。
print()我们先写出一个棋盘的走向:
众所周知,骑士或者说🐎,在棋盘中的走法归总有8种(马走日),我们也只需要遍历这8种不同方式,就能知道共有几种方式可以走遍所有格子。
python
"""
递归回溯法:叫称为试探法,按选优条件向前搜索,当搜索到某一步,发现原先选择并不优或达不到目标时,就退回一步重新选择,比较经典的问题包括骑士巡逻、八皇后和迷宫寻路等。
"""
import sys
import time
SIZE = 5
total = 0
def print_board(board):
for row in board:
for col in row:
print(str(col).center(4), end='') # center()返回一个原字符串居中,并使用空格填充至长度width的新字符串。默认填充字符为空格。
print()
def patrol(board, row, col, step=1): # 用step来代表每次走的步数
if row >= 0 and row < SIZE and \
col >= 0 and col < SIZE and \
board[row][col] == 0: # 这段语句是设置递归条件,即不超过棋盘和此路并未被走过
board[row][col] = step # 每一步都要标记在棋盘上
if step == SIZE * SIZE: # 每一种走法就是当步数=棋盘数为止
global total
total += 1
print(f'第{total}种走法')
print_board(board)
# 以下是八种走法
patrol(board, row - 2, col - 1, step + 1)
patrol(board, row - 1, col - 2, step + 1)
patrol(board, row + 1, col - 2, step + 1)
patrol(board, row + 2, col - 1, step + 1)
patrol(board, row + 2, col + 1, step + 1)
patrol(board, row + 1, col + 2, step + 1)
patrol(board, row - 1, col + 2, step + 1)
patrol(board, row - 2, col + 1, step + 1)
board[row][col] = 0
def main():
board = [[0] * SIZE for _ in range(SIZE)]
patrol(board, SIZE - 1, SIZE - 1)
我们main()函数开头创建的board是这个样子的:
第一卒是从右下角开始走,因为5x5太多,所以暂时先拿3x3给大伙举个例子。
代码中的boardrowcol = 0 作用是前面的八种走法统统没有退路了,则证明此次出发的这个棋子点是错误的,并没有走完棋局且无法继续向下落子,故将其数字设置为0,退出至上一层递归重新开始。(也就是说相当于这步已经死棋了)


2.4、动态规划例子:子列表元素之和的最大值。
说明:子列表指的是列表中索引(下标)连续的元素构成的列表;列表中的元素是int类型,可能包含正整数、0、负整数;程序输入列表中的元素,输出子列表元素求和的最大值,例如:
输入:1 -2 3 5 -3 2
输出:8
输入:0 -2 3 5 -1 2
输出:9
输入:-9 -2 -3 -5 -3
输出:-2
python
def main():
items = list(map(int, input().split()))
# input().split()是将input()函数输入的数据分割,且input()的返回类型为str
# map()是将分割好的str数据转化成int类型,并返回一个迭代器
# list()是将这个迭代器转换成列表
overall = partial = items[0]
for i in range(1, len(items)):
partial = max(items[i], partial+items[i]) # partial代表中途的动态规划
# 如果partial+items[i] > items[i],则证明数字相加要大于原来的单独数字,故可以将其放入观察
# 如果partial+items[i] < items[i],则证明加了一个数字之后,整体的和反倒变小了,亦或是理解为相加之和没有下一个元素本身大,应是前面的元素和造成了抑制作用
# 如若是这种情况[1,2,-4,-5,1,1,1,1,1,1],在1+2之后,再将其-4则元素总和会变小,但和-4相比会大且是负数,则在后面在遇到可以增加的元素时,总和就会转换到后面的元素身上开始了
overall = max(overall, partial) # overall代表最终最大数值
print(overall)说明:这个题目最容易想到的解法是使用二重循环,但是代码的时间性能将会变得非常的糟糕。使用动态规划的思想,仅仅是多用了两个变量,就将原来O(N\^2)复杂度的问题变成了O(N)。