引言
今天带来一篇RAG微调的论文笔记------RA-DIT: RETRIEVAL-AUGMENTED DUAL INSTRUCTION TUNING。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
我们引入了检索增强双指令微调(Retrieval-Agumented Dual Instruction Tuning,RA-DIT):(1)更新预训练的LM以更好地利用检索到的信息; (2) 更新检索器以返回LM所偏好更相关的结果。通过在需要知识利用和上下文感知的任务上进行微调。
1. 总体介绍
现有的RALM(Retrival-Augumented Language Modeling)架构侧重于两个挑战: (i) 增强LLM结合检索知识的能力 (ii) 改进检索组件以返回更相关的内容。
在这项工作中,我们展示了轻量级指令微调本身就能显著提升RALM的性能。提出了RA-DIT,通过在一组任务上进行微调来为任何LLM装备检索能力的方法,这些任务用于训练语言模型预测中的知识利用和上下文感知。使用预训练的LLAMA和最先进的基于双编码器的密集检索器DRAGON+初始化框架。

图 1:RA-DIT 方法分别微调 LLM 和检索器。对于给定示例,LM-ft 组件更新 LLM 以最大化给定检索增强指令的正确答案的可能性;R-ft 组件更新检索器以最小化检索器得分分布与 LLM 偏好之间的 KL 散度。
分两个步骤进行指令微调。对于语言模型微调(LM-ft),采用标签损失目标,并在每个微调提示中添加一个检索到的背景字段。该字段至于指令之前。通过在微调过程中加入背景文本,引导LLM最佳地利用检索到的信息并忽略干扰内容。
对于检索微调(R-ft),使用一个基于监督任务和无监督文本完成的组合计算广义LM监督搜索训练目标来更新查询编码器。使检索器能生成与LLM偏好一致的、更具上下文相关的内容。
2. 方法
2.1 架构
语言模型 检索增强型预训练自回归语言模型。特别是,使用LLAMA;
检索器 采用基于双编码器的检索器架构。给定一个语料库 C \mathcal C C和一个查询 q q q,文档编码器将每个文本片段 c ∈ C c \in \mathcal C c∈C映射到一个嵌入 E d ( c ) E_d(c) Ed(c),而查询编码器将 q q q映射到一个嵌入 E q ( q ) E_q(q) Eq(q)。基于查询-文档嵌入相似度检索 q q q中排名前k的相关文本片段,相似度通过点积计算:
s ( q , c ) = E q ( q ) ⋅ E d ( c ) (1) s(q,c) = E_q(q) \cdot E_d(c) \tag 1 s(q,c)=Eq(q)⋅Ed(c)(1)
使用DRAGON +初始化检索器。
并行上下文检索增强 对于给定的语言模型提示 x x x,检索出排名靠前的k个相关文本片段 C ′ ⊂ C , ∣ C ′ ∣ = k \mathcal C^\prime \subset \mathcal C, |\mathcal C^\prime| = k C′⊂C,∣C′∣=k。为了保持上下文窗口大小限制,每个检索到的片段都预先添加到提示中,并且对来自多个增强提示的语言模型预测执行并行计算。最终输出概率是每个增强提示的概率混合,并根据片段相关性得分进行加权。
p L M ( y ∣ x , C ′ ) = ∑ c ∈ C ′ p L M ( y ∣ c ∘ x ) ⋅ p R ( c ∣ x ) (2) p_{LM} (y|x,\mathcal C^\prime) = \sum_{c \in \mathcal C^\prime} p_{LM}(y|c \,\circ\, x) \cdot p_R(c|x) \tag 2 pLM(y∣x,C′)=c∈C′∑pLM(y∣c∘x)⋅pR(c∣x)(2)
其中 ∘ \circ ∘表示序列拼接; p R ( c ∣ x ) = exp s ( x , c ) ∑ c ′ ∈ C ′ exp s ( x , c ′ ) p_R(c|x) = \frac{\exp s(x,c)}{\sum_{c^\prime \in \mathcal C^\prime} \exp s(x,c^\prime)} pR(c∣x)=∑c′∈C′exps(x,c′)exps(x,c) 是在top-k相关片段中重新归一化的检索分数。
使用一对起始(
Background)和结束(\n\n)标记来划定增强提示中的检索段。
2.2 微调数据集
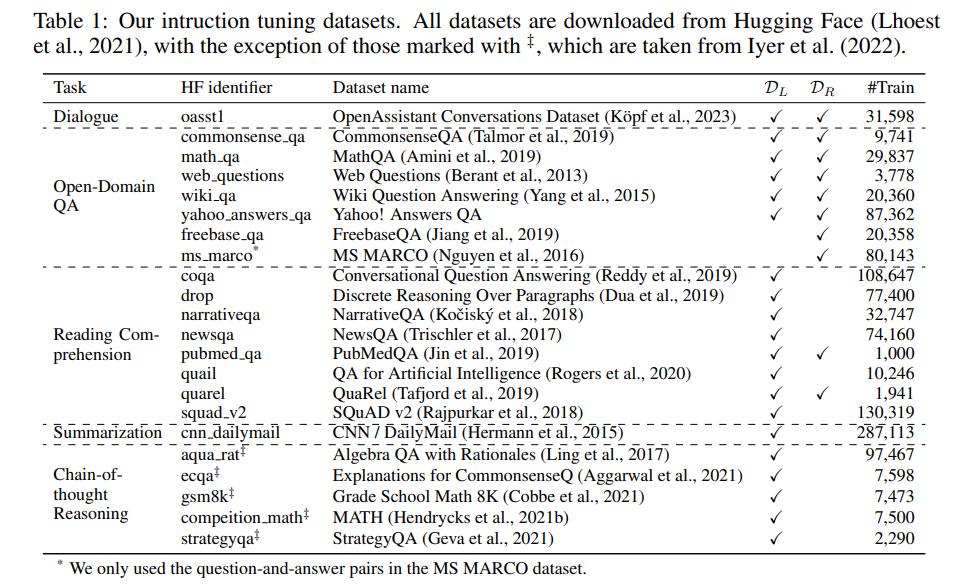
语言模型微调数据集( D L \mathcal D_L DL)包含20个数据集。每个数据集的示例使用手动编译的模板进行序列化。
2.3 检索增强语言模型微调
将每个微调序列分词一个指令段( x x x)和一个输出段( y y y)。对于每个示例 ( x i , y i ) ∈ D L (x_i,y_i) \in \mathcal D_L (xi,yi)∈DL,根据 x i x_i xi检索 top- k ~ \text{top-}\tilde k top-k~相关的文本片段 C i ⊂ C \mathcal C_i \subset \mathcal C Ci⊂C。对于每个检索到的片段 c i j ∈ C i c_{ij} \in \mathcal C_i cij∈Ci,通过将其作为背景字段添加到指令前面,创建一个单独的微调示例,从而为每个原始示例生成 k ~ \tilde k k~个独立的微调示例: { ( c i j ∘ x i , y i ∣ j = 1 , ⋯ , k ~ } \{(c_{ij} \circ x_i,y_i| j=1,\cdots,\tilde k\} {(cij∘xi,yi∣j=1,⋯,k~}。
使用下一词预测目标对语言模型进行微调,最小化每个实例输出段中词的损失:
L ( D L ) = − ∑ i ∑ j log p L M ( y i ∣ c i j ∘ x i ) (3) \mathcal L(\mathcal D_L) = -\sum_i \sum_j \log p_{LM}(y_i|c_{ij}\circ x_i) \tag 3 L(DL)=−i∑j∑logpLM(yi∣cij∘xi)(3)
在微调过程中集成上下文检索增强带来了双重益处。首先,它使 LLM 能够更好地利用相关背景知识进行预测。其次,即使是最先进的检索器也可能出错并返回不准确的结果。通过训练 LLM 在给出错误检索片段时做出正确预测,我们使 LLM 能够忽略误导性的检索内容,并在这种情况下依赖其参数化知识。
2.4 检索器微调
采用了一种广义的LSR((LM-Supervised Retrieval)训练方法,利用语言模型本身为检索器微调提供检索。
对于检索微调数据集 D R \mathcal D_R DR中的训练样本 ( x , y ) (x,y) (x,y),我们定义检索到的片段 c c c的LSR分数如下:
p L S R ( c ∣ x , y ) = exp ( p L M ( y ∣ c ∘ x ) / τ ) ∑ c ′ ∈ C exp ( p L M ( y ∣ c ′ ∘ x ) / τ ) ≈ exp ( p L M ( y ∣ c ∘ x ) / τ ) ∑ c ′ ∈ C ′ exp ( p L M ( y ∣ c ′ ∘ x ) / τ ) (4) p_{LSR}(c|x,y) = \frac{\exp(p_{LM}(y|c\circ x)/\tau)}{\sum_{c^\prime \in \mathcal C} \exp(p_{LM}(y|c^\prime \circ x)/\tau)} \approx \frac{\exp(p_{LM}(y|c\circ x)/\tau)}{\sum_{c^\prime \in \mathcal C^\prime} \exp(p_{LM}(y|c^\prime \circ x)/\tau)} \tag 4 pLSR(c∣x,y)=∑c′∈Cexp(pLM(y∣c′∘x)/τ)exp(pLM(y∣c∘x)/τ)≈∑c′∈C′exp(pLM(y∣c′∘x)/τ)exp(pLM(y∣c∘x)/τ)(4)
其中 τ \tau τ是一个温度参数; C ′ ∈ C \mathcal C^\prime \in \mathcal C C′∈C表示 x x x的top-k检索片段。更高的LSR分数表明 c c c在提高语言模型预测正确答案的概率方面更有效。LSR训练的目标是让检索器为能够提高LLM生成正确答案的可能性更高的片段分配更高的分数。
为了实现这一点,我们最小化了 p L S R p_{LSR} pLSR与公式2中定义的检索器分数 p R p_R pR之间的KL散度:
L ( D R ) = E ( x , y ) ∈ D R K L ( p R ( c ∣ x ) ∣ ∣ p L S R ( c ∣ x , y ) ) ) (5) \mathcal L(\mathcal D_R) = \Bbb E_{(x,y) \in \mathcal D_R} KL(p_R(c|x) \,||\, p_{LSR}(c|x,y) )) \tag 5 L(DR)=E(x,y)∈DRKL(pR(c∣x)∣∣pLSR(c∣x,y)))(5)
在实践中,只更新检索器的查询编码器,因为微调两个编码器会损害性能。
结论
本文提出了一种轻量级的检索增强双指令微调框架 RA-DIT,它可以有效地为任何预训练的 LLM 添加检索能力。RA-DIT 通过检索增强指令微调更新 LLM,以更好地利用检索到的知识并忽略无关或干扰信息。它还通过来自 LLM 的监督对检索器进行微调,以检索能够更好地帮助 LLM 生成正确输出的文本。
总结
⭐ 作者提出了一种检索增强微调的方法,为语言模型和检索器进行微调。引导LLM最佳地利用检索到的信息并忽略干扰内容。