C++ | STL | 侯捷 | 学习笔记
文章目录
- [C++ | STL | 侯捷 | 学习笔记](#C++ | STL | 侯捷 | 学习笔记)
-
-
- [1 STL概述](#1 STL概述)
-
- [1.1 头文件名称](#1.1 头文件名称)
- [1.2 STL基础介绍](#1.2 STL基础介绍)
- [1.3 typename](#1.3 typename)
- [2 OOP vs. GP](#2 OOP vs. GP)
- [3 容器](#3 容器)
-
- [3.1 容器结构分类](#3.1 容器结构分类)
- [3.2 序列式容器](#3.2 序列式容器)
- [3.3 关联式容器](#3.3 关联式容器)
- [4 分配器](#4 分配器)
-
- [4.1 测试](#4.1 测试)
- [4.2 源码解析](#4.2 源码解析)
- [5 迭代器](#5 迭代器)
-
- [5.1 迭代器的设计准则](#5.1 迭代器的设计准则)
- [5.2 迭代器的分类](#5.2 迭代器的分类)
- 5.3迭代器对算法的影响
- [6 算法](#6 算法)
-
- [6.1 算法源码](#6.1 算法源码)
-
- [6.1.1 accumulate](#6.1.1 accumulate)
- [6.1.2 for_each](#6.1.2 for_each)
- [6.1.3 replace...](#6.1.3 replace…)
- [6.1.4 count...](#6.1.4 count…)
- [6.1 5 find...](#6.1 5 find…)
- [6.1.6 sort](#6.1.6 sort)
- [6.1.7 binary_search](#6.1.7 binary_search)
- [7 仿函数](#7 仿函数)
- [8 适配器](#8 适配器)
-
- [8.1 容器适配器](#8.1 容器适配器)
- [8.2 函数适配器](#8.2 函数适配器)
-
- [8.2.1 binder2nd](#8.2.1 binder2nd)
- [8.2.2 not1](#8.2.2 not1)
- [8.2.3 bind](#8.2.3 bind)
- [8.3 迭代器适配器](#8.3 迭代器适配器)
-
- [8.3.1 reverse_iterator](#8.3.1 reverse_iterator)
- [8.3.2 inserter](#8.3.2 inserter)
- [8.4 X适配器](#8.4 X适配器)
-
- [8.4.1 ostream_iterator](#8.4.1 ostream_iterator)
- [8.4.2 istream_iterator](#8.4.2 istream_iterator)
- [9 STL周围](#9 STL周围)
-
- [9.1 万用Hash Function](#9.1 万用Hash Function)
- [9.2 Tuple](#9.2 Tuple)
-
- [9.2.1 用例](#9.2.1 用例)
- [9.2.2 原理](#9.2.2 原理)
- [9.3 type traits](#9.3 type traits)
-
- [9.3.1 用例](#9.3.1 用例)
- [9.3.2 原理](#9.3.2 原理)
- [9.4 move](#9.4 move)
-
1 STL概述
STL ------ Standard Template Library,标准模板库
C++ Standard LIbrary,C++标准库中包含STL(即STL+一些小东西)
1.1 头文件名称
- C++标准库的 header files 不带
.h,例如:#include<vector> - 新式 C header files 不带
.h,例如:#include<cstdio> - 老式 C header files 带
.h仍然可用,例如:#include<stdio.h>
新式 header 内的组件封装于 namespace std
老式 header 内的组件不 封装于 namespace std
1.2 STL基础介绍
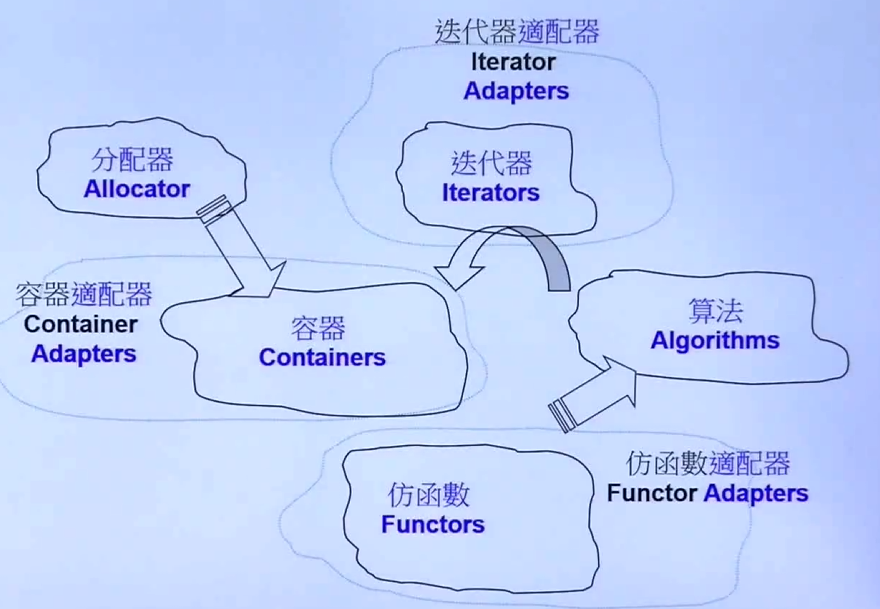
STL六大部件:容器(Containers)、分配器(Allocators)、算法(Algorithms)、迭代器(Iterators)、仿函数(Functors)、适配器(Adapters)
- 容器:放数据
- 分配器:是来支持容器将数据放到内存里
- 算法:是一个个函数来处理存放在容器里的数据
- 迭代器:就是来支持算法操作容器的
- 仿函数:作用类似函数,例如相加相减等等
- 适配器:有三种,分别将容器,迭代器,仿函数来进行一个转换
实例:
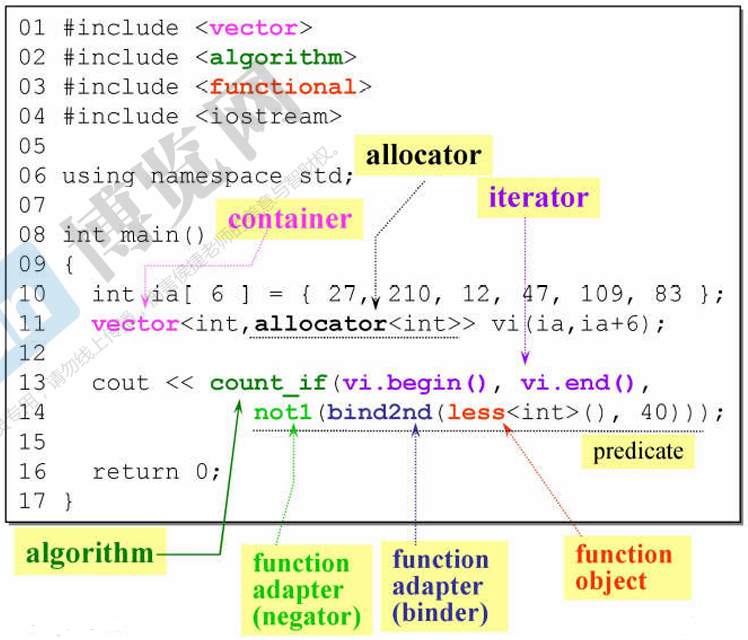
- 首先是创建一个 container(vector)
- allocator 来帮助 container 来分配内存(一般会忽略不写)
- 用一个 Algorithm 来操作数据(count_if 是数出满足条件的个数)
- iterator 就是一个泛化的指针,来告诉 Algorithm 要处理哪里的数据
- 用一个 functor 来判断数据(less 其有两个参数传入,第一个 < 第二个就为真)
- 先用一个 function adapter(bind2nd )绑定了第二个参数为 40;再用一个 function adapter(not1)来对整个判断结果进行否定
判断条件 predicate 为:not1(bind2nd(less<int>(), 40)) ------ 表示 >= 40 数为真
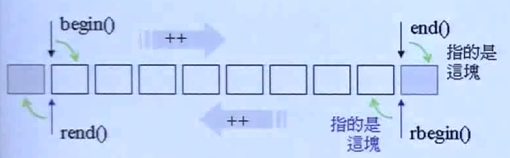
前闭后开:[ ),基本所有容器都有
begin()end(),但 begin 是指向的容器的第一个元素,而 end 是指向的容器最后一个元素的下一个例子:遍历容器
cpp... Container<T> c; Container<T>::iterator i = c.begin(); for (; i != c.end(); ++i) { ... } //但在C++11中可以用新语法简写 ... Container<T> c; for (auto elem : c) { ... }
1.3 typename
在模板参数的关键字使用中与 class 是一样的
在类型前面加上 typename:
cpp
template <typename T>
class MyTemplateClass {
public:
typedef typename T::NestedType NestedType;
};
template <typename T>
void MyTemplateFunction() {
typename T::SomeType variable;
// ...
}在这个例子中,typename 用于告诉编译器 T::NestedType 和 T::SomeType 是类型名称而不是成员变量
typename 是一个用于明确指定符号是一个类型的关键字,以帮助编译器正确解析代码并避免歧义,如果不使用 typename,编译器可能会认为符号是一个值而不是类型,导致编译错误。
2 OOP vs. GP
-
OOP ------ Object-Oriented programming 面向对象编程
将数据和操作关联到一起
例如容器 List,其自带了一个
sort(),因为链表的存储空间不是连续的,Iterator 不能实现加减操作,所以不能使用全局的::sort() -
GP ------ Generic Programming 泛式编程
将数据和操作分开
- 容器和算法的团队就可以各自闭门造车,其间通过 Iterator 联通即可
- 算法通过 Iterator 确定操作范围,并通过 Iterator 取用容器的元素
- 所有的算法,其内的最终涉及元素的操作都是比大小
3 容器
3.1 容器结构分类
分类:序列式容器 Sequence Container ,关联式容器 Associative Container
-
序列式容器:按照放入的次序进行排列
- Array 数组,固定大小
- Vector 向量,会自动扩充大小
- Deque 双向队列,双向都可以扩充
- List 链表,双向链表
- Forward-List 链表,单向链表
-
关联式容器:有 key 和 value,适合快速的查找
STL中实现使用红黑树(高度平衡二叉树)和哈希表
-
Set,key 就是 value,元素不可重复
-
Map,key 和 value 是分开的,元素不可重复
-
Multi~,元素是可以重复的
-
Unordered~,HashTable Separate Chaining
-
其中 Array ,Forward-List ,Unordered~ 都是C++11的
3.2 序列式容器
3.2.1 array
测试
cpp
#include <array>
#include <iostream>
#include <ctime>
#include <cstdlib> //qsort, bsearch, NULL
void test_array() {
cout << "\n test_array().......... \n";
// 创建一个包含long型元素的array容器,ASIZE为数组的大小
array<long, ASIZE> c;
// 记录开始时间
clock_t timeStart = clock();
// 填充数组 c 中的元素,使用 rand() 生成随机数
for (long i = 0; i < ASIZE; ++i) {
c[i] = rand();
}
// 输出填充数组所花费的毫秒数
cout << "milli-seconds : " << (clock() - timeStart) << endl;
// 输出数组的大小、第一个元素、最后一个元素、起始地址
cout << "array.size()= " << c.size() << endl;
cout << "array.front()= " << c.front() << endl;
cout << "array.back()= " << c.back() << endl;
cout << "array.data()= " << c.data() << endl;
// 获取目标值
long target = get_a_target_long();
// 记录开始时间
timeStart = clock();
// 使用标准库的 qsort 函数(快排)对数组 c 进行排序
::qsort(c.data(), ASIZE, sizeof(long), compareLongs);
// 使用标准库的 bsearch 函数(二分查找)在排序后的数组中搜索目标值
long* pItem = (long*)::bsearch(&target, c.data(), ASIZE, sizeof(long), compareLongs);
// 输出排序和搜索所花费的毫秒数
cout << "qsort()+bsearch(), milli-seconds : " << (clock() - timeStart) << endl;
// 如果找到目标值,输出该值;否则输出未找到消息
if (pItem != NULL)
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}运行结果:
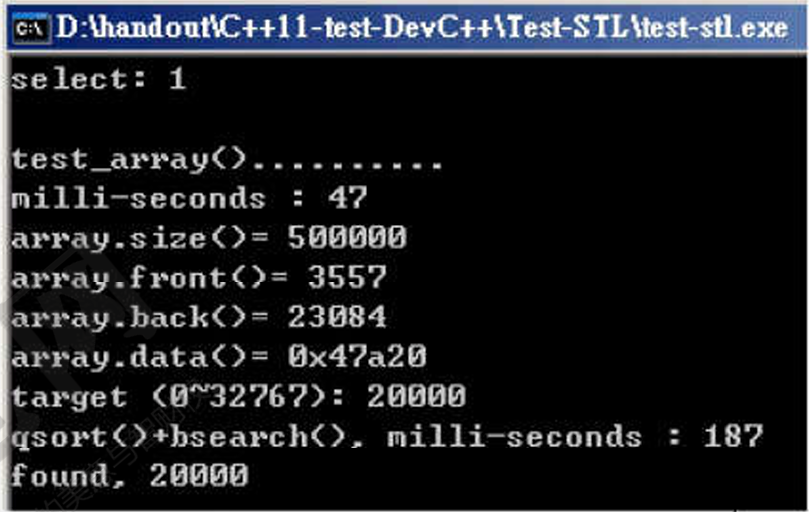
随机数据填充容器:47ms;排序和搜索:187ms
深度探索
C++TR1下(比较简单):
cpp
template <typename _Tp, std::size_t _Nm>
struct array
{
typedef _Tp value_type;
typedef _Tp* pointer;
typedef value_type* iterator; // 迭代器为_Tp*
value_type _M_instance[_Nm ? _Nm : 1]; // 如果_Nm为0,就分配一个空间
iterator begin() { return iterator(&_M_instance[0]); }
iterator end() { return iterator(&_M_instance[_Nm]); }
...
};GCC4.9下(复杂且无益处):
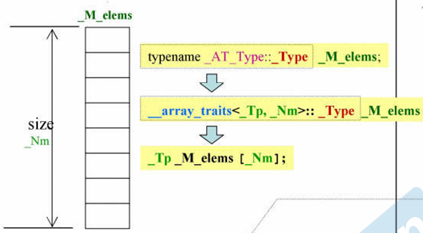
cpp
// GCC4.9通过多个typedef以下面的逻辑创建的array里的data
typedef int T[100]; // T即类型int[100]
T c; // 与int c[100]一样3.2.2 vector
测试

cpp
#include <vector>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
#include <algorithm> //sort()
// 测试函数,接受一个引用类型的长整型参数
void test_vector(long& value)
{
cout << "\ntest_vector().......... \n";
vector<string> c; // 创建一个字符串类型的向量
char buf[10];
clock_t timeStart = clock(); // 记录开始时间
for(long i=0; i< value; ++i) // 循环插入随机生成的字符串
{
try {
snprintf(buf, 10, "%d", rand()); // 将随机整数转换为字符串
c.push_back(string(buf)); // 将字符串添加到向量中
} // 这里是处理异常,如内存不够
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
// 输出出现异常的信息以及对应的索引值
// 曾經最高 i=58389486 then std::bad_alloc
abort(); // 异常处理后中止程序
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl; // 输出填充向量花费时间
cout << "vector.max_size()= " << c.max_size() << endl; // 输出向量的最大容量
cout << "vector.size()= " << c.size() << endl; // 输出向量的实际大小
cout << "vector.front()= " << c.front() << endl; // 输出向量的首元素
cout << "vector.back()= " << c.back() << endl; // 输出向量的末尾元素
cout << "vector.data()= " << c.data() << endl; // 输出向量地址
cout << "vector.capacity()= " << c.capacity() << endl << endl; // 输出向量的容量
// 直接find来查找------------次序查找
string target = get_a_target_string(); // 获取一个目标字符串
{
timeStart = clock(); // 记录开始时间
auto pItem = find(c.begin(), c.end(), target); // 在向量中查找目标字符串
cout << "std::find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl << endl; // 输出找到的目标字符串
else
cout << "not found! " << endl << endl; // 输出未找到目标字符串
}
// 先排序再二分法查找
{
timeStart = clock(); // 记录开始时间
sort(c.begin(), c.end()); // 对向量中的字符串进行排序
cout << "sort(), milli-seconds : " << (clock()-timeStart) << endl;
timeStart = clock();
string* pItem = (string*)::bsearch(&target, (c.data()),
c.size(), sizeof(string), compareStrings);
cout << "bsearch(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != NULL)
cout << "found, " << *pItem << endl << endl; // 输出在排序后向量中找到的目标字符串
else
cout << "not found! " << endl << endl; // 输出在排序后向量中未找到目标字符串
}
c.clear(); // 清空向量中的数据
test_moveable(vector<MyString>(),vector<MyStrNoMove>(), value); // 调用另一个函数进行测试
}这是 array 在后面插入元素,其中若空间 capacity 不够,其会进行两倍扩充 ------即空间不够时会将原来的空间 *2
cpp
c.push_back(string(buf));运行结果:
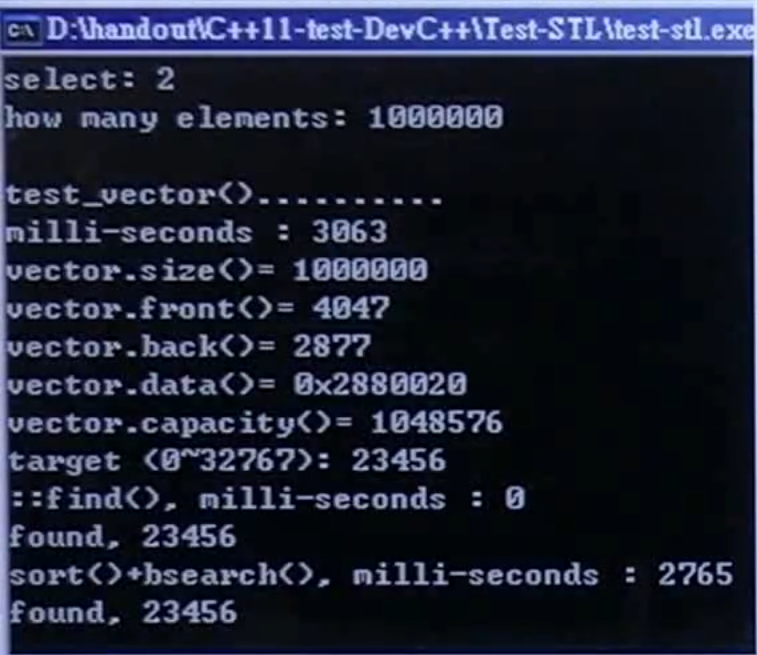
随机数据填充容器:3063ms;直接搜索:0ms(运气很好);排序后二分查找:2765ms
深度探索
GCC2.9下:
一共3个指针:start,finish,end_of_storage
所以 sizeof(vector<int>) 是12
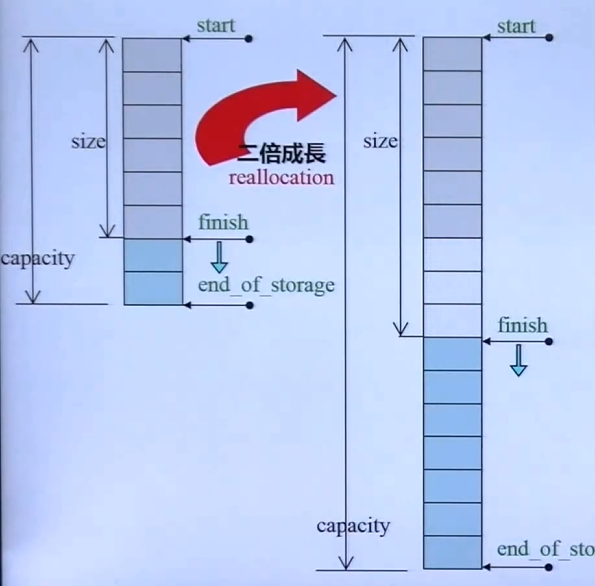
cpp
template <class T, class Alloc = alloc>
class vector
{
public:
typedef T value_type;
typedef value_type* iterator; // 迭代器就是T*
typedef value_type& reference;
typedef size_t size_type;
protected:
iterator start;
iterator finish;
iterator end_of_storage;
public:
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const { return size_type(end() - begin()); }
size_type capacity() const { return size_type(end_of_storage - begin()); }
bool empty() const { return begin() == end(); }
reference operator[](size_type n) { return *(begin() + n); }
// 所有连续储存的容器都有[]的重载
reference front() { return *begin(); }
reference back() { return *(end() - 1); }
}vector 每次成长会大量调用元素的拷贝构造函数和析构函数,是一个大成本
cpp
void push_back(const T& x)
{
if (finish != end_of_storage) // 还有备用空间
{
construct(finish, x); // 全局函数
++finish;
}
else // 无备用空间
insert_aux(end(), x);
}
template <class T, class Alloc>
void vector<T, Alloc>::insert_aux(iterator position, const T& x){
if (finish != end_of_storage){ // insert_aux还会被其他函数调用所以还有检查
// 在'备用空间起始处'构建一个元素以vector最后一个元素为初值
// insert_aux也可能被insert调用,元素插入位置不定
construct(finish, *(finish - 1));
++finish;
T x_copy = x;
copy_backward(position, finish - 2, finish - 1);
*position = x_copy;
}
else{
const size_type old_size = size();
const size_type len = old_size != 0 ? 2 * old_size : 1;
// 原大小为0,则分配1;否则,分配原大小的2倍
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
try{
// 拷贝安插点前的原内容
new_finish = uninitialized_copy(start, position, new_start);
construct(new_finish, x);
++new_finish;
// 拷贝安插点后的原内容
new_finish = uninitialized_copy(position, finish, new_finish);
}
catch (...){
destroy(new_start, new_finish);
data_allocator::deallocate(new_start, len);
throw;
}
// 解构并释放原vector
destroy(begin(), end());
deallocate();
// 调整迭代器,指向新vector
start = new_start;
finish = new_finish;
end_of_storage = new_start + len;
}GCC4.9下变得复杂:
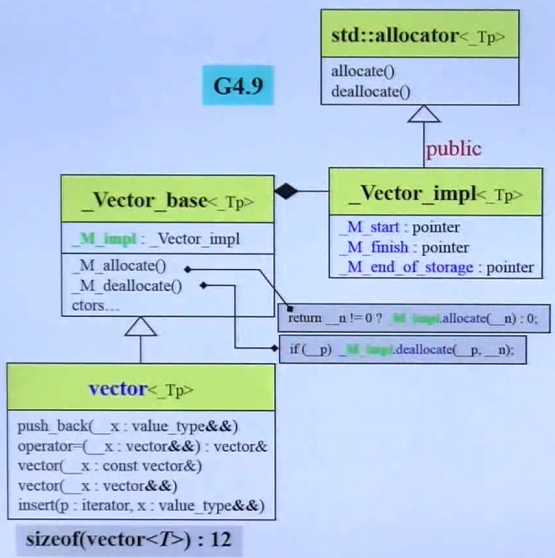
且迭代器也变得乱七八糟,舍近求远,何必如此!!
3.2.3 list
测试
cpp
// 同理
void test_list(long& value)
{
...
list<string> c; // 创建一个字符串列表
char buf[10]; // 字符串缓冲区
...
string target = get_a_target_string(); // 获取目标字符串
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); // 在列表中查找目标字符串
cout << "std::find(),milli-seconds : " << (clock()-timeStart) << endl; // 输出查找时间
...
timeStart = clock();
c.sort(); // 对列表进行排序
cout << "c.sort(), milli-seconds : " << (clock()-timeStart) << endl; // 输出排序时间
c.clear(); // 清空
}注意:
c.sort();是容器自带的排序函数,如果容器自带肯定是要比全局的排序函数好的list 同样也是用
c.push_back(string(buf));往里添加元素的
运行结果:
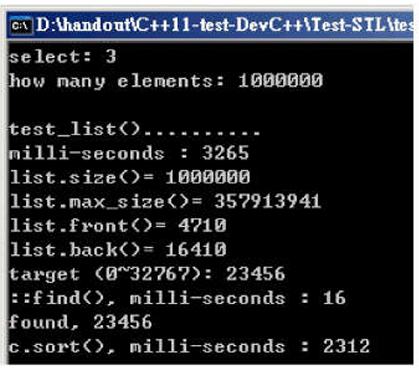
随机数据填充容器:3265ms;直接搜索:16ms;排序:2312ms
深度探索
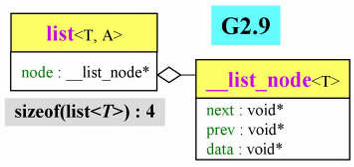
GCC2.9中
cpp
// list class
template <class T, class Alloc = alloc>
class list
{
protected:
typedef __list_node<T> list_node;
public:
typedef list_node* link_type;
typedef __list_iterator<T, T&, T*> iterator; // 迭代器,每一个容器都会 typedef
// 只传一个参数就行了 不理想
protected:
link_type node; // 一个 __list_node<T> 的指针
...
};
// 节点 class
template <class T>
struct __list_node
{
typedef void* void_pointer; // 每次用还要转换类型 不理想
void_pointer prev;
void_pointer next;
T data;
};除了 array,vector 这样是连续存储的容器,其他容器的 iterator 都是智能指针,其有大量的操作符重载 ------ 模拟指针
基本上所有的 iterator 都有下面5 个 typedef 和一大堆操作符重载
cpp
// iterator class
template <class T, class Ref, class Ptr>
struct __list_iterator
{
typedef __list_iterator<T, T&, T*> self;
typedef bidirectional_iterator_tag iterator_category; // (1)双向迭代器
typedef T value_type; // (2)迭代器所指对象的类型
typedef Ptr pointer; // (3)迭代器所指对象的指针类型
typedef Ref reference; // (4)迭代器所指对象的引用类型
typedef __list_node<T>* link_type;
typedef ptrdiff_t difference_type; // (5)两个迭代器之间的距离类型
link_type node; // iterator本体,一个指向__list_node<T>的指针
reference operator*() const { return (*node).data; }
pointer operator->() const { return &(operator*()); }
self& operator++() // ++i
{
node = (link_type)((*node).next); // 移到下一个节点
return *this;
}
self operator++(int) // i++ 为了区分加上了一个参数其实无用
{
self tmp = *this;
++*this;
return tmp;
}
...
};注意:self operator++(int){...} 的 self tmp = *this; 中,由于先调用了 = 唤起了 copy ctor 用以创建 tmp 并以 *this 为初值,所以不会唤起 operator* ------ *this 已经被解释为 ctor 的参数
下面的 ++*this; 同理
与 int 类似:iterator 可以连续前++,但不能连续后++
所以前++是返回引用,后++返回值


因为要符合前闭后开原则,所以在 list 尾端加上了一个空白节点
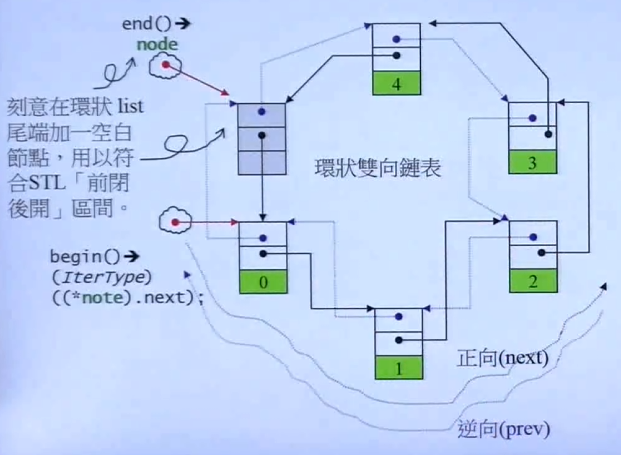
GCC4.9中做出了改进:
- 迭代器模板参数从三个 --> 只有一个
- 节点 class 中的前后指针类型从
void*-->_LIst_node_base*
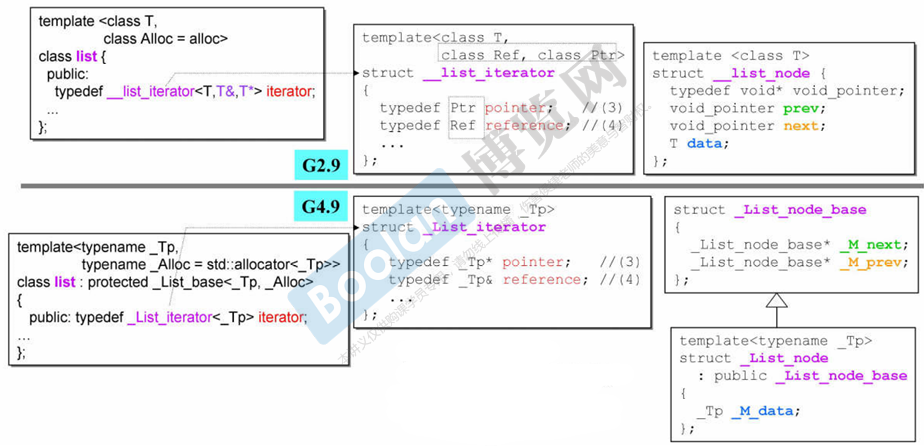
在GCC4.9中 sizeof(list<int>) 是 8
在GCC2.9中 sizeof(list<int>) 是 4
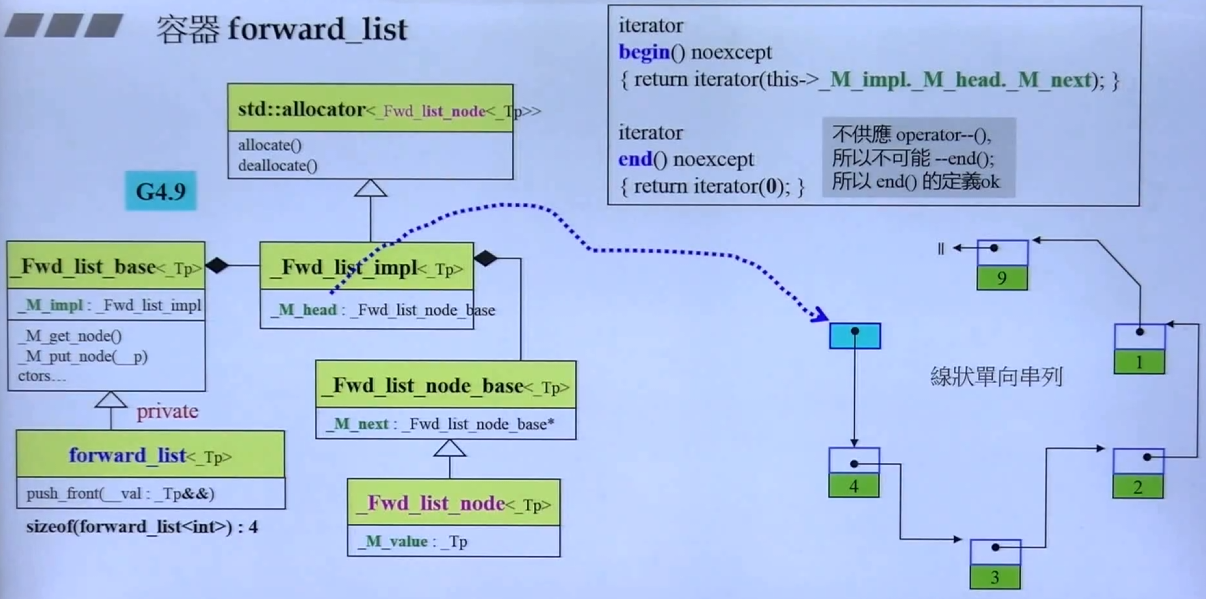
3.2.4 forward_list
测试

cpp
// 同理
void test_forward_list(long& value)
{
...
forward_list<string> c; // 创建一个前向列表
char buf[10]; // 字符串缓冲区
...
string target = get_a_target_string(); // 获取目标字符串
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); // 在前向列表中查找目标字符串
cout << "std::find(),milli-seconds : " << (clock()-timeStart) << endl; // 输出查找时间
...
timeStart = clock();
c.sort(); // 进行排序
cout << "c.sort(), milli-seconds : " << (clock()-timeStart) << endl; // 输出排序时间
c.clear(); // 清空
}注意:forward_list 只有
c.push_front();且没有forward_list.back()forward_list.size()
运行结果:
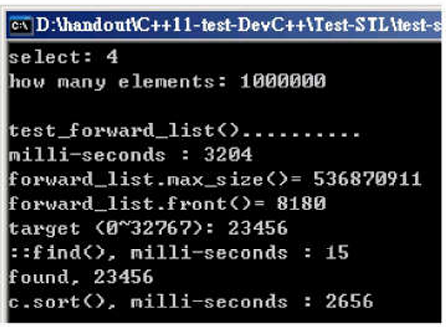
随机数据填充容器:3204ms;直接搜索:15ms;排序:2656ms
深度探索
与 list 相似,略
3.2.6 deque
测试

类似vector,两边都能扩充,实际上是分段连续的
其是通过 map (是一个vector,但在扩充时会 copy 到中间)里的指针指向各个 buffer ,buffer 里再存数据,每个 buffer 的大小一致,每次扩充都是扩充一个指针指向一个新的 buffer
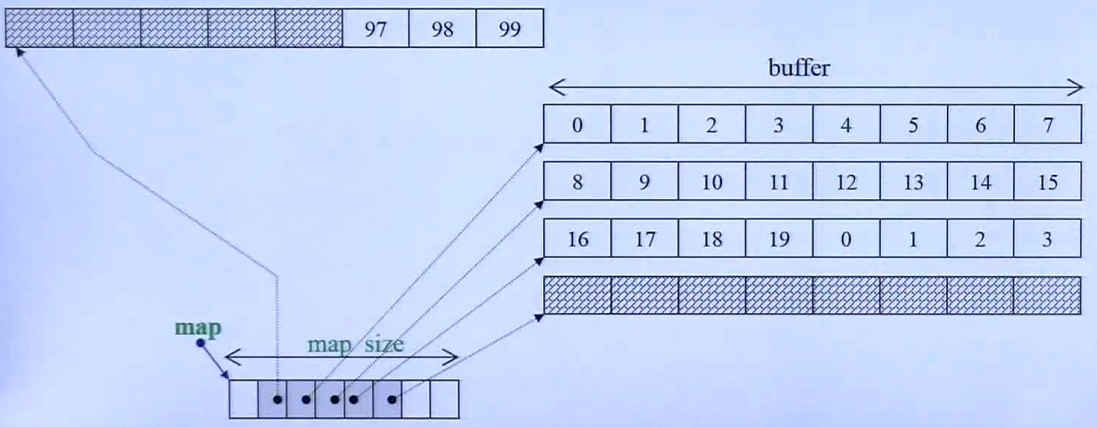
map其实是vector,它扩充的时候会增长为原来的2倍,移动原数据到新内存空间的时候,它会放到新内存空间的中间,方便扩充
比如:原来大小为8,扩充为16,那原来这8个放在 5-12这个位置,前面和留后面留着扩充
cpp
void test_deque(long& value)
{
...
deque<string> c; // 创建一个双端队列
char buf[10]; // 字符串缓冲区
...
string target = get_a_target_string(); // 获取目标字符串
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); // 在队列中查找目标字符串
cout << "std::find(),milli-seconds : " << (clock()-timeStart) << endl; // 输出查找时间
...
timeStart = clock();
sort(c.begin(), c.end()); // 对队列进行排序
cout << "sort(),milli-seconds : " << (clock()-timeStart) << endl; // 输出排序时间
c.clear(); // 清空队列
}运行结果:
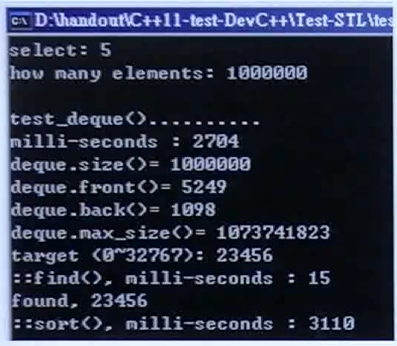
随机数据填充容器:2704ms;直接搜索:15ms;排序:3110ms
下面的 stack 和 queue 内部都是一个 deque ,所以技术上这两个可以看作容器适配器 Container Adapter
深度探索
GCC2.9下
cpp
template <class T, class Alloc = alloc, size_t BufSiz = 0>
class deque
{
public:
typedef T value_type;
typedef __deque_iterator<T, T&, T*, BufSiz> iterator;
typedef size_t size_type;
typedef T* pointer;
protected:
typedef pointer* map_pointer; // T** 指向指针的指针
protected:
iterator start;
iterator finish;
map_pointer map;
size_type map_size;
// 两个迭代器:16*2,一个指针:4,一个size_t:4,一共40字节
public:
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const { return finish - start; }
...
};注意:第三个模板参数
size_t BufSiz = 0有一个函数:如果不为0,则 buffer size 就是传入的数据
如果为0,表示预设值,那么
如果
sz = sizeof(value_type)< 512,传回512/sz如果
sz = sizeof(value_type)>= 512,传回1
迭代器四个指针,cur 指向当前元素,first 指向当前 buffer 的第一个元素,last 指向当前 buffer 的最后一个元素的下一个,node 指向当前 buffer 在 map(控制中心)的指针
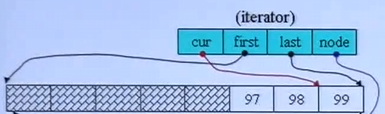
cpp
// deque迭代器
template <class T, class Ref, class Ptr, size_t BufSiz>
struct __deque_iterator
{
typedef random_access_iterator_tag iterator_category; // (1)
typedef T value_type; // (2)
typedef Ptr pointer; // (3)
typedef Ref reference; // (4)
typedef size_t size_type;
typedef ptrdiff_t difference_type; // (5)
typedef T** map_pointer;
typedef __deque_iterator self;
T* cur;
T* first;
T* last;
map_pointer node; // 指向指针的指针
// 四个指针,一共16字节
...
};deque 中的 insert 函数:
cpp
iterator insert(iterator position, const T& x)
{
if (position.cur == start.cur) // 插入点在deque最前端
{ // 交给push_front
push_front(x);
return start;
}
else if (position.cur == finish.cur) // 插入点在deque最尾端
{ // 交给push_front
push_back(x);
iterator tmp = finish;
--tmp;
return tmp;
}
else // 在中间插入
{
return insert_aux(position, x);
}
}
iterator insert_aux(iterator pos, const T& x)
{
difference_type index = pos - start; // 安插点前元素个数
value_type x_copy = x;
if (index < size() / 2) // 安插点前的元素少------------搬前面的
{
push_front(front());
...
copy(front2, pos1, front1); // 搬元素
}
else // 安插点后的元素少------------搬后面的
{
push_back(back());
...
copy_backward(pos, back2, back1);
}
*pos = x_copy; // 安插点设新值
return pos;
}deque 模拟连续空间(deque iterator 的功能):
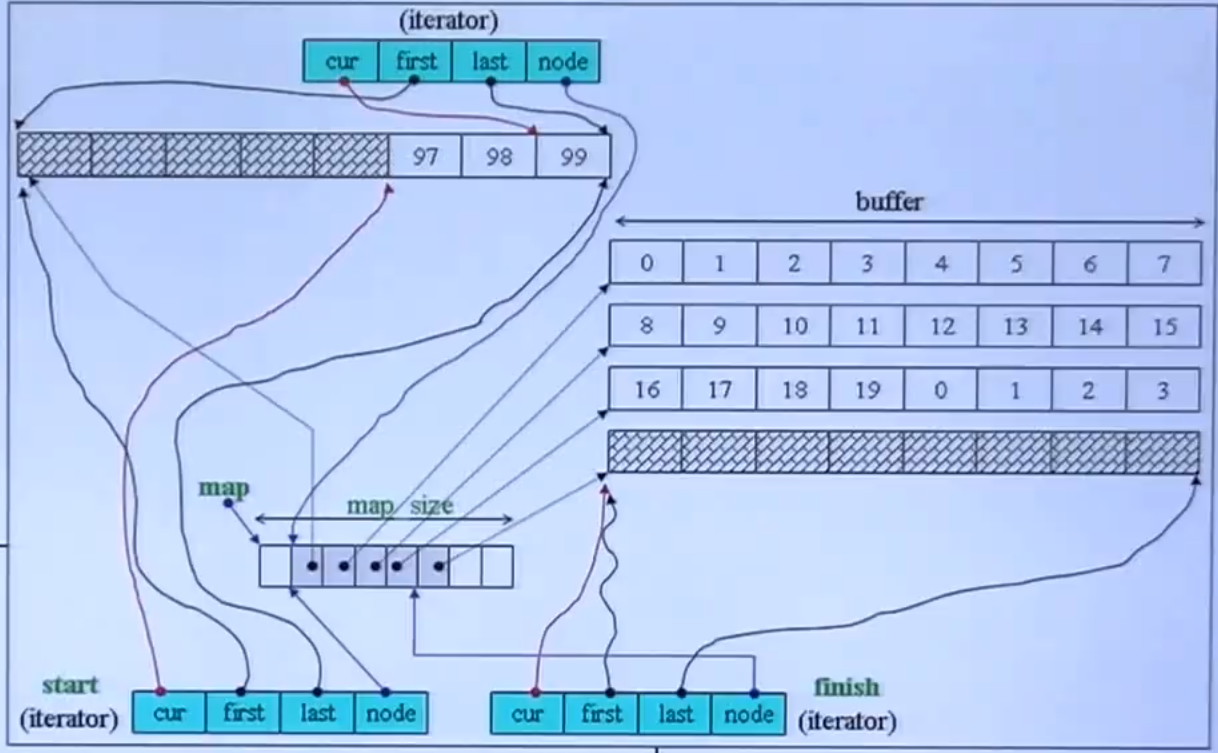
-
-:两个位置之间的距离------前闭后开的元素个数两个位置之间的距离 = buffer_size * 两个位置之间 buffer 的数量 + 末尾位置到 buffer 前端的长度 + 起始位置到 buffer 末尾的长度
-
++/--:注:下面带参数的是后++(i++) -
+=/+:cppself& operator+=(difference_type n) { difference_type offset = n + (cur - first); if (offset >= 0 && offset < difference_type(buffer_size())) // 若+了之后在缓冲区大小范围内 cur += n; // 直接移动迭代器 n 步 else { difference_type node_offset = offset > 0 ? offset / difference_type(buffer_size()) : -difference_type((-offset - 1) / buffer_size()) - 1; // 计算偏移的节点数,offset > 0判断是为了之后的-=/- // 这里(-offset - 1)后除buffer_size()再-1是为了offset==buffer_size()的情况 set_node(node + node_offset); // 调整节点,使迭代器指向正确的节点 cur = first + (offset - node_offset * difference_type(buffer_size())); // 调整迭代器位置 } return *this; } self operator+(difference_type n) const { self tmp = *this; // 复制当前迭代器 return tmp += n; // 返回向前移动 n 步后的迭代器副本 } -
-=/-:cpp// -就等于+负的 self& operator-=(difference_type n) { return *this += -n; } self operator-(difference_type n) const { self tmp = *this; return tmp -= n; } -
[]:cppreference operator[](difference_type n) const { return *(*this + n); }
GCC4.9下:其实没必要这样
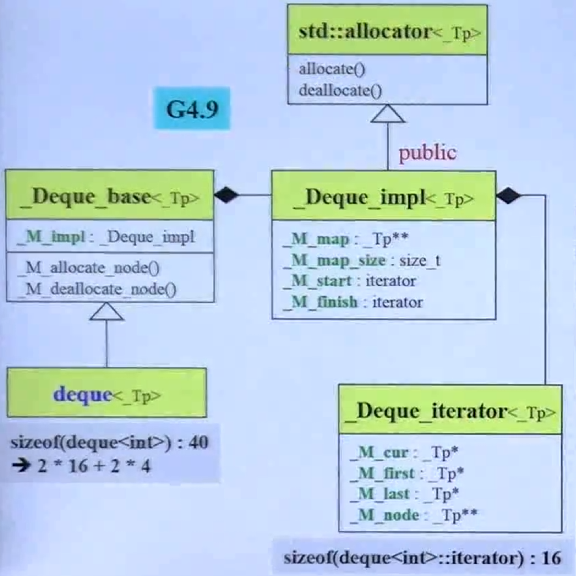
G2.91 允许指派 buffer_size
G4.53 不允许了
3.2.7 stack,queque
测试
stack:
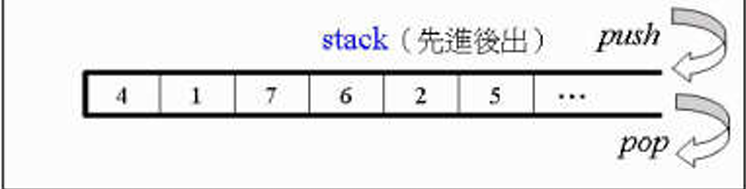
queue:

stack ,queue 是通过
push()和pop()来放取元素的,且无iterator 的操作
深度探索
stack 和 queue 内部默认用 deque 来实现,所以有时候不会将这两个认为容器而是一个适配器
- 底层函数可以使用 list 和 deque(deque默认更快)
- queue 不能用 vector,stack 可以用 vector
- set,map 都不能用
用时编译器可以通过的,但在具体使用函数时,若遇到底层容器没有这个函数时,就会报错
cpp
// queue
template<class T, class Sequence = deque<T>>
class queue
{
...
protected:
Sequence c; // 底层容器
public:
// 都是通过底层容器来实现
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference front() { return c.front(); }
const_reference front() const { return c.front(); }
reference back() { return c.back(); }
const_reference back() const { return c.back(); }
void push(const value_type& x) { c.push_back(x); }
void pop() { c.pop_front(); }
};
// stack
template<class T, class Sequence = deque<T>>
class stack
{
...
protected:
Sequence c; // 底层容器
public:
// 都是通过底层容器来实现
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference top() { return c.back(); }
const_reference top() const { return c.back(); }
void push(const value_type& x) { c.push_back(x); }
void pop() { c.pop_back(); }
};stack,queue 都不允许遍历,也不提供 iterator
3.3 关联式容器
3.3.0 RB-Tree
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树 BST(AVL 是另一种),其设计目标是在最坏情况下也能保证基本的动态集合操作(如插入、删除和查找)的时间复杂度为O(log n)。红黑树通过一系列的颜色和性质约束来维持其平衡性,这些约束包括:
- 节点是红色或黑色:每个节点都有一个颜色属性,可以是红色或黑色。
- 根节点是黑色:确保树的根始终为黑色,这有助于维持树的平衡。
- 所有叶子节点都是黑色:这里的叶子节点指的是树中的空节点(NIL节点),它们被假定为黑色。
- 红色节点的子节点必须是黑色(也称为"不能有两个连续的红色节点"):这个性质确保了在任何路径上,红色节点不会紧密相连,从而限制了树的高度。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点:这个性质被称为"黑色平衡性质",它确保了树在整体上保持平衡。
rb-tree 提供遍历操作和 iterators,按中序遍历遍历,便可以得到排序状态
不能用 iterator 去改变元素的 key(其有严谨的排列规则)
rb-tree 提供两种 insertion 操作:insert_unique()和insert_equal(),前者表示 key 独一无二,后者表示 key 可重复
GCC2.9下:
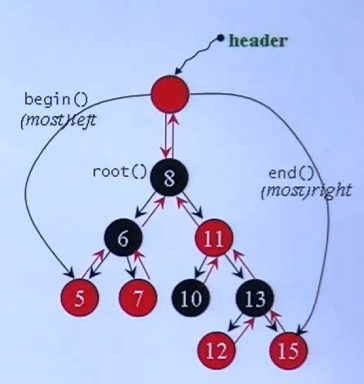
cpp
template<class Key, // key的类型
class Value, // Value里包含key和date
class KeyOfValue, // 从Value中取出key的仿函数
class Compare, // 比较key大小的仿函数
class Alloc = alloc>
class rb_tree
{
protected:
typedef __rb_tree_node<Value> rb_tree_node;
...
public:
typedef rb_tree_node* link_type;
...
protected:
size_type node_count; // rb-tree节点数量,大小4
link_type header; // 头指针,大小4
Compare Key_compare; // key比大小的仿函数,大小1
// sizeof: 9 ------> 12(填充到4的倍数)
...
};GCC4.9下:
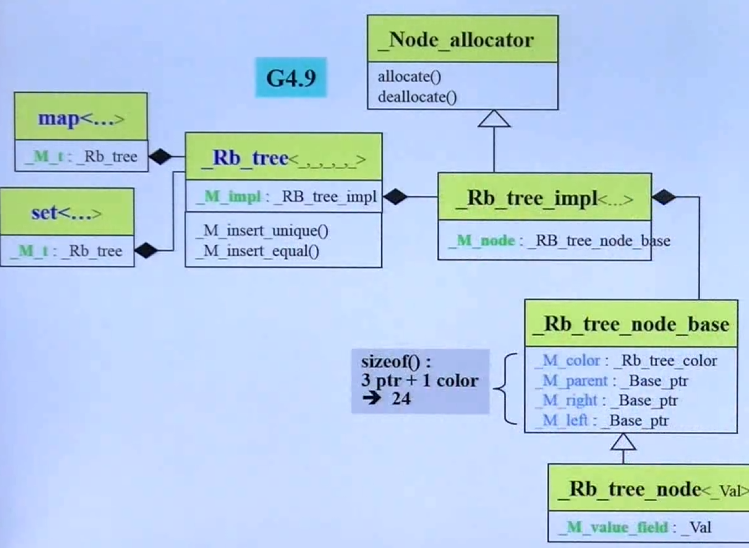
_M_color 是 "枚举"(Enumeration)
3.3.1 set / multiset
set/multiset的value和key合一,value就是key
测试
cpp
void test_multiset(long& value)
{
cout << "\ntest_multiset().......... \n";
multiset<string> c; // 创建一个multiset
char buf[10];
clock_t timeStart = clock(); // 记录起始时间
for(long i=0; i< value; ++i) // 添加元素到multiset中
{
try {
snprintf(buf, 10, "%d", rand()); // 将随机数转换为字符串格式
c.insert(string(buf)); // 将字符串插入multiset中
}
catch(exception& p) { // 捕获可能的异常
cout << "i=" << i << " " << p.what() << endl; // 输出异常信息
abort(); // 终止程序
}
}
cout << "毫秒数 : " << (clock()-timeStart) << endl; // 输出时间差,计算插入时间
cout << "multiset.size()= " << c.size() << endl; // 输出multiset大小
cout << "multiset.max_size()= " << c.max_size() << endl; // 输出multiset的最大容量
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); // 在multiset中使用 std::find(...) 查找目标字符串
cout << "std::find(),毫秒数 : " << (clock()-timeStart) << endl;
...
}
{
timeStart = clock();
auto pItem = c.find(target); // 在multiset中使用 c.find(...) 查找目标字符串
cout << "c.find(),毫秒数 : " << (clock()-timeStart) << endl;
...
}
c.clear(); // 清空multiset
}安插元素是使用
insert(),其位置由红黑树决定
容器自己有c.find(),其会比全局的::find()快
运行结果:
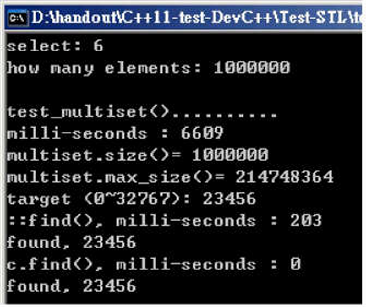
随机数据填充容器:6609ms(其在填充的时候就进行排序了);直接搜索 ::find():203ms;c.find():0ms
深度探索
以 rb-tree 为底层结构,因此有------元素自动排序,key 与 value 和一
set / multiset 提供遍历操作和 iterators,按中序遍历遍历,便可以得到排序状态
禁止用 iterator 去改变元素的值(其有严谨的排列规则)
set的key 独一无二,其insert()操作用的 rb-tree 的:insert_unique()multiset 的 key 可以重复,其
insert()操作用的 rb-tree 的:insert_equal()
GCC2.9下:
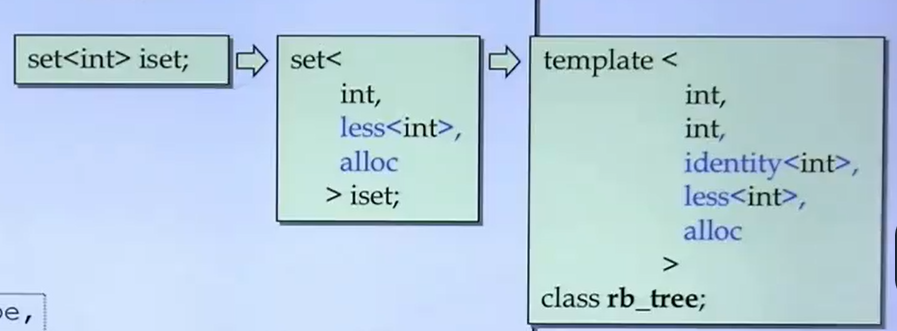
cpp
// set
template <class Key, class Compare = less<Key>, class Alloc = alloc>
class set
{
public:
typedef Key key_type;
typedef Key value_type;
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree<key_type, value_type, identity<value_type>,
key_compare, Alloc> rep_type;
rep_type t; // 采用红黑树作为底层机制
public:
typedef typename rep_type::const_iterator iterator;
// 注意:这里是const_iterator,所以不能用iterator改元素
...
};3.3.2 map / multimap
key是key,val是val
测试
cpp
void test_multimap(long& value)
{
...
multimap<long, string> c; // 创建一个multimap,key 为 long 类型,value 为 string 类型
char buf[10];
clock_t timeStart = clock(); // 记录起始时间
for(long i=0; i< value; ++i) // 添加元素到multimap中
{
try {
snprintf(buf, 10, "%d", rand()); // 将随机数转换为字符串格式并复制到缓冲区
// multimap 不可使用 [] 做 insertion
c.insert(pair<long, string>(i, buf)); // 将元素插入multimap中
}
catch(exception& p) { // 捕获可能的异常
cout << "i=" << i << " " << p.what() << endl; // 输出异常信息
abort(); // 终止程序
}
}
cout << "毫秒数 : " << (clock()-timeStart) << endl; // 输出时间差,计算插入时间
cout << "multimap.size()= " << c.size() << endl; // 输出multimap大小
cout << "multimap.max_size()= " << c.max_size() << endl; // 输出multimap的最大容量
long target = get_a_target_long();
timeStart = clock();
auto pItem = c.find(target); // 在multimap中查找目标 key
cout << "c.find(),毫秒数 : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "找到,value=" << (*pItem).second << endl; // 如果找到,输出找到的值
else
cout << "未找到!" << endl; // 如果未找到,输出未找到的信息
c.clear(); // 清空multimap
}
c.insert(pair<long, string>(i, buf));中 key 是从1~1000000,value 是随机取的,将其组合为 pair 插入
运行结果:
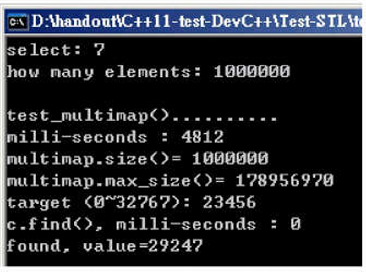
随机数据填充容器:4812ms(其在填充的时候就进行排序了);c.find():0ms
深度探索
以 rb-tree 为底层结构,因此有------元素自动排序
map/ multimap 提供遍历操作和 iterators,按中序遍历遍历,便可以得到排序状态
不能用 iterator 去改变元素的key(其有严谨的排列规则),但可以用 iterator 去改变元素的 data因此 map / multimap 将 user 指定的 key_type 设定成
const
map的key 独一无二,其insert()操作用的 rb-tree 的:insert_unique()multimap 的 key 可以重复,其
insert()操作用的 rb-tree 的:insert_equal()
GCC2.9下:
cpp
template <class Key, // key的类型
class T, // data的类型
class Compare = less<Key>,
class Alloc = alloc>
class map
{
public:
typedef Key key_type;
typedef T data_type;
typedef T mapped_type;
typedef pair<const Key, T> value_type;
// 注意:这里是const Key ------------ 防止改key
typedef Compare key_compare;
private:
typedef rb_tree<key_type, value_type, select1st<value_type>, key_compare, Alloc> rep_type;
rep_type t; // 采用红黑树作为底层机制
public:
typedef typename rep_type::iterator iterator;
...
};map 的插入元素有特殊写法:
c[i] = string(buf),其中i就是 key;multimap没有map 的
[]功能:访问元素: 如果指定的键存在于映射中,
map[key]将返回与该键关联的 data;如果键不存在,map[key]将自动创建一个新的键值对,key 为指定的 key,data 为默认 data,并返回这个默认 data
3.3.3 HashTable
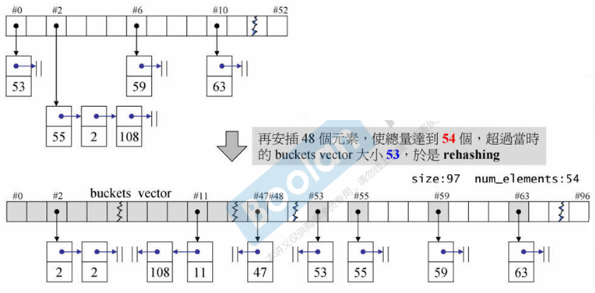
-
元素的位置 = key % bucket大小
-
bucket vector 的大小为质数
-
当元素个数大于 bucket 的总数时,bucket vector 扩充并重新打散放在新计算的 bucket 中(rehashing 很花时间)------ bucket 一定比元素多
在扩充时,按 vector 扩充为2倍大小,但会选择靠进这个数的一个质数做新的大小
GCC2.9下:
cpp
template <class Value, // Value里包含key和date
class Key, // key的类型
class HashFcn, // hash函数
class ExtractKey, // 从Value中取出key的方法
class EqualKey, // 判断key相等的函数
class Alloc>
class hashtable
{
public:
typedef HashFcn hasher;
typedef EqualKey key_equal; // 判断key相等的函数
typedef size_t size_type;
private:
// 3个函数对象,大小一共3(应该是0,因为一些因素)
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
vector<node*, Alloc> buckets; // vector里3个指针,大小12
size_type num_elements; // 大小4
// 一共19 ------> 20(调整为4的倍数)
public:
size_type bucket_count() const { return buckets.size(); }
};Hash函数:
给传进来的参数生成一个编号
偏特化写不同类型的 hash 函数,下图都是数值类型,直接返回就可以
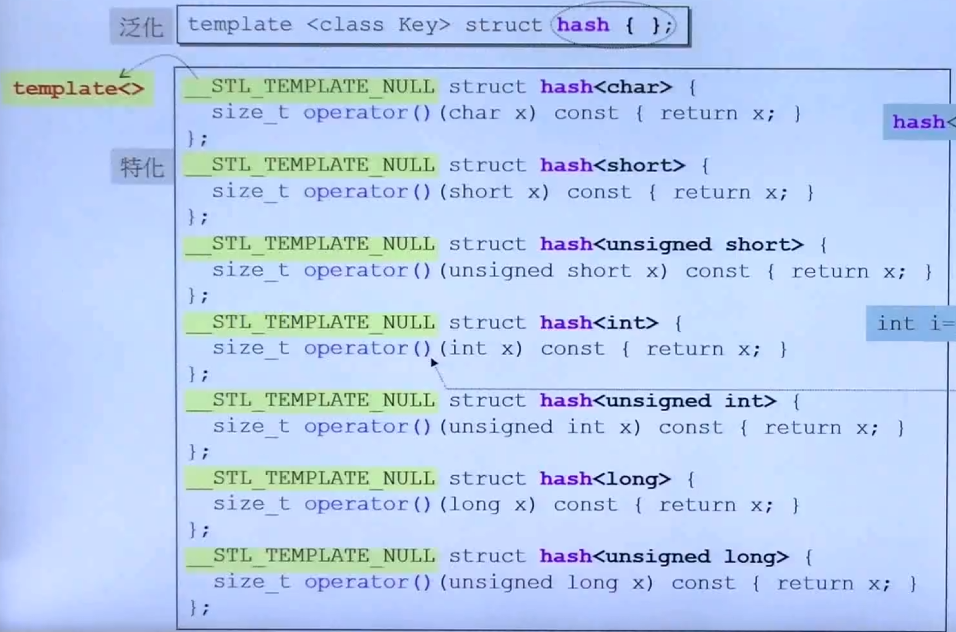
下图对 c 风格的字符串做了处理(也可以自己设计),来生成 hash code

注意:老版本STL没有提供现成的 string 类型的 hash 函数
3.3.4 unordered容器
测试
cpp
void test_unordered_multiset(long& value)
{
cout << "\ntest_unordered_multiset().......... \n";
unordered_multiset<string> c; // 创建一个 unordered_multiset
char buf[10];
clock_t timeStart = clock(); // 记录起始时间
for(long i=0; i< value; ++i) // 添加元素到 unordered_multiset 中
{
try {
snprintf(buf, 10, "%d", rand()); // 将随机数转换为字符串格式
c.insert(string(buf)); // 将字符串插入 unordered_multiset 中
}
catch(exception& p) { // 捕获可能的异常
cout << "i=" << i << " " << p.what() << endl; // 输出异常信息
abort(); // 终止程序
}
}
cout << "毫秒数 : " << (clock()-timeStart) << endl; // 输出时间差,计算插入时间
cout << "unordered_multiset.size()= " << c.size() << endl; // 输出 unordered_multiset 大小
cout << "unordered_multiset.max_size()= " << c.max_size() << endl; // 输出 unordered_multiset 的最大容量
cout << "unordered_multiset.bucket_count()= " << c.bucket_count() << endl; // 输出 unordered_multiset 的桶数量
cout << "unordered_multiset.load_factor()= " << c.load_factor() << endl; // 输出 unordered_multiset 的负载因子
cout << "unordered_multiset.max_load_factor()= " << c.max_load_factor() << endl; // 输出 unordered_multiset 的最大负载因子
cout << "unordered_multiset.max_bucket_count()= " << c.max_bucket_count() << endl; // 输出 unordered_multiset 的最大桶数量
for (unsigned i=0; i< 20; ++i) {
cout << "bucket #" << i << " has " << c.bucket_size(i) << " elements.\n"; // 输出前20个桶中的元素数量
}
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); // 在 unordered_multiset 中使用 std::find(...) 查找目标字符串
cout << "std::find(),毫秒数 : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl; // 如果找到,输出找到的元素
else
cout << "not found! " << endl; // 如果未找到,输出未找到的信息
}
{
timeStart = clock();
auto pItem = c.find(target); // 在 unordered_multiset 中使用 c.find(...) 查找目标字符串
cout << "c.find(),毫秒数 : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl; // 如果找到,输出找到的元素
else
cout << "not found! " << endl; // 如果未找到,输出未找到的信息
}
c.clear(); // 清空unordered_multiset
} 运行结果:
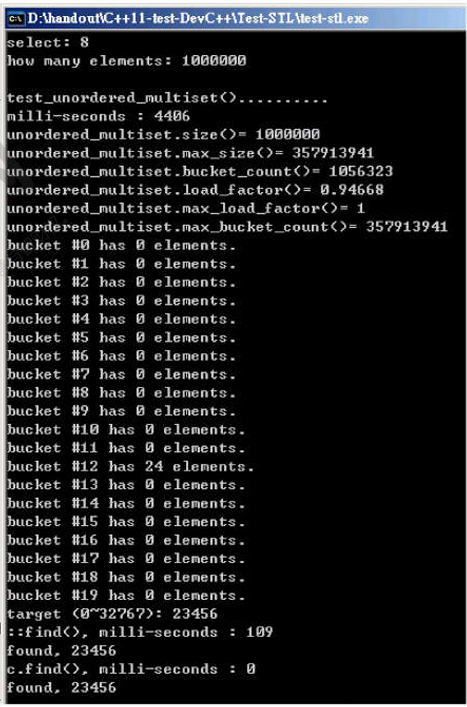
随机数据填充容器:4406ms;直接搜索 ::find():109ms;c.find():0ms;前二十个 bucket 中只有一个有24个元素
深度探索

4 分配器
4.1 测试
分配器都是与容器共同使用的,一般分配器参数用默认值即可
cpp
list<string, allocator<string>> c1;不建议直接用分配器分配空间,因为其需要在释放内存时也要指明大小
cpp
int* p;
p = allocator<int>().allocate(512, (int*)0); // 临时变量调用函数
allocator<int>().deallocate(p,512); // 释放时需要指明之前申请的大小4.2 源码解析
VC6 下:allocator 中有 allocate,deallocate 其分别用函数 ::operator new 和 ::operator delete 来调用 c 中的 malloc 和 free
cpp
pointer allocate(size_type _N, const void*){...} // 后面一个参数只是用来指明类型的
void deallocate(void _FARQ *_P, size_type){...}这里经过包装还是调用的 malloc 和 free,其执行效率变慢;且如果申请的空间比较小,会有较大比例的额外开销(cookie,调试模式所需空间等等)
GCC2.9 下:其容器都是调用的名叫 alloc 的分配器
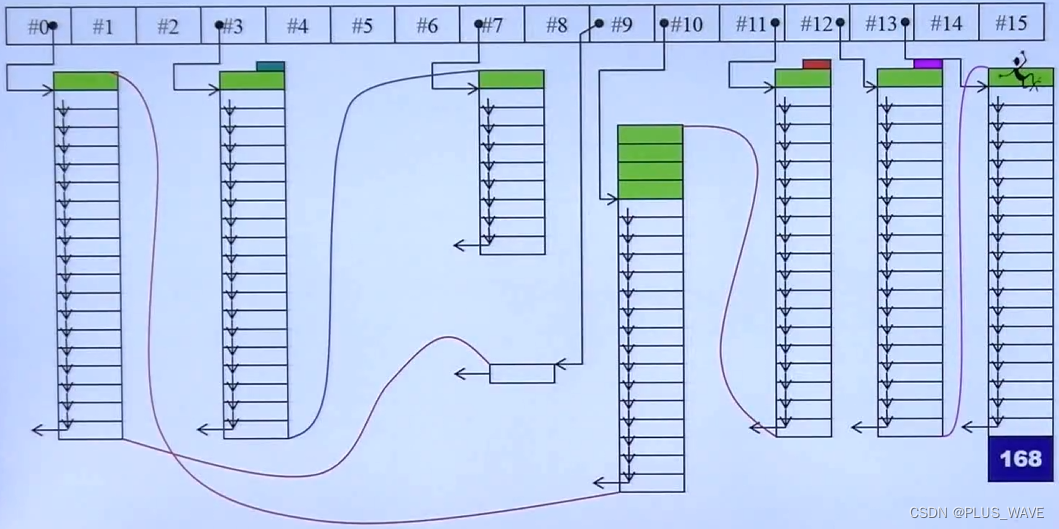
其从0到15有一共16个链表,分别代表8字节到16*8字节,例如 #0 的位置用 malloc 要一大块内存,然后做切割,切成一块一块的8字节空间不带cookie,用单向链表穿起来;当要申请6字节的大小的空间时,其就会到 #0 中占用一块 ------ 节省空间
在 GCC4.9 中各个容器又用回了 allocator,而上面的 alloc 变成了
__poll_alloc
5 迭代器
迭代器必须能回答算法的所有提问,才能搭配该算法的所有操作
5.1 迭代器的设计准则
Iterator 必须提供5种 associated type(说明自己的特性的)来供算法来识别,以便算法正确地使用 Iterator
cpp
template <class T, class Ref, class Ptr>
struct __list_iterator
{
...
typedef bidirectional_iterator_tag iterator_category; // (1)迭代器类别:双向迭代器
typedef T value_type; // (2)迭代器所指对象的类型
typedef Ptr pointer; // (3)迭代器所指对象的指针类型
typedef Ref reference; // (4)迭代器所指对象的引用类型
typedef ptrdiff_t difference_type; // (5)两个迭代器之间的距离类型
// iter1-iter2 时,要保证数据类型以存储任何两个迭代器对象间的距离
...
}
// 迭代器回答
// | Λ
// | |
// | |
// V |
// 算法直接提问
template <typename I>
inline void algorithm(I first, I last)
{
...
I::iterator_category
I::pointer
I::reference
I::value_type
I::difference_type
...
}但当 Iterator 并不是 class 时,例如指针本身,就不能 typedef 了 ------ 这时就要设计一个 Iterator Traits
Traits:用于定义类型特征的信息,从而在编译时根据类型的不同进行不同的操作或处理 ------ 类似一个萃取机(针对不同类型做不同操作:偏特化)
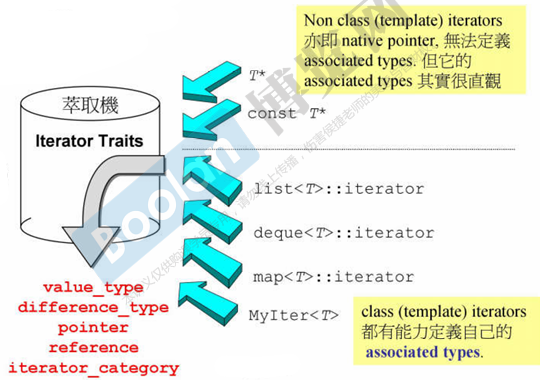
cpp
// I是class iterator进
template <class I>
struct Iterator_traits
{
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
// typename用于告诉编译器,接下来的标识符是一个类型名,而不是一个变量名或其他名称
// I::iterator_category 是一个类型名
// iterator_category是这个迭代器类型内部的一个嵌套类型(typedef ...)
};
// I是指向T的指针进
template <class T>
struct Iterator_traits<T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
// I是指向T的常量指针进
template <class T>
struct Iterator_traits<const T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type; // 注意是T而不是const T
// 按理说是const T,但声明一个不能被赋值的变量无用
// 所以value_type不应加上const
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};除了 Iterator Traits,还有很多其他 Traits
5.2 迭代器的分类
迭代器的分类对算法的效率有很大的影响
- 输入迭代器 input_iterator_tag:istream迭代器
- 输出迭代器 output_iterator_tag:ostream迭代器
- 单向迭代器 forward_iterator_tag:forward_list,hash类容器
- 双向迭代器 bidirectional_iterator_tag: list、红黑树容器
- 随机存取迭代器 random_access_iterator_tag:array、vector、deque
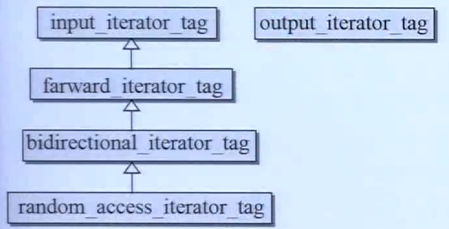
用有继承关系的class实现:
- 方便迭代器类型作为参数进行传递,如果是整数的是不方便的
- 有些算法的实现没有实现所有类型的迭代器类别,就要用继承关系去找父迭代器类别
cpp
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};5.3迭代器对算法的影响
1.算法 distance 将会按照迭代器的类别进行不同的操作以提升效率
- 如果迭代器可以跳,直接
last - first即可 - 如果迭代器不能跳,就只能一步一步走来计数
两者的效率差别很大

但如果迭代器类别是
farward_iterator_tag或者bidirectional_iterator_tag,该算法没有针对这种类型迭代器实现,就可以用继承关系 来使用父类的实现(继承关系------"is a" 子类是一种父类,当然可以用父类的实现)
2.算法 copy 将经过很多判断筛选来找到最高效率的实现
其中用到了 Iterator Traits 和 Type Traits 来进行筛选
has trivial op=() 是指的有不重要的拷贝赋值函数(例如复数用的自带的拷贝赋值函数)
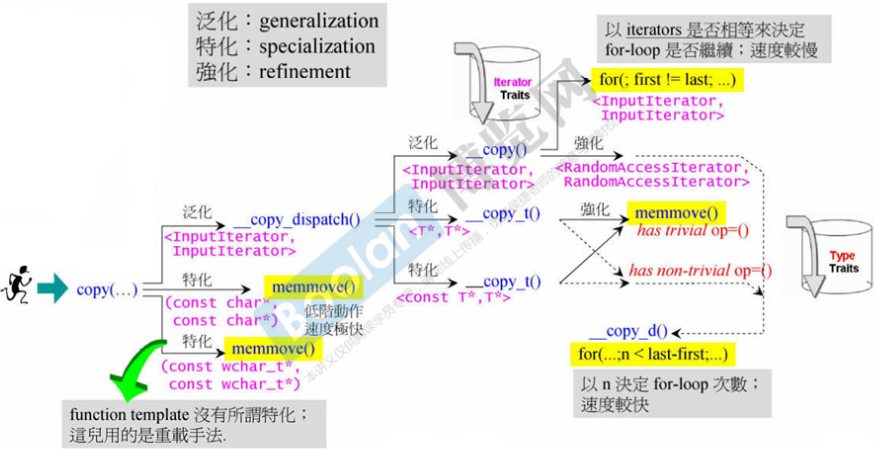
注意:由于 output_iterator_tag (例如 ostream_iterator )是 write-only ,无法用
*来读取内容,所以在设计时就需要再写个专属版本
在源码中,算法都是模板函数,接受所有的 iterator,但一些算法只能用特定的 iterator,所以其会在模板参数的名称上进行暗示:

6 算法
算法的标准样式:需要传进去两个指针

6.1 算法源码
算法一般最后一个参数会允许我们传入一个函数对象,使得原来的函数对元素的操作有一定的规则
6.1.1 accumulate
两个版本:
-
元素累加 到 init 上
cpptemplate <class InputIterator, class T> T accumulate(InputIterator first, InputIterator last, T init) { for (; first != last; ++first) init = init + *first; // 累加到init return init; } -
元素累运算 到 init 上
cpptemplate <class InputIterator, class T, class BinaryOperation> T accumulate(InputIterator first, InputIterator last, T init, BinaryOperation binary_op) { for (; first != last; ++first) init = binary_op(init, *first); // 累运算到init上 return init; }
这里可以用任意的二元操作(可以是函数,也可以是仿函数)
测试:
cpp
#include <iostream> // std::cout
#include <functional> // std::minus
#include <numeric> // std::accumulate
// 函数
int myfunc (int x, int y) {return x+2*y;}
// 仿函数
struct myclass {
int operator()(int x, int y) {return x+3*y;}
} myobj;
void test_accumulate()
{
cout << "\ntest_accumulate().......... \n";
int init = 100;
int nums[] = {10,20,30};
cout << "using default accumulate: ";
cout << accumulate(nums,nums+3,init); //160
cout << '\n';
cout << "using functional's minus: ";
cout << accumulate(nums, nums+3, init, minus<int>()); //40
cout << '\n';
cout << "using custom function: ";
cout << accumulate(nums, nums+3, init, myfunc); //220
cout << '\n';
cout << "using custom object: ";
cout << accumulate(nums, nums+3, init, myobj); //280
cout << '\n';
} 6.1.2 for_each
让范围里的所有元素都依次做同一件事情
Function 可以是函数也可以是仿函数
cpp
template <class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function f)
{
for (; first != last; ++first) {
f(*first);
}
return f;
}与C++11中的 range-based for statement 差不多
6.1.3 replace...
-
replace:范围内的所有等于 old_value 的,都被 new_value 取代cpptemplate <class ForwardIterator, class T> void replace(ForwardIterator first, ForwardIterator last, const T& old_value, const T& new_value) { for (; first != last; ++first) { if (*first == old_value) *first = new_value; } } -
replace_if:范围内所有满足pred()为 true 的元素都被 new_value 取代cpptemplate <class ForwardIterator,class Predicate, class T> void replace_if(ForwardIterator first, ForwardIterator last, Predicate pred, const T& new_value) { for (; first != last; ++first) { if (pred(*first)) *first = new_value; } } -
replace_copy:范围内的元素全部 copy 到新地方,其中所有等于 old_value 的,都被替代为 new_valuecpptemplate <class InputIterator, class OutputIterator, class T> OutputIterator replace_copy(InputIterator first, InputIterator last, OutputIterator result, const T& old_value, const T& new_value) { for (; first != last; ++first, ++result) { *result = (*first == old_value) ? new_value : *first; } return result; }
6.1.4 count...
-
count:在范围中计数值等于 value 的个数cpptemplate <class InputIterator, class T> typename iterator_traits<InputIterator>::difference_type // 返回类型 count (InputIterator first, InputIterator last, const T& value) { typename iterator_traits<InputIterator>::difference_type n = 0; for (; first != last; ++first) { if (*first == value) ++n; } return n; } -
count_if:在范围中计数满足条件pred()的个数cpptemplate <class InputIterator, class Predicate> typename iterator_traits<InputIterator>::difference_type // 返回类型 count_if (InputIterator first, InputIterator last, Predicate pred) { typename iterator_traits<InputIterator>::difference_type n = 0; for (; first != last; ++first) { if (pred(*first)) ++n; } return n; }
- 容器不带 成员函数
count():array,vector,forward_list,deque- 容器自带 成员函数
count():set / multiset,map / multimap,unordered_set / unordered_multiset,unordered_map / unorderd_multimap ------ 所有关联式容器
6.1 5 find...
-
find:在范围内找到值等于 value 的元素cpptemplate <class InputIterator, class T> InputIterator find(InputIterator first, InputIterator last, const T& value) { while (first != last && *first != value) ++first; return first; } -
find_if:在范围内找到满足pred()的元素cpptemplate <class InputIterator, class Predicate> InputIterator find_if(InputIterator first, InputIterator last, Predicate pred) { while (first != last && !pred(*first)) ++first; return first; }
都是循序查找,效率低
- 容器不带 成员函数
find():array,vector,forward_list,deque- 容器自带 成员函数
find():set / multiset,map / multimap,unordered_set / unordered_multiset,unordered_map / unorderd_multimap ------ 所有关联式容器
6.1.6 sort
源码复杂
测试:
cpp
// 函数
bool myfunc (int i,int j) { return (i<j); }
//仿函数
struct myclass {
bool operator() (int i,int j) { return (i<j);}
} myobj;
// 定义向量
int myints[] = {32,71,12,45,26,80,53,33};
vector<int> myvec(myints, myints+8); // 32 71 12 45 26 80 53 33
// 用默认的比较(operator <)
sort(myvec.begin(), myvec.begin()+4); //(12 32 45 71)26 80 53 33
// 用自己的函数作比较
sort(myvec.begin()+4, myvec.end(), myfunc); // 12 32 45 71(26 33 53 80)
// 用自己的仿函数作比较
sort(myvec.begin(), myvec.end(), myobj); //(12 26 32 33 45 53 71 80)
// 用反向迭代器 reverse iterator 和默认的比较(operator <)
sort(myvec.rbegin(), myvec.rend()); // 80 71 53 45 33 32 26 12
// 用显式默认比较(operator <)
sort(myvec.begin(), myvec.end(), less<int>()); // 12 26 32 33 45 53 71 80
// 使用另一个比较标准(operator >)
sort(myvec.begin(), myvec.end(), greater<int>()); // 80 71 53 45 33 32 26 12
- 容器不带 成员函数
sort():array,vector,deque,所有关联式容器(本身就排好序了)- 容器自带 成员函数
sort():list,forward_list(只能用自带)
reverse iterator:其中用的是 reverse_iterator ------ iterator adapter
6.1.7 binary_search
二分查找是否存在目标元素(并不给予位置),使用前必须先排序;其主要使用 lower_bound() 来找到能放入 val 的最低位置,再判断该元素是否存在
cpp
template <class ForwardIterator, class T>
bool binary_search(ForwardIterator first, ForwardIterator last, const T& value)
{
first = lower_bound(first, last, value);
return (first != last && !(value < *first));
// first == last 就是序列中所有元素都小于value
// first == last 时,*first是没有值的,所以需要先检查
// value < *first 就是序列中没有等于value的
}
lower_bound():用于在有序序列中查找第一个大于等于该值的元素(包括目标值本身),并返回一个指向该位置的迭代器
- 如果目标值在序列中多次出现,返回第一个出现的位置
- 如果目标值在序列中不存在,它将返回指向比目标值大的第一个元素位置,或者返回
last
upper_bound():用于在有序序列中查找第一个大于该值的元素(不包括目标值本身),并返回一个指向该位置的迭代器
- 如果目标值在序列中多次出现,返回第一个大于目标值的位置
- 如果目标值在序列中不存在,它将返回与
lower_bound()一样的位置一样是前闭后开的原则,且他们都用的是二分查找的方法
7 仿函数
仿函数专门为算法服务,设计成一个函数/仿函数是为了能传入算法

STL中的每个仿函数都继承了 binary_function / unary_function------ 融入到STL中
STL规定每个 Adaptable Function(之后可以改造的函数)都应该继承其中一个(因为之后 Function Adapter 将会提问)
cpp
// 一个操作数的操作,例如"!"
template <class Arg, class Result>
struct unary_function
{
typedef Arg argument_type;
typedef Result result_type;
};
// 两个操作数的操作,例如"+"
template <class Arg1, class Arg2, class Result>
struct binary_function
{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
// 理论大小都是0,实际上可能是1(如果有人继承,那就一定是0)仿函数是我们自己可能会写的,所以自己写的时候,如果想要融入STL,就要继承上面的两个之一
8 适配器
- 适配器 Adapter 只是一个小变化,比如改个接口,函数名称等等
- 其出现在三个地方:仿函数适配器,迭代器适配器,容器适配器
- 可以使用继承 / 复合的两种方式实现,STL中都用复合
其思想就是将该记的东西记起来,然后看要怎么样去改造它,以便日后使用
8.1 容器适配器
stack ,queue 都是属于 deque 的 Adapter
比如 stack 中将 deque 的 push_back 改名为 push
8.2 函数适配器
8.2.1 binder2nd
binder2nd ------ 绑定第二参数
这个例子的OP就是less<int>
1.先是传给bind2nd函数
2.bind2nd生成binder2nd对象
3.对象里面记录op是less<int>,第二参数是40
4.然后都搞定以后返回一个函数对象op(其实返回的是op调用小括号重载运算符,这是一个函数对象)给到count_if作为第三参数,然后继续执行程序
cpp
// 数范围内所有小于40的元素个数
cout << count_if(vi.begin(), vi.end(),
bind2nd(less<int>(), 40));
// 辅助函数bind2nd,使用方便
// 编译器自动推动op的类型(函数模板)
template <class Operation, class T>
inline binder2nd<Operation> bind2nd(const Operation& op, const T& x)
{
typedef typename Operation::second_argument_type arg2_type;
// 调用ctor生成一个binder2nd临时对象并返回
return binder2nd<Operation>(op, arg2_type(x));
}
// binder2nd适配器:将二元函数对象转换为一元函数对象
template <class Operation>
class binder2nd
: public unary_function<typename Operation::first_argument_type,
typename Operation::result_type>
// 可能binder2nd也要被改造,要回答问题
{
protected:
Operation op; // 内部成员,记录op和第二实参
typename Operation::second_argument_type value;
public:
binder2nd(const Operation& x,
const typename Operation::second_argument_type& y)
: op(x), value(y) {} // ctor,将op和第二实参记录下来
typename Operation::result_type
operator()(const typename Operation::first_argument_type& x) const
{
return op(x, value); // 实际调用op,第二实参为value
}
};当然还有:binder1st ------ 绑定第二参数
新型适配器:bind,代替了 bind1st,bind2nd,binder1st,binder2nd
8.2.2 not1
not1 ------ 否定
cpp
// 数范围内所有大于等于40的元素个数
cout << count_if(vi.begin(), vi.end(),
not1(bind2nd(less<int>(), 40)));8.2.3 bind
C++11提供的 Adapter,其可以绑定:
- functions
- function objects
- member functions
- data members
测试函数 / 对象
cpp
// functions
double my_divide(double x, double y)
{
return x/y;
}
// function objects 测试与functions同理
// divides<double> my_divide;
struct MyPair
{
// data members
double a, b;
// member functions
double multiply()
{
return a*b;
}
};占位符 placeholders:
using namespace std::placeholders;提供了
_1,_2,_3,·······下面的的
_1指的是被绑函数中的第一个参数
-
binding functions / function objects 测试
-
单纯将两个整数
10,2绑定到my_dividecppauto fn_five = bind(my_divide, 10, 2); cout << fn_five() << endl; // 5.0 -
用
_1占据第一参数,第二参数绑定2,即x/2cppauto fn_half = bind(my_divide, _1, 2); cout << fn_half(10) << endl; // 5.0 -
用
_1占据第一参数,_2占据第二参数,即y/xcppauto fn_invert = bind(my_divide, _2, _1); cout << fn_invert(10, 2) << endl; // 0.2 -
给
bind指定了一个模板参数int,将my_divide的返回类型变为int,即int(x/y)cppauto fn_rounding = bind<int>(my_divide, _1, _2); cout << fn_rounding(10, 3) << endl; // 3
-
-
binding member functions / data members 测试
MyPair ten_two {10, 2};用C++11的新语法定义一个实例当函数是类的成员函数时,直接使用函数名并不能获取其地址(因为成员函数隐含地需要一个类的实例来调用),而是需要使用特定的语法来获取指向成员函数的指针。这时,
&的使用就显得尤为重要了。对于普通的全局函数或静态成员函数,直接使用函数名和加&都可以获取其地址。-
绑定 member functions ,由于成员函数有
this,所以_1就相当于this,即x.multiply()cppauto bound_memfn = bind(&MyPair::multiply, _1); cout << bound_memfn(ten_two) << endl; // 20 -
绑定 data members,绑定是谁的数据
把实例
ten_two绑定到a,即ten_two.acppauto bound_memdata = bind(&MyPair::a, ten_two); cout << bound_memdata() << endl; // 10用占位符绑定,即
x.acppauto bound_member_data2 = bind(&MyPair::b, _1); cout << bound_member_data2(ten_two) << endl;
-
8.3 迭代器适配器
8.3.1 reverse_iterator
注意:对逆向迭代器取值,就是取其所指正向迭代器的前一个位置
cpp
template <class Iterator>
class reverse_iterator
{
protected:
Iterator current;
public:
// 五个associated types与对应的正向迭代器相同
typedef Iterator iterator_type; // 代表正向迭代器
typedef reverse_iterator<Iterator> self; // 代表逆向迭代器
public:
explicit reverse_iterator(iterator_type x) : current(x) {}
reverse_iterator(const self& x) : current(x.current) {}
iterator_type base() const { return current; } // 取出正向迭代器
// 对逆向迭代器取值,就是取其所指正向迭代器的前一个位置
reference operator*() const
{ Iterator tmp = current; return *--tmp; }
pointer operator->() const { return &(operator*()); } // 同上
// 前进变后退,后退变前进
self& operator++()
{ --current; return *this; }
self& operator--()
{ ++current; return *this; }
self operator+(difference_type n)const
{ return self(current-n); }
self operator-(difference_type n)const
{ return self(current+n); }
};8.3.2 inserter
对于 copy(InputIterator first, InputIterator last, OutputIterator result),其会不管 OutputIterator 后是否有充裕空间,对 result 开始依次赋值
但如果使用 inserter,就会有如下用 copy 实现的插入的效果

cpp
list<int> foo, bar;
for (int i = 1; i <= 5; i++)
{
foo.push_back(i);
bar.push_back(i*10);
}
list<int>::iterator it = foo.begin();
advance(it, 3);
copy(bar.begin(), bar.end(), inserter(foo, it));注:其是 output_iterator_tag
其实现原理核心就是 ------ 对 = 的操作符重载

cpp
insert_iterator<Container>&
operator=(const typename Container::value_type& val)
{
// 关键:转调用insert()
iter = container->insert(iter, val);
++iter; // 使其一直随target贴身移动
return *this;
}8.4 X适配器
8.4.1 ostream_iterator
其会将 copy 变为一个输出工具,分隔符是 ,
cpp
vector<int> vec = { 1,2,3,4,5,6,7,8,9,10 };
ostream_iterator<int> out_it(cout, ",");
copy(vec.begin(), vec.end(), out_it); // 1,2,3,4,5,6,7,8,9,10,其核心依然是操作符重载 ,这样就相当于 cout<<*first; cout<<",";
cpp
basic_ostream<charT,traits>* out_stream;
const charT* delim;
...
ostream_iterator<T, charT, traits>& operator=(const T& value)
{
*out_stream << value;
if(delim!=0) *out_stream << delim; // 分隔符delimiter
return *this;
}
ostream_iterator<T,charT,traits>& operator*(){return *this;}
ostream_iterator<T,charT,traits>& operator++(){return *this;}
...其中 out_stream 存的 cout,delim 存的 ,
8.4.2 istream_iterator
例一:
在创建 iit 的时候就已经把所有的键盘输入读进去了,之后就是一个一个取出来赋值给 value 的操作
cpp
double value1, value2;
istream_iterator<double> eos; // end of stream iterator
istream_iterator<double> iit(cin); // 相当于cin>>value
if(iit != eos)
value1 = *iit; // 相当于return value
iit++; // 迭代器不断++,就是不断地读内容
if(iit != eos)
value2 = *iit;例二:
从 cin 读 data,插入到目的容器
cpp
istream_iterator<double> eos; // end of stream iterator
istream_iterator<double> iit(cin);
copy(iit, eos, inserter(c,c.begin()));原理依旧是大量的**操作符重载 **------ 就可以改变原函数的作用
cpp
basic_istream<charT, traits>* in_stream;
T value;
...
istream_iterator():in_stream(0){} // eos
istream_iterator(istream_type& s):in_stream(&s){++*this;} // 进++
istream_iterator<T,charT,traits,Distance>& operator++()
{
if(in_stream && !(*in_stream >> value)) // 开始读了
in_stream = 0;
return *this;
}
const T& operator*() const { return value; }
...9 STL周围
9.1 万用Hash Function
Hash Function的常规写法:其中 hash_val 就是万用Hash Function
cpp
class CustumerHash
{
public:
size_t operator()(const Customer& c) const
{ return hash_val(c.fname(), c.lname(), c.no()); }
};还可以直接用函数实现,或者写一个
hash的特化版本
原理:
通过三个函数重载实现从给入数据中逐一提取来不断改变 seed
cpp
// 第一个函数 首先进入该函数
template <typename... Types>
inline size_t hash_val(const Type&... args)
{
size_t seed = 0; // 设置初始seed
hash_val(seed, args...); // 进入第二个函数
return seed; // seed就是最后的HashCode
}
// 第二个函数 该函数中逐一提取一个参数
template <typename T, typename... Types>
inline void hash_val(size_t& seed, const T& val, const Types&... args)
{
hash_combine(seed, val); // 逐一取val,改变seed
hash_val(seed, args...); // 递归调用自己,直到取完进入第三个函数
}
// 第三个函数
template <typename T>
inline void hash_val(size_t& seed, const T& val)
{
hash_combine(seed, val); // 取最后一个val,改变seed
}
// 改变seed的函数
template <typename T>
inline void hash_combine(size_t& seed, const T& val)
{
// 乱七八糟的运算,越乱越好
seed ^= hash<T>()(val) + 0x9e3779b9 + (seed<<6) + (seed>>2);
}最后的seed就是hash code
C++11中 variadic templates:
从传入的内容(任意个数,任意元素类型)分为一个和其他,递归再分为一个和其他······
0x9e3779b9:是黄金比例!
C++11及其后续版本并没有为每个类型都自动提供哈希函数,但它确实为一些标准类型提供了std::hash的特化,并且允许开发者为用户定义的类型提供自己的std::hash特化。
9.2 Tuple
可以将一些东西组合在一起
9.2.1 用例
-
创建
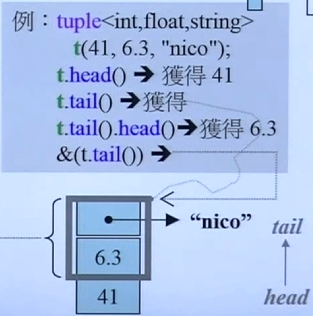
tuplecpptuple<string, int, int, complex<double>> t; tuple<int, float, string> t1(41, 6.3, "nico"); auto t2 = make_tuple(22, 44, "stacy"); -
输出
tuplecpp// 输出t1中的第一个 cout << get<0>(t1) << endl; // 41 cout << t << endl; // 在VS2022上并没有<<的重载 需要自己写一个重载 -
运算
cppt1 = t2; if(t1 < t2) // 以特定的方式进行的比较 里面的东西拿出来一个一个比 { ... } -
绑定解包
cpptuple<int, float, string> t3(77, 1.1, "more light"); int i; float f; string s; tie(i, f, s) = t3; // i == 77, f == 1.1, s == "more light"
cpp
// tuple里有多少类型
tuple_size< tuple<int, float, string> >::value; // 3
// 取tuple里面的类型,前面一堆代表float
tuple_element<1, TupleType>::type fl = 1.0; // float fl = 1.0;9.2.2 原理
依然是使用 variadic templates ,通过递归继承,不断从 ... 中提取内容
cpp
// 空的tuple
template <> class tuple<> {}; // 直到取完
// tuple主体
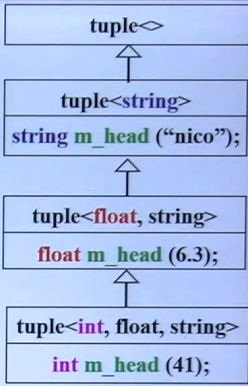
template <typename Head, typename... Tail>
class tuple<Head, Tail...>
: private tuple<Tail...> // 递归继承
{
typedef tuple<Tail...> inherited;
public:
tuple() {}
tuple(Head v, Tail... vtail)
: m_head(v), inherited(vtail...) {}
...
protected:
Head m_head; // 每次取出的元素
}; 👈🏻不断的继承就可以实现不同类型的组合了
👈🏻不断的继承就可以实现不同类型的组合了
其余函数:
cpp
...
{
public:
...
Head head() { return m_head; }
inherited& tail() { return *this; } // 通过转型获得Tail部分
...
}; 一般不这么用
一般不这么用
出去head的41,剩下的都是tail部分,所以出来的是6.3
9.3 type traits
9.3.1 用例
GCC2.9中:
默认的 __type_traits 进行了一系列泛化 的设定(trivial 是不重要的意思)
cpp
struct __true_type {};
struct __false_type {};
template <class type>
struct __type_traits
{
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type; // Plain Old Data 类似C的struct
};还会通过特化来实现针对不同类型的设定,例
cpp
template <> struct __type_traits<int>
{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};C++11 中:
有了很多个 type traits,可以回答更多问题
测试:
cpp
cout << is_void<T>::value << endl;
cout << is_integral<T>::value << endl;
cout << is_floating_point<T>::value << endl;
cout << is_array<T>::value << endl;
...
不论是什么类型都可以自动检测 它的 traits,非常厉害!(里面有虚函数------就能自动检测出它有多态性)
9.3.2 原理
模板的作用
例 is_integral
依然是采用的一种问答的方式实现的
cpp
template <typename _Tp>
struct is_integral
:public __is_intagral_helper<typename remove_cv<_Tp>::type>::type
{ };首先 remove_cv(const 和 volatile)
cpp
// 通过偏特化实现remove const
template <typename _Tp>
struct remove_const
{ typedef _Tp type };
template <typename _Tp>
struct remove_const<_Tp const>
{ typedef _Tp type };
// remove volatile 同理再通过 __is_intagral_helper 进行问答
cpp
// 通过偏特化实现
template <typename>
struct __is_integral_helper
:public false_type { };
template <>
struct __is_integral_helper<bool>
:public true_type { };
template <>
struct __is_integral_helper<int>
:public true_type { };
template <>
struct __is_integral_helper<long>
:public true_type { };
...其他深入 class 内部的一些 traits 比如是否有虚函数,是否是一个类,是否是POD等等,其实现可能都与编译器有关
9.4 move
moveable class 中有:
cpp
// move ctor
MyString(MyString&& str) noexcept // 用&&与普通版本区别开
: _data(str._data), _len(str._len)
{
str._len = 0;
str._data = NULL; // 避免析构函数释放资源
}
// move assignment
MyString& operator=(MyString&& str) noexcept
{
if (this != &str)
{
_len = str._len;
_data = str._data;
str._len = 0;
str._data = NULL; // 避免析构函数释放资源
}
return *this;
}
// dtor
virtual ~MyString()
{
if(_data) delete _data; // 一定要检查
}
MyString C11(C1); // ctor
MyString C12(move(C1)); // move ctor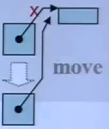 是浅拷贝,并且把之前的指向去除了
是浅拷贝,并且把之前的指向去除了
对于 vector 这样的容器,其用 move 就只是 swap 了三根指针,非常快!
move 之后原来的东西不能再使用
拿数据插入容器,用临时对象,编译器看到就会自动使用 move 版本的
MyString C11(C1);时,创建了一个实例 C11,编译器就不知道是否能用 move,就需要自己MyString C12(move(C1));使用 move,但注意之后一定不能用原来的C1
&&(右值引用)这是C++11引入的特性,右值引用用于处理临时对象或将资源所有权转移给其他对象,以提高性能和资源管理