参数
sklearn.tree.DecisionTreeClassifier 相关参数及说明 ):
类与参数整体
- 类:
sklearn.tree.DecisionTreeClassifier,用于构建决策树分类模型
参数及说明
-
criterion:- 功能:采用基尼系数(
gini)还是熵(entropy)衡量分裂标准,默认基尼系数 - 作用:决定如何评估特征分裂的优劣
- 功能:采用基尼系数(
-
splitter:- 可选值:
best(在所有特征中找最优切分点 )、random(在部分特征中找切分点 ) - 说明:默认
best,数据量大时random可提升效率
- 可选值:
-
max_features:- 含义:寻找最优分裂时考虑的特征数量,默认
None(考虑所有特征 ),也可设log2(取对数 )、sqrt(开平方 )等 - 场景:特征数少(小于 50 )时一般用默认,按需调整控制特征参与分裂的范围
- 含义:寻找最优分裂时考虑的特征数量,默认
-
max_depth:- 含义:树的最大深度,控制树生长的纵向规模
- 说明:数据 / 特征少可忽略,样本和特征多时常限制,避免过拟合,未设置则展开到叶子节点纯或达最小样本数
-
min_samples_split:- 含义:分裂内部节点所需最小样本数,默认 2
- 逻辑:样本数少于此值,节点不再分裂,样本量小可不关注,样本量大(数量级高 )建议留意调整
-
min_samples_leaf:- 含义:叶子节点最少样本数,限制叶子节点规模
- 作用:辅助剪枝,样本数不足则和兄弟节点被剪枝,构建树后剪枝阶段起作用
-
min_weight_fraction_leaf:- 含义:叶子节点最小样本权重和,默认 0(不考虑权重 )
- 场景:样本有缺失值、类别分布偏差大时,引入权重需关注此参数,控制叶子节点权重门槛
-
max_leaf_nodes:- 含义:最大叶子节点数,限制树的横向规模,默认
None(不限制 ) - 效果:设值后算法在该数量内找最优树结构,防止过拟合,如设 10 则节点分裂到 10 个叶子后停止
- 含义:最大叶子节点数,限制树的横向规模,默认
-
min_impurity_decrease:(原文虽未完整展开说明逻辑,但属于参数之一 )- 角色:和决策树生长、不纯度变化关联,影响节点是否分裂
-
min_impurity_split:- 含义:限制决策树增长的不纯度阈值(基尼系数、信息增益等指标 )
- 逻辑:节点不纯度小于此值,不再生成子节点,直接作为叶子节点
-
class_weight:- 功能:指定样本各类别权重
- 作用:防止训练集类别分布不均导致树偏向多数类,可手动设置类别权重平衡影响
这些参数共同控制决策树的结构、生长逻辑、防过拟合策略以及对类别不平衡数据的适配,是使用 sklearn 决策树分类器时调优模型的核心配置项 。
class_weight参数 :使用balanced时,算法自动计算权重,样本量少的类别对应样本权重高,用于平衡类别分布影响,防止决策树偏向多数类random_state参数 :设置决策树分枝随机模式,特征数量多时有明显随机性,作用是确保每次运行代码结果相同,控制随机性以实现可复现性 ,属于sklearn决策树模型中影响权重计算和结果可复现性的关键配置 。

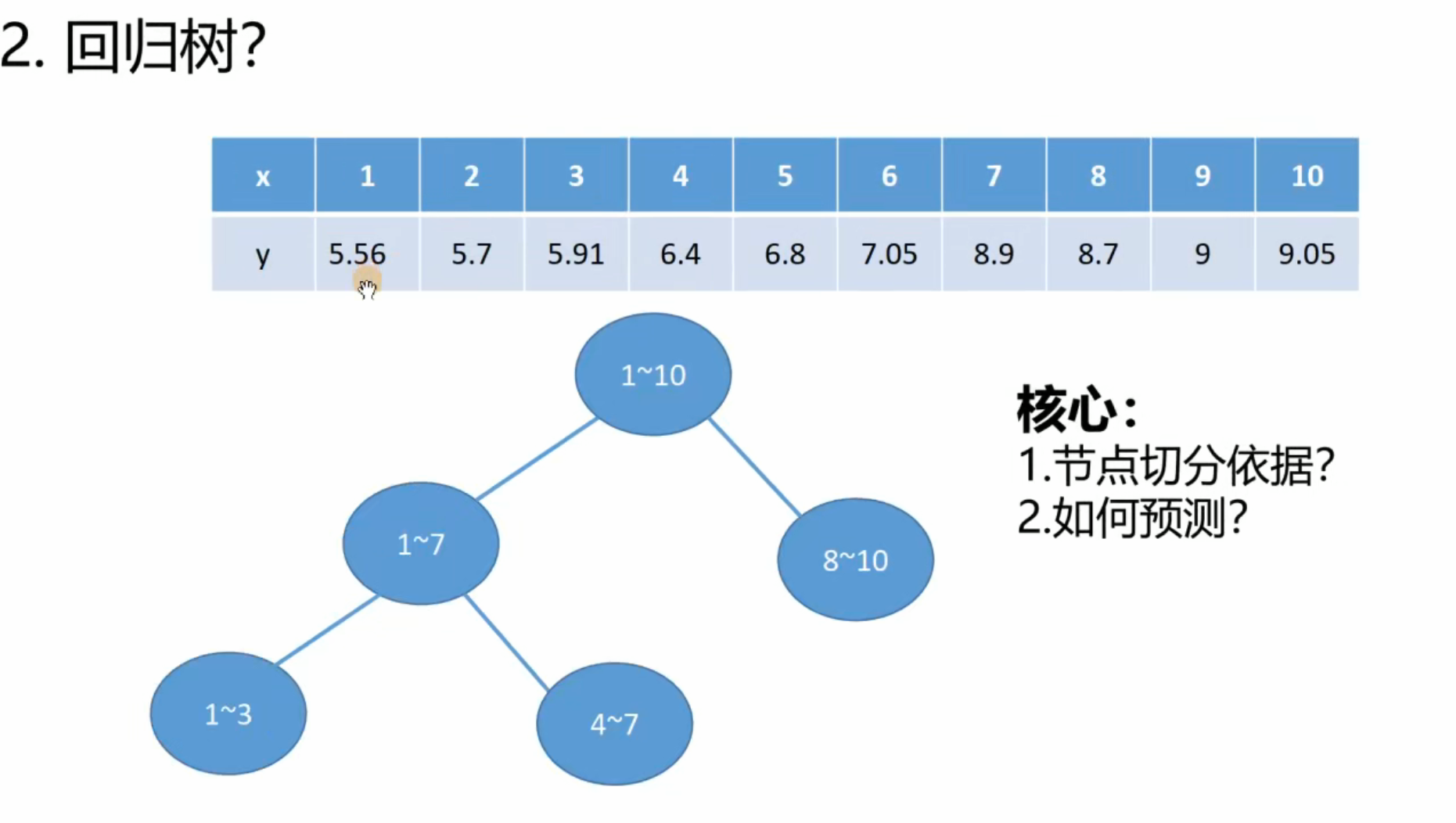
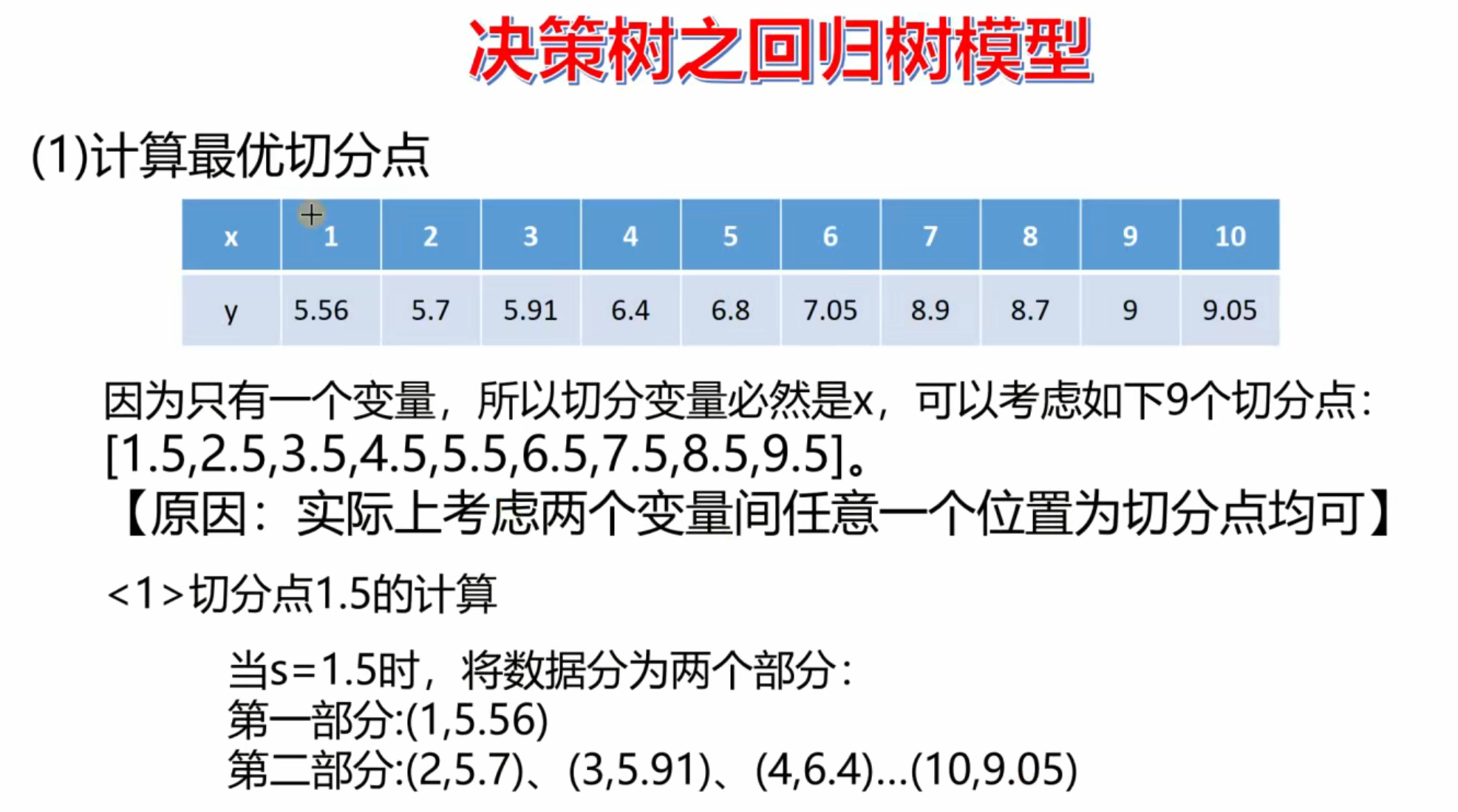

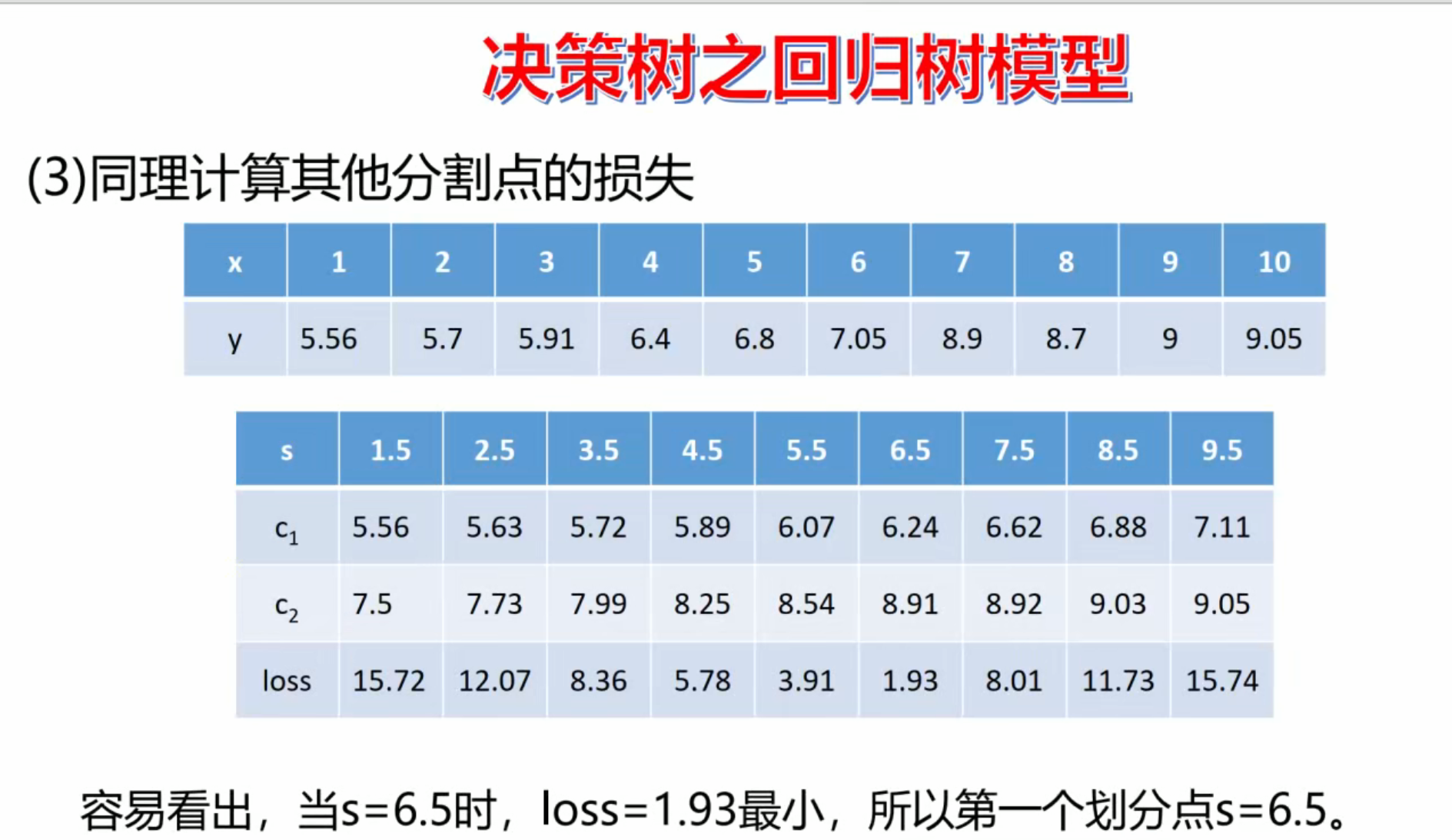
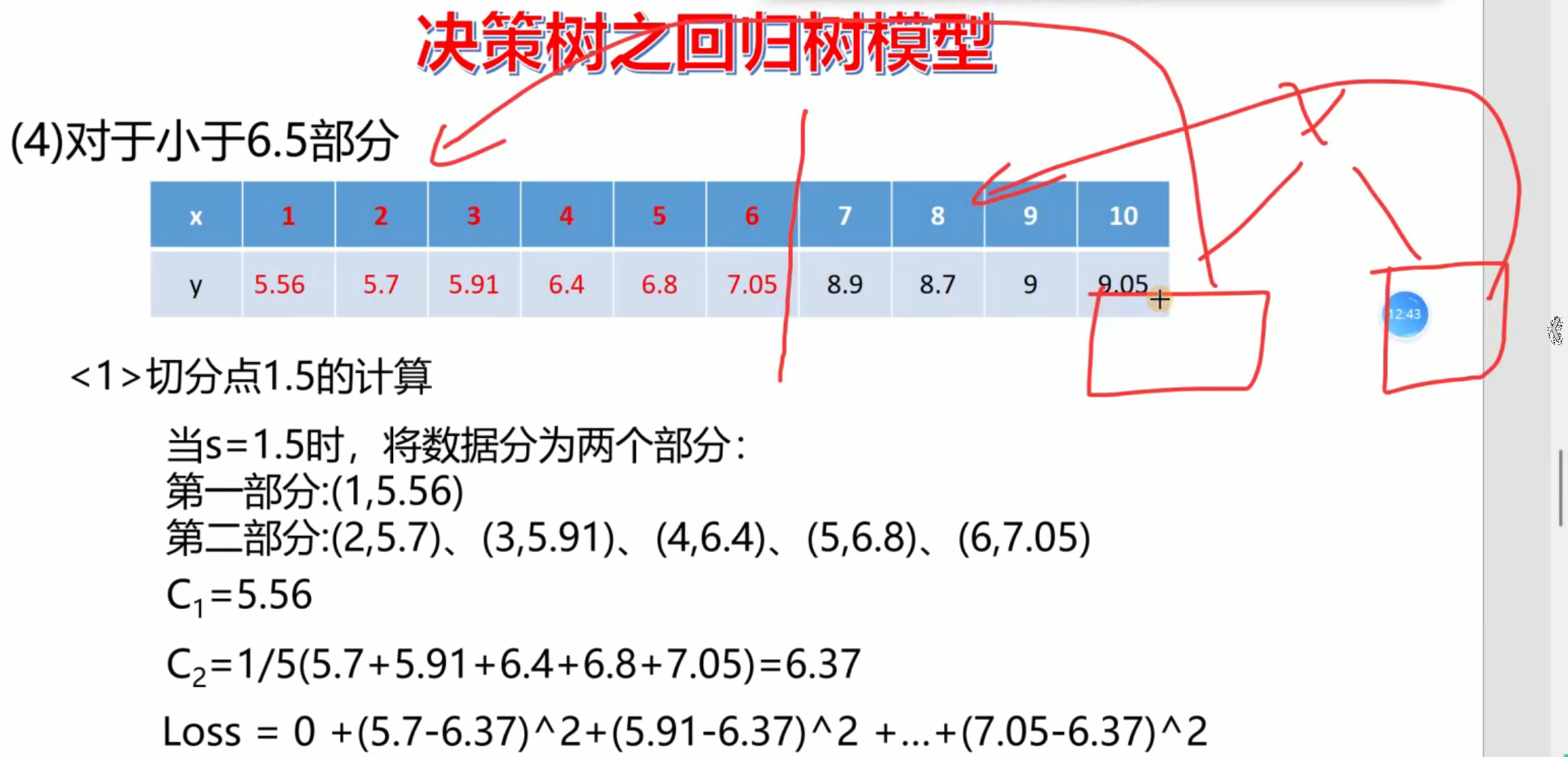

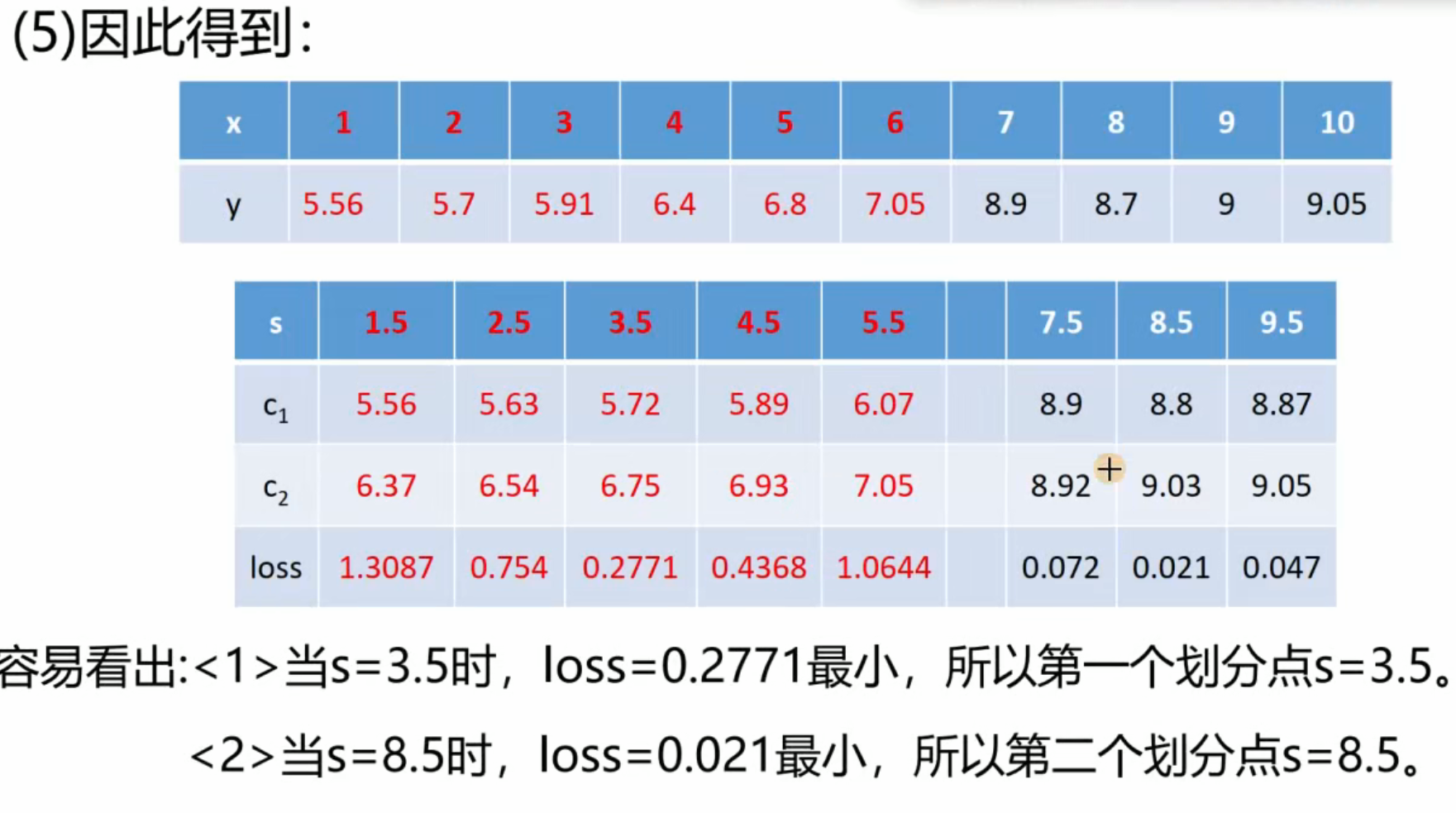

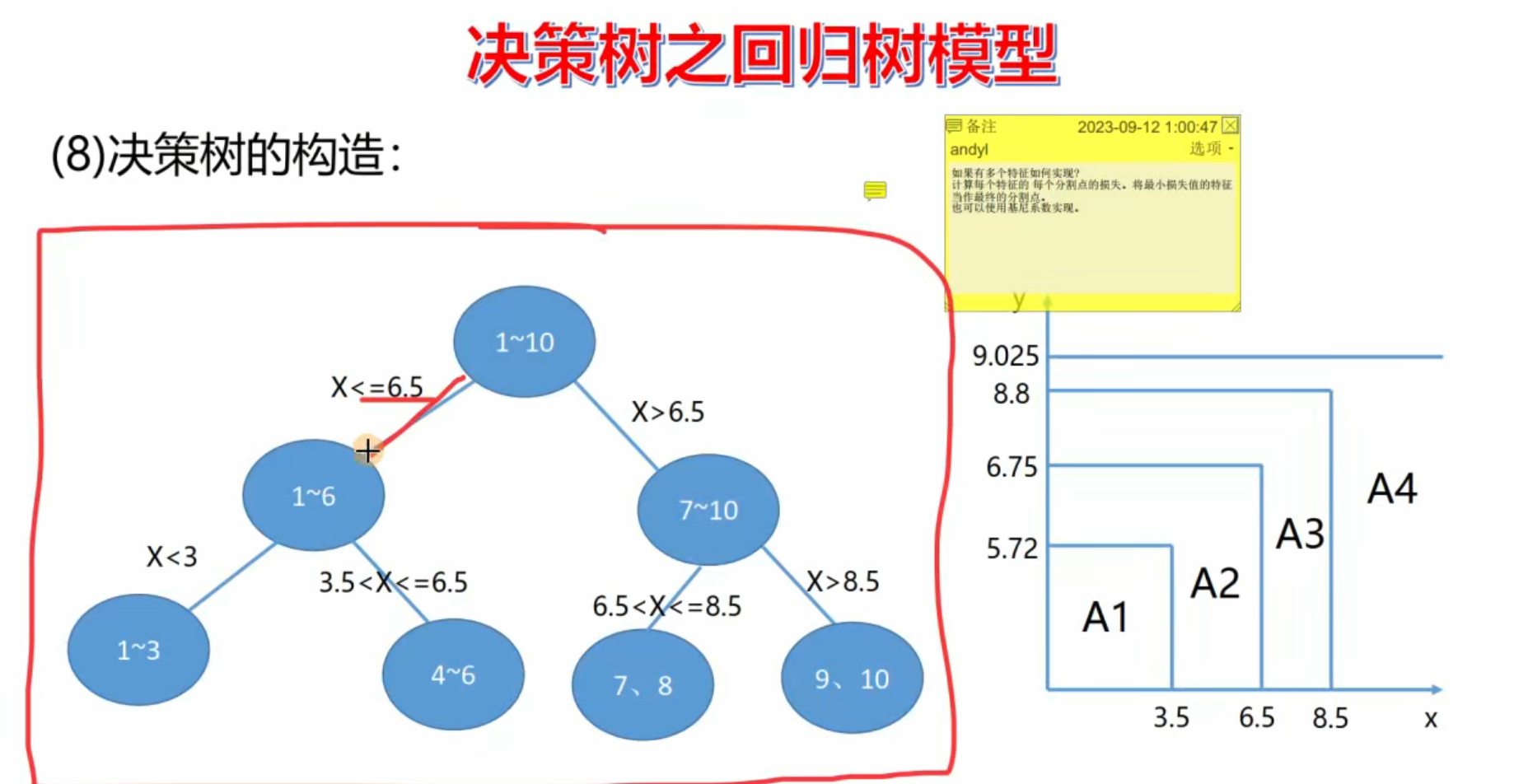

python
import pandas as pd
from sklearn import tree
# 读取数据
data = pd.read_csv("多元回归.csv")
# data = pd.read_csv("多元回归.csv",encoding='gbk')
# 变量与标签的分离
x = data.iloc[:,:-1]
y = data.iloc[:,-1]
# 实例化一个回归树对象
reg = tree.DecisionTreeRegressor()#修改参数试试效果:ma
reg = reg.fit(x,y)
# 预测
y_pr = reg.predict(x)
print(y_pr)
score = reg.score(x,y)#
print(score)