小罗碎碎念
今天的四篇文章跨度很大,从18年跨到24年。
第一篇文章主要研究的是通过病理预测基因突变,要注意这篇文章发表的时间是2018年!!所以我们在看到这篇文章的简介时,会看到他们用的模型现在基本都没听人提到了。
第二篇文章是一篇关于鼻咽癌病理的研究,但是通篇看下来,没有一张病理切片的配图。但是考虑到这篇文章是2019年发表在Cancer Medicine(IF=2.9,二区)的,我好像又理解了。
第三篇和第四篇文章,都是最近发表的文章,所以我们能看到文章研究内容也比较新颖------AI辅助预筛选。具体来讲,可以筛选对于靶向治疗敏感或者免疫检查点抑制剂治疗敏感的患者,这可以一定程度上加速临床试验。
一、人工智能辅助病理诊断:肺癌类型区分与基因突变预测

一作&通讯
| 作者角色 | 作者姓名 | 单位名称 | 单位翻译 |
|---|---|---|---|
| 第一作者 | Nicolas Coudray | Applied Bioinformatics Laboratories, New York University School of Medicine | 应用生物信息学实验室,纽约大学医学院 |
| 第一作者 | Paolo Santiago Ocampo | Skirball Institute, Department of Cell Biology, New York University School of Medicine | 斯科尔研究所,细胞生物学系,纽约大学医学院 |
| 通讯作者 | Narges Razavian | Department of Population Health and the Center for Healthcare Innovation and Delivery Science, New York University School of Medicine | 人口健康系和医疗创新与交付科学中心,纽约大学医学院 |
| 通讯作者 | Aristotelis Tsirigos | Department of Pathology, New York University School of Medicine | 病理学系,纽约大学医学院 |
文献概述
这篇文章是关于使用深度学习技术来分析非小细胞肺癌(NSCLC)的组织病理学图像,以预测肺癌的类型和突变情况的研究。
-
背景 :肺癌是全球广泛传播的癌症之一,其中肺腺癌(LUAD)和肺鳞癌(LUSC)是非小细胞肺癌的两种最常见类型。这两种类型的肺癌需要不同的治疗指南,但在没有明确的组织学特征的情况下,区分它们可能具有挑战性,并且需要确认性的免疫组化染色。
-
研究目的:开发一种基于深度学习的模型,自动分析肿瘤切片图像,以准确分类LUAD、LUSC或正常肺组织。此外,研究者还训练了网络来预测LUAD中最常见的十种突变基因。
-
方法:研究者使用了来自癌症基因组图谱(TCGA)的全切片图像,这些图像通过手术切除后冷冻切片制备的。他们采用了Inception v3架构的深度卷积神经网络(CNN),并使用512×512像素的瓷砖块进行训练、验证和测试。
-
结果 :深度学习模型的表现与病理学家相当,平均AUC(曲线下面积)为0.97。该模型在独立的数据集上进行了验证,包括冷冻组织、甲醛固定石蜡包埋组织和活检样本。此外,研究者还发现,可以通过病理图像预测六个常见突变基因(STK11、EGFR、FAT1、SETBP1、KRAS和TP53),AUC值在0.733到0.856之间。
-
讨论:研究表明,卷积神经网络可以协助病理学家从组织病理学切片中诊断肺癌,并且能够以高精度区分肺癌类型。此外,该模型还能够从图像数据中预测某些基因的突变状态,这对于肺癌治疗尤为重要,因为这些突变通常具有预后和预测信息。
-
结论:深度学习模型可以作为病理学家在肺癌分类和基因突变预测方面的有力工具,有助于为肺癌患者提供更精确的治疗方案。
文章还提到了研究的局限性,包括训练数据可能无法完全代表病理学家通常检查的组织的多样性和异质性,以及对于某些类型的肺癌(如大细胞癌和小细胞肺癌)和LUAD的组织学亚型(如腺泡型、鳞状细胞型、乳头状、微乳头状和实性)的分类能力有待提高。
研究者希望将来能够扩展算法,以识别更广泛的组织学特征,并提供定量和空间评估,以协助病理学家进行更适合自动化分析的评估。
简要分析
图1展示了用于训练深度学习模型的数据和策略的概览。
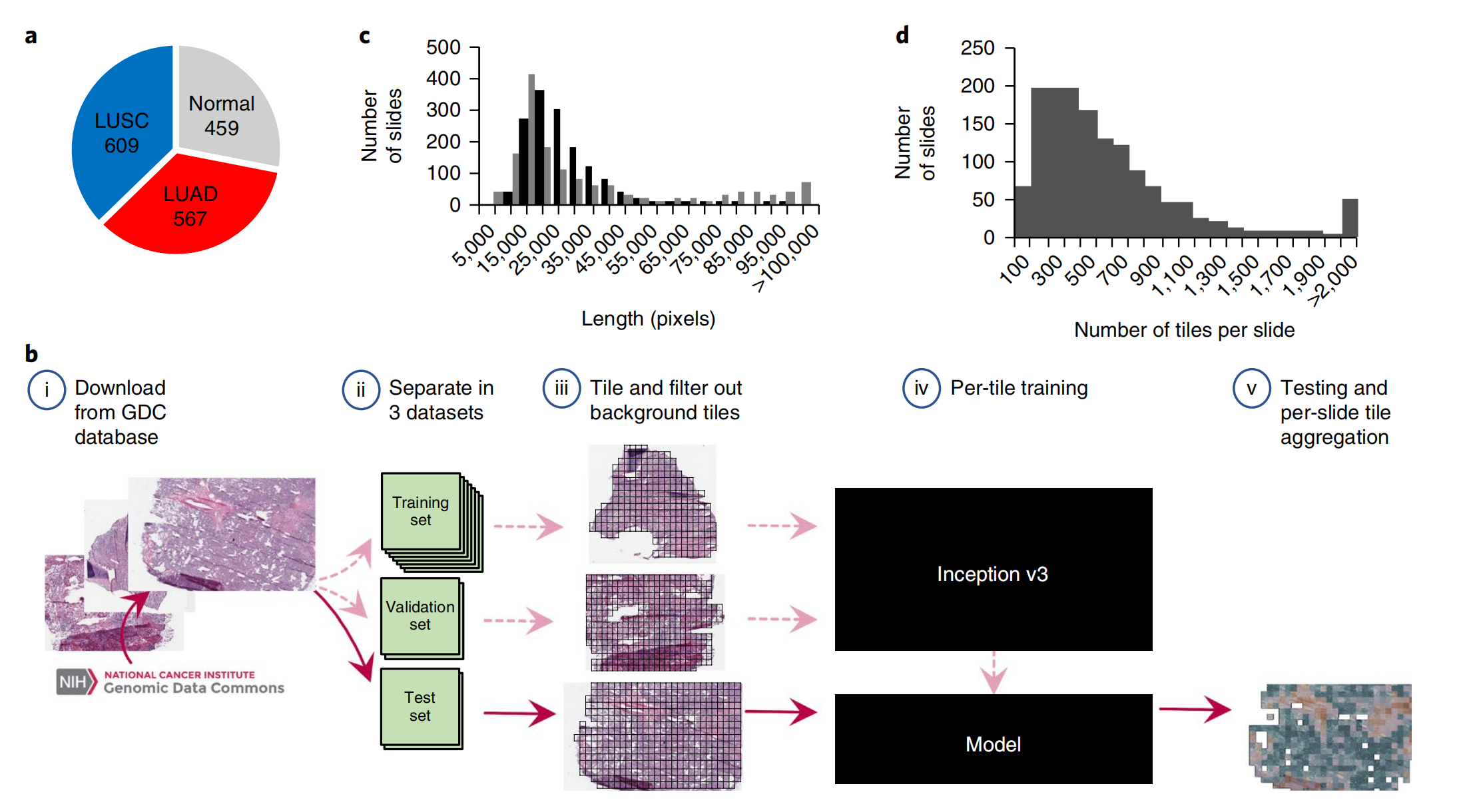
a. 每个类别的全切片图像数量:这部分显示了用于研究的全切片图像在不同类别(如正常组织、LUAD、LUSC)中的分布情况。
b. 训练策略:
- (b, i) 数据下载:研究者首先从基因组数据共享中心(Genomic Data Commons database)下载了肺癌组织图像。
- (b, ii) 数据集划分:下载的切片被分为训练集(70%)、验证集(15%)和测试集(15%)。这种划分有助于模型在未见数据上的性能评估。
- (b, iii) 图像分块:将切片分割成不重叠的512×512像素的窗口(tiles),并排除了超过50%背景的tiles。这样做可以确保模型专注于含有实际组织信息的数据。
- (b, iv) 模型训练:使用Inception v3架构,部分或全部重新训练网络,使用训练和验证tiles。Inception v3是一种深度卷积神经网络,适合处理图像识别任务。
- (b, v) 分类与结果聚合:在独立的测试集上进行分类,并将结果按切片聚合,以提取热图和AUC统计数据。这有助于评估模型的性能和准确性。
c. 图像尺寸分布:展示了图像宽度和高度的分布情况,以灰色和黑色表示。这有助于了解数据的多样性和规模。
d. 每张切片的tiles数量分布:这部分显示了每张切片被分割成的tiles数量,这反映了数据的密度和复杂性。
总的来说,图1概述了从数据准备到模型训练和评估的整个流程,强调了数据的分割、处理和分析方法,这些都是深度学习模型开发中的关键步骤。通过这种方法,研究者能够构建一个强大的模型,用于自动识别和分类肺癌的组织病理学图像。
二、利用深度学习从病理显微图像中预测鼻咽癌患者的生存风险及治疗响应

一作&通讯
| 姓名 | 单位 | 单位(中文) |
|---|---|---|
| Kuiyuan Liu | State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Guangzhou, Guangdong, China | 华南肿瘤学国家重点实验室,癌症医学协同创新中心,广州,广东,中国 |
| Weixiong Xia | Department of nasopharyngeal carcinoma, Sun Yat-sen University Cancer Centre, Guangzhou, Guangdong, China | 鼻咽科,中山大学肿瘤防治中心,广州,广东,中国 |
| Xing Lv | Department of nasopharyngeal carcinoma, State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Sun Yat-sen University Cancer Center, 651 Dongfeng Road East, Guangzhou, China. Email: lvxing@sysucc.org.cn | 鼻咽科,华南肿瘤学国家重点实验室,癌症医学协同创新中心,中山大学肿瘤防治中心,广州,广东,中国。电子邮件:lvxing@sysucc.org.cn |
| Xiang Guo | Department of nasopharyngeal carcinoma, State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Sun Yat-sen University Cancer Center, 651 Dongfeng Road East, Guangzhou, China. Email: guoxiang@sysucc.org.cn | 鼻咽科,华南肿瘤学国家重点实验室,癌症医学协同创新中心,中山大学肿瘤防治中心,广州,广东,中国。电子邮件:guoxiang@sysucc.org.cn |
文献概述
这篇文章通过深度学习分析鼻咽癌患者的病理显微特征(DSPMF),发现了一种新的预后工具,能够预测生存风险并指导个体化诱导化疗的治疗决策。
研究使用了QuPath软件从训练队列(广州训练队列,n = 843)中提取病理显微特征,并利用神经网络DeepSurv分析这些特征,将患者分为高风险和低风险组。通过时间依赖的接收者操作特征(ROC)曲线来确定风险评分,并将患者分为高风险和低风险组。研究的主要终点是无进展生存期(PFS),并在验证队列(n = 212)中验证了病理特征的预后准确性。
研究发现,在H&E图像中有429个病理显微特征。训练队列中高风险评分的患者5年PFS更短(HR 10.03, 95% CI 6.06-16.61; P < .0001)。DSPMF(C-index: 0.723)的C-index高于EBV DNA(C-index: 0.612)和N分期(C-index: 0.593)。此外,在高风险组中,接受诱导化疗(ICT)加同期放化疗(CCRT)的患者比仅接受CCRT的患者有更好的5年PFS(P < .0001)。
研究结论是DSPMF是一个可靠的NPC患者生存风险预后工具,并且可能有助于指导治疗决策。研究还提到了一些限制,包括数据的回顾性评估可能混淆了因果关系的推断,研究仅限于鼻咽癌的特定地区,并且病理微特征帮助指导治疗的原理尚不清楚。
简要分析
FIGURE 2 展示了在训练队列和验证队列中,使用Kaplan-Meier方法分析的几种不同生存指标的曲线。

这些指标包括:
-
5年无进展生存期(PFS):
- 训练队列(A):显示了训练队列中患者从治疗开始起5年内无疾病进展的生存概率。
- 验证队列(E):显示了验证队列中患者同样指标的生存概率。
-
5年远处转移无病生存期(DMFS):
- 训练队列(B):显示了训练队列中患者从治疗开始起5年内未发生远处转移的生存概率。
- 验证队列(F):显示了验证队列中患者同样指标的生存概率。
-
5年总生存期(OS):
- 训练队列(C):显示了训练队列中患者从治疗开始起5年内的整体生存概率。
- 验证队列(G):显示了验证队列中患者同样指标的生存概率。
-
5年局部无复发生存期(LRFS):
- 训练队列(D):显示了训练队列中患者从治疗开始起5年内局部未复发的生存概率。
- 验证队列(H):显示了验证队列中患者同样指标的生存概率。
通过比较训练队列和验证队列中的生存曲线,研究者可以评估他们的风险评分模型在不同患者群体中的一致性和可靠性。如果训练队列和验证队列的生存曲线显示出相似的趋势,这表明风险评分模型具有较好的泛化能力。
三、基于组织病理学的FGFR患者预筛选算法

一作&通讯
| 作者角色 | 姓名 | 单位名称 |
|---|---|---|
| 第一作者 | Albert Juan Ramon | Janssen R&D, LLC, 强生公司(Johnson & Johnson Company). 数据科学和数字健康,圣地亚哥,加利福尼亚州,美国。 |
| 通讯作者 | Kristopher A. Standish | Janssen R&D, LLC, 强生公司(Johnson & Johnson Company). 数据科学和数字健康,圣地亚哥,加利福尼亚州,美国。 |
文献概述
这篇文章报道了一种基于深度学习的组织病理学图像分析算法的开发和临床试验部署,该算法能够高效地预筛选出可能携带FGFR遗传变异的尿路上皮癌患者,以加速靶向治疗的临床应用。
该算法旨在通过分析H&E染色的全切片图像来识别肿瘤中的遗传变异,例如成纤维细胞生长因子受体(FGFR)。这对于使用靶向治疗药物(如BALVERSA™,即erdafitinib)治疗患者至关重要。然而,分子测试可能因时间和组织需求量大而延误患者护理。
研究团队开发了一种深度学习算法,使用来自3000多名晚期尿路上皮癌患者的H&E染色全切片图像进行训练,优化了高灵敏度以避免排除符合试验条件的患者。该算法在350名患者的数据集上进行了验证,达到了0.75的曲线下面积(AUC),在88.7%的灵敏度下特异性为31.8%,并预计可减少28.7%的分子测试需求。该系统已成功部署在包含89个全球研究临床站点的非干预性研究中,展示了其在优先分配/取消分子测试资源和在药物开发及临床环境中节省大量成本的潜力。
文章还讨论了将这种基于H&E的FGFR+筛查设备部署在临床试验或临床实践中的潜在价值,包括降低成本、减少患者入组或接受正确靶向治疗的时间,以及通过提供快速、可操作的洞察来丰富可能为FGFR+的患者队列。
研究还展示了算法的开发、验证和部署过程,并在非干预性临床研究中进行了前瞻性部署,以筛选患者是否在分子测试前有可能携带目标变异,并展示了这种技术在减少筛查负担和提高试验效率方面的潜力。
研究还表明,通过这种AI设备,可以在标准临床环境中优先考虑(或取消考虑)分子测试的患者,从而为精准医疗提供了快速、可操作的临床洞察。
简要分析
图3展示了使用深度学习算法对尿路上皮癌(MIBC)组织切片进行FGFR阳性和阴性预测的可解释性分析结果。
该图由三部分组成,每部分包含三张图像:
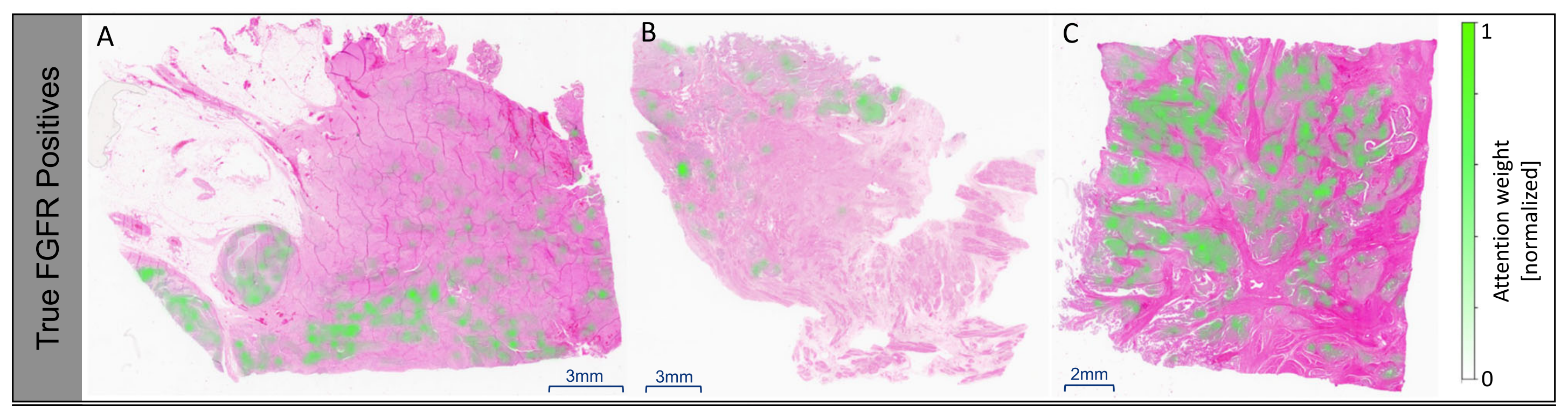
A-C部分:
- 展示了随机选择的FGFR阳性(FGFR+)的全切片图像(WSIs),这些图像显示了MIBC肿瘤组织,并且叠加了表示归一化注意力权重的热图(绿色)。
- 注意力权重被归一化到1,以便在不同图像之间进行比较。
- 每个图像面板右侧的色条对应于归一化权重,所有图像共享相同的色条。
- 越亮的绿色区域表示模型认为对做出预测更重要的区域(更高的注意力权重)。
- 值得注意的是,无论切片被预测为FGFR阳性还是阴性,算法都会在用于推理的所有瓦片上产生注意力权重。
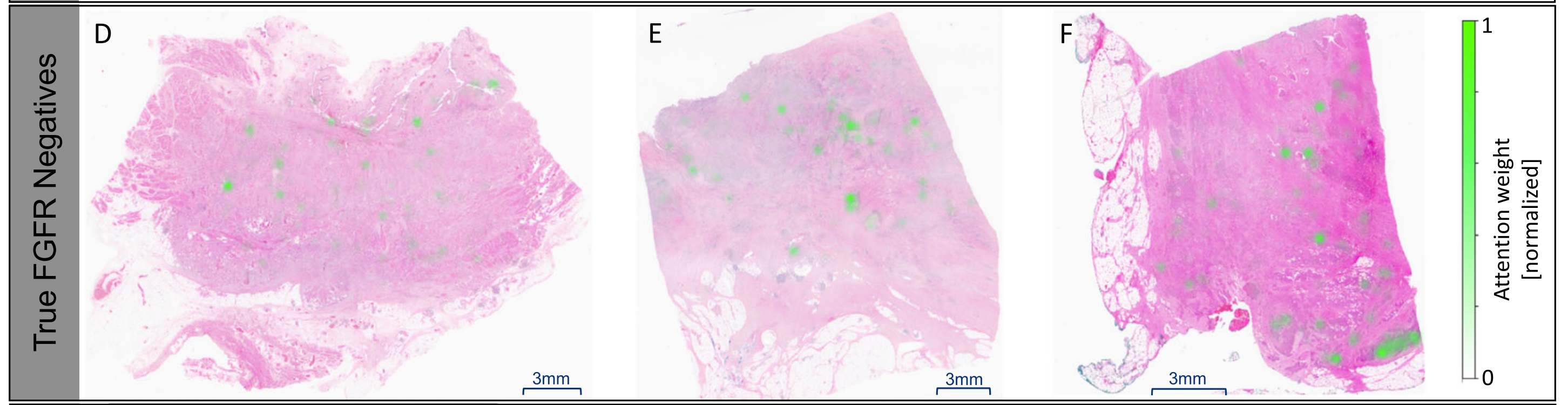
D-F部分:
- 展示了FGFR阴性(FGFR-)的全切片图像示例,这些图像同样带有热图,但预测结果为阴性。
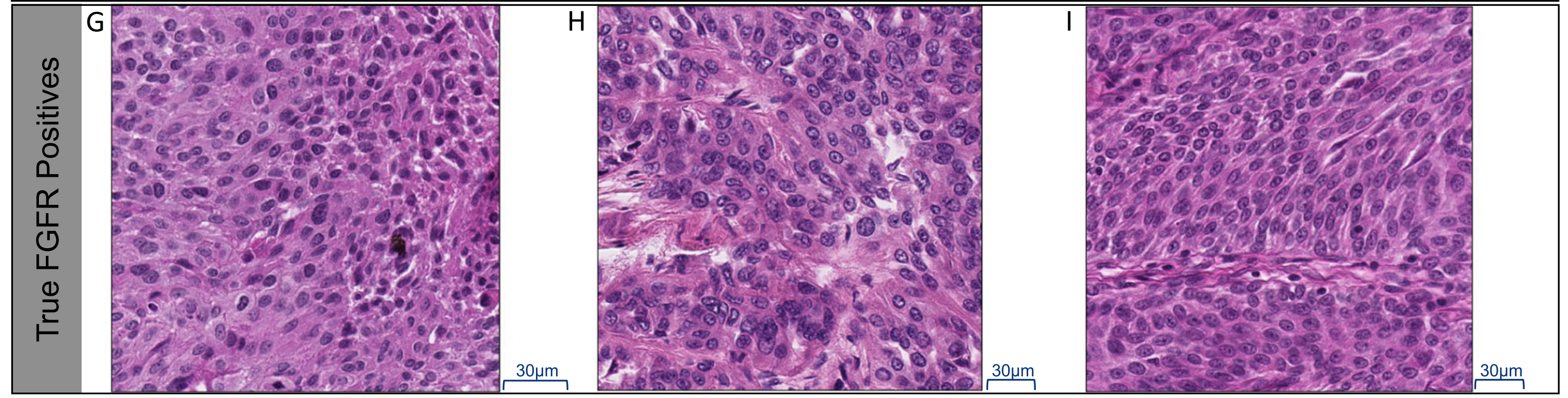
G-I部分:
- 展示了A-C部分中FGFR阳性图像中得分最高的瓦片在40倍放大下的图像。
- 这些高分瓦片显示出更多实体肿瘤细胞,细胞分级较低到中等,与之前的观察结果一致。
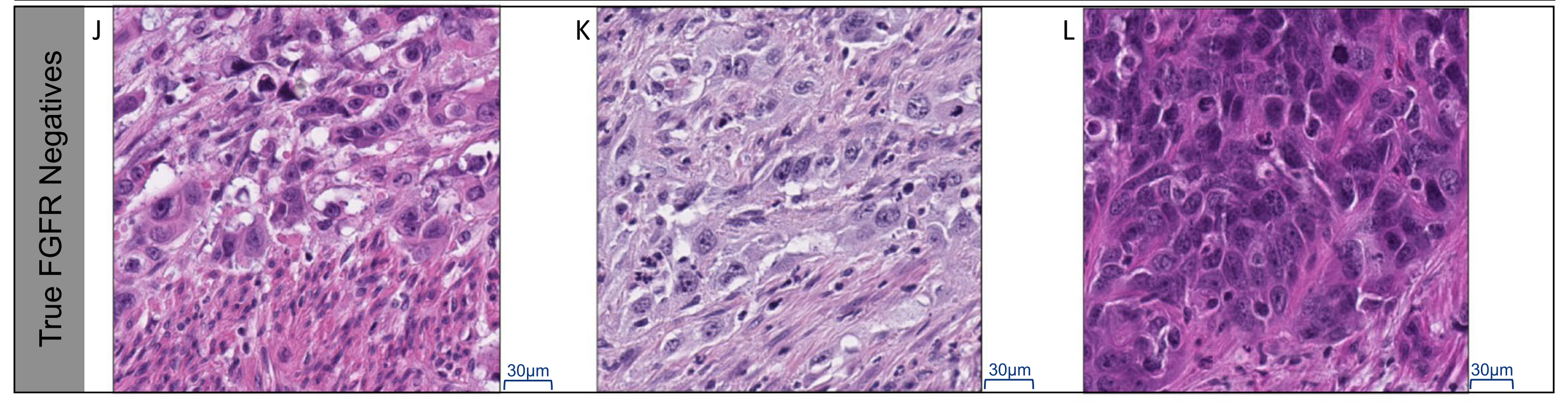
J-L部分:
- 展示了D-F部分中FGFR阴性图像中得分最高的瓦片在40倍放大下的图像。
- 这些高分瓦片显示出相对更多的分散肿瘤细胞,细胞分级较高。
总体而言,图3通过热图直观地展示了算法在做出FGFR阳性或阴性预测时所关注的图像区域,并通过对比阳性和阴性样本中的高分瓦片,揭示了与FGFR状态相关的细胞形态学特征。这种可解释性分析有助于理解算法的决策过程,并为病理学家和临床医生提供了一种评估和信任AI算法预测结果的方法。
关键问题
筛选患者是否在分子测试前有可能携带目标变异的意义是什么?
- 提高治疗效率:通过预先筛选出可能携带特定遗传变异的患者,可以确保他们更快地接受针对性的靶向治疗,从而提高治疗效果和患者的生存率。
- 减少医疗资源浪费:对于那些不太可能携带目标变异的患者,可以避免不必要的分子测试,从而节省医疗资源,包括时间、金钱和人力。
- 加速临床试验:在临床试验中,快速识别出符合特定遗传特征的患者有助于加速试验进程,因为这样可以更快地招募到合适的参与者。
- 改善患者体验:减少患者等待测试结果的时间,可以减轻他们的焦虑和不确定性,改善整体的医疗体验。
- 促进精准医疗:这种筛选方法支持了精准医疗的理念,即根据患者的具体遗传特征提供个性化的治疗方案。
- 提高试验的成功率:通过确保试验参与者更有可能对试验药物产生反应,可以提高临床试验的成功率,从而加速新药的审批和上市。
- 降低医疗成本:分子测试通常成本较高,通过AI预筛选可以减少必要的测试数量,从而降低整体的医疗成本。
- 增加患者对治疗的信心:当患者知道他们正在接受基于自己遗传特征的个性化治疗时,他们对治疗的信心可能会增加,这可能对治疗的依从性和效果产生积极影响。
- 促进新药开发:通过快速有效地识别出可能对新药有反应的患者群体,可以促进新药的开发和改进。
四、MSIntuit:结直肠癌微卫星不稳定性的AI预筛选工具

一作&通讯
| 角色 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Charlie Saillard | Owkin France, Paris, France(法国,巴黎,Owkin公司) |
| 通讯作者 | Jakob Nikolas Kather | Else Kroener Fresenius Center for Digital Health, Technical University Dresden, Dresden, Germany(德国德累斯顿,德累斯顿工业大学,Else Kroener Fresenius数字健康中心) |
| 通讯作者 | Magali Svrcek | Department of Pathology, Saint-Antoine Hospital - Sorbonne Université, AP-HP, Paris, France(法国,巴黎,Saint-Antoine医院-索邦大学,AP-HP,病理学系) |
文献概述
这篇文章是关于一项名为MSIntuit的人工智能(AI)工具的研究,该工具用于从结直肠癌(CRC)组织学切片中预筛选微卫星不稳定性(MSI)。
MSI是结直肠癌中的一个重要生物标志物,其普遍筛查现在被推荐用于所有CRC患者,但这也增加了病理学家的工作量,并可能延迟治疗决策。深度学习有潜力简化dMMR/MSI测试,并加速临床实践中肿瘤学家的决策,但迄今为止,尚无全面验证的临床批准工具。
研究团队开发了MSIntuit,这是一个基于AI的预筛选工具,用于从苏木精-伊红(H&E)染色的切片中检测MSI。该工具在癌症基因组图谱(TCGA)样本上训练后,在600个连续CRC患者的独立数据集上进行了盲验证。
研究还探讨了使用两种不同扫描仪数字化每个切片的互扫描器可靠性。MSIntuit的敏感性为0.96-0.98,特异性为0.47-0.46,并且具有出色的互扫描器一致性(Cohen's κ: 0.82)。研究表明,MSIntuit在保持与黄金标准方法相当的高敏感性的同时,可以排除近一半的非MSI人群,有效减轻临床实践中MSI测试的负担。
文章还讨论了MSI在CRC患者临床管理中的重要性,包括其在诊断、预后和治疗方面的影响。MSI是Lynch综合征(LS)的标志,也是最常见的遗传性CRC易感性形式。MSI肿瘤对免疫检查点抑制剂治疗敏感。2017年,这种基因组不稳定性表型成为美国食品药品监督管理局(FDA)批准的首个泛癌生物标志物,允许使用pembrolizumab治疗MSI不可切除或转移性实体瘤患者。
研究还涉及了MSIntuit的技术细节,包括使用自监督学习(SSL)训练的特征提取器,以及如何通过自动化质量检查和校准步骤使其适用于临床实践。此外,研究还探讨了MSIntuit在不同扫描仪和不同肿瘤区域的一致性和重复性。
最后,文章讨论了MSIntuit在临床实践中的潜在应用,包括其在减轻病理学家工作量、加速肿瘤学家决策、优化成本和组织MSI测试方面的潜力。尽管如此,研究也指出了MSIntuit的一些局限性,包括其仅在手术标本切片上进行了开发和验证,以及在小型中心进行校准可能存在的挑战。
研究呼吁进行进一步的工作,以确保AI模型能够无视不同中心的数据获取差异。
简要分析
Fig. 1展示了MSIntuit在MSI筛查中的临床工作流程和盲验证方法。
这个流程包括以下几个步骤:
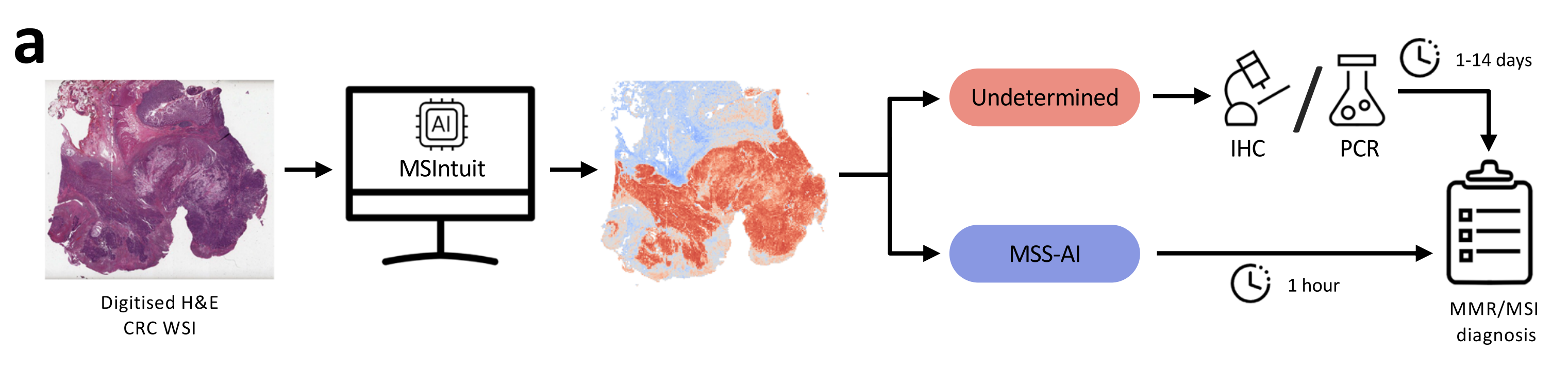
a. MSI筛查的临床工作流程:
- 使用常规的H&E染色的结直肠癌(CRC)组织切片。
- MSIntuit分析这些切片,输出患者是否有可能是MSI(不确定)并需要进行确认性测试(MMR-IHC和/或MSI-PCR),或者不是(MSS-AI)。
- 通过排除大部分非MSI患者,减轻病理学家的工作量并加速MSI筛查过程。
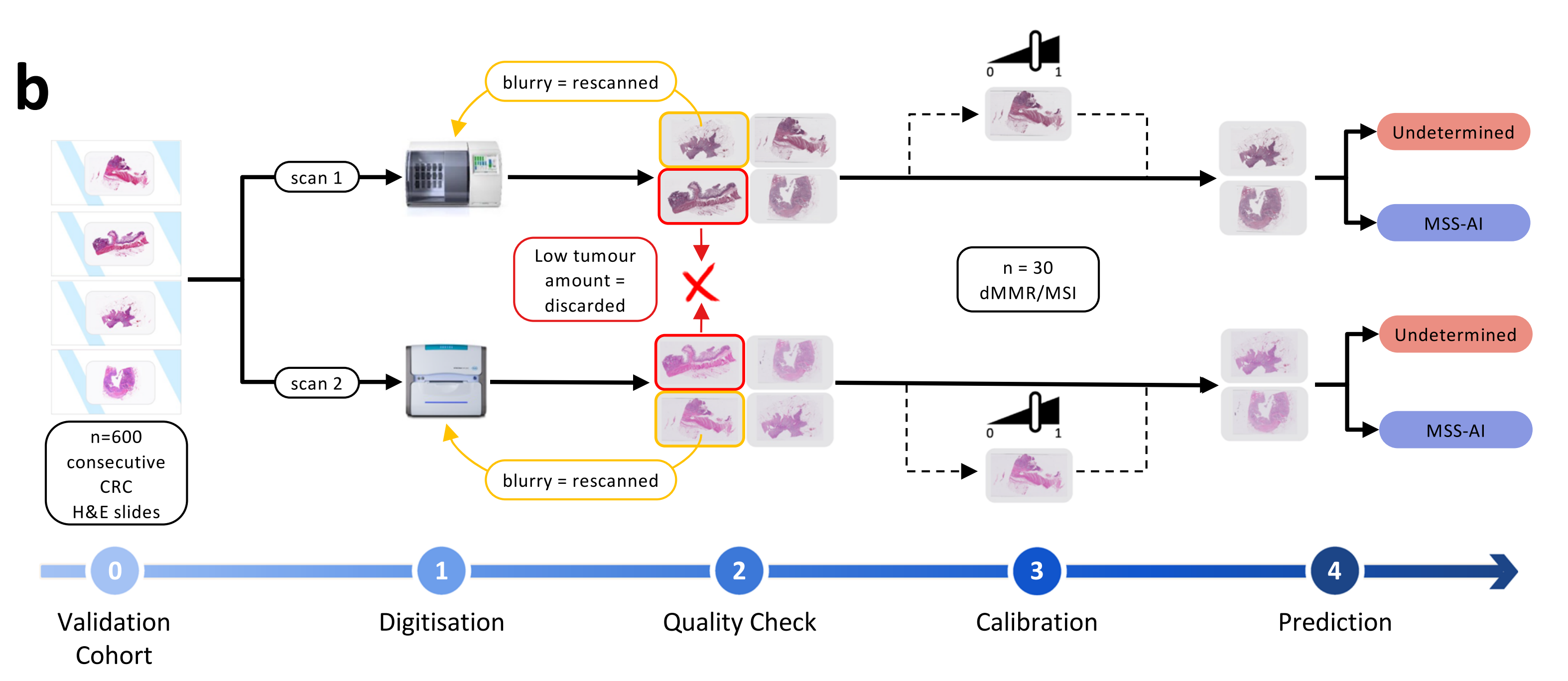
b. 盲验证方法:
- 收集了600例连续切除的CRC样本的H&E切片。
- 使用两台不同的扫描仪(Phillips UFS和Ventana DP200)对这些切片进行数字化,得到两组切片:MPATH-UFS和MPATH-DP200(步骤1)。
- 对每个队列应用相同的处理流程:
- 自动化质量检查,排除不符合标准的切片(如大片模糊区域或肿瘤组织太少)。大片模糊区域的切片需要重新扫描(步骤2)。
- 随机选择30个dMMR/MSI的全切片图像(WSIs)来定义适当的阈值(步骤3)。
- 使用上述步骤中定义的阈值,对剩余的切片进行MSIntuit预测,将患者分类为两个类别:MSS-AI和不确定(步骤4)。
这个流程说明了MSIntuit如何集成到现有的病理诊断流程中,通过自动化的方法提高MSI检测的效率和准确性。通过这种方式,MSIntuit有助于在临床实践中快速识别可能需要进一步MSI检测的患者,同时减少对非MSI患者的不必要的额外测试。
关键问题
盲验证方法在临床试验中具体是如何实施的?
盲验证方法在临床试验中的实施通常遵循以下步骤:
- 随机化(Randomization) :
- 参与者被随机分配到实验组或对照组,以确保各组之间的基线特征均衡。
- 盲法(Blinding) :
- 单盲:只有研究者知道谁接受了实验干预,而参与者不知道。
- 双盲:研究者和参与者都不知道谁接受了实验干预。
- 三盲:研究者、参与者和负责数据收集与分析的人员都不知道分组情况。
- 分配隐藏(Allocation Concealment) :
- 使用中央随机化系统或其他方法确保分配序列对研究者和参与者保密。
- 实施盲法 :
- 制作相同外观的安慰剂或对照治疗,以确保参与者无法通过外观区分治疗。
- 确保所有研究相关文档和通信不透露分组信息。
- 数据收集 :
- 研究人员在不知道分组信息的情况下收集数据,以减少偏见。
- 质量控制 :
- 定期审计研究流程,确保盲法得到维持。
- 数据分析 :
- 在揭盲前进行数据分析,分析人员通常也不知道分组信息。
- 揭盲(Unblinding) :
- 在研究结束或数据分析完成后,才会揭开谁接受了哪种治疗。
- 揭盲通常在最终数据分析完成后进行。
- 结果报告 :
- 研究报告应详细记录盲法的实施情况,包括任何盲法的违反。
在MSIntuit的研究中,盲验证的实施包括以下具体步骤:
- 样本收集:收集600例连续切除的CRC样本的H&E切片。
- 数字化处理:使用两种不同的扫描仪对切片进行数字化处理,形成两组数据集。
- 质量控制:通过自动化质量检查排除不符合标准的切片。
- 阈值设定:使用一部分已知的dMMR/MSI样本来定义预测模型的阈值。
- 模型预测:对剩余的切片进行MSIntuit预测,研究者在预测过程中不知道每个样本的MSI状态。
- 揭盲与分析:在预测完成后,根据实际的MSI状态来评估MSIntuit的性能。
通过这种严格的盲验证方法,研究者能够确保MSIntuit工具的预测性能是准确和可靠的,而不受到任何预期偏见的影响。