1. 前言
Elasticsearch数据搜索和关系型数据库的SQL查询最显著的区别就是:除了精准匹配和模糊查询,Elasticsearch还具备全文检索的能力,而全文检索的核心是文本分析。
文本分析会将长文本内容进行字符过滤和细粒度的分词,先将长文本里面一些无关紧要的字符给过滤掉,再按照语义将长文本切分为一个个单独的词,然后可能还会根据切分后的词再添加一些同义词,最终构建倒排索引用于全文检索 。
文本分析使得Elasticsearch能够执行全文检索召回相关的文档,而不仅仅是是精准匹配。如下示例,当用户搜索"苹果"二字,召回下面三个文档在ES看来都是合理的:
json
{
"_id":"1",
"text":"什么品种的苹果更好吃呢?"
}
{
"_id":"2",
"text":"Apple Store上海静安店今日开业!"
}
{
"_id":"3",
"text":"番茄是水果还是蔬菜?"
}1号文档召回是因为直接有"苹果"二字、2号文档召回可以理解为"Apple"和"苹果"是同义词、3号文档召回有点意外,如果分词的粒度很细就会导致"果"字被切分为一个单独的词,从而和搜索词匹配成功。
全文检索时,如果Elasticsearch没有召回预期的文档,就应该检查一下文本分析器的配置是否合理。
2. 分析器的构成
Elasticsearch规定,文本分析器由三个基本组件构成,分别是:
- 0个或多个字符过滤器 character filters
- 一个分词器 tokenizer
- 0个或多个分词过滤器 token filters
2.1 字符过滤器
字符过滤器接收作为字符流的原始文本,并可以通过添加、删除或更改字符来转换该流。简单来说,就是字符过滤器可以在原始文本的基础上,做一些字符过滤、删除、替换等操作,在分词前做一些预处理的工作。
例如,字符过滤器可以把"&"符号替换成"and"、也可以去除HTML中的标签,保留文本内容。
Elasticsearch内置了三种字符过滤器,下面分别介绍。
html_strip 用于过滤HTML元素标签,如下示例,结果自动过滤掉了
和标签
json
POST _analyze
{
"char_filter": [
{
"type": "html_strip"
}
],
"text": "<p><b>听我说</b>谢谢你,因为有你</p>"
}
{
"tokens": [
{
"token": """
听我说谢谢你,因为有你
""",
"start_offset": 0,
"end_offset": 25,
"type": "word",
"position": 0
}
]
}mapping 用于替换字符,给定一个mappings数组,Elasticsearch扫描原始文本时每当遇到相同的Key就会替换成指定的Value。如下示例:
json
POST _analyze
{
"char_filter": [
{
"type": "mapping",
"mappings": [
"& => 和",
":) => 开心",
":( => 悲伤"
]
}
],
"text": "我&你独自:),独自:("
}
{
"tokens": [
{
"token": "我和你独自开心,独自悲伤",
"start_offset": 0,
"end_offset": 12,
"type": "word",
"position": 0
}
]
}pattern_replace 使用正则表达式来匹配和替换字符,比如可以给重要信息如身份证号脱敏:
json
POST _analyze
{
"char_filter": [
{
"type": "pattern_replace",
"pattern":"(\\d{6})\\d{8}(\\d{4})",
"replacement":"$1******$2"
}
],
"text": "The ID number is:362330199001012345"
}
{
"tokens": [
{
"token": "The ID number is:362330******2345",
"start_offset": 0,
"end_offset": 35,
"type": "word",
"position": 0
}
]
}2.2 分词器
分词器接收一个被字符过滤器预处理后的字符流作为输入,它是文本分析最重要的一个环节,直接决定了一段长文本会按照怎样的算法来切分成一个个分词。
除了切分文本,分词器还会保留以下信息:
- 每个分词的相对位置,用于短语搜索和单词临近搜索
- 字符偏移量,记录分词在原始文本中的出现的位置
- 分词类型,记录分词的种类,是单词还是数字等
Elasticsearch 内置了大量的面向单词的分词器
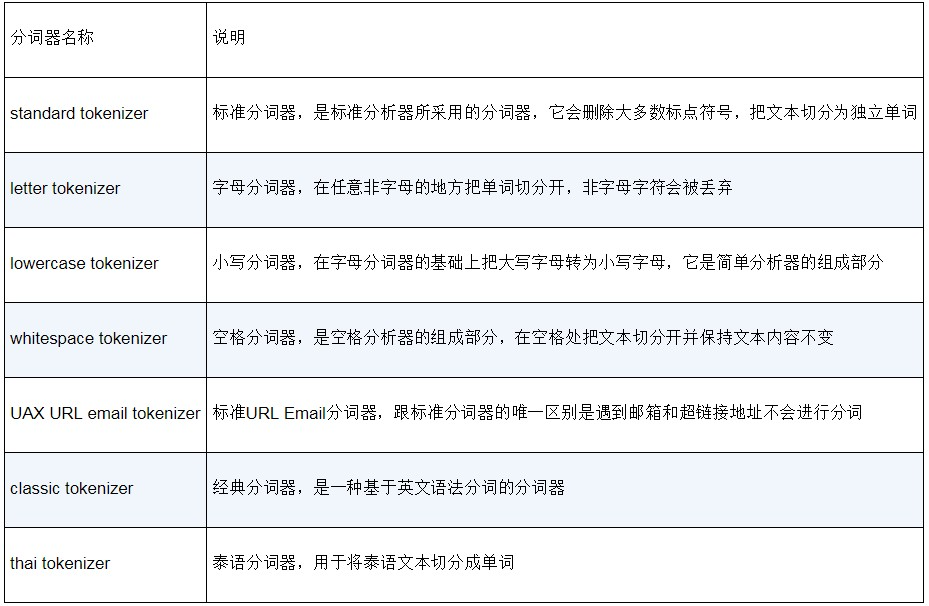
以 standard 为例,它也是默认的分词器。它会按照Unicode文本分割算法定义的词边界将文本划分为术语,并且删除了大多数标点符号。对于英文,它会按照空格来分词;对于中文,它会按照一个个汉字来分词。
如下示例,对于英文分词效果还行,针对中文效果就不好了,切分成一个个汉字丢失了词意。
json
POST _analyze
{
"tokenizer":"standard",
"text": "I am from China.我爱中国"
}
分词结果
["I","am","from","China","我","爱","中","国"]Elasticsearch 还内置了一些比较特殊的分词器:N-Gram Tokenizer,也叫 N元语法分词器。它会将单词分解成更小的片段,用于部分单词匹配,缺点是分词数量太多,占用更多的存储空间。
json
POST _analyze
{
"tokenizer":{
"type":"ngram",
"min_gram":2, // 分词最小长度
"max_gram":3, // 分词最大长度
"token_chars":["letter"] // 只切分字母
},
"text": "Elasticsearch 666"
}
分词结果
["se","sea","ea","ear","ar","arc","rc","rch","ch"]此外,Elasticsearch还内置了一些用于结构化文本的分词器,比如:keyword 是一个什么也不做的分词器,它的分词结果就是原始文本。
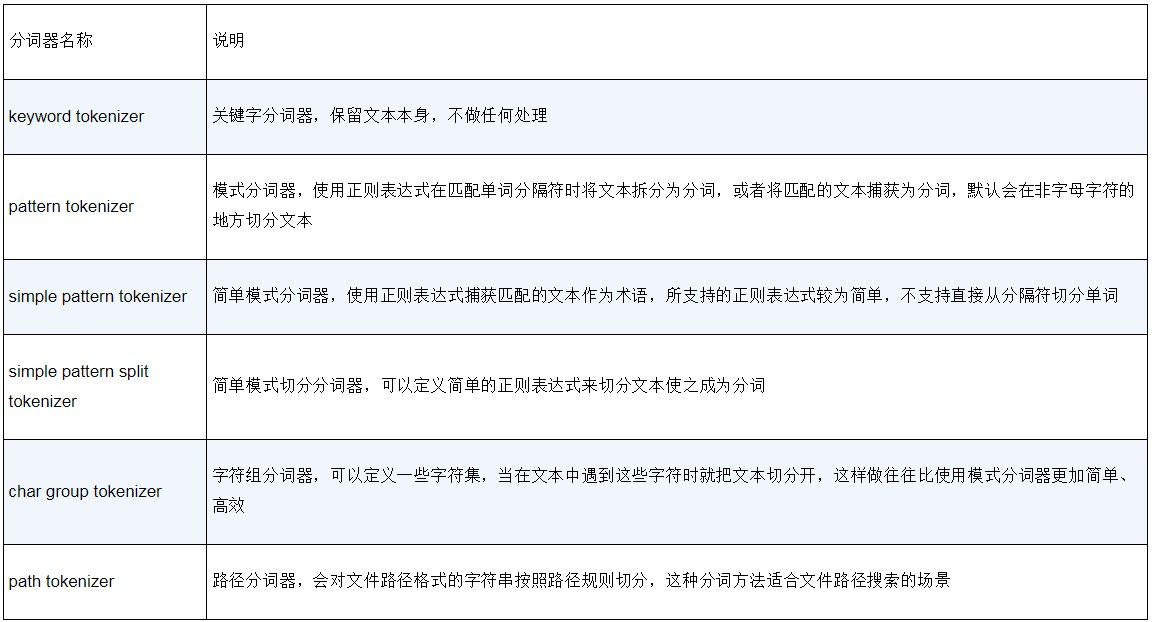
char_group 分词器会根据给定的字符集对原始文本做切分,它比正则表达式的效率要高,适用于分词规则简单的场景。
json
POST _analyze
{
"tokenizer":{
"type":"char_group",
"tokenize_on_chars":["_"]
},
"text": "I_am_from_China"
}
分词结果
["I","am","from","China"]再比如,path_hierarchy 会按照路径分隔符做分词,并输出每个子路径的分词结果。如下示例:
json
POST _analyze
{
"tokenizer":{
"type":"path_hierarchy"
},
"text": "/users/admin/a.txt"
}
分词结果
["/users","/users/admin","/users/admin/a.txt"]2.3 分词过滤器
分词过滤器接收来自分词器切分后的文本作为输入,并做最后处理。包括:改写词(转换大小写)、删除停用词、添加同义词等操作。
截止Elasticsearch8.13版本,官方内置了几十种分词过滤器,这里只介绍几个,其它参考官方文档。
apostrophe 分词过滤器会删除撇号后面的所有字符,包括撇号本身,适用于土耳其语。如下示例:
json
POST _analyze
{
"tokenizer":"standard",
"filter":["apostrophe"],
"text": "I'm 18 years old now"
}
分词结果
["I","18","years","old","now"]reverse 分词过滤器会反转切分后的每个词,这对于后缀检索非常有用。如下示例:
json
POST _analyze
{
"tokenizer":"standard",
"filter":["reverse"],
"text": "hello world"
}
分词结果
["olleh","dlrow"]stemmer 分词过滤器会根据分词的单词去掉复数、时态等,统一转换成对应的原型,这在英文搜索时非常有用。如下示例:
json
POST _analyze
{
"tokenizer":"standard",
"filter":["stemmer"],
"text": "they flying peoples"
}
分词结果
["thei","fly","peopl"]stop 分词过滤器器会删除分词中无意义的停用词,比如冠词、介词等,还可以自定义停用词黑名单。
如下示例,过滤后只保留了"apple"
json
POST _analyze
{
"tokenizer":"standard",
"filter":["stop"],
"text": "this is an apple"
}
分词结果
["apple"]3. 自定义分析器
Elasticsearch规定,任何分析器都由0个或多个字符过滤器、1个分词器、0个或多个分词过滤器组成,官方内置了大量的基础组件,同时又基于这些基础组件定义了一堆内置的分析器。如果这些内置分析器不能够满足我们的需求,我们也可以任意搭配组合定制化一个分析器。
假设,我们现在创建一个questions索引,用来索引问题,然后可以根据关键词搜索问题。question字段使用text类型,同时使用我们自定义的文本分析器my_analyzer。
假设自定义的文本分析器需要满足下列需求:
- 自动过滤掉文本中的标点符号
- 简单点,针对"/"符号来做分词吧
- 自动过滤掉一些无意义的停用词,例如:"的"、"啊"
- 使用同义词也能搜索到文档,例如搜索"Android"可以召回含"安卓"的文档
基于以上需求,我们可以先从字符过滤器、分词器、分词过滤器的顺序来慢慢调试我们的分析器。这里可以用到Elasticsearch提供的「_analyze」端点,它可以很方便的用来测试分析器的效果。
过滤标点符号可以用"mapping"实现,分词就用"char_group",删除停用词用"stop",最后同义词可以用"synonym"实现,最终自定义分析器的配置如下:
json
POST _analyze
{
"char_filter": [
{
"type": "mapping",
"mappings": [
", => ",
"。 => ",
"? => "
]
}
],
"tokenizer": {
"type": "char_group",
"tokenize_on_chars": ["/"]
},
"filter":[
{
"type":"stop",
"stopwords":["的","呢","和"]
},
{
"type":"synonym",
"synonyms":[
"安卓 => 安卓,Android",
"鸿蒙 => 鸿蒙,HarmonyOS,OpenHarmony"
]
}
],
"text": "鸿蒙/系统/和/安卓/系统/有/什么/区别/呢/?"
}测试一下,分词结果如下所示,符合我们的需求:
json
["鸿蒙","HarmonyOS","OpenHarmony","系统","安卓","Android","系统","有","什么","区别"]接下来就是创建索引时,指定我们自定义的分析器即可:
json
PUT questions
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"char_filter": [
"my_char_filter"
],
"tokenizer": "my_char_group",
"filter": [
"stop_filter",
"synonym_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
", => ",
"。 => ",
"? => "
]
}
},
"tokenizer": {
"my_char_group": {
"type": "char_group",
"tokenize_on_chars": [
"/"
]
}
},
"filter": {
"stop_filter": {
"type": "stop",
"stopwords": [
"的",
"呢",
"和"
]
},
"synonym_filter": {
"type": "synonym",
"synonyms": [
"安卓 => 安卓,Android",
"鸿蒙 => 鸿蒙,HarmonyOS,OpenHarmony"
]
}
}
}
},
"mappings": {
"properties": {
"question": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "my_analyzer"
}
}
}
}索引一篇文档
json
POST questions/_doc
{
"question":"鸿蒙/系统/和/安卓/系统/有/什么/区别/呢/?"
}搜索"Android",发现成功召回了预期的文档
json
GET questions/_search
{
"query": {
"match": {
"question": "Android"
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.32792777,
"hits": [
{
"_index": "questions",
"_id": "y-SQx44BPIYet_3fDf9T",
"_score": 0.32792777,
"_source": {
"question": "鸿蒙/系统/和/安卓/系统/有/什么/区别/呢/?"
}
}
]
}
}4. IK中文分析器
无论是Elasticsearch官方提供的分析器,还是我们自定义的分析器,都很难对中文内容有很好的分词效果,把一段中文切分成孤立的汉字会丢失语义。所以,我们需要一款针对中文的文本分析器,这里推荐 IK Analysis。
IK分析器需要单独安装,进入到Github页面:https://github.com/infinilabs/analysis-ik/releases,找到对应版本下载安装包放到Elasticsearch安装目录下的plugins目录,重启Elasticsearch即可使用。
IK Analysis 提供了两种中文分析器供我们使用,分别是:ik_max_word和ik_smart。
ik_max_word 切分的粒度更细,ik_smart 切分的粒度会粗一下,占用的存储空间也会相对少一些。一般推荐索引时使用ik_smart节省存储空间,搜索时使用 ik_max_word 切分出更多的词以便能搜索到结果。
如下示例,是ik_max_word的分词效果,分出10个词
json
POST _analyze
{
"analyzer":"ik_max_word",
"text": "ik_max_word分词器的测试效果"
}
分词结果
["ik_max_word","ik","max","word","分词器","分词","器","的","测试","效果"]下面是ik_smart的分词效果,只切分出5个词
json
POST _analyze
{
"analyzer":"ik_smart",
"text": "ik_smart分词器的测试效果"
}
分词结果
["ik_smart","分词器","的","测试","效果"]