目录
前言
- 这篇博客是ElasticSearch的第二篇,篇一主要讲解ElasticSearch的基础概念和原理,以及索引库和文档基本操作ElasticSearch篇一,这一篇主要讲解springboot整合ElasticSearch实践,如果还未安装部署rabbitMQ,可以参考我的这篇博客centos7用docker compose 快速部署 Elasticsearch + Kibana。
- RestHighLevelClient 是 Elasticsearch 官方提供的 Java 高级 REST 客户端,用于与 Elasticsearch 集群进行通信。它基于低级客户端构建,提供了更友好的 API 接口,支持完整的 Elasticsearch 功能。
初始化RestClient
-
引入依赖:
xml<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency>由于pringBoot默认的ES版本是7.17.10,如果需要其他版本,直接在本地pom文件在标签中指定新版本。
xml<properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> <elasticsearch.version>7.12.1</elasticsearch.version> </properties> -
将ElasticSearch客户端bean注入容器中
javapublic ElasticSearchConfig{ @Bean public RestHighLevelClient restHighLevelClient(){ RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200") )); } }
索引库操作
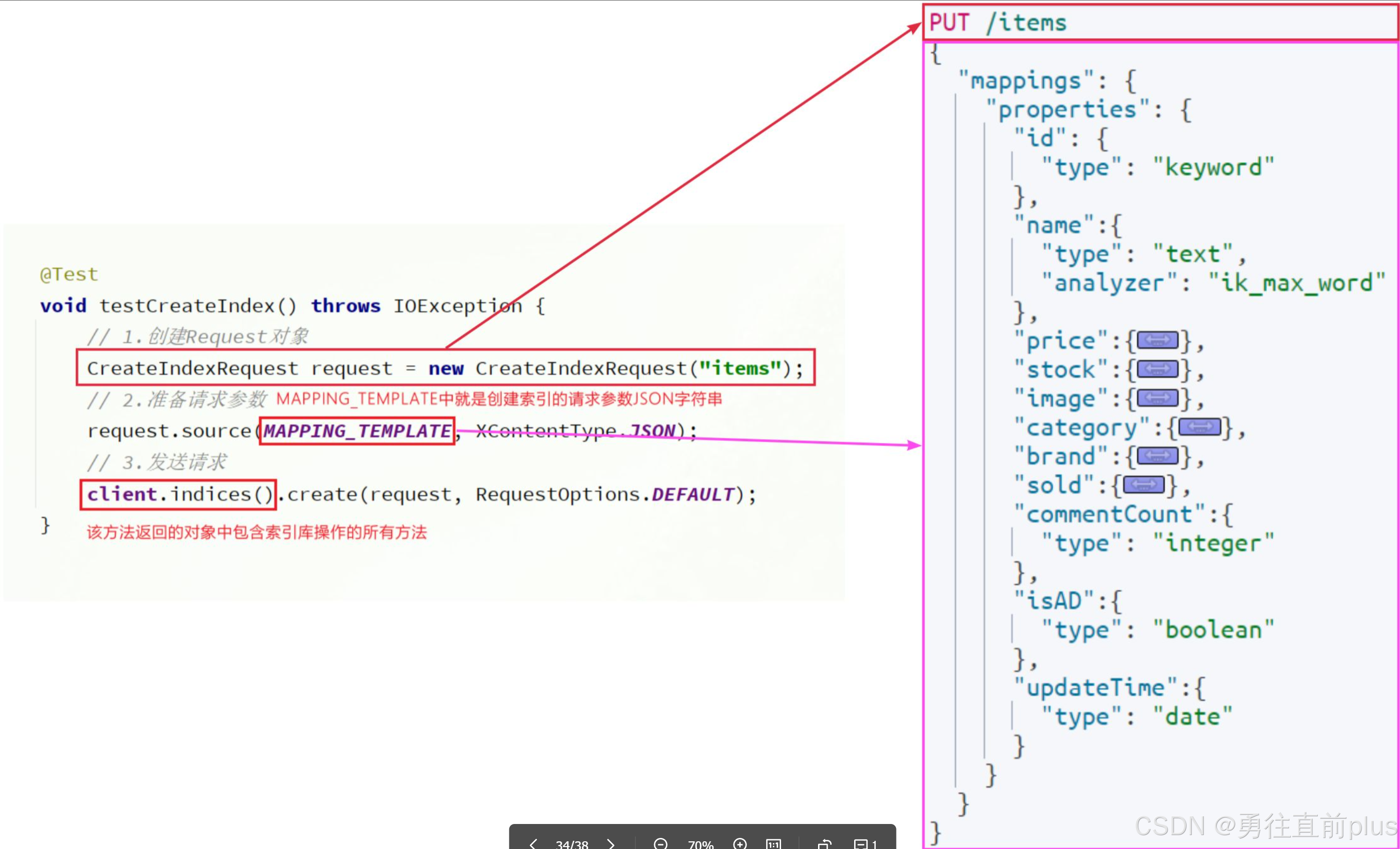
创建索引库
删除索引库
java
@Test
void testDeleteIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}判断索引库是否存在
java
@Test
void testExistsIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("items");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}文档操作
新增文档

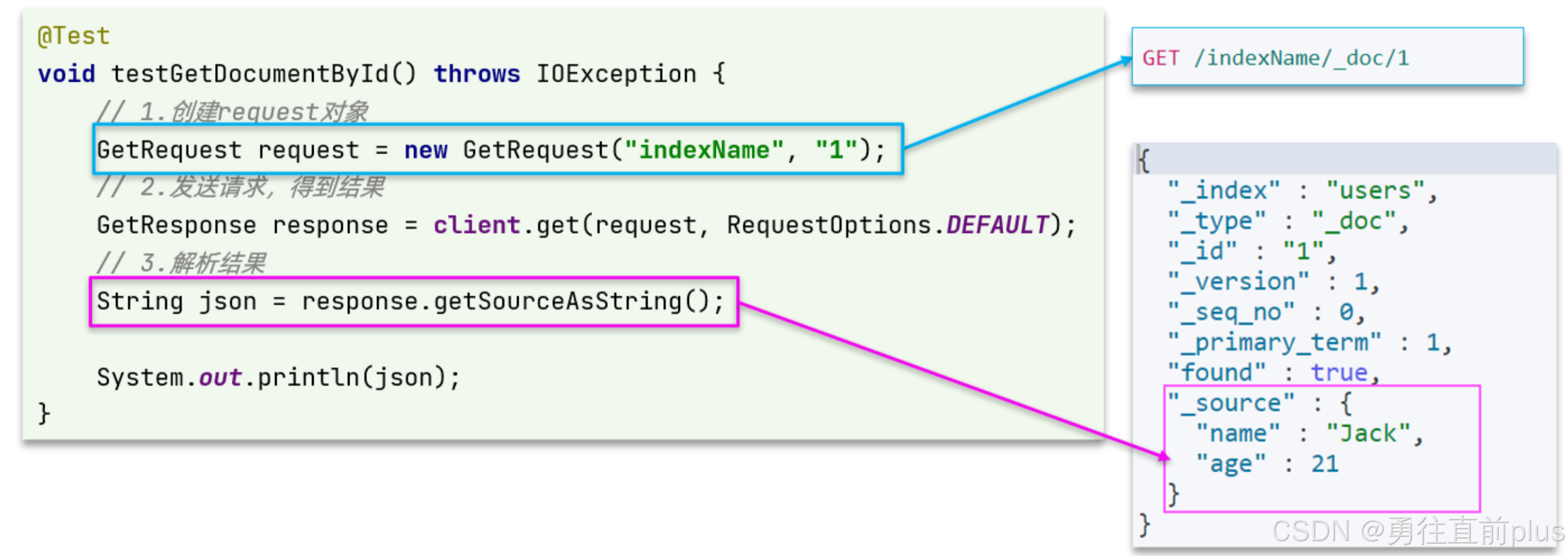
查询文档
删除文档
java
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request,两个参数,第一个是索引库名,第二个是文档id
DeleteRequest request = new DeleteRequest("item", "100002644680");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
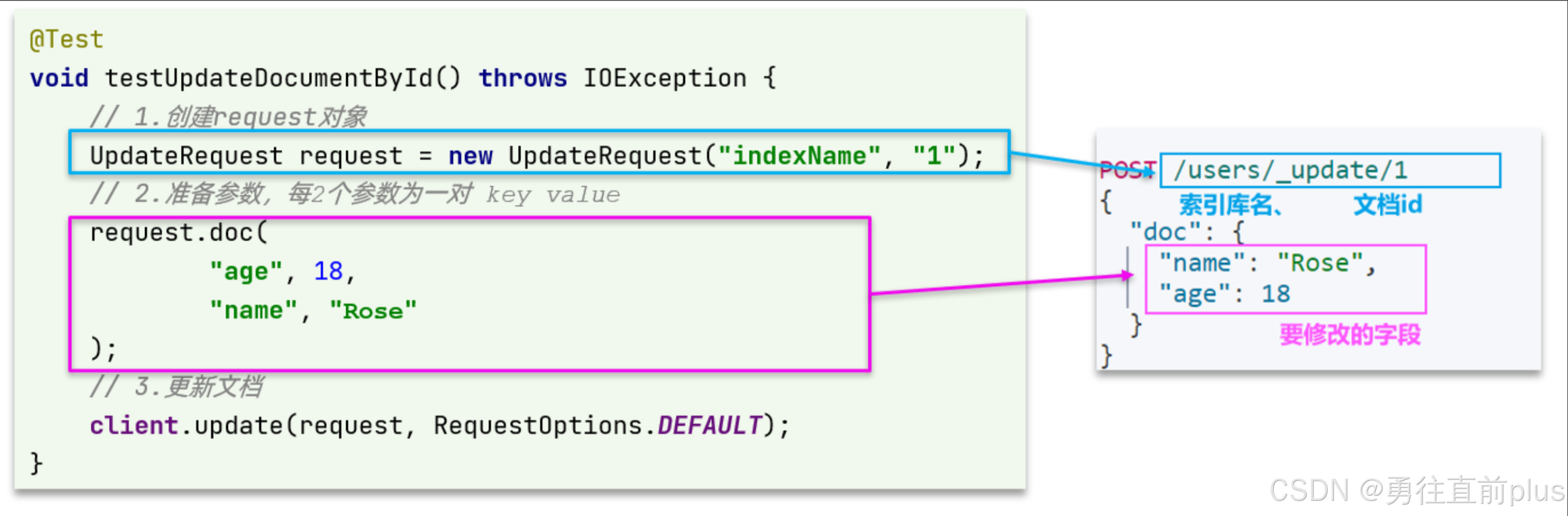
}修改文档
如果是全量修改,与新增API一样,判断依据是id,如果id存在,则是修改,如果不存在,则新增。
这里我们主要关注增量修改。
批处理
-
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送
 java
java@Test void testBulk() throws IOException { // 1.创建Request BulkRequest request = new BulkRequest(); // 2.准备请求参数 request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON)); request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON)); // 3.发送请求 client.bulk(request, RequestOptions.DEFAULT); }
DSL检索(RestClient查询)
- 我们同样可以利用RestHighLevelClient 客户端发送复杂的DSL语句查询
快速入门
发送请求
- 由于Elasticsearch对外暴露的接口都是Restful风格的接口,因此JavaAPI调用就是在发送Http请求。而我们核心要做的就是利用利用Java代码组织请求参数,解析响应结果。
- 第一步,创建SearchRequest对象,指定索引库名、
- 第二步,利用request.source()构建DSL请求体,DSL中可以包含查询、分页、排序、高亮

- 这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能:
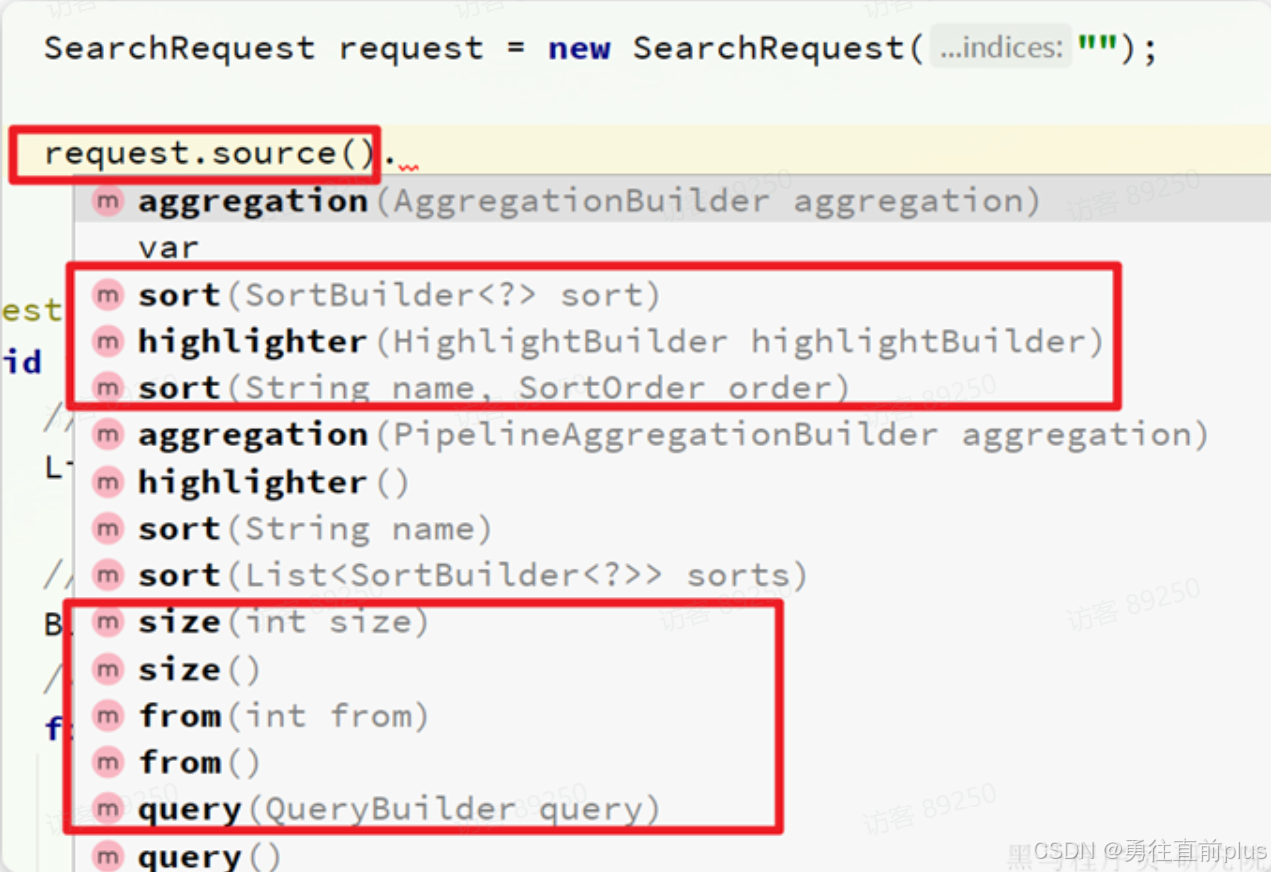
- 另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询、复合查询等:

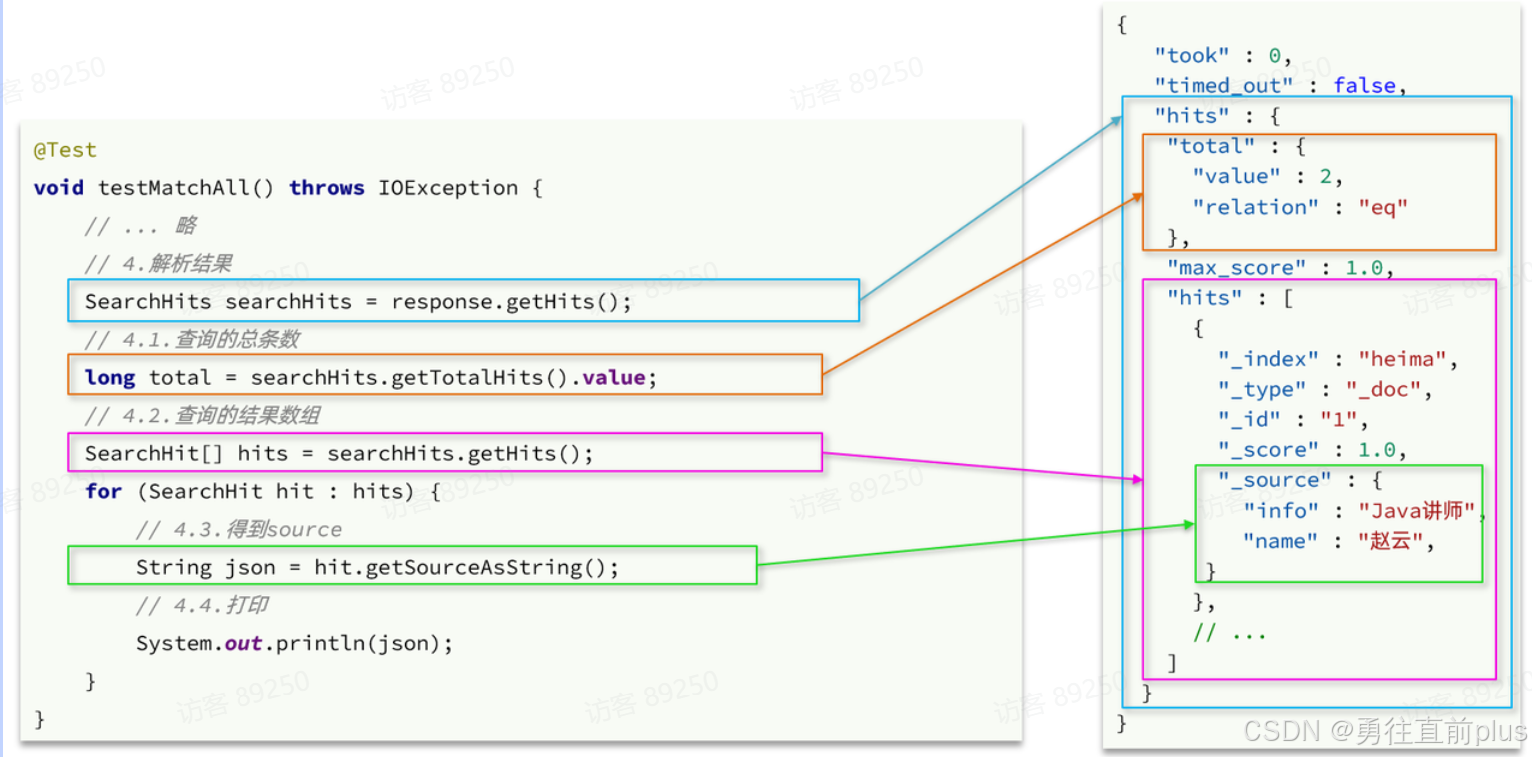
解析响应结果
- 在发送请求以后,得到了响应结果SearchResponse,这个类的结构与我们在kibana中看到的响应结果JSON结构完全一致:
叶子查询
-
所有的查询条件都是由QueryBuilders来构建的,叶子查询和复合查询都是这样。因此整套代码中变化的部分仅仅是query条件构造的方式,其它不动。
java@Test void testMatch() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } -
再比如multi_match查询:
java@Test void testMultiMatch() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } -
还有range查询:
java@Test void testRange() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000)); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } -
还有term查询:
java@Test void testTerm() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.termQuery("brand", "华为")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); }
复合查询
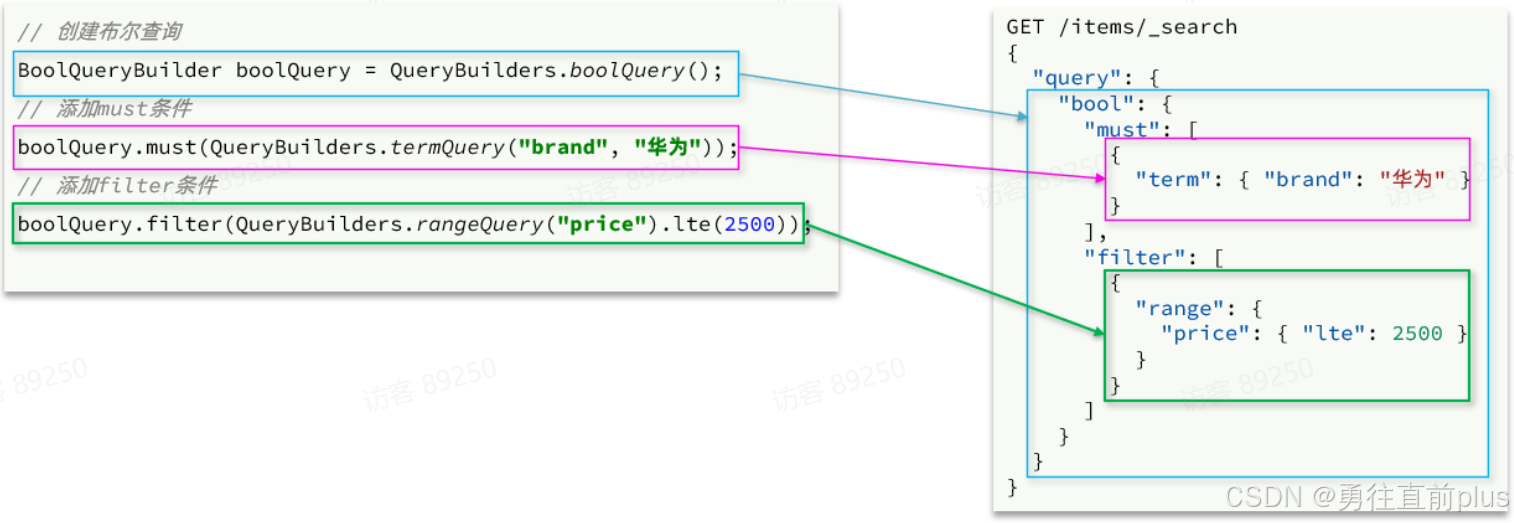
-
复合查询(bool查询)也是由QueryBuilders来构建
-
完整代码如下:
java@Test void testBool() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 // 2.1.准备bool查询 BoolQueryBuilder bool = QueryBuilders.boolQuery(); // 2.2.关键字搜索 bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶")); // 2.3.品牌过滤 bool.filter(QueryBuilders.termQuery("brand", "德亚")); // 2.4.价格过滤 bool.filter(QueryBuilders.rangeQuery("price").lte(30000)); request.source().query(bool); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); }
排序和分页
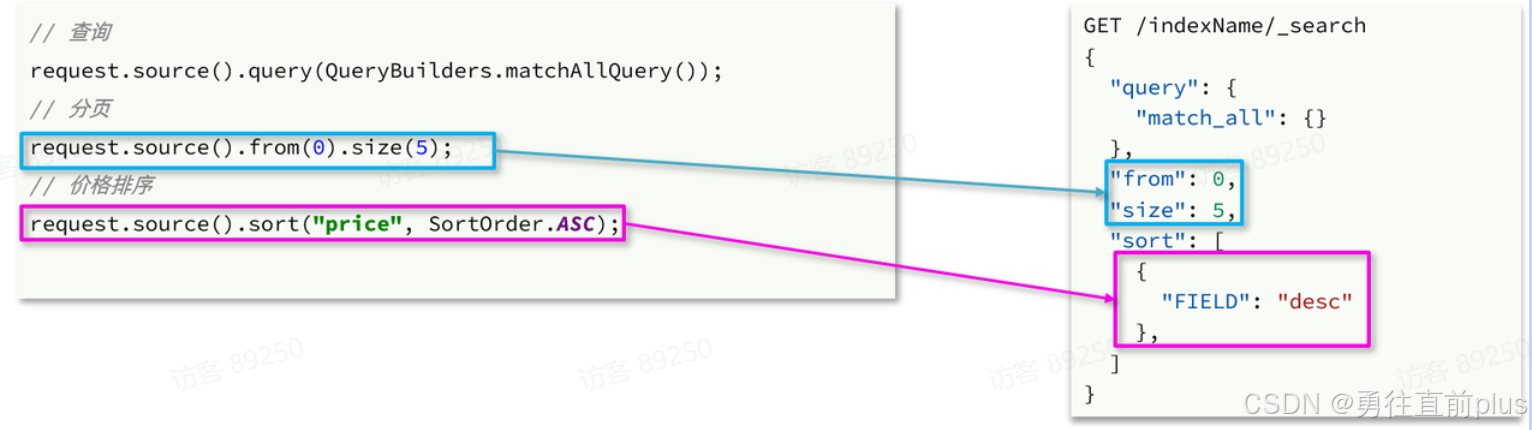
高亮

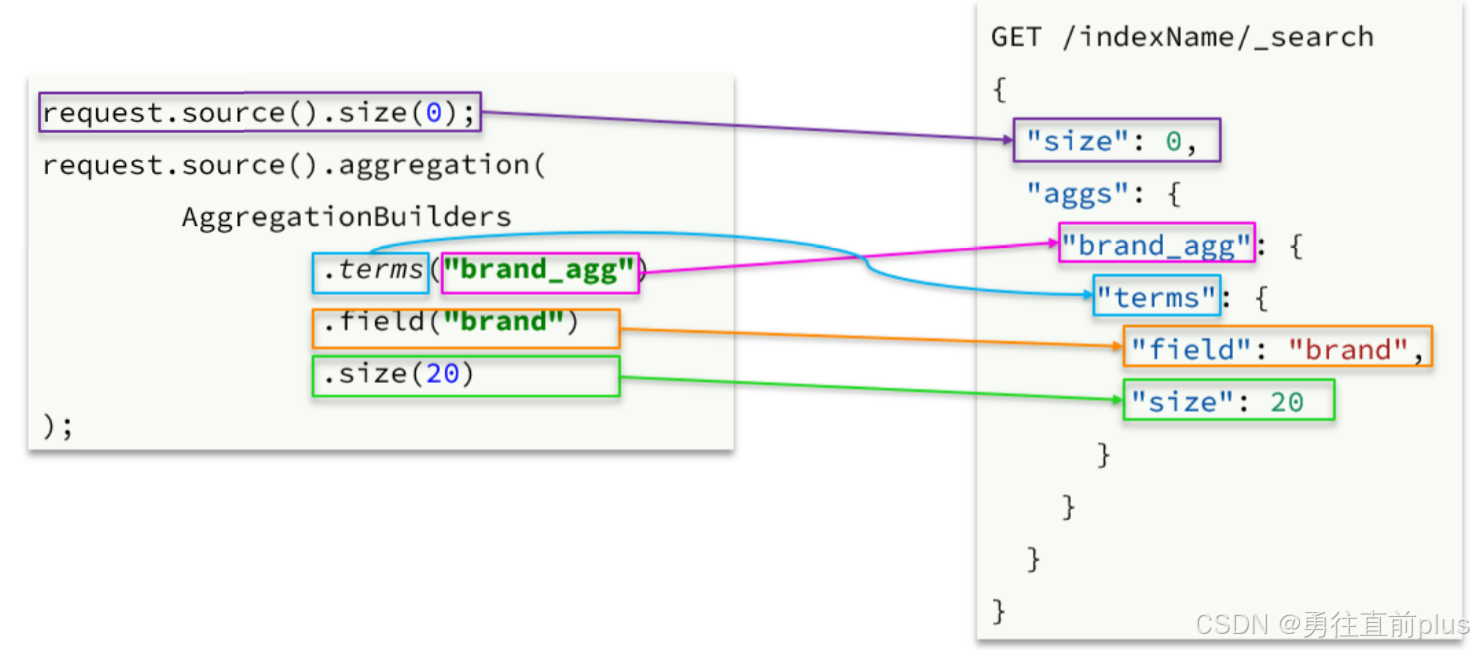
聚合
- 可以看到在DSL中,aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用
request.source()方法来设置 - 不过聚合条件的要利用AggregationBuilders这个工具类来构造。DSL与JavaAPI的语法对比如下:
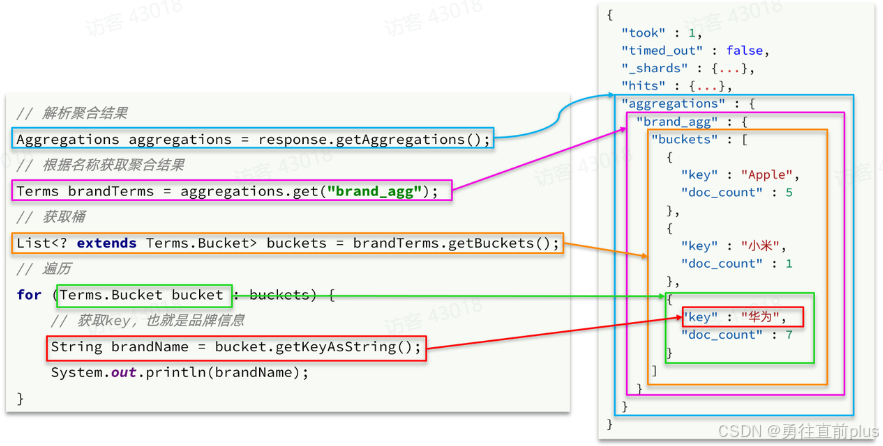
- 聚合结果与搜索文档同一级别,因此需要单独获取和解析。具体解析语法如下: