Apache Flink 是一个分布式流处理引擎,它提供了丰富且易用的API来处理有状态的流处理应用,并且在支持容错的前提下,高效、大规模的运行此类应用。通过支持事件时间(event-time)、计算状态(state)以及恰好一次(exactly-once)的容错保证,Flink迅速被很多公司采纳,成为了新一代的流计算处理引擎。
2020 年 2 月 11 日,社区发布了 Flink 1.10.0 版本,该版本对性能和稳定性做了很大的提升,同时引入了 native Kubernetes 的特性。对于 Flink 的下一个稳定版本,社区在 2020 年 4 月底冻结新特性的合入,预计在 2020 年 5 月中旬会推出 Flink 1.11,在新版本中将重点引入新特性,以扩容 Flink 的使用场景。
一、Flink运行模式
一)Flink运行模式 on 虚拟机
1、开发者模式
在idea中运行flink程序的方式
2、local-cluster模式
flink中的local-cluster(本地集群)模式,单节点运行,主要用于测试、学习。
3、Standalone模式
独立集群模式,由flink自身提供计算资源
4、Yarn模式
把flink应用提交给Yarnde ResourceManager
Flink会根据运行在JobManger的job的需要的slot的数量动态的分配TaskManger资源
yarn-cluster提交流程
- 0.Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
- 1.向Yarn ResourceManager提交任务,ResourceManager分配Container资源
- 2.通知对应的NodeManager启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager(Dispatcher)
- 2.1.Dispatcher启动JobMaster
- 3.JobMaster向ResourceManager(Flink)申请资源
- 4.ResourceManager(Flink)向ResourceManager(Yarn)申请资源启动TaskManager
- 5.ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
- 6.TaskManager注册Slot
- 7.发出提供Slot命令
- 8.TaskManager向JobMaster提供Slot
- 9.JobMaster提交要在Slot中执行的任务
Yarn又分为三种模式
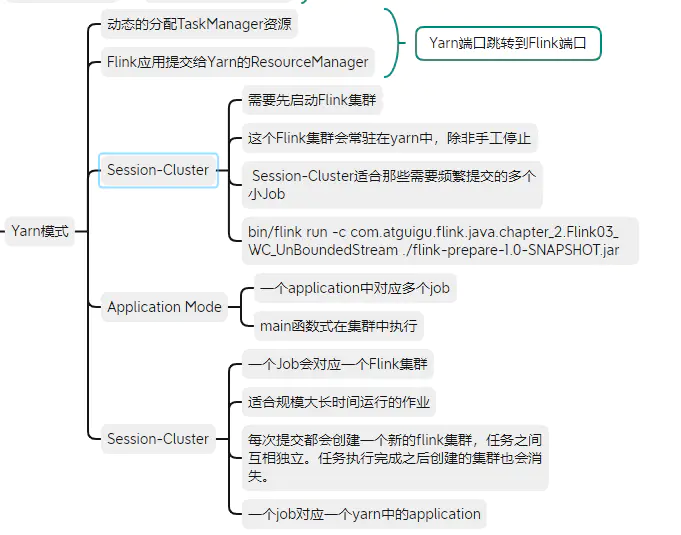
4.1 Session-Cluster

Session-Cluster模式需要先启动Flink集群,向Yarn申请资源,以后提交任务都向这里提交。
这个Flink集群会常驻在Yarn集群中,除非手动停止。
在向Flink集群提交job的时候,若Yarn资源被用完了,则新的job不能正常提交。
缺点:若提交的任务中有长时间执行的大作业,占用了该flink集群的所有资源,则后续无法提交新的job。
**应用场景:**Session-Cluster适合那些需要频繁提交的多个小job,并且执行时间不长的job。
4.2 Per-Job-Cluster

一个job对应一个flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,指导作业执行完成。一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManger,按需接受资源申请。
应用场景:适合规模大、长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建也会消失。
per-job模式执行结果,一个job对应一个application。

4.3 Application Mode
application mode会在yarn上启动集群,应用jar包的main函数(用户类的main函数)将会在JobManager上执行。只要应用程序执行结束,flink集群会马上被关闭,也可以手动停止集群。
与Per-Job-Cluster的区别:
- application mode下,用户的main函数在集群中执行的,并且当一个application中有多个job的话,application mode则这个application中对应多个job
- 并且当一个application中有多个job的话,per-job模式则是一个job对应一个yarn中的application

** 官方建议:** 出于生产的需求, 我们建议使用Per-job or Application Mode,因为他们给应用提供了更好的隔离!
二)fink on kubernetes
1、flink为什么选择kubernetes?
kubernetes项目源自Google内部Borg项目,基于Borg多年来优秀实践和其超前的设计理念,并凭借众多豪门、大厂的背书,时至今日,kubernetes已经成长为容器管理领域的事实标准。
在大数据及相关领域,包括Spark、Hive、Airflow、Kafka等众多知名产品正在迁往kubernetes,Apache Flink也是其中一员。
flink选择kubernetes作为其底层资源管理平台,原因包括两个方面:
- flink特性:流式服务一般是常驻进程,经常用于电信质量监控、商业数据即席分析(在解决特定问题的特定分析)、实时风控和实时推荐等对稳定性要求比较高的场景。
- kubernetes优势:为在线业务提供了更好的发布、管理机制,并保证其稳定运行,同时kubernetes具有很好的生态优势,能很方便地和各种工具集成,如Prometheus监控,主流的日志采集工具等;同时kubernetes在资源弹性方面提供了很好的扩缩容机制,很大程度上提高了资源利用率。
- 容器环境,易于部署、清理、重建
- 多租户,更好的隔离性与安全性
- 混合部署,在线服务、机器学习、搜索引擎混部在一起,有更好的集群利用率。
- 丰富的k8s生态,日志、监控等
2、flink on kubernetes的发展史
- 在 Flink 的早期发行版 1.2 中,已经引入了 Flink Session 集群模式,用户得以将 Flink 集群部署在 Kubernetes 集群之上。
- 随着 Flink 的逐渐普及,越来越多的 Flink 任务被提交在用户的集群中,用户发现在 session 模式下,任务之间会互相影响,隔离性比较差,因此在 Flink 1.6 版本中,推出了 Per Job 模式,单个任务独占一个 Flink 集群,很大的程度上提高了任务的稳定性。
- 在满足了稳定性之后,用户觉得这两种模式,没有做到资源按需创建,往往需要凭用户经验来事先指定 Flink 集群的规格,在这样的背景之下,native session 模式应用而生,在 Flink 1.10 版本进入 Beta 阶段,我们增加了 native per job 模式,在资源按需申请的基础上,提高了应用之间的隔离性。
- 本文根据 Flink 在 Kubernetes 集群上的运行模式的趋势,依次分析了这些模式的特点,并在最后介绍了 Flink operator 方案及其优势。
3、Flink运行模式
分析了Apache Flink1.10在kubernetes集群已经GA(生产可用)的两种部署方式,然后分析了处于Beta版本native session部署模式和即将在flink1.11发布的native per-job部署模式,最后根据这些部署模式的利弊,目前比较流行的native kubernetes的部署方式:flink-operator。
正在使用的flink版本已经很好的支持了native session和native per-job两种模式,在flink operator中,也对这两种模式做了支持。
- Flink session 模式
- Flink per-job 模式
- Flink native session 模式
- Flink native per-job 模式
这四种部署模式的优缺点对比,可以用如下表格来概括,更多的内容,请参考接下来的详细描述。

1)Session Cluster 模式
原理简介
Session 模式下,Flink 集群处于长期运行状态,当集群的Master组件接收到客户端提交的任务后,对任务进行分析并处理。用户将Flink集群的资源描述文件提交到 Kubernetes 之后,Flink 集群的 FlinkMaster 和 TaskManager 会被创建出来,如下图所示,TaskManager 启动后会向 ResourceManager 模块注册,这时 Flink Session 集群已经准备就绪。当用户通过 Flink Clint 端提交了 Job 任务时,Dispatcher 收到该任务请求,将请求转发给 JobMaster,由 JobMaster 将任务分配给具体的 TaskManager。
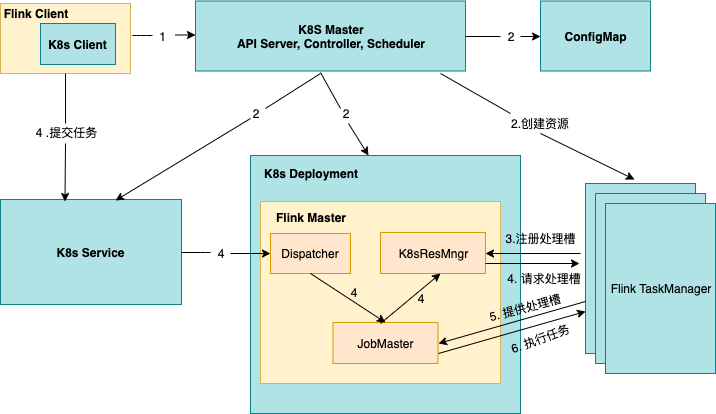
特点分析
这种类型的 Flink 集群,FlinkMaster 和 TaskManager 是以Kubernetes deployment的形式长期运行在 Kubernetes 集群中。在提交作业之前,必须先创建好 Flink session 集群。多个任务可以同时运行在同一个集群内,任务之间共享 K8sResourceManager 和Dispatcher,但是 JobMaster 是单独的。这种方式比较适合运行短时作业、即席查询、任务提交频繁、或者对任务启动时长比较敏感的场景。
- 优点:作业提交的时候,FlinkMaster 和 TaskManager已经准备好了,当资源充足时,作业能够立即被分配到 TaskManager 执行,无需等待 FlinkMaster,TaskManager,Service 等资源的创建。
- 缺点:
- 需要在提交 Job 任务之前先创建 Flink 集群,需要提前指定 TaskManager 的数量,但是在提交任务前,是难以精准把握具体资源需求的,指定的多了,会有大量 TaskManager 处于闲置状态,资源利用率就比较低,指定的少了,则会有任务分配不到资源,只能等集群中其他作业执行完成后,释放了资源,下一个作业才会被正常执行。
- 隔离性比较差,多个 Job 任务之间存在资源竞争,互相影响;如果一个 Job 异常导致 TaskManager crash 了,那么所有运行在这个 TaskManager 上的 Job 任务都会被重启;进而,更坏的情况是,多个 Jobs 任务的重启,大量并发的访问文件系统,会导致其他服务的不可用;最后一点是,在 Rest interface 上是可以看到同一个 session 集群里其他人的 Job 任务。
2)Per Job Cluster 模式
顾名思义,这种方式会专门为每个 Job 任务创建一个单独的 Flink 集群,当资源描述文件被提交到 Kubernetes 集群,Kubernetes 会依次创建 FlinkMaster Deployment、TaskManagerDeployment 并运行任务,任务完成后,这些 Deployment 会被自动清理。
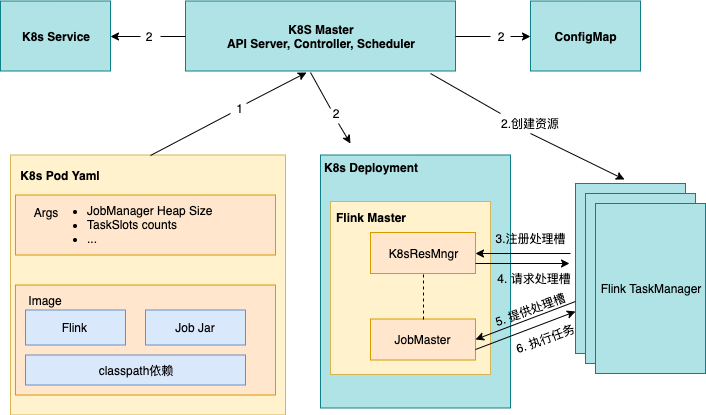
特点分析
- 优点:隔离性比较好,任务之间资源不冲突,一个任务单独使用一个 Flink 集群;相对于 Flink session 集群而且,资源随用随建,任务执行完成后立刻销毁资源,资源利用率会高一些。
- 缺点:需要提前指定 TaskManager 的数量,如果 TaskManager 指定的少了会导致作业运行失败,指定的多了仍会降低资源利用率;资源是实时创建的,用户的作业在被运行前,需要先等待以下过程:
- Kubernetes scheduler为FlinkMaster和 TaskManager 申请资源并调度到宿主机上进行创建;
- Kubernetes kubelet拉取FlinkMaster、TaskManager 镜像,并创建出FlinkMaster、TaskManager容器;
- TaskManager启动后,向Flink ResourceManager 注册。
这种模式比较适合对启动时间不敏感、且长时间运行的作业。不适合对任务启动时间比较敏感的场景。
3)Native Session Cluster 模式
原理分析
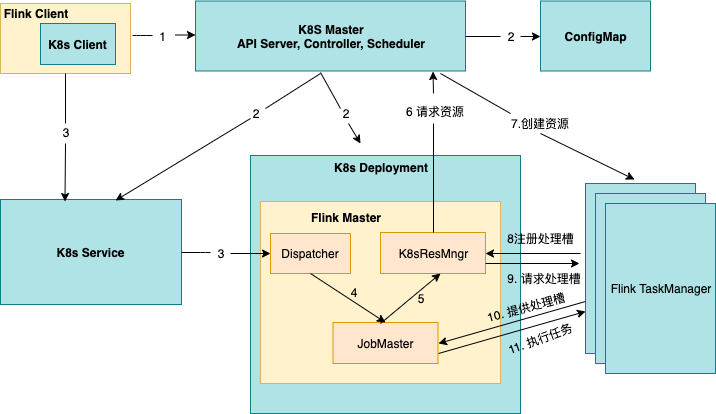
- Flink提供了 Kubernetes 模式的入口脚本 kubernetes-session.sh,当用户执行了该脚本之后,Flink 客户端会生成 Kubernets 资源描述文件,包括 FlinkMaster Service,FlinkMasterDeloyment,Configmap,Service并设置了owner reference,在 Flink 1.10 版本中,是将 FlinkMaster Service 作为其他资源的 Owner,也就意味着在删除 Flink 集群的时候,只需要删除 FlinkMaster service,其他资源则会被以及联的方式自动删除;
- Kubernetes 收到来自 Flink 的资源描述请求后,开始创建FlinkMaster Service,FlinkMaster Deloyment,以及 Configmap 资源,从图中可以看到,伴随着 FlinkMaster 的创建,Dispatch 和 K8sResMngr 组件也同时被创建了,这里的 K8sResMngr 就是 Native 方式的核心组件,正是这个组件去和 Kubernetes API server 进行通信,申请 TaskManager 资源;当前,用户已经可以向 Flink 集群提交任务请求了;
- 用户通过 Flink client 向 Flink 集群提交任务,flink client 会生成 Job graph,然后和 jar 包一起上传;当任务提交成功后,JobSubmitHandler 收到了请求并提交给 Dispatcher并生成 JobMaster,JobMaster 用于向 KubernetesResourceManager 申请 task 资源;
- Kubernetes-Resource-Manager 会为 taskmanager 生成一个新的配置文件,包含了 service 的地址,这样当 Flink Master 异常重建后,能保证 taskmanager 通过 Service 仍然能连接到新的 Flink Master;
- TaskManager 创建成功后注册到 slotManager,这时 slotManager向TaskManager 申请 slots,TaskManager 提供自己的空闲 slots,任务被部署并运行。
** 特点分析**
之前我们提到的两种部署模式,在 Kubernetes 上运行 Flink 任务是需要事先指定好 TaskManager 的数量,但是大部分情况下,用户在任务启动前是无法准确的预知该任务所需的 TaskManager 数量和规格。
指定的多了会资源浪费,指定的少了会导致任务的执行失败。最根本的原因,就是没有 Native 的使用 Kubernetes 资源,这里的 Native,可以理解为 Flink 直接与 Kuberneter 通信来申请资源。
这种类型的集群,也是在提交任务之前就创建好了,不过只包含了 FlinkMaster 及其 Entrypoint(Service),当任务提交的时候,Flink client 会根据任务计算出并行度,进而确定出所需 TaskManager 的数量,然后 Flink 内核会直接向 Kubernetes API server 申请 taskmanager,达到资源动态创建的目的。
- 优点:相对于前两种集群而言,taskManager 的资源是实时的、按需进行的创建,对资源的利用率更高,所需资源更精准。
- 缺点:taskManager 是实时创建的,用户的作业真正运行前,与 Per Job集群一样,仍需要先等待 taskManager 的创建,因此对任务启动时间比较敏感的用户,需要进行一定的权衡。
4)Native Per Job 模式

当任务被提交后,同样由 Flink 来向 Kubernetes 申请资源,其过程与之前提到的 native session 模式相似,不同之处在于:
- Flink Master是随着任务的提交而动态创建的;
- 用户可以将 Flink、作业 Jar 包和 classpath 依赖打包到自己的镜像里;
- 作业运行图由 Flink Master 生成,所以无需通过 RestClient 上传 Jar 包(图 2 步骤 3)。
** 特点分析**
native per-job cluster 也是任务提交的时候才创建 Flink 集群,不同的是,无需用户指定 TaskManager 资源的数量,因为同样借助了 Native 的特性,Flink 直接与 Kubernetes 进行通信并按需申请资源。
- 优点:资源按需申请,适合一次性任务,任务执行后立即释放资源,保证了资源的利用率。
- 缺点:资源是在任务提交后开始创建,同样意味着对于提交任务后对延时比较敏感的场景,需要一定的权衡;。
5)Flink-operator
简介
分析以上四种部署模式,我们发现,对于 Flink 集群的使用,往往需要用户自行维护部署脚本,向 Kubernetes 提交各种所需的底层资源描述文件(Flink Master,TaskManager,配置文件,Service)。
在 session cluster 下,如果集群不再使用,还需要用户自行删除这些的资源,因为这类集群的资源使用了 Kubernetes 的垃圾回收机制 owner reference,在删除 Flink 集群的时候,需要通过删除资源的 Owner 来进行及联删除,这对于不熟悉 Kubernetes 的 Flink 用户
说,就显得不是很友好了。
通过 Flink-operator,我们可以把 Flink 集群描述成 yaml 文件,这样,借助 Kubernetes 的声明式特性和协调控制器,我们可以直接管理 Flink 集群及其作业,而无需关注底层资源如 Deployment,Service,ConfigMap 的创建及维护。
Flink-operator 原理及优势
当 Fink operator 部署至 Kubernetes 集群后, FlinkCluster 资源和 Flink Controller 被创建。其中 FlinkCluster 用于描述 Flink 集群,如 JobMaster 规格、TaskManager 和 TaskSlot 数量等;Flink Controller 实时处理针对 FlinkCluster 资源的 CRUD 操作,用户可以像
理内置 Kubernetes 资源一样管理 Flink 集群。
例如,用户通过 yaml 文件描述期望的 Flink 集群并向 Kubernetes 提交,Flink controller 分析用户的 yaml,得到 FlinkCluster CR,然后调用 API server 创建底层资源,如JobMaster Service,JobMaster Deployment,TaskManager Deployment。
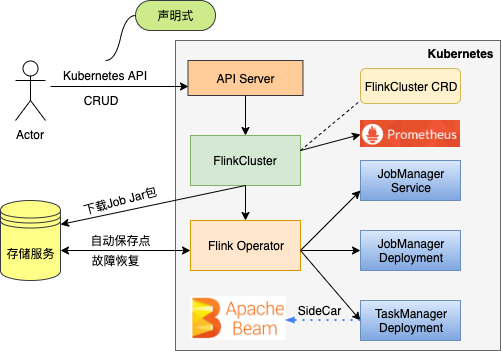
通过使用 Flink Operator,有如下优势:
- 管理 Flink 集群更加便捷
flink-operator 更便于我们管理 Flink 集群,我们不需要针对不同的 Flink 集群维护 Kubenretes 底层各种资源的部署脚本,唯一需要的,就是 FlinkCluster 的一个自定义资源的描述文件。创建一个 Flink session 集群,只需要一条 kubectl apply 命令即可,下图是 Flink Session集群的 yaml 文件,用户只需要在该文件中声明期望的 Flink 集群配置,flink-operator 会自动完成 Flink 集群的创建和维护工作。如果创建 Per Job 集群,也只需要在该 yaml 中声明 Job 的属性,如 Job 名称,Jar 包路径即可。通过 flink-operator,上文提到的四种 Flink 运行模式,分别对应一个 yaml 文件即可,非常方便。
apiVersion: flinkoperator.k8s.io/v1beta1
kind: FlinkCluster
metadata:
name: flinksessioncluster-sample
spec:
image:
name: flink:1.10.0
pullPolicy: IfNotPresent
jobManager:
accessScope: Cluster
ports:
ui: 8081
resources:
limits:
memory: "1024Mi"
cpu: "200m"
taskManager:
replicas: 1
resources:
limits:
memory: "2024Mi"
cpu: "200m"
volumes:
- name: cache-volume
emptyDir: {}
volumeMounts:
- mountPath: /cache
name: cache-volume
envVars:
- name: FOO
value: bar
flinkProperties:
taskmanager.numberOfTaskSlots: "1"- 声明式:通过执行脚本命令式的创建 Flink 集群各个底层资源,需要用户保证资源是否依次创建成功,往往伴随着辅助的检查脚本。借助 flink operator 的控制器模式,用户只需声明所期望的 Flink 集群的状态,剩下的工作全部由 Flink operator 来保证。在 Flink 集群运行的过程中,如果出现资源异常,如 JobMaster 意外停止甚至被删除,Flink operator 都会重建这些资源,自动的修复 Flink 集群。
- 自定义保存点:用户可以指定 autoSavePointSeconds 和保存路径,Flink operator 会自动为用户定期保存快照。
- 自动恢复:流式任务往往是长期运行的,甚至 2-3 年不停止都是常见的。在任务执行的过程中,可能会有各种各样的原因导致任务失败。用户可以指定任务重启策略,当指定为 FromSavePointOnFailure,Flink operator 自动从最近的保存点重新执行任务。
- sidecar containers:sidecar 容器也是 Kubernetes 提供的一种设计模式,用户可以在 TaskManager Pod 里运行 sidecar 容器,为 Job 提供辅助的自定义服务或者代理服务。
- Ingress 集成:用户可以定义 Ingress 资源,flink operator 将会自动创建 Ingress 资源。云厂商托管的 Kubernetes 集群一般都有 Ingress 控制器,否则需要用户自行实现 Ingress controller。
- Prometheus 集成:通过在 Flink 集群的 yaml 文件里指定 metric exporter 和 metric port,可以与 Kubernetes 集群中的 Prometheus 进行集成。