一、模型介绍
Video-Infinity是一个先进的视频生成模型,使用多个 GPU 快速生成长视频,无需额外训练。它能够基于用户提供的文本或图片提示,创造出高质量、多样化的视频内容。
二、模型搭建流程
1.大模型 Video-Infinity 一键使用
基础环境最低要求说明:
| 环境名称 | 版本信息1 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.1.105 |
| Python | 3.10.14 |
| NVIDIA Corporation | RTX 3060 |
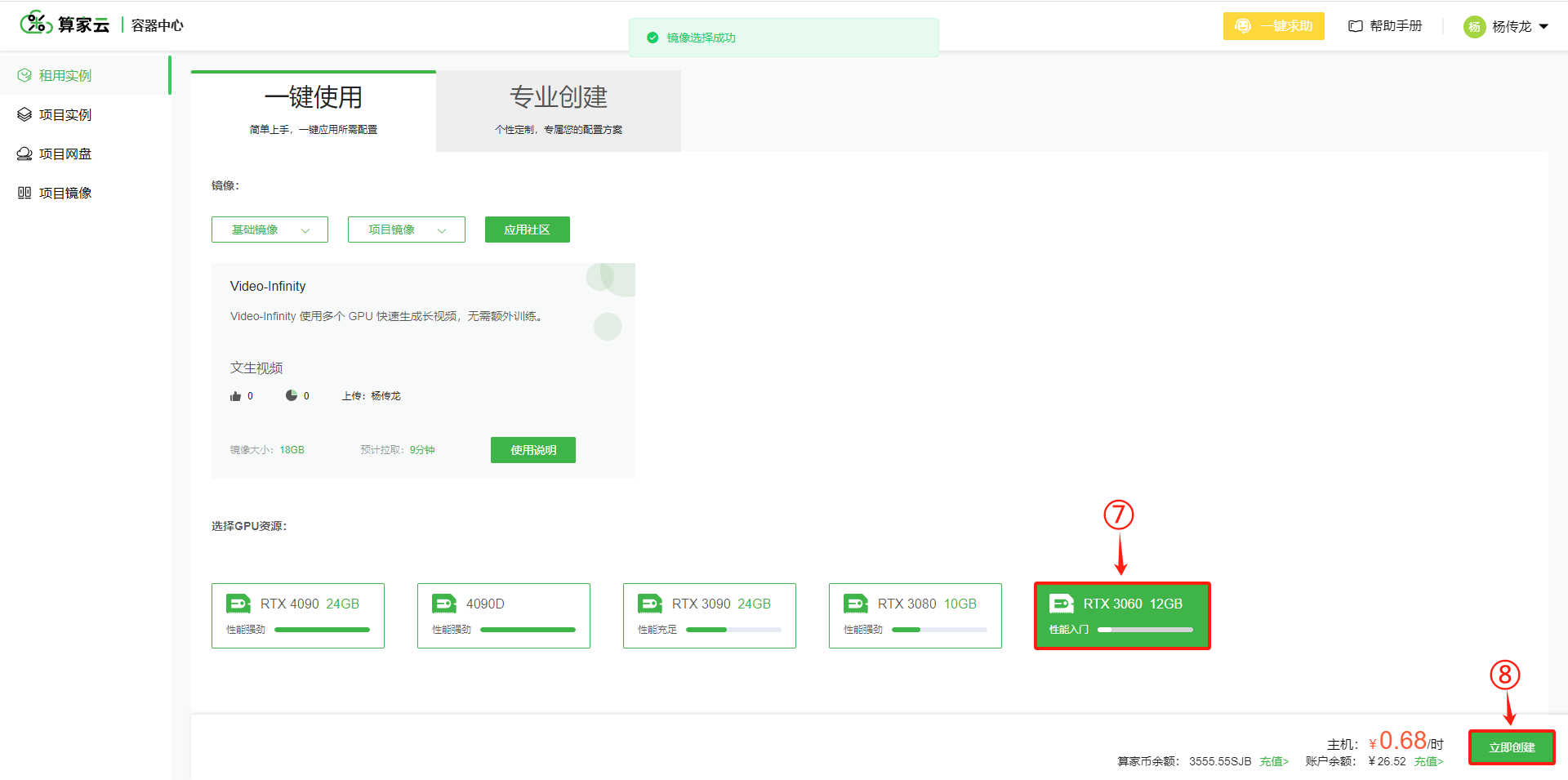
根据需求选择主机和镜像,一键创建实例
- 在租用实例页面,通过一键使用进入应用社区

- 搜索并选择 Video-Infinity 大模型
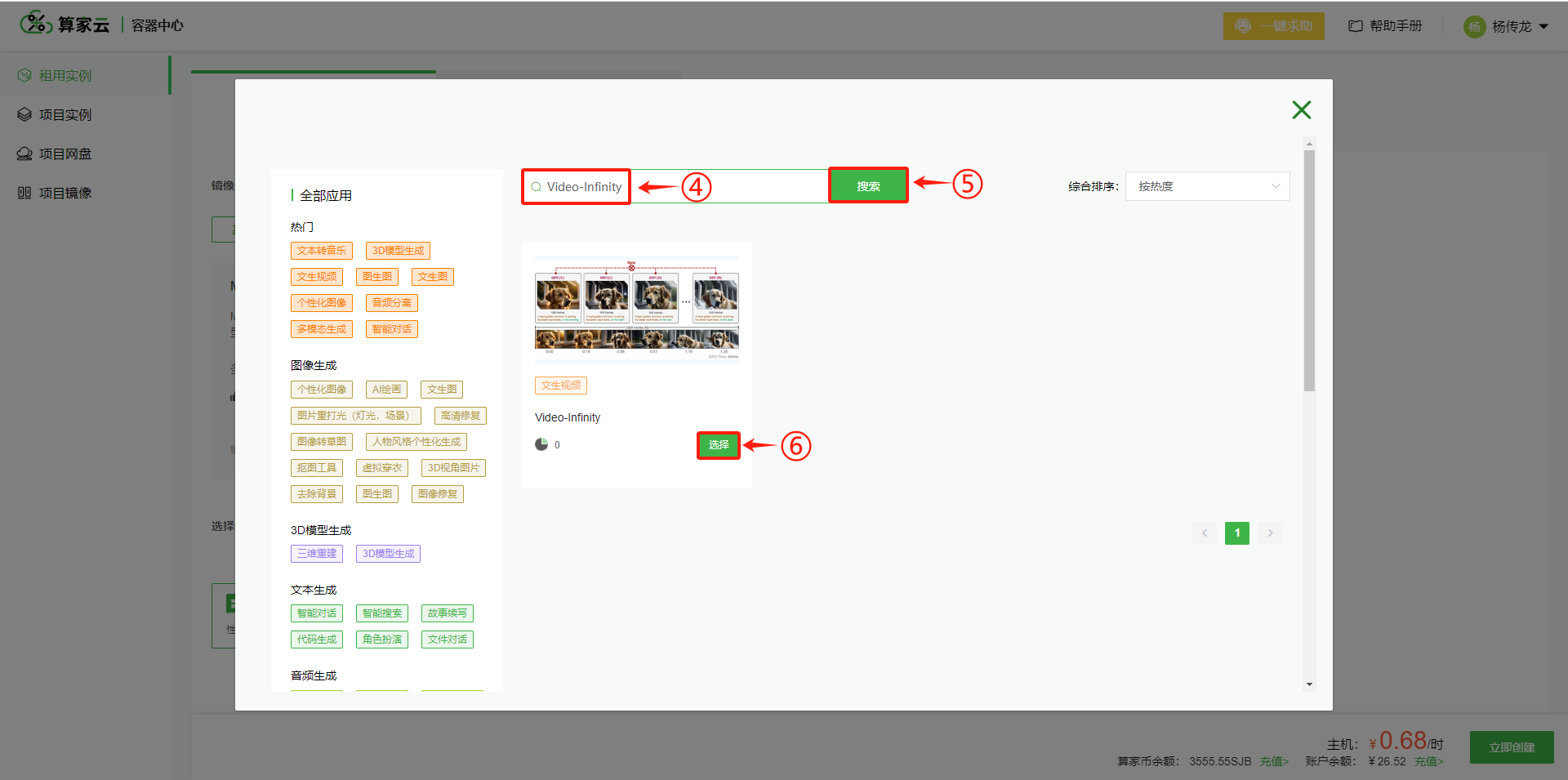
- 选择 RTX 3060 GPU,进行创建实例
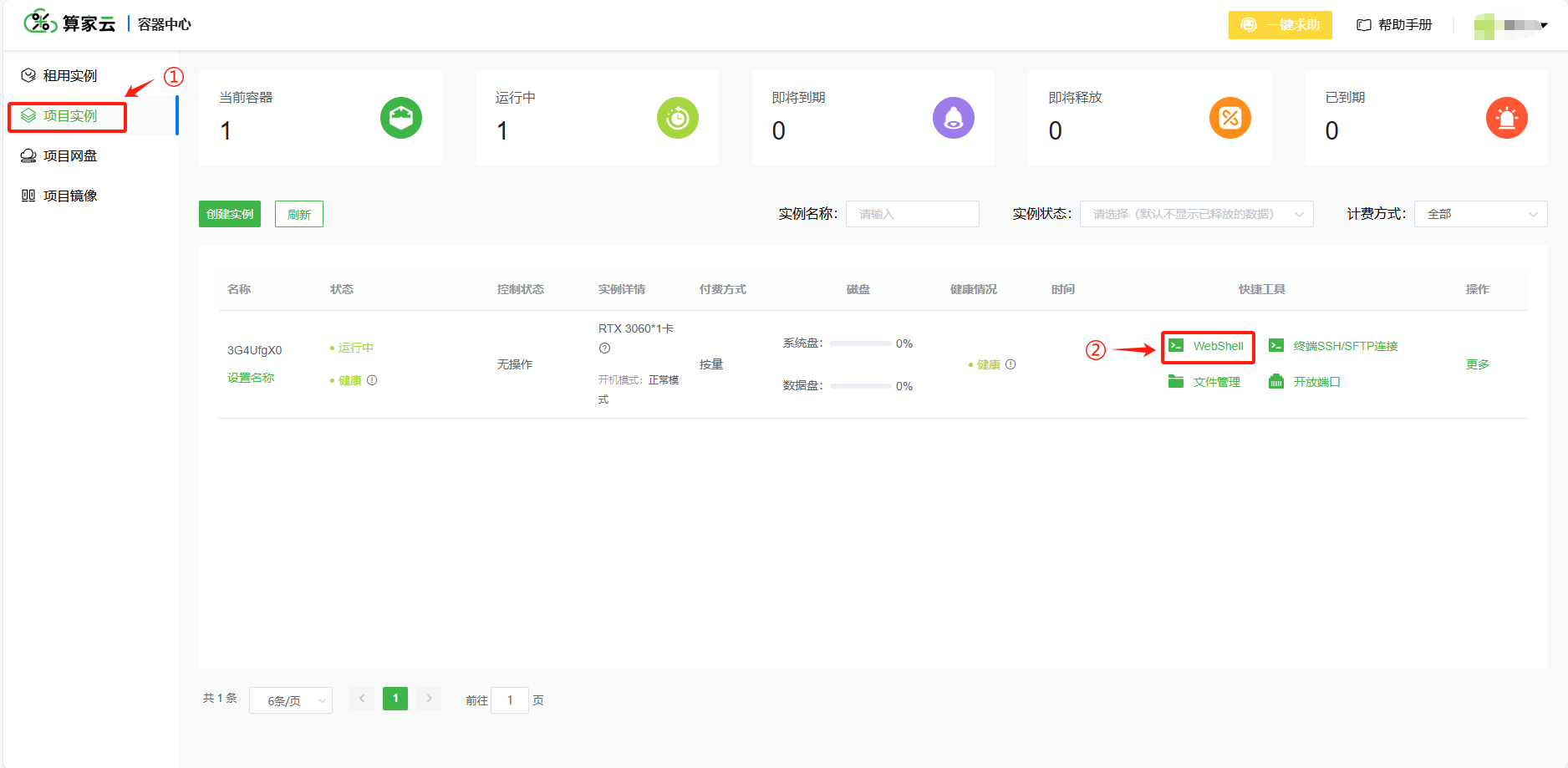
2. 进入网页端命令行
- 在"项目实例"页面点击对应实例的"WebShell",进入终端操作页面
- 进入 WebShell 页面,运行后续的功能代码
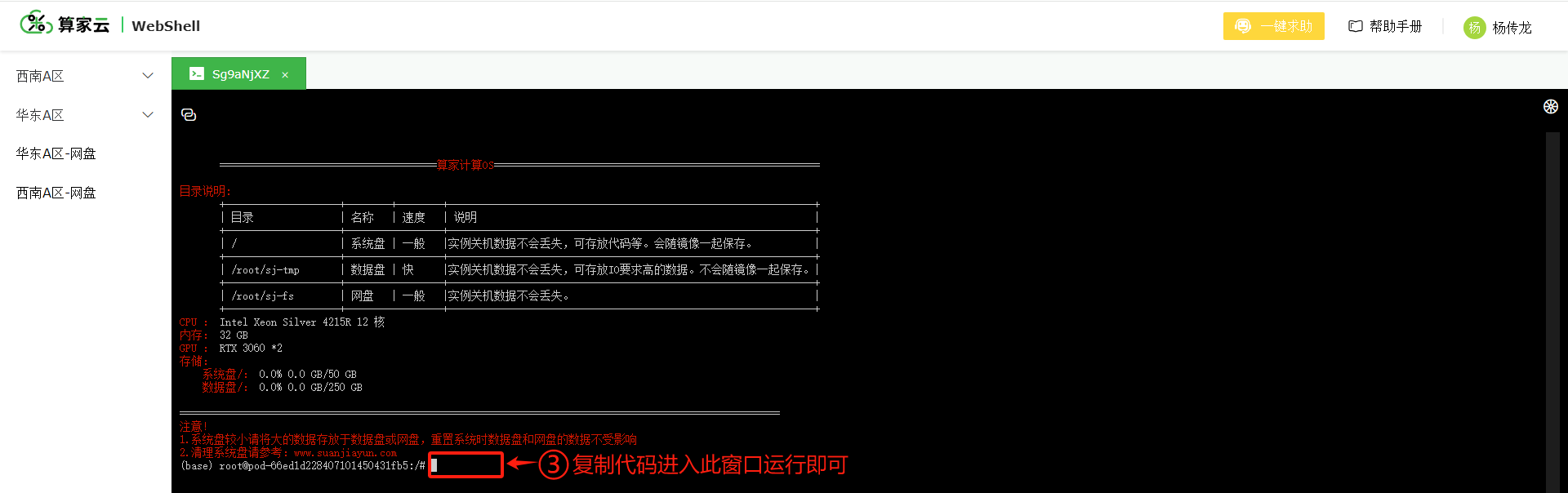
3. 启动 inference.py 文件(此模型没有页面,只能使用命令进行操作)
# 切换到项目工作目录
cd Video-Infinity
# 激活 video_infinity_vc2 虚拟环境
conda activate video_infinity_vc2
# 运行 inference.py 文件
python inference.py --config examples/single_gpu.json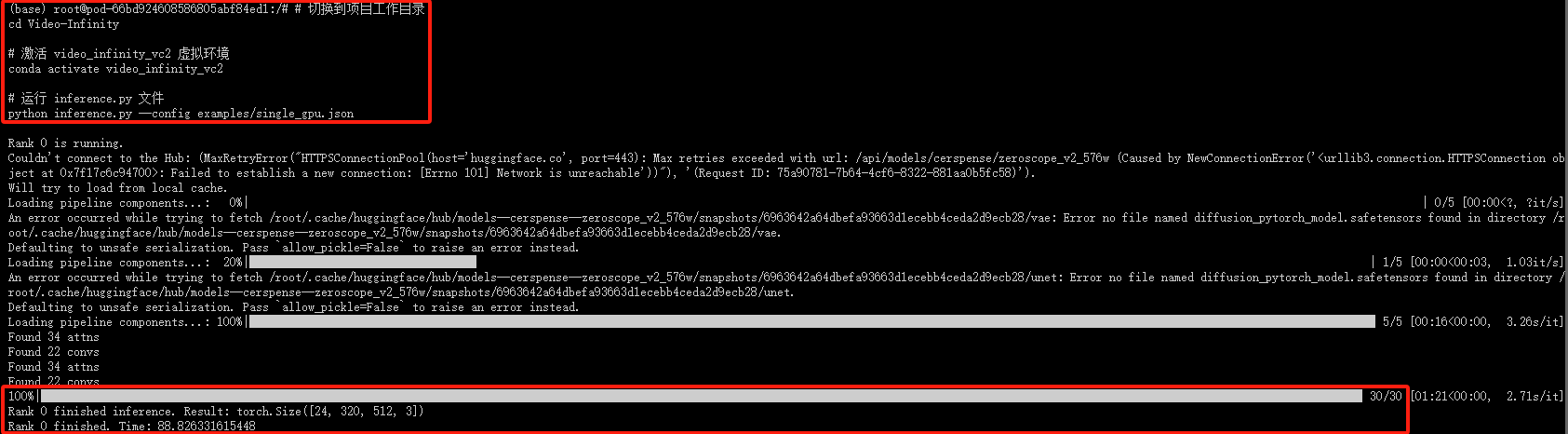
以上进度条全部运行完成,即是代表视频已经生成成功。
以上就是在算家云搭建 Video-Infinity 的流程,具体使用方式可进入算家云应用社区查看该模型的使用说明。
点击应用社区(www.suanjiayun.com/mirror) ,选择模型,一键开启 AI 之旅!
