文章目录
- 1.使用官网文档
- 2.redis通用命令
-
- 2.1set
- 2.2get
- 2.3.redis全局命令
-
- [2.3.1 keys](#2.3.1 keys)
- [2.4 exists](#2.4 exists)
- [2.5 del(delete)](#2.5 del(delete))
- [2.6 expire - (失效时间)](#2.6 expire - (失效时间))
- [2.7 ttl - 过期时间](#2.7 ttl - 过期时间)
-
- [2.7.1 redis中key的过期策略](#2.7.1 redis中key的过期策略)
- 2.7.2redis定时器的实现原理
- [2.8 type](#2.8 type)
- [2.9 object](#2.9 object)
- 3.生产环境
- 4.常用的数据结构
- 5.单线程模型
-
- 5.1单线程模式的工作过程
- [5.2 redis相关面试题](#5.2 redis相关面试题)
大家好,我是晓星航。今天为大家带来的是 redis通用命令 相关的讲解!😀
1.使用官网文档
通过 redis-cli 客户端和 redis 服务器交互涉及到很多的 redis 的命令

2.redis通用命令
redis 是按照键值对的方式存储数据的.
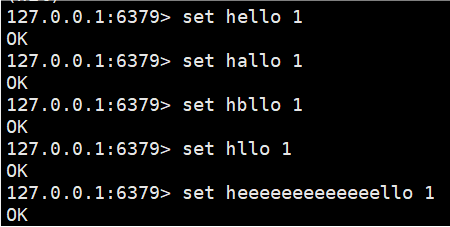
2.1set
set - 把 key 和 value 存储进去
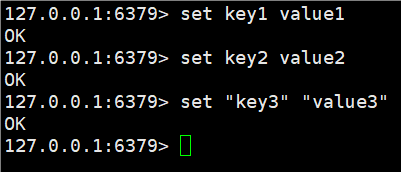
这里的key value不加引号可以,加上引号也可以。
redis中的命令不区分大小写
2.2get
get - 根据 key 来取 value
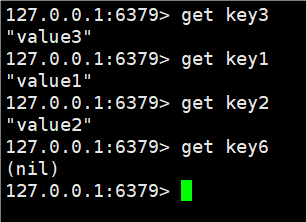
这里我们get key所得到的值就是我们set进去的value值,如果不存在key则返回(nil)。
2.3.redis全局命令
Redis 支持很多种数据结构。整体上来说, Redis 是键值对结构.key 固定就是字符串. value 实际上会有多种类型
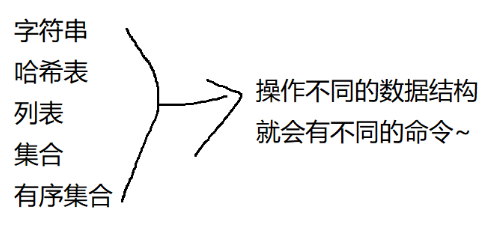
全局命令,就是能够搭配任意一个数据结构来使用的命令
2.3.1 keys
用来查询当前服务器上匹配的key,通过一些特殊符号(通配符)来描述key的模样,匹配上述模样的key就能被查询出来。

Redis有5种数据结构,但它们都是键值对种的值,对于键来说有一些通用的命令。
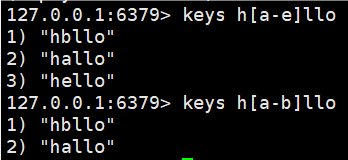
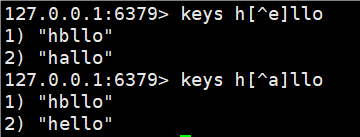
h?llo匹配hello,hallo和hxlloh*llo匹配hllo和heeeelloh[ae]llo匹配hello和hallo但不匹配hilloh[^e]llo匹配hallo,hbllo,... 但不匹配helloh[a-b]llo匹配hallo和hbllo
语法:
sql
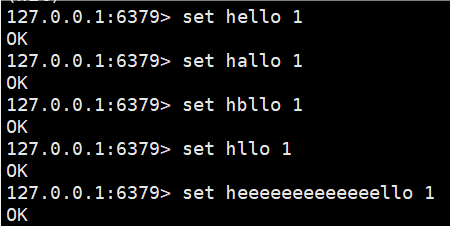
KEYS pattern我们redis库里设置的key-value值:
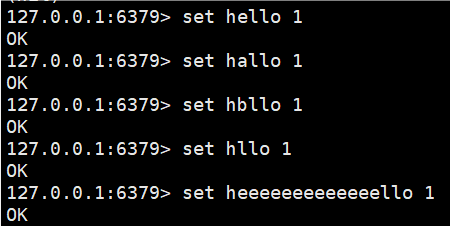
1.? 匹配任意一个字符
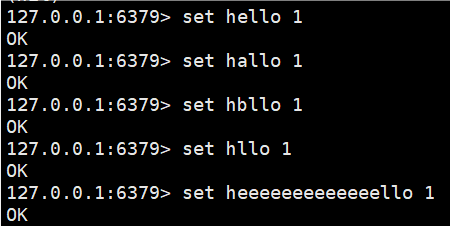

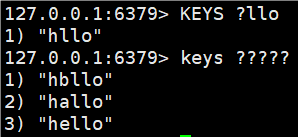
2.* 匹配0个或者多个任意字符
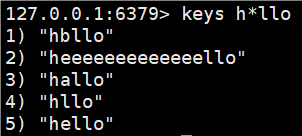
使用 keys * 可以查看所有的key值
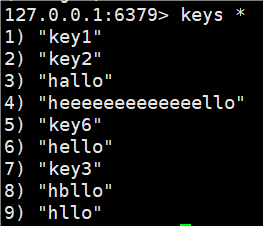
3.[abcde] 只能匹配到a b c d e,别的不行,相当于给出固定选项了
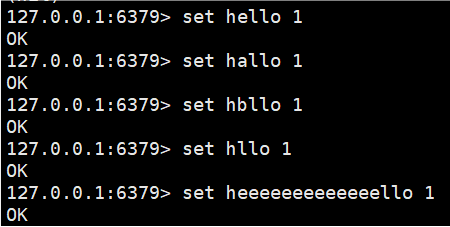
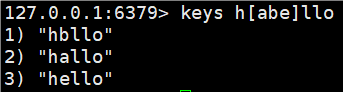
4.[a-e] 匹配 a-e 这个范围内的字符。包含两侧边界
5.[^e] 排除e,只有e匹配不了。其他都能匹配 ^读法: /ˈkærət/
注意事项:
keys 命令的时间复杂度是 O(N)
在生产环境上,一般都会禁止使用 keys 命令,尤其是大杀器 key * (查询 redis 中所有的 key)


2.4 exists
判断key是否存在
语法:
sql
exists key [key...]返回值:key存在的个数。
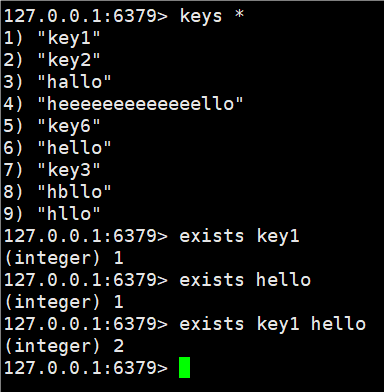
时间复杂度:O(1)
那么这里一次查询一个和一次查询两个有什么不一样么?
答:分开的写法会产生更多轮次的网络通信。使得效率变低,成本变高 --> 和直接操作内存相比(一个命令能写完就不要写多个命令,用来节省资源)
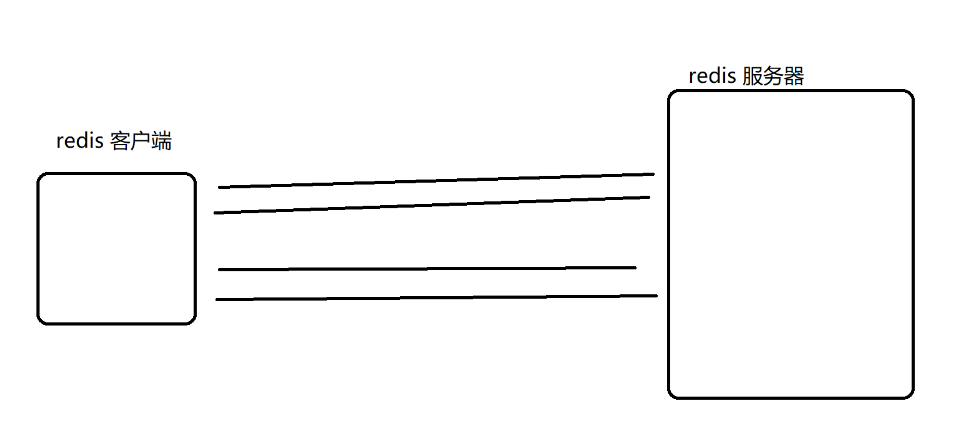
封装和分用
进行网络通信的时候,发送方发送一个数据,这个数据就要从应用层到物理层,层层封装。(每一层协议都要加上报头或报尾) => 发一个快递要包装一下,包装几层
接收方收到一个数据,这个数据就要从物理层, 到应用层 层层分用(把每一层协议中的报头或者尾给拆掉)=>收到一个快递,要拆快递,要拆很多层
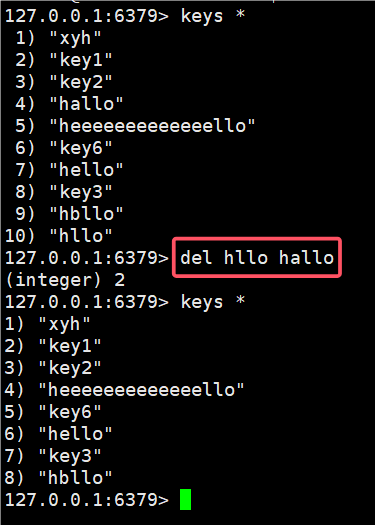
2.5 del(delete)
del(delete) 删除指定的key
语法:
bash
del key [key ...]时间复杂度:O(1)
返回值:删除掉的key的个数
redis 主要的应用场景, 就是作为缓存
此时 redis 里存的只是一个热点数据,全量数据是在 mysql 数据库中
此时, 如果把 redis 中的 key 删除了几个, 一般来说,问题不大
但是 如果把redis作为数据库,此时误删数据的影响就很大了
2.6 expire - (失效时间)
expire 作用是给指定的 key 设置过期时间
过期时间:key存活时间超出这个指定值,就会被自动删除。
业务场景:例如 手机验证码,该验证码在5分钟内有效。
点外卖,优惠卷,在指定时间之内有效。
基于 redis 实现分布式锁.为了避免出现不能正确解锁的情况, 通常都
会在加锁的时候设置一下过期时间. (所谓的使用 redis 作为分布式锁,就
是给 redis 里写一个特殊的key value)
语法:
expire key seconds时间复杂度:O(1)
返回值:1表示设置成功。0表示设置失败
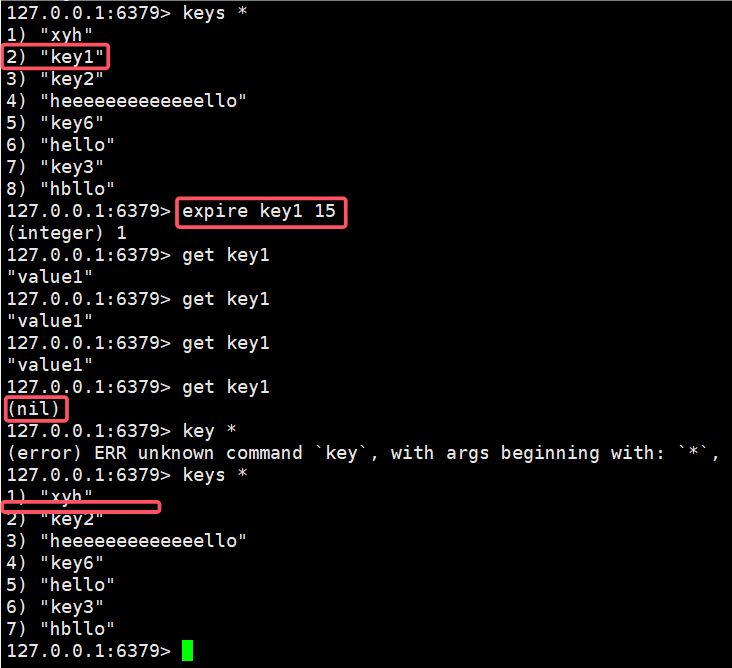
这里我们设置key1存在的时间为15秒,在15秒之后查询,结果返回nil。
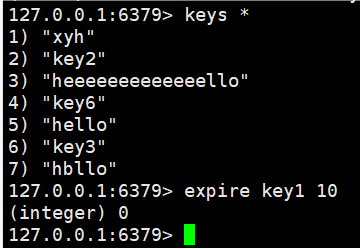
因为我们库里没有set一个key1,因此在给key1设置存在时间时,我们返回的是0,即设置失败。
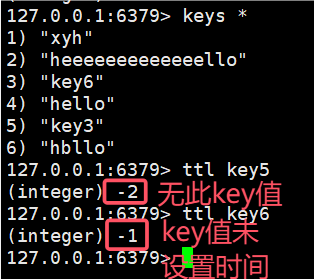
2.7 ttl - 过期时间
查看当前key的过期时间还剩多少。
语法:
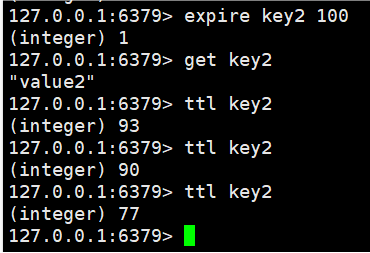
ttl key时间复杂度:O(1)
返回值:剩余过期时间。-1表示没有关联过时间,-2表示key不存在。
2.7.1 redis中key的过期策略
redis的key的过期策略是怎么实现的? 经典面试题
一个 redis 中可能同时存在很多很多 key.这些 key 中可能有很大一部分都有过期时间.此时,redis 服务器咋知道哪些key 已经过期要被删除,哪些 key 还没过期??
redis整体的策略是
1.定期删除
每次抽取一部分,进行验证过期时间,保证这个抽取检查的过程,足够快!!
为啥这里对于定期删除的时间,有明确的要求呢?
因为 redis 是单线程的程序
主要的任务(处理每个命令的任务,刚才扫描过期 key ...)
如果扫描过期 key 消耗的时间太多了,就可能导致正常处理请求命令就被阻塞了:(产生了类似于执行keys*这样的效果)
2.惰性删除
假设这个 key 已经到过期时间了,但是暂时还没删它,key 还存在,紧接着,后面又一次访问,正好用到了这个 key,于是这次访问就会让 redis 服务器触发删除 key 的操作,同时再返回一个 nil
虽然有了上述两种策略结合,整体的效果一般
仍然可能会有很多过期的 key 被残留了,没有及时删除掉
redis 为了对上述进行补充,还提供了一系列的内存淘汰策略
1.redis 中并没有采取 定时器 的方式来实现过期 key 删除.
2.如果有多个 key 过期,也可以通过一个定时器来高效/节省cpu的前提下来处理多个 key 基于 优先级队列 或者 基于 时间轮 都可以实现比较高效的定时器
2.7.2redis定时器的实现原理
定时器:在某个时间到达之后,执行指定任务。
1.基于优先级队列/堆
正常的队列是先进先出,
优先级队列则是按照指定的优先级,先出
啥叫优先级高?自定义的
在 redis 过期 key 的场景中,就可以通过"过期时间越早, 就是优先级越高
现在假定有很多 key 设置了过期时间,就可以把这些 key 加入到一个优先级队列中,指定优先级规则是过期时间早的,先出队列.

此时定时器中只要分配一个线程,让这个线程去检査队首元素,看是否过期即可!!
如果队首元素还没过期,后续元素一定没过期!
此时 扫描线程 不需要遍历所有 key 只盯住这一个队首元素即可!!
另外在扫描线程检查队首元素过期时间的时候,也不能检查的太频繁
此时做法就是可以根据当前时刻和队首元素的过期时间,设置一个等待
当时间差不多到了,系统再唤醒这个线程!
此时 扫描线程 不需要高频扫描队首元素.把 cpu 的开销也节省下来了
万一在线程休眠的时候,来了一个新的任务,是 11:30 要执行
可以在新任务添加的时候,唤醒一下刚才的线程 重新检査一下队首元素, 再根据时间差距重新调整阻塞时间即可
2.基于时间轮实现的定时器
把时间划分成很多小段~~(划分的粒度,看实际需求)

2.8 type
返回 key 对应的类型
此处 redis 所有的 key 都是 string key 对应的 value 可能会存在多种类型
语法:
type key时间复杂度:O(1)
返回值:key的类型

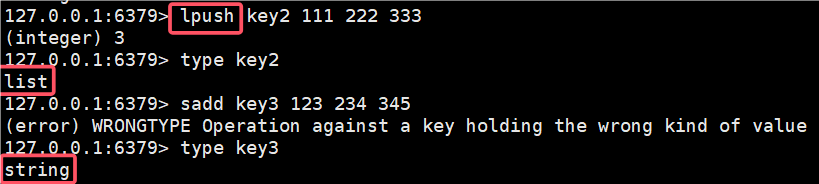
链表
默认为字符串
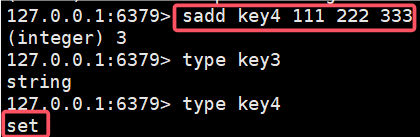
集合

哈希表
2.9 object
查看 key 对应的 value 的实际编码方式
语法:
object encoding key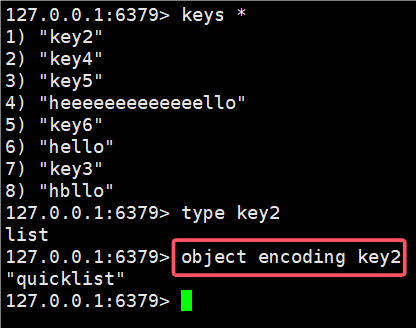
3.生产环境
1.办公环境(公司入职之后,公司给你发的电脑、手机等)
笔记本(windows,mac)/台式机
现在办公电脑,一般8C16G12G
2.开发环境
有的时候,开发环境和办公环境是一个
有的时候,开发环境是单独的服务器

3.测试环境 (测试工程师使用)
Linux环境上拉取最新包进行测试
4.线上环境
(办公环境,开发环境, 测试环境,也统称为 线下环境,外界用户无法
访问到的)
线上环境则是 外界用户 能够访问到的.
一旦生产环境上出问题,一定会对于用户的使用产生影响!!
直接影响到公司营收。
4.常用的数据结构
4.1认识数据类型和编码方式

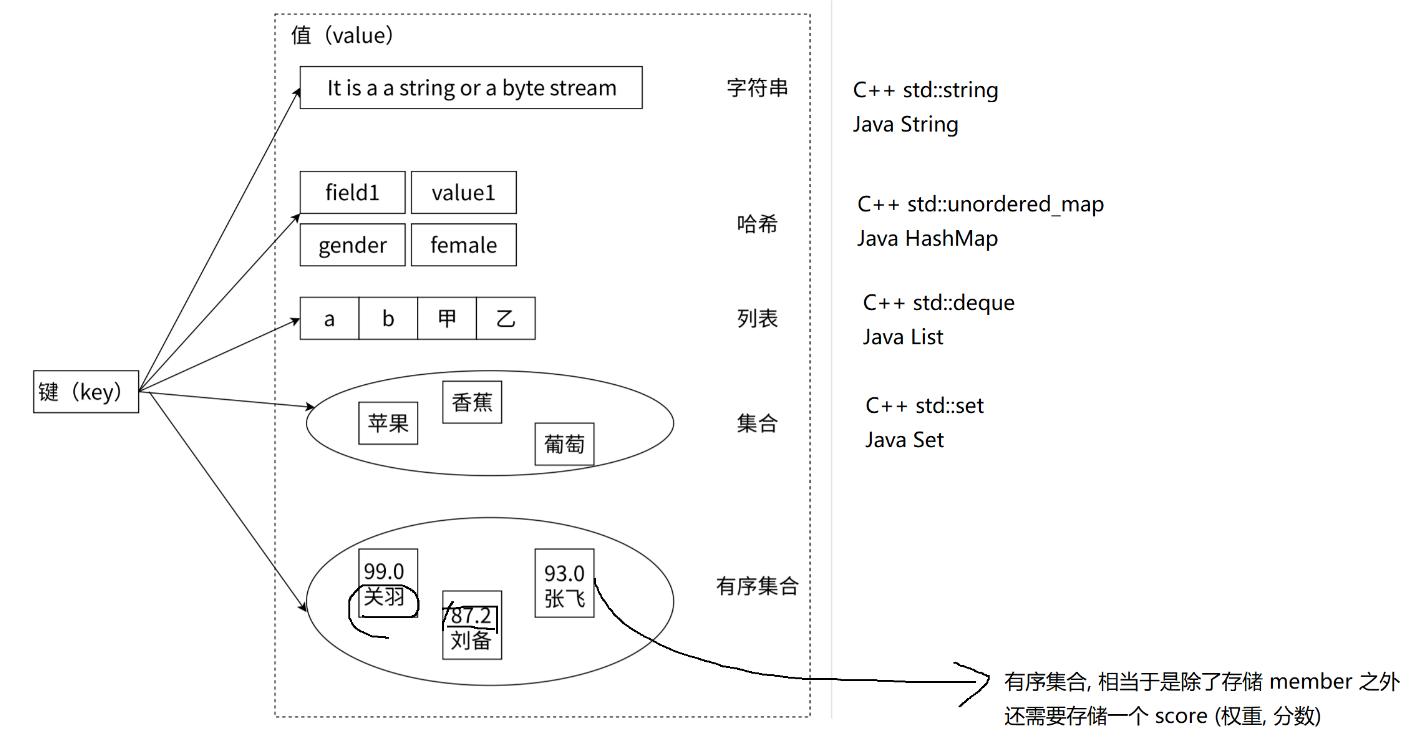
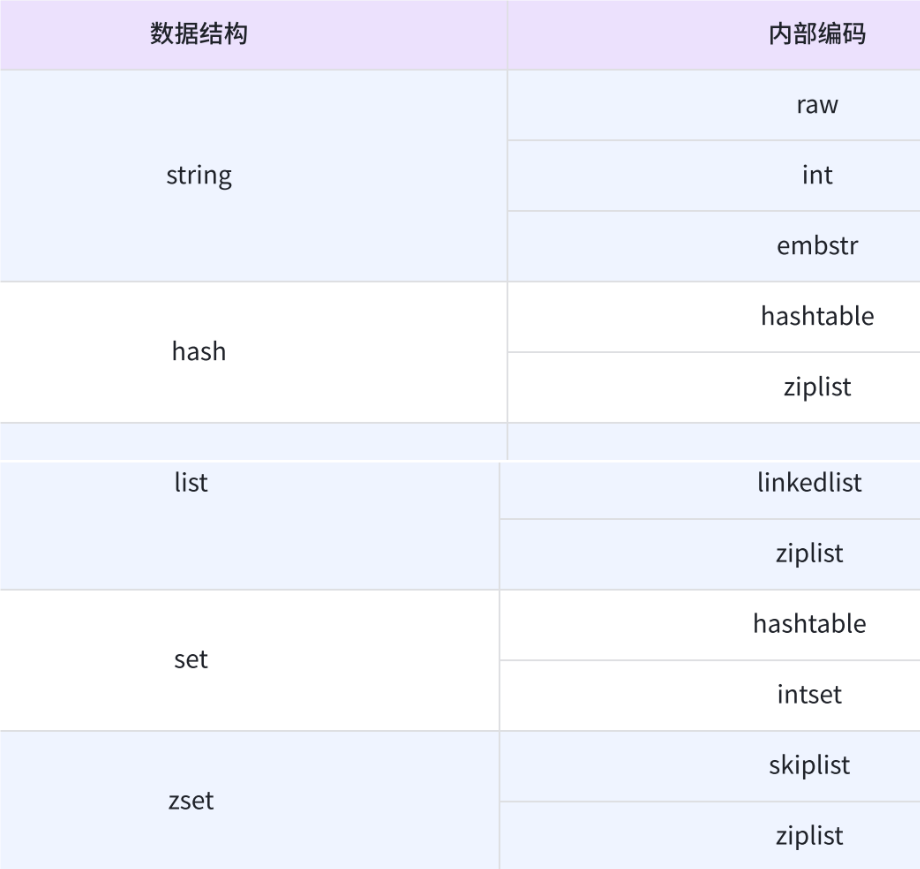
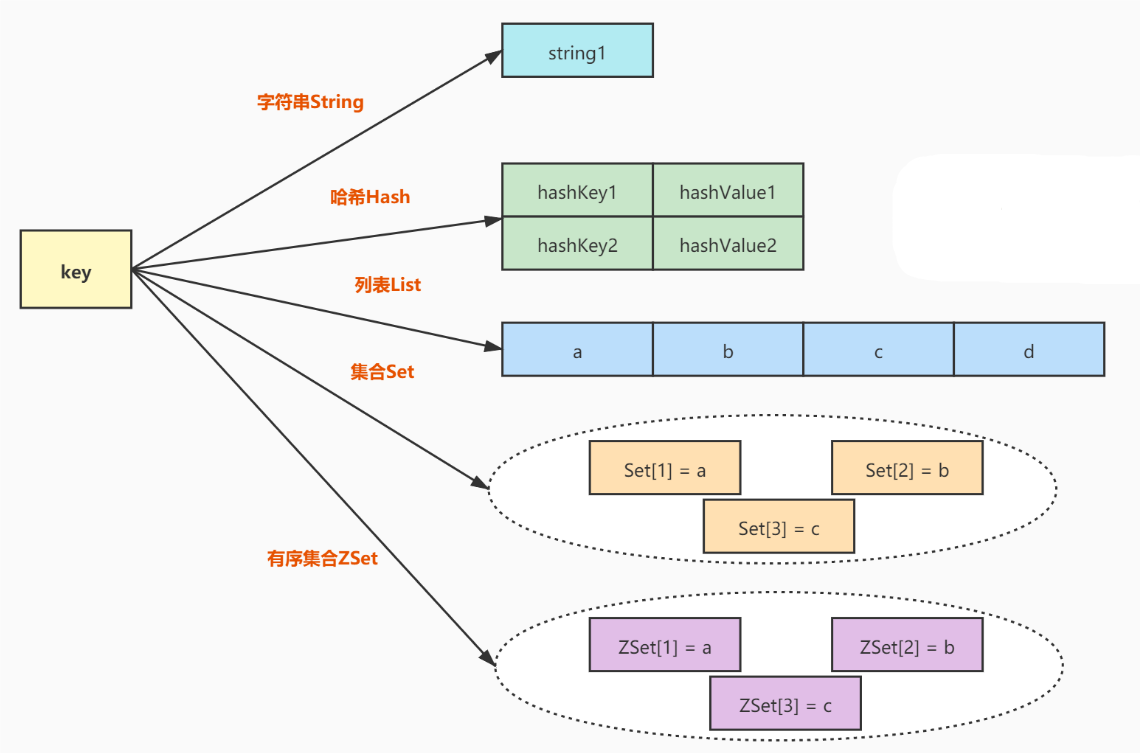
Redis 底层在实现上述数据结构的时候,会在源码层面,针对上述实现进行特定的优化,来达到 节省时间/节省空间 效果
特定的优化:内部的具体实现的 数据结构(编码方式),还会有变数。
redis 承诺, 现在我这有个 hash 表,你进行 査询,插入, 删除 操作,都保证 O(1)
但是,这个背后的实现,不一定就是一个标准的 hash 表.可能再特定场景下,使用别的数据结构实现,但是仍然保证时间复杂度符合承诺!!!
5.单线程模型
5.1单线程模式的工作过程
redis只使用一个线程,处理所有的命令请求。不是说一个redis服务器进程内部真的就只有一个线程。其实也有多个线程,多个线程是在处理 网络 IO。
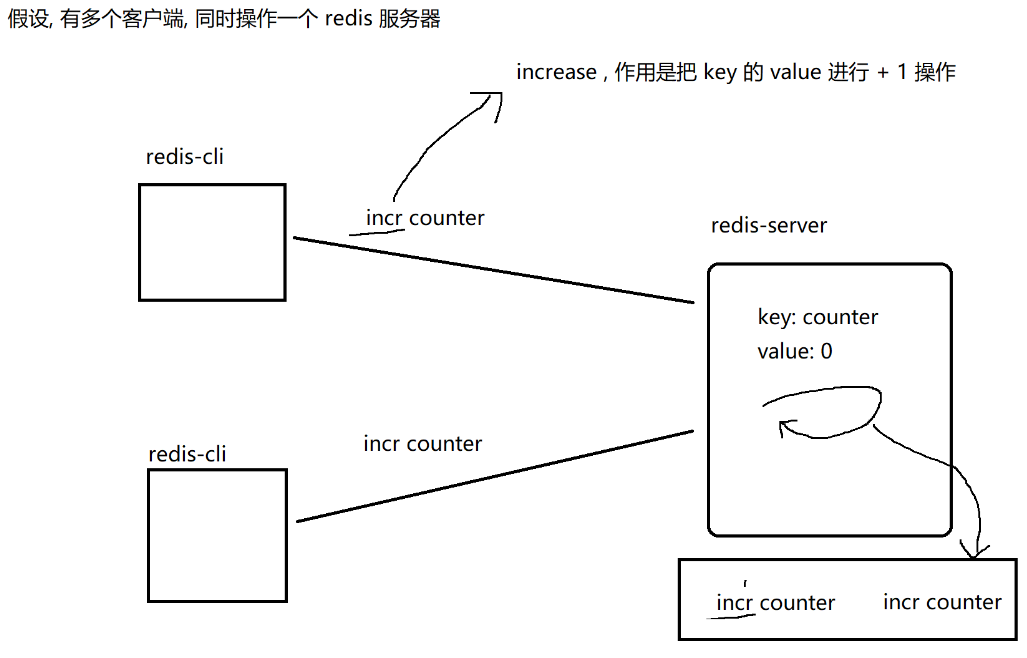

但是redis不会出现这个问题,redis服务器使用的是单线程模式。保证了当前收到的这多个请求是串行执行的。redis的核心业务逻辑,都是短平快的,不太消耗 cpu
资源也就不太吃多核了。
redis使用单线程缺点:redis必须要特别小心,某个操作占用时间长,就会阻塞其他命令的执行。
5.2 redis相关面试题
redis 虽然是单线程模型,为啥效率这么高呢?速度这么快呢?重要面试题参照物:mysql,oracle,sql,server
答:
1.redis 访问内存,数据库则是访问硬盘。
2.redis 核心功能,比数据库的核心功能简单。
数据库对于数据的插入删除査询....都有更复杂的功能支持,这样的功能势必要花费更多的开销。比如,针对插入删除,数据库中的各种约束,都会使数据库做额外的工作.
redis 干的活少,提供的功能相比于 mysq! 也是少了不少
3.单线程模型,避免了一些不必要的线程竞争开销。
redis每个基本的操作都是短平快的,就是简单操作一下内存数据,不是什么特别消耗 cpu 的操作。就算多搞个线程,也提升不大。
4.处理网络 IO 的时候,使用了 epoll 这样的 IO 多路复用机制。
IO 多路复用机制:一个线程,就可以管理多个 socket
针对 TCP 来说,服务器这边每次要服务一个客户端,都需要给这个客户端安排一个 socket
一个服务器服务多个客户端,同时就有很多个 socket.
这些 socket 上都是无事不刻的在传输数据嘛???
很多情况下,每个客户端和服务器之间的通信也没那么频繁,此时这么多 socket 大部分时间都是 静默 的,上面是没有数据需要传输的
同一时刻,只有少数 socket 是活跃的


IO多路复用 生活中的例子可以为我们有三个人想买三个小吃:臭豆腐、烤鸡腿、烤冷面。
自己去,先买臭豆腐, 等.再买烤鸡腿,等.再买烤冷面,等.这样的方案效率是最低的(单线程服务多个socket)
那么我们平时线程处理socket时是一个一个处理,就是a买臭豆腐,b买烤鸡腿,c买烤冷面。这样我们速度很快但是开销很大。(多线程服务多socket)
使用了IO多路复用后,我们可以自己先去买臭豆腐,用等待时间再去买烤鸡腿,然后继续用等待时间去买烤冷面,这三个哪一个先好了,对应的老板可以喊我们一嗓子(epoll事件通知/回调机制)。这时我们速度很快开销也很小。(IO多路复用)
感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘