诞生背景
伴随现代信息技术的持续发展,我们能清晰地察觉到,信息生产的规模不断扩张,信息更新的速率持续攀升。以电商系统为例,用户从搜索商品到下单支付,整个链路可能短短几秒就可以完成,倘若能在这条链路里更迅速地分析与挖掘出价值更高的信息,便能取得优势地位。在这种需求推动的宏大背景下,各类批处理、流处理引擎得以快速发展,其中 Apache Flink 更是成为后来居上的佼佼者。
2014年,Flink作为主攻流计算的大数据引擎开始崭露头角,与 Storm、Spark 以及其它流计算引擎相比,它不仅是一个高吞吐、低延迟的的流计算引擎,同时还提供了诸如 有状态计算、状态管理、数据强一致性、丰富的时间语义等高级功能。
Flink是什么
Flink 给自己的定位是大数据流处理引擎。数据处理引擎是指 Flink 可以从数据源读取数据,完成数据的加工处理,再输出到目标数据源。数据源一般是数据存储引擎,比如Flink可以从Kafka读取用户的行为日志,完成数据的处理加工转换,再把处理结果写入到MySQL供业务方使用。
Flink 另一个特点是实时流处理引擎,大数据处理引擎分为两个流派:批处理和流处理。
- 批处理 针对的是有限的数据集,比如数据按照 天、小时 分类,然后批处理程序针对这些有限的数据集进行统一的处理,最后输出有限的处理结果集。主流的批处理以引擎有 Spark。
- 流处理 针对的是实时的、无限的数据流,数据无时无刻、源源不断的产生,数据流处理引擎需要处理这些实时的数据流,并且持续不断地输出处理结果。
Flink 主打的是流处理能力,同时兼具批处理能力,可以把它看作是一个流批一体的数据处理引擎。
数据流
既然是大数据流处理引擎,首先要弄清楚,到底什么是"数据流"?
Flink认为任何数据产生和传输的过程,本质上就是一个数据流。以电商系统为例,用户下单行为必然会导致数据库里生成一条订单交易记录,这条订单记录就是"数据",用户的下单行为是源源不断的,意味着订单数据在源源不断的产生,这些源源不断产生的订单数据就是"数据流"。Flink要做的,就是从数据库里面读取这些订单数据流,然后进行诸如过滤、转换、聚合等计算操作,并输出最终的计算结果。
Flink 将数据流分为两类:有界流和无界流。
- 有界流:数据流有明确的开始和结束标志,比如一张表的所有数据、过去1天的所有订单数据等,有界流的数据量是有限的,数据处理只会持续一段时间。
- 无界流:数据流没有开始和结束标志,数据量是无限的,源源不断产生的,数据处理需要持续进行。
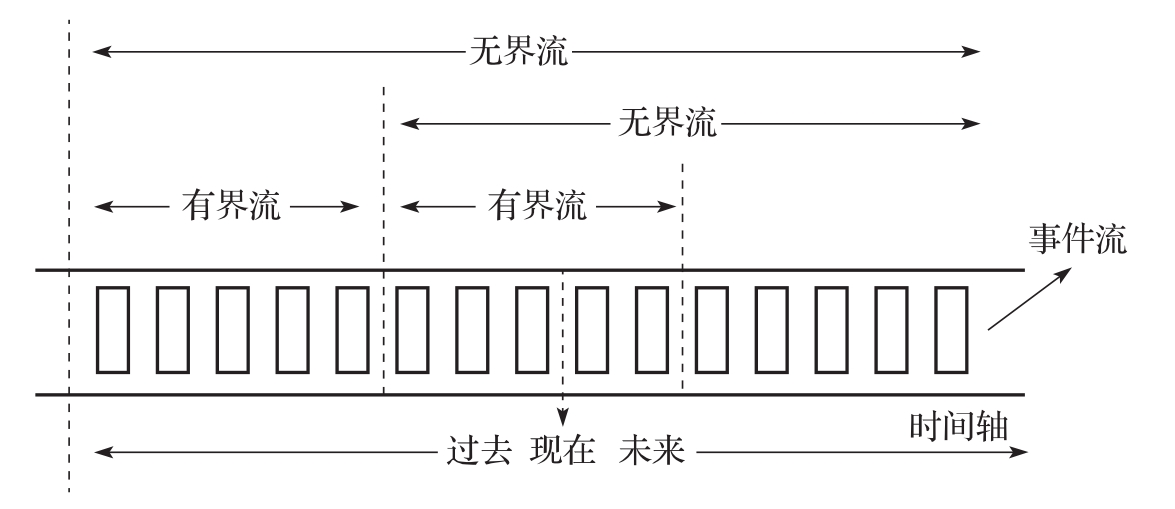
大数据计算引擎,有界流一般对应的是批处理、无界流对应的是流处理。在Flink中,数据流类型和处理方式不是强绑定的,Flink既可以在无界流上做流处理,也可以做批处理。这里的批处理,是指数据按照时间划分为固定大小的窗口,以及对应的窗口计算。Flink也可以在有界流上做流处理,不过意义不大,既然是有界流,批处理的性能会更好一些。
Flink适合做哪些事
系统的技术选型特别重要,针对实战中遇到的问题选择合适的工具往往可以事半功倍,反之一旦选错了工具则会事倍功半,清楚Flink擅长的领域,这点很重要。
Flink官方列举了三种应用场景,分别是:
- 数据同步型应用
- 数据分析型应用
- 事件驱动型应用
数据同步型应用
数据同步型应用的目的是把一个数据源中的数据同步到另一个数据源,典型的案例就是构建离线数仓。
在线业务系统往往需要OLTP数据库的支持,OLTP数据库的特点是高并发低延迟和高吞吐的事务支持,重点是支持ACID特性来确保数据的可靠性和一致性,主要用于处理用户在线实时的请求,请求一般要求在毫秒级完成。
但是对于企业来说,往往还有另一个需求:数据分析,比如分析每个商品的销量,每个用户给公司带来的利润等等,数据分析师需要提供相应的数据报表。此时就需要用到OLAP数据库,OLAP数据库用于处理大量数据的复杂分析查询和报表生成,它对请求处理的时间没有那么严格,允许在秒级甚至分钟级完成,OLAP数据库往往不直接对外提供服务。
在这个场景下,一份数据需要接入两个数据库,业务系统不可能写两次啊,怎么办呢?这时候,企业就可以利用Flink将OLTP数据库里的数据实时同步到OLAP离线数仓,业务系统不需要做任何改动。
数据分析型应用
Flink除了可以把OLTP数据库里的数据同步到OLAP数据库供复杂的数据分析外,Flink自身也可以直接用于数据分析。
数据分析型应用,一般做法是通过接入原始数据源,对原始数据进行数据清洗、过滤、聚合,最后提取出有价值的信息或指标。
离线分析一般是利用批处理,周期性的处理并产生结果,但是会带来一定的延迟。随着企业对数据实时性的要求越来越高,运营人员希望能够获取实时的数据,从而做出更优的决策,实时数据分析应用应运而生。Flink支持有状态的计算,计算的中间结果维护在Flink内部的状态中,并支持按照一定的策略周期性的输出到三方数据源。
事件驱动型应用
事件驱动型应用是一类有状态的应用,通过从一个或多个数据源中读取事件数据,然后触发事件对应的动作,把整个流程给串起来。
事件驱动型应用可以看作是传统事务型应用的升级版。以外卖系统为例,传统事务型应用的做法是,用户下单后系统会往商家服务数据库写入一条接单数据,商家接单后开始备餐,同时系统再往骑手服务写入一条送单数据,商家服务和骑手服务通过访问各自的数据库来串起整个流程。
再来看看事件驱动型应用的做法,用户下单后直接往消息队列中发一条下单事件,Flink读取到下单事件后把相关的订单信息直接写入到本地存储,同时生成一条商家接单提醒事件;商家接单后直接向消息队列发一条已接单事件,Flink读取到该事件后修改本地订单状态,同时生成一条骑手送单提醒事件;骑手接单以后再向消息队列发一条骑手已接单事件,Flink读取到该事件后修改本地订单状态,进行后续的流程处理。
事件驱动型应用的特点是,数据处理的过程是由一个个事件触发的,再加上Flink直接将状态数据保存在本地,拥有极高的读写性能,所以这类应用通常具备高吞吐和低延迟的特点。
Flink核心特性
Flink作为大数据流处理引擎,它具备的五个核心特性奠定了它在流处理中的地位。
- 流处理引擎:不同于批处理,Flink是真正的流处理引擎,它处理数据的粒度是数据粒度,来一条数据就处理一条,因此延迟极低,一般是毫秒级延迟,如果业务对数据处理延迟非常敏感,那么Flink就是不二之选。
- 高性能分布式计算引擎:Flink是分布式的计算引擎,数据处理的吞吐能力能轻松达到百万、千万级QPS。通过升级硬件资源或扩容等操作,可以快速提升Flink处理数据的吞吐量。
- 丰富的时间语义:相较于其它流处理引擎,Flink提供了丰富的时间语义,包括:事件时间、摄入事件、处理时间,基于这些时间语义可以实现窗口计算。
- 高可用的有状态计算引擎:Flink提供了丰富的状态类型和简单易用的操作API,同时还内置了Checkpoint,Savepoint快照机制来保证状态数据的强一致性,实现数据的精准一次处理。即使服务宕机,作业异常,也无须担心数据丢失或重复处理。另外,Flink支持TB级别的状态数据存储能力。
- 流批一体的计算引擎:Flink同时支持流处理和批处理,开发者甚至可以通过一条SQL就可以同时完成流处理和批处理计算,显著降低开发成本。
尾巴
Flink作为新一代大数据流处理引擎,在企业中承担了 实时数仓、智能风控、系统监控、机器学习等重要职责。Flink是一个支持流批一体、具备丰富的时间语义、高性能低延时并且具备数据精准一次处理的流计算引擎,此外Flink还支持TB级别的状态数据存储能力,面对海量数据,Flink毫不畏惧。