我自己的原文哦~https://blog.51cto.com/whaosoft/12320882
#自动驾驶数据集全面调研
自动驾驶技术在硬件和深度学习方法的最新进展中迅速发展,并展现出令人期待的性能。高质量的数据集对于开发可靠的自动驾驶算法至关重要。先前的数据集调研试图回顾这些数据集,但要么集中在有限数量的数据集上,要么缺乏对数据集特征的详细调查。为此,这里从多个角度对超过200个自动驾驶数据集进行了详尽的研究,包括传感器模态、数据大小、任务和上下文条件。引入了一种新的评估每个数据集影响的度量标准,该标准还可以成为建立新数据集的指南。进一步分析了数据集的标注过程和质量。此外,对几个重要数据集的数据分布进行了深入分析。最后,讨论未来自动驾驶数据集的发展趋势。
当前行业的概述
自动驾驶(AD)旨在通过创建能够准确感知环境、做出智能决策并在没有人类干预的情况下安全行驶的车辆,彻底改变交通系统。由于令人激动的技术发展,各种自动驾驶产品已在多个领域实施,例如无人出租车。这些对自动驾驶的快速进展在很大程度上依赖于大量的数据集,这些数据集帮助自动驾驶系统在复杂的驾驶环境中变得稳健可靠。
近年来,自动驾驶数据集的质量和种类显著增加。数据集开发的第一个显著现象是各种不同的数据收集策略,包括通过仿真器生成的合成数据集和从真实世界记录的数据集等。其次,数据集在组成方面也各种各样,包括但不限于多种感知数据(如相机图像和LiDAR点云)以及用于自动驾驶各个任务的不同标注类型。下图1以俯视图的方式显示了六个真实世界数据集(Argoverse 2 、KITTI 、nuScenes 、ONCE 、Waymo 和ZOD )的3D目标边界框分布的统计数据,展示了每个数据集的独特标注特性。

根据传感器的设备位置,数据集的多样性还体现在感知领域中,包括车载、V2X、无人机等。此外,几何多样性和天气条件的改变提高了自动驾驶数据集的泛化能力。
为什么研究?动机是什么?
下图2中展示了每年发布的感知数据集数量,以从一个角度反映自动驾驶数据集的趋势。由于存在大量且不断增加的公开发布的数据集,对自动驾驶数据集进行全面调查对推动学术和工业研究非常有价值。在先前的工作中,Yin等人总结了27个在公共道路上收集的数据的公开可用数据集。35除了描述现有数据集,讨论了合成数据和真实数据之间的域适应以及自动标注方法。36总结了现有数据集,并对下一代数据集的特征进行了详尽的分析。然而,这些调查仅总结了少量数据集,导致范围不够广泛。AD-Dataset 收集了大量数据集,但缺乏对这些数据集属性的详细分析。与对所有类型的数据集进行研究相比,一些研究人员对特定类型的自动驾驶数据集进行了调查,例如异常检测、合成数据集、3D语义分割和决策。

因此,本文的目标是提出一项全面而系统的研究,涵盖自动驾驶中的大量数据集,从感知到控制的所有任务,考虑真实世界和合成数据,并深入了解若干关键数据集的数据模态和质量。在下表I中对比了其他数据集调查和作者的调查。

主要贡献
本文的主要贡献可总结如下:
- 对自动驾驶数据集进行了全面调查。尽可能全面地考虑公开可用数据集,记录它们的基本特征,如发布年份、数据大小、传感器模态、感知领域、几何和环境条件以及支持任务。据我们所知,本工作提供了迄今为止记录的最广泛的自动驾驶数据集概述。
- 系统地说明了收集自动驾驶数据的传感器和感知领域。此外,描述了自动驾驶的主要任务,包括任务目标、所需数据模态和评估指标。
- 根据感知领域和支持任务对数据集进行了总结和划分,以帮助研究人员高效选择和收集目标数据集的信息。从而促进更有针对性和有效的研究和开发工作。
- 此外,引入了一个影响分数度量标准,评估了在社区中发布的感知数据集的影响力。这个指标也可以作为未来数据集开发的指导。深入分析了具有最高分数的数据集,突出它们的优势和效用。
- 调查了数据集的标注质量以及各种自动驾驶任务的现有标注程序。
- 进行了详细的数据统计,展示了不同角度的各种数据集的数据分布,展示了它们固有的限制和适用情况。
- 分析了最近的技术趋势,并展示了下一代数据集的发展方向。还展望了大语言模型进一步推动未来自动驾驶的潜在影响。
范围与局限性
本文的目标是对现有的自动驾驶数据集进行详尽调查,以提供对该领域未来算法和数据集的开发提供帮助和指导。收集了侧重于四个基本自动驾驶任务的数据集:感知、预测、规划和控制。由于有几个多功能数据集支持多个任务,作者只在它们主要支持的主要范围中解释它们,以避免重复介绍。此外,收集了大量数据集,并以它们的主要特征展示在表格中。然而,对所有收集到的数据集进行详细解释可能无法突显最受欢迎的数据集,可能会妨碍研究人员通过这项调查找到有价值的数据集。因此,只详细描述了最有影响力的数据集。
文章结构
本文的其余部分结构如下:第二节介绍了用于获取公共数据集以及数据集的评估指标的方法。第三节展示了自动驾驶中使用的主要传感器及其模态。第四节讨论了自动驾驶任务、相关挑战和所需数据。在第五节进一步讨论了几个重要的数据集。在第六节展示了标注过程和影响标注质量的因素。此外,在第七节对几个数据集的数据分布进行了统计。在第八节中,调查了自动驾驶数据集的发展趋势和未来工作。最后,在第九节总结。此调查的分类结构如下图3所示。

方法论介绍
本节包括1) 如何收集和筛选数据集(II-A),以及2) 如何评估数据集对自动驾驶领域的影响(II-B)。
数据集收集
作者遵循42的方法进行系统性的回顾,以详尽收集已发布的自动驾驶数据集。为确保来源的多样性,作者利用了知名的搜索引擎,如Google、Google Scholar和Baidu来搜索数据集。为了确保从各个国家和地区全面收集数据集,使用英语、中文和德语进行搜索,使用关键词如"autonomous driving datasets"、"intelligent vehicle datasets"以及与目标检测、分类、跟踪、分割、预测、规划和控制相关的术语。
此外,在IEEE Xplore和自动驾驶及智能交通系统领域的相关会议中搜索,以收集来自期刊和会议论文集的数据集。通过关键词搜索和手动标题审查验证了这些来源的数据集。
最后,为了确保包括专业或较少知名的数据集,作者通过Github仓库和Paperwithcodes进行了搜索。类似于数据库,对数据集进行了手动和基于关键词的搜索。
数据集评估指标
作者引入了一个新的度量标准,即影响分数(impact score),用于评估已发布数据集的重要性,这也可以作为准备新数据集的指南。在本节中,详细解释了计算自动驾驶数据集影响分数的方法。
为了进行公平和可比较的比较,作者仅考虑与感知领域相关的数据集,因为感知领域占据了自动驾驶数据集的很大一部分。此外,为了确保评分系统的客观性和可理解性,考虑了各种因素,包括引用次数、数据维度和环境多样性。所有的值都是从官方论文或开源数据集网站收集而来。


环境多样性评分。根据以下因素评估数据集的环境多样性:
- 天气条件,例如雨雪。
- 白天或黄昏等数据收集时间。
- 驾驶场景的类型,例如城市或乡村。
- 几何范围指的是数据记录的国家或城市数量。

数据源和自动驾驶中的协同感知
本节介绍主要用于自动驾驶的传感器及其模态。此外,分析了数据采集和通信领域,如车载、无人机和V2X的协同感知。
数据的传感器和模态
高效而准确地从周围环境中收集数据是自动驾驶可靠感知系统的关键。为了实现这一目标,在自动驾驶车辆和基础设施上使用了各种类型的传感器。传感器的示例如下图 4 所示。最常用的传感器是相机、LiDAR 和Radar。事件型和热成像相机也安装在车辆或道路旁边,以进一步提高感知能力。

RGB 图像。RGB 图像通常由单目、双目或鱼眼相机记录。单目相机提供不带深度的 2D 视图;双目相机通过其双镜头提供深度感知;鱼眼相机使用广角镜头捕捉广阔的视野。所有这些相机通过透镜将光传导到图像传感器(例如 CMOS),将这些光转换为表示图像的电子信号。如下图 5 (a) 所示,2D 图像捕捉环境的颜色信息、丰富的纹理、模式和视觉细节。由于这些特性,RGB 图像主要用于检测车辆和行人,并识别道路标志。然而,RGB 图像容易受到低照明、雨、雾或耀斑等条件的影响 。
LiDAR 点云。LiDAR 使用激光束测量传感器与目标之间的距离,从而创建 3D 环境表示 。LiDAR 点云(如下图 5 (b) 所示)提供高分辨率的精确空间信息,可以检测长距离内的目标。然而,这些点的密度会随着距离的增加而减小,导致远处目标的表示更为稀疏。天气条件,如雾,也会限制 LiDAR 的性能。总体而言,LiDAR 适用于需要 3D 简要信息的情况。
Radar点云。Radar通过发射射频波并分析其反射来检测目标、距离和相对速度。此外,Radar在各种天气条件下都具有很强的鲁棒性 。然而,Radar点云通常比 LiDAR 数据更粗糙,缺乏目标的详细形状或纹理信息。因此,Radar通常用于辅助其他传感器。下图 5 (c) 展示了Radar点云。
事件相机。事件型相机异步捕捉数据,仅在像素检测到亮度变化时才激活。捕捉到的数据称为事件(如图 5 (d) 所示)。由于采用了特定的数据生成方法,记录的数据具有极高的时间分辨率,并且可以捕捉快速运动而不模糊 。
热成像相机的红外图像。热成像相机(见下图 5 (e))通过捕捉红外辐射来检测热特征 。由于基于温差生成图像,热成像相机可以在完全黑暗中工作,并且不受雾或烟影响。然而,热成像相机无法分辨颜色或详细的视觉图案。此外,与光学相机相比,红外图像的分辨率较低。

惯性测量单元(IMU)。IMU 是一种电子设备,用于测量并报告目标的特定力、角速度,有时还有目标周围的磁场 。在自动驾驶中,它用于跟踪车辆的运动和方向。虽然 IMU 不包含周围环境的视觉信息,但通过将 IMU 的数据与其他传感器的数据融合,感知系统可以更准确、更鲁棒地跟踪车辆的运动和方向。
作者从收集的数据集中分析传感器的分布,如下图 6 所示。超过一半的传感器是单目相机(53.85%),这是因为它们价格低廉且性能可靠。此外,93 个数据集包含 LiDAR 数据,由于其高分辨率和精确的空间信息而受到重视。然而,由于高昂的成本,限制了 LiDAR 的广泛使用。除 LiDAR 点云外,29 个数据集利用双目相机捕捉深度信息。此外,分别包含Radar、热像相机和鱼眼相机的数据集比例分别为5.41%、3.42%和1.71%。考虑到以事件为基础的相机捕捉动态场景的时间效率,有三个数据集生成基于事件的相机数据。

传感域和协同感知系统
自动驾驶系统中,自车与周围环境中其他实体之间的感知数据和通信起着至关重要的作用,确保了自动驾驶系统的安全性、效率性和整体功能性。因此,传感器的位置决定了可以收集的数据的质量、角度和范围,因此非常关键。总体而言,在自动驾驶环境中,传感器可以分为以下几个领域:自车、车联网(V2X)、无人机和其他。
自车:自车传感器直接安装在自动驾驶车辆上,通常包括相机、LiDAR、Radar和惯性测量单元(IMU)。这些传感器提供了车辆视角的直接视图,即时反馈车辆周围的情况。然而,由于车辆检测范围的限制,自车传感器可能在提供盲点内障碍物的预警或检测急弯附近的危险方面存在局限性。
车联网(V2X):车联网包括车辆与交通系统中的任何其他组件之间的通信,包括车辆对车辆(V2V)、车辆对基础设施(V2I)和车辆对网络(V2N)(如下图7所示)。除了直接的感知输入外,协同系统确保多个实体协同工作。

- 车到车(V2V) V2V使附近的车辆能够共享数据,包括它们的位置、速度和传感器数据,如相机图像或LiDAR扫描,有助于更全面地了解驾驶场景。
- 车到基础设施(V2I) V2I促进了自动驾驶车辆与基础设施组件之间的通信,例如交通灯、标志或路边传感器。嵌入在道路基础设施中的传感器,包括相机、LiDAR、Radar或基于事件的相机,协同工作以扩展感知范围并提高自动驾驶车辆的情境感知。在这项调查中,作者将通过基础设施或V2I进行的感知都归类为V2I。
- 车到网络(V2N) V2N指的是在车辆和更广泛的网络基础设施之间交换信息,通常利用蜂窝网络为车辆提供对云数据的访问。V2N通过共享跨区域数据或提供有关交通拥堵或道路封闭的实时更新,帮助V2V和V2I的合作感知。
无人机(Drone):无人机提供了一种空中视角,提供了轨迹预测和路径规划所需的数据。例如,来自无人机的实时数据可以集成到交通管理系统中,以优化交通流并提醒自动驾驶车辆前方的事故。
其他 未由前三种类型收集的数据被定义为其他,例如安装在非车辆目标上或多个领域的其他设备。
自动驾驶中的任务
这一部分深入介绍了自动驾驶中的关键任务,如感知和定位、预测以及规划和控制。自动驾驶流程的概览如下图8所示。详细说明它们的目标、它们所依赖的数据的性质以及固有的挑战。图9展示了自动驾驶中若干主要任务的示例。


感知和定位
感知侧重于根据感知数据理解环境,而定位确定自动驾驶车辆在该环境中的位置。
2D/3D 目标检测
2D或3D目标检测旨在识别和分类驾驶环境中的其他实体。而2D目标检测在图像空间中识别目标,3D目标检测进一步整合由LiDAR提供的精确深度信息。尽管检测技术取得了显著进展,但仍存在一些挑战,如目标遮挡、光照变化和多样的目标外观。
通常情况下,使用AP度量来评估目标检测性能。根据1,AP度量可表述为:

2D/3D 语义分割
语义分割涉及将图像的每个像素或点云的每个点分类到其语义类别。从数据集的角度来看,保持细粒度的目标边界并管理大量标签要求对这个任务来说是一个重要的挑战。
正如中提到的,用于分割的主要度量标准包括平均像素准确率(mPA):

目标跟踪
目标跟踪监控单个或多个目标随时间的轨迹。这项任务需要时间序列的RGB数据、LiDAR或Radar序列。通常,目标跟踪包括单目标跟踪或多目标跟踪(MOT)。
多目标跟踪准确度(MOTA)是用于多目标跟踪的广泛使用的度量,它结合了假反例、假正例和不匹配率(参见方程9):

此外,与其考虑单一阈值不同,Average MOTA(AMOTA)是基于所有目标置信阈值计算的。
高精度地图
高精度地图的目标是构建详细、高度准确的表示,其中包括有关道路结构、交通标志和地标的信息。一个数据集应该提供LiDAR数据以获取精确的空间信息,以及相机数据以获取视觉细节,以确保建立的地图准确性。
根据,高精度地图自动化和高精度地图变更检测越来越受到关注。通常,高精度地图的质量是通过准确度度量来估算的。
SLAM
同时定位与建图(SLAM)涉及构建周围环境的同时建图,并在该地图中定位车辆。因此,来自相机、用于位置跟踪的IMUs以及实时LiDAR点云的数据是至关重要的。引入了两个评估指标,相对位姿误差(RPE)和绝对轨迹误差(ATE),用于评估从输入RGB-D图像估计的轨迹的质量。
预测
预测是指对周围agents的未来状态或行为进行预测。这种能力确保在动态环境中更安全地导航。预测使用了一些评估指标,例如均方根误差(RMSE):

轨迹预测
利用来自相机和LiDAR等传感器的时间序列数据,轨迹预测涉及预测其他实体(如行人、骑车人或其他车辆)未来的路径或移动模式。
行为预测
行为预测预测其他道路使用者的潜在动作,例如车辆是否会变道。训练行为预测模型依赖于具有广泛标注的数据,因为在不同情境中实体可能采取各种潜在动作。
意图预测
意图预测侧重于推断目标行为背后的意图的高级目标,涉及对人类目标的物理或心理活动进行更深层次的语义理解。由于任务的复杂性,它不仅需要来自感知相机等传感器的数据,还需要其他信息,如交通信号和手势,以推断其他agents的意图。
规划与控制
- 规划: 规划代表对感知环境和预测做出反应的决策过程。经典的三级分层规划框架包括路径规划、行为规划和运动规划。
- 路径规划: 路径规划,也称为路线规划,涉及设定长期目标。这是一个高层次的过程,确定到达目的地的最佳路径。
- 行为规划: 行为规划位于框架的中层,与决策制定相关,包括变道、超车、合并和十字路口穿越等。这个过程依赖于对其他agents行为的正确理解和交互。
- 运动规划: 运动规划处理车辆实时应该遵循的实际轨迹,考虑到障碍物、道路状况和其他道路agents的预测行为。与路径规划相反,运动规划生成实现局部目标的适当路径。
- 控制: 自动驾驶中的控制机制管理自动驾驶汽车如何执行来自运动规划系统的决定的路径或行为,并纠正跟踪误差。它将高级命令转换为可执行的油门、刹车和转向命令。
端到端自动驾驶
端到端自动驾驶是指单个深度学习模型处理从感知到控制的所有任务,绕过传统的模块化流程。这样的模型通常更具适应性,因为它们通过学习来调整整个模型。它们的固有优势在于简单性和效率,通过减少手工制作组件的需求。然而,实施端到端模型面临着关键限制,如大量的训练数据需求、低解释性和不灵活的模块调整。
对端到端自动驾驶进行大规模基准测试可以分为闭环和开环评估。闭环评估基于仿真环境,而开环评估涉及根据来自真实世界数据集的专业驾驶行为评估系统的性能。
高影响力数据集
本节描述了在感知、预测、规划和控制领域中的具有里程碑意义的自动驾驶数据集。还展示了端到端自动驾驶的数据集。
感知数据集
感知数据集对于开发和优化自动驾驶系统至关重要。它们通过提供丰富的多模态感知数据,确保对周围环境进行有效感知和理解,从而增强车辆的可靠性和稳健性。
作者利用提出的数据集评估指标计算收集的感知数据集的影响分数,随后根据这些分数选择前50个数据集,以创建一个按时间顺序排列的概述,如下图10所示。同时,如前章节中所述,将数据集分为车载、V2X、无人机和其他,从每个类别中选择一个子集,编制一个包含50个数据集的综合表格(下表II)。值得注意的是,表中的数据集是按照其各自类别内的影响分数进行排序的,不代表总体的前50。在以下部分,作者选择了每个感知来源中影响分数最高的几个数据集,并考虑它们的发布年份。


车载
- KITTI: KITTI 自2012年发布以来,深刻影响了自动驾驶领域。KITTI包含通过各种传感器记录的各种真实驾驶场景,包括相机、LiDAR和GPS/IMU。其丰富的标注和高分辨率的传感器数据促进了在各种自动驾驶任务(如目标检测、跟踪、光流、深度估计和视觉里程计)方面的算法开发和基准测试。
- Cityscapes: Cityscapes 包括在复杂城市环境中明确捕获的大量图像。通过精心标注,Cityscapes为30个不同的目标类别提供像素级分割,其中包括各种车辆类型、行人、道路和交通标志信息。由于其复杂性和丰富性,Cityscapes已成为诸如城市场景中语义分割等任务的标准基准。
- SYNTHIA: SYNTHIA 是自动驾驶领域的合成数据集。该数据集包含13,400张图像,具有语义分割的逐像素标注。SYNTHIA的一个显著特点是它能够弥合现实世界和合成数据之间的差距,促进了在不同领域之间开发稳健且可转移的方法。
- Virtual KITTI: Virtual KITTI 通过虚拟环境密切模仿了原始KITTI数据集,通过提供包含各种交通情况和环境条件的高分辨率视频序列而脱颖而出。类似于,Virtual KITTI支持关键的自动驾驶任务,包括目标检测、语义分割和目标跟踪。
- VIPER: VIPER 是从现实虚拟世界的驾驶、骑行和步行视角收集的合成数据集,解决了数据稀缺和标注现实世界数据的高成本挑战。VIPER包含超过25万帧视频,为低级和高级视觉任务提供了真值数据,同时涵盖各种天气条件、光照场景和复杂的城市风景。总体而言,VIPER为研究人员提供了一个宝贵且经济高效的工具,以加速可靠且安全的自动驾驶的发展。
- **Apolloscapes:**Apolloscapes 提供了超过140,000个高分辨率帧,具有准确的边界框和像素级语义标签,对于训练和验证自动车辆的感知和导航系统至关重要。Apolloscapes支持图像和点云的语义分割,2D/3D目标检测,多目标跟踪和车道线分割,从而实现先进且安全的自动驾驶系统的创建和评估。
- **SemanticKITTI:**SemanticKITTI 是KITTI家族的一个显著扩展,专注于自动驾驶领域的语义分割。SemanticKITTI包含超过43,000个LiDAR点云帧,使其成为户外环境中3D语义分割最大的数据集之一。SemanticKITTI为28个类别提供精确的标签,如汽车、道路、建筑等,为评估点云语义分割方法的性能提供了强有力的基准,支撑了相关领域的许多研究和创新。
- **nuScenes:**nuScenes 是自动驾驶领域的重要贡献,提供了一个丰富的数据库,满足感知系统的多样化需求。nuScenes利用LiDAR、Radar和相机记录来自波士顿和新加坡不同城市场景的数据。值得一提的是,其六个相机提供了对周围环境的全面视角,在多视角目标检测任务中得到广泛应用。总体而言,nuScenes数据集是发展自动驾驶技术的基石,支持多任务和应用,并在该领域设立了新的基准。
- **Waymo:**Waymo Open Dataset ,于2019年推出,通过提供大量的多模态感知数据和高质量标注,显著影响了自动驾驶研究和进展。Waymo数据集的关键贡献包括其对驾驶条件和地理位置的全面覆盖,这对于不同任务(如检测、跟踪和分割)的鲁棒性和通用性至关重要。
- **BDD100K:**BDD100K 数据集,由伯克利DeepDrive中心于2018年发布,是一个规模庞大且多样化的驾驶数据集,以其规模和多样性而闻名。它包括100,000个大约40秒的视频。同时,它为目标检测、跟踪、语义分割和车道线检测提供了各种标注标签。这个庞大的数据集推动了自动驾驶社区的进展,成为研究人员和工程师提出和改进算法的具有挑战性和多功能的平台。
- **RADIATE:**RADIATE 是第一个公开的Radar数据集,包含44,140帧在不同恶劣天气条件下收集的带标注的图像,如雨天、雾天、阴天和雪天。它还整合了LiDAR和相机数据,使驾驶环境的全面感知和理解成为可能。
- **Argoverse 2:**Argoverse 2 作为Argoverse 1 的续集,引入了更多样化和复杂的驾驶场景,展示了迄今为止最大的自动驾驶分类法。它捕捉了六个城市和不同条件下的各种实际驾驶场景。Argoverse 2支持多个重要任务,包括但不限于3D目标检测、语义分割和跟踪。总之,Argoverse 2数据集提供了大量真实驾驶场景的多模态数据,促进了算法的创新和进步,并展示了其在自动驾驶中作为重要资源的实质潜力。
V2X
- **V2VNet:**V2VNet 引入的数据集专注于利用V2V通信,允许自动车辆从多个视点共享信息,这对于检测被遮挡目标和预测其他交通参与者的行为至关重要。该数据集使用名为Lidarsim 的高保真LiDAR仿真器创建,该仿真器利用真实世界数据生成各种交通场景的逼真LiDAR点云。总的来说,这项工作引起了对V2V作为提高自动车辆能力的有前途的途径的关注。
- **DAIR-V2X:**DAIR-V2X 是在车辆基础设施协同自动驾驶领域的开创性资源,提供大规模、多模态、多视图的真实世界数据。该数据集旨在解决车辆和基础设施传感器之间的时间不同步以及此类协作系统中涉及的数据传输成本等挑战。DAIR-V2X数据集对自动驾驶的影响很大,因为它为车辆基础设施合作的复杂性设立了一个基准,多亏了其来自真实世界的多种场景。
- **Rope3D:**Rope3D 是感知系统的重要贡献,通过利用从路边相机收集的数据,填补了自动驾驶中的关键差距。Rope3D包括50,000张图像,处于不同的环境条件,包括不同的照明(白天、夜晚、黄昏)和天气情况(雨天、晴天、多云)。总体而言,Rope3D数据集是推动路边感知在自动驾驶中取得进展的先导工作,同时也是研究人员和工程师开发更健壮、智能的自动驾驶系统的重要工具。
- **V2V4Real:**V2V4Real 是第一个大规模的真实世界数据集,用于处理V2V合作感知。该数据集从两辆配备有多模态传感器(如LiDAR和相机)的车辆中收集。V2V4Real关注一系列感知任务,如合作3D目标检测、合作3D目标跟踪和Sim2Real域适应。这种多功能性使其成为开发和基准测试自动驾驶算法的宝贵资源。
无人机
- UAVDT:UAVDT 数据集包含80,000个准确标注的帧,其中包括14种属性,如天气条件、飞行姿态、相机视图、车辆类别和遮挡级别。该数据集专注于在城市环境中基于UAV的目标检测和跟踪。此外,UAVDT基准测试包括密集场景、小型目标和显著的相机运动,这对于当前最先进的方法来说都是具有挑战性的。
- **DroneVehicle:**DroneVehicle 提出了一个大规模的基于无人机的数据集,提供28,439个RGB-红外图像对,用于解决低照明条件下的目标检测问题。此外,它涵盖了各种场景,如城市道路、住宅区和停车场。由于其在广泛条件下的独特无人机视角,这个数据集是发展自动驾驶技术的重要一步。
其它
- **Pascal3D+:**Pascal3D+ 是PASCAL VOC 2022 的扩展,通过为图像提供更丰富和多样化的标注来克服以前数据集的局限性。Pascal3D+通过为12个刚性目标类别(如汽车、公共汽车、自行车)提供3D姿势标注,并从ImageNet 添加更多图像,实现了高度的可变性。
- **TT 100K:**清华大学-腾讯100K 解决了在现实驾驶条件下检测和分类交通标志的挑战。它提供了100,000张图像,包括30,000个交通标志实例。除了大规模的数据大小外,高分辨率的图像涵盖了各种照明和天气条件,使其对于交通标志识别的训练和验证具有鲁棒性。
- **Mapillary Vistas :**由于2017年提出,主要旨在对街景进行语义分割。该数据集包含25,000张图像,标有66个目标类别,并包括37个类别的实例特定标注。它包含来自不同天气、时间和几何位置的图像,有助于减轻对特定区域或条件的偏见。
预测、规划和控制数据集
预测、规划和控制数据集是促进训练和评估驾驶系统的基础,用于预测交通动态、行人移动和其他影响驾驶决策的重要因素。通过仿真各种驾驶场景,它们使自动驾驶车辆能够做出明智的决策,穿越复杂的环境,并在道路上保持安全和高效。因此,作者根据数据大小、模态和引用数量详细展示与这些任务相关的几个高影响力的数据集。将预测、规划和控制数据集总结为任务特定和多任务两组。
任务特定数据集:
- **highD。**基于无人机的highD 数据集提供了德国高速公路上自然车辆轨迹的大规模收集,包含110,000辆汽车和卡车的后处理轨迹。该数据集旨在克服现有基于场景的安全验证测量方法的局限性,这些方法通常无法捕捉道路用户的自然行为或包含具有足够质量的所有相关数据。
- **PIE。**由提出的行人意图估计(PIE)数据集在理解城市环境中的行人行为方面取得了重大进展。它包含在多伦多市中心记录的超过6小时的行车录像,涵盖了各种光照条件。PIE数据集提供了对感知和视觉推理的丰富标注,包括带有遮挡标志的边界框、过街意图置信度以及行人行为的文本标签。长时间的连续序列和标注有助于多个任务,如轨迹预测和行人意图预测。
- **USyd。**USyd 在没有交通信号灯的城市交叉口背景下推动了驾驶员意图预测的进展,这在城市设置中很常见,由于缺乏明确的道路规则和信号,构成了一项挑战。该数据集包括超过23,000辆车穿越五个不同的交叉口的数据,使用车载LiDAR跟踪系统收集。数据模态包括详尽无遗的提供了横向和纵向坐标、航向和速度的车辆轨迹。这些信息对于预测驾驶行为至关重要,考虑到人类驾驶模式中固有的不确定性。
- **Argoverse。**Argoverse 是3D目标跟踪和运动预测中的一个关键数据集。Argoverse提供了来自7个相机、前视双目图像和LiDAR点云的360°图像。记录的数据涵盖了来自290km映射车道线的300,000多条车辆轨迹。借助丰富的传感器数据和语义地图,Argoverse对于推动预测系统的研究和开发至关重要。
- **inD。**inD 的重要性在于它大规模、高质量且多样化的轨迹数据,对于道路用户预测模型和城市交叉口环境中自动车辆的基于场景的安全验证至关重要。它涵盖了大约11,500条不同的道路用户轨迹,例如车辆、自行车和行人。这些轨迹的定位误差小于0.1米,对于数据的可靠性至关重要。
- **PePscenes。**PePscenes 解决了在动态驾驶环境中理解和预测行人动作的需求。该数据集通过添加每帧2D/3D边界框和行为标注,重点关注行人过马路行为,增强了nuScenes 数据集。的一个关键属性是结合各种数据类型,包括语义地图、场景图像、轨迹和自车状态,这对于创建能够理解复杂交通场景的强大模型至关重要。
- **openDD。**openDD 数据集专注于分析和预测环状交叉口周围的交通场景,这些场景复杂且不受交通信号灯约束。它是在使用高分辨率(4K)的无人机捕获的图像的基础上创建的,跨足了来自501次单独飞行的62小时轨迹数据。该数据集不仅包含轨迹,还包括描述道路拓扑结构的shapefiles和可扩展标注语言(XML)文件,以及每个底层交叉口的参考图像。
- **nuPlan。**nuPlan 是自动驾驶中世界上第一个闭环机器学习规划基准。这个多模态数据集包括来自美国和亚洲四个城市的约1,500小时的人类驾驶数据,展示了不同的交通模式,如合并、变道、与骑自行车和行人的互动以及在施工区驾驶。nuPlan数据集的这些特征考虑了实际驾驶的动态和互动性质,使其更适合进行更真实的评估。
- exiD。 exiD 轨迹数据集是2022年提出的,对高度交互的高速公路场景具有重要意义。它利用无人机记录交通情况,减少对交通的影响,并确保高数据质量和效率。这个基于无人机的数据集在捕捉各种交互中的多样性方面超过了先前的数据集,特别是涉及高速入口和出口的车道线变更。
- **MONA。**Munich Motion Dataset of Natural Driving (MONA) 是一个庞大的数据集,包含来自130小时视频的702,000条轨迹,覆盖了具有多个车道线的城市道路、市区高速公路以及它们的过渡。这个数据集展示了0.51米的平均整体位置精度,展示了使用高度精确的定位和LiDAR传感器收集数据的质量。
多任务数据集:
- INTERACTION。 INTERACTION 数据集涵盖了多样、复杂和关键的驾驶场景,结合了全面的语义地图,使其成为一个多功能平台,可用于多种任务,如运动预测、模仿学习以及决策和规划的验证。它包括不同国家的数据,进一步提高了对不同文化驾驶行为进行分析的鲁棒性,这对全球自动驾驶的发展至关重要。
- BLVD。 BLVD 基准有助于动态4D(3D+时间)跟踪、5D(4D+交互)交互事件识别和意图预测等任务,这些对于更深入理解交通场景至关重要。BLVD提供了来自不同交通场景的约120,000帧,包括目标密度(低和高)和照明条件(白天和夜晚)。这些帧被完全标注,包括大量的3D标签,涵盖了车辆、行人和骑手。
- **rounD。**由提出的rounD数据集对于场景分类、道路用户行为预测和驾驶员建模至关重要,因为它收集了在环状交叉口的大量道路用户轨迹。该数据集利用装备有4K分辨率相机的无人机收集了超过六小时的视频,记录了超过13,000名道路用户。广泛记录的交通情况和高质量的录像使rounD成为自动驾驶中不可或缺的数据集,促进了对公共交通中自然驾驶行为的研究。
- **Lyft Level 5。**Lyft Level 5 是迄今为止最大规模的用于运动预测的自动驾驶数据集之一,拥有超过1,000小时的数据。它包括17,000个25秒长的场景,一个具有超过15,000个人工标注的高清语义地图,8,500个车道线段和该区域的高分辨率航拍图像。它支持多个任务,如运动预测、运动规划和仿真。详细标注的众多多模态数据使Lyft Level 5数据集成为预测和规划的重要基准。
- **LOKI。**LOKI 代表着长期和关键意图(Long Term and Key Intentions),是多agents轨迹预测和意图预测中的一个重要数据集。LOKI通过提供大规模、多样化的数据,包括行人和车辆在内,弥补了智能和安全关键系统的一个关键空白。该数据集通过利用带有相应LiDAR点云的相机图像,提供了交通场景的多维视图,使其成为社区中非常灵活的资源。
- **SceNDD。**SceNDD 引入了真实驾驶场景,展示了多样的轨迹和驾驶行为,可用于开发高效的运动规划和路径跟踪算法。它还适用于自动驾驶汽车不同配置,并包含可以分解为时间戳进行详细分析的预测时间视角。总的来说,SceNDD数据集是自动驾驶预测和规划研究的重要补充。
- DeepAccident。 合成数据集DeepAccident 是第一个为自动驾驶汽车提供直接且可解释的安全评估指标的工作。这个包含57,000个带标注帧和285,000个带标注样本的大规模数据集支持端到端的运动和事故预测,对于提高自动驾驶系统在避免碰撞和确保安全方面的预测能力至关重要。此外,这个多模态数据集对于各种基于V2X的感知任务,如3D目标检测、跟踪和鸟瞰(BEV)语义分割,都是多才多艺的。
- **Talk2BEV。**创新的数据集Talk2BEV 推动了从传统的自动驾驶任务转向在自动驾驶背景下将大型视觉语言模型与BEV地图相结合的趋势。Talk2BEV利用了视觉语言模型的最新进展,允许对道路场景进行更灵活、全面的理解。该数据集包含超过20,000个多样的问题类别,全部由人工标注,并源自。所提出的Talk2BEV-Bench基准可用于多项任务,包括决策制定、视觉和空间推理以及意图预测。
- **V2X-Seq(预测)。**轨迹预测数据集是现实世界数据集V2X-Seq 的重要组成部分,包含约80,000个基础设施视图和80,000个车辆视图场景,以及额外的50,000个协同视图场景。这种感知领域的多样性为研究和分析车辆基础设施协同(VIC)轨迹预测提供了更全面的视角。
端到端数据集
端到端已经成为自动驾驶中的一个趋势,作为模块化架构的替代。一些多功能数据集(如nuScenes 和Waymo )或仿真器(如CARLA )提供了开发端到端自动驾驶的机会。同时,一些工作提出了专门用于端到端驾驶的数据集。
- DDD17。 DDD17 数据集因其使用事件型相机而显著,该相机提供标准主动像素传感器(APS)图像和动态视觉传感器(DVS)时间对比事件的同时流,提供了视觉数据的独特组合。此外,DDD17捕捉了包括高速公路和城市驾驶在内的各种驾驶场景,以及不同的天气条件,为训练和测试端到端自动驾驶算法提供详尽而现实的数据。
在本调查中总结的其他数据集显示在表IV、表V、表VI中。



标注过程
自动驾驶算法的成功和可靠性不仅依赖于大量的数据,还依赖于高质量的标注。本节首先解释了标注数据的方法。此外分析了确保标注质量的最重要方面。
标注是如何创建的
不同的自动驾驶任务需要特定类型的标注。例如,目标检测需要实例的边界框标签,分割基于像素或点级别的标注,对于轨迹预测来说,标注连续的轨迹至关重要。另一方面,如下图11所示,标注流程可以分为三种类型:手动标注、半自动标注和全自动标注。在本节详细说明了不同类型标注的标注方法。

**标注分割数据。**标注分割数据的目标是为图像中的每个像素或LiDAR帧中的每个点分配一个标签,以指示它属于哪个目标或区域。在标注之后,属于同一目标的所有像素都用相同的类别进行标注。对于手动标注过程,标注者首先在目标周围画出边界,然后填充区域或直接涂抹像素。然而,以这种方式生成像素/点级别标注是昂贵且低效的。
许多研究提出了全自动或半自动的标注方法以提高标注效率。提出了一种基于弱监督学习的完全自动标注方法,用于分割图像中提出的可行驶路径。265是一种半自动标注方法,利用目标先验生成分割mask。之后,266提出了一种考虑20个类别的半自动方法。Polygon-RNN++ 提出了一种交互式分割标注工具,遵循268的思路。269不使用图像信息生成像素级标签,而是将3D信息转移到2D图像领域生成语义分割标注。对于标注3D数据,270提出了一个图像辅助标注流程。271利用主动学习选择少量点并形成最小训练集,以避免标注整个点云场景。272引入了一种使用半/弱监督学习进行标注的高效标注框架,以标注室外点云。
**标注2D/3D边界框。**边界框标注的质量直接影响了自动驾驶车辆感知系统(如目标检测)在现实场景中的有效性和鲁棒性。标注过程通常涉及使用矩形框标注图像或使用长方体标注点云,以精确包围感兴趣的目标。
Labelme 是一种专注于为目标检测标注图像的工具。然而,由专业标注者生成边界框面临与手动分割标注相同的问题。Wang等人 提出了一种基于开源视频标注系统VATIC的半自动视频标注工具。275是另一种用于自动驾驶场景的视频标注工具。与白天标注相比,处理夜间的边界框标注更具挑战性。276介绍了一种利用轨迹的半自动方法来解决这个问题。
与2D标注相比,3D边界框包含了更丰富的空间信息,如准确的位置、目标的宽度、长度、高度以及空间中的方向。因此,标注高质量的3D标注需要一个更复杂的框架。Meng等人 应用了一个两阶段的弱监督学习框架,使用人为循环来标注LiDAR点云。ViT-WSS3D 通过对LiDAR点和相应弱标签之间的全局交互建模来生成伪边界框。Apolloscape 采用了类似于的标注流程,包括3D标注和2D标注两个分支,分别处理静态背景/目标和移动目标。3D BAT 开发了一个标注工具箱,以辅助在半自动标注中获取2D和3D标签。
**标注轨迹。**轨迹本质上是一系列点,映射了目标随时间的路径,反映了空间和时间信息。为自动驾驶标注轨迹数据的过程涉及对驾驶环境中各种实体的路径或运动模式进行标注,如车辆、行人和骑车者。通常,标注过程依赖于目标检测和跟踪的结果。
在轨迹标注的先前工作中,280在线生成了用于演习的动作,并被标注到轨迹中。281包括一个众包步骤,后跟一个专家集成的精确过程。282开发了一个主动学习框架来标注驾驶轨迹。精确地预测行人的运动模式对于驾驶安全至关重要。Styles等人 引入了一种可扩展的机器标注方案,用于无需人工努力的行人轨迹标注。
**在合成数据上进行标注。**由于在真实世界数据上进行手动标注的费时昂贵,通过计算机图形和仿真器生成的合成数据提供了解决这个问题的替代方法。由于数据生成过程是可控的,场景中每个目标的属性(如位置、大小和运动)都是已知的,因此可以自动且准确地标注合成数据。
生成的合成场景被设计成模仿真实世界的条件,包括多个目标、各种地貌、天气条件和光照变化。为了实现这个目标,一些研究人员利用了《侠盗猎车手5》(GTA5)游戏引擎构建了数据集 。284基于多个游戏构建了一个实时系统,用于生成各种自动驾驶任务的标注。SHIFT 、CAOS 和V2XSet 是基于CARLA 仿真器创建的,而不是应用游戏视频。与11相比,V2X-Sim 研究了使用多个仿真器 ,为V2X感知任务生成数据集。CODD 进一步利用生成用于合作驾驶的3D LiDAR点云。其他工作利用Unity开发平台 生成合成数据集。
标注的质量
现有基于监督学习的自动驾驶算法依赖于大量的标注数据。然而,在质量低的标注上进行训练可能会对自动驾驶车辆的安全性和可靠性产生负面影响。因此,确保标注的质量对于提高在复杂的现实环境中行驶时的准确性是至关重要的。根据研究,标注质量受到多个因素的影响,例如一致性、正确性、精度和验证。一致性是评估标注质量的首要标准。它涉及在整个数据集上保持一致性,对于避免在训练在这些数据上的模型时产生混淆至关重要。例如,如果特定类型的车辆被标注为汽车,那么在所有其他情况下,它应该被一致地进行相同的标注。标注精度是另一个重要的指标,它指的是标签是否与目标或场景的实际状态相匹配。相比之下,正确性强调标注的数据是否适用于数据集的目的和标注准则。在标注之后,验证标注数据的准确性和完整性是至关重要的。这个过程可以通过专家或算法的手动审查来完成。验证有助于在问题影响自动驾驶车辆性能之前有效地防止数据集中的问题,从而减少潜在的安全风险。288提出了一种面向数据的验证方法,适用于专家标注的数据集。
KITTI 的一个标注失败案例如下图12所示。在相应的图像和LiDAR点云中说明了真值边界框(蓝色)。在图像的左侧,汽车的标注(用红色圈出)不准确,因为它未包含整个汽车目标。此外,尽管相机和LiDAR清晰捕捉到两辆汽车(绿色长方体突出显示),但它们未被标注。

数据分析
这一部分将详细系统地从不同角度分析数据集,例如全球数据的分布,时间趋势,以及数据分布。
全球分布
在图13中展示了191个自动驾驶数据集的全球分布概况。该图表显示美国处于领先地位,拥有40个数据集(占比21%),突显了其在自动驾驶领域的领导地位。德国拥有24个数据集,反映了其强大的汽车工业和对自动驾驶技术推动的影响。中国紧随其后,拥有16个数据集,表明中国在这一领域的兴趣和投资。另一个值得注意的点是,全球范围内有11个数据集,欧洲地区(不包括德国)有24个数据集。这种多样化的区域分布增强了收集到的数据的稳健性,并突显了研究界和工业界的国际合作和努力。
另一方面,尽管较小的部分代表了包括加拿大、韩国、英国、日本和新加坡在内的其他国家,这些国家都是拥有坚实技术背景和积累的发达国家------这一统计数据反映了极端的地区偏见。美国、西欧和东亚的主导地位导致了自动驾驶系统在这些地区典型的环境条件下过度拟合的偏见。这种偏见可能导致自动驾驶车辆在各种或未知的地区和情况下无法正常运行。因此,引入来自更广泛国家和地区的数据,如非洲,可以促进自动驾驶车辆的全面发展。
此外,由CARLA 等仿真器生成的35个合成数据集占18.32%。由于实际驾驶环境录制的局限性,这些合成数据集克服了这些缺点,对于开发更强大和可靠的驾驶系统至关重要。

感知数据集的时间趋势
在图10中,作者介绍了从2007年到2023年(截至本文撰写时)具有前50影响分数的感知数据集的时间趋势概览。这些数据集根据它们的数据来源领域进行了颜色编码,并且合成数据集用红色外框标注,清晰地展示了朝着多样化数据收集策略的进展。一个明显的趋势显示了多年来数据集的数量和种类的增加,表明随着自动驾驶领域的不断发展,需要高质量数据集。
总体而言,由于自动驾驶汽车有效而准确地感知周围环境的能力的重要性,大多数数据集提供了来自装备在自车上的传感器的感知视角(车载)。另一方面,由于实际世界数据成本高昂,一些研究人员提出了高影响力的合成数据集,如VirtualKITTI (2016年),以减轻对实际数据的依赖。在仿真器的有效性的推动下,近年来发布了许多新颖的合成数据集。在时间线上,像DAIR-V2X (2021年)这样的V2X数据集也呈现出向合作驾驶系统的趋势。此外,由于无人机提供的非遮挡视角,基于无人机的数据集,如2018年发布的UAVDT ,在推动感知系统方面发挥着关键作用。
数据分布
在图14中介绍了这些数据集每帧目标数量的情况。值得注意的是,Waymo 展示了大量帧数少于50个目标的情况,同时在图表中占据了广泛的位置,说明了它在每帧中从低到高的目标密度涵盖了各种场景。相反,KITTI 展示了一个更为受限的分布和有限的数据规模。Argoverse 2 具有大量帧数的高目标计数,其峰值约为70,这表明了它在一般情况下复杂的环境表示。对于 ONCE ,其目标密度均匀地分布在支持的感知范围内。像 nuScenes 和 ZOD 这样的数据集展示了类似的曲线,快速上升然后缓慢下降,暗示了环境复杂性的适度水平,每帧中目标数量具有相当的可变性。

除了场景中目标数量之外,基于与自车的距离的目标分布是揭示数据集的多样性和显著差异的另一个重要点,如下图15所示。Waymo 数据集展示了大量标注目标在近场到中场场景中。相反,Argoverse 2 和 ZOD 展示了更宽的检测范围,有些帧甚至包括超过200米的边界框。nuScenes 的曲线意味着它在较短范围内的目标非常丰富,这在城市驾驶场景中是典型的。然而,随着距离的增加,nuScenes 数据集的目标数量迅速减少。ONCE 数据集覆盖了目标在不同距离上更均匀的分布,而KITTI 数据集更注重近距离检测。

讨论与未来工作
本文主要关注分析现有数据集,这些数据集通常包含丰富的视觉数据,并旨在完成模块化pipeline中的任务。然而,随着技术的迅速发展,尤其是大语言模型的出色性能,下一代自动驾驶数据集出现了许多新的趋势,提出了新的挑战和需求。
**端到端驾驶数据集。**与模块化设计的自动驾驶pipeline相比,端到端架构简化了整体设计过程并减少了集成复杂性。UniAD 的成功验证了端到端模型的潜在能力。然而,端到端自动驾驶的数据集数量有限 。因此,引入专注于端到端驾驶的数据集对推动自动驾驶车辆的发展至关重要。另一方面,在数据引擎中实施自动标注pipeline可以显著促进端到端驾驶框架和数据的开发 。
自动驾驶数据集中引入语言。视觉语言模型(VLMs)最近在许多领域取得了令人印象深刻的进展。其在为视觉任务提供语言信息方面的固有优势使得自动驾驶系统更具解释性和可靠性。强调了多模式大语言模型在各种自动驾驶任务中的重要作用,例如感知 ,运动规划 和控制 。下面表 VII 中展示了包含语言标签的自动驾驶数据集。总体而言,将语言纳入自动驾驶数据集是未来数据集发展的趋势。

**通过VLMs生成数据。**正如所提到的,VLMs的强大能力可以用于生成自动驾驶数据。例如,DriveGAN 通过在没有监督的情况下解开不同组件来生成高质量的自动驾驶数据。此外,由于世界模型理解驾驶环境的能力,一些工作探索了使用世界模型生成高质量驾驶视频。DriveDreamer 作为从真实场景中派生的先驱性工作,解决了游戏环境或仿真设置的局限性。
**域自适应。**域自适应是开发自动驾驶车辆时面临的关键挑战 ,它指的是在一个数据集(源域)上训练的模型在另一个数据集(目标域)上能够稳定执行的能力。这个挑战表现在多个方面,如环境条件的多样性 、传感器设置 或从合成到真实的转换 。
结论
本文对200多个现有的自动驾驶数据集进行了详尽而系统的回顾和分析。从传感器类型和模态、感知领域以及与自动驾驶数据集相关的任务开始。引入了一个称为"影响分数"的新型评估指标,以验证感知数据集的影响力和重要性。随后,展示了几个高影响力数据集,涉及感知、预测、规划、控制和端到端自动驾驶。此外,解释了自动驾驶数据集的标注方法,并调查了影响标注质量的因素。
此外,描述了收集到的数据集的年代和地理分布,为理解当前自动驾驶数据集的发展提供了全面的视角。同时,研究了几个数据集的数据分布,为理解不同数据集之间的差异提供了一个具体的观点。最后,讨论了下一代自动驾驶数据集的发展和趋势。
#关于BEV落地的点点滴滴
1: 21年的大争论
现在回看21年底组内决定做BEV障碍物的时候,应该来说是一个幸运,或者说有一点运气在里面。最开始面临的当时是大家每个人都熟悉的拍板的事情,到底是按照业界成熟的2D检测方案,或者说单目3D的的检测方案来做。还是说按照21 在自动驾驶届最火的那个Tesla Ai Day 的方案来做。争论,和彷徨应该持续了有一个月左右的时间。很幸运的是,最终我们老大直接拍板了,决定做BEV 障碍物。现在回看为什么说幸运:一个是在21年后学术届有很多优秀的BEV论文出来,一个是行车感知这块一直没有作为一个正式项目立项,给了我们足够的时间去试错,(最开始只有2-3个人来做这件事情)。如果缺少这一些因素,也许最后是做不出来的。这样可能往往一件成功的事情都伴随着一些幸运在里面吧。
2:BEV 如何做方案
在21年10份的时候,能够找到的BEV 障碍物检测的资料还是比较少的,看的最多的就是21 年Tesla AI day 上面的BEV pipeline。我记得很清楚组内对21年的Tesla AI day 的pipeline 方案(感知部分)进行了拆解分析,最后的难点卡在了2D image Feature 到 BEV Feature 的转换上面。其实那个时候还真不知道如何和Tranformer 结合来做这个。在这里不得不感慨CV 领域的开源文化,有一天看到了 Patrick Langechuan Liu. (在这里很感谢刘兰个川持续关于自动驾驶经典论文的输出Paper notes,不过近期看到刘兰个川从自动驾驶行业跳去做机器人和大模型去了。)写的一篇文章,里面有一个图,感觉对2Dto BEV 的转换清楚了很多。如图1

图1 来自
然后我们就开始按图索骥,开始设计我们的网络,后面Detr3D DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queri 开源,结合Detr3D 我们的BEV 障碍物网络在nuscenes 数据集上开始收敛还不错。在验证集上跑出一个视频效果,大家都比较兴奋。那个时候我们只有2张40G的A100, 现在回想哈哈,我们真是无知者无畏。
3: 痛苦开始的22年
到22年的时候,我们面临的两个问题一个是自己车型的BEV训练数据如何构建,一个是如何把BEV 网络部署到车上。先说数据,这面临两个问题,一个是采集,一个是标注,还有一个是标定。采集我们搞了一台真值采集车,但是因为没有搞硬同步,导致7v(前视2V,后视1V,周视4V) 摄像头 和lidar 时间同步有问题,然后我们就搞了一套所谓的软同步的方案,只能说凑合着够用。然后说到标注,其实在22年标注行业里面,或者说我们选到标注供应商他们是没有标注过BEV 障碍物的, 然后我们就从零开始写标注文档(这个过程是真痛苦 ), 第一版的标注文档,加上供应商提供的标注工具,最后标注出来的数据,一个字是真贵呀, 每标一帧都在滴血。经过1-2个月双方痛苦的磨合和优化过程,最终价格在一个合理的范围内了,不过现在回看,我们在22年标注的数据量还是有点多了。标定,最开始标定我们是求助外力来搞的,但是效果是真不行。最终只能自己动手风衣足食,磕磕绊绊搞了一个lidar 和7v 的联合标注。经过这一系列的操作,在这里感谢商汤开源的标定工具,https://github.com/pjlab-adg/sensorscalibration。我们终于搞到了质量还算可以的数据(现在回看,我们应该提早为时序模型的数据进行布局)。然后就是部署了,我记得很清楚上海刚好有疫情,然后我们居家了3个月左右。我们差不多痛苦了1个多月,在部署的时候,有一些算子不支持(也主要是2D-to-3D 的算子),后面是转出来模型性能差,然后优化。然后是Pytroch 的模型和转出来在工程上部署的模型掉点很严重,我们曾一度想搞一个Fcos3D(https://arxiv.org/abs/2104.10956) 的网络先搞到板子上。组内的同学很给力的,我们差不多就3-4个人力左右的情况下,最后我们的模型能跑到10hz, 然后在大家的努力下我们差不多在22年7,8月份的时候,我们的视觉 BEV 障碍物就能跑上车了。看到BEV 障碍物在车上实时跑起来的时候,还是感觉到很兴奋的。(跨相机的case 是真稳,整个后处理pipeline 是真的很简洁的)。整个22年对我们来说收获还很大的,BEV 障碍物跑的不错。但22年我们也面临了来自项目的压力我们曾面临着人力资源紧缺,只有一个人力在投入在BEV 上面,还好大家坚持了下。
4:收获的23年
在前面差不多1年多的积累下,也随着组内的资源越来越多,23年我们做出来BEV 车道线,还有前融合的BEV多任务模型,端到端的红绿灯(一介书生:城市自动驾驶红绿灯方案何去何从?)目前都已经落地,在项目中开始测试,交付中。目前我们在探索时序的BEV,以及大模型相关的(一介书生:2024年自动驾驶标注行业是否会被世界模型所颠覆?) 现在来看在21年投入去积累BEV技术,是一个很恰当的时机,当然抛开技术本身,我们老大也顶下来很大的压力和质疑,因为有人的地方就有江湖的。
#自动驾驶岗位

算法工程师
- 激光SLAM算法工程师
- 视觉SLAM算法工程师
- 多传感器融合算法工程师
- 机器学习算法工程师
- 计算机视觉算法工程师
- 自然语言处理算法工程师
- 决策算法工程师
- 规划算法工程师
- 控制算法工程师
非算法类工程师
- 软件平台开发工程师
- 系统工程师
- 功能安全工程师
- 标定工程师
- 仿真环境工程师
- 测试工程师
- 数据工程师
- UI开发工程师
- 下面详细介绍每个岗位的工作职责和需要学习的内容
2.算法工程师
2.1.激光SLAM算法工程师

岗位介绍:
- 采集激光传感器数据,根据点云数据对自动驾驶车辆的周围环境进行地图构建。
- 负责实现基于激光传感器的SLAM算法设计和开发,能够覆盖各种复杂场景的高精度地图更新和制作。
技能要求:
- 使用c、c++编程;
- 需要有滤波算法知识:ESKF、EKF、UKF等;
- 同时需要学习G2O、ceres等用来优化非线性误差函数的c++框架。
- 熟悉开源SLAM框架,如GLoam、kimera、VINS等优先;
2.2.视觉SLAM算法工程师

岗位介绍:
- 以VSLAM为基础,研发机器人自主导航定位算法,包括基于激光雷达、陀螺仪、里程计、视觉等多信息融合,构建机器人运动模型
技能要求:
- 学习常用的VSLAM算法,如ORB-SLAM、SVO、DSO、MonoSLAM,VINS以及RGB-D等;
- ROS机器人操作系统;
- 需要有滤波算法知识:ESKF、EKF、UKF等;
- 同时需要学习G2O、ceres等用来优化非线性误差函数的c++框架。
2.3.多传感器融合算法工程师

岗位介绍:
- 将相机、激光雷达、毫米波雷达等多传感器的信息处理和融合,提高自 主驾驶车的环境感知能力;
- 负责基于多源信息融合的目标检测、跟踪、识别与定位;
- 负责基于多源信息融合的环境特征抽取,为地图构建提供支持;为基于基于多源信息融合的导航定位提供支持。
技能要求:
- 掌握camera、毫米波雷达、激光雷达、惯性导航等相关数据解析融合算法;
- 计算机信息科学、电子工程或数学相关专业本科及以上学历,具备扎实的计算机理论基础
- 精度相机模型、多视觉几何、Bundle Adjustment 原理,有SfM、几何测距等项目经验
- 精通C/C++,熟悉Matlab,良好的面向对象编程思想和编码习惯
- 熟悉IMU、GPS、DR等惯导定位算法框架
- 熟悉IMU、GPS、车身系统原理、硬件特性、标定算法
2.4.机器学习算法工程师
岗位介绍:
- 该方向主要负责车辆行驶过程中产生的数据在工程上的应用,偏向于数据分析方向,如车辆行驶里程的影响分析、大数据分析建模等等。
技能要求:
- Python,C/C++
- 学习机器学习的基础理论算法,如 LR、GBDT、SVM、DNN等等;
- 学习scikit-learn 等传统机器学习框架的模型训练;
- 熟悉 PyTorch、TensorFlow等深度学习框架(偏神经网络部分)等等。
2.5.计算机视觉算法工程师

岗位介绍:
- 该方向主要基于摄像头传感器,主要包括:车道线检测、车辆等障碍物检测、可行驶区域检测、红绿灯等交通信息检测等等。
技能要求:
- C/C++,Python,OpenCV;
- 需要机器学习的基本算法 ( 降维、分类、回归等 );
- 需要学习深度学习,深度学习框架;
- 学习计算机视觉和图像处理的常用方法 ( 物体检测、跟踪、分割、分类识别等 ) 。
2.6.自然语言处理算法工程师
岗位介绍:
- 该方向主要负责车载场景下的语音识别,语音交互设计等等
技能要求:
- 学习机器学习算法、深度学习算法(RNN);
- 自然语言处理基本任务(分词、词性标注、句法分析、关键字抽取)
- 需要使用机器学习方法聚类、分类、回归、排序等模型解决文本业务问题;
- 熟悉 PyTorch、TensorFlow等深度学习框架(偏RNN部分)等等。
2.7.决策算法工程师

岗位介绍:
- 自动驾驶的决策是将感知模块传递的信息,转化成车辆的行为,达到驾驶的目标。例如,汽车加速、减速、左转、右转、换道、超车都是决策模块的输出。决策需要考虑到汽车的安全性和舒适性,保证乘客的安全的情况下,尽快到达目标地点。
技能要求:
- c/c++/python,熟悉ROS系统;
- 学习常用的决策算法,如决策状态机、决策树、马尔可夫决策过程,POMDP等;
- 如果往深里学的话,需要熟悉机器学习算法(RNN、LSTM、RL),掌握至少一种深度学习框架(比如gym或者universe等深度强化学习平台);
- 熟悉车辆运动学和动力学模型。
2.8.规划算法工程师

岗位介绍:
- 规划包括路径规划和速度规划
- 规划算法中,自动驾驶车辆首先通过路径规划确定车辆可行驶的路径,然后选择该路径确定可行驶的速度。
技能要求:
- c/c++/python,ROS机器人操作系统;(有些公司是用Matlab/simulink开发的)
- 学习常见路径规划算法,例如A*、D*、RRT等;
- 学习一些曲线的表示方法,如:五次曲线、回旋线、三次样条曲线、B样条曲线等;
- 如果往深里学的话;学习轨迹预测算法,如MDP、POMDP、Came Theory等;
- 学习深度学习和强化学习技术也是加分项,例如RNN、LSTM、Deep Q-Learning等;
- 有数学理论基础和背景,熟悉车辆运动学和动力学模型。
2.9.控制算法工程师

岗位介绍:
- 一般是对车辆横纵向动力学建模,然后开发控制算法,实现车辆运动控制等;
- 这个岗位跟车辆打交道较多,对于传统车厂转型到自动驾驶领域的伙伴来说,是个很好的切入机会。
技能要求:
- C/C++、Matlab/Simulink
- 学习自动控制理论基础,学习现代控制理论;
- 学习PID、LQR、MPC算法;
- 学习车辆运动学、动力学模型,对汽车的底盘有一定了解;
- 学习CarSim等仿真软件;
- 学习ACC、AEB、APA、LKA、LCC等辅助驾驶功能开发的是加分项;
- 拥有实车调试经验也是加分项。
3.非算法类工程师
3.1.软件平台开发工程师
岗位介绍:
- 设计和实现自动驾驶软件平台,包括内核修改/扩展、驱动程序实现/增强、中间件实现/增强、系统集成、性能/功耗优化、压力/稳定性/符合性测试;
- 负责搭建系统架构、编写底层驱动程序;
- 负责视觉相关算法在嵌入式处理器(GPU、DSP、ARM等平台)上的代码实现及性能优化、测试和维护;
- 协助算法工程师完成算法在嵌入平台上的移植、集成、测试和优化。
技能要求:
- C/C++编程技巧、Python;
- 具有嵌入式操作系统和实时操作系统的内核或驱动开发经验,熟悉QNX、ROS;
- 熟悉软件调试和debug工具;
- 了解车辆ADAS ECU和传感器,如雷达、摄像头、超声波和激光雷达;
- 熟悉通用诊断服务(UDS)、控制器局域网(CAN);
- 熟悉通信协议(CAN、UDS、DoIP、SOME/IP、DDS、MQTT、REST等)是加分项。
3.2.系统工程师
岗位介绍:
- 负责客户需求对接,以及与内部开发人员的需求释放;
- 负责无人驾驶软件系统框架构建 ;
- 负责模块化、可验证的系统软件架构设计和实时性能优化;
- 与硬件、算法和测试团队合作,集成并优化自动驾驶系统。
技能要求:
- 拥有扎实的计算机基础理论知识(如:自动控制、模式识别、机器学习、计算机视觉、点云处理);
- 具有嵌入式操作系统和实时操作系统的内核或驱动开发经验;
- 具备很好的沟通表达能力和团队合作意识
3.3.功能安全工程师
岗位介绍:
- 在产品全生命周期内对产品的功能安全进行支持
- 负责无人/自动驾驶系统产品的功能安全系统设计,并对现有流程提出改进意见;
- 负责无人/自动驾驶系统的危险分析(HARA, FMEAs, FMEDA, FTA);
- 负责无人/自动驾驶系统的安全目标定义;
- 负责无人/自动驾驶系统的安全需求定义;
技能要求:
- 精通ISO26262并有自动驾驶或者ADAS系统功能安全项目实施经验;(在传统车厂做功能安全想要转行的也可以考虑);
- 了解FMEA,FMEDA,FMEA-MSR,FTA等相应的方法;
3.4标定工程师
岗位介绍:
- 负责自动驾驶多传感器标定,包括GPS、IMU、LiDAR、Camera、Radar 和 USS 等;
- 设计实现传感器内参外参标定算法,搭建多传感器标定系统;
- 负责对标定参数进行相关车辆测试,给出测试报告。
技能要求:
- C++编程, 熟悉 Linux及ROS系统;
- 有传感器标定工作经历,熟悉视觉或激光 SLAM 算法;
3.5仿真环境工程师

岗位介绍:
- 该方向需要参与自动驾驶相关仿真系统的搭建,包括车辆动力学相关仿真,各类虚拟传感器模型和虚拟场景的建模与仿真,根据测试案例搭建测试场景,执行自动驾驶算法仿真测试等等;
- 负责搭建无人驾驶模拟系统,对汽车、传感器、环境进行软件模拟。模拟结果将与真实数据一同用于预测汽车在真实场景中的行为;
- 配合驾驶决策、路径规划、仿真算法等模块,实现自动驾驶闭环仿真,并可视化相关调试信息。
技能要求:
- MATLAB/simulink、Python/C++
- 熟练操作一种常用车辆动力学或无人车相关仿真软件,比如Perscan、Carsim、Carmaker等;
- 熟悉机器人操作系统ROS等;
- 有的仿真岗位纯属于做仿真,但有的岗位需要做仿真环境的开发,这样的岗位对编程要求会更高一些。
3.6测试工程师
岗位介绍:
- 该方向主要负责自动驾驶车辆的相关测试工作,测试自动驾驶系统功能各项指标的性能,评估其边界条件和失效模式;
- 负责自动化测试(SIL、HIL)的设计实现及智能驾驶产品的相关验证;
- 负责根据系统或产品的功能需求制定测试用例和测试计划;
- 负责制定完整的系统或产品的测试计划并实施,最后撰写测试报告;
- 收集和测试系统的边界样例,对智能驾驶系统的安全性进行评估,对技术提出合理的反馈。
技能要求:
- 熟悉Ubuntu/Linux操作系统,会写python脚本
- 熟悉CAN总线;
- 熟悉测试用例的编写方法和技巧;
- 熟悉图像识别算法,熟悉深度学习,掌握spark等大数据相关工具者加分;
- 熟悉激光雷达,毫米波雷达,超声波探头和摄像头的应用是加分项。
3.7大数据开发工程师
岗位介绍:
- 数据包括后台数据架构和前台呈现。一辆自动驾驶车每天都要生成1个T的数据量。数据该怎样快速清洗、提炼、总结,比如怎样迅速找出一次路测中最重要的几次介入(disengagements)。从而更高效的帮助工程师测试。
- 负责自动驾驶大数据平台系统的设计、开发和优化;
- 负责自动驾驶数据标注与处理流程的可视化工具开发,自动化标注平台的设计与研发。
技能要求:
- 具备扎实的数据结构及算法功底;
- 精通Java/Python/C++等至少一门高级编程语言;
- 熟悉Linux开发环境;
- 有基于SQL或No-SQL数据库的应用程序的设计、开发经验;
- 熟悉REST服务及Web标准,熟悉一种主流前端开发框架,如React/AngularJS,能独立构建前端应用者加分;
- 熟悉自动驾驶及相关的Lidar、Camera等传感器数据者加分。
3.8.UI开发工程师
岗位介绍:
- 每个公司都需要搭建内部工具,用于验证整车开发。也需要给远程控制中心做各种交互页面,通过一个UI远程控制自动驾驶车。同时也包括车厢内为乘客准备的UI。喜欢设计或者擅长前端的朋友可以考虑。
技能要求:
- 具有优秀的审美和丰富的视觉表现力;
- 精通色彩、图形、信息和GUI设计原则及方法。
#SparseAD
端到端的范式使用统一的框架在自动驾驶系统中实现多任务。尽管这种范式具有简单性和清晰性,但端到端的自动驾驶方法在子任务上的性能仍然远远落后于单任务方法。同时,先前端到端方法中广泛使用的密集鸟瞰图(BEV)特征使得扩展到更多模态或任务变得成本高昂。这里提出了一种稀疏查询为中心的端到端自动驾驶范式(SparseAD),其中稀疏查询完全代表整个驾驶场景,包括空间、时间和任务,无需任何密集的BEV表示。具体来说,设计了一个统一的稀疏架构,用于包括检测、跟踪和在线地图绘制在内的感知任务。此外,重新审视了运动预测和规划,并设计了一个更合理的运动规划框架。在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中实现了最先进的全任务性能,并显著缩小了端到端范式与单任务方法之间的性能差距。
领域背景
自动驾驶系统需要在复杂的驾驶场景中做出正确的决策,以确保驾驶的安全性和舒适性。通常,自动驾驶系统集成了多个任务,如检测、跟踪、在线地图、运动预测和规划。如图1a所示,传统的模块化范式将复杂的系统拆分为多个单独的任务,每个任务都独立优化。在这种范式中,独立的单任务模块之间需要手工进行后处理,这使得整个流程变得更为繁琐。另一方面,由于堆叠任务之间的场景信息损失压缩,整个系统的误差会逐渐累积,这可能导致潜在的安全问题。

关于上述问题,端到端自动驾驶系统以原始传感器数据作为输入,并以更简洁的方式返回规划结果。早期的工作提出跳过中间任务,直接从原始传感器数据预测规划结果。尽管这种方法更为直接,但在模型优化、可解释性和规划性能方面并不令人满意。另一种具有更好可解释性的多面范式是将自动驾驶的多个部分集成到一个模块化的端到端模型中,其中引入了多维度的监督,以提高对复杂驾驶场景的理解能力,并带来多任务处理的能力。
如图1b所示,在大多数先前的模块化端到端方法中,整个驾驶场景通过密集的鸟瞰图(BEV)特征进行表示,这些特征包括多传感器和时间信息,并作为全栈驾驶任务(包括感知、预测和规划)的源输入。尽管密集的BEV特征在跨空间和时间的多模态和多任务中确实发挥了关键作用,将之前使用BEV表示的端到端方法总结为Dense BEV-Centric范式。然而,尽管这些方法具有简洁性和可解释性,它们在自动驾驶的每个子任务上的性能仍然远远落后于相应的单任务方法。此外,在Dense BEV-Centric范式下,长期时间融合和多模态融合主要是通过多个BEV特征图来实现的,这导致了计算成本、内存占用显著增加,给实际部署带来了更大的负担。
这里提出了一种新颖的以稀疏查询为中心的端到端自动驾驶范式(SparseAD)。在该范式中,整个驾驶场景中的空间和时间元素均由稀疏查询表示,摒弃了传统的密集鸟瞰图(BEV)特征,如图1c所示。这种稀疏表示使得端到端模型能够更高效地利用更长的历史信息,并扩展到更多模态和任务,同时显著降低了计算成本和内存占用。
具体来说,重新设计了模块化端到端架构,并将其简化为一个由稀疏感知和运动规划器组成的简洁结构。在稀疏感知模块中,利用通用的时间解码器[将包括检测、跟踪和在线地图绘制在内的感知任务统一起来。在这个过程中,多传感器特征和历史记忆被视为tokens,而物体查询和地图查询则分别代表驾驶场景中的障碍物和道路元素。在运动规划器中,以稀疏感知查询作为环境表示,同时对自车和周围代理进行多模态运动预测,以获取自车的多种初始规划方案。随后,充分考虑多维度的驾驶约束,生成最终的规划结果。
主要贡献:
- 提出了一种新颖的以稀疏查询为中心的端到端自动驾驶范式(SparseAD),该范式摒弃了传统的密集鸟瞰图(BEV)表示方法,因此具有巨大的潜力,能够高效地扩展到更多模态和任务。
- 将模块化的端到端架构简化为稀疏感知和运动规划两部分。在稀疏感知部分,以完全稀疏的方式统一了检测、跟踪和在线地图绘制等感知任务;而在运动规划部分,则在更合理的框架下进行了运动预测和规划。
- 在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中取得了最先进的性能,并显著缩小了端到端范式与单任务方法之间的性能差距。这充分证明了所提出的稀疏端到端范式具有巨大的潜力。SparseAD不仅提高了自动驾驶系统的性能和效率,还为未来的研究和应用提供了新的方向和可能性。
SparseAD网络结构
如图1c所示,在提出的以稀疏查询为中心的范式中,不同的稀疏查询完全代表了整个驾驶场景,不仅负责模块之间的信息传递和交互,还以端到端的方式在多任务中传播反向梯度以进行优化。与以往以密集鸟瞰图(BEV)为中心的方法不同,SparseAD中没有使用任何视图投影和密集BEV特征,从而避免了沉重的计算和内存负担,SparseAD的详细架构如图2所示。

从架构示意图上看,SparseAD主要由三部分组成,包括传感器编码器、稀疏感知和运动规划器。具体来说,传感器编码器将多视图相机图像、雷达或激光雷达点作为输入,并将其编码成高维特征。这些特征随后与位置嵌入(PE)一起作为传感器tokens输入到稀疏感知模块中。在稀疏感知模块中,来自传感器的原始数据将被聚合成多种稀疏感知查询,如检测查询、跟踪查询和地图查询,它们分别代表驾驶场景中的不同元素,并将进一步传播到下游任务中。在运动规划器中,感知查询被视为驾驶场景的稀疏表示,并被充分利用于所有周围agent和自车。同时,考虑了多方面的驾驶约束以生成既安全又符合动力学要求的最终规划。
此外,架构中引入了端到端多任务记忆库,用于统一存储整个驾驶场景的时序信息,这使得系统能够受益于长时间历史信息的聚合,从而完成全栈驾驶任务。
如图3所示,SparseAD的稀疏感知模块以稀疏的方式统一了多个感知任务,包括检测、跟踪和在线地图绘制。具体来说,这里有两个结构完全相同的时序解码器,它们利用来自记忆库的长期历史信息。其中一个解码器用于障碍物感知,另一个用于在线地图绘制。

通过不同任务对应的感知查询进行信息聚合后,检测和跟踪头以及地图部分别被用于解码和输出障碍物和地图元素。之后,进行更新过程,该过程会过滤并保存当前帧的高置信度感知查询,并相应地更新记忆库,这将有利于下一帧的感知过程。
通过这种方式,SparseAD的稀疏感知模块实现了对驾驶场景的高效、准确的感知,为后续的运动规划提供了重要的信息基础。同时,通过利用记忆库中的历史信息,模块能够进一步提高感知的准确性和稳定性,确保自动驾驶系统的可靠运行。
稀疏感知
在障碍物感知方面,在统一的解码器内采用联合检测和跟踪的方式,无需任何额外的手工后处理。检测和跟踪查询之间存在明显的不平衡,这可能导致检测性能的显著下降。为了缓解上述问题,从多个角度改进了障碍物感知的性能。首先,引入了两级记忆机制来跨帧传播时序信息。其中,场景级记忆维持没有跨帧关联的查询信息,而实例级记忆则保持跟踪障碍物相邻帧之间的对应关系。其次,考虑到两者起源和任务的不同,对场景级和实例级记忆采用了不同的更新策略。具体来说,通过MLN来更新场景级记忆,而实例级记忆则通过每个障碍物的未来预测进行更新。此外,在训练过程中,还对跟踪查询采用了增强策略,以平衡两级记忆之间的监督,从而增强检测和跟踪性能。之后,通过检测和跟踪头部,可以从检测或跟踪查询中解码出具有属性和唯一ID的3D边界框,然后进一步用于下游任务。
在线地图构建是一个复杂而重要的任务。根据目前所了解的知识,现有的在线地图构建方法大多依赖于密集的鸟瞰视图(BEV)特征来表示驾驶环境。这种方法在扩展感知范围或利用历史信息方面存在困难,因为需要大量的内存和计算资源。我们坚信所有的地图元素都可以以稀疏的方式表示,因此,尝试在稀疏范式下完成在线地图构建。具体来说,采用了与障碍物感知任务中相同的时序解码器结构。最初,带有先验类别的地图查询被初始化为在驾驶平面上均匀分布。在时序解码器中,地图查询与传感器标记和历史记忆标记进行交互。这些历史记忆标记实际上是由之前帧中高度可信的地图查询组成的。然后,更新后的地图查询携带了当前帧地图元素的有效信息,可以被推送到记忆库中,以便在未来的帧或下游任务中使用。
显然,在线地图构建的流程与障碍物感知大致相同。也就是说,统一了包括检测、跟踪和在线地图构建在内的感知任务,采用了一种通用的稀疏方式,这种方式在扩展到更大范围(例如100m × 100m)或长期融合时更加高效,而且不需要任何复杂的操作(如可变形注意力或多点注意力)。据我们所知,这是第一个在稀疏方式下在统一感知架构中实现在线地图构建的。随后,利用分段贝塞尔地图Head来回归每个稀疏地图元素的分段贝塞尔控制点,这些控制点可以方便地转换以满足下游任务的要求。
Motion Planner
我们重新审视了自动驾驶系统中的运动预测与规划问题,并发现许多先前的方法在预测周围车辆运动时忽略了本车(ego-vehicle)的动态。虽然这在大多数情况下可能不会显现出来,但在诸如交叉口等场景中,当近处车辆与本车之间交互紧密时,这可能会带来潜在风险。受此启发,设计了一个更加合理的运动规划框架。在这个框架中,运动预测器同时预测周围车辆和本车的运动。随后,本车的预测结果作为运动先验被用于后续的规划优化器。在规划过程中,我们考虑了不同方面的约束,以产生既满足安全性又符合动力学要求的最终规划结果。

如图4所示,SparseAD中的运动规划器将感知查询(包括轨迹查询和地图查询)作为当前驾驶场景的稀疏表示。多模态运动查询被用作媒介,以实现对驾驶场景的理解、对所有车辆(包括本车)之间交互的感知,以及对不同未来可能性的博弈。随后,本车的多模态运动查询被送入规划优化器,其中充分考虑了包括高级指令、安全性和动力学在内的多个方面的驾驶约束。
运动预测器。遵循先前的方法,通过标准的transformer层实现了运动查询与当前驾驶场景表示(包括轨迹查询和地图查询)之间的感知和整合。此外,应用自车agent和跨模态交互来共同建模未来时空场景中周围agent和本车之间的交互。通过多层堆叠结构内部和之间的模块协同作用,运动查询能够聚合来自静态和动态环境的丰富语义信息。
除了上述内容外,还引入了两种策略来进一步提高运动预测器的性能。首先,利用轨迹查询的实例级时间记忆进行简单直接的预测,并将其作为周围agent运动查询初始化的一部分。通过这种方式,运动预测器能够从上游任务中获得的先验知识中受益。其次,得益于端到端记忆库,能够以几乎可忽略的成本、以流式方式通过代理记忆聚合器从保存的历史运动查询中同化有用信息。
需要注意的是,本车的多模态运动查询是同时更新的。通过这种方式,可以获得本车的运动先验,这可以进一步促进规划的学习过程。
规划优化器。借助运动预测器提供的运动先验,获得了更好的初始化,从而在训练过程中减少了绕行。作为运动规划器的关键组成部分,成本函数的设计至关重要,因为它将极大地影响甚至决定最终性能的质量。在提出的SparseAD运动规划器中,主要考虑安全和动力学两大方面的约束,旨在生成令人满意的规划结果。具体来说,除了VAD中确定的约束外,还重点关注本车与附近agent之间的动态安全关系,并考虑它们在未来时刻的相对位置。例如,如果agent i相对于本车持续保持在前方左侧区域,从而阻止本车向左变道,那么agent i将获得一个左标签,表示agent i对本车施加了向左的约束。因此,约束在纵向方向上被分为前、后或无,在横向方向上被分为左、右或无。在规划器中,我们从相应的查询中解码其他agent与本车在横向和纵向方向上的关系。这个过程涉及确定这些方向上其他代理与本车之间所有约束关系的概率。然后,我们利用focal loss作为Ego-Agent关系(EAR)的成本函数,有效地捕获附近agent带来的潜在风险:

实验结果
在nuScenes数据集上进行了大量实验,以证明方法的有效性和优越性。公正地说,将对每个完整任务的性能进行评估,并与之前的方法进行比较。本节实验使用了SparseAD的三种不同配置,分别是仅使用图像输入的SparseAD-B和SparseAD-L,以及使用雷达点云和图像多模态输入的SparseAD-BR。SparseAD-B和SparseAD-BR都使用V2-99作为图像骨干网络,输入图像分辨率为1600 × 640。SparseAD-L则进一步利用ViTLarge作为图像骨干网络,输入图像分辨率为1600×800。
在nuScenes验证数据集上的3D检测和3D多目标跟踪结果如下。"仅跟踪方法"指的是通过后期处理关联进行跟踪的方法。"端到端自动驾驶方法"指的是具备自动驾驶全栈任务能力的方法。表中的所有方法都是在全分辨率图像输入下进行评估的。†:结果是通过官方开源代码复现的。-R:表示使用了雷达点云输入。
与在线建图方法的性能比较如下,结果是在1.0m, 1.5m, 2.0m的阈值下进行评估的。‡:通过官方开源代码复现的结果。†:根据SparseAD中规划模块的需求,我们进一步将边界细分为路段和车道,并分别进行评估。∗:骨干网络和稀疏感知模块的成本。-R:表示使用了雷达点云输入。
Multi-Task结果
障碍感知。在Tab. 2中将SparseAD的检测和跟踪性能与nuScenes验证集上的其他方法进行了比较。显然,SparseAD-B在大多数流行的仅检测、仅跟踪和端到端多目标跟踪方法中表现出色,同时与SOTA方法如StreamPETR、QTrack在相应任务上的性能相当。通过采用更先进的骨干网络进行扩展,SparseAD-Large实现了整体更好的性能,其mAP为53.6%,NDS为62.5%,AMOTA为60.6%,整体上优于之前的最佳方法Sparse4Dv3。
在线建图。在Tab. 3中展示了SparseAD与其他先前方法在nuScenes验证集上的在线建图性能比较结果。需要指出的是,根据规划的需求,我们将边界细分为路段和车道,并分别进行评估,同时将范围从通常的60m × 30m扩展到102.4m × 102.4m,以与障碍感知保持一致。在不失公平性的前提下,SparseAD以稀疏的端到端方式实现了34.2%的mAP,无需任何密集的BEV表示,这优于大多数之前流行的方法,如HDMapNet、VectorMapNet和MapTR,在性能和训练成本方面都具有明显优势。尽管性能略逊于StreamMapNet,但我们的方法证明了在线建图可以在统一的稀疏方式下完成,无需任何密集的BEV表示,这对于以显著较低成本实现端到端自动驾驶的实际部署具有重要意义。诚然,如何有效利用其他模态(如雷达)的有用信息仍是一个值得进一步探索的任务。我们相信在稀疏方式下仍有很大的探索空间。
运动预测。在Tab. 4a中展示了运动预测的比较结果,其中指标与VIP3D保持一致。SparseAD在所有端到端方法中实现了最佳性能,具有最低的0.83m minADE、1.58m minFDE、18.7%的遗漏率以及最高的0.308 EPA,优势巨大。此外,得益于稀疏查询中心范式的效率和可扩展性,SparseAD可以有效地扩展到更多模态,并从先进的骨干网络中受益,从而进一步显著提高预测性能。
规划。规划的结果呈现在Tab. 4b中。得益于上游感知模块和运动规划器的卓越设计,SparseAD的所有版本在nuScenes验证数据集上都达到了最先进水平。具体来说,与包括UniAD和VAD在内的所有其他方法相比,SparseAD-B实现了最低的平均L2误差和碰撞率,这证明了我们的方法和架构的优越性。与上游任务(包括障碍感知和运动预测)类似,SparseAD通过雷达或更强大的骨干网络进一步提升了性能。


#视觉和Lidar里程计
自动驾驶的发展需要研究和开发准确可靠的自定位方法。其中包括视觉里程计方法,在这种方法中,精度可能优于基于GNSS的技术,同时也适用于无GPS信号的区域。本文深入回顾了视觉和点云里程计SOTA方法,并对其中一些技术在自动驾驶环境中的性能进行了直接比较。评估的方法包括相机、激光雷达和多模态方法,并从共同的角度比较了基于特征知识和基于学习的算法。
在过去十年中,自动驾驶一直是许多技术和科学研究的主题。它的许多好处,如提高乘客安全性、舒适性和便利性、更好的交通流量、无人驾驶交通和降低了燃料消耗,吸引了负责自动驾驶汽车技术进步的大型制造商的投资。对于任何自动驾驶智能体,自定位的能力在每个导航任务中都是必不可少的。尽管GNSS(全球导航卫星系统)接收器通常是现代车辆自定位的主要来源,但大众市场设备提供的精度和可靠性远远低于自动驾驶车辆所需的水平。因此,由于定位误差、信号延迟和服务质量问题的不确定性,自动驾驶车辆不会强依赖于卫星数据1。而且这一问题在城市场景中进一步加剧1,由于此场景中卫星能见度有限、多径效应、干扰和其他误差。人类驾驶员自己的视觉感知能力弥补了所有这些限制。以同样的方式,自动驾驶汽车可以配备传感器,当与适当的里程计技术一起使用时,传感器可以提供类似人类水平的精确的相对定位。
里程计可以被定义为使用局部传感器的数据来估计一个特定的起始点,估计一段时间内车辆的姿态变化。通常,这些方法试图通过传感器(如车轮编码器、RADAR、惯性测量单元(IMU)、LiDAR)来恢复车辆的位置和方向,这些传感器在现代车辆中越来越普遍。同样重要的是,要认识到这些传感器类型不是限制死的,因为里程计方法可以是多模态的,即不同的传感器可以通过一个算法一起使用。随着相机和激光雷达在现代车辆中的使用越来越普遍,基于视觉和点云的里程计正在成为关键的方法。与GNSS不同,这些传感器不需要外部信号。此外,这些技术比车轮里程计更为稳健,并且易于通过IMU或GPS进行补充2。
随着政府对驾驶员辅助和自动驾驶安全功能的需求增加,自动驾驶相关领域的研究也在增加。参与感知领域的里程计对开发此类系统至关重要。本研究提供了视觉、点云和多模态里程计的概述,并将这些类别与一个共同的基准进行了比较,同时考虑了在完全相同的条件下获得的实际结果。此外,深度学习(DL)技术的兴起使得有必要评估其相对于传统方法的发展现状。这项工作背后的另一个动机是使用一个众所周知的数据集(KITTI-3603)创建一个最先进的视觉、基于点云和多模态方法的无偏见基准。基准测试在具有挑战性的情况下测试不同的算法,以验证所调研技术的优势和局限性。本文件还讨论了一些当前的问题,这些问题可以帮助研究人员超越常见的视觉里程限制,例如恶劣的天气条件、计算能力限制和动态目标的存在。
本调研主要贡献是:
**(1)**视觉里程计相关和有前景的工作的分类和理论讨论,从基于特征和外观的技术到利用深度学习能力的最新工作;基于点云的里程计,包括基于知识和学习的方法;同时还分析了不同类型的传感器融合。在相同场景下,使用通用评估程序对这些技术进行了分析;
**(2)**对几种开源算法进行基准测试的大量实验,特别关注动态环境、开放空间、亮度变化、密集植被、转向机动和高速等具有挑战性的情况;
**(3)**识别自运动估计的当前挑战,例如对场景外观的依赖性、高计算负载和移动目标的存在。分析和量化这些条件对不同类型所述方法性能的影响;
**(4)**识别自运动估计的当前挑战,例如对场景外观的依赖性、高计算负载和移动目标的存在。分析和量化这些条件对不同类型所述方法性能的影响;
视觉里程计

现有的 VO 方法可以分为两类: 基于知识的方法和基于学习的方法。前者利用相机的几何关系来评估运动,而后者则基于机器学习技术,依赖于大量的数据来获得姿态预测能力。如下图所示,基于知识的方法可以分为三个子组: 基于外观的、基于特征的和混合的,这取决于如何使用视觉组件来生成里程计估计值。

基于知识的技术
基于特征的方法侧重于这样一个前提,即每帧中的关键点或区域可以用来确定相机的运动。这些关键点由角、边、线和斑点组成,这些图像模式在强度、颜色或纹理方面与周围环境不同,因此更可能在多个图像中匹配良好2 ,4 ,5。对于特征提取,通常采用 SIFT 6、 SURF 7、 ORB 8和 BRISK 9。基于特征的VO对于几何失真和照明不一致都有相当强的鲁棒性10。然而,由于这些方法高度依赖于正确的对应关系,因此只选取图像中的某些点,就会丢弃一些有价值的信息,因此必须尽量减少异常值的存在。下图描述了基于特征的算法所使用的pipline。

因为这些pipline通常遵循结构化的pipline,其中涉及特征检测和匹配阶段(或特征跟踪) ,然后是运动估计,最后是优化步骤。尽管这些步骤通常是横向的,但是每种技术提出它们的方式都是不同的。
在运动估计中,最常用的方法包括特征-特征匹配(2D-2D) ,它利用了纵向几何的约束。纵向约束与从不同角度看到的相同特征有关,其中 P1和 P2是图像坐标上图像1和图像2中同一点的坐标,E 是本质矩阵。通过选择一组匹配,可以计算出运动参数(E 中隐含的) ,从而使纵向约束带来的误差最小化。

ORB-SLAM212是 VO 和SLAM中流行的算法。它是 ORB-SLAM 13用于单目、多目和 RGB-D 相机的扩展。这种开源方法通常被认为是视觉里程计的基准。作为一种 SLAM 技术,该算法由三个线程组成: 跟踪和局部建图,里程计模块和闭环。运动估计是利用关键帧和局部地图上跟踪的 ORB 特征计算出来的,特别强调多步光束法平差。VISO214是2011年的另一个流行算法,它可以使用立体相机构建环境的3D 地图。这种方法应用了著名的立体匹配方法将稀疏的特征集与使用卡尔曼滤波器的里程计方法相结合15。此外,Cvisic和 Petrovi 16-18的工作在基于视觉特征的方法领域具有特殊的相关性,因为他们的结果使视觉方法的精度更接近基于 LiDAR 技术的精度水平。在16中,作者提出了一个立体里程计算法,其主要重点是仔细选择和跟踪特征(SOFT)和这些步骤对自运动估计的影响。旋转和平移分别计算,以提高整个系统的性能。对于旋转,Nister 的5点19以单目方式使用,以概率地减少异常值和不完善的立体设备标定的有害影响,同时利用旋转以后使用3点计算平移。此外,该算法的一个扩展被提出来积分 IMU,用卡尔曼滤波器估计旋转集成。第一个估计有助于进一步去除异常值和减轻计算成本的5点算法,使用 P3P 20和 Ransac 21替代。当通过视觉里程计计算旋转时,Kalman 会更新。后来,Cvisic和 Petrovi用一个附加的建图线程扩展了 SOFT,从而产生了 SOFT-SLAM 17。这种方法最初是为自动驾驶飞行器设计的,侧重于计算效率。SLAM 集成了 SOFT 可视里程计pipline,并通过一个建图模块完成,该建图模块增加了 SLAM 的特性,如闭环和全局一致性约束。这些增加的能力使得这种技术在 KITTI 数据集22中的定位精度优于其最先进的替代方案,如 ORB-SLAM2和 LSD-SLAM 23。最近,Cvisic 等人18重新审视了 KITTI 里程数据集的标定参数。在最后的工作中,作者提出了一种新的一次性标定多相机 KITTI 装置参数的方法,该方法可以获得较小的重投影误差,直接影响 VO 算法的精度。将调整后的参数应用于 ORB-SLAM2、 SOFT 和 VISO2,平移误差平均提高了28% ,旋转误差平均提高了46% 。
另一方面,基于特征的技术通过仅集中在少数几个选定的点来丢弃图像数据的重要部分。此外,这些技术可能需要额外的计算成本在匹配或跟踪操作和离群点去除。反过来,基于外观的 VO 技术利用捕获帧中的所有信息,而不仅仅是使用关键点。这些方法通过分析图像像素的强度并最小化光度误差来估计相机的姿态,这依赖于一帧中的像素在考虑移动传感器的同时保持其在第二帧中的强度的一致性原则5。通过这种方法,可以减轻由重复模式引起的混叠效应,并确保在有限纹理的场景中更加稳健,因为在这些场景中很难检测到好的特征(例如,雾或沙质环境)。基于外观的技术避免了提取和匹配特征以及运行异常去除算法所需的时间。另一方面,与基于特征的 VO 相比,它们对光照变化和相机突变运动敏感。基于外观的方法,也称为直接方法,一般分为基于区域匹配或基于光流的方法。前者通过在连续帧中对齐某些相应区域来估计相机的运动,但是在场景中存在动态目标的情况下,除了容易受到局部极小解的影响外,还会出现失效问题。另一方面,基于光流的技术利用环境场景的光流来估计基于运动模型的相机运动的6自由度(DoF)。下图在直接技术的通用pipline中汇总了两种方法。

为了减轻基于特征和基于外观的方法的缺点,以及聚合每种方法的附加值,还可以采用来自每个领域的不同方法。这些被称为混合技术5。
2017年,恩格尔等24提出了直接稀疏里程计法(DSO)。这个方法包括一个直接和稀疏的方案,因此不需要特征提取和配对操作。这种方法通过不断优化光度误差在一个有限的框架窗口。然而,与典型的直接方法相比,该方法同时对所有参数进行优化,包括自运动、相机标定和三维点的反深度。通过考虑完全误差,而不是仅仅考虑特定迭代的误差,该策略限制了异常值的影响。作者得出结论,有了合适的硬件(全局快门、精密镜头和高帧频) ,直接方法在精度方面可以超过几何/间接方法,这些方法在过去十年里一直主导着研究兴趣。传统(或几何)方法已经有了良好的基础,尽管这些方法在其演化过程中产生了合理的结果,但在复杂性增加的环境中,它们仍然被证明是脆弱的。事实上,仅仅依靠这些类型的技术变得极具挑战性,因为通过手工制定来捕捉现实世界的复杂性是极其困难的。
基于学习的技术
如在不同领域所见,数据驱动的基于学习的方法可以获得对场景的高层次理解,而不需要明确的建模,只要他们在足够大的代表性数据集上进行训练25。此外,相机标定参数不需要事先知道; 平移可以用正确的尺度估计,系统对图像噪声的鲁棒性更强26。因此,近年来 VO 的范式发生了转变,倾向于采用基于学习的方法。典型的数据驱动技术通常由多个具有不同功能的子网组成,例如深度估计、特征提取和自运动估计25。它们可以用来补充传统的pipline,也可以用来构建端到端的体系结构,如下图所示。

对网络进行训练的方法是,将输出与监督信号对接,或根据调整和微调网络参数的cost函数对输出进行评估。
Yang 等27提出了深度虚拟立体里程计(DVSO) ,它用一个基于深度学习的框架来补充 DSO。这项工作的核心是通过网络扩展 DSO 的能力,从而产生精确的深度估计,从而减少尺度漂移。提出的全卷积网络(FCN) StackNet 生成一对深度图,用于模拟虚拟立体平台。通过比较反向扭曲的产出和原始输入,以自监督的方式进行训练。这种技术在基于里程学习的方法中很常见,因此可以避免使用真值,而这些真值的获取成本很高。StackNet 的预测深度图被添加到原始 DSO 通用优化问题的预测深度图中,作为额外的几何约束。深度视觉里程计法迄今未能取代传统的方法。然而,这项工作超越了基于学习的替代方案,更接近于传统的最先进的技术。实际上,在 KITTI 选择的一组序列中,DVSO 比 ORB-SLAM2的平移误差略有提高,提高了2.2% 。此外,虽然 DVSO 不是一个端到端的视觉里程计架构,如 DeepVO 28 ,在 KITTI 数据集中 DVSO 的翻译误差是9.3倍。
2020年,同样是 DVSO 的作者,Yang等人29提出了Deep Depth,Deep Pose和Deep Uncertainty,也被称为 D3VO。D3VO 的总体结构与 DVSO 和 DSO 略有不同。在 D3VO 中,深度是由一个称为 DepthNet 的卷积网络估计的,它也预测与估计相关的不确定性。反过来,相机的姿态是由另一个叫做 PoseNet 的深度卷积网络估计出来的,除了变换之外,PoseNet 还可以平衡当前帧和之前帧的照度,这两个帧共同构成了一对网络输入,以减少由于光照变化而产生的误差。不确定性在此均衡过程中尤为重要,因为它有助于检测容易违反帧间光度一致性原则的非朗伯反射表面。DepthNet 和 PoseNet 都是以自监督和联合方式进行训练的。姿态预测基于以前的工作DVSO和DSO补充了一个直接跟踪前端模块和一个全局光束法平差后端模块。在轨迹精度方面,结果略高于DVSO(在选定的 KITTI 序列中为10%)。
与以前的方法不同,由 Wang 等人28提出的 DeepVO 是一种端到端的监督方法,其重点是学习具有适当几何意义的特征提取,并隐式建模一系列帧上的运动动力学。一对连续的图像被叠加并作为输入传递给卷积神经网络(CNN) ,生成一个输入对的简洁描述,然后被馈送给一个递归神经网络(RNN) ,允许捕捉视频的连续属性。尽管如此,与DVSO 和 D3VO 不同,其结果有些令人不满意。然而,这种方法允许非调优相关模型,它可以作为端到端DL方法的概念验证。事实上,计算机视觉中大多数常用的DL结构,如 CNN 和 RNN,并不适合 VO。这项工作可以作为一个起点,催化新的 VO 应用研究。ESP-VO 30通过计算姿态估计的不确定性扩展了这项工作,这对传感器融合特别有用。按照类似的路径,PoseCon-vGRU 31是一种端到端的可比方法。PoseCon-vGRU 利用 DeepVO 的时间效率,使用堆叠的门控循环单元(GRU)代替长短期内存模块(LSTM)。LSTM 和 GRU 是特定类型的 RNN,它们通过学习和在内部存储与保持或不保持内部状态相关的内容来捕获连续输入之间的长期关系。这种类型的结构是特别重要的视觉里程计,给予时间几何约束的序列框架。在 PoseConverGRU 中,GRU 是首选的,因为它们在性能方面非常接近于 LSTM,但是用更少的参数和更少的时间实现类似的结果。尽管如此,虽然取得了比 DeepVO 略好的结果,但改善并不显着,因此导致相同的结论。
DeepAVO 32是另一种基于光流的 DL 方法,其依赖于基于学习的光流提取器 PWC-Net 33。它每个图像象限提供四分支网络,以利用局部视觉线索。卷积块注意模块(CBAM)34机制被纳入到特征编码器之前的姿态估计。这种机制作为一个mask,提取相关的特征,集中在不同运动的像素,丢弃前景和模糊的目标。同样依靠 PWC-Net,Zhao等35预测光流,计算相机姿态的相对变换,并通过三角测量重建场景的一些三维结构。然后,这些结构被用来标定来自平行神经网络的深度预测,解决姿态和深度预测之间尺度不一致的问题。这是一个阻碍学习过程和结果的问题,因此笔者将姿势分支和深度分支的训练过程进行了划分,利用两者的输出相互补充,形成一致性。
ClusterVO36是一种动态感知的 VO 技术,它可以在检索相机轨迹和被检测目标轨迹的同时分割动态目标。运动估计部分基于关键帧和滑动窗口优化(部分类似于 ORB-SLAM2)。VLocNet 37提出了一种应用于视觉里程计的基于辅助学习的方法。除了一个 VO 专用网络,作者提出了另一个模块来估计车辆的全局姿态,在两个任务之间共享特征,因为这两个任务在性质上非常相似。这种做法促进了一个更一致的学习和较少的易感性过度拟合。该技术在 VLocNet++ 38中通过包含一个场景分割任务得到了进一步的扩展。
到目前为止,视觉方法景观已经被传统的基于特征的方法所主导,如 ORB-SLAM2和 SOFT-SLAM。最近,直接的公式化方法已经取得了有趣的成果,而作者也开始观察到一种趋势,即整合基于学习的子模块,以补充更传统的架构,如 DVSO 和 D3VO。与此同时,许多端到端的自运动估计方法已经出现,尽管结果令人失望,但在道路交通环境复杂性的抽象方面仍然有很大的潜力。
基于点云的里程计
点云帧通常以点云的形式表示,点云由一组直接以世界坐标给出的3D点组成,而VO则是以像素/图像坐标给出点。激光雷达传感器的工作原理是测量发射和反射的激光线的飞行时间或相移。要创建环境的3D点云,需要多次执行此操作以覆盖整个扫描区域。基于点云的里程计方法的分类不像 VO 方法那样简单。将这些工作分类的最简单的方法是将它们分为以下几类: 基于知识的,使用标准和传统算法的,以及基于学习的,使用机器和深度学习技术的。
Jonnavithula 等39帮助定义激光里程计算法的基本步骤: (1)预处理,(2)特征提取,(3)对应搜索,(4)转换估计和(5)后处理(如下图所示)。


基于知识的技术
ICP 41在90年代有了第一个版本,可以被认为是基于 LiDAR 的里程计领域最有影响力的算法之一。在其最基本的版本中,该方法通过两个步骤找到两个点云之间的转换: 数据关联和转换估计。数据关联步骤旨在找到两个点云之间的对应点,这可以使用最近邻方法来完成。第二步通过计算每个点云的质心并对齐,然后利用单值分解(SVD)计算点云的旋转,最小化点对之间的距离。该算法进行多次迭代,直到找到一个局部最小值。ICP 的基本概念被用于各种最先进的方法,例如 CT-ICP 42 ,这是 KITTI 自动驾驶基准上表现最好的里程计系统之一。ICP 算法考虑了传感器运动引起的点云畸变,使得 ICP 算法能够实时工作,就像在自动驾驶场景中发生的那样。这个公式使这种方法对传感器的高频运动具有鲁棒性,这是该方法的主要强项。该算法估计每个激光雷达扫描的初始和最终位置,同时通过插值执行弹性扫描匹配。与类似的方法不同,最终姿态不一定对应于下一次滑动的初始姿态,提供弹性和鲁棒性,以应对传感器运动中更突然的变化。同时,该方法提供了一个完整的建图模块和一个新的闭环过程。通过剪切特定阈值之间的 z 坐标,地图的点被插入到二维高程网格中,只有当传感器在 z 轴上的运动相对稳定时,这种方法才有效。当构建一个新的网格时,使用旋转不变的2D 特征将其与旧网格进行匹配。当一个匹配被验证,ICP 被用来细化二维变换获得一个6自由度的闭环约束。
最近的另一种依赖于 ICP 基础的方法是 MULLS (多度量线性最小二乘)43 ,它提供了一个高效、低漂移的3D SLAM 系统。这种架构是专门设计的独立于激光雷达的规格,不需要转换的激光雷达数据环或Range图像。首先对几何特征点进行提取和编码,区分地面、立面、柱子等几类特征点。下一步涉及多度量线性最小二乘 ICP 的自运动估计,基于选定的特征,这是修改,以提高准确性和效率。这种变化有四个基本步骤。首先,在每个特征类别中确定点对应关系。然后,在考虑点强度等因素的情况下,计算每个对应关系的权重。然后,根据点对应关系和计算出的权值,计算出变换估计。最后,作者使用统计指标来评价注册过程的质量。下图描述了在 LiDAR 收集的点云上执行的 MULLS 注册过程的一个例子。

另一项在这个领域具有高度相关性的工作是 LOAM 44。该方法同时解决了不同频率下的里程计和周边建图问题。里程函数以较高的节奏运作,并产生较低的保真度估计。同时,建图模块在生成和细化全局地图的同时,速度较慢并调整里程估计值。对于里程计,在初始阶段提取点云特征,将点云特征选取并分组为尖锐边缘和平面表面斑块。沿着激光雷达扫描,假设传感器的恒定角速度和线速度,捕获的点逐渐投影到前一帧。当特征被提取和匹配时,ICP 的一个变体会产生新的估计。当扫描完成后,建图模块细化对齐,完成建图并产生更高精度的姿态估计,再次传递回里程计模块。
其他的工作,比如 LeGOLOAM 45和 ELO 46 ,使用了 LOAM 的变体,这些变体专门设计为在保持或改进原始性能的同时具有较低的运行时间。LeGOLOAM 是轻量级和地面优化 LOAM 的缩写,其开发目的是为了在计算能力较低且没有悬挂的车辆上实现(这会加剧点云失真)。基本的工作原理依赖于分割点云,去除小的集群和保留点,可能代表大的目标,如树干和道路表面,并保存在一个range图像中。然后从这些range图像中提取特征,分为地面特征和非地面特征。关于里程计算法本身,由于地面优化过程,跨帧特征匹配变得更快。正如预期的那样,这种方法提高了 LOAM 的效率,使用的特性减少了72% 。ELO46是最近由zheng等人提出的。对于 LOAM 这样的方法来说,以基于树的形式对点云进行编码是很常见的,这种方法虽然在搜索方面很有效,但在大规模的点云中会受到一定的限制。为了最大限度地提高效率,该方法提出将激光雷达测量结果投影到球面图像上,直接恢复点之间的邻域。问题在于,在自动驾驶汽车中,激光雷达传感器捕获了大量的地面点,而这些地面点在球面几何学的投影中变得过于遥远。作为一种利用这些点的方式,地面点投影在一个自上而下的鸟瞰角度。通过对地面点和非地面点的合理分割,以及适当的二维投影,使得帧匹配搜索方法的应用更加有效。关于运行时间,作者认为 ELO 在一台普通笔记本电脑上可以达到169帧率。事实上,这项工作记录的运行时间比 KITTI 里程计基准中十个最高位置的平均值低21倍。尽管在提高效率方面做出了努力,但 ELO 的性能与MULLS 等其他方法相当。
其他一些工作也应该提到。例如,F-LOAM 47试图通过将 LOAM 的迭代过程转化为两阶段失真补偿方法来减少计算负担。该算法还利用了局部光滑度较高的边缘特征和平面光滑度较低的特征,有利于匹配。通过这样的努力,该方法在低功耗嵌入式计算单元上实现了20Hz 的周期频率。ISC-LOAM 48类似于 F-LOAM,但是使用点云的强度值和它们的几何形状来进一步提高循环闭合的能力。R-LOAM 49通过将 LOAM 框架与关于引用目标的先前知识相结合,以不同的方式对这种改进进行了处理。它需要事先了解障碍物的三维模型及其在全局坐标系上的位置。然而,这种表述使 R-LOAM 不适合于自动驾驶环境。
基于学习的技术
一种不同类型的方法涉及使用深度学习技术来解决里程计问题。由于来自range传感器的数据是无序和稀疏的,这是具有挑战性的应用典型的卷积为基础的 DL 模块。因此,一些使用 DL 技术的方法将3D 点云转换成其他格式,如range图像。LO-Net 50是一种使用这种方法检索传感器里程估计的算法。LO-net 首先从点云格式传递到矩阵,将点投影到圆柱坐标系中。然后,对于每个点,计算其各自的法向量。将包含当前时刻法向量和前一次激光雷达扫描法向量的矩阵传递给Siamese神经网络(SNN) ,后者将输出合并并提供给卷积网络,用于估计自运动参数。整个网络都是以监督的方式进行训练的。此外,该算法还包含场景中动态目标的掩模估计模块和建图块,通过扫描-建图匹配进一步细化估计。DeepLO 51是另一种方法,它首先将入射的点云投影到二维空间中。投影表示被一对包含点云顶点和法线的2D图所替代,而且没有精度损失。从当前时刻和前一时刻的顶点建图被传递到一个完全卷积网络,从中提取各自对的特征向量。这同样适用于法线的图,它们被并行地提供给另一个类似的网络。然后将两个合成的特征向量相加并传递给第三个神经网络,该神经网络预测运动参数。这个网络可以训练,在监督的方式,辅助序列真值,或在无监督的方式,通过一个误差函数,其中包括一个版本的 ICP。LodoNet 52也值得一提,因为它使用 SIFT 将3D 数据转换成二维表示和每种形式的特征提取,从而在连续扫描之间获得关键点对。然后,这些通信被输入一个卷积神经网络pipline,提取匹配的关键点对(MKPs)。MkPs 可以精确地返回到3D空间,并输入一个为激光雷达里程计设计的卷积神经网络。另一项利用神经网络的工作是 PWCLO-net 53。该算法以端到端的方式从原始的3D 点云中学习 LiDAR 里程计,不需要将点云投影到2D 表示中。网络的输入是两个点云,由一个孪生特征金字塔编码,提取每个点云的层次特征。然后,利用一个注意力cost体积来关联两个点云,生成包含点相关信息的点嵌入特征。利用嵌入掩模从这些特征中获取姿态变换,同时去除动态元素。
其他最近使用深度学习的相关工作是 PSF-LO 54 ,它使用参数化的语义特征来促进注册任务,并使用动态和静态目标分类器; 以及 CAE-LO 55 ,与以前的方法一样,使用无监督的深度学习并使用紧凑的2D 球形环投影。DMLO 56也是一项有趣的工作,通过将姿态估计分解为两部分来使特征匹配适用于 LiDAR 里程计: 使两个扫描之间的匹配网络和刚性变换估计运算变换估计运算。SuMa++ 57扩展了 Behley 等人以前的工作58 ,并对自定位问题有不同的方法。通过分析语义surfel-based的地图变化来估计机器人的位置,同时检测和去除动态目标,提高姿态估计的精度。每个扫描的激光雷达帧被转换成一个二维投影。然后,通过点云分割网络RangeNet++ 59对每个帧进行分割,因为每个点都属于一个语义标签。在此步骤之后,图像被转换回一个更新世界地图的3D 投影。本节提供了基于点云的里程计的一般概念的概述。文章还分析了这一领域的几个工作,以及它们的独特性,从知识到基于学习的方法,这些方法正在变得越来越流行,就像视觉里程计一样。
多模态里程计
自动驾驶汽车行驶的道路环境是非常复杂的。自动驾驶车可以通过结合不同的传感器(如相机、激光雷达和IMU) ,接近人类的感知能力,从多模态感知中受益。随着这些传感器开始被汽车制造商广泛采用,这种方法正变得越来越重要。
数据融合策略
数据融合依赖于从不同的传感器收集数据将允许从周围捕获更丰富和冗余的信息,这反过来又能够降低状态估计的不确定性。这种方法还有助于减少个别传感模式的失败成本,从而提高系统的鲁棒性。例如,视觉里程计可能会受到光照变化、照明条件差和无纹理环境的影响; 激光雷达难以应对高速公路或长隧道等宽阔的开放空间,以及恶劣的天气条件; 如果不定期调整,IMU 的轨迹估计往往漂移得非常快。因此,拥有不止一种模式应该可以弥补最终的短期或长期失败。在多模态方法中,可以根据合并在系统框架上下文中发生的瞬间对数据融合进行分类(如下图)。

在早期融合中,在任何预处理之前,通常通过将一个或多个传感器投影到另一个传感器的输入空间,在原始阶段合并数据。这种方法通常具有较低的计算成本,但高度依赖于传感器间的空间和时间标定60。后期融合意味着数据的后处理合并。这是最常见的策略,因为它需要更低的复杂性和更高的模块化。然而,它带来了更高的计算费用,并阻碍了每种数据类型的潜在有价值的中间特征的使用60。最重要的,在后期融合中的局限性仅仅依赖于姿态估计,它赋予融合层一个抽象级别,在某些情况下可能会受到限制。最后,中间融合是更加全面的技术,因为它可以以许多可能的方式部署,这取决于系统的体系结构,特别是如果是基于DL 的。由于数据经过一定的处理后进行融合,因此也称为特征级融合。在里程计的上下文中,可以对数据如何被用来生成系统的输出进行分类。例如,激光雷达测量可以补充图像,同时估计自运动与视觉里程计或反之亦然,或两种类型的里程计可以分开操作,融合在更高的系统框架抽象层61。遵循第一种方法的系统通常表示为紧耦合,而其他系统称为松耦合62。在这种情况下,图像和点云通常是里程测量法估计的主要来源,而 IMU 和全球定位系统提供便利的先验和/或轨迹漂移校正。
目前的数码相机技术,相比其他传感器,使相机具有非常有竞争力的价格和更小的尺寸和重量。相机通过提取颜色和纹理信息来记录周围场景的高分辨率图像,这对于检测轮廓和物体特别有效,而且,对于 VO 来说,可以识别在连续帧中容易跟踪的感兴趣点。然而,相机是非常依赖于环境条件和照明,面临着一些问题,规模恢复。反过来,激光雷达传感器可以检索自然深度信息,并通常提供更宽的空间覆盖。channel的数量通常在16到128之间,刷新频率可能在5到20Hz 之间变化。然而,雨、雾和雪会对激光雷达的性能造成高达25%的负面影响63,因此考虑这些现象非常重要。一些研究,如在60,64,证明了激光束的波长影响天气条件的不利影响。
在合并来自不同传感器的数据时,标定也是一个关键的方面,特别是在紧耦合系统中。每个传感器具有内部和外部标定参数,捕捉传感器的内部几何特性,并将世界帧与设备帧相关联。此外,传感器必须联合标定,以便由不同传感器检测到的完全相同特征的多个检测结果转换到系统公共帧中完全相同的位置(理想情况下)。最常见的技术使用具有众所周知尺寸的物理目标。这些结构必须具有易于检测的特征,并根据每种传感器模式进行分割。每个传感器分割的特征构成了一组物理约束,允许通过参数优化估计它们之间的旋转和平移。例如,在65中,作者仅使用一个简单的任意平面多边形进行相机-LiDAR 标定,而在66中,作者提出了一个具有四个锥形孔和金属反射镜的矩形块,以允许相机,LiDAR 和雷达的外部标定。67作者编制了一套公开可用的传感器外部标定工具包,同时也提出了一些实际的考虑,有时在标定传感器。在68-71中可以找到一些额外的技术,主要用于相机-激光雷达融合,以及用于多相机和相机-IMU 融合的 kalibr 工具包,其使用来自72-76的技术。
Multi-scale detection

其中第一个运动估计是由启发于 DSO 的基于直接贴片的方法产生的24。通过应用滑动窗口优化技术,保证局部一致性和实时性,进一步提高了估计精度。如果最新的帧是关键帧候选,则从相应的 LiDAR 扫描中提取特征并加入到全局图中,然后允许在从扫描到建图的过程中再进行一个细化步骤。这个步骤允许使用整个激光雷达的覆盖角度,而不仅仅是相应的拍摄角度。后端模块负责地图维护,包括闭环和姿态图优化器,以减少长途旅行中的累积漂移。此外,DV-LOAM 提出了一个有见地的消融研究。结论表明,这项工作所采用的直接和基于补丁的可视化 LiDAR 里程测量方法比单纯的 LiDAR 里程测量方法具有更高的精度,因为它依赖于图像来检测点云中不易区分的边缘。此外,它还受益于直接深度测量增强图像,这使得该方法即使在图像模糊时也能工作。
从 LOAM 的同一作者,V-LOAM 77旨在减轻 LOAM 对平滑运动的依赖。相机集成到 V-LOAM 允许视觉里程测量作为激光雷达里程测量之前的估计和处理快速运动。类似于 LOAM 的架构,V-LOAM 也使用双频模型。视觉块计算姿态转换的速度更快,使用一种特征匹配方法,它依赖于图像点,其深度或者直接由激光雷达测量,或者通过三角测量获得。同时,当每个激光雷达扫描完成时,假设线性运动不变,新的点云不会失真。这些点被记录在一个由激光里程块维护的局部地图中,如 LOAM 中。注册允许生成自运动估计,纠正影响视觉估计的漂移。此外,LiDAR-camera 组合还支持短期光照爆发期间的操作。
与 V-LOAM 不同,由 J.Graeter 等78提出的 LIMO 利用激光雷达测量以紧耦合的方式补充摄像机图像的深度信息。从图像帧中选取突出点,丢弃位于汽车和行人上的突出点,以避免动态物体的影响。这是通过深度学习语义分割来完成的。将激光雷达点云投影到图像上,通过平面拟合插值计算每个特征点的邻域深度。融合阶段还包括前景和地面分割。通过匹配特征,姿态变换估计由应用光束法平差的改进后端块生成和调整。在这一块中,特别强调仔细选择关键帧和地标,以及使用修剪后的最小二乘法加强模块,以减少异常值的存在。
一种进一步的方法是来自C.Chow等人的紧耦合可视激光雷达 SLAM (TVL-SLAM)79 ,其中视觉和 LiDAR 模块独立运行,直到来自两者的数据合并时流水线中的某个点,从而构成中间融合情况。关于里程测量领域,视觉前端在视觉残差旁边生成初步的姿态估计。这一估计有助于激光前端残差的计算。融合发生在一个大规模的最佳化问题中,其输入是两个模块的残差。在最后一步中,模块之间的内部和内部一致性由一组约束来确保,这些约束包括视觉标志重投影误差、扫描到地图配准和交叉约束,因为两个前端代表相同的环境。此外,该算法还具有传感器之间的外部标定技术和拒绝运动目标的多步技术。KAIST 数据集80的测试由拥挤道路环境中的具有挑战性的场景组成,由于其多模态特征(仅 TVL-SLAM LiDAR 和 ORB-SLAM2的准确性分别提高了88% 和78%),证明了 TVL-SLAM 的优越性能。
Wisth 等62最近提出了一种紧耦合的 LiDAR-Visual-IMU 里程测量结构。状态估计被表述为一个具有多传感器因素的大规模姿态图最佳化问题。视觉地标的深度是通过 LiDAR 点的投影计算的,如78 ,或通过立体匹配; 点云不失真到最接近的图像时间戳,以确保时间同步,使用 IMU 的运动先验; 平面/线特征提取类似于44 ,这减少了90% 的点为了效率的目的。实验表明对宽阔空间、黑暗隧道、密集的树叶和突然的运动具有相当强的鲁棒性。此外,姿态图公式允许不同的模式独立地影响系统,强调性能一致性的情况下,其中一个传感器的故障。
Ramezani 等人的工作组成了一个不同类型的方法,其主要焦点是通过惯性导航系统(INS)估计药剂里程。通过使用多状态约束卡尔曼滤波器来传播智能体的运动状态。同时,在设置中集成了立体装置,允许通过二维和三维特征匹配方法给车辆运动增加额外的约束,限制了 IMU 估计的漂移。本节提供了几个例子,说明如何组合来自不同传感器的数据,以获得更准确的结果和更健壮的体系结构。通过与单一模式方法的直接比较,上述许多技术显示了汇总不同模式和处理数据冗余的重要性。下表汇总所有参考的里程计技术以及各自的分类、类型和相关关键点。



视觉里程计基准到目前为止,在里程计领域的一些最相关和创新的工作已经被简要地描述和评论,包括视觉,基于点云,多模态方法。因此,本节将包含对一些暴露问题的一个关键的分析技术,支持的结果由作者获得的 KITTI 里程数据集。KITTI 数据集22包括总共22个视觉序列,记录在一辆车上的激光雷达和 GPS/IMU 数据,在常见的道路交通环境中采集,其中11个包括各自的真值。此外,KITTI 还提供了一个比较多种算法的评估工具,并在计分板上对它们进行排名。结果根据三个指标进行评估: i) trel,序列长度为100米至800米的平均相对平移误差(百分比) ; ii) rrel,在轨迹上的 deg/100米的旋转误差; iii)以毫秒为单位的运行时间。表2和表3中的数据对应于 KITTI 里程计基准训练和评估序列中最佳技术的评估。


通过以下分析表,值得注意的是,不管它们的模式或技术性如何,顶部位置之间几乎没有隔离。
事实上,上表中的前三个位置获得了低于0.5% 的树状图,并且每种方法对应于不同的传感模式,即多传感器,视觉和仅激光雷达。其余的地方都大致包括在0.70% 到0.90% 的范围内,除了最后两个,它们是 DL 端到端架构。类似地,在上表中,前五个位置构成了一个非常小的错误范围,大约为0.06%,同样来自每个模态的代表。
还可以观察到,与基于学习的技术相比,传统技术占主导地位。事实上,在过去的几年中,只有在轨迹精度方面有了很小的改进。最终,重点将有所改变,以进一步强化里程计系统,并使其计算效率更高。与运行时或算法分配的数据不同,量化和度量鲁棒性并非易事。对这些技术进行测试的最常见方法是在包含有挑战性场景的数据集中对它们进行评估。虽然 KITTI 被广泛使用,因此适合进行比较,但其他一些数据集,如 KAIST 80包括更具挑战性的序列。在这方面,多模态系统取得了更好的结果,如 KAIST 的c.Chou 等79和d.wish 等62的实验所显示的,这些实验针对针对特定传感器模式的不利条件评估了他们各自的工作,都经受住了测试,并且没有显示出整体退化的迹象,不像视觉或仅激光雷达方法。在效率方面,ELO 脱颖而出无与伦比,同时在准确性方面也表现得非常有竞争力。另一方面,像 TVL-SLAM 这样的复杂方法需要增加计算量,因为它们需要依靠并行运行的多个模块来实现这样的精度和鲁棒性,其中一些可能是需要的,例如优化和建图模块。这种架构的一个可能的解决方案是增强单个功能块,例如将 ELO 或类似的方法集成到激光里程计前端。
开源方法的基准
为了扩展以前的方法82 ,对里程计进行结构良好和无偏倚的评估。一些开放源码的方法被选择。这些技术是针对从 KITTI-360数据集3中提取的一组具有挑战性的序列进行测试的,这些序列从安静的住宅街道上的常规驾驶到繁忙的高速公路都有所不同。
KITTI-360是著名的 KITTI 22自动驾驶数据集的继承者。它通过增加传感器,如一对鱼眼摄像头和一个额外的激光扫描仪,以及更长和更复杂的驱动器,改进了以前的迭代。通过这种方法,提取了11个序列,并在下表中进行了简要描述。

每个序列 ID 的前两位数字对应于 KITTI-360数据集中的驱动器。这些序列构成了各种各样的环境,特别是挑战里程计算法和评估相应的限制。一些挑战包括高亮度变化,存在许多动态目标,传感器堵塞,和广泛开放的空间,等等。
所选择的评估场景被用来测试一些视觉里程计方法在不同的情况下同化在不同条件下的最先进的表现,同时讨论每种模式的局限性。选择了一些最流行和性能最好的算法:
🔹 可视里程计: ORB-SLAM212 ,LIBVISO214和 SOFT116和 SOFT-SLAM217的开源实现。深度学习方法 SC-SfMLearner 83和zhao等35的工作也进行了测试。
🔹 基于点云的里程计: MULLS43,CT-ICP42,F-LOAM47和ISC-LOAM48。
**🔹 多模态里程计:**Ramezani等人的工作81 ,将多目装置与IMU融合。这些方法之所以被选中,是因为它们是开放源码的,并且有良好的文档说明,允许任何人实现它们。有些像 ORB-SLAM2,被认为是 VO 领域的里程碑,而其他像 CT-ICP 则是表现最好的在 KITTI 里程计基准上。
本集提供了一个良好的理解和所有视觉里程计类别的代表性,包括知识和学习为基础的工作。
挑战分析



评估方法的性能将在下面的段落中讨论,特别是关于一些特殊的挑战。
植物和开阔的道路在03_02的顺序中,车辆行驶在一条短直路上,整个路边都有茂密的植物环绕,如下图所示。

植被对于相机和激光雷达技术来说是一个特殊的挑战。由于重复和噪声的模式使得视觉方法的特征匹配/跟踪变得困难。密集的叶片由于表面的不规则性和多个小遮挡影响了激光束的有缺陷反射,阻碍了点云的精确排列。即使一般来说视觉结果更好,但是基于激光雷达的方法比纯视觉的方法表现更好,平均误差低55%。原因可能是,视觉技术依赖于路上的视觉线索,激光雷达检测不到。除此之外,相机的垂直视野比激光雷达的视野略宽,这得益于更加鲜明的特征,因为顶部的植被没有那么密集。序列07_01包含相对较宽的开放道路(图10b),这对激光雷达技术构成了挑战,因为开放空间由于缺乏特征使得点云的排列变得困难。在这个序列中,性能最好的视觉方法(ORB-SLAM2)比性能最好的基于LiDAR的CT-ICP技术的平移误差降低了20.3% 。同样值得注意的是 IMU 的免疫力,因为它是本体感觉传感器,对场景中的外部因素具有免疫力,因为 Ramezani 等人(与 IMU 一起)在03_02中排名第二,在07_01中排名第一。回转机动和隧道序列06_01具有回转机动,其中基于点云的方法的360度空间覆盖有助于更精确的旋转估计。在图中,可以看到视觉方法出现的最明显的偏差。序列10_02具有一个黑暗的隧道通道,其中视觉方法仅仅依赖于从缩小的窗口中提取的远距离特征,如下图所示。

这个通道影响基于相机的里程计技术,这可以在图9c 中观察到,因为所有的视觉方法在最后的左转时开始漂移,因为在弯道前发生的隧道穿越期间错误的前向自运动感知。因此,视觉技术获得的平移误差几乎比基于点云的替代方案在序列10 _ 02中评估的误差大六倍。
动态目标序列05_01具有少量大尺度视觉遮挡(如下图)。

这种场景对于纯粹的视觉技术来说尤其具有挑战性,因为这些目标所占据的视野范围相当大,难以提取出高质量的特征,甚至由于光圈问题而阻碍了对运动目标的检测。下图展示了当一辆大型卡车在车辆人前面横穿而它是固定的时候,偏差对视觉方法的影响。

从下表中可以看出,基于激光雷达的方法在05_01中表现得更加准确,平移误差小了10倍,这要么是因为360度的场景覆盖,要么是因为算法中包含了特定的动态目标抑制方法。

序列07_02包含几个启动和停止时刻,其中有多个车辆的速度与车辆相似,如下图所示。

类似于序列05_01,多个动态目标扰乱视觉算法,当无数汽车开始移动时,车辆仍然保持静止,造成自运动的错误感觉。ORB-SLAM2(图15)是这种效应的一个明显例子,因为平移错误公式和公式分别是图12的8.7倍和7.0倍。高于这项技术的平均水平。

此外,几乎所有其他视觉方法的性能都低于平均水平。LiDAR 方法对这些现象的鲁棒性增强,如表5所示。再次,关于场景中的运动目标,IMU 的集成可以增加一个置信度量来估计姿态,在这些情况下,会有来自两个传感器的分歧信息。观察 Ramezani 等人在07_02序列中的两个版本(有和没有IMU) ,作者可以看到IMU的参考影响,因为平均平移漂移从6.58米下降到1.61米。
一般性能比较
基准测试的结果加强了基于激光雷达方法的普遍性。从上表5中可以看出,当没有明显的退化迹象时,激光雷达技术的轨迹误差始终低于其他方法,如07_01和07_02。这表明,这些估计不仅准确,而且精确。请注意,评估的误差是通过积分轨迹计算的; 因此,少量具有显著偏差的估计值或多个具有较小偏差的估计值,将导致轨迹误差在整个序列中逐渐传播,或者不传播。实际上,值得注意的是 CT-ICP 和 F-LOAM/ISC-LOAM 在大多数序列中占主导地位,最后两个是相同方法的近似版本。除了基于学习的技术外,纯视觉技术的平均平移误差为9.5米,而基于点云技术的平均平移误差为5.4米。在点云里程计中,周围的3D 结构是直接绘制的,而 VO 中的输入是场景的2D投影,受到像素离散化的影响,因此精度有所下降。此外,虽然视觉技术的感知只限于一小部分涉及的空间,普通的激光雷达有一个360度的水平覆盖。这符合基于激光雷达技术的目的,因为运动估计受益于空间中的离散点,同时对离群点更有弹性。这些直接的比较有助于解释为什么点云方法通常更加精确和健壮。此外,与原始 KITTI 数据集不同的是,点云并非没有扭曲,所以像 MULLS 这样的算法比通常的算法性能更差。
关于长序列,如00_01和07_01(图9b 和9i) ,无论该方法的传感模式如何,沿着轨迹的漂移的积累通常会发生,因为里程计是一个综合过程。出于这个原因,总是值得依赖于偶尔校正轨迹的技术,如 SLAM 算法中的建图和环闭合,或精确 GPS 测量的集成。或者,结合多个传感器,如 Ramezani 等81 ,在自定位中提供冗余,这可以避免与只有一个传感参考相比的漂移趋势。结合外感知(相机,激光雷达,雷达等)和本体感知传感器(IMU) ,在最后一个例子,是特别有用的方面的健壮性。这是因为影响这些传感器的错误性质非常明显,而且它们不太可能受到相同环境条件的影响。
此外,尽管 Ramezani 等81的工作仅在两个序列中超过了剩余的算法,但在所有序列的平均误差方面,超过了顶尖的 CT-ICP 约6% 的平均平移误差。这一结果表明,包含第二种数据模态(惯性)可以实现更稳定的性能,尽管在某些情况下表现不佳,但在所有测试中仍然表现一致,证明即使面对上述挑战,它也能保持在正轨上。
就像原始 KITTI 数据集上显示的结果一样,基于学习的方法呈现的结果仍然远远低于传统方法。尽管在KITTI-360上执行的测试在DL方法级别上没有显着的代表性,但获得的误差大小和各自的轨迹表明它们的性能仍无法与经典拓扑的视觉方法相媲美,即使与基线模型相比也是如此。从原始数据到姿态估计,视觉里程计pipline反映了一个复杂的问题,深度学习端到端方法还不能重现有竞争力的结果。
自运动的当前挑战和局限
值得注意的是,最近的工作日益复杂,随之而来的性能却没有以同样的速度增长。这种现象可能会指出,传统的基于知识的方法开始显示出成熟的迹象,并可能趋于发展瓶颈。这些技术发展的两个主要障碍与实际环境的高度复杂性和不可预测性密切相关。一方面,里程计系统需要尽可能强大的各种不利条件,如照明和天气,这是直接相关的物理感应周围环境。另一方面,算法应该具有最大可能的抽象性,以便在软件层面上,感知能够承受它可能遇到的各种场景,无论是宽阔的开放区域还是拥挤的区域,有许多动态的目标或植被。因此,这是物理和软件领域的联合泛化问题。从更具体的角度来看,与视觉和基于点云的里程计有关的最相关的障碍可以分为三类: 场景条件,计算成本和动态目标。
场景条件
基于视觉的系统对环境的视觉外观非常敏感。视觉里程计,更具体地说是基于特征的视觉输出,在环境缺乏可以在后续帧中跟踪的相关数量的高质量特征时,往往表现不佳。这可能发生在不同的场景条件下,在夜间环境能见度很低,或在恶劣的条件下,如大雨或雾。像沙漠或开阔地围绕道路的情况也往往影响这些方法,因为这种环境的无特征性质。光线的变化也会带来额外的困难,特别是在直接视觉里程计的情况下,因为高亮度的变化,比如黑暗隧道的入口,可能会产生显著的影响。发生这种情况是因为光照一致性假设,假设在这种方法中使用的连续帧具有恒定的亮度,在这些条件下不起作用。反过来,基于激光雷达的技术不受光照条件的影响。但激光雷达受天气和大气条件的影响很大。Carballo 等84测试了12种不同的激光雷达模型在恶劣的天气条件下,如大雾和降雨,证明了一些局限性。例如,在大雨中,激光束反射到雨滴上,在扫描中形成"雨柱",在点云中构成高噪音,如下图所示。

如前所述,激光束的波长可以影响传感器在不利条件下的性能64。基于激光的传感器也受到反射率的严重影响,无法检测到反射率低的目标,如玻璃。像 VO 一样,这些方法也倾向于在没有明显突出线索的环境中失败,例如被广阔开阔的田野包围的乡村道路。KITTI-360数据集的评估证实了这些局限性,其中基于激光雷达的方法显示出性能下降的迹象。另一方面,正如预期的那样,当面对照明变化时,基于激光雷达的方法没有报告任何性能问题。
计算成本
在计算能力和时间方面的计算成本限制也应该得到解决。在自动驾驶的情况下,这一点尤其重要,因为在自动驾驶的情况下,估计数应该以足够高的速度提供,以满足与自动驾驶车辆有关的严格的时间限制。许多作者使用高性能的硬件来开发他们的工作,但因为移动机器人通常配备低级别的硬件。该设备可能无法以实时操作所需的频率运行算法。在视频录像中,如果无人机有几个摄像头,计算时间是必不可少的,特别是采集的图像是高分辨率的,这会使处理的数据量难以管理。减少计算负担的一种方法是仔细选择特征,而不是使用整个原始图像。尽管如此,特征提取/匹配和异常去除任务也可能耗费大量时间。
在基于点云的技术中,同样的问题依然存在,增加的成本与点云的无序性有关,点云的预处理操作可能耗费大量时间。有效地排序和存储点云的一种方法是使用八叉树或 K-D 树,它们允许快速的多维搜索。
动态目标
动态目标检测在讨论视觉和激光测距时非常有趣,特别是在自动驾驶中,因为这种类型的目标非常普遍,即其他移动的汽车、行人和骑自行车的人。虽然有些作者考虑了动态目标,但大多数作者没有考虑。这意味着假设世界是静态的,这在估计车辆的自运动时有重要的含义。动态目标,当不计入时,会在轨迹估计中引入误差。如果认为运动目标是静态的,里程计算将基于错误的假设,姿态估计将不准确。同样值得注意的是,由于传感器安装在移动的车辆上,在自动驾驶领域,检测动态目标可能特别复杂。因此,检测到的运动有两个组成部分: 自运动(传感器的运动)和目标自身的运动,都与同一固定帧有关。区分这些运动类型的一种方法是使用额外的传感器(如IMU或GPS)来补充里程计算法,以推断自运动,然后通过减牵引来推断被检测目标的运动。对具有挑战性的场景进行的评估显示,当VO方法面临高度动态环境时,除了相机和 IMU 融合方法之外,其准确性显著下降81。在这种情况下,基于LiDAR的方法也更加稳健。这是因为 VO算法在没有正确的masking操作时,倾向于从运动目标中提取特征(运动目标通常具有显著的视觉特征)如下图17所示。

运动分析技术,例如光学和场景流,是推断场景中目标运动的典型方法85。利用光流算法推导出的流场可以实现运动目标的分割方法。此外,随着使用 Flownet 88和 RAFT 89等深度学习方法在光流估计方面的最新进展,可以准确和及时地计算稠密流估计。上面章节中的一些公开的方法,比如 ClusterVo,SuMa + + 和 TVL-SLAM,已经考虑到了这个问题,因为他们使用了不同的技术,比如语义分割或者重投影策略来过滤掉不需要的目标。虽然与里程计任务没有直接关系,但几位作者提出了在自动驾驶环境下检测和分割动态目标的方法。其中一个例子是 Chen 等人90的工作,他们从 LiDAR 扫描中创建残留图像,并将它们提供给常规的点云分割网络,以识别运动目标。Pfreundschuh 等91提出了一种用离线算法识别动态目标的方法,然后使用标注数据训练一个能够实时检测移动障碍物的神经网络。FuseMODNet 92是一个多模态方法的例子,它使用相机和激光雷达来探测在弱光情况下移动的障碍物。
研究机会
多模态架构可以在一个传感器补偿另一个传感器失效的情况下提供更强的鲁棒性。然而,多模态方法的进一步发展仍然是必要的和合理的,因为从本车的角度对环境的表征与各自的结果之间存在着强烈的相关性,这种相关性往往更好,表征越完整。此外,多样化和完整的收集数据集总是提供更好的洞察力和可靠性。由于这些原因,视觉里程计算法的部分局限性,特别是关于环境感应,可以通过开发集成多个传感器的系统来减轻,从而产生更准确和可行的估计。然而,复杂场景和概括问题并没有明显的解决办法。在实践中,关于现有的实际传感选项,手工制定可靠的现实世界模型仍然非常具有挑战性,即里程计问题受到许多因素的影响,这些因素非常难以检测,特别是难以推广。考虑到可能遇到的各种各样的情况,从有几十个动态目标的城市景观,到可能只有很少landmarks可以追踪的漫长的沙漠道路,除了传感器和相关噪音的局限性。因此,一个可行的选择是设计深度学习的能力来捕捉数据中更复杂的潜在特征,而传统的方法迄今为止发现这很困难。然而,基于学习的技术仍然远远不能满足需要,至少在自动驾驶的情况下是这样。此外,数据的可用性仍然不够大,现有的数据逻辑结构,如近年来主导计算机视觉的 CNN,在学习顺序数据关系方面效果不佳。反过来,RNN也能够解决这个问题,但是在捕捉图像特征方面却不如CNN擅长的那样。因此,经常发现 CNN 之后是 RNN,因为通常的解决方案倾向于适应现有的结构,而不是从头开始设计和裁剪它们。沿着这条路线,由于深度学习的使用是高度灵活的,25确定需要将新的技术和架构引入视觉/激光里程计作为未来的工作机会。此外,最近的工作,如 D3VO 开始接近传统的方法,不是通过端到端架构,其中的学习过程可能太复杂,但通过学习为基础的子模块,旨在补充系统链,如深度预测模块,例如。另一个似乎无人关注的提议是将深度学习算法集成到多模态体系结构中,以努力利用两者的上述优势。虽然新的方法正在出现,但是基于学习的里程计的全景仍然处于非常不成熟的状态,因此需要进展到更先进和更适合在现实世界中使用的状态,因为它已经在其他领域中使用。
结论
本文介绍了基于视觉和点云的里程计的一些基本要素,并对目前的最新技术进行了广泛的综述。根据 KITTI 数据集获得的结果,讨论了最佳性能技术。此外,在 KITTI-360数据集的一系列具有挑战性的场景中,评估了一组具有代表性的公开可用的方法,包括视觉、点云、多模态和基于学习的方法。结果表明,基于点云的方法在轨迹平移漂移方mask有优势,比视觉方法提高了33.14% 。场景,天气,照明条件,动态障碍和计算成本的高度复杂性和可变性被指数作为里程计算法进展的最大限制因素,因为作者确定了当前传统方法的发展瓶颈。作为解决方案的一部分,本文强调了多模态方法日益增长的稳健性,以及研究和开发更好的基于深度学习的解决方案的必要性,以利用这些方法的数据驱动建模能力,因为目前的方法仍然不具有竞争力。因此,加入深度学习算法和传感器融合也可能是一个有希望的突破性研究,因为它仍然略有待探索。
#NeuroNCAP
本文提出了一种用于测试自动驾驶(AD)软件系统的多功能基于NeRF的仿真器,其设计重点是传感器真实闭环评估和安全关键场景的创建。仿真器从真实世界的驾驶传感器数据序列中学习,并能够重新配置和渲染新颖的场景。在这项工作中,使用本文提出的仿真器来测试AD模型对安全关键场景的响应。评估表明,尽管最先进的端到端规划器在开环环境中的标称驾驶场景中表现出色,但在闭环环境中导航关键场景时,他们表现出了不可忽略的缺陷。这突出了端到端规划器在安全性和现实可用性方面的进步需求。通过将我们的仿真器和场景作为一个易于运行的评估套件公开发布,并邀请社区在受控但高度可配置且具有挑战性的传感器现实环境中探索、完善和验证他们的端到端模型。
开源链接:https://github.com/atonderski/neuro-ncap
总结来说,本文的主要贡献如下:
- 发布了一个开源框架,用于自动驾驶的真实感闭环仿真。
- 受行业标准EuroNCAP的启发,构建了无法在现实世界中安全收集的安全关键场景。
- 使用仿真器和我们构建的场景,设计了一个新的评估协议,该协议侧重于碰撞而不是位移度量。
- 本文发现尽管准确地感知了环境,但两个SoTA端到端规划器在安全关键场景中严重失败,这值得社区进一步探索。
相关工作回顾
端到端驾驶模型:传统上,自动驾驶任务被划分为不同的模块,例如感知、预测和规划,这些模块是单独构建的。胡等人认为,这种划分有很多缺点:跨模块的信息丢失、错误积累和特征错位。姜等人强调,规划模块可能需要访问手工制作的界面中不存在的传感器数据的语义信息。这两项工作继续支持端到端规划。Pomerlau等人的开创性工作提出了这样一种规划器,其中训练单个神经网络将传感器输入映射到输出轨迹。几十年的神经网络进步激发了人们对端到端规划的新兴趣。然而,这些规划者的黑匣子性质使他们难以优化,其结果也难以解释。胡等人和姜等人提出了两种具有中间输出的端到端神经网络规划器,对应于模块化方法。他们的规划者被划分为多个模块,但模块接口是学习的,由深度特征向量组成。
端到端规划器的开环评估:Pomerleau等人通过让其驾驶真实世界的测试车辆来评估他们的驾驶模型。这样的设置使得大规模测试成本高昂,并且结果可能难以再现。最近在端到端规划方面的工作改为在开环中进行评估,在该开环中,模型根据记录的传感器数据预测计划。预测的计划从未被执行,相反,行动被固定在记录的内容上。这种设置也被用于目标级规划工作,该工作假设了完美的感知,并将静态环境的地图和动态对象的轨迹输入到模型中。这种开环评估构成了评估与现实部署之间的差距。此外,性能通常被测量为记录中预测的计划和车辆驾驶的轨迹之间的距离。虽然零的误差对应于人类水平的驾驶,但误差越低越好并不一定是真的。这可以通过考虑两个不同轨迹相同好的场景来实现。Codevilla等人对这些问题进行了研究,发现开环评估与实际驾驶质量不一定相关。Dauner等人得出了类似的结论。
闭环评估和仿真:考虑到上述开环评估问题,闭环仿真变得很有吸引力。已经提出了几种对象级仿真器。然而,这些仿真器不生成传感器数据,这使得无法在闭环中测试端到端规划器。已经提出了许多手工制作的图形仿真器。这种仿真器面临的挑战有两个:很难创建逼真的图像,也很难创建捕捉真实世界多样性的图形资产。对世界模型的研究表明,场景的未来------例如雅达利游戏------可以在潜在空间中预测,并且潜在空间中的向量可以解码为传感器输入。胡等利用大规模的真实世界汽车数据集建立了一个世界模型。Amini等人提出了VISTA,其中可以通过预测深度取消投影最近的图像并重新投影,在局部轨迹周围合成新的视图。杨等人提出使用神经辐射场(NeRF)来创建场景的真实感传感器输入。该方法随后由Tonderski等人进行了改进。具有更准确的传感器建模和更高的渲染质量,特别是对于此处考虑的360度设置。
新车评估计划:新车评估计划(NCAP)由美国交通部国家公路安全管理局于1979年推出,旨在为消费者提供有关汽车相对安全潜力的信息。NCAP对车辆进行了碰撞测试,并根据严重受伤的概率对车辆进行评分。1996年提出了一项类似的欧洲协议,即欧洲新车评估计划(Euro NCAP)。2009年,欧洲NCAP进行了全面改革,以纳入新兴防撞系统的测试。最初,这包括电子稳定控制和速度辅助系统,但后来扩展到包括其他系统,如自动紧急制动和自动紧急转向。在这项工作中,我们从欧洲NCAP自动防撞评估协议中获得了灵感。该协议提供了除非采取措施,否则将发生崩溃的场景。为了获得满分,车辆需要刹车或转向以避免事故发生。如果冲击速度充分降低,则会获得部分分数。
方法详解
闭环仿真
我们的闭环仿真重复执行四个步骤。首先,在给定ego车辆的状态和相机校准的情况下,渲染高质量的相机输入。渲染器是根据驾驶车辆的日志构建的。其次,在给定渲染的相机输入和自车状态的情况下,端到端规划器预测未来自车轨迹。第三,控制器将计划轨迹转换为一组控制输入。第四,在给定控制输入的情况下,车辆模型在时间上向前传播自我状态。此过程如图2所示。接下来,我们详细介绍四个步骤中的每一个。

神经渲染器:为了仿真新颖的传感器数据,我们采用了神经渲染器。NeRF从收集的真实世界数据的日志中学习3D环境的隐含表示。一旦经过训练,NeRF就可以从所述场景中渲染传感器逼真的新颖视图。最近的进步增加了通过更改场景中动态对象的相应三维边界框来编辑动态对象的能力。具体来说,参与者可以被移除、添加或设置为遵循新的轨迹,在我们的案例中,这使得能够创建安全关键场景。例如,为了仿真一种罕见但关键的安全场景,可以将原本在相邻车道上行驶的车辆定位为静止,并与自身车辆位于同一车道上。这种新颖的情况需要自车刹车或执行精确的超车动作。
有两件事需要注意。首先,最近提出的NeuRAD还支持激光雷达数据的渲染。然而,由于最先进的端到端规划者只消耗相机数据,我们在这项工作中只关注相机数据。其次,正如我们在实验中所示,与真实数据相比,现代NeRF引入的领域差距足够小,端到端计划者的感知部分仍能以高性能运行。然而,我们预计随着神经渲染的未来发展,这一差距将进一步缩小。
AD模型:最近关于端到端规划的工作描述了一个消耗(i)原始传感器数据的系统;(ii)自车状态;以及(iii)预测计划轨迹的高级计划。计划的轨迹包括在某个频率和某个时间范围的路点。需要注意的是,虽然我们的主要目标是分析最先进的端到端规划器,但该模块可以用任何类型的规划器取代,例如模块化检测器-跟踪器-规划器管道。
控制器:为了应用车辆模型,需要将路点转换为一系列控制信号,对应于一系列转向角(δ)和加速度(a)命令。继Caesar等人之后,我们用线性二次型调节器(LQR)实现了这一点。请注意,虽然我们只分析输出路点的规划器,但规划器可以直接输出一系列控制信号。
车辆模型:给定一组由计划轨迹产生的控制信号,车辆状态通过时间传播。为此,我们遵循先前的闭环仿真器,并采用离散版本的运动自行车模型。它可以正式地描述为:

评估
与常见的评估实践(即大规模数据集的平均性能)相反,我们将评估重点放在一小部分精心设计的安全关键场景上。这些场景经过精心设计,任何无法成功处理所有场景的模型都应被视为不安全。我们从行业标准的欧洲NCAP测试中获得了灵感(见第2节),并定义了三种类型的场景,每种场景的特征都是我们即将碰撞的参与者的行为:静止、正面和侧面。根据欧洲NCAP命名法,我们将此参与者称为目标参与者。其目的是控制自车以避免与目标行为者发生碰撞或至少降低碰撞速度。
对于每种场景类型,我们都会创建多个场景。每个场景都基于从真实世界中大约20秒的驾驶中收集的数据。自车和目标参与者状态被初始化,这样,如果保持当前速度和转向角,碰撞将在未来约4秒发生。所有非平稳演员都被从场景中移除,我们随机选择其中一个作为目标演员,考虑到演员是否已经被足够近的观察到,并且在必要的角度下,以产生逼真的渲染。由于我们的渲染器仅限于僵硬的参与者,因此我们将行人排除在该选择之外。最后,我们在特定场景的间隔内随机抖动目标演员的位置、旋转和速度。在评估过程中,我们将每个场景运行大量的运行(使用固定的随机种子),并计算平均结果。接下来,我们将描述每种类型场景的特征。

静止:这是一种相对简单的场景,其中一个静止的目标演员被放置在自车车道上。目标车辆可以任意旋转放置,但在整个场景中都将保持静止。这意味着自车可以进行剧烈的刹车或转向操作以避免碰撞。见图3a。
正面:正面场景包括一个目标演员,他正朝相反的方向行驶,并在与自车的碰撞路径上漂移到自我车道上。因此,ego车辆不能通过断裂来避免碰撞,只会降低碰撞速度。为了完全避免碰撞,自车必须执行转向操作。见图3b。
侧面:侧面碰撞场景的特点是目标演员从垂直方向穿过我们的车道。如果自车的当前速度保持不变,就会发生侧面碰撞。自车可以通过为迎面而来的目标行为者刹车,或者在超速经过目标行为者时进行轻微的转向操纵来避免碰撞。见图3c。
NeuroNCAP评分:对于每个场景,都会计算一个评分。只有完全避免碰撞才能获得满分。成功降低冲击速度可获得部分分数。本着五星级欧洲NCAP评级系统的精神,我们将NeuroNCAP评分(NNS)计算为:

实验
数据集:虽然有许多针对自动驾驶的数据集,但nuScenes在端到端规划方面得到了最广泛的适应。它以具有高度互动场景的城市环境为特色,适用于我们的安全关键场景生成。由于其广泛的适应性,它还允许我们使用我们评估的模型的官方实现和网络权重。NuScenes分为1000个序列,其中150个保留用于验证。从这150个序列中,我们选择了14个不同的序列------根据场景中特工的行为,这些序列被认为是合适的------作为我们安全关键场景的基础。
场景:每个场景都是手工设计的,考虑哪些参与者适合给定的序列、最合理的碰撞轨迹,以及定义不同类型随机化的允许范围。在评估过程中,我们将每个场景运行100次(使用固定的随机种子),并对结果进行平均。并不是所有的序列都可以用于所有类型的场景,例如,我们无法仿真一条直线路上的真实侧面碰撞。因此,我们为每种场景类型选择合适的序列。关于每个场景的更多细节和定性示例,我们参考补充材料。
神经渲染器:作为我们的渲染器,我们选择使用NeuRAD,这是一款专门为自动驾驶开发的SotA神经渲染器,经验证可与nuScenes很好地配合使用。由于我们希望最大限度地提高重建质量,我们使用更大的配置(NeuRAD-L),并使用默认的超参数训练100k步。由于nuScenes中的姿态信息仅限于鸟瞰平面,我们采用姿态优化来恢复丢失的信息。最后,我们采用了沿对称轴翻转演员的方式,以实现从所有视点对演员的逼真渲染。
AD模型:根据我们提出的评估协议,我们评估了目前的两种SotA端到端驱动模型,即UniAD和VAD。在这两种情况下,我们都使用了作者提供的预先训练的权重,这些权重在同一数据集上训练,而不会对所述模型的配置进行任何更改。这两种型号都消耗360°摄像头输入,以及can总线信号和高级命令:右、左或直,并在未来3秒内输出一系列未来路线点。虽然在我们的场景中,这比碰撞的初始时间(TTC)更短,但这不是一个问题,因为规避机动可以而且应该在最终航路点与当前参与者位置相交之前开始。此外,我们的场景设计得相当宽松,因此TTC<3s的计划仍然可以成功避免碰撞。
这两个模型之间的一个主要区别是,UniAD将防撞优化后处理步骤应用于它们的预测轨迹。使用具有基于预测占用率和未优化输出轨迹的成本函数的经典求解器来执行优化。当在开环中评估时,这种优化被证明可以显著降低碰撞率,我们现在可以在更有趣的闭环设置中研究它。为了实现更直接的可比分析,我们对VAD实现了相同的防撞优化。然而,由于VAD不能直接预测未来的占用,我们将其预测的未来对象光栅化,并将其用作未来的占用。请注意,这种方法可能高估了占用率,因为所有未来模式都被视为具有同等可能性。
为了进行比较,我们基于UniAD/VAD的感知输出实现了一种天真的基线方法。规划逻辑只是一个等速模型,除非我们在自车前方的走廊中观察到物体,在这种情况下,我们会执行制动操作。走廊被定义为横向±2米,纵向范围从0到2维戈米,即如果TTC<2s且前方有物体,我们会刹车。
实验结果
我们使用图4中每种场景类型的渲染前置摄像头图像,以及计划轨迹的重叠投影来增强定量分析。图4a描绘了一个成功的回避动作,同时也突出了我们呈现复杂实体(如摩托车手)的能力。然而,如果没有后期处理,规划者似乎容易忽视安全关键事件,如图4b所示。




限制
我们看到以下限制。首先,神经渲染器在场景和场景中受到限制,例如,没有雨,它能够准确渲染。此外,自车轨迹的大偏差和非常近的物体会导致视觉伪影(见图4)。其次,我们采用了一个简化的车辆模型,它不建模,例如延迟、摩擦或悬架。此外,我们不考虑路面方面,如颠簸、坑洞、砾石等。第三,我们对所有车型都采用了单一控制器,即使它们是紧密耦合的。我们的评估协议允许提交直接输出控制信号的AD模型。第四,神经渲染器无法处理可变形对象,例如行人。我们希望神经渲染的进一步进步将解除这一限制,并实现一套新的安全关键场景,重点关注弱势道路使用者。第五,目标行动者遵循预定的轨迹,而不动态地对自车做出反应。虽然这遵循了EuroNCAP的设置,但我们认为,未来有多个参与者的场景将需要反应行为。
结论
总之,我们的仿真环境提供了一种新的方法来评估自动驾驶模型的安全性,利用真实世界的传感器数据和受欧洲NCAP启发的安全协议。通过NeuroNCAP框架,包括静止、正面和侧面碰撞场景,我们暴露了当前SotA规划者的重大漏洞。这些发现不仅强调了在端到端规划者的安全性方面取得进展的迫切需要,而且为未来的研究提供了有希望的途径。通过向更广泛的研究界公开我们的评估套件,我们的目标是促进更安全的自动驾驶方面的进展。展望未来,我们预计将开发该套件以应对更广泛的场景,集成更精细的车辆模型,并采用先进的神经渲染技术,从而为安全评估设定新的基准。
#RoadBEV
原标题:RoadBEV: Road Surface Reconstruction in Bird's Eye View
论文链接:https://arxiv.org/pdf/2404.06605.pdf
代码链接:https://github.com/ztsrxh/RoadBEV
作者单位:清华大学 加州大学伯克利分校
论文思路:
道路表面状况,尤其是几何轮廓,极大地影响自动驾驶车辆的驾驶性能。基于视觉的在线道路重建有望提前捕获道路信息。现有的解决方案如单目深度估计和立体匹配的性能表现一般。最近的鸟瞰视角(BEV)感知技术为更可靠和精确的重建提供了巨大潜力。本文统一提出了两种简单而有效的BEV道路高程重建(road elevation reconstruction)模型,分别命名为RoadBEV-mono和RoadBEV-stereo,它们分别利用单目和立体图像估计道路高程。前者直接基于从图像视图中查询的体素特征拟合高程值,而后者有效地基于表示左右体素特征差异的BEV体积识别道路高程模式。深入的分析揭示了它们与透视视图的一致性和差异。在真实世界数据集上的实验验证了模型的有效性和优越性。RoadBEV-mono和RoadBEV-stereo的高程误差分别为1.83厘米和0.56厘米。基于单目图像的BEV估计性能提高了50%。本文的模型对实际应用充满希望,为基于视觉的BEV自动驾驶感知提供了宝贵的参考。
主要贡献:
本文首次从理论和实验两个方面展示了鸟瞰视角下道路表面重建的必要性和优越性。
对于单目和立体基础方案,本文分别提出了两个模型,分别命名为RoadBEV-mono和RoadBEV-stereo。本文详细解释了它们的机制。
本文全面测试和分析了所提出模型的性能,为未来的研究提供了宝贵的见解和展望。
网络设计:
近年来,无人地面车辆(UGVs)的快速发展对车载感知系统提出了更高的要求。实时理解驾驶环境和条件对于准确的运动规划和控制至关重要1-3。对于车辆来说,道路是与物理世界接触的唯一媒介。道路表面状况决定了许多车辆特性和驾驶性能4。如图1(a)所示,道路的不平整性,如颠簸和坑洼,会加剧乘用车的乘坐体验,这是直观可感知的。实时道路表面状况感知,特别是几何高程(geometry elevation),极大地有助于提升乘坐舒适度5,6。
与无人地面车辆(UGVs)中的其他感知任务如分割和检测相比,道路表面重建(road surface reconstruction)(RSR)是一种新兴技术,最近越来越受到关注。与现有的感知流程类似,RSR通常利用车载激光雷达(LiDAR)和摄像头传感器来保留道路表面信息。激光雷达直接扫描道路轮廓并派生出点云7,8。车辆轨迹上的道路高程可以直接提取,无需复杂算法。然而,激光雷达传感器成本较高,限制了它们在经济型量产车辆上的应用。与车辆和行人等体积较大的交通物体不同,道路的不平整性通常幅度较小,因此点云的准确性至关重要。实时道路扫描上的运动补偿和过滤是必需的,这进一步要求在厘米级别的高精度定位。
基于图像的道路表面重建(RSR),作为一个三维视觉任务,在精度和分辨率方面比激光雷达(LiDAR)更有前景。它还保留了道路表面纹理,使得道路感知更加全面。基于视觉的道路高程重建实际上是一个深度估计问题。对于单目相机,可以基于单张图片实施单目深度估计,或者基于序列实施多视角立体(MVS)来直接估计深度9。对于双目相机,双目匹配回归视差图,这可以转换为深度10,11。给定相机参数,就可以恢复相机坐标系中的道路点云。通过初步的后处理流程,最终获得道路结构和高程信息。在真值(GT)标签的指导下,可以实现高精度和可靠的RSR。
然而,图像视角下的道路表面重建(RSR)存在固有的缺点。对于特定像素的深度估计实际上是沿着垂直于图像平面方向寻找最优箱体(optimal bins)(如图1(b)中的橙色点所示)。深度方向与道路表面存在一定的角度偏差。道路轮廓特征的变化和趋势与搜索方向上的变化和趋势不一致。在深度视图中关于道路高程变化的信息线索是稀疏的。此外,每个像素的深度搜索范围是相同的,导致模型捕捉到的是全局几何层次结构而不是局部表面结构。由于全局但粗糙的深度搜索,精细的道路高程信息被破坏。由于本文关注的是垂直方向上的高程,因此在深度方向上所做的努力被浪费了。在透视视图中,远距离的纹理细节丢失,这进一步为有效的深度回归带来了挑战,除非进一步引入先验约束12。
从俯视图(即鸟瞰图,BEV)估计道路高程是一个自然的想法,因为高程本质上描述了垂直方向的振动。鸟瞰图是一种有效的范式,用于以统一坐标表示多模态和多视图数据13,14。最近在三维目标检测和分割任务上取得的 SOTA 性能是通过基于鸟瞰图的方法实现的15,这与透视视图不同,后者通过在视图转换的图像特征上引入估计头部来进行。图1展示了本文的动机。与在图像视图中关注全局结构不同,鸟瞰图中的重建直接在垂直方向上的一个特定小范围内识别道路特征。在鸟瞰图中投影的道路特征密集地反映了结构和轮廓变化,有助于进行有效和精细化的搜索。透视效应的影响也被抑制,因为道路在垂直于观察角度的平面上被统一表示。基于鸟瞰图特征的道路重建有望实现更高的性能。
本文重建了BEV下的道路表面,以解决上述识别出的问题。特别地,本文关注道路几何,即高程(elevation)。为了利用单目和双目图像,并展示鸟瞰图感知的广泛可行性,本文提出了两个子模型,分别命名为RoadBEV-mono和RoadBEV-stereo。遵循鸟瞰图的范例,本文定义了覆盖潜在道路起伏的感兴趣体素。这些体素通过3D-2D投影查询像素特征。对于RoadBEV-mono,本文在重塑的体素特征上引入了高程估计头。RoadBEV-stereo的结构与图像视图中的双目匹配保持一致。基于左右体素特征,在鸟瞰图中构建了一个4D代价体积,该体积通过3D卷积进行聚合。高程回归被视为对预定义箱体的分类,以实现更高效的模型学习。本文在本文作者之前发布的真实世界数据集上验证了这些模型,显示出它们比传统的单目深度估计和双目匹配方法有着巨大的优势。

图1. 本文的动机。(a)无论是单目还是双目配置,本文在鸟瞰图(BEV)中的重建方法都优于图像视图中的方法。(b)在图像视图中进行深度估计时,搜索方向与道路高程方向存在偏差。在深度视图中,道路轮廓特征是稀疏的。坑洼不容易被识别。(c)在鸟瞰图中,能够精确捕捉到轮廓振动,例如坑洼、路边台阶乃至车辙。垂直方向上的道路高程特征更加密集,也更容易识别。

图2. 坐标示意及真值(GT)高程标签的生成。(a)坐标(b)图像视图中的感兴趣区域(ROI)(c)鸟瞰图中的感兴趣区域(ROI)(d)在网格中生成真值(GT)标签

图3. 道路图像及真值(GT)高程图的示例。

图4. 图像视图中感兴趣的特征体素。位于相同水平位置的堆叠体素的中心被投影到红色线段上的像素点。

图5. RoadBEV-mono的架构。本文利用3D到2D的投影来查询像素特征。高程估计头部使用2D卷积在重塑后的鸟瞰图(BEV)特征上提取特征。

图6. RoadBEV-mono的机制。体素以侧视图展示。

图7. RoadBEV-stereo的架构。定义在左相机坐标系下的体素查询左右特征图的像素特征。本文通过左右体素特征之间的相减,在鸟瞰图(BEV)中构建差异体积。然后,3D卷积对鸟瞰图中的4D体积进行聚合。

图8. RoadBEV-stereo的机制。
实验结果:

图9. (a) RoadBEV-mono和 (b) RoadBEV-stereo的训练损失。

图10. 在单目和双目基础上,与SOTA模型的距离方向上的高程误差比较。

图11. 由RoadBEV-mono重建的道路表面可视化。

图12. 由RoadBEV-stereo重建的道路表面可视化。
总结:
本文首次在鸟瞰图中重建了道路表面的高程。本文分别提出并分析了基于单目和双目图像的两种模型,分别命名为RoadBEV-mono和RoadBEV-stereo。本文发现,BEV中的单目估计和双目匹配与透视视图中的机制相同,通过缩小搜索范围和直接在高程方向挖掘特征而得到改进。在真实世界数据集上的全面实验验证了所提出的BEV体积、估计头和参数设置的可行性和优越性。对于单目相机,在BEV中的重建性能比透视视图提高了50%。同时,在BEV中,使用双目相机的性能是单目的三倍。本文提供了关于模型的深入分析和指导。本文的开创性探索也为与BEV感知、3D重建和3D检测相关的进一步研究和应用提供了宝贵的参考。
#RSRD~
首个自动驾驶路面重建数据集
作者构建了路面重建数据集(Road Surface Reconstruction Dataset, RSRD),该数据集含有100万张精确标注的路面图像。这是首个专门面向自动驾驶路面感知的高精度、多模态和大规模数据集,可作为诸多计算机视觉和自动驾驶应用的测试基准。
数据集主页:https://thu-rsxd.com/rsrd
背景
近年来,智能和自动驾驶车辆的快速发展对驾乘舒适性也提出了更高的要求。路面作为车辆与物理世界有接触的唯一媒介,对车辆行驶性能有决定性影响。提前感知路面状态,尤其是重建路面几何轮廓信息,能为后续决策规划和动力学控制系统提供关键参考信息。基于此实际背景,我们构建并发布了该路面重建数据集(Road Surface Reconstruction Dataset, RSRD)。这是首个专门面向自动驾驶路面感知的高精度、多模态和大规模数据集,可作为诸多计算机视觉和自动驾驶应用的测试基准。
此外,我们于2022年发布了首个大规模路面分类数据集RSCD,含有100万张精确标注的路面图像。此数据集与之结合, 能够提供更加准确、全面的路面状态信息,赋能高阶自动驾驶。

数据采集
我们搭建了实车数据采集系统,包含IMU、双目摄像头、激光雷达和RTK高精定位单元。不同于现有自动驾驶感知数据集,我们专注于路面区域并保留细致的路面纹理信息。我们在城市和乡村区域开展实验,覆盖众多水泥和沥青路面工况,并包含常见路面不平如凹坑、裂缝和减速带。激光雷达点云经过运动补偿和多帧融合处理,为深度学习模型提供高精度、密集的真实标签。更多细节请参考数据集网页。
数据集内容
我们提供约2800对含有密集点云标签,和13000对有稀疏标签的样本。具体包含以下数据:
- 精准校正的双目图像。分辨率为1920*1080,路面预瞄距离约在12米。
- 经过准确运动补偿和多帧融合的激光雷达点云。路面区域的点云密度高,保留细节的路面轮廓变化。
- 由点云生成的单目深度和双目视差真值图。
- 运动位姿信息。经过严格筛选,仅保留定位精度在厘米级的片段。
- 标定参数。因为提供的数据均经过准确的预处理流程,仅提供关键的传感器标定参数,研究人员可直接在数据上开发算法。
此外,我们提供半分辨率(960*540)的版本,研究人员可根据条件和需求选择。
数据集性能

上图左侧为点云标签数量的统计直方图。大部分图像有8万~10万个真值标签,对于960*540大小的图像,GT比例在17%左右。右图统计了路面纵向方向上,每40cm间隔内点云扫描线的平均数量。在9米的预瞄距离内,能保证每20cm有一条雷达扫描。路面区域点云密度显著高于现有数据集,为高精度、高可靠的路面感知提供坚实基础。
应用和基准
该数据集面向路面重建应用,同时作为诸多下游任务的测试基准,例如:
- 单目深度估计和运动恢复结构(SfM)
- 立体匹配和多视立体视觉(MVS)
- 路面点云分割
- 定位与建图
- 路面不平检测与分割(需要额外标注)
作为基线,我们开源了基于立体匹配和BEV进行路面重建的代码,更多细节请参考数据集网页。下图为重建的可视化效果:

基于单目深度估计的路面重建

基于BEV的路面重建
#运动规划~搜索算法
16-18年做过一阵子无人驾驶,那时候痴迷于移动规划;然而当时可学习的资料非常少,网上的论文也不算太多。基本就是Darpa的几十篇无人越野几次比赛的文章,基本没有成系统的文章和代码讲解实现。所以对移动规划的认识不算全面,这几年随着自动驾驶、无人机的研究和应用的增多,很多的论文课程成体系的开始介绍这方面的内容。对于一个理工男来说机器人并且是能自动的、智能规划的,相信没有多少理工男是可以抗拒不想去做进一步了解的。所以一直在收集资料,筹划这哪一天可以出一个这方面系列,然后在code一个项目出来在机器人上捣腾各种实现。再一次加速本人对这一想法落实是两年前看到fast-lab高飞团队出的一系列飞行走廊解决无人机路径规划的工作视频。第一次看到视频时候真被震惊到,移动规划原来还可以这么玩,如此优美的数学框架。讲了这么多只是想致敬过去的经历,开启这个专题第一讲。这个系列主线就是围绕高飞老师《移动机器人动态规划》课程讲稿,里面会补充一些算法细节和自己的思考。这个课程对移动规划体系框架构建非常棒,内容排布的也非常好,唯一缺憾就是对于动态不确定障碍物的规划会少一些,因为课程本来就是针对无人机设计的。
现代机器人学和自动驾驶等领域,路径规划是一个重要的主题. 它涉及到在给定的环境中找到从起点到终点的最优路径. 这个过程通常分为两个部分:前端路径搜索和后端轨迹规划. 前端路径搜索在地图中搜索出一条避开障碍物的轨迹,而后端轨迹规划则对搜索到的轨迹进行优化,使其符合机器人的运动学和动力学约束.
实环境中的机器人运动规划是一个比较复杂的问题,对于复杂的问题人类的解法一般都是分步求解:先做个大概、然后在大概轮廓上逐步的复杂精细。机器人运动规划的学院派解法也是如此:
1.前端:路径规划
- 基于搜索的方法
- 通用图搜索:深度优先搜索(DFS),广度优先搜索(BFS)
- Dijkstra 和 A* 搜索
- 跳点搜索
- 基于采样的方法
- 概率路线图(PRM)
- 快速探索随机树(RRT)
- RRT,有信息的 RRT
- 带动力学约束路径规划
- 状态-状态边界值最优控制问题
- 状态栅格搜索
- 动力学RRT*
- 混合A*
2.后端:轨迹生成
- 最小抖动轨迹生成
- 微分平坦性
- 最小抖动优化
- 最小抖动的闭式解
- 时间分配
- 实际应用
- 软硬约束轨迹优化
- 软约束轨迹优化
- 硬约束轨迹优化
3.不确定性状态求解:移动障碍物、突变环境、设备建模变化
- 基于马尔可夫决策过程的规划(MDP)
- 规划中的不确定性和马尔可夫决策过程
- 最小最大成本规划和期望成本最小规划
- 值迭代和实时动态规划
- 机器人规划的模型预测控制(MPC)
- 线性模型预测控制
- 非线性模型预测控制
前端------搜索路径规划
在开始这部分内容介绍前,需要介绍几个概念。介绍这几个概念的目的在于更贴近实际的去理解搜索在业务中应用。搜索路径规划中是把机器人当成一个质点来考虑的,然而实际的机器人是有一定形状和占用空间的,如果把机器人当成质点来考虑很可能是会搜索出一条实际上不可行的(会碰到障碍物的)路径的。为了解决这个问题呢,我们可以简单的物体的形状转移到地图(让地图障碍物区域加上物体占用空间)。在这样的地图里把机器人当成质点来搜索可行路径。

在配置空间中规划¹²³
- 机器人在C-space中被表示为一个点,例如,位置(在R3中的一个点),姿态(在 (3)中的一个点),等等⁴⁷⁸
- 障碍物需要在配置空间中表示(在运动规划之前的一次性工作),称为配置空间障碍物,或C-障碍⁴⁵⁶
- C-space = (C-障碍) ∪ (C-自由)⁴⁵⁶
- 路径规划是在C-自由中找到从起点qstart到目标点qgoal的路径⁹10¹⁵

在工作空间中
- 机器人有形状和大小(即,难以进行运动规划)
- 在配置空间:C-space中
- 机器人是一个点(即,易于进行运动规划)⁶
- 在进行运动规划之前,障碍物在C-space中表示⁸10
- 在C-space中表示障碍物可能非常复杂。因此,在实践中使用近似(但更保守)的表示。
如果我们保守地将机器人建模为半径为 _ 的球,那么可以通过在所有方向上膨胀障碍物 _ 来构造C-space1。这是一种常见的机器人碰撞检测方法,通过确保球体中心在膨胀地图的自由空间中来实现碰撞评估1。然而,这种保守的方法并未考虑到机器人的形状和大小。
构建地图:
在路径规划中,构建搜索地图是一个关键步骤。这通常涉及到将实际环境抽象为一个图(Graph),其中节点(Nodes)代表可能的位置,边(Edges)代表从一个位置到另一个位置的移动。以下是一个详细的例子:
假设我们有一个机器人需要在一个室内环境中导航。这个环境可以是一个房间,有一些障碍物,比如桌子和椅子。
- 定义节点(Nodes):首先,我们需要确定节点的位置。在这个例子中,我们可以将房间的每一个可达的位置定义为一个节点。例如,我们可以创建一个网格(Grid),每一个网格单元都是一个节点。
- 定义边(Edges):然后,我们需要确定边。如果机器人可以直接从一个节点移动到另一个节点,那么这两个节点之间就有一条边。在我们的例子中,如果两个网格单元相邻,并且没有障碍物阻挡,那么这两个网格单元(即节点)之间就有一条边。
- 定义权重(Weights):最后,我们需要为每一条边定义一个权重。权重可以根据实际的移动成本来确定。例如,如果从一个节点到另一个节点的距离更远,或者路径上有斜坡,那么这条边的权重就应该更大。
地图种类:
栅格地图(Grid Map)则是把环境划分成一系列栅格,在数学视角下是由边联结起来的结点的集合,一个基于图块拼接的地图可以看成是一个栅格图,每个图块(tile)是一个结点,图块之间的连接关系如短线。
概率图(Cost Map)如果在栅格图的基础上,每一栅格给定一个可能值,表示该栅格被占据的概率,则该图为概率图。
特征地图(Feature Map)特征地图用有关的几何特征(如点、直线、面)表示环境。常见于vSLAM(视觉SLAM)技术中。它一般通过如GPS、UWB以及摄像头配合稀疏方式的vSLAM算法产生,优点是相对数据存储量和运算量比较小,多见于最早的SLAM算法中。
拓扑地图(Topological Map)是指地图学中一种统计地图, 一种保持点与线相对位置关系正确而不一定保持图形形状与面积、距离、方向正确的抽象地图。包括有有向图和无向图(字面意思)。

栅格地图

概率图

特征地图

拓扑地图-有向图

拓扑地图-无向图
搜索算法介绍
有了这么多种的地图,那么对应每种图可以用什么对应的算法来做路径的规划呢?下面是地图对应路径搜索算法:
1. 栅格地图 / 概率图
1. Dijkstra
2. BFS(Best-First-Search)
3. A*
4. hybrid A*
5. D *
6. RRT
7. RRT*
8. 蚁群算法
9. Rectangular Symmetry Reduction (RSR)
10. BUG
11. Beam search
12. Iterative Deepeningc
13. Dynamic weighting
14. Bidirectional search
15. Dynamic A* and Lifelong Planning A *
16. Jump Point Search
17. Theta *
2. 拓扑地图
1. Dijkstra
2. BFS(Best-First-Search)
3. A*
4. CH
5. HH
6. CRP图搜索算法结构
:::success
- 维护一个容器来存储所有待访问的节点
- 该容器以起始状态XS进行初始化
- 循环
- 根据某个预定义的评分函数从容器中移除一个节点
- 访问一个节点
- 扩展:获取该节点的所有邻居
- 发现所有的邻居
- 将它们(邻居)推入容器
- 扩展:获取该节点的所有邻居
- 结束循环 :::
通用搜索算法结构
常用的图搜索有3大类的搜索结构,其它算法都是在这三个大的框架之下做改进。
深度优先搜索(Depth-First Search, DFS):
- 原理:DFS是一种用于遍历或搜索树或图的算法。这个算法会尽可能深地搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
- 优点:实现简单,当目标明确时,搜索效率高。
- 缺点:不保证找到最短路径,有可能会导致搜索陷入无限循环。
广度优先搜索(Breadth-First Search, BFS):
- 原理:BFS是一种广度优先的搜索算法,用于搜索树或图。这个算法从根节点开始,沿着树的宽度遍历树的节点,如果所有节点均被访问,则算法结束。
- 优点:可以找到最短路径,结果可靠。
- 缺点:空间复杂度高,当解空间大时,内存消耗大。
贪婪搜索(Greedy Search):
- 原理:贪婪搜索是一种在每一步选择中都采取在当前看来最好的选择,希望通过一系列的最优选择,能够产生一个全局最优的解决方案。
- 优点:简单,易于实现,计算速度快。
- 缺点:不能保证找到全局最优解,只能保证找到局部最优解。
- 深度优先搜索(DFS):DFS会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条路径。这种搜索策略可以看作是"先入后出",因此在实现DFS时通常使用栈(Stack)这种数据结构。DFS的优点是实现简单,当目标明确时,搜索效率高。然而,DFS的缺点是不保证找到最短路径,有可能会导致搜索陷入无限循环。
- 广度优先搜索(BFS):相比之下,BFS会根据离起点的距离,按照从近到远的顺序对各节点进行搜索。这种搜索策略可以看作是"先入先出",因此在实现BFS时通常使用队列(Queue)这种数据结构。BFS的优点是可以找到最短路径,结果可靠。然而,BFS的缺点是空间复杂度高,当解空间大时,内存消耗大。

算法核心的三个问题是:
- 问题1:何时结束循环?
- 可能的选项:当容器为空时结束循环
- 问题2:如果图是循环的怎么办?
- 当一个节点从容器中移除(扩展/访问)后,它就不应该再被添加回容器
- 问题3:如何移除正确的节点以便尽快到达目标状态,从而减少图节点的扩展。
深度优先算法:数据结构维护一个后进先出(LIFO)的容器(即栈),算法移除/扩展容器中最深的节点

#生成示例数据
graph = {}
graph["A"] = ["B", "D", "F"]
graph["B"] = ["C", "E"]
graph["D"] = ["C"]
graph["F"] = ["G", "H"]
graph["C"] = []
graph["E"] = []
graph["G"] = []
graph["H"] = []
from collections import deque
search_queue = deque() # 创建一个节点列表
search_queue += graph["A"] # 表示将"A"的相邻节点都添加到节点列表中
from collections import deque
def search(start_node):
search_queue = deque()
search_queue += graph[start_node]
searched = [] # 这个数组用于记录检查过的节点
while search_queue: # 只要节点列表不为空
node = search_queue.pop() #深度优先
#node = search_queue.popleft() # 广度优先取出节点列表中最左边的节点
print(node, end=' ') # 打印出当前节点
if not node in searched: # 如果这个节点没检查过
if node == 'G': # 检查这个节点是否为终点"G"
print("\nfind the destination!")
return True
else:
search_queue += graph[node] # 将此节点的相邻节点都添加到节点列表中
searched.append(node) # 将这个节点标记为检查过
# 如果节点列表为空仍没找到终点,则返回False
return False
print(search("A"))广度优先搜索算法:
数据结构:维护一个先进先出(FIFO)的容器(即队列),算法操作:移除/扩展容器中最浅的节点。具体代码参考上面深度搜索算法,把"node = search_queue.pop() #深度优先"换成"node = search_queue.popleft() # 广度优先取出节点列表中最左边的节点"即可。可以看出BFS和DFS差别就在于根据"先入"或"后入"的原则,从边界中选择下一个节点。

贪婪搜索 (Greedy Search):
贪心算法的特点是考虑了从目标节点找到任意点的代价,而一般算法考虑的是从起始节点到任意点的代价 。即贪心算法考虑的是如何快速的找到目标节点,使得到达目标节点的时间成本最小;而一般算法考虑的是目标节点到达目标节点的花费代价是最小的,而不是快速找到目标节点。基于贪心策略试图向目标移动尽管这不是正确的路径。由于它仅仅考虑到达目标的代价,而忽略了当前已花费的代价,于是尽管路径变得很长,它仍然继续走下去。
贪婪算法中"行动的成本"可以用启发式函数h(n)来算从任意结点n到目标结点的最小代价评估值;启发函数决定了贪婪算法运算书读,所以选择一个好的启发函数很重要。
- 实际的搜索问题中,从一个节点到其邻居有一个"C"的成本
- 可以作为启发函数计算代价的有:长度,时间,能量等
- 当所有权重都为1时,贪婪算法找到最优解
- 对于一般情况,如何尽快找到最小成本路径?
Dijkstra算法:
Dijkstra算法算是贪心思想实现的,其可以适用与拓扑图或者栅格图,具体实现方法是,首先把起点到所有点的距离存下来找个最短的,然后松弛一次再找出最短的,所谓的松弛操作就是,遍历一遍看通过刚刚找到的距离最短的点作为中转站会不会更近,如果更近了就更新距离,这样把所有的点找遍之后就存下了起点到其他所有点的最短距离:

- 策略:扩展/访问具有最低累积成本g(n)的节点
- g(n):从起始状态到节点"n"的累积成本的当前最佳估计
- 更新所有未扩展邻居"m"的累积成本g(m)
- 已经被扩展/访问的节点保证具有从起始状态到该节点的最小成本 :::success
- 维护一个优先队列来存储所有待扩展的节点
- 用起始状态XS初始化优先队列
- 设置g(XS)=0, 对图中的其他所有节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从优先队列中取出g(n)最小的节点"n"
- 将节点"n"标记为已扩展
- 如果节点"n"是目标状态,返回TRUE并退出循环
- 对节点"n"的所有未扩展的邻居节点"m":
- 如果g(m) = 无穷
- g(m)= g(n) + Cnm
- 将节点"m"加入队列
- 如果g(m) > g(n) + Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点的循环
- 结束主循环 ::: BFS(Best-First-Search)算法
BFS(Best-First-Search)算法也是可以看作基于启发式的深度优先算法,其按照和Dijkstra类似的流程运行,不同的是它能够评估任意结点到目标点的代价(即启发式函数)。与选择离初始结点最近的结点不同的是,它选择离目标最近的结点。BFS不能保证找到一条最短路径。但是它比Dijkstra算法快的多,因为它用了一个启发式函数(heuristic )能快速地导向目标结点。例如,如果目标位于出发点的南方,BFS将趋向于导向南方的路径。在下面的图中,越黄的结点代表越高的启发值(移动到目标的代价高),而越黑的结点代表越低的启发值(移动到目标的代价低)。这表明了与Dijkstra 算法相比,BFS运行得更快。

然而,这两个例子都仅仅是最简单的情况------地图中没有障碍物,最短路径是直线的。现在我们来考虑前边描述的凹型障碍物。Dijkstra算法运行得较慢,但确实能保证找到一条最短路径:

另一方面,BFS运行得较快,但是它找到的路径明显不是一条好的路径:

由于BFS是基于贪心策略的,它试图向目标移动尽管这不是正确的路径。由于它仅仅考虑到达目标的代价,而忽略了当前已花费的代价,于是尽管路径变得很长,它仍然继续走下去。
结合两者的优点不是更好吗?1968年发明的A算法就是把启发式方法(heuristic approaches)如BFS,和常规方法如Dijsktra算法结合在一起的算法。有点不同的是,类似BFS的启发式方法经常给出一个近似解而不是保证最佳解。然而,尽管A基于无法保证最佳解的启发式方法,A却能保证找到一条最短路径。
A: 带有启发式函数的Dijkstra算法 *
把Dijkstra算法(靠近初始点的结点)和BFS算法(靠近目标点的结点)的信息块结合起来。在A的标准术语中,g(n)表示从初始结点到任意结点n的代价,h(n)表示从结点n到目标点的启发式评估代价(heuristic estimated cost)。当从初始点向目标点移动时,A* 权衡这两者。每次进行主循环时,它检查f(n)最小的结点n,其中f(n) = g(n) + h(n)。
- 累积成本
- g(n): 从起始状态到节点"n"的累积成本的当前最佳估计
- 启发式函数
- h(n): 从节点n到目标状态(即目标成本)的预计最小成本
- 从起始状态到通过节点"n"的目标状态的最小预计成本是 f(n) = g(n) + h(n)
- 策略: 扩展具有最便宜的 f(n) = g(n) + h(n) 的节点
- 更新所有未扩展邻居"m"的节点"n"的累积成本 g(m)
- 已经扩展的节点保证具有从起始状态到该节点的最小成本 :::success
- 维护一个优先队列来存储所有待扩展的节点
- 对所有节点预定义启发函数h(n)
- 用起始状态XS初始化优先队列
- 设置g(XS)=0,对图中的其他节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从队列中取出f(n)=g(n)+h(n)最小的节点"n"
- 将节点"n"标记为已扩展
- 如果节点"n"是目标状态,返回TRUE并退出循环
- 对节点"n"的所有未扩展邻居节点"m":
- 如果g(m)=无穷
- g(m)= g(n) + Cnm
- 将节点"m"加入队列
- 如果g(m)>g(n)+Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点循环
- 结束主循环 ::: 通过对启发式函数的调节,可以达成控制A* 的行为:
- 一种极端情况,如果h(n)是0,则只有g(n)起作用,此时A* 演变成Dijkstra算法,这保证能找到最短路径。
- 如果h(n)经常都比从n移动到目标的实际代价小(或者相等),则A保证能找到一条最短路径。h(n)越小,A扩展的结点越多,运行就得越慢。
- 如果h(n)精确地等于从n移动到目标的代价,则A 将会仅仅寻找最佳路径而不扩展别的任何结点,这会运行得非常快。尽管这不可能在所有情况下发生,但是你仍可以在一些特殊情况下让它们精确地相等。只要提供完美的信息,A会运行得很完美,认识这一点很好。
- 如果h(n)有时比从n移动到目标的实际代价高,则A* 不能保证找到一条最短路径,但它运行得更快。
- 另一种极端情况,如果h(n)比g(n)大很多,则只有h(n)起作用,A* 就演变成了BFS算法。
如果目标的引力太低,会得到最短路径,不过速度变慢了;如果目标引力太高,那就放弃了最短路径,但A运行得更快,所以最优路径和最快搜索在复杂情况下需要有一个取舍/平衡。
A的这个特性非常有用。例如,你会发现在某些情况下,你希望得到一条好的路径,而不是一条完美的路径,为了权衡g(n)和h(n),你可以修改任意一个。

如果alpha是0,则改进后的代价函数的值总是1。这种情况下,地形代价被完全忽略,A工作变成简单地判断一个网格可否通过。如果alpha是1,则最初的代价函数将起作用,然后你得到了A的所有优点。你可以设置alpha的值为0到1的任意值。
可以考虑对启发式函数的返回值做选择:绝对最小代价或者期望最小代价。例如,如果你的地图大部分地形代价为2,其它一些地方是代价为1的道路,那么你可以考虑让启发式函数不考虑道路,而只返回2距离。
速度和精确度之间的选择并不是全局固定对。在地图上的某些区域,精确度是重要的,你可以基于此进行动态选择。例如,假设我们可能在某点停止重新计算路径或者改变方向,则在接近当前位置的地方,选择一条好的路径则是更重要的,对于在地图上的一个安全区域,最短路径也许并不十分重要,但是当从一个危险区域脱离对时候,轨迹的精度是最重要的。
同样通过对g(n)或者f(n)的调节,也可以达成A具体动作的控制
-
通过加上障碍物cost function到g(n)或者f(n)(这两个动作是一个意思),可以实现规划路径在障碍物中间。
-
通过加上车辆几何或者轨迹kappa平滑度cost function的到g(n)或者f(n),可以实现规划出来的路径是平滑变化的。
-
通过加上到way point的cost function的到g(n)或者f(n),规划出来的路径则倾向于走way points的方向。
-
构造精确启发函数的一种方法是预先计算任意一对结点之间最短路径的长度。有几种方法可以近似模拟这种启发函数:
-
【降采样地图-预计算】在密集栅格图的基础上添加一个分辨率更大的稀疏栅格图。预计算稀疏图中任意两个栅格的最短路径。
-
【waypoings-预计算】在密集栅格图上,预计算任意两个way points的的最短路径。
-
通过以上方法,添加一个启发函数h'用于评估从任意位置到达邻近导航点/中继点(waypoints)的代价。最终的启发式函数可以是:
h(n) = h'(n, w1) + distance(w1, w2), h'(w2, goal)
网格地图中的启发式算法
在网格地图中,有一些众所周知的启发式函数计算方法:
1. 曼哈顿距离
2. 对角线距离
3. 欧几里得距离
4. 欧几里德距离平方曼哈顿距离
标准的启发式函数是曼哈顿距离(Manhattan distance)。考虑代价函数并找到从一个位置移动到邻近位置的最小代价D。因此,h是曼哈顿距离的D倍:
``` H(n) = D \ * (abs ( n.x -- goal.x ) + abs ( n.y -- goal.y ) ) ```
对角线距离
如果在地图中允许对角运动那么需要考虑对角线距离。(4 east, 4 north)的曼哈顿距离将变成8D。然而,可以简单地移动(4 northeast)代替,所以启发函数应该是4D。这个函数使用对角线,假设直线和对角线的代价都是D:
H(n) = D * max(abs(n.x - goal.x), abs(n.y - goal.y))
如果对角线运动的代价不是D,但类似于D2 = sqrt(2) * D,则准确的计算方法如下:
h_diagonal(n) = min(abs(n.x - goal.x), abs(n.y - goal.y))
h_straight(n) = (abs(n.x - goal.x) + abs(n.y - goal.y))
H(n) = D2\* h_diagonal(n) + D\* (h_straight(n) - 2\ *h_diagonal(n)))计算h_diagonal(n):沿着斜线可以移动的步数;h_straight(n):曼哈顿距离;然后合并这两项,让所有的斜线步都乘以D2,剩下的所有直线步(注意这里是曼哈顿距离的步数减去2倍的斜线步数)都乘以D。
欧几里德距离
如果单位可以沿着任意角度移动(而不是网格方向),那么应该使用直线距离:
``` H(n) = D* sqrt((n.x-goal.x)^2 + (n.y-goal.y)^2) ```然而,如果是这样的话,直接使用A时将会遇到麻烦,因为代价函数g不匹配启发函数h。因为欧几里得距离比曼哈顿距离和对角线距离都短,你仍可以得到最短路径,不过A将运行得更久一些:

欧几里德距离平方
还有一个方法是,使用距离的平方替代距离,避免进行平方根开方运算,从而减少计算消耗:
``` H(n) = D* ((n.x-goal.x)^2 + (n.y-goal.y)^2) ```不过这样做会明显地导致衡量单位的问题。当A计算f(n) = g(n) + h(n),距离的平方将比g的代价大很多,并且会因为启发式函数评估值过高而停止。对于更长的距离,这样做会靠近g(n)的极端情况而不再计算任何东西,A退化成BFS:

启发函数的启发因子
导致A搜索低性能的另外一个原因是启发函数的启发因子。当某些路径具有相同的f值的时候,它们都会被探索,比较函数无法打破比较平衡点,尽管我们这时候只需要搜索其中的一条,下图为没有添加启发因子的效果:

为了解决这个问题,我们可以为启发函数添加一个较小的启发因子。启发因子对于每个结点必须是确定的唯一的,而且它必须让f值体现区别。因为A将会对f值进行堆排序,让f值不同,意味着只有一个f值会被检测。
-
一种添加启发因子的方式是稍微改变h的衡量单位。如果我们减少衡量单位,那么当我们朝着目标移动的时候f将逐渐增加。很不幸,这意味着A倾向于扩展到靠近初始点的结点,而不是靠近目标的结点。我们可以稍微的微调h的衡量单位(甚至是0.1%),A就会倾向于扩展到靠近目标的结点。
heuristic \ \ *= (1.0 + p)
其中这里的启发因子需要满足
p < 移动一步的最小代价 / 期望的最长路径长度。假设你不希望你的路径超过1000步(step),你可以使p = 1 / 1000。添加这个附加值的结果是,A比以前搜索的结点更少了。如下图所示。

当存在障碍物时,当然仍要在它们周围寻找路径,但要意识到,当绕过障碍物以后,A搜索的区域非常少:

-
Steven van Dijk的建议是:直接把h放到比较函数中。当f值相等时,比较函数将会通过比较两个节点h的大小实现启发因子的功能,打破比较平衡点。
-
Cris Fuhrman的建议的启发因子是:给每个节点加一个决定性的任意数,例如所在坐标系中位置的hash值
-
最后一种方法类似于frenet坐标系的做法:对比起点到终点的直连线段的投影距离,计算方法入下:
dx1 = current.x - goal.x
dy1 = current.y - goal.y
dx2 = start.x - goal.x
dy2 = start.y - goal.y
cross = abs(dx1dy2 - dx2dy1)
heuristic += cross*0.001
其目的是:计算初始->目标向量和当前->目标向量的向量叉乘(cross-product)。当向量偏离方向后,其叉乘将会提供一个较大的启发因子。结果是,这段代码选择的路径稍微倾向于从初始点到目标点的直线。当没有障碍物时,A不仅搜索很少的区域,而且它找到的路径看起来非常棒:

跳点搜索
Jump Point Search (JPS) 是一种改进的 A_ 算法,它保留了 A_ 算法的主体框架,但在寻找后继节点的操作上进行了优化。在 A 算法中,会将当前节点的所有未访问邻居节点加入 openlist。而 JPS 则使用一些方法将有"价值"的节点加入 openlist。JPS 的核心就是寻找跳点 (Jump Point),在 JPS 中,就是将跳点加入 openlist。跳点就是路径的转折点。

JPS明智地进行探索,因为它总是根据规则向前看。强调了其在搜索过程中的智能性和前瞻性。
JPS 算法的基本流程与 A 一致,代价函数 f(n) 仍然表示如下:f(n)=g(n)+h(n)。
JPS 算法的优点在于,由于它只扩展跳点,跳点间的栅格被跳过,不加入 OpenList,因此,它的搜索效率比 A 算法提高了一个等级。
在实现JPS前先了解它的规则
- 强迫邻居:节点X的邻居节点有障碍物,且X的父节点P经过X到达N的距离代价,比不经过X到达N的任一路径的距离代价都小,则称N是X的强迫邻居。

- 跳点(Jump Point):什么样的节点可以作为跳点
(1)节点 A 是起点、终点.
(2)节点A 至少有一个强迫邻居.
(3)父节点在斜方向(斜向搜索),节点A的水平或者垂直方向上有满足 (1)、(2) 的节点
在搜索过程中它可以将水平和垂直方向两个分量,分解为一个方向为(1, 0)的水平搜索,一个方向为(0, 1)的垂直搜索
同理斜向有四种方向
左上 (-1, 1) ------>对应的水平 (-1, 0),垂直 ( 0, 1)
右上 ( 1, 1) ------>对应的水平 ( 1, 0),垂直 ( 0, 1)
右下 ( 1, -1) ------>对应的水平 ( 1, 0),垂直 ( 0, -1)
左下 (-1, -1) ------>对应的水平 (-1, 0),垂直 ( 0, -1) 如上所说(3)的情形即为如下

- 递归应用直线剪枝规则,并将 y 识别为 x 的跳点后继。这个节点很有趣,因为它有一个邻居 z,除非通过访问 x 然后 y 的路径,否则无法最优地到达。
- 递归应用对角线剪枝规则,并将 y 识别为 x 的跳点后继。
- 在每次对角线步骤之前,我们首先递归直线。只有当两次直线递归都未能识别出跳点时,我们才再次对角线步进。
- 节点 w,x 的强制邻居,正常扩展。(也推入开放列表,优先队列)。
记住:你只能直线跳跃或对角线跳跃;不能分段跳跃。:::success - 维护一个优先队列来存储所有待扩展的节点
- 对所有节点预先定义启发函数h(n)
- 用起始状态XS初始化优先队列
- 设置g(XS)=0,对图中的其他节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从队列中取出f(n)=g(n)+h(n)最小的节点"n"
- 将节点"n"标记为已扩展
- 如果节点"n"是目标状态,返回TRUE并退出循环
- 对节点"n"的所有未扩展邻居节点"m":
- 如果g(m)=无穷
- g(m)= g(n) + Cnm
- 将节点"m"加入队列
- 如果g(m)>g(n)+Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点的循环
- 结束主循环 ::: openlist查找具体流程如下²:
- 初始化起点节点 start ,将起点周围四个角落的空闲节点相对于起点的相对位置加入起点节点的 forced_neighbor_list。
- 创建一个 openlist ,将 start 加入 openlist。
- while openlist is not empty:
- node ← openlist.Pop ()
- 从 node 开始跳跃,首先进行直线跳跃,再进行对角线跳跃。
- 用 parent 表示从 node 进行对角线跳跃得到的节点,用 current 表示从 parent 进行直线跳跃得到的节点。
- 如果 current 是跳点,而 parent 与 node 是同一个节点,则将 current 加入 openlist,同时将 current 的父节点指向 node;
- 如果 current 是跳点,而 parent 与 node 不是同一个节点,则将 parent 和 current 加入 openlist,同时将 current 的父节点指向 parent,将 parent 的父节点指向 node;
- 如果 current 是障碍物或者边界,则进行对角线跳跃;
- 如果 parent 是障碍物或者边界,则进入下一轮循环。
例子:

- 扩展--->对角线移动
- 最终找到一个关键节点,将其加入开放列表。
- 从开放列表中弹出它(唯一的节点)。
- 垂直扩展,在障碍物处结束。

- 水平扩展,遇到一个具有强制邻居的节点。
- 将其添加到开放列表。

- 对角线扩展,扩展后没有发现任何新的节点。
- 完成当前节点的扩展。

- 对角线移动。
- 先沿垂直和水平方向扩展。
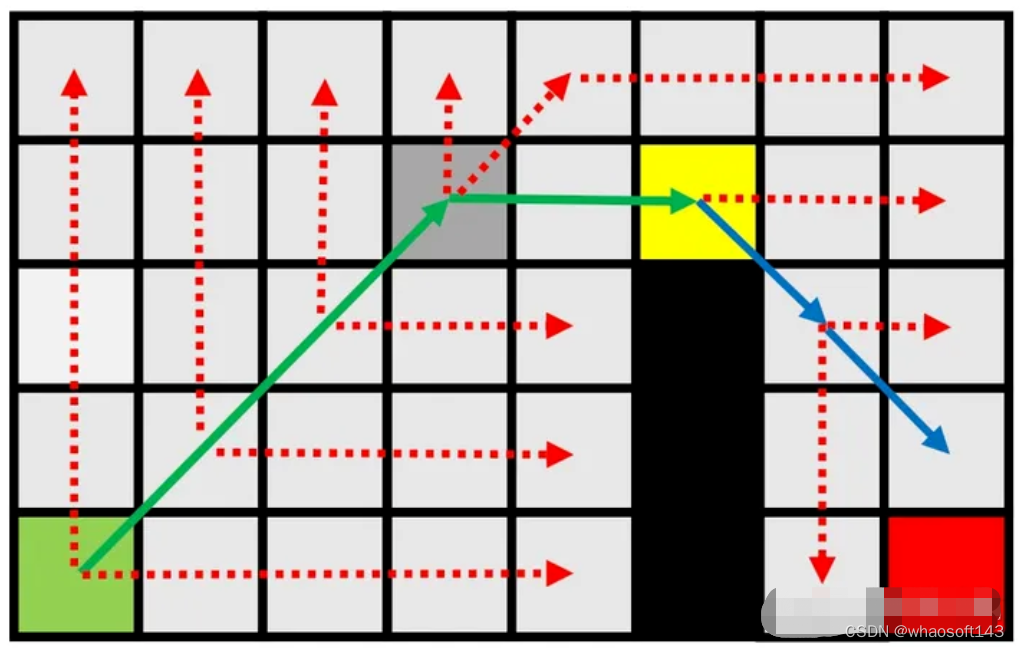
- 没有发现任何新的节点。
- 对角线移动。
更详细跳点搜索可以参考下面文章: 也致敬这个大佬~
小结:
本文介绍了motion plan学院派的框架:
- 前端路径规划
- 后端轨迹生成
- 不确定障碍物预估规划
并且详细介绍了前端路径规划常用的搜索规划,介绍了搜索规划的一些前置知识:
- c-space,为了方便物体质点化处理,建图时把物体形状构建转移到图
- 各种不同图如何构建成适合搜索算法的数据格式,以及不同图适合的搜索算法
- 搜索算法的三个基本框架:深度搜索、广度搜索、贪心搜索
详细介绍了了几种贪心搜索算法原理和实现思路:
- Dijkstra算法:
- A* 搜索
- 跳点搜索
并且介绍了:累计成本,启发函数,以及这两个函数的物理意义;如何调控两个参数来实现计算速度和最优路径的平衡。
- 累积成本
- g(n): 从起始状态到节点"n"的累积成本的当前最佳估计
- 启发式函数
- h(n): 从节点n到目标状态(即目标成本)的预计最小成本