分布式数据库环境(HBase分布式数据库)的搭建与配置
- [1. VMWare安装CentOS7.9.2009](#1. VMWare安装CentOS7.9.2009)
-
- [1.1 下载 CentOS7.9.2009 映像文件](#1.1 下载 CentOS7.9.2009 映像文件)
- [1.2启动 VMware WorkstationPro,点击"创建新的虚拟机"](#1.2启动 VMware WorkstationPro,点击“创建新的虚拟机”)
- 1.3在新建虚拟机向导界面选择"典型(推荐)"
- [1.4安装来源选择"安装程序光盘映像文件(iso)",点击"浏览"按钮,选择下载的 centos7映像文件:CentOS-7-x86_64-Minimal-2009.iso](#1.4安装来源选择“安装程序光盘映像文件(iso)”,点击“浏览”按钮,选择下载的 centos7映像文件:CentOS-7-x86_64-Minimal-2009.iso)
- [1.5指定虚拟机名称和位置(建议存储位置从默认的 C 盘改为其它盘)](#1.5指定虚拟机名称和位置(建议存储位置从默认的 C 盘改为其它盘))
- [1.6指定磁盘容量,可以使用推荐的 20GB](#1.6指定磁盘容量,可以使用推荐的 20GB)
- 1.7点击"自定义硬件",修改默认配置参数
- [1.8 VM 自动运行 CentOS7 映像文件,点击鼠标进入虚拟机,用键盘选中"Install CentOS7",然后按回车键](#1.8 VM 自动运行 CentOS7 映像文件,点击鼠标进入虚拟机,用键盘选中“Install CentOS7”,然后按回车键)
- [1.9在 CentOS 7 的安装欢迎界面,选择安装语言为"简体中文"。](#1.9在 CentOS 7 的安装欢迎界面,选择安装语言为“简体中文”。)
- 1.10设置"安装信息摘要"。
-
- [1.10.1 点击"安装位置",在新窗口中,可以使用默认设置,直接点击左上角的"完成"按钮。](#1.10.1 点击“安装位置”,在新窗口中,可以使用默认设置,直接点击左上角的“完成”按钮。)
- [1.10.2点击"KDUMP",在新窗口中取消"启用 kdump"后,点击左上角的"完成"按钮。](#1.10.2点击“KDUMP”,在新窗口中取消“启用 kdump”后,点击左上角的“完成”按钮。)
- 1.10.3点击"网络和主机名",在新窗口中点击按钮打开以太网连接,在下方设置主机名为"centos7server",并点击"应用"按钮,然后点击左上角的"完成"按钮。
- [1.10.4配置完毕,点击"开始安装"。在安装界面点击"ROOT 密码",在新窗口中设置密码为:root,然后需要两次点击左上角的"完成按钮",返回安装界面。](#1.10.4配置完毕,点击“开始安装”。在安装界面点击“ROOT 密码”,在新窗口中设置密码为:root,然后需要两次点击左上角的“完成按钮”,返回安装界面。)
- 1.10.5等安装结束后,点击"重启"按钮。
- [1.10.6重启进入登陆界面,输入用户名 root,密码 root(输入密码时没有回显),即可成功登陆。](#1.10.6重启进入登陆界面,输入用户名 root,密码 root(输入密码时没有回显),即可成功登陆。)
- 1.11系统设置
- [2. 安装hadoop](#2. 安装hadoop)
- [3. 安装Hbase](#3. 安装Hbase)
-
- [3.1 准备安装文档。](#3.1 准备安装文档。)
- 3.2配置环境变量
- 3.3修改Hbase配置文件
- 3.4启动hbase。
- 4.总结
- 5.参考资料
1. VMWare安装CentOS7.9.2009
1.1 下载 CentOS7.9.2009 映像文件
下载网址:下载网址
1.2启动 VMware WorkstationPro,点击"创建新的虚拟机"
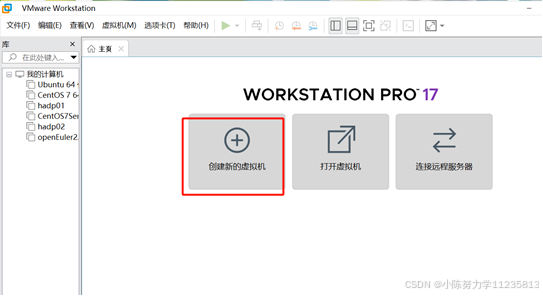
1.3在新建虚拟机向导界面选择"典型(推荐)"
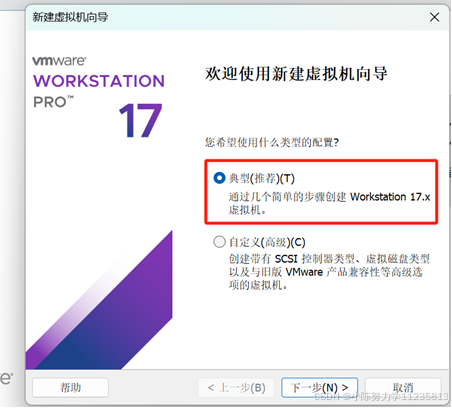
1.4安装来源选择"安装程序光盘映像文件(iso)",点击"浏览"按钮,选择下载的 centos7映像文件:CentOS-7-x86_64-Minimal-2009.iso
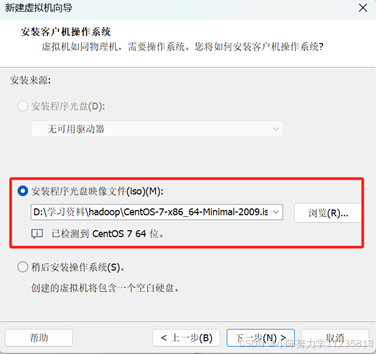
1.5指定虚拟机名称和位置(建议存储位置从默认的 C 盘改为其它盘)
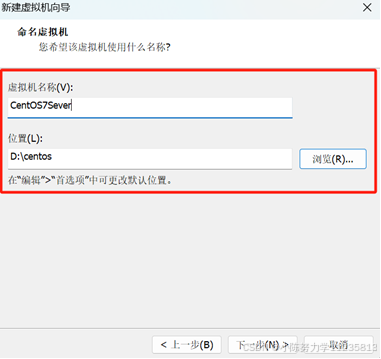
1.6指定磁盘容量,可以使用推荐的 20GB
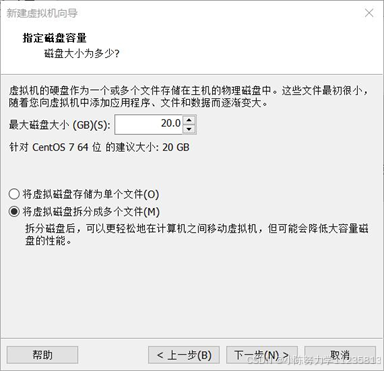
1.7点击"自定义硬件",修改默认配置参数

设置内存为 4G,处理器为 2 核
移除打印机(选中打印机后,点击移除按钮)

配置完成后,点击"关闭"按钮。
回到新建虚拟机向导界面,点击"完成"按钮。

1.8 VM 自动运行 CentOS7 映像文件,点击鼠标进入虚拟机,用键盘选中"Install CentOS7",然后按回车键
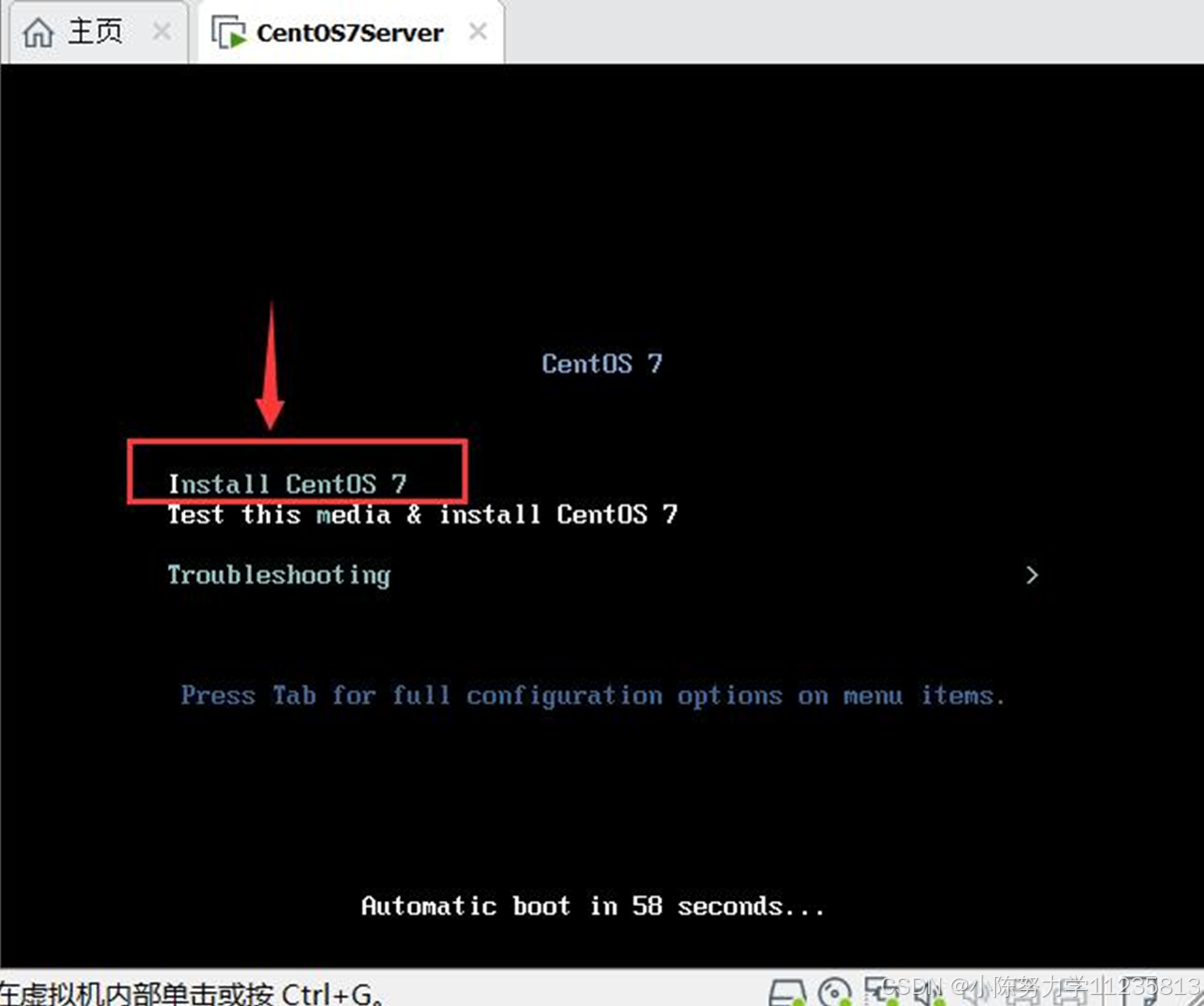
1.9在 CentOS 7 的安装欢迎界面,选择安装语言为"简体中文"。
1.10设置"安装信息摘要"。
1.10.1 点击"安装位置",在新窗口中,可以使用默认设置,直接点击左上角的"完成"按钮。
1.10.2点击"KDUMP",在新窗口中取消"启用 kdump"后,点击左上角的"完成"按钮。


1.10.3点击"网络和主机名",在新窗口中点击按钮打开以太网连接,在下方设置主机名为"centos7server",并点击"应用"按钮,然后点击左上角的"完成"按钮。
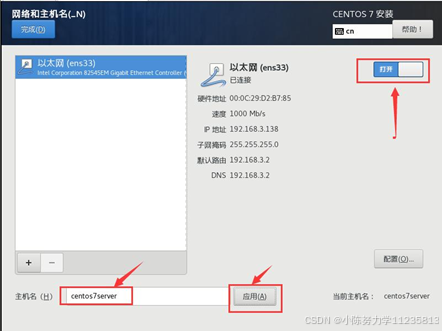
1.10.4配置完毕,点击"开始安装"。在安装界面点击"ROOT 密码",在新窗口中设置密码为:root,然后需要两次点击左上角的"完成按钮",返回安装界面。
1.10.5等安装结束后,点击"重启"按钮。
1.10.6重启进入登陆界面,输入用户名 root,密码 root(输入密码时没有回显),即可成功登陆。

1.11系统设置
1.11.1修改网卡配置信息
查看当前ip地址

切换工作目录:cd /etc/sysconfig/network-scripts/
编辑网卡文件:vi ifcfg-ens33
默认为命令模式,无法修改文件内容,按下字母"i"进入编辑模式,修改内容如下:

修改完毕后,按"ESC"键进入命令模式,输入":wq"保存退出
重启网卡:systemctl restart network
检查网络是否连通:ping www.baidu.com
显示如下结果,说明网络正常,按 Ctrl+C 退出执行:

关闭防火墙:systemctl disable firewalld
关闭 selinux:sed -i 's/enforcing/disabled/' /etc/selinux/config
重启:reboot
2. 安装hadoop
2.1克隆一台虚拟机,设置网卡静态ip
• cd /etc/sysconfig/network-scripts
• 编辑网卡文件:vi ifcfg-ens33
• 将IPADDR的值修改为192.168.37.182(其它配置不变)。
• 保存后,执行systemctl restart network,即可重启网卡,使设置生效
• 运行ping www.baidu.com检查网络是否连通。
2.2配置主机名
• 在虚拟机hadp01上编辑hostname文件vi /etc/hostname,修改文件内容为:hadp01
• 编辑hadp01的hosts文件vi /etc/hosts。
加以下内容:192.168.3.182 hadp02
• 在虚拟机的hosts文件中增运行reboot重启CentOS系统,使设置生效
2.3安装jdk和Hadoop
• 在官网下载文件:jdk-8u201-linux-x64.tar.gz和hadoop-2.9.2.tar.gz,通过MobaXterm,将保存在Win10中的jdk-8u201-linux-x64.tar.gz和hadoop-2.9.2.tar.gz传递到hadp01的/home/root目录中,并解压到执行命令tar -xzvf jdk-8u201-linux-x64.tar.gz -C apps/,tar -xzvf hadoop-2.9.2.tar.gz -C apps/, 将jdk解压到指定目录中(/home/root/apps)。
• vi /etc/profile 编辑/etc/profile文件,在文件的末尾设置JAVA环境变量

2.4配置相关文件
• 2.4.1 vi /etc/profile 编辑/etc/profile文件,在文件的末尾设置Hadoop环境变量

运行source /etc/profile 让修改后的/etc/profile文件立即生效
• 执行命令cd /home/root/apps/hadoop-2.9.2/etc/hadoop,切换到目录/home/root/apps/hadoop-2.9.2/etc/hadoop下。
• 编辑core-site.xml文件vi core-site.xml

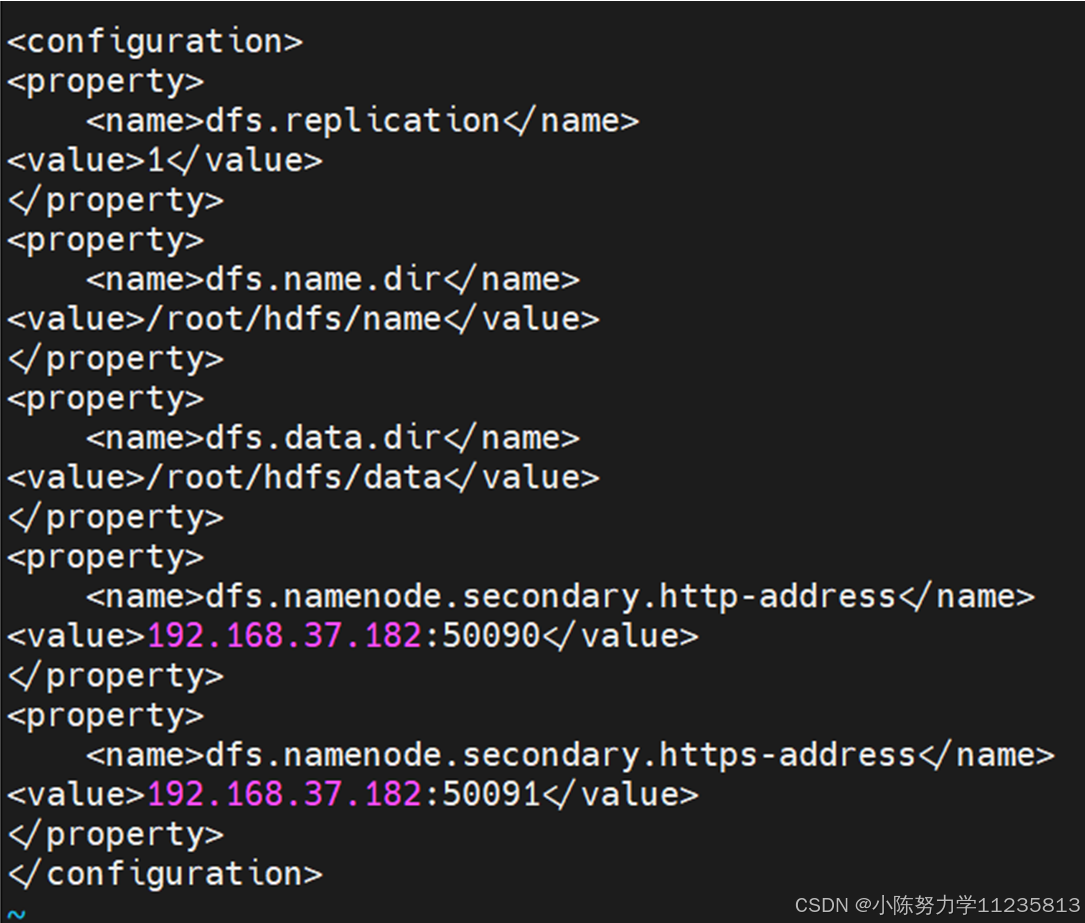
• 编辑hdfs-site.xml文件,vi hdfs-site.xml
• 根据模板创建mapred-site.xml文件:cp mapred-site.xml.template mapred-site.xml
• 编辑mapred-site.xml文件
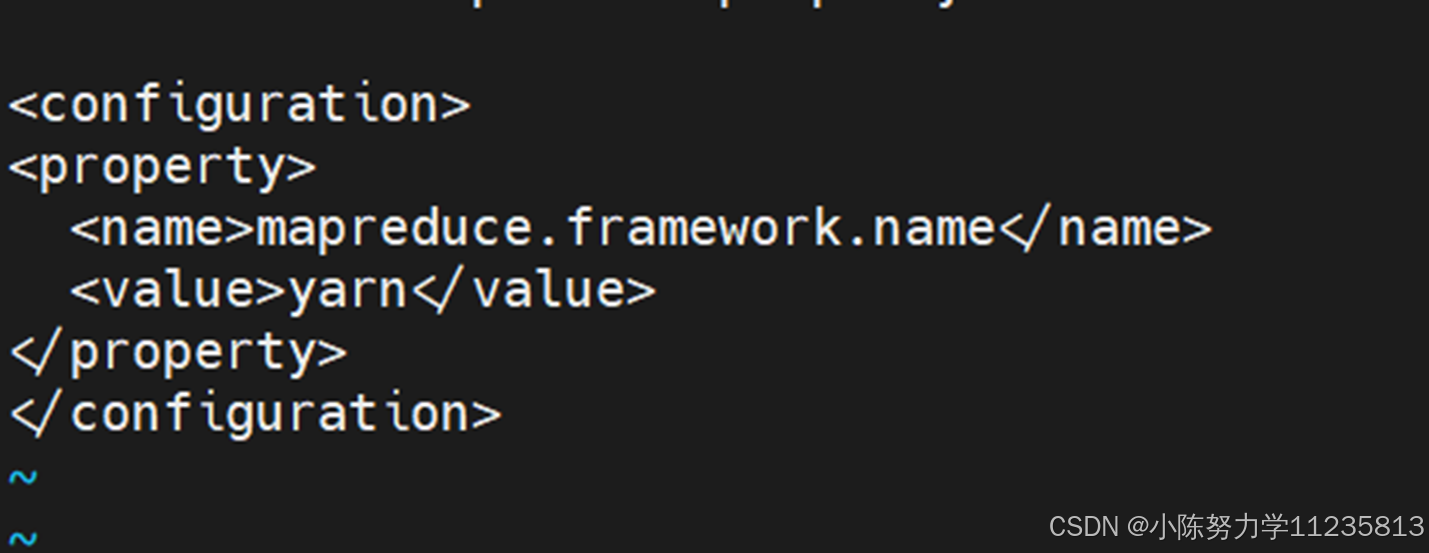
• 编辑yarn-site.xml文件vi yarn-site.xml
o yarn.nodemanager.aux-services:指定辅助服务
o yarn.resourcemanager.hostname:指定resourcemanager的地址
xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadp01</value>
</property>• 编辑hadoop-env.sh文件vi hadoop-env.sh
o 将默认的export JAVA_HOME=${JAVA_HOME}替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201
• 编辑yarn-env.sh文件i
o 将默认的# export JAVA_HOME=/home/y/libexec/jdk1.6.0/替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201,记得删除这一行最前面的#
• 编辑mapred-env.sh文件vi mapred-env.sh
o 将默认的# export JAVA_HOME=/home/y/libexec/jdk1.6.0/替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201,记得删除这一行最前面的#
• 编辑slaves文件vi slaves
o 将默认的localhost改为hadp01
2.5运行启动hadoop
• 格式化namenode节点:hdfs namenode -format
• 启动Hadoop集群
o cd /home/root/apps/hadoop-2.9.2/sbin
o ./start-all.sh
o 提示Are you sure you want to continue connecting (yes/no)?时,输入yes
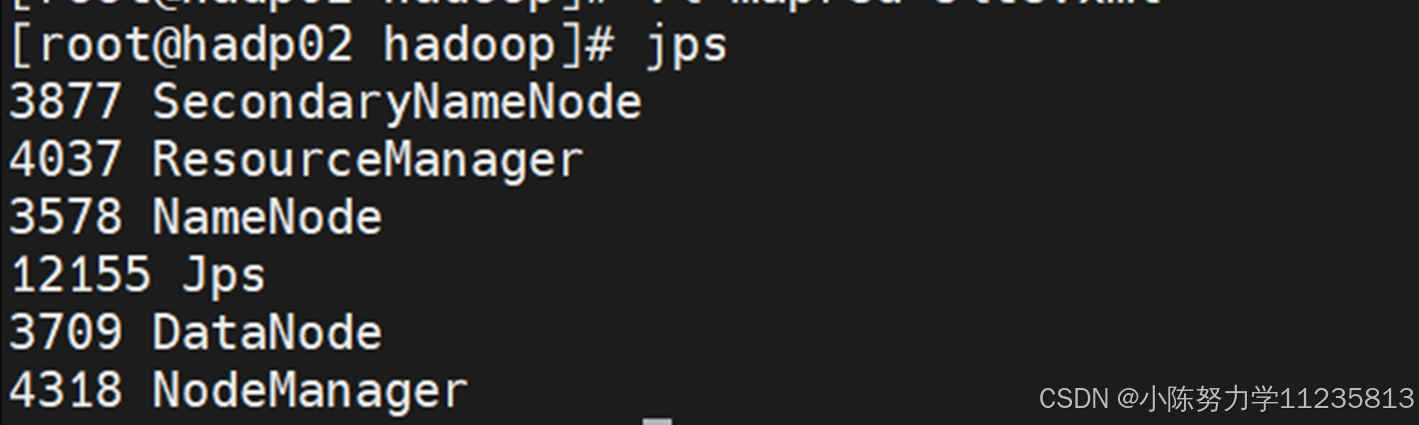
• jps显示当前所有java进程pid,查看Hadoop是否启动成功(NameNode,SecondaryNameNode,DataNode,ResouceManager,NodeManager)
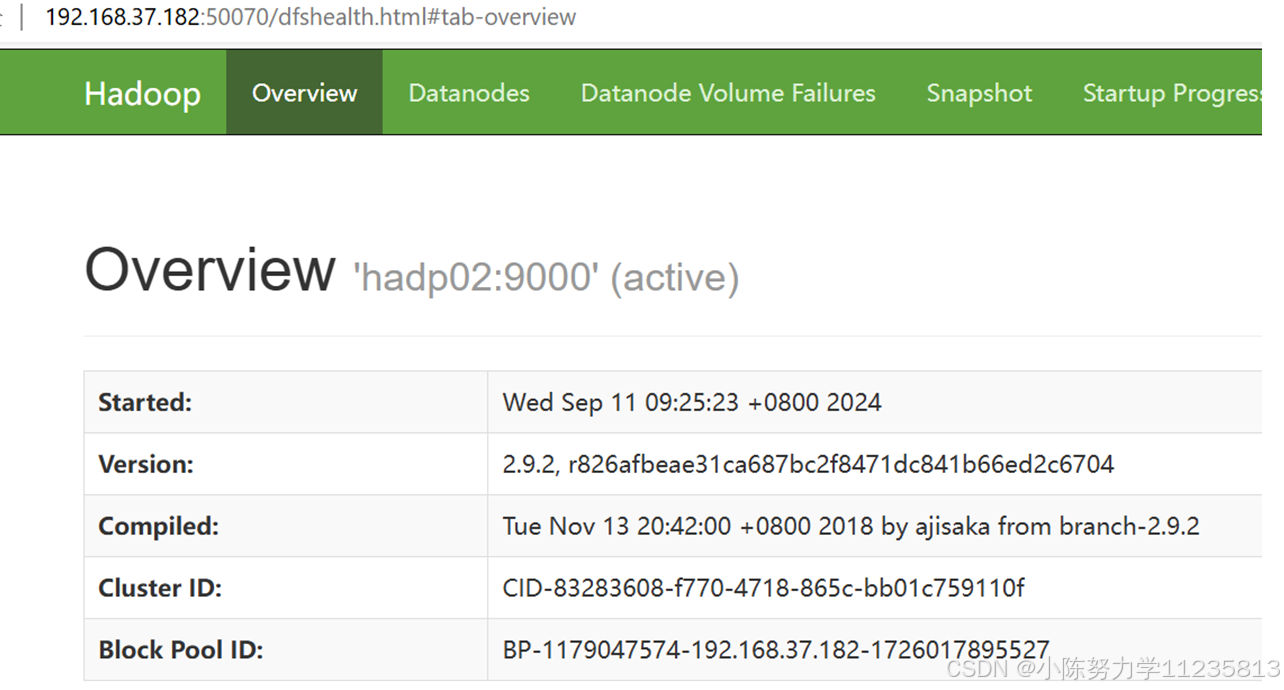
• 在Windows中启动浏览器查看运行情况(推荐使用Google Chrome浏览器)
o HDFS的Web页面:192.168.37.182:50070
o YARN的Web页面:192.168.37.182:8088

3. 安装Hbase
3.1 准备安装文档。
• 在Windows中下载HBase,下载链接:https://archive.apache.org/dist/hbase/2.2.6/hbase-2.2.6-bin.tar.gz
• 利用MobaXterm,将Windows中保存的hbase-2.2.6-bin.tar.gz拷贝到hadp02虚拟机,存储位置:/home/root/
• 在hadp01中切换到HBase安装文件所在目录:cd /home/root
• 解压缩到apps目录中:tar -xzvf hbase-2.2.6-bin.tar.gz -C apps
3.2配置环境变量
• 编辑/etc/profile文件,vi /etc/profile,,在文件末尾增加内容如下:

• 并使修改的profile文件生效:source /etc/profile
3.3修改Hbase配置文件
• 切换到配置文件目录:cd /home/root/apps/hbase-2.2.6/conf
• 编辑hbase-env.sh文件:vi hbase-env.sh
o 配置JAVA_HOME,HBASE_MANAGES_ZK
o 找到# export JAVA_HOME=/usr/java/jdk1.6.0/,修改为export JAVA_HOME=/home/root/apps/jdk1.8.0_201(注意:要去掉最前面的#)

o 找到如下代码
xml
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# export HBASE_MANAGES_ZK=true去掉export前面的#,修改效果如下:
xml
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=true• 编辑hbase-site.xml文件:vi hbase-site.xml
o 修改第一项hbase.cluster.distributed的value值为true,并添加部分内容,修改后文件如下:

• 编辑regionservers文件:vi regionservers,删除原有内容localhost,修改内容为:

3.4启动hbase。
• 启动hdfs集群

• 启动hbase
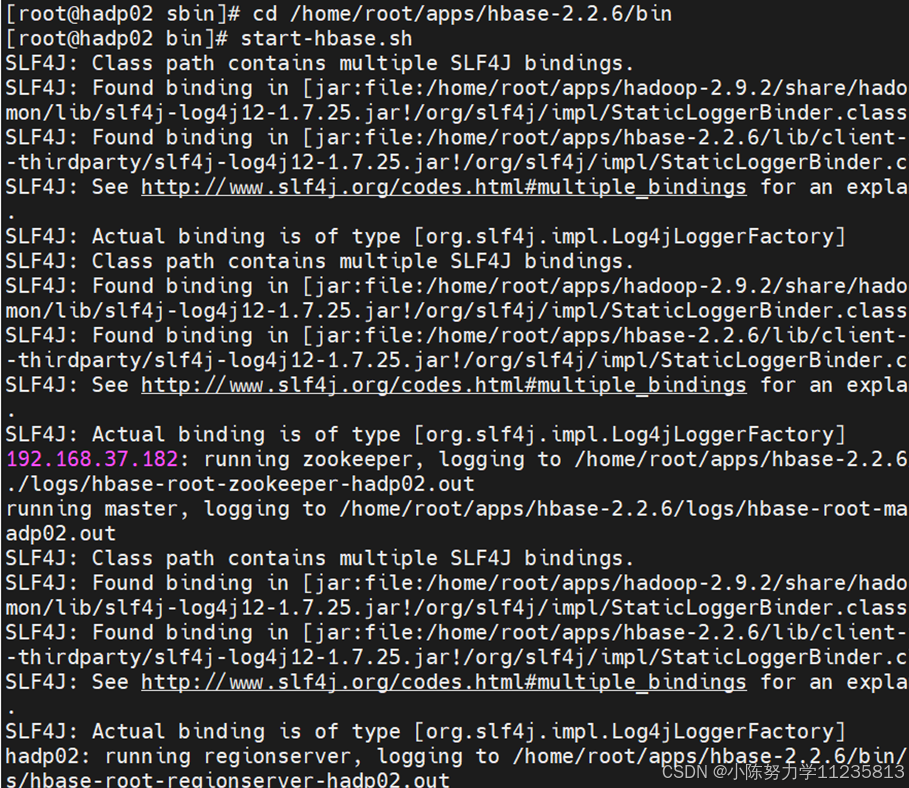
• 检查启动状态。
o 输入jps,查看进程中是否包含HMaster、HRegionServer、HQuorumPeer
o 在Windows环境下,启动Chrome浏览器,输入:192.168.37.182:16010


• 命令行形式操作hbase。

4.总结
这个搭建过程主要是CentOS上成功完成了Hadoop和HBase的伪分布式安装。主要包括环境配置、Hadoop与HBase的安装、配置与测试。
如果对您有帮助,希望您能给我点个赞~!
5.参考资料
(1)HBase基础知识
https://www.cnblogs.com/boanxin/p/10407778.html
https://blog.csdn.net/qq_1018944104/article/details/85013790?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param
(2)搭建5个节点的hadoop集群环境(CDH5)
https://blog.csdn.net/u010270403/article/details/51446674
(3)HBase完全分布式集群环境搭建过程总结
https://blog.csdn.net/qq_38586378/article/details/81352358
附选:
Oracle的安装与卸载
目的与要求
掌握Oracle 10g数据库服务器的安装与配置
掌握Oracle 10g数据库服务器安装过程中问题的解决