文章目录
- Pytorch|李沐动手学深度学习:数学基础(一)
-
- (一)线性代数
-
- [1. 基础 + 实战](#1. 基础 + 实战)
-
- (1)标量
- (2)向量
- (3)矩阵
- (4)张量
- (5)张量算法的基本性质
- (6)降维
- (7)非降维求和
- [(8)点积(dot product)](#(8)点积(dot product))
- (9)矩阵-向量积
- (10)矩阵-矩阵乘法
- (11)范数
- (12)特征向量和特征值
- [2. 练习](#2. 练习)
- (二)微积分
-
- [1. 基础 + 实战](#1. 基础 + 实战)
- [2. 练习](#2. 练习)
- 参考
Pytorch|李沐动手学深度学习:数学基础(一)
(一)线性代数
1. 基础 + 实战
(1)标量
- 仅包含一个数值被称为标量(scalar),**变量(variable)**表示未知的标量值。
- 标量由只有一个元素的张量表示。
python
# 创建标量并执行基础算术运算
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x ** y
(2)向量
- 向量 可被视为标量值组成的列表,这些标量值被称为向量的元素(element)或分量(component)。
- 向量由一维张量表示。
- 张量可以具有任意长度,取决于机器的内存限制。
- 向量为行向量,可以用二维矩阵来区分行向量和列向量。
python
# 创建向量
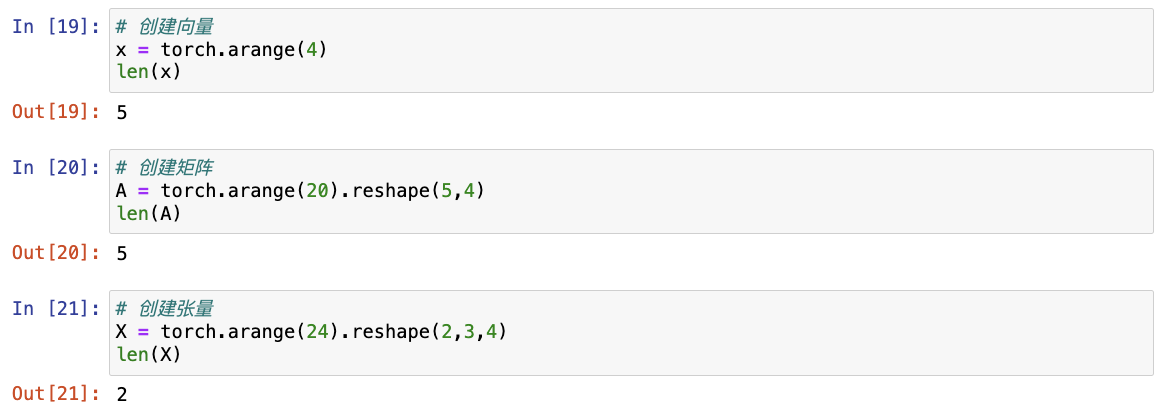
x = torch.arange(4)
x
# 通过张量索引访问向量的元素
x[3]
-
向量的长度通常称为向量的维度。
-
可以通过调用Python的内置
len()函数或者.shape属性来访问向量的长度。
python
# 通过调用Python的内置len()函数来访问向量的长度
len(x)
# 通过.shape属性访问向量的长度
x.shape
注意 :向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。 然而,张量的维度用来表示张量具有的轴数,张量的某个轴的维数就是这个轴的长度,如果直接使用 len() 来访问张量的长度,则显示的为第一个轴的长度。
(3)矩阵
- 正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。
- 当矩阵具有相同数量的行和列时,被称为方阵(square matrix)。
python
# 创建矩阵
A = torch.arange(20).reshape(5, 4)
A
# 访问矩阵元素
A[1,1]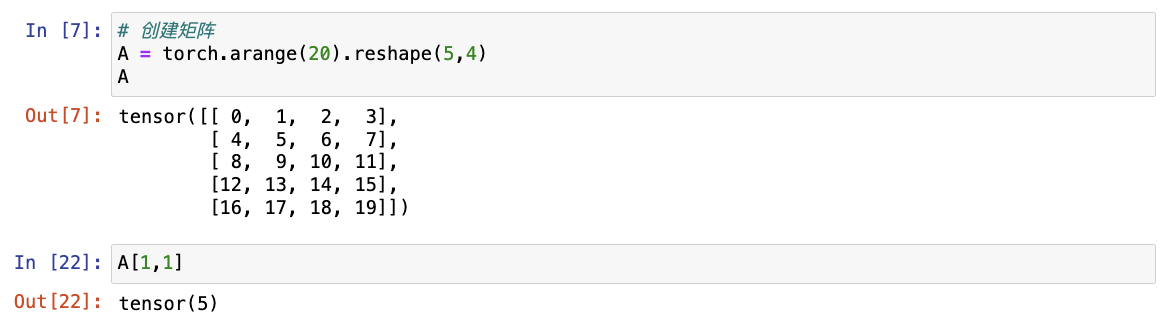
python
# 访问矩阵的转置
A.T
# 对称矩阵(symmetric matrix)等于其转置
B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B == B.T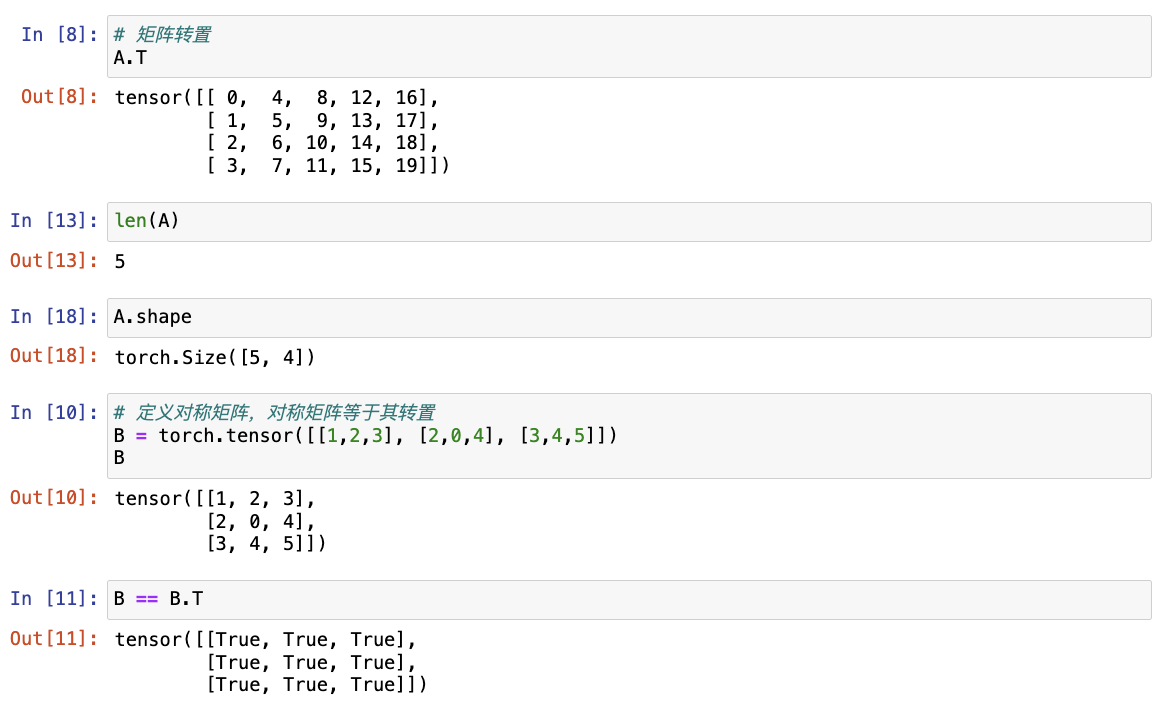
注意:尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见,这种约定将支持常见的深度学习实践,如沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。
(4)张量
- 张量是描述具有任意数量轴的 n 维数组的通用方法,向量是一阶张量,矩阵是二阶张量。
python
# 创建张量
X = torch.arange(24).reshape(2, 3, 4)
X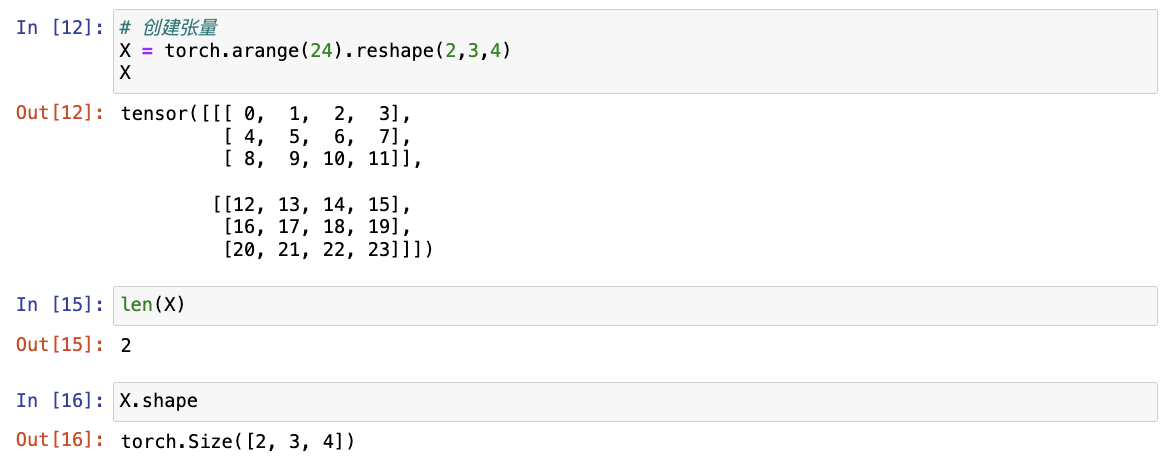
(5)张量算法的基本性质
- 任何按元素的一元运算都不会改变其操作数的形状。
- 给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量,如将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
python
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
注意 :如果直接 B = A,不会对 B 进行任何内存的分配,只是重新设定了索引,使用B = A.clone() 则可以对 B 重新分配内存,使 A 和 B 不存在任何关系。
- 两个矩阵的按元素乘法称为 Hadamard 积,将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。

python
# 两矩阵相乘
A * B
# 张量与标量相加/相乘
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape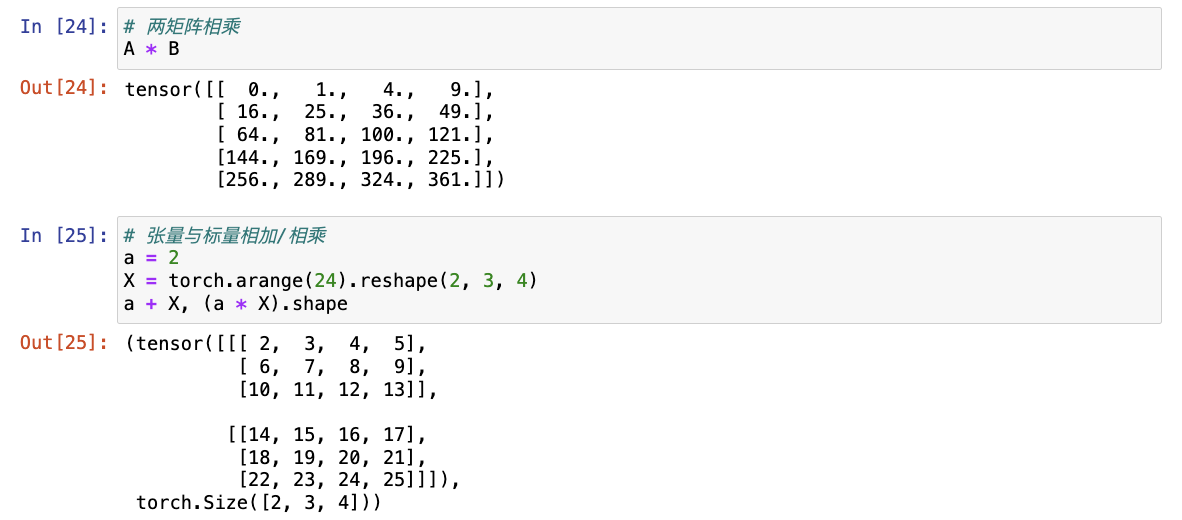
(6)降维
- 使用
sum()计算张量元素的总和。
python
# 计算向量中元素总和
x = torch.arange(4, dtype=torch.float32)
x, x.sum()
# 计算矩阵中元素总和
A.shape, A.sum()
- 默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。
- 通过指定
axis可以指定张量沿哪一个轴来通过求和降低维度。 - 沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
python
# 通过求和所有行的元素来降维(轴0)
# 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
# 指定 axis=1 将通过汇总所有列的元素降维(轴1)
# 输入轴1的维数在输出形状中消失
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
# 沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和
A.sum(axis=[0, 1]) # 结果和A.sum()相同
补充 :axis = 0 按照行,可以理解为把"行"给抹去只剩1行,也就是上下压扁;axis = 1 按照列,可以理解为把"列"给抹去只剩1列,也就是左右压扁。
- 平均值(mean或average) :通过将总和除以元素总数来计算,可以调用函数
mean()来计算任意形状张量的平均值。
python
# 计算平均值
A.mean(), A.sum() / A.numel()
# 指定轴计算平均值
A.mean(axis=0), A.sum(axis=0) / A.shape[0]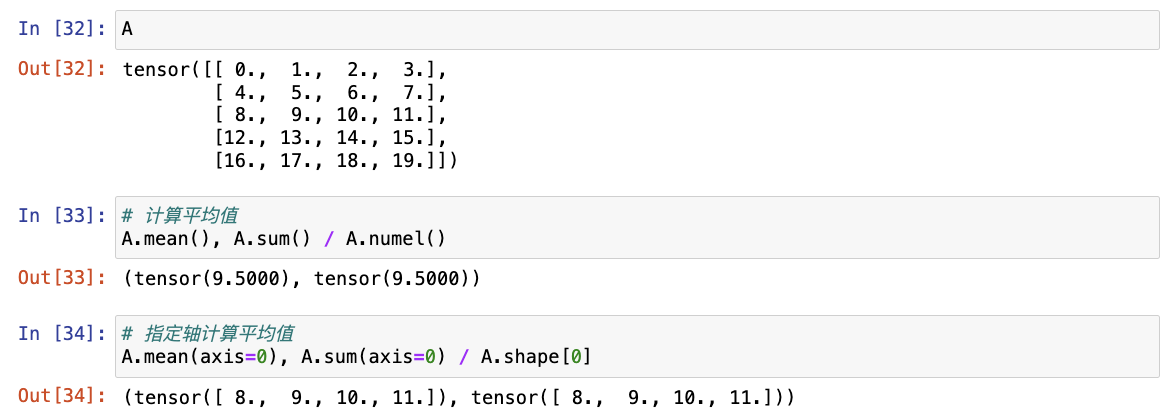
(7)非降维求和
-
在调用函数来计算总和或均值时保持轴数不变。
sum_A = A.sum(axis=1, keepdims=True)
sum_A, sum_A.shape -
由于
sum_A在对每行进行求和后仍保持两个轴,可以通过广播将A除以sum_A。A / sum_A
-
可以调用
cumsum函数沿某个轴计算A元素的累积总和, 不会沿任何轴降低输入张量的维度。
python
A.cumsum(axis=0)
(8)点积(dot product)
-
给定两个向量,其点积(dot product)为相同位置的按元素乘积的和。
调用 dot 函数计算点积
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)通过执行按元素乘法,然后进行求和来表示两个向量的点积
torch.sum(x * y)

- 给定一组由向量 x 表示的值和一组由 w 表示的权重,其点积可以表示为向量 x 根据权重 w 的加权和。
- 当权重为非负数且和为1 时,点积表示加权平均(weighted average)。
- 将两个向量规范化得到单位长度后,点积表示其夹角的余弦。
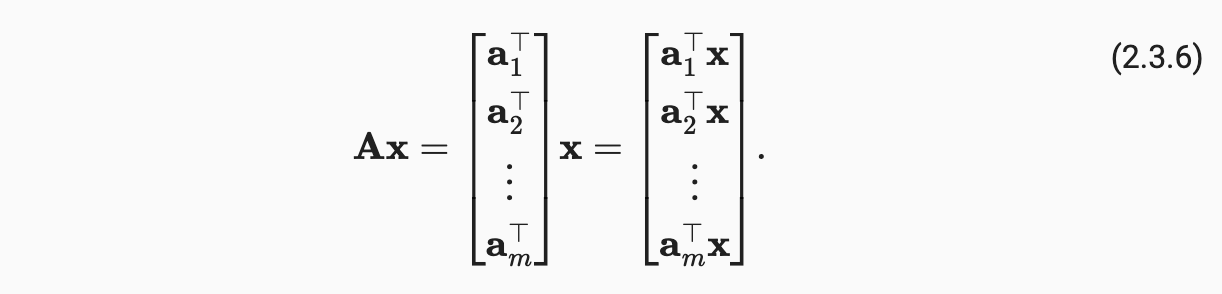
(9)矩阵-向量积
- 给定矩阵 A 和向量 x,其向量积为矩阵 A 的每个行向量与向量 x 的点积。
python
# 使用 mv 函数,执行矩阵-向量积
A.shape, x.shape, torch.mv(A, x)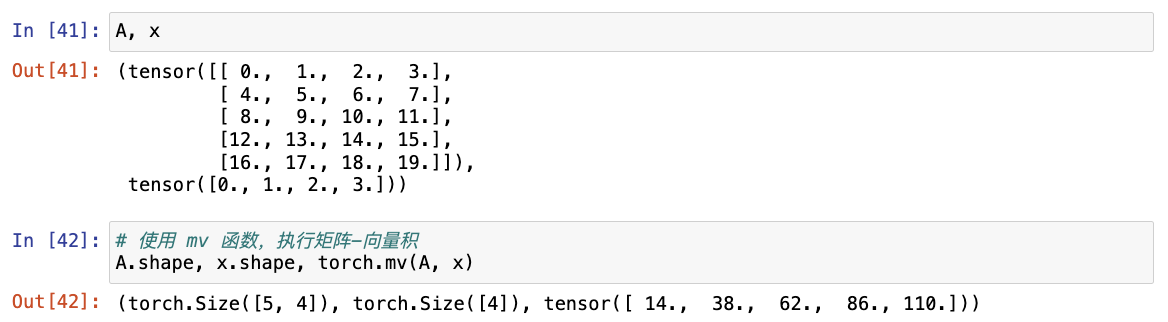
注意:A 的列维数(沿轴1的长度)必须与 x 的维数(其长度)相同。
(10)矩阵-矩阵乘法
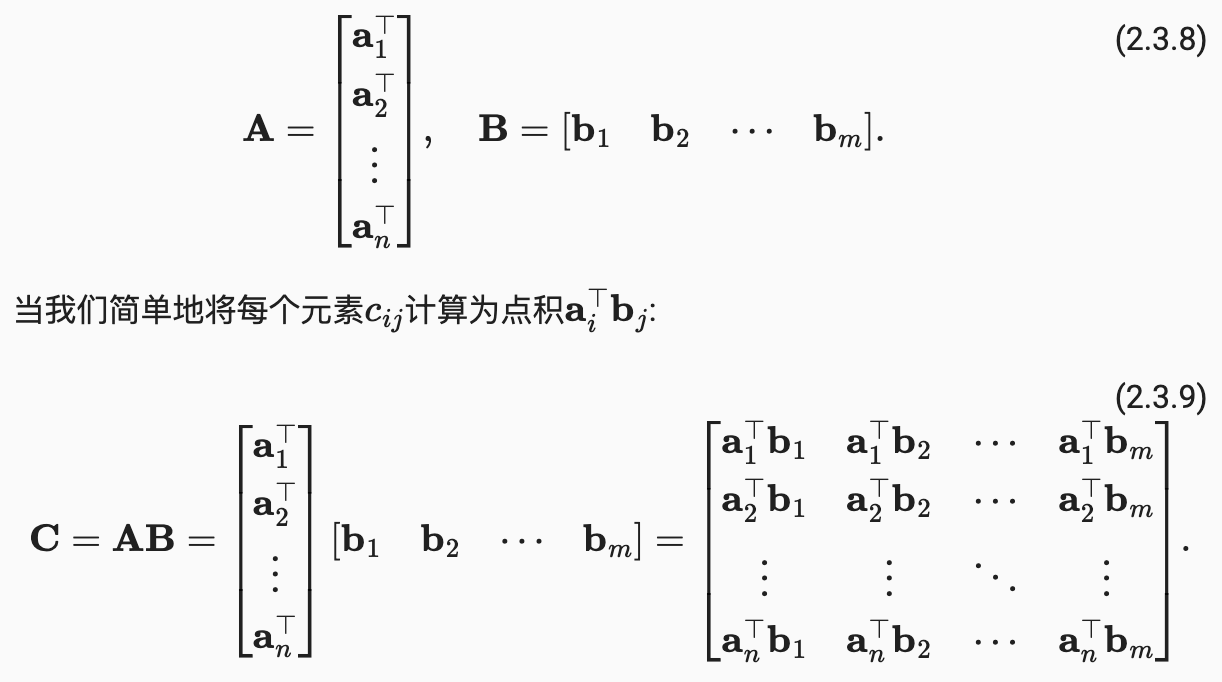
- 给定两个矩阵 A(n×k)和B(k×m),矩阵-矩阵乘法 AB 可以看作简单地执行m次矩阵-向量积,并将结果拼接在一起,形成一个 n×m 矩阵。
python
B = torch.ones(4, 3)
torch.mm(A, B)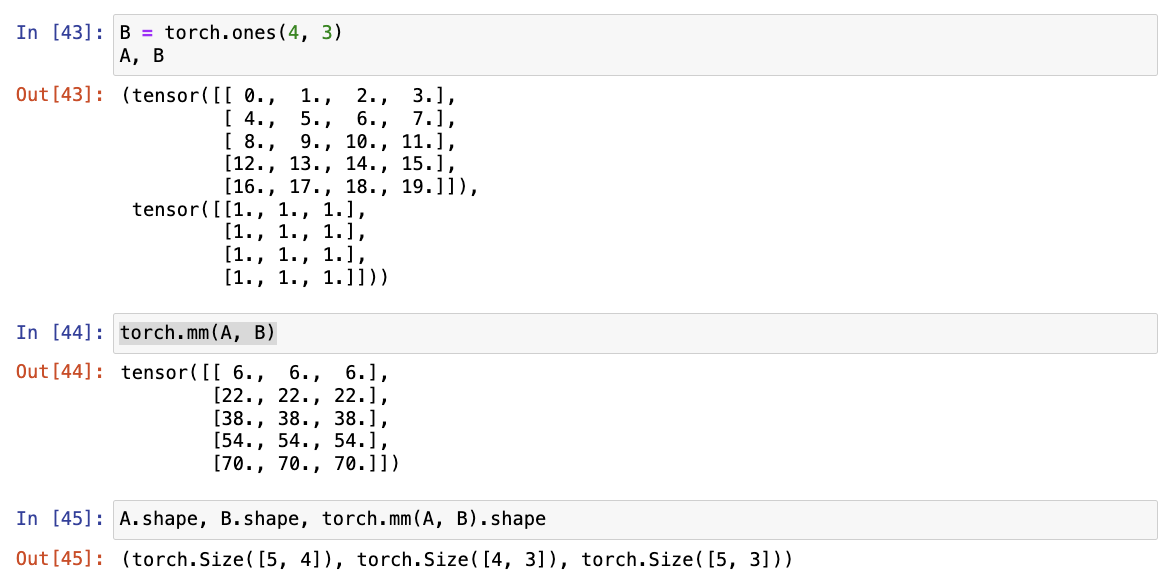
注意 :矩阵-矩阵乘法可以简单地称为矩阵乘法,但与"Hadamard积"不同。
(11)范数
-
向量的范数表示一个向量有多大,此处的大小(size)不涉及维度,而是分量的大小;在线性代数中,向量范数是将向量映射到标量的函数 f;给定任意向量x,向量范数要满足一些属性:
-
如果按常数因子 α 缩放向量的所有元素,其范数也会按相同常数因子的绝对值缩放
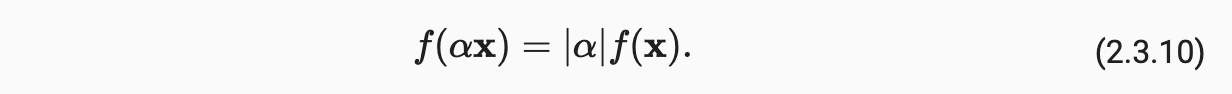
-
三角不等式
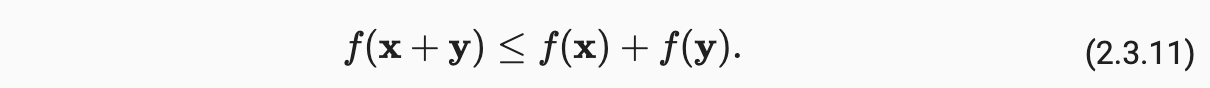
-
范数必须是非负的;范数最小为0,当且仅当向量全由0组成
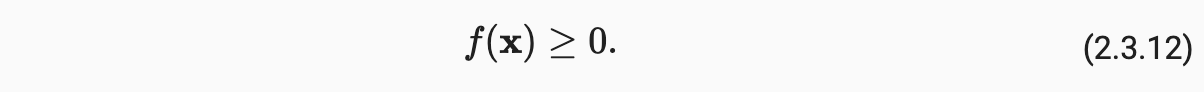
-
-
范数听起来很像距离的度量,欧几里得距离是一个L2范数(向量元素平方和的平方根)。
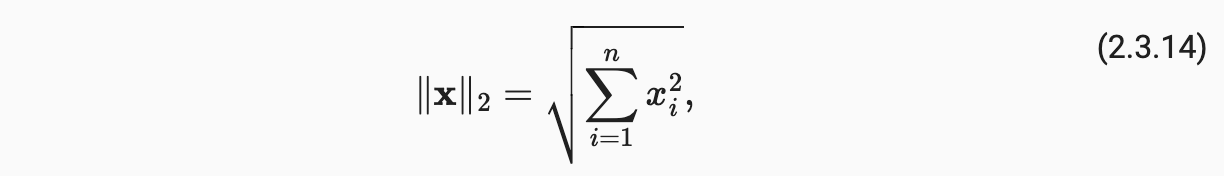
-
深度学习中更经常地使用L2范数的平方,也会经常遇到L1范数,表示为向量元素的绝对值之和。

-
L2范数和L1范数都是更一般的Lp范数的特例。
python
# 计算向量的 L2 范数(向量元素平方和的平方根)
u = torch.tensor([3.0, -4.0])
torch.norm(u)
# 计算向量的 L1 范数(向量元素的绝对值之和)
torch.abs(u).sum()
注意:与L2范数相比,L1范数受异常值的影响较小。
-
类似于向量的L2范数,矩阵的Frobenius范数(Frobenius norm)是矩阵元素平方和的平方根(最常用):

python
# 计算矩阵的 Frobenius 范数
torch.norm(torch.ones((4, 9)))
在深度学习中,经常试图解决优化问题: 最大化分配给观测数据的概率; 最小化预测和真实观测之间的距离。 用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。 目标 是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
(12)特征向量和特征值
- 特征向量为不被矩阵改变方向的向量。向量与矩阵相乘时结果仍为向量,可以看作为原先向量与矩阵相乘后发生了空间扭曲于是变成了新向量,而特征向量则表示在受矩阵的空间扭曲作用下仍然保持方向不变的向量,其大小可以发生变化。
A x = λ x Ax=\lambda x Ax=λx
- 对称矩阵总是可以找到特征向量。
2. 练习
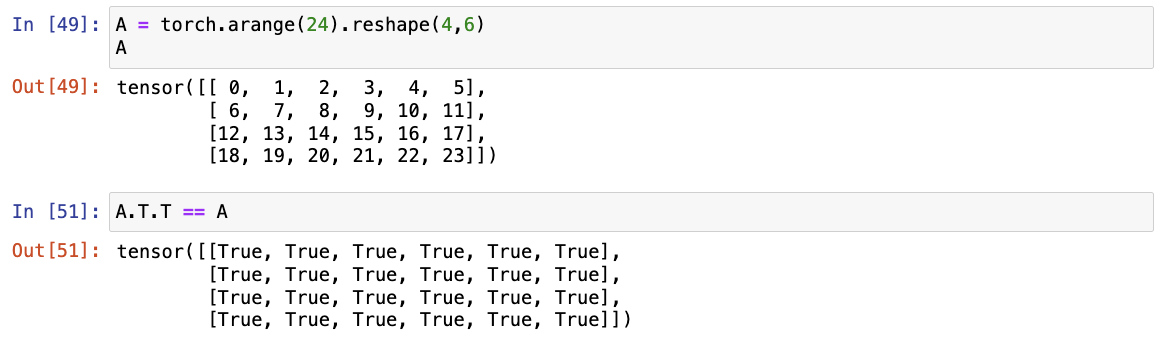
- 证明一个矩阵A的转置的转置是A,即(A⊤)⊤=A。
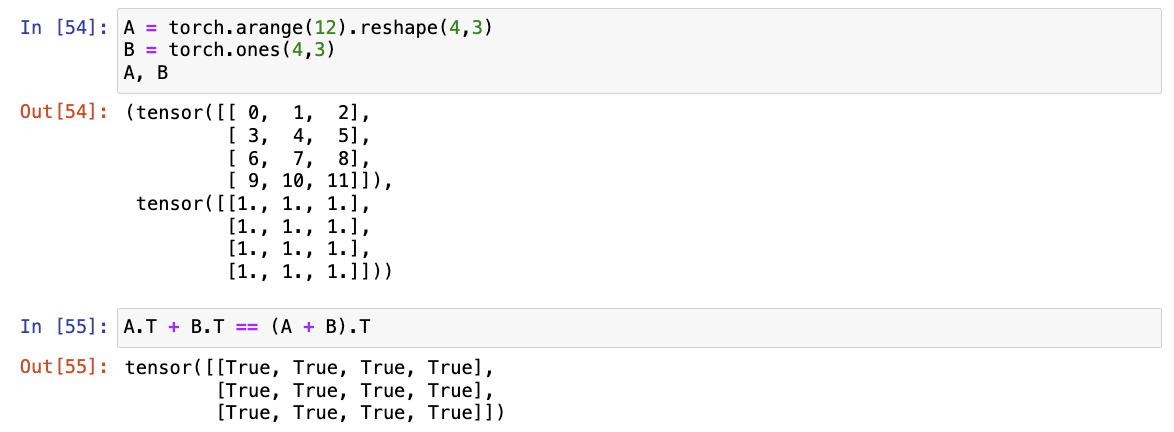
- 给出两个矩阵A和B,证明"它们转置的和"等于"它们和的转置",即A⊤+B⊤=(A+B)⊤。
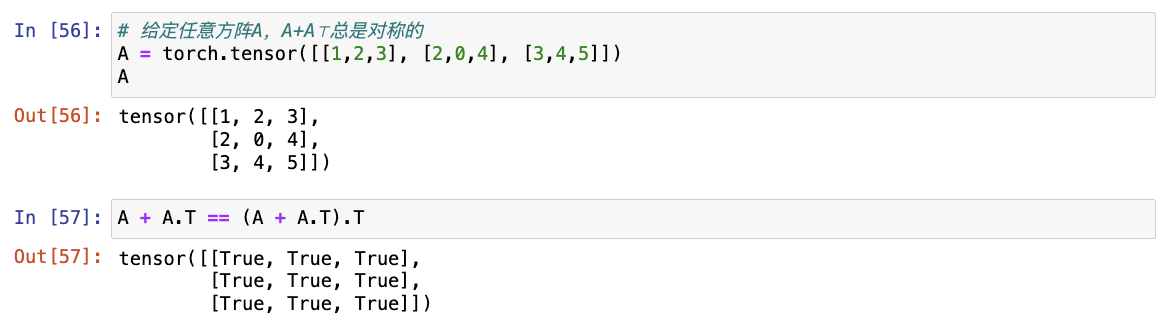
- 给定任意方阵A,A+A⊤总是对称的吗?为什么?
给定任意方阵A,A+A⊤总是对称的,因为 A = A⊤。
- 本节中定义了形状(2,3,4)的张量
X。len(X)的输出结果是什么?
len(X)的输出结果是第一轴的元素个数。

- 对于任意形状的张量
X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?
对于任意形状的张量X,len(X)总是对应于第一个轴 axis=0 的长度。

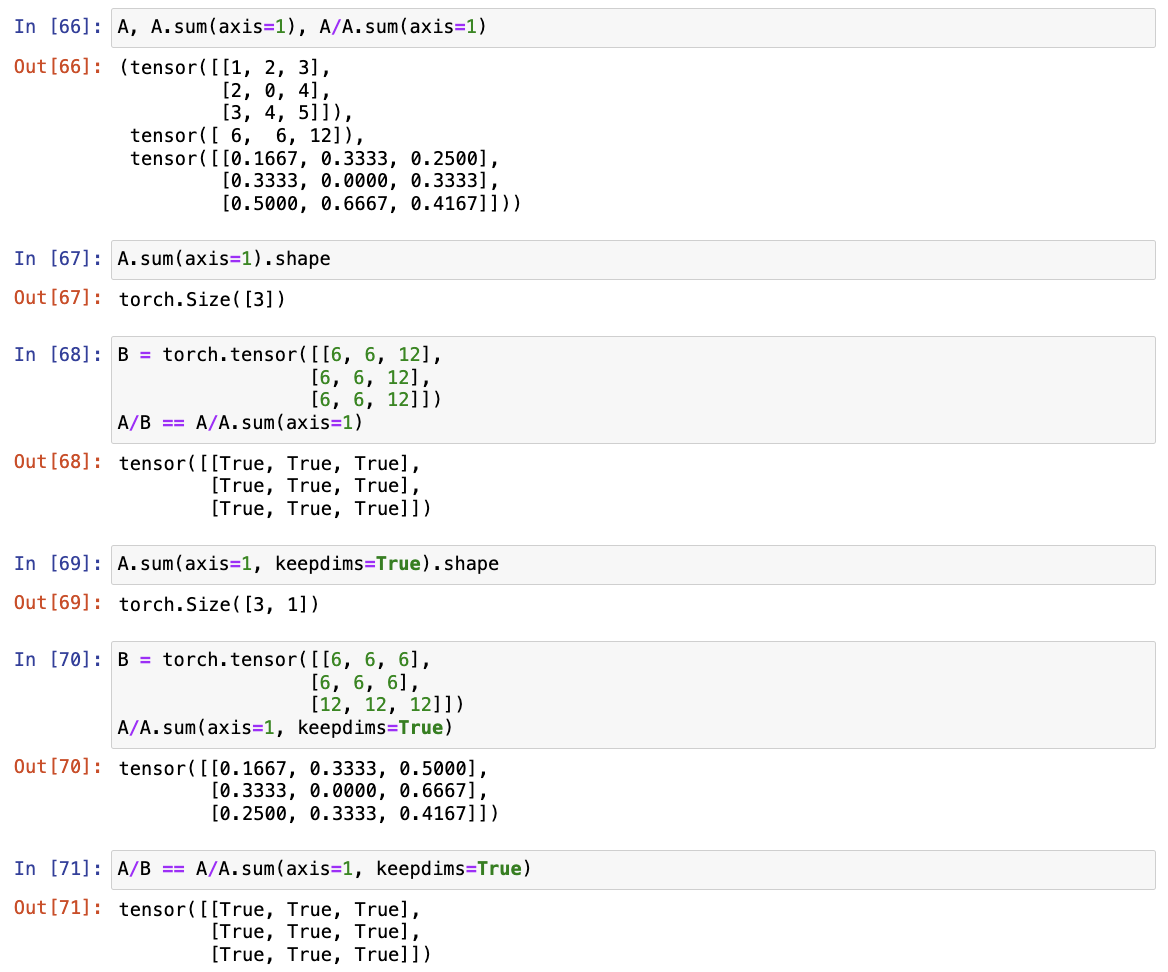
- 运行
A/A.sum(axis=1),看看会发生什么。请分析一下原因?
A.sum(axis=1) 为 A 每行所有列元素的和,由于此处没有 keepdims=TRUE, A.sum(axis=1) 变成了长度为3的向量,在 A/A.sum(axis=1) 中会先广播,使 A.sum(axis=1) 变成 3*3 的矩阵,再与 A 相除。
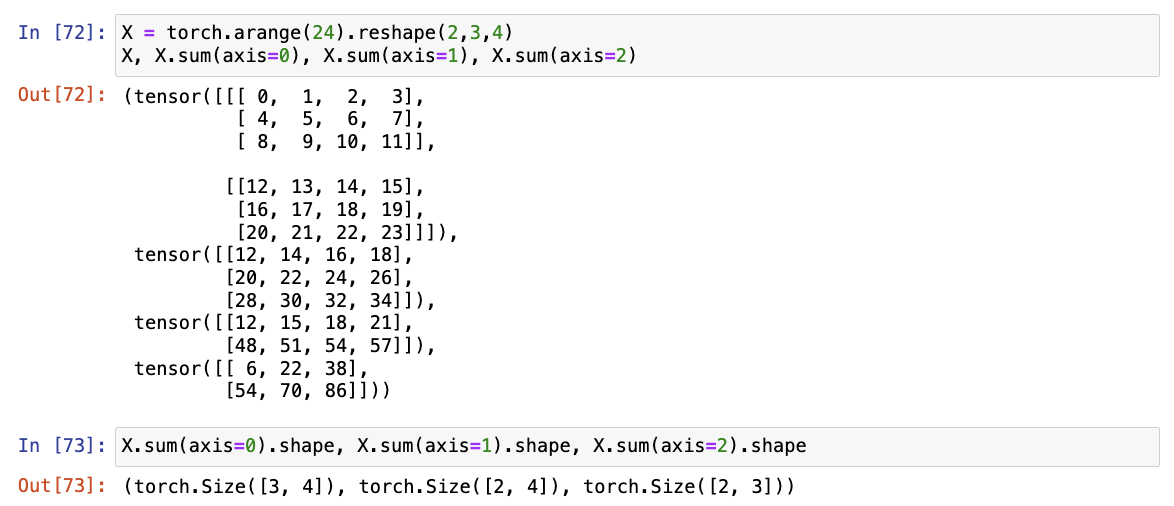
- 考虑一个具有形状(2,3,4)的张量,在轴0、1、2上的求和输出是什么形状?
在轴0、1、2上的求和输出形状会减少输出对应轴的维度。
- 为
linalg.norm函数提供3个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?

linalg.norm 默认为求第二范数L2,对于任意形状的张量均为求所有元素平方和,再开根号。

(二)微积分
- 拟合模型的任务为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):指导生成出有效性超出用于训练的数据集本身的模型。
1. 基础 + 实战
(1)导数和微分
-
在深度学习中,通常选择对于模型参数可微的损失函数 ;对于每个参数, 如果把这个参数增加 或减少一个无穷小的量即可以知道损失会以多快的速度增加或减少。
-
假设有一个函数 f,其输入和输出都是标量,如果 f 的导数 存在,这个极限被定义为
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h f'(x)=\lim_{h \to 0}\frac{f(x+h)-f(x)}{h} f′(x)=h→0limhf(x+h)−f(x)如果 f'(a) 存在,则 f 在 a 处可微;如果 f 在一个区间内的每一个数上都可微,则 f 在此区间可微。
python# 以 u=f(x)=3x^2-4x 为例理解导数 %matplotlib inline from matplotlib_inline import backend_inline from mxnet import np, npx from d2l import mxnet as d2l npx.set_np() def f(x): return 3 * x ** 2 - 4 * x def numerical_lim(f, x, h): return (f(x + h) - f(x)) / h h = 0.1 for i in range(5): print(f'h={h:.5f}, numerical limit={numerical_lim(f, 1, h):.5f}') h *= 0.1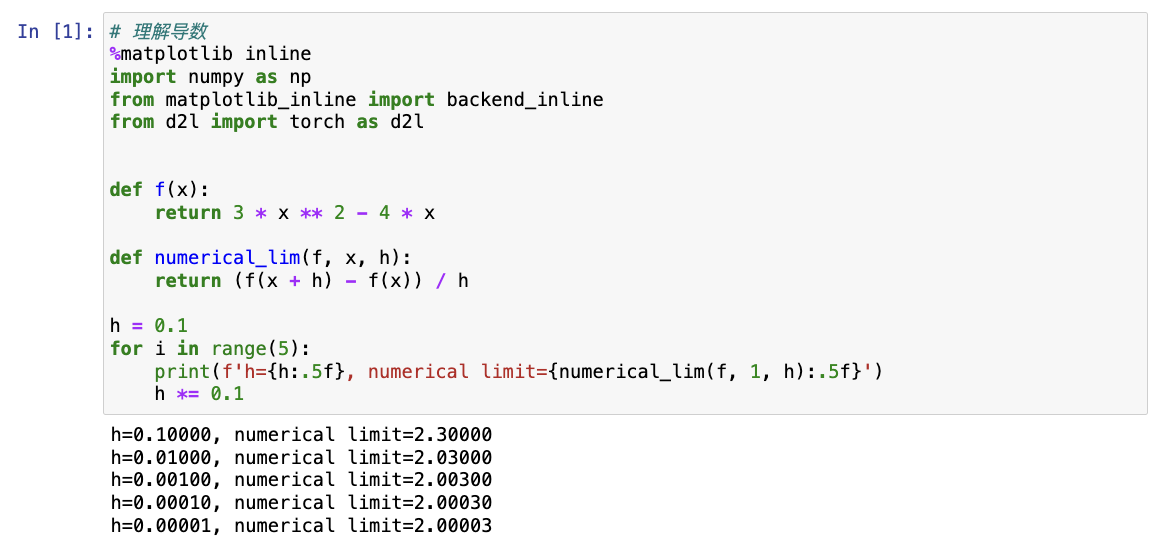
-
导数的等价符号:
f ′ ( x ) = y ′ = d y d x = d f d x = d d x f ( x ) = D f ( x ) = D x f ( x ) f'(x)=y'=\frac{{\rm d}y}{{\rm d}x}=\frac{{\rm d}f}{{\rm d}x}=\frac{{\rm d}}{{\rm d}x}f(x)=Df(x)=D_xf(x) f′(x)=y′=dxdy=dxdf=dxdf(x)=Df(x)=Dxf(x)常见函数求微分:
D C = 0 D x n = n x n − 1 D e x = e x D l n ( x ) = 1 / x DC=0 \\ Dx^n=nx^{n-1} \\ De^x=e^x \\ Dln(x)=1/x DC=0Dxn=nxn−1Dex=exDln(x)=1/x -
假设函数 f 和 g 都是可微的,C 是一个常数,则
常数相乘法则: d d x C f ( x ) = C d d x f ( x ) 加法法则: d d x f ( x ) + g ( x ) = d d x f ( x ) + d d x g ( x ) 乘法法则: d d x f ( x ) g ( x ) = f ( x ) d d x g ( x ) + g ( x ) d d x f ( x ) 除法法则: d d x f ( x ) g ( x ) = g ( x ) d d x f ( x ) − f ( x ) d d x g ( x ) g ( x ) 2 常数相乘法则:\frac{\rm d}{{\rm d}x}Cf(x)=C\frac{\rm d}{{\rm d}x}f(x) \\ 加法法则:\frac{\rm d}{{\rm d}x}f(x)+g(x)=\frac{\rm d}{{\rm d}x}f(x)+\frac{\rm d}{{\rm d}x}g(x) \\ 乘法法则:\frac{\rm d}{{\rm d}x}f(x)g(x)=f(x)\frac{\rm d}{{\rm d}x}g(x)+g(x)\frac{\rm d}{{\rm d}x}f(x) \\ 除法法则:\frac{\rm d}{{\rm d}x}\\frac{f(x)}{g(x)}=\frac{g(x)\frac{\rm d}{{\rm d}x}f(x)-f(x)\frac{\rm d}{{\rm d}x}g(x)}{g(x)^2} 常数相乘法则:dxdCf(x)=Cdxdf(x)加法法则:dxdf(x)+g(x)=dxdf(x)+dxdg(x)乘法法则:dxdf(x)g(x)=f(x)dxdg(x)+g(x)dxdf(x)除法法则:dxdg(x)f(x)=g(x)2g(x)dxdf(x)−f(x)dxdg(x)python# 图形参数设置 def use_svg_display(): #@save """使用svg格式在Jupyter中显示绘图""" backend_inline.set_matplotlib_formats('svg') def set_figsize(figsize=(3.5, 2.5)): #@save """设置matplotlib的图表大小""" use_svg_display() d2l.plt.rcParams['figure.figsize'] = figsize #@save def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend): """设置matplotlib的轴""" axes.set_xlabel(xlabel) axes.set_ylabel(ylabel) axes.set_xscale(xscale) axes.set_yscale(yscale) axes.set_xlim(xlim) axes.set_ylim(ylim) if legend: axes.legend(legend) axes.grid()注意 :注释
#@save是一个特殊的标记,会将对应的函数、类或语句保存在d2l包中,无须重新定义就可以直接调用(如d2l.use_svg_display())python# 定义plot函数来简洁地绘制多条曲线 #@save def plot(X, Y=None, xlabel=None, ylabel=None, legend=None, xlim=None, ylim=None, xscale='linear', yscale='linear', fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5), axes=None): """绘制数据点""" if legend is None: legend = [] set_figsize(figsize) axes = axes if axes else d2l.plt.gca() # 如果X有一个轴,输出True def has_one_axis(X): return (hasattr(X, "ndim") and X.ndim == 1 or isinstance(X, list) and not hasattr(X[0], "__len__")) if has_one_axis(X): X = [X] # 如果X为一个轴,将其列表化 if Y is None: X, Y = [[]] * len(X), X # 如果没有Y,X为包含X长度个空列表的大列表,Y为X elif has_one_axis(Y): Y = [Y] # 如果Y为一个轴,将其列表化 if len(X) != len(Y): X = X * len(Y) # 如果X的长度和Y的长度不一样,X改为Y长度数个X axes.cla() # 清除axes for x, y, fmt in zip(X, Y, fmts): if len(x): # 如果X的元素x不为空 axes.plot(x, y, fmt) else: axes.plot(y, fmt) set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend) # 绘制 f(x) 以及其在 x=1 处切线 y=2x-3 def f(x): return 3 * x ** 2 - 4 * x x = np.arange(0, 3, 0.1) plot(x, [f(x), 2 * x - 3], 'x', 'f(x)', legend=['f(x)', 'Tangent line (x=1)'])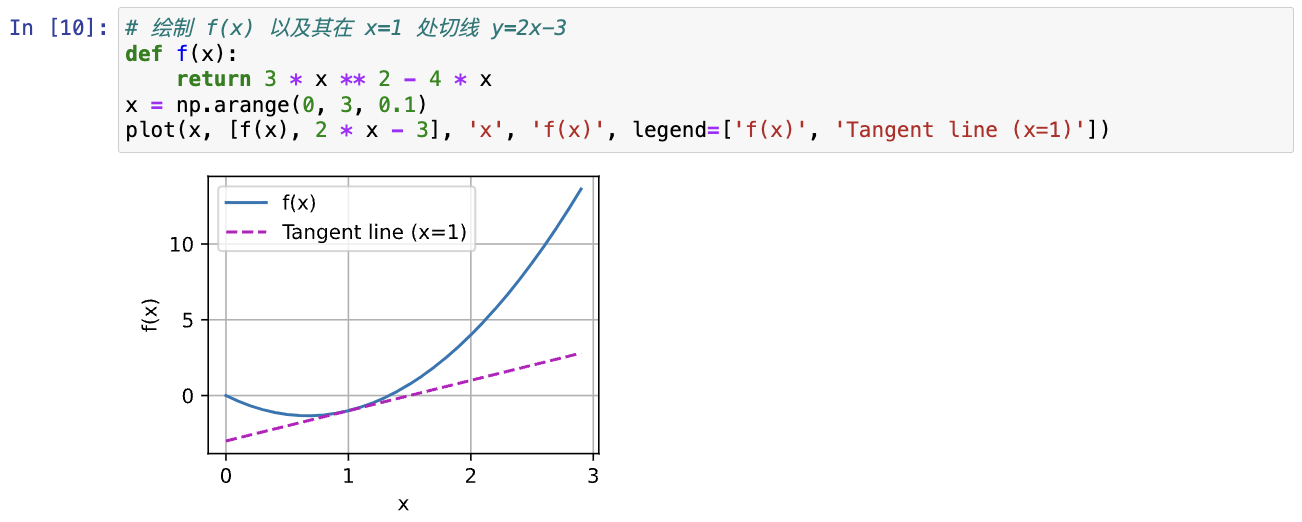
-
一般的标量导数是切线的斜率,亚导数可以将导数扩展到不可微的函数,即在函数的不可导点将导数取为一个范围内的任意值。

(2)偏导数
- 在深度学习中,函数通常依赖于多变量,因此需要将微分扩展到多元函数。

(3)梯度(gradient)
-
连接一个多元函数对其所有变量的偏导数 -> 梯度向量,梯度指向值变化最大的方向
-
将导数扩展到向量/矩阵(分子布局法)

-
分子布局法和分母布局法(https://zhuanlan.zhihu.com/p/263777564):分子转置了,就是分母布局;分母转置了,就是分子布局。
-
对于 y 为标量,x 为向量,其梯度为(分子布局法):
∂ y ∂ x = ∂ y ∂ x 1 , ∂ y ∂ x 2 , ... , ∂ y ∂ x n \frac{\partial y}{\partial x} = \\frac{\\partial y}{\\partial x_1}, \\frac{\\partial y}{\\partial x_2}, ..., \\frac{\\partial y}{\\partial x_n} ∂x∂y=∂x1∂y,∂x2∂y,...,∂xn∂y常见的梯度计算:

-
对于 y 为向量,x 为向量,其梯度为(分子布局法):
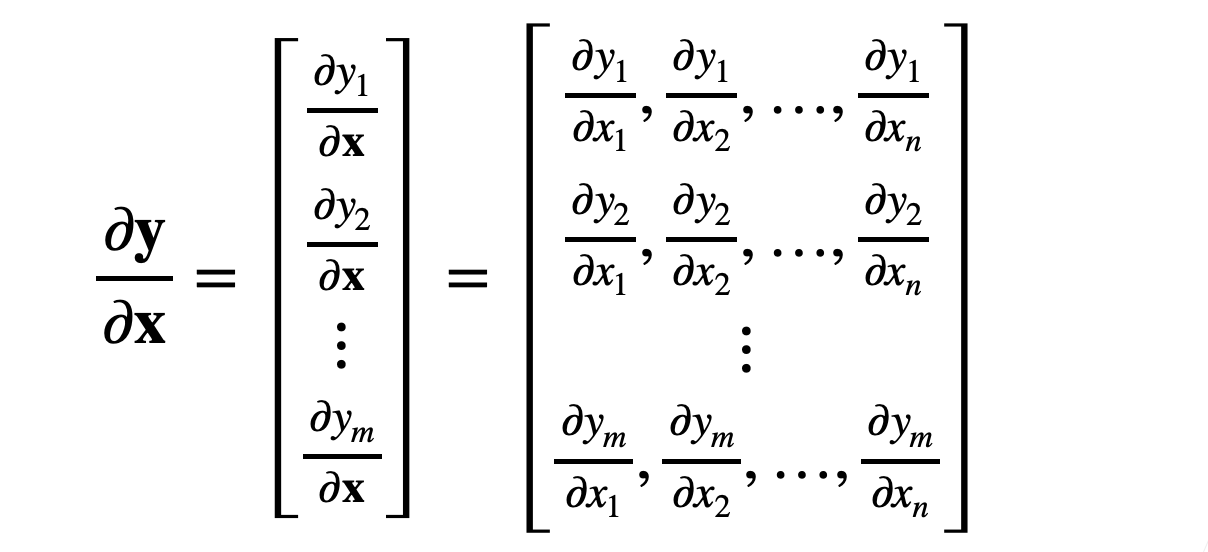
常见的梯度计算:

(4)链式法则
-
标量的链式法则:
y = f ( u ) , u = g ( x ) ∂ y ∂ x = ∂ y ∂ u ∂ u ∂ x y=f(u), u=g(x) \\ \frac{\partial y}{\partial x} = \frac{\partial y}{\partial u} \frac{\partial u}{\partial x} y=f(u),u=g(x)∂x∂y=∂u∂y∂x∂u -
向量的链式法则:
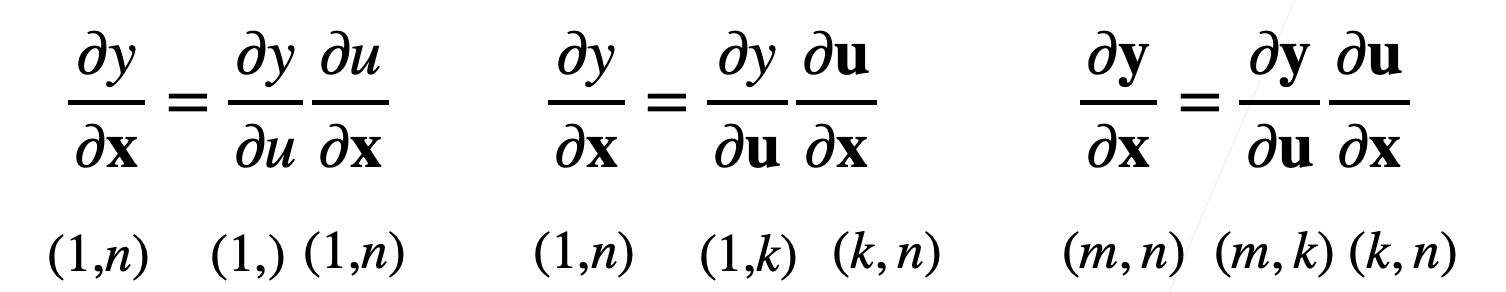
-
链式法则可以用来微分复合函数:

2. 练习
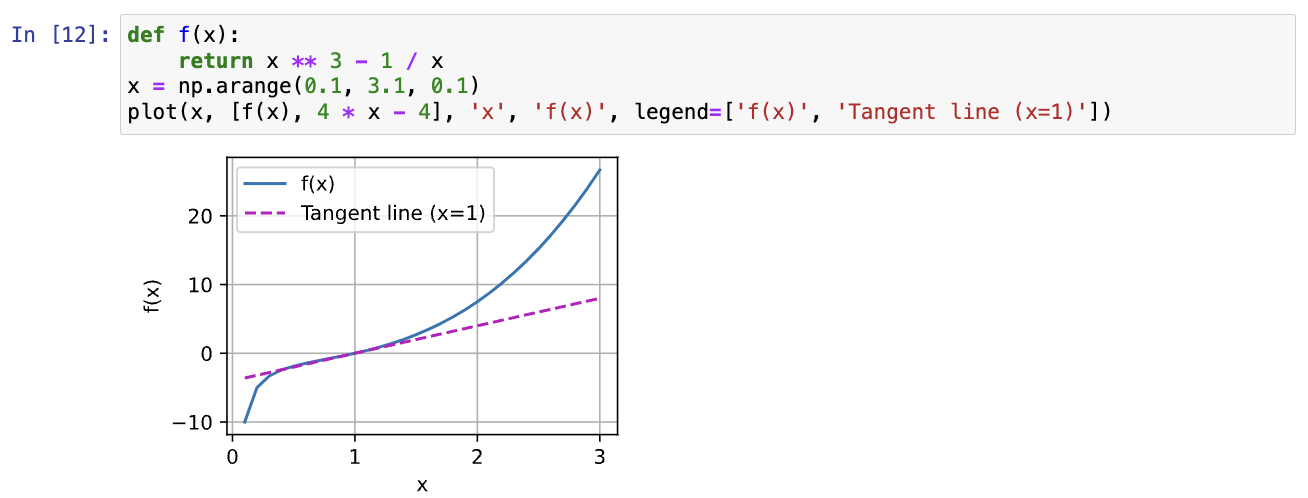
- 绘制函数 y=f(x)=x^3-1/x 和其在 x=1 处切线图像
- 求如下函数梯度
f ( x ) = 3 x 1 2 + 5 e x 2 ∂ f ( x ) ∂ x = ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 = 6 x 1 , 5 e x 2 f(\boldsymbol x)=3x_1^2+5e^{x_2} \\ \frac{\partial f(x)}{\partial \boldsymbol x}= \\frac{\\partial f(x)}{\\partial x_1}, \\frac{\\partial f(x)}{\\partial x_2}=6x_1,5e\^{x_2} f(x)=3x12+5ex2∂x∂f(x)=∂x1∂f(x),∂x2∂f(x)=6x1,5ex2
- 求范数的梯度

- 写出 u=f(x,y,z),其中 x=x(a,b),y=y(a,b),z=z(a,b) 的链式法则。
∂ u ∂ a = ∂ u ∂ x ∂ x ∂ a + ∂ u ∂ y ∂ y ∂ a + ∂ u ∂ z ∂ z ∂ a ∂ u ∂ b = ∂ u ∂ x ∂ x ∂ b + ∂ u ∂ y ∂ y ∂ b + ∂ u ∂ z ∂ z ∂ b \frac{\partial u}{\partial a} = \frac{\partial u}{\partial x}\frac{\partial x}{\partial a}+\frac{\partial u}{\partial y}\frac{\partial y}{\partial a}+\frac{\partial u}{\partial z}\frac{\partial z}{\partial a} \\ \frac{\partial u}{\partial b} = \frac{\partial u}{\partial x}\frac{\partial x}{\partial b}+\frac{\partial u}{\partial y}\frac{\partial y}{\partial b}+\frac{\partial u}{\partial z}\frac{\partial z}{\partial b} ∂a∂u=∂x∂u∂a∂x+∂y∂u∂a∂y+∂z∂u∂a∂z∂b∂u=∂x∂u∂b∂x+∂y∂u∂b∂y+∂z∂u∂b∂z
参考
- 动手学深度学习_上官永石的博客-CSDN博客:https://blog.csdn.net/qq_36793268/category_11249955.html