文章目录
- [0 简介](#0 简介)
- [1 二维码基础概念](#1 二维码基础概念)
-
- [1.1 二维码介绍](#1.1 二维码介绍)
- [1.2 QRCode](#1.2 QRCode)
- [1.3 QRCode 特点](#1.3 QRCode 特点)
- [2 机器视觉二维码识别技术](#2 机器视觉二维码识别技术)
-
- [2.1 二维码的识别流程](#2.1 二维码的识别流程)
- [2.2 二维码定位](#2.2 二维码定位)
- [2.3 常用的扫描方法](#2.3 常用的扫描方法)
- [4 深度学习二维码识别](#4 深度学习二维码识别)
-
- [4.1 部分关键代码](#4.1 部分关键代码)
- 最后
0 简介
今天学长向大家分享一个毕业设计项目
**毕业设计 基于深度学习二维码检测识别系统 **
项目运行效果:
毕业设计 深度学习二维码检测识别
🧿 项目分享:见文末!
1 二维码基础概念
1.1 二维码介绍
二维条码/二维码(2-dimensional bar
code)是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;在代码编制上巧妙地利用构成计算机内部逻辑基础的"0"、"1"比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理:它具有条码技术的一些共性:每种码制有其特定的字符集;每个字符占有一定的宽度;具有一定的校验功能等。同时还具有对不同行的信息自动识别功能、及处理图形旋转变化点。
1.2 QRCode
常见的二维码为QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar
Code条形码能存更多的信息,也能表示更多的数据类型。
1.3 QRCode 特点
1、符号规格从版本1(21×21模块)到版本40(177×177 模块),每提高一个版本,每边增加4个模块。
2、数据类型与容量(参照最大规格符号版本40-L级):
- 数字数据:7,089个字符
- 字母数据: 4,296个字符
- 8位字节数据: 2,953个字符
- 汉字数据:1,817个字符
3、数据表示方法:
- 深色模块表示二进制"1",浅色模块表示二进制"0"。
4、纠错能力:
- L级:约可纠错7%的数据码字
- M级:约可纠错15%的数据码字
- Q级:约可纠错25%的数据码字
- H级:约可纠错30%的数据码字
5、结构链接(可选)
- 可用1-16个QR Code码符号表示一组信息。每一符号表示100个字符的信息。
2 机器视觉二维码识别技术
2.1 二维码的识别流程
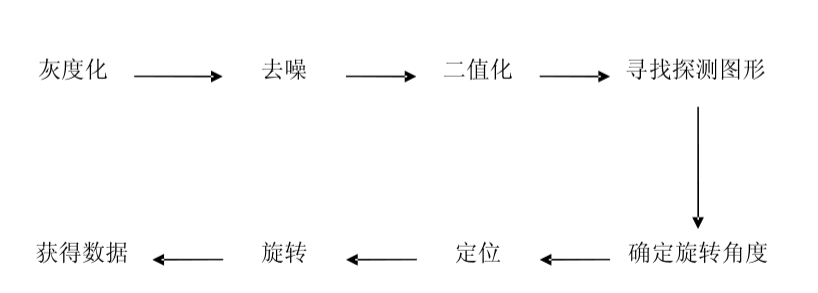
首先, 对采集的彩色图像进行灰度化, 以提高后继的运行速度。
其次, 去除噪声。 采用十字形中值滤波去除噪音对二码图像的干扰主要是盐粒噪声。
利用灰度直方图工具, 使用迭代法选取适当的阈值, 对二维码进行二值化处理,灰度化 去噪 二值化 寻找探测图形确定旋转角度 定位 旋转
获得数据使其变为白底黑色条码。
最后, 确定二维码的位置探测图形, 对条码进行定位, 旋转至水平后, 获得条码数据,
以便下一步进行解码。
2.2 二维码定位
QR 码有三个形状相同的位置探测图形, 在没有旋转的情况下, 这三个位置探测图形分别位于 QR 码符号的左上角、 右上角和左下角。
三个位置探测图形共同组成图像图形。
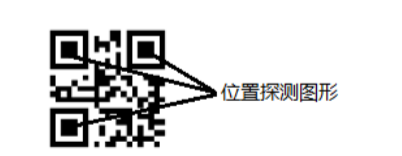
每个位置探测图形可以看作是由 3 个重叠的同心的正方形组成, 它们分别为 7 7 个深色模块、 5 5 个浅模块和 3*3 个深色模块。
位置探测图形的模块宽度比为 1: 1:3: 1: 1。
!在这里插入图片描述(https://img-
blog.csdnimg.cn/dd71567e55d24dea842dba7c6c344b2c.png?x-oss-
process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARGFuQ2hlbmctc3R1ZGlv,size_8,color_FFFFFF,t_70,g_se,x_16)
这种 1: 1: 3: 1: 1 的宽度比例特征在图像的其他位置出现的可能性很小, 故可以将此作为位置探测图形的扫描特征。 基于此特征,
当一条直线上(称为扫描线) 被黑白相间地截为1: 1: 3:1: 1 时, 可以认为该直线穿过了位置探测图形。
另外, 该扫描特征不受图像倾斜的影响。 对比中的两个 QR 码符号可以发现, 无论 QR码符号是否倾斜, 都符合 1: 1: 3:1: 1 的扫描特征。
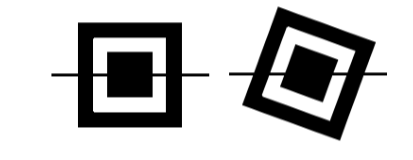
2.3 常用的扫描方法
1. 在 X 方向进行依次扫描。
(1) 固定 Y 坐标的取值, 在 X 方向上画一条水平直线(称为扫描线) 进行扫描。 当扫描线被黑白相间地截为 1: 1: 3: 1: 1 时,
可以认为该直线穿过了位置探测图形。 在实际判定时, 比例系数允许 0. 5 的误差, 即比例系数为1 的, 允许范围为 0. 5~1. 5, 比例系数为 3
的, 允许范围为 2. 5~3. 5。
(2) 当寻找到有直线穿过位置探测图形时, 记录下位置探测图形的外边缘相遇的第一点和最后一点 A 和 B。 由 A、 B
两点为端点的线段称为扫描线段。将扫描线段保存下来。
!在这里插入图片描述(https://img-
blog.csdnimg.cn/2ca811301e4b404caeae92e5a32c1bec.png?x-oss-
process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARGFuQ2hlbmctc3R1ZGlv,size_9,color_FFFFFF,t_70,g_se,x_16)
用相同的方法, 完成图像中所有水平方向的扫描。
2. 在 Y 方向, 使用相同的方法, 进行垂直扫描, 同样保存扫描得到的扫描线段。
扫描线段分类扫描步骤获得的扫描线段是没有经过分类的, 也就是对于特定的一条扫描线段, 无法获知其具体对应于三个位置探测图形中的哪一个。 在计算位置探测图形中
距离邻域法的思想是: 给定一个距离阈值 dT, 当两条扫描线段的中点的距离小于 d T 时, 认为两条扫描线段在同一个邻域内, 将它们分为一类,
反之则归为不同的类别。
距离邻域法的具体步骤如下:
(1) 给定一个距离阈值 dT , d T要求满足以下条件: 位于同一个位置探测图形之中的任意两点之间的距离小于 dT ,
位于不同位置探测图形中的任意两点之间的距离大于 d T
(2) 新建一个类别, 将第 1 条扫描线段归入其中。
(3) 对于第 i 条扫描线段 l i (2≤i≤n), 做以下操作:
a) 求出 l i 的中点 C i 。
b) 分别计算C i与在已存在的每一个类别中的第一条扫描线段的中点的距离d,若 d<d T , 则直接将 l i 加入相应类别中。
c) 若无法找到 l i 可以加入的类别, 则新建一个类别, 将 l i 加入其中。
(4) 将所有类别按照包含扫描线段的数目进行从大到小排序, 保存前 3 个类别(即
包含扫描线段数目最多的 3 个类别), 其余的视为误判得到的扫描线段(在位置探测图形以外的位置得到的符合扫描特征的扫描线段),
直接舍去。距离邻域法结束后得到的分好 3 个类别的扫描线段就分别对应了 3 个位置探测图形。距离邻域法的关键就是距离阈值的选取。 一般对于不同大小的 QR
码图像, 要使用不同的距离阈值。
(1) 在 X 方向的扫描线段中找出最外侧的两条, 分别取中点, 记为 A、 B。 由 A、 B两点连一条直线。
!在这里插入图片描述(https://img-
blog.csdnimg.cn/d29d87f65f7548daab27b87f6b055294.png?x-oss-
process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARGFuQ2hlbmctc3R1ZGlv,size_7,color_FFFFFF,t_70,g_se,x_16)
(2) 在 Y 方向的扫描线段中找出最外侧的两条, 分别取中点, 记为 C、 D。 由 C、 D两点连一条直线。
!在这里插入图片描述(https://img-
blog.csdnimg.cn/8ecb2bc8a4604940a1e3e02147baed59.png?x-oss-
process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARGFuQ2hlbmctc3R1ZGlv,size_8,color_FFFFFF,t_70,g_se,x_16)
(3) 计算直线 AB 与直线 CD 的交点 O, 即为位置探测图形中心点。
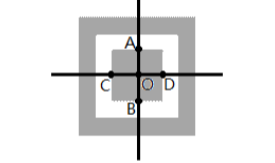
将 QR 码符号的左上、 右上位置探测图形的中心分别记为 A、 B。 连接 A、 B。 直线 AB 与水平线的夹角α 即为 QR 码符号的旋转角度。
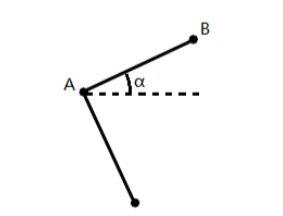
对于该旋转角度α , 求出其正弦值 sinα 与余弦值 cosα 即可。 具体计算公式如下:
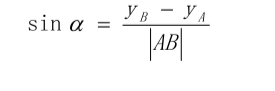
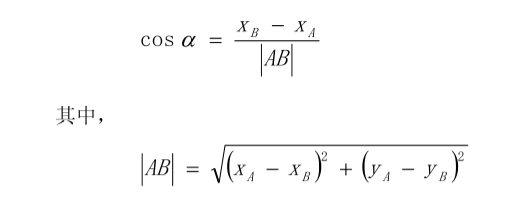
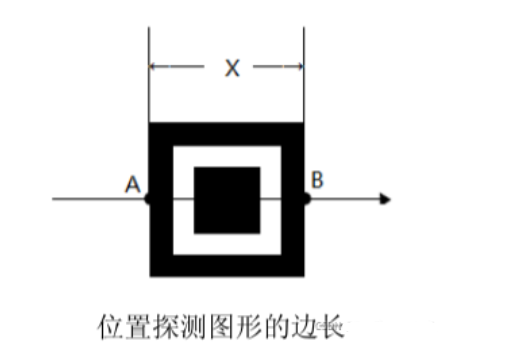
位置探测图形边长的计算是基于无旋转图像的, 在无旋转图像中, 水平扫描线段的长度即为位置探测图形的边长。
水平扫描线段 AB 的长度即为位置探测图形的边长 X。
对于经过旋转的 QR 码图像, 先通过插值算法生成旋正的 QR 码图像, 然后按照如上所述的方法进行位置探测图形边长的计算
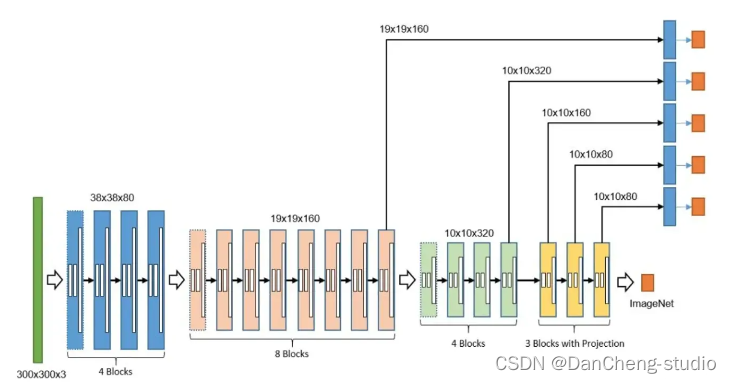
4 深度学习二维码识别
基于 CNN 的二维码检测,网络结构如下
4.1 部分关键代码
篇幅有限,学长在这只给出部分关键代码
首先,定义一个 AlgoQrCode.h
#pragma once
#include
#include
using namespace cv;
using namespace std;
class AlgoQRCode
{
private:
Ptr<wechat_qrcode::WeChatQRCode> detector;
public:
bool initModel(string modelPath);
string detectQRCode(string strPath);
bool compression(string inputFileName, string outputFileName, int quality);
void release();
};
该头文件定义了一些方法,包含了加载模型、识别二维码、释放资源等方法,以及一个 detector 对象用于识别二维码。
然后编写对应的源文件 AlgoQrCode.cpp
bool AlgoQRCode::initModel(string modelPath) {
string detect_prototxt = modelPath + "detect.prototxt";
string detect_caffe_model = modelPath + "detect.caffemodel";
string sr_prototxt = modelPath + "sr.prototxt";
string sr_caffe_model = modelPath + "sr.caffemodel";
try
{
detector = makePtr<wechat_qrcode::WeChatQRCode>(detect_prototxt, detect_caffe_model, sr_prototxt, sr_caffe_model);
}
catch (const std::exception& e)
{
cout << e.what() << endl;
return false;
}
return true;
}
string AlgoQRCode::detectQRCode(string strPath)
{
if (detector == NULL) {
return "-1";
}
vector<Mat> vPoints;
vector<cv::String> vStrDecoded;
Mat imgInput = imread(strPath, IMREAD_GRAYSCALE);
// vStrDecoded = detector->detectAndDecode(imgInput, vPoints);
....
}
bool AlgoQRCode::compression(string inputFileName, string outputFileName, int quality) {
Mat srcImage = imread(inputFileName);
if (srcImage.data != NULL)
{
vector<int>compression_params;
compression_params.push_back(IMWRITE_JPEG_QUALITY);
compression_params.push_back(quality); //图像压缩参数,该参数取值范围为0-100,数值越高,图像质量越高
bool bRet = imwrite(outputFileName, srcImage, compression_params);
return bRet;
}
return false;
}
void AlgoQRCode::release() {
detector = NULL;
} 
最后
项目运行效果:
毕业设计 深度学习二维码检测识别
🧿 项目分享:见文末!