
算法解析
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一组用于自动评估文本摘要质量的指标,主要通过比较机器生成的摘要与一个或多个参考摘要之间的重合程度来衡量。ROUGE 包括多个变体,其中最常用的有 ROUGE-N、ROUGE-L、ROUGE-W 和 ROUGE-S。下面将详细介绍这四种 ROUGE 测量方法的算法定义、它们之间的区别,并通过生动的例子来帮助理解。






Abstract
ROUGE 是 "Recall-Oriented Understudy for Gisting Evaluation"的缩写。它是一种通过将 AI 生成的摘要与人类创建的理想摘要进行比较来自动确定摘要质量的测量方法。这些测量方法计算计算机生成的待评估摘要与人类创建的理想摘要之间的重叠单位数量,如 n-gram、词序列和词对。本文介绍了四种不同的 ROUGE 测量方法:ROUGE-N、ROUGE-L、ROUGE-W 和 ROUGE-S 四种不同的 ROUGE 测量方法及其评估结果。其中三种已在 2004 年文档理解大会 (DUC) 上使用,这是 NIST 赞助的一次大规模摘要评估。
1. Introduction
传统的摘要评估包括人工对不同质量指标的判断,例如连贯性、简洁性、语法性、可读性和内容(Mani,2001)。然而,即使是像文档理解会议(DUC)(Over and Yen, 2003)那样,针对几个语言质量问题和内容覆盖范围对摘要进行大规模的简单人工评估,也需要花费超过 3000 个小时的人力。这不仅成本高昂,而且难以经常进行。因此,如何自动评估摘要近年来引起了摘要研究界的广泛关注。例如,Saggion 等人(2002 年)提出了三种基于内容的评估方法来衡量摘要之间的相似性。这些方法分别是:余弦相似度(cosine similarity)、单词重叠(unit overlap),即单字符串或大字符串和最长公共子序列(longest common subsequence)。
然而,他们并没有说明这些自动评估方法的结果与人类判断之间的关联。继 BLEU(Papineni 等人,2001 年)等自动评估方法成功应用于机器翻译评估之后,Lin 和 Hovy(2003 年)证明,与 BLEU 相似的方法,即 n-gram 共同出现统计法,也可用于评估摘要。
在本文中,我们介绍了一个用于自动评估摘要及其评估的软件包 ROUGE。ROUGE 是 Recall-Oriented Understudy for Gisting Evaluation 的缩写。它包括几种衡量摘要之间相似性的自动评估方法。我们将在第 2 节介绍 ROUGE-N,在第 3 节介绍 ROUGE-L,在第 4 节介绍 ROUGE-W,在第 5 节介绍 ROUGE-S。第 6 节利用 DUC 2001、2002 和 2003 数据说明了这些测量方法与人类判断的相关性。第 7 节是本文的结论,并讨论了未来的发展方向。
2. ROUGE-N: N-gram Co-Occurrence Statistics
形式上,ROUGE-N 是候选摘要与参考摘要集之间的 n-gram 召回率。ROUGE-N 的计算方法如下:
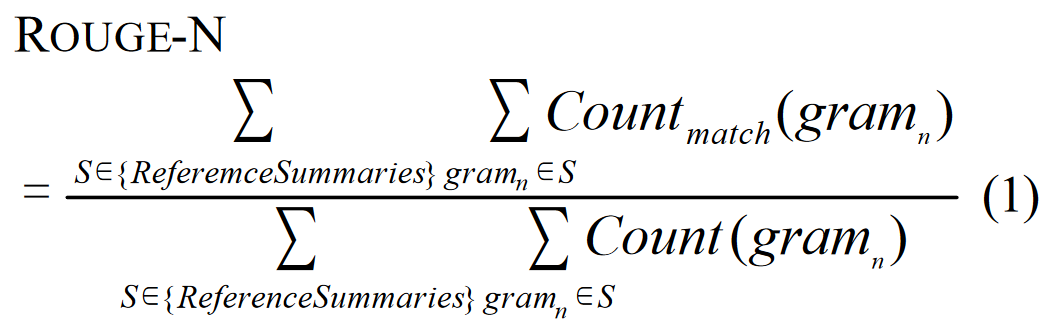
其中,n 代表 n-gram 的长度(gramn),Countmatch(gramn) 是候选摘要(candidate summary)和一组参考摘要(reference summaries)中共同出现的 n-gram 的最大数量。
很明显,ROUGE-N 是一种与召回率相关的测量方法,因为等式的分母是出现在参考摘要侧的 n-grams 数量的总和。机器翻译自动评估中使用的一个密切相关的指标 BLEU 是一种基于精确度的指标。BLEU 通过计算候选译文中与参考译文重叠的 n-grams 百分比来衡量候选译文与一组参考译文的匹配程度。有关 BLEU 的详细信息,请参见 Papineni 等人(2001 年)。
请注意,随着参考摘要的增加,ROUGE-N 公式分母中的 n-grams 数量也会增加。这既直观又合理,因为可能存在多个好的摘要。每当我们向参考摘要池中添加一个参考摘要,就会扩大备选摘要的空间。通过控制添加到参考摘要池中的参考摘要类型,我们可以设计出侧重于摘要不同方面的评估。还要注意的是,分母是所有参考文献摘要的总和。这就有效地提高了出现在多个参考文献中的匹配 n-gram 的权重。因此,ROUGE-N 方法更倾向于使用包含更多参考摘要共享词语的候选摘要。这也是非常直观和合理的,因为我们通常更喜欢与参考文献摘要中的共识更相似的候选摘要。
2.1. Multiple References
到目前为止,我们只演示了如何使用单个 reference 计算 ROUGE-N。当使用多个参考文献时,我们会计算候选摘要 s 与 reference 集中每个 ri 之间的成对摘要级 ROUGE-N。然后,我们取成对摘要级 ROUGE-N 分数的最大值作为最终的多参考 ROUGE-N 分数。其写法如下:
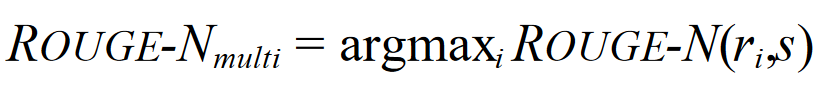
这个过程也适用于计算 ROUGE-L(第 3 节)、ROUGE-W(第 4 节)和 ROUGE-S(第 5 节)。在实现过程中,我们使用了积分法(Jackknifing)。给定 M 个参考文献,我们计算 M 集合中 M-1 参考文献的最佳得分。最终的 ROUGE-N 分数是使用不同 M-1 参考文献的 M 个 ROUGE-N 分数的平均值。由于我们经常需要比较系统和人工性能,而参考摘要通常是唯一可用的人工摘要,因此我们采用了积层假定(Jackknifing)程序。使用该程序,我们可以通过一个参考文献的 M ROUGE-N 分数与其余 M-1 参考文献的平均值来估算人类的平均性能。虽然当我们只想使用多个参考文献计算 ROUGE 分数时不需要 Jackknif ing 程序,但在 ROUGE 评估软件包中的所有 ROUGE 分数计算中都使用了该程序。
下一节,我们将介绍一种基于两个摘要之间最长公共子序列的 ROUGE 测量方法。
3. ROUGE-L: Longest Common Subs equence
一个序列 Z = z1, z2, ..., zn 是另一个序列 X = x1, x2, ..., xm 的子序列,如果存在一个 X 指数的严格递增序列 i1, i2, ..., ik,对于所有 j = 1, 2, ..., k,我们有 xij = zj(Cormen 等人,1989 年)。给定两个序列 X 和 Y,X 和 Y 的最长公共子序列(LCS)是具有最大长度的公共子序列。LCS 已被用于从平行文本中构建 N 个最佳翻译词典时识别候选同源词。Melamed(1995 年)使用两个词的 LCS 长度与两个词中较长单词长度之间的比率(LCSR)来衡量它们之间的同义性。他使用 LCS 作为近似字符串匹配算法。Saggion 等人(2002 年)在自动摘要评价中使用归一化的成对 LCS 来比较两个文本之间的相似性。
3.1. Sentence-Level LCS
在摘要评估中应用 LCS 时,我们将摘要句子视为单词序列。我们的直觉是,两个摘要句的 LCS 越长,这两个摘要就越相似。我们建议使用基于 LCS 的 Fmeasure 来估计长度为 m 的两个摘要句 X 和长度为 n 的两个摘要句 Y 之间的相似度,假设 X 是参考摘要句,Y 是候选摘要句,具体如下:
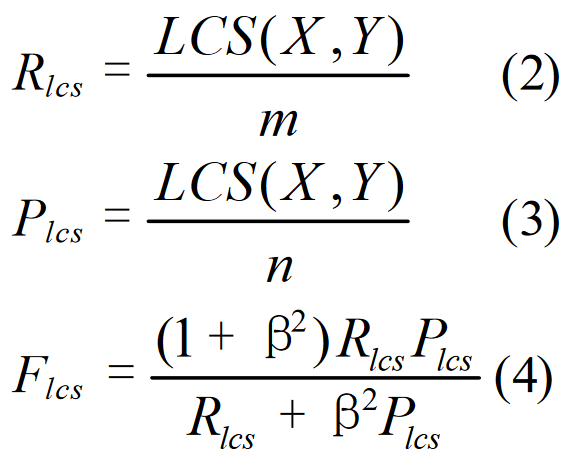
其中,LCS (X,Y) 是 X 和 Y 的最长公共子序列的长度,当 ?Flcs/?Rlcs = ?Flcs/?Plcs 时,ß = Plcs/Rlcs。在 DUC 中,ß 被设置为一个非常大的数字(? 8)。因此,只考虑 Rlcs。我们将基于 LCS 的 F 测量(即公式 4)称为 ROUGE-L。请注意,当 X = Y 时,ROUGE-L 为 1;而当 LCS(X,Y) = 0 时,ROUGE-L 为 0,即 X 和 Y 之间没有共同点。本例中的综合因子是基于 LCS 的召回率和精确率。Melamed 等人(2003 年)使用单字节 Fmeasure 估算机器翻译质量,结果表明单字节 Fmeasure 与 BLEU 一样好。
使用 LCS 的一个优点是,它不要求连续匹配,而是要求反映句子级词序的内序匹配 n-gram。另一个优点是,它能自动包含最长的序列内常见 n-gram,因此无需预定义 n-gram长度。
等式 4 中定义的 ROUGE-L 具有这样一个特性,即其值小于或等于 X 和 Y 的单字符 F 测量值的最小值。单词召回率反映了 X(参考摘要句子)中同时出现在 Y(候选摘要句子)中的单词比例;而单词精确率则是 Y 中同时出现在 X 中的单词比例。
ROUGE-L 只对序列内的非词块匹配进行评分,因此也能以自然的方式捕捉句子层面的结构。请看下面的例子:

为了便于解释,我们只考虑 ROUGE-2,即 N=2。以 S1 为参照句,S2 和 S3 为候选摘要句,S2 和 S3 的 ROUGE-2 得分相同,因为它们都有一个大字符串,即 "枪手"。然而,S2 和 S3 的含义却截然不同。在 ROUGE-L 中,S2 得分为 3/4 = 0.75,S3 得分为 2/4 = 0.5,ß = 1。因此,根据 ROUGE-L 标准,S2 优于 S3。这个例子还说明,ROUGE-L 可以在句子层面可靠地发挥作用。
但是,LCS 有一个缺点,那就是它只计算主要的序列内单词,因此,其他可供选择的 LCS 和较短的序列不会反映在最终得分中。例如,下面是一个候选句子:
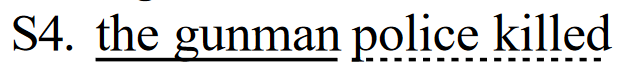
以 S1 为参照,LCS 只计算 "枪手 "或 "警察被杀",而不同时计算两者;因此,S4 的 ROUGE-L 得分与 S3 相同。与 S3 相比,ROUGE-2 更倾向于 S4。
3.2. Summary-Level LCS
上一节介绍了如何计算基于句子级 LCS 的 F-measure 分数。当应用到摘要层面时,我们取参考摘要句子 ri 和每个候选摘要句子 cj 之间的 LCS 匹配值。给定一个由 u 个句子(共包含 m 个单词)组成的参考摘要和一个由 v 个句子(共包含 n 个单词)组成的候选摘要,基于摘要级 LCS 的 F-measure 计算公式如下:
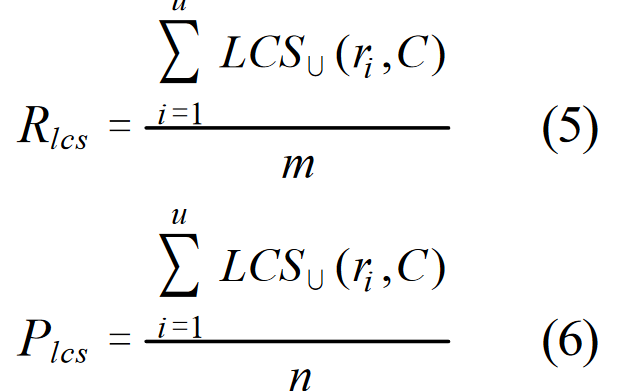
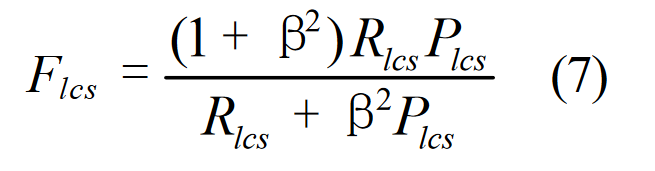
在 DUC 中,ß 又被设为一个很大的数字(? 8),即只考虑 Rlcs。LCS∪(ri , C) 是参考句 ri 和候选摘要 C 之间联合最长公共子序列的 LCS 得分。例如,如果 ri = w1 w2 w3 w4 w5,而 C 包含两个句子:c1 = w1 w2 w6 w7 w8 和 c2 = w1 w3 w8 w9 w5,那么 ri 和 c1 的最长公共子序列是 "w1 w2",而 ri 和 c2 的最长公共子序列是 "w1 w3 w5"。ri、c1 和 c2 的联合最长公共子序列为 "w1 w2 w3 w5",且 LCS∪(ri , C) = 4/5。
3.3. ROUGE-L vs. Normalized Pairwise LCS
Radev 等人(2002 年,第 51 页)提出的两个摘要 S1 和 S2 之间的归一化成对 LCS,LCS(S1 ,S2)MEAD 的写法如下:
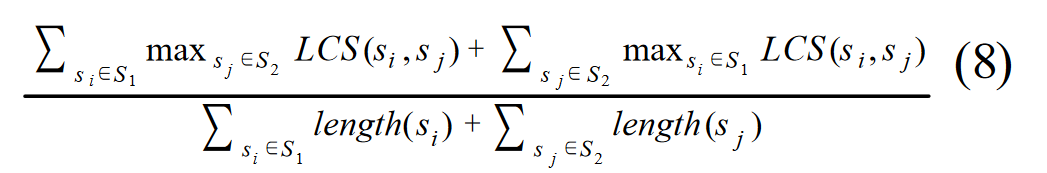
假设 S1 有 m 个字,S2 有 n 个字,由于对称性,等式 8 可改写为等式 9:
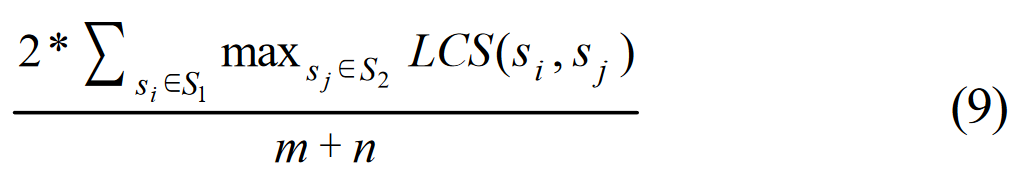
然后,我们对 MEAD LCS 的召回率(Rlcs-MEAD)和 MEAD LCS 的精确率(Plcs-MEAD)定义如下:

我们可以用常数 ß = 1 的 Rlcs-MEAD 和 Plcs-MEAD 对等式 (9) 进行如下重写:
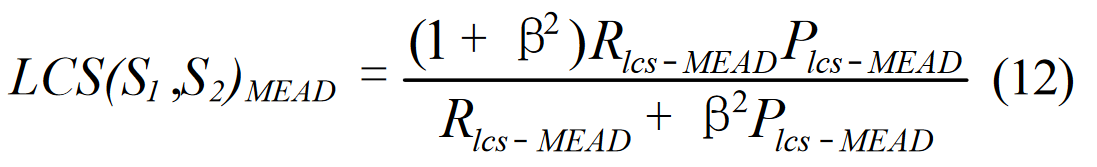
等式 12 表明,Radev 等人(2002 年)定义并在 MEAD 中实现的归一化成对 LCS 也是 ß = 1 时的 F 。句子级归一化配对的 LCS 与 ß = 1 时的 ROUGE-L 相同。除了设置 ß = 1 外,摘要级归一化成对 LCS 与 ROUGE-L 的不同之处还在于句子如何从其引用中获得 LCS 分数。归一化成对 LCS 采用最佳 LCS 得分,而 ROUGE-L 则采用联合 LCS 得分。
4. ROUGE-W: Weighted Longest Common Subsequence
正如我们在前面的章节中所描述的,LCS 具有许多很好的特性。遗憾的是,基本 LCS 也有一个问题,即它不能区分嵌入序列中不同空间关系的 LCS。例如,给定一个参考序列 X 和两个候选序列 Y1 和 Y2 如下:
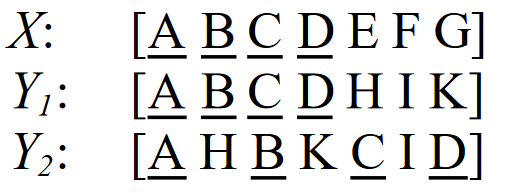
Y1 和 Y2 的 ROUGE-L 分数相同。但是,在这种情况下,Y1 应该比 Y2 更优,因为 Y1 有连续匹配。为了改进基本的 LCS 方法,我们可以简单地将迄今为止遇到的连续匹配长度记入计算 LCS 的常规二维动态程序表中。我们称之为加权 LCS(WLCS),并用 k 表示当前以单词 xi 和 yj 结尾的连续匹配长度。给定两个句子 X 和 Y,X 和 Y 的 WLCS 得分可通过以下动态编程过程计算:

其中,c 是动态编程表,c(i,j) 存储以 X 的词 xi 和 Y 的词 yj 结尾的 WLCS 得分,w 是存储以 c 表位置 i 和 j 结尾的连续匹配长度的表,f 是表位置 c(i,j) 的连续匹配函数。请注意,通过提供不同的加权函数 f,我们可以对 WLCS 算法进行参数化,为连续的序列内匹配分配不同的信用。
对于任何正整数 x 和 y,加权函数 f 必须具有 f(x+y) > f(x) + f(y) 的特性。换句话说,连续比赛的得分要高于非连续比赛。例如,当 k >= 0 且 α、β > 0 时,f(k)-=-αk - β。另一个可能的函数族是形式为 kα 的多项式函数族,其中 -α > 1。然而,为了规范 ROUGE-W 的最终得分,我们还倾向于使用具有近似形式反函数的函数。例如,f(k)-=-k2 有一个近似形式的反函数 f-1(k)-=-k1/2。给定两个长度为 m 的序列 X 和长度为 n 的序列 Y,基于 WLCS 的 F 测量可按如下方法计算:

其中 f -1 是 f 的反函数。在 DUC 中,ß 被设置为一个很大的数字(? 8)。因此,只考虑 ROUGE。我们将基于 WLCS 的 Fmeasure(即公式 15)称为 ROUGE-W。使用公式 15 和 f(k)-=-k2 作为加权函数,序列 Y1 和 Y2 的 ROUGE-W 分数分别为 0.571 和 0.286。因此,使用 WLCS,Y1 的排名会高于 Y2。我们使用 ROUGE 评估软件包中 kα 形式的多项式函数。下一节我们将介绍跳格共生统计。
5. ROUGE-S: Skip-Bigram Co-Occurrence Statistics
Skip-bigram 是指按句子顺序排列的任意一对单词,允许任意间隙。跳格共生统计测量候选译文与一组参考译文之间的跳格重叠度。以第 3.1 节中的例子为例:

每个句子都有 C42 = 6 个跳字。例如,S1 有以下跳格:

S2 与 S1 有三个跳格匹配("police the"、"police gunman"、"the gunman"),S3 与 S1 有一个跳格匹配("the gunman"),S4 与 S1 有两个跳格匹配("police kille d"、"the gunman")。给定长度为 m 的译文 X 和长度为 n 的译文 Y,假设 X 是参考译文,Y 是候选译文,我们计算基于跳格的 F-measure 如下:
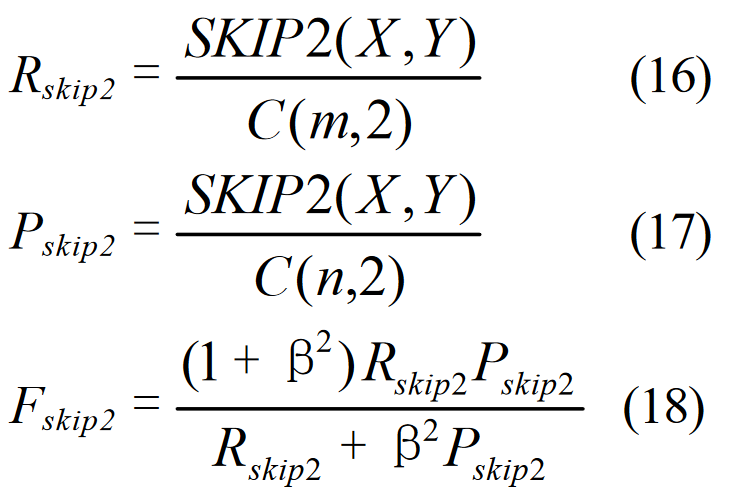
其中,SKIP2(X,Y) 是 X 和 Y 之间的跳格匹配数,ß 控制 Pskip2 和 Rskip2 的相对重要性,C 是组合函数。我们将基于跳格的 F-measure(即公式 18)称为 ROUGE-S。
使用等式 18,ß = 1,以 S1 为参照,S2 的 ROUGE-S 得分为 0.5,S3 为 0.167,S4 为 0.333。因此,S2 优于 S3 和 S4,S4 优于 S3。这一结果比使用 BLEU-2 和 ROUGE-L 更为直观。与 BLEU 相比,skip-bigram 的一个优点是它不需要连续匹配,但对词序仍然很敏感。将 skip-bigram 与 LCS 进行比较,skip-bigram 计算所有顺序匹配的词对,而 LCS 只计算一个最长公共子序列。
在不对词与词之间的距离进行任何限制的情况下使用跳越重构,"the "或 "of in "等虚假匹配可能会被算作有效匹配。为了减少这些虚假匹配,我们可以限制两个同序词之间的最大跳越距离(dskip)。例如,如果我们将 dskip 设为 0,那么 ROUGE-S 就等同于 bigram overlap Fmeasure。如果我们将 dskip 设为 4,那么只有相距最多 4 个词的词对才能形成跳越重构。
调整等式 16、17 和 18 以使用最大跳越距离限制非常简单:我们只计算最大跳越距离内的跳越图匹配数 SKIP2 (X,Y),并将等式 16 的分母 C(m,2) 和等式 17 的分母 C(n,2) 分别替换为参考图和候选图的实际跳越图数量。
5.1. ROUGE-SU: Extension of ROUGE-S
ROUGE-S 的一个潜在问题是,如果候选句子中没有任何词对与参考句子同时出现,它就不会给该句子任何评分。例如,以下句子的 ROUGE-S 得分为零:
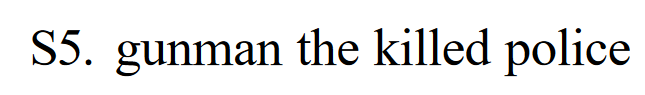
S5 与 S1 完全相反,两者之间不存在跳过 bigram 匹配。然而,我们希望将与 S5 相似的句子与那些与 S1 没有单词共现的句子区分开来。为此,我们对 ROUGE-S 进行了扩展,增加了单字符作为计数单位。扩展版本称为 ROUGE-SU。我们还可以通过在候选句和参考句的开头添加句首标记,从 ROUGE-S 中得到 ROUGE-SU。
6. Evaluations of ROUGE
为了评估 ROUGE 测量的有效性,我们计算了 ROUGE 分配的摘要得分与人工分配的摘要得分之间的相关性。我们的直觉是,好的评估方法应该给好的摘要打分,给差的摘要打分。基本事实是基于人类给出的分数。获取人工评判的成本通常很高;幸运的是,我们拥有 DUC 2001、2002 和 2003 年的评估数据,其中包括以下方面的人工评判:
-
100 字左右的单份文件摘要:2001 年 DUC 有 12 个系统 2,2002 年有 14 个系统。在 DUC 2001 中,每个系统评出了 149 份单一文件摘要,在 DUC 2002 中评出了 295 份。
-
单份文件非常简短的摘要,约 10 个字(类似标题、关键词或短语):DUC 2003 的 14 个系统。在 DUC 2003 中,每个系统评出了 624 篇超短摘要。
-
约 10 个字的多文件摘要:2002 年 DUC 的 6 个系统;50 个字:100 字:100 字:2001 年 DUC 的 14 个系统、2002 年 DUC 的 10 个系统和 2003 年 DUC 的 18 个系统;200 字:200 字:14 个 DUC 2001 系统和 10 个 DUC 2002 系统;400 字:400 字:14 个 DUC 2001 系统。在 DUC 2001 中,每个系统按摘要大小评出 29 篇摘要,在 DUC 2002 中评出 59 篇,在 DUC 2003 中评出 30 篇。
除了这些人工评判之外,我们还为 DUC 2001 准备了 3 套人工摘要,为 DUC 2002 准备了 2 套,为 DUC 2003 准备了 4 套。人工评委通过使用南加州大学信息科学研究所(ISI)开发的摘要评估环境3 (SEE),检查人工摘要单元(即基本话语单元或句子)与候选摘要之间的内容重叠百分比,从而为候选摘要分配内容覆盖分数。候选摘要的总分是人工摘要中所有单元内容覆盖得分的平均值。请注意,尽管有多个备选摘要,但人工评委在所有评估中只使用了一个人工摘要。
利用 DUC 数据,我们计算了系统的平均 ROUGE 分数与人工分配的平均覆盖率分数之间的皮尔逊积矩相关系数、斯皮尔曼等级相关系数和肯德尔相关系数(使用单个参考文献和多个参考文献)。为了研究词干化和包含或排除停止词的效果,我们还对原始自动摘要和 3 SEE 进行了实验,实验结果可在 http://www.isi.edu/~cyl 上在线查阅。人工摘要(CASE 集)、词干化4 版本的摘要(STEM 集)和停止版本的摘要(STOP 集)。例如,我们使用带有单一参考的 CASE 集计算了参加 DUC 2001 单篇文档摘要评估的 12 个系统的 ROUGE 分数,然后计算了这 12 个系统的 ROUGE 分数与人类指定的平均覆盖率分数的三个相关分数。之后,我们使用多个参考文献重复这一过程,然后使用 STEM 和 STOP 集。因此,我们为每个 ROUGE 指标和每个 DUC 任务收集了 2(多个或单个)x 3(CASE、STEM 或 STOP)x 3(Pearson、Spearman 或 Kendall)= 18 个数据点。为了评估结果的显著性,我们采用了引导重采样技术(Davison 和 Hinkley,1997 年)来估计每次相关计算的 95% 置信区间。
使用 ROUGE 评估软件包 v1.2.1 对每次运行的 17 个 ROUGE 测量进行了测试:ROUGE-N (N = 1 至 9)、ROUGE-L、ROUGE-W(加权系数 α = 1.2)、ROUGE-S 和 ROUGE-SU(最大跳越距离 dskip = 1、4 和 9)。由于篇幅有限,我们只报告基于皮尔逊相关系数的相关分析结果。基于斯皮尔曼(Spearman)和肯德尔(Kendall)相关系数的相关分析结果与皮尔逊相关系数非常接近,稍后将发布在 ROUGE 网站5 上,以供参考。皮尔逊相关系数的临界值6 为 0.632,置信度为 95%,自由度为 8。
表 1 显示了在 DUC 2001 和 2002 年 100 词单篇文档摘要数据中,17 个 ROUGE 测量值与人类判断的皮尔逊相关系数。每列中的最佳值用深色(绿色)标出,与最佳值在统计上相当的值用灰色标出。我们发现,在这个数据集中,相关性不受词干化或删除停止词的影响;在 ROUGE-N 变体中,ROUGE-2 的表现更好;ROUGE-L、ROUGE-W 和 ROUGE-S 的表现都很好;使用多个参考文献虽然对表现的提高不大,但也有所改善。在 DUC 2002 数据中,所有 ROUGE 测量结果都与人类判断有很好的相关性。这可能是由于 DUC 2002 中每个系统的样本量增加了一倍(DUC 2001 中为 295 个,而 DUC 2002 中为 149 个)。
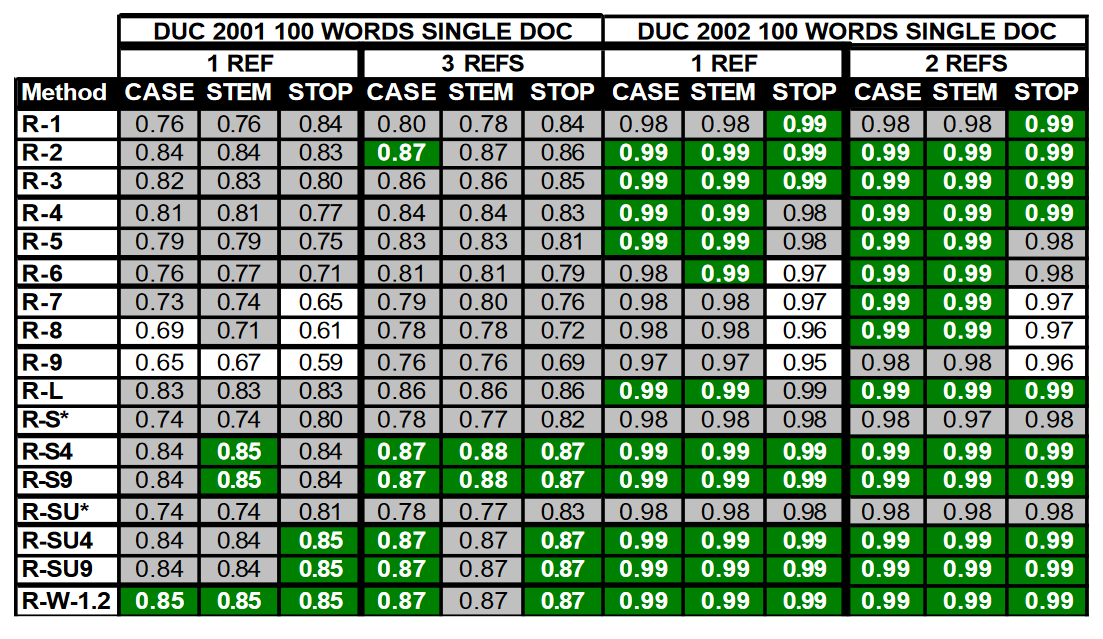
表 1:在 DUC 2001 和 2002 年 100 字单篇文档摘要任务中,17 项 ROUGE 测量得分与人判断的皮尔逊相关性
表 2 显示了对 DUC 2003 单文档极短摘要数据的相关性分析结果。我们发现,ROUGE-1、ROUGE-L 和 ROUGE-SU4 和 9 以及 ROUGE-W 是非常好的测量方法,而 N > 1 的 ROUGE-N 的表现明显差于所有其他测量方法,除 ROUGE-1 外,排除停止词一般都能提高性能。由于该数据集中的样本数量较多(624 个),使用多个参考文献并不能提高相关性。
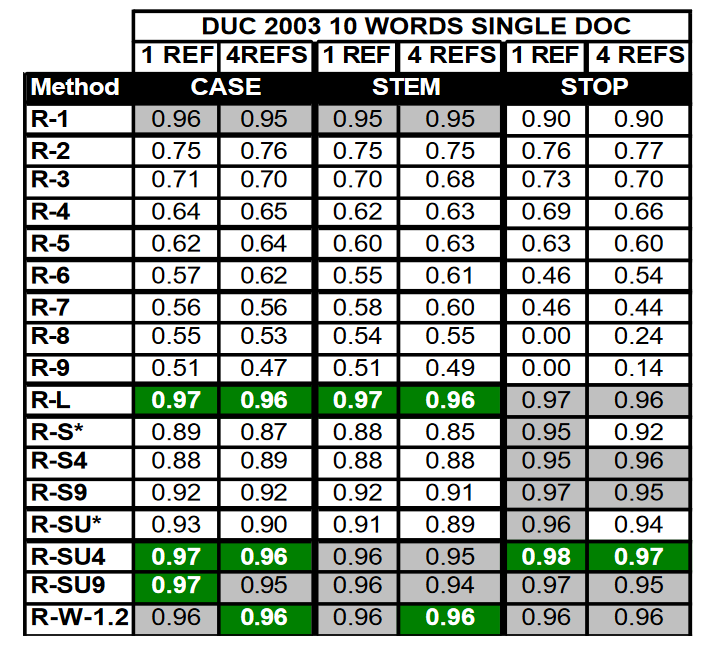
表 2:在 DUC 2003 极简短摘要任务中,17 项 ROUGE 测量得分与人类判断的皮尔逊相关性
表 3 中的 A1、A2 和 A3 显示了 DUC 2001、2002 和 2003 年 100 词多文档摘要数据的相关性分析结果。结果表明,使用多个参考文献可以提高相关性,而排除停顿词通常可以提高性能。ROUGE-1、2 和 3 性能良好,但不一致。ROUGE-1 、ROUGE-S4、ROUGE-SU4、ROUGE-S9 和 ROUGESU9 在去除停顿词后的相关性超过了 0.70。ROUGE-L 和 ROUGE-W 在这组数据中效果不佳。
表 3 中的 C、D1、D2、E1、E2 和 F 显示了使用多参考文献对 DUC 其余数据进行的相关性分析。这些结果再次表明,在 50 个词的多文档摘要中,剔除定语从句的效果更好。在长摘要任务(即 200 字和 400 字摘要)中观察到了更好的相关性(> 0.70)。ROUGE 测量的相对性能与 100 词多文档摘要任务的模式相同。
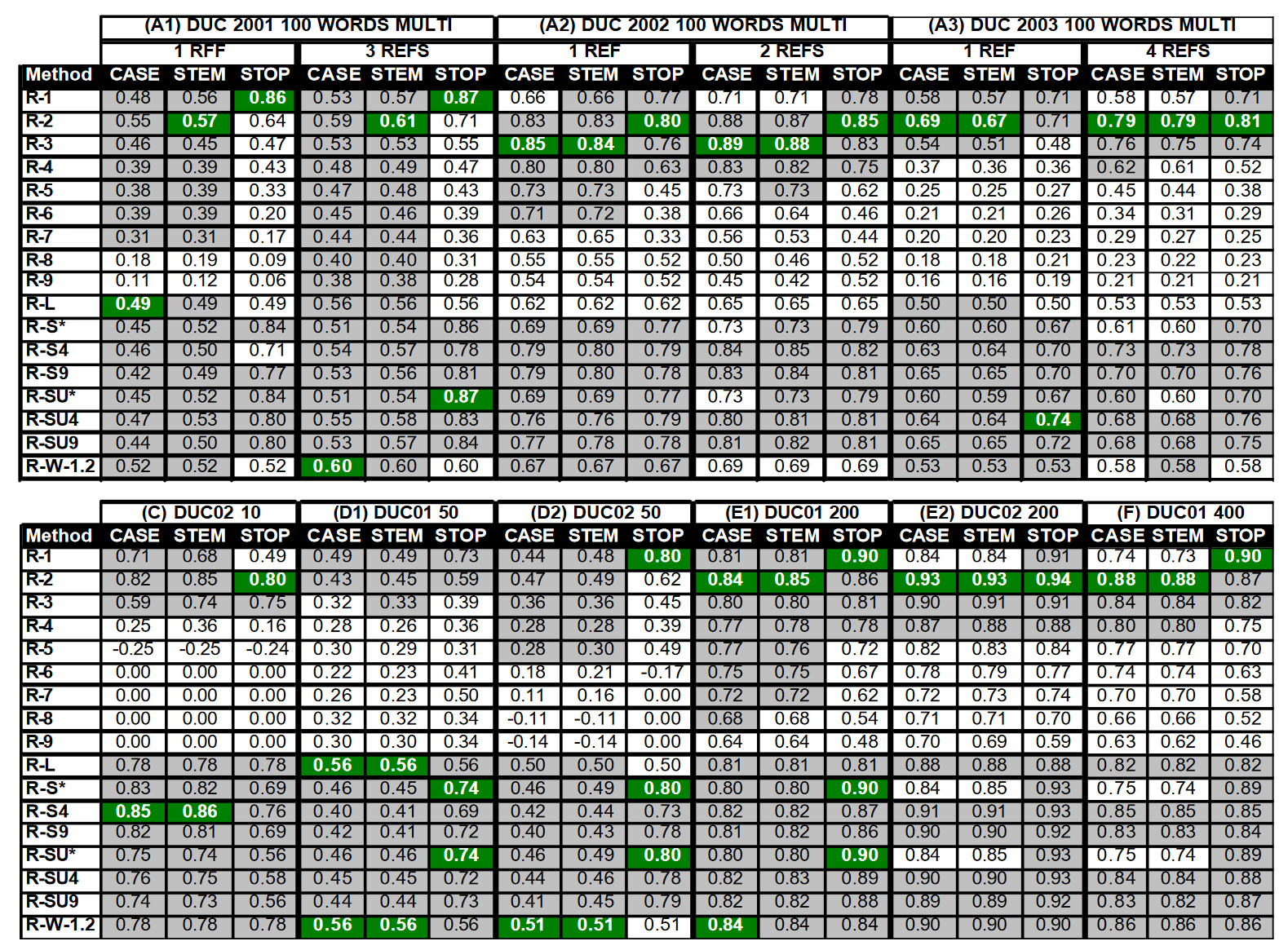
表 3:在 DUC 2001、2002 和 2003 多文档摘要任务中,17 项 ROUGE 测量得分与人判断的皮尔逊相关性
将表 3 中的结果与表 1 和表 2 进行比较,我们发现除了长摘要任务外,多文档任务中的相关值很少达到 90% 以上。造成这种结果的一个可能原因是我们在多文档任务中没有大量的样本。在单文档摘要任务中,我们有 100 多个样本;而在多文档任务中,我们只有大约 30 个样本。唯一超过 30 个样本的任务来自 DUC 2002,在 100 词摘要任务中,ROUGE 测量与人类判断的相关性比 DUC 2001 和 2003 中的类似任务要好得多,也更稳定。由于缺乏样本,可能无法获得统计上稳定的人类对系统性能的判断,这反过来又造成了相关性分析的不稳定性。
7. Conclusions
在本文中,我们介绍了用于总结摘要的自动评估软件包 ROUGE,并使用三年的 DUC 数据对 ROUGE 软件包中的自动测量方法进行了全面评估。为了检验结果的显著性,我们使用引导重采样法估计了相关性的置信区间。我们发现:
-
ROUGE-2、ROUGE-L、ROUGE-W 和 ROUGE-S 在单篇文档摘要任务中表现出色;
-
ROUGE-1、ROUGE-L、ROUGE-W、ROUGE-SU4 和 ROUGE-SU9 在评估非常短的摘要(或类似标题的摘要)时表现出色
-
ROUGE-1 和 ROUGE-S 在多文档摘要任务中很难达到 90% 以上的相关性、ROUGE-1、ROUGE-2、ROUGE-S4、ROUGE-S9、ROUGE-SU4 和 ROUGE-SU9 在排除停止词匹配的情况下工作得相当好
-
排除 stopwords 通常会提高相关性
-
使用多个参考文献会提高与人类判断的相关性
总之,我们证明了 ROUGE 软件包可以有效地用于摘要的自动评估。在另一项研究中(Lin 和 Och,2004 年),我们发现了 ROUGE 软件包在自动评估摘要中的应用、在机器翻译的自动评估中,ROUGE-L、W 和 S 也被证明非常有效。作者在(Lin,2004)中报告了 ROUGE 在不同样本量下的稳定性和可靠性。然而,如何在多文档摘要任务中实现与人类判断的高度相关性,就像 ROUGE 在单文档摘要任务中已经做到的那样,仍然是一个开放的研究课题。