转自:萤火架构
本文聊聊 LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上------创造价值。
使用LLama-Factory,常见的就是训练LoRA模型,增强模型在某方面的生成能力。本教程将以增强 GLM-4-9B-Chat 模型的脑筋急转弯能力为例,演示LoRA模型的微调方法。
想要掌握如何将大模型的力量发挥到极致吗?2024年10月26日叶老师带您深入了解 Llama Factory ------ 一款革命性的大模型微调工具。
*留言"参加"即可来叶老师的直播间互动,*1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。互动交流,畅谈工作中遇到的实际问题。
环境准备
本地使用
LLama-Factory 的安装比较简单,大家直接看官网页面就够了:
https://github.com/hiyouga/LLaMA-Factory
云镜像
如果你本地没有一张好显卡,也不想费劲的安装,就想马上开始训练。
可以试试我的云镜像,开箱即用:https://www.haoee.com/applicationMarket/applicationDetails?appId=40\&IC=XLZLpI7Q
平台注册就送一定额度,可以完成本教程的的演示示例。
镜像已经内置了几个基础模型,大都在6B-9B,单卡24G显存即可完成LoRA微调。
如果要微调更大的模型,则需要更多的显卡和显存,请在购买GPU时选择合适的显卡和数量。
已经内置的模型:Yi-1.5-9B-Chat、Qwen2-7B、meta-llama-3.1-8b-instruct、glm-4-9b-chat、chatglm3-6b
如果缺少你需要的模型,可以给我反馈。
假设你已经解决了程序运行环境问题,下边将开始讲解 LLama-Factory 的使用方法。
LLama-Factory 支持命令行和Web页面训练两种方式,为了方便入门,这篇文章以Web页面训练为例。
选择基础模型
语言:zh,因为我们要微调的是中文模型。
模型选择:GLM-4-9B-Chat
模型路径:/root/LLaMA-Factory/models/glm-4-9b-chat,默认会自动下载模型,不过速度可能比较慢,我们的镜像中已经下载好这个模型,所以直接填写路径更快。
微调方法:lora

准备训练数据集
LLaMA-Factory自带了一些常用的数据集,如果你使用的数据集不在里边,可以修改 data/dataset_info.json,在其中增加自己的数据集。
这里我使用的是一个弱智吧问答数据集,数据集的格式是 alpaca,来源:https://huggingface.co/datasets/LooksJuicy/ruozhiba
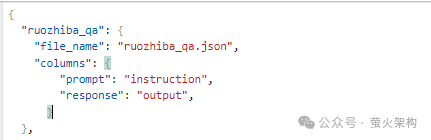
大家准备自己的数据的时候,也一定要按照指定的格式来。
训练参数设置
训练参数需要根据实际训练效果进行调整,这里给出一个参考设置。
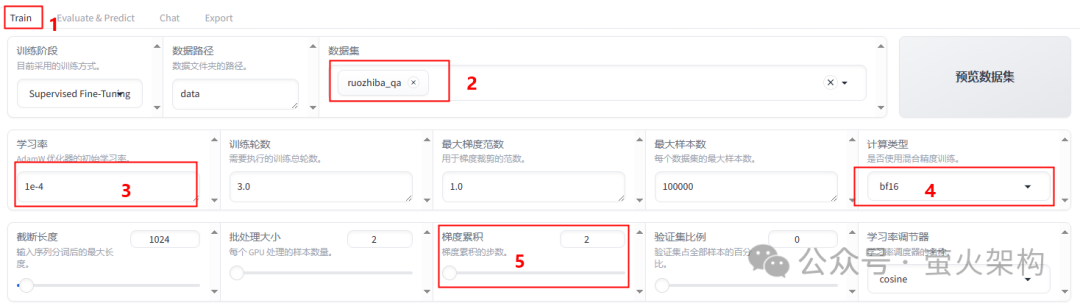
数据集:请根据你的需要选择,这里选择我上边定义的 ruozhiba_qa。
学习率:1e-4,设置的大点,有利于模型拟合。
计算类型:如果显卡较旧,建议计算类型选择fp16;如果显卡比较新,建议选择bf16。
梯度累计:2,有利于模型拟合。

LoRA+学习率比例:16,相比LoRA,LoRA+续写效果更好。
LoRA作用模块:all**,**表示将LoRA层挂载到模型的所有线性层上,提高拟合效果。
开始训练
点击"开始"按钮,可以在页面上看到训练进度和训练效果。
根据训练方法和训练数据的大小,训练需要的时间不定。

推理测试
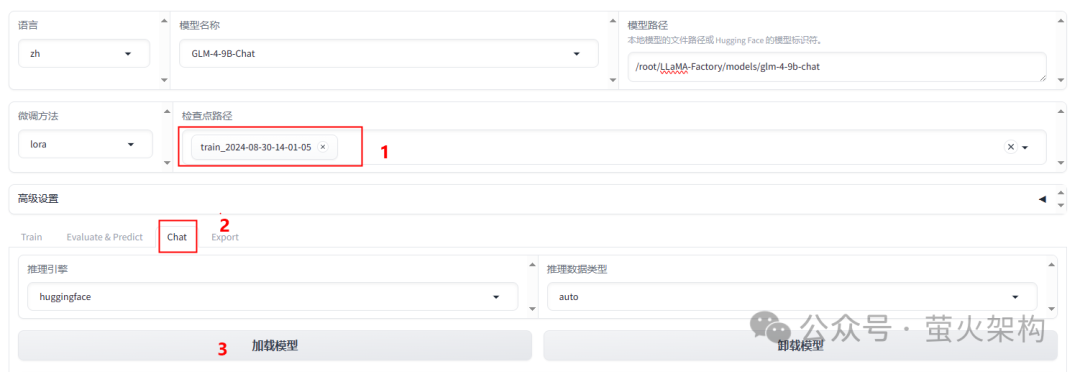
在"检查点路径"这里加载刚刚训练的LoRA模型,然后切换到"Chat"页签,点击"加载模型"。
测试完毕后,记得点击"卸载模型",因为模型占用显存比较大,不释放的话,再进行别的任务可能会出错。
对比训练前后的变化:
训练前:
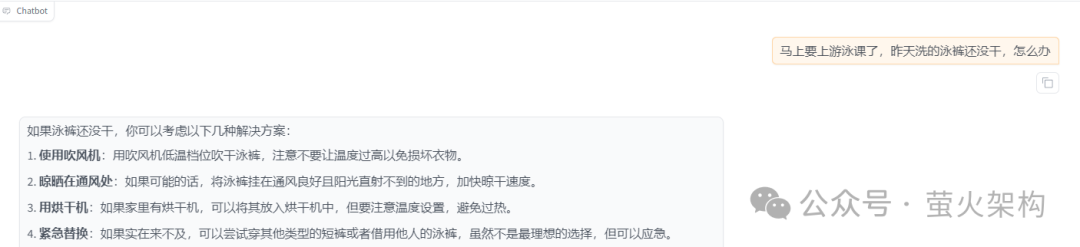
训练后:

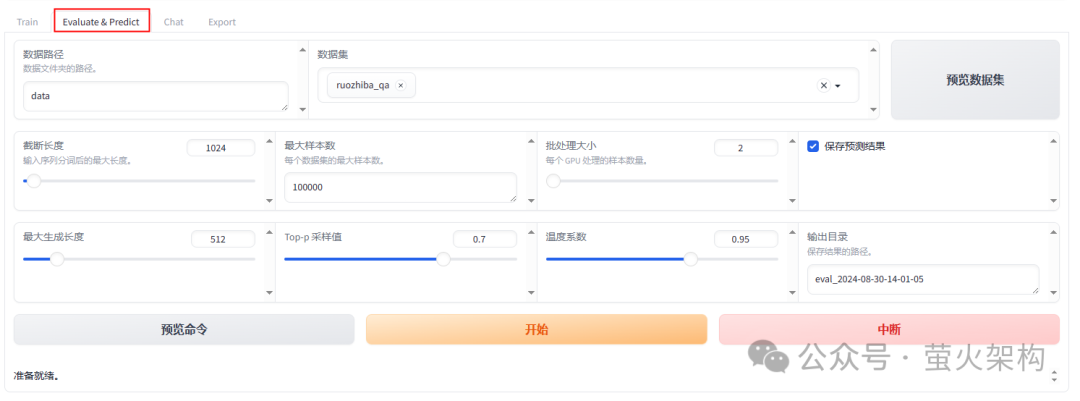
这是一个比较感性的测试,如果需要更为正式的效果评估,请使用"Evaluate & Predict" 选择合适的评测数据集进行评估。
合并导出模型
有时候我们需要把模型导出来放在别的地方使用,输出一个完整的模型文件,而不是基础模型+LoRA模型。

检查点路径:训练出来的LoRA模型
导出目录:设置一个服务器上的路径,新的模型会存放到这里。
最后点击"开始导出"就行了。导出完毕后,请前往服务器相关的路径中下载模型。
LLaMA-Factory 架构
最后送大家一张 LLaMA-Factory 的架构图,方便理解其原理。
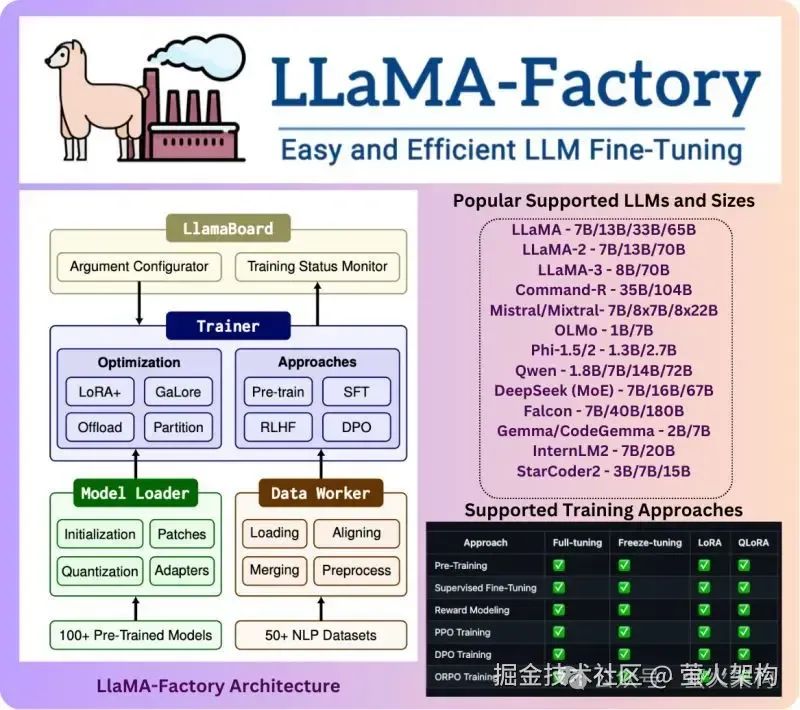
图片左侧:显示了 LLaMA-Factory 的架构,分为四个主要部分:LlamaBoard、Trainer、Model Loader 和 Data Worker。
-
LlamaBoard:用于参数配置和训练状态监视。
-
Trainer:负责优化和训练方法的选择,如 LoRA+、GaLoRe、Pre-train、SFT 等。
-
Model Loader:负责模型初始化、补丁、量化和适配器等功能。
-
Data Worker:负责加载、对齐、预处理和合并训练数据。
图片右侧:列出了支持的流行语言模型和大小,以及支持的训练方法。
-
支持的语言模型和大小:LLaMA、LLaMA-2、LLaMA-3、Command-R、Mistral/Mixtral、OLMo、Phi-1.5/2、Qwen、DeepSeek (MoE)、Falcon、Gemma/CodeGemma 和 StarCoder2。
-
支持的训练方法:全量调整、冻结调整、LoRA、QLoRA、奖励建模、PPO 训练、DPO 训练、ORPO 训练。
总体上来说,LLama-Factory 的使用还是挺顺利的,没有太多的坑。
听不如见,见不如做,自己动手,才能真正有所感悟!