
核心速览
研究背景
-
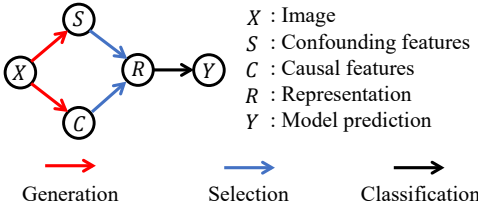
研究问题:这篇文章要解决的问题是服装变化人物再识别(CC-ReID),即在不同的摄像头视角或时间段内匹配同一个人的图像,同时考虑到姿势、光照和服装变化等因素引起的外观变化。
-
研究难点:该问题的研究难点包括:传统方法依赖于多模态数据或手动标注的服装标签,这不仅增加了模型的复杂性,还需要大量的人工努力;深度神经网络(DNN)倾向于利用训练分布中的细微统计相关性进行预测,导致在服装变化环境下出现"捷径"现象,即模型忽略了其他特征而仅依赖服装特征,从而降低了泛化能力。
-
相关工作:早期的人再识别研究主要集中在不换衣服的场景下,这些方法在短期数据集上表现良好,但在长期数据集上性能显著下降。现有的方法主要通过结合多模态数据或使用手工标注的服装标签来解决问题,但这些方法需要额外的模型和训练时间,并且引入了额外的偏差。
研究方法
这篇论文提出了一种基于密度比估计的特征解相关技术(DEAR),用于解决CC-ReID问题。具体来说,
- 概念分离:首先,假设卷积神经网络(CNN)中的每个滤波器一致地表示相同的概念。通过K-means聚类将滤波器分组,并最大化组间相似性和最小化组内相似性。
- 概念解相关:为了有效测量特征的相关性,采用密度比估计的方法。
- 训练过程 :DEAR的训练过程分为两个阶段:
- 阶段I:应用K-means算法对预训练的ResNet50生成的特征进行索引,定期更新ReID骨干网络以确保准确的标签。然后,DEAR对原始人物特征进行随机打乱以创建解相关分布。
- 阶段II:优化域分类器以识别特征的来源。一旦域分类器的参数固定,最小化身份分类损失和概念惩罚项,同时最大化密度比损失。



实验设计
实验在三个公开的CC-ReID数据集上进行评估:PRCC、LTCC和VC-Clothes。实验使用了两种常见的评估指标:top-1准确率和mAP。定义了三种不同的测试设置:一般设置、服装变化设置(CC)和相同服装设置(SC)。实验设计包括:
- 数据预处理:对图像进行全局平均池化和全局最大池化,拼接特征并通过BatchNorm归一化,输入图像调整为384 x 192,并应用随机水平翻转、裁剪和擦除等数据增强技术。
- 训练过程:训练共进行150个epoch,批量大小为64,包含8个人和每个人的8张图像,使用Adam优化器,学习率设置为3.5e-4,每20个epoch衰减10倍。
结果与分析
-
与现有方法的比较:在LTCC和PRCC数据集上,DEAR方法在所有评估指标上均优于现有的最先进方法,包括标准ReID模型和专门为服装变化场景设计的模型。

-
在大规模数据集上的评估:在LaST和DeepChange数据集上,DEAR方法也表现出优越的性能,特别是在与CAL方法的对比中,DEAR在没有额外数据的情况下显著提高了模型的性能。

-
特征可视化:使用t-SNE在2D特征空间中对特征分布进行可视化,结果显示DEAR方法能够有效区分和聚类同一人在不同服装状态下的特征嵌入。
-
注意力图分析:通过类激活映射(CAM)生成的热图分析模型的学习情况,发现基线模型主要关注服装,而DEAR方法则优先关注头部和鞋子,特别是面部特征。

总体结论
本文提出了一种名为密度比正则化(DEAR)的新方法,用于解决CC-ReID问题。通过引入对抗损失项,鼓励模型生成解相关的特征。实验结果表明,DEAR方法在多个数据集上均显著优于基线方法,特别是在服装变化场景下,DEAR能够有效提高模型的鲁棒性和泛化能力。
论文评价
优点与创新
- 提出了密度比正则化(DEAR)方法:通过计算模型特征分布与重新采样生成的"去相关"特征分布之间的密度比,鼓励模型生成低相关特征。
- 无需额外数据和标签:该方法不依赖于额外的数据或标签,适用于广泛的当前方法,提供了显著的改进。
- 理论分析:对特征去相关操作进行了理论证明,展示了其在消除混杂特征方面的有效性。
- 实验验证:在多个流行的长时变装人物再识别(CC-ReID)数据集上进行了全面的实验,验证了DEAR方法的有效性。
- 注意力图分析:通过热图可视化展示了模型在不同设置下的注意力变化,证明了DEAR方法在长时变装人物再识别任务中的优势。
- 特征可视化:使用t-SNE对特征分布进行二维可视化,展示了DEAR方法在减少特征差异和增强特征区分度方面的能力。
不足与反思
- 局限性:论文中提到,尽管DEAR方法在多个数据集上表现出色,但在某些特定场景下可能仍需进一步优化和调整。
- 下一步工作:未来的研究可以进一步探索DEAR方法的适用性和扩展性,例如在不同类型的视觉数据(如视频、三维数据等)上的应用。
关键问题及回答
问题1:DEAR方法如何通过密度比估计来实现特征解相关?
DEAR方法通过密度比估计来实现特征解相关。具体步骤如下:
- 构建无相关数据分布:首先,从特征分布中通过重采样生成一个无相关的数据分布。例如,使用K-means聚类将卷积神经网络(CNN)中的滤波器分组,并生成无相关特征分布。
- 概率分类方法:采用概率分类方法估计密度比。假设有两个类别,分别表示原始特征和无相关特征,使用多层感知器(MLP)作为分类器,
- 优化过程:在训练过程中,通过最小化身份分类损失和概念分类损失,同时最大化密度比损失,迫使骨干网络生成低相关性的特征。
问题2:DEAR方法在实验中是如何验证其有效性的?
DEAR方法在多个公开数据集上进行了广泛的实验验证,具体包括:
- 数据集:实验在三个公开的CC-ReID数据集上进行:PRCC、LTCC和VC-Clothes。
- 评估指标:使用top-1准确率和mAP两种常见指标进行评估。
- 测试设置:定义了三种不同的测试设置:
- 一般设置:使用服装一致和服装变化的样本计算准确率。
- 服装变化设置(CC):仅使用服装变化的样本计算准确率。
- 相同服装设置(SC):仅使用相同服装的样本计算准确率。
- 对比方法:DEAR方法与多种最先进的ReID模型进行对比,包括标准ReID模型和专门针对服装变化场景的模型。
实验结果表明,DEAR方法在不使用额外数据和标签的情况下,一致优于所有现有的方法,特别是在应对服装变化方面,显著提高了模型的鲁棒性和泛化能力。
问题3:DEAR方法在注意力图分析中表现出哪些特点?
通过类激活映射(CAM)生成的热图分析模型的学习情况,DEAR方法表现出以下特点:
- 基线模型:基线模型主要关注服装,而忽略了头部和其他重要特征,这导致了在服装变化设置下性能较差。
- DEAR方法:DEAR方法则优先关注头部和鞋子,特别是面部特征。这表明DEAR方法能够有效地识别出与身份相关的关键特征,而减少了对服装的关注。
- 特征选择:DEAR方法通过特征解相关,使得模型能够更好地选择与身份相关的特征,从而提高了在服装变化环境下的性能。
这些观察结果进一步验证了DEAR方法在特征选择和识别方面的有效性,特别是在应对服装变化时,能够显著提高模型的鲁棒性和准确性。