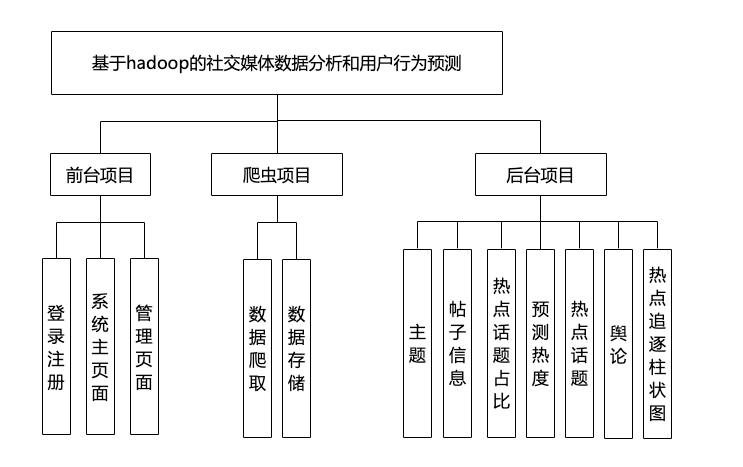
大数据项目:基于Hadoop的Python实现社交媒体数据分析和用户行为预测背景
一、项目背景
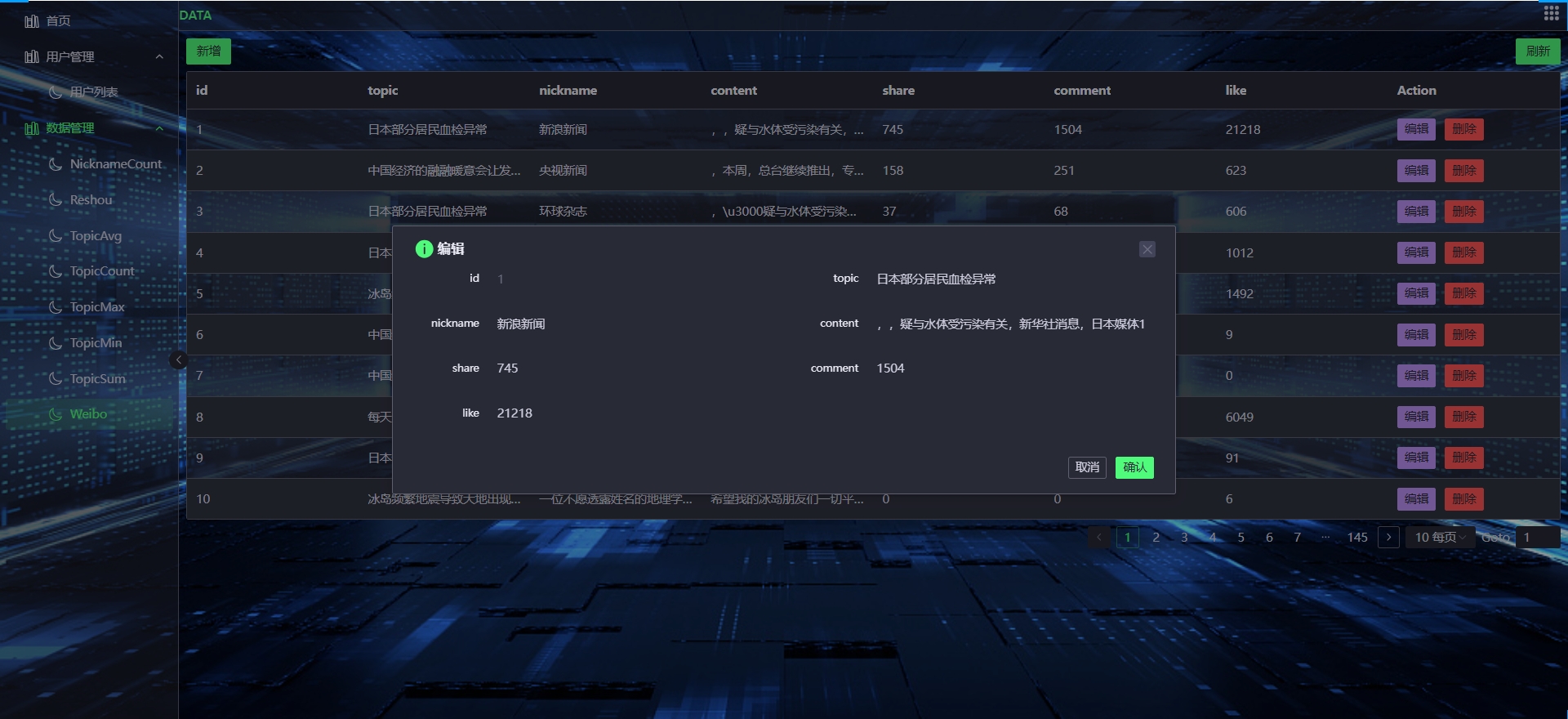
随着互联网技术的快速发展,社交媒体平台已经成为人们日常生活中不可或缺的一部分。这些平台产生了大量的用户数据,包括用户的行为、言论、关系等信息,这些数据蕴含着巨大的价值。如何有效地处理和分析这些社交媒体数据,挖掘其中的价值,成为了大数据领域中一个重要的研究方向。Hadoop作为大数据处理平台,具有高可靠性、高扩展性等特点,成为了处理和分析社交媒体数据的重要工具。
二、项目目标
本项目旨在利用Hadoop平台和Python编程语言,实现社交媒体数据的高效处理和分析,进而对用户行为进行预测。具体目标包括:
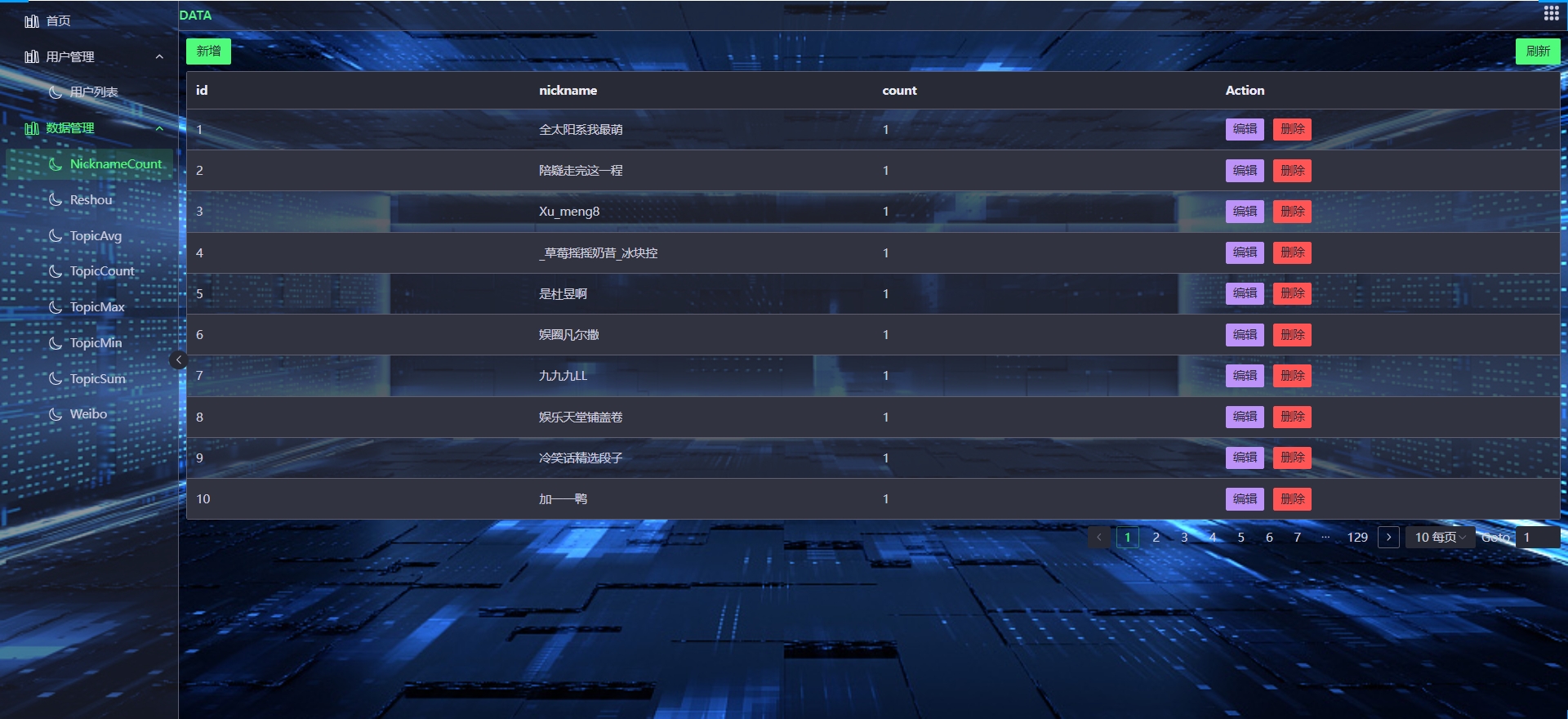
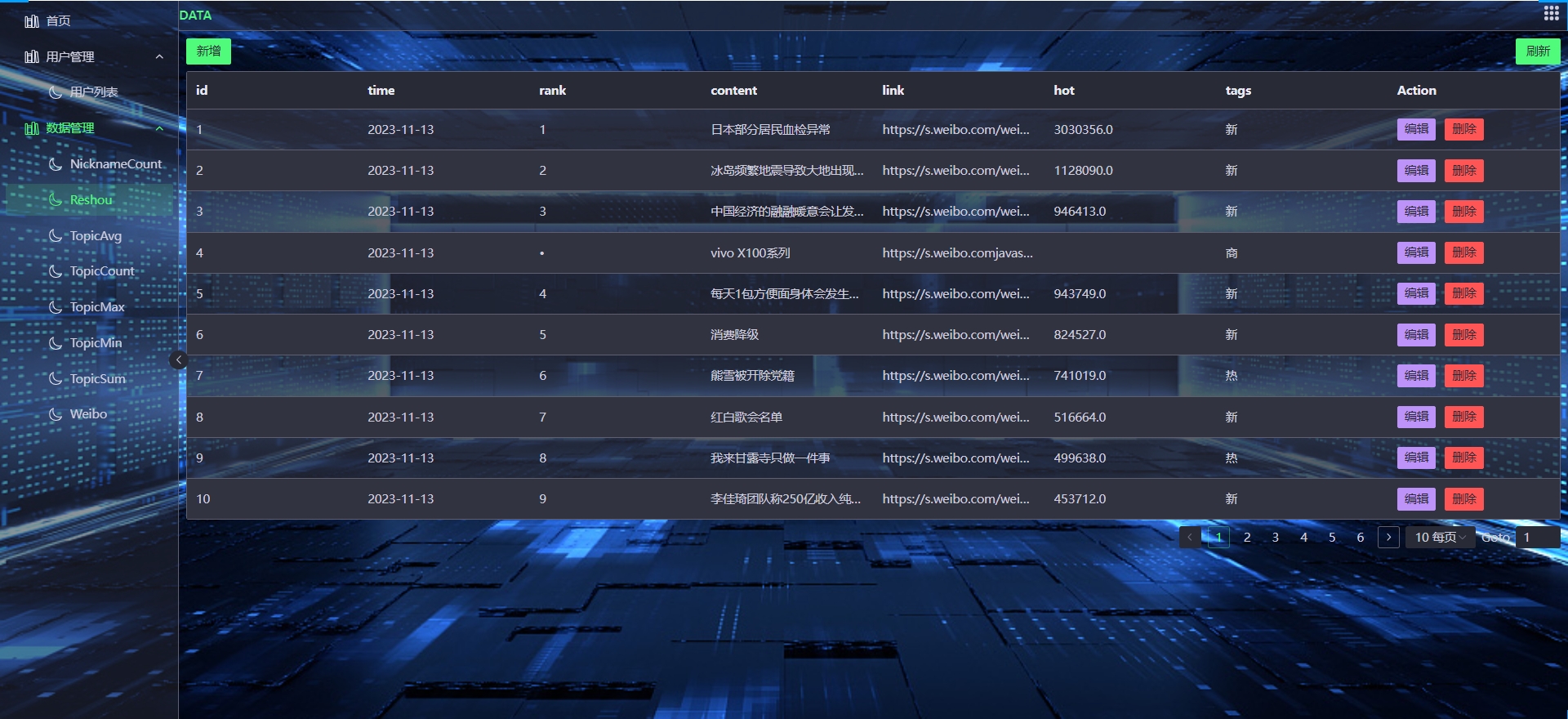
- 数据收集与整合:从多个社交媒体平台收集用户数据,包括用户行为数据、言论数据、关系数据等,并进行整合和清洗。
- 数据预处理:对收集到的数据进行预处理,包括数据去重、缺失值处理、异常值处理等,以确保数据的质量和准确性。
- 数据分析与挖掘:利用Hadoop平台对预处理后的数据进行深入分析和挖掘,发现用户行为的规律和趋势,提取有用的特征和模式。
- 用户行为预测:基于挖掘到的特征和模式,构建用户行为预测模型,对未来的用户行为进行预测。
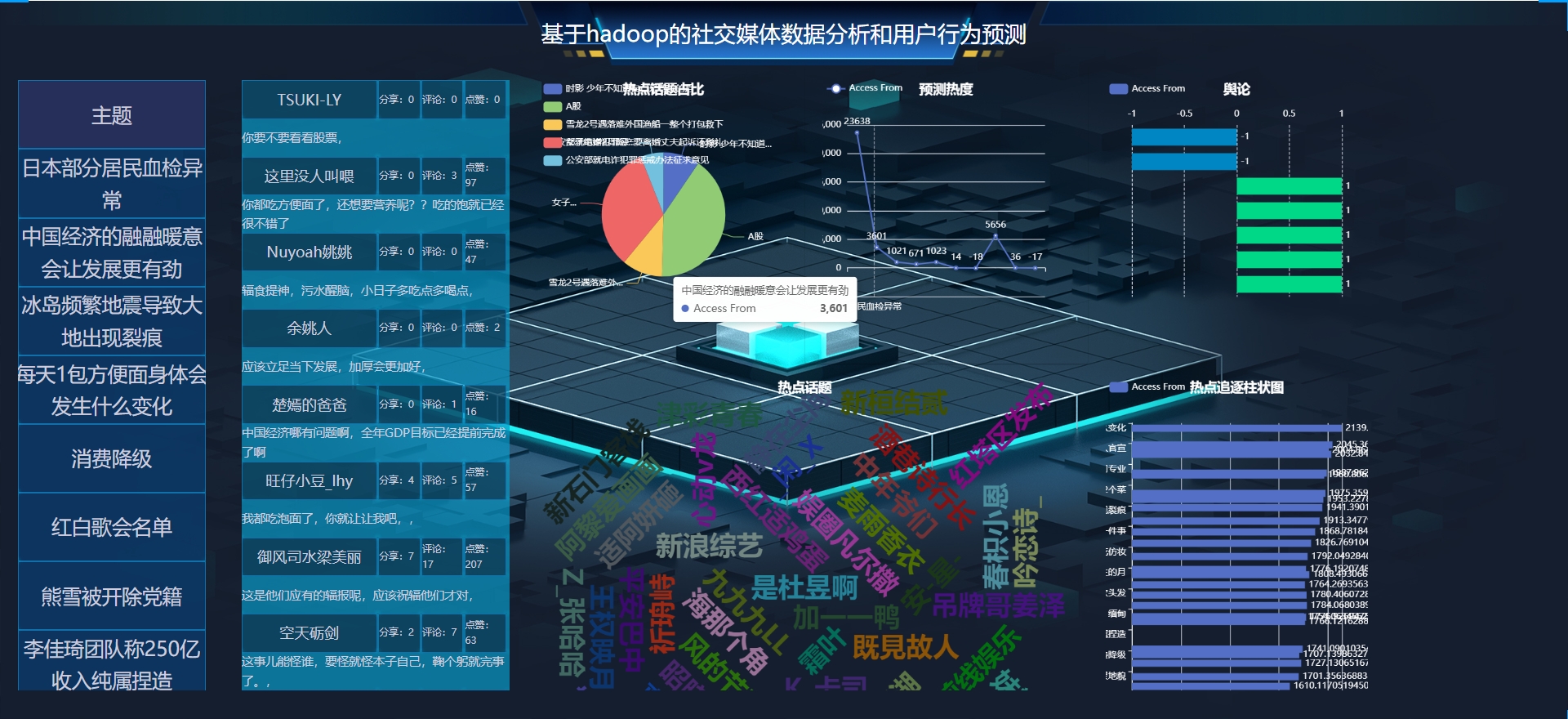
- 结果可视化与报告:将分析结果和预测结果以可视化的方式呈现,生成详细的报告,为决策提供有力支持。
三、Hadoop与Python的结合优势
- Hadoop的分布式计算能力:Hadoop平台具有强大的分布式计算能力,能够处理PB级别的数据,实现高并发和分布式计算,保证数据处理的可靠性和效率。
- Python的灵活性和丰富库支持:Python语言简洁易读,具有强大的数据处理和分析能力,特别是其丰富的库支持(如NumPy、Pandas、SciPy等),为数据分析和数据科学提供了强大的工具箱。
- Hadoop与Python的无缝集成:通过Hadoop Streaming、Apache Hive等方式,可以实现Python与Hadoop的无缝集成,使得Python能够充分利用Hadoop的分布式计算能力来处理大规模数据集。
四、项目实现步骤
- Hadoop集群搭建:搭建Hadoop集群,包括HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算模型)等核心组件的配置和优化。
- 数据收集与整合:利用Python编写爬虫程序或调用API接口,从多个社交媒体平台收集用户数据,并进行整合和清洗。
- 数据预处理:使用Hadoop平台对收集到的数据进行预处理,包括数据去重、缺失值处理、异常值处理等。
- 数据分析与挖掘:利用Hadoop的MapReduce编程模型或Hive SQL查询语言,对预处理后的数据进行深入分析和挖掘,提取有用的特征和模式。
- 用户行为预测模型构建:基于挖掘到的特征和模式,使用Python构建用户行为预测模型,如逻辑回归、随机森林等。
- 模型训练与评估:利用训练集数据对模型进行训练,并使用测试集数据对模型进行评估和优化。
- 结果可视化与报告:使用Python的可视化库(如Matplotlib、Seaborn等)将分析结果和预测结果以可视化的方式呈现,并生成详细的报告。
五、项目意义与应用价值
本项目利用Hadoop平台和Python编程语言实现了社交媒体数据的高效处理和分析,以及用户行为的预测。这不仅有助于深入挖掘社交媒体数据的价值,还为企业的市场策略制定、用户体验优化等提供了有力的数据支持。同时,该项目也为大数据技术在社交媒体领域的应用提供了新的思路和方法,具有重要的理论意义和实践价值。
数据库管理工具:phpstudy/Navicat或者phpstudy/sqlyog
后台管理系统涉及技术:
后台使用框架:Django
前端使用技术:Vue,HTML5,CSS3、JavaScript等
数据库:Mysql数据库
本系统功能完整,适合作为计算机项目设计参考 以及学习、就业面试、商用皆可。
下面是资料信息截图:
功能介绍:

下面是系统运行起来后的一些截图: