
AVadCLIP: Audio-Visual Collaboration for Robust Video Anomaly Detection
https://arxiv.org/pdf/2504.04495
摘要
随着视频异常检测在智能监控领域的广泛应用,传统的仅基于视觉的检测方法在复杂环境中常面临信息不足和误报率高的问题。为解决这些限制,我们提出了一种新颖的弱监督框架,利用音视频协作实现鲁棒的视频异常检测。利用对比语言-图像预训练(CLIP)在视觉、音频和文本领域卓越的跨模态表示学习能力,我们的框架引入了两个主要创新:一种高效的音视频融合,通过轻量级参数自适应实现跨模态整合,同时保持CLIP主干网络冻结 ;以及一种新颖的音视频提示,基于音视频特征与文本标签之间的语义相关性,动态增强文本嵌入的关键多模态信息,显著提升CLIP在视频异常检测任务中的泛化能力。此外,为增强推理过程中对模态缺失的鲁棒性,我们进一步开发了不确定性驱动的特征蒸馏模块,从仅视觉输入中合成音视频表示。该模块采用基于音视频特征多样性的不确定性建模,在蒸馏过程中动态强调具有挑战性的特征。我们的框架在多个基准测试中表现出卓越性能,音频集成显著提升了各种场景下的异常检测准确性。值得注意的是,通过不确定性蒸馏增强的单模态数据,我们的方法持续优于当前的单模态VAD方法。
I. INTRODUCTION
视频异常检测(VAD)作为智能监控系统中的关键技术,专注于识别视频中的异常事件,近年来引起了大量的研究兴趣1--11。由于异常事件的罕见性和人工标注的高成本,完全监督的框架在大规模部署中不切实际。作为解决方案,弱监督视频异常检测(WSVAD)方法12--15获得了关注,旨在粗略监督下发现潜在异常。当前的WSVAD方法主要依赖于多实例学习(MIL)框架,使用视频级标签进行模型训练12, 16。具体来说,这些方法将视频视为段(实例)的集合,并通过硬注意力机制(即Top-K)17来区分异常模式。随着基础模型的快速发展,对比语言-图像预训练(CLIP)18在各种下游任务中,包括视频理解19, 20,显示出卓越的潜力。基于CLIP的显著成功,像VadCLIP21和TPWNG15这样的最新方法通过利用CLIP的语义对齐能力推进了WSVAD。
然而,这些方法,无论是基于CLIP的还是传统的,主要依赖于单模态视觉信息,这往往在复杂的现实世界场景中导致显著的检测限制。视觉遮挡、极端光照变化和环境噪声会使视觉特征不可靠或模糊22--24。在这些具有挑战性的条件下,多模态信息,特别是音频,提供了不可或缺的上下文线索,可以补充和增强基于视觉的检测。例如,当视觉数据受损时,音频仍然保持稳健,允许检测到画外事件。在声音丰富的环境中,某些异常如爆炸、尖叫或枪声表现出独特的声学特征,使其在音频领域更具区分度。同样,在视觉特征退化的低光照条件下,音频作为关键的补充模态。这些观察强调了整合音频和视频模态的重要性,因为它们的互补性质可以显著提高异常检测系统在多样化和具有挑战性的环境中的准确性和鲁棒性。我们在图1中说明了音视频整合对WSVAD的影响。
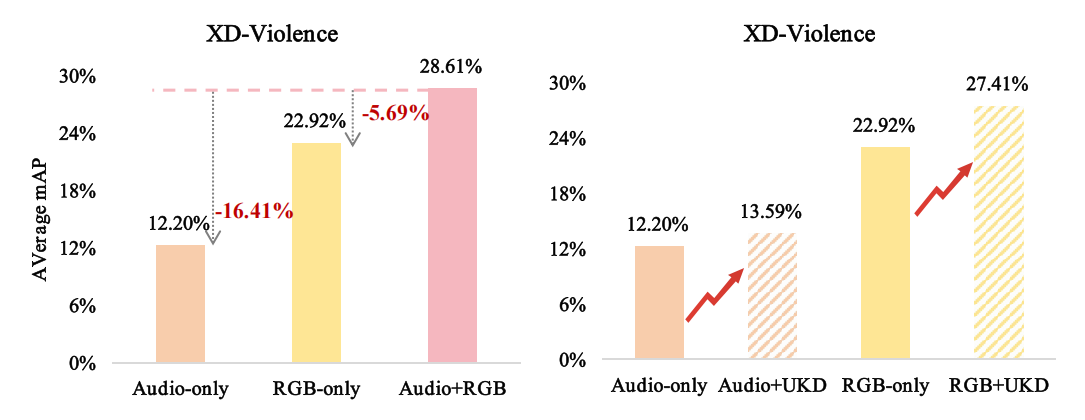
图1. 左图:音视频协作效果的示意图;右图:我们提出的蒸馏(UKD)效果的示意图。
现有的尝试22, 25, 26将音频纳入视频异常检测通常采用传统的特征连接方法,例如将I3D27或C3D28提取的视觉特征与VGGish29提取的音频特征融合。这些方法未能充分利用多模态学习的潜力,导致次优的跨模态整合。此外,它们忽视了视觉和听觉模态之间固有的语义对齐,这对增强异常检测性能至关重要。
为了解决这些限制,我们提出了AVadCLIP,一个利用音视频协作学习,通过CLIP驱动的跨模态对齐来推动音视频异常检测的WSVAD框架。AVadCLIP充分利用了CLIP在视觉、文本和音频之间建立语义一致性的内在能力,确保视频异常检测在统一的多模态语义空间中进行,而不仅仅是融合原始特征。我们的框架引入了三个重要创新:一种高效的音视频特征融合机制,不同于简单的特征连接,通过轻量级参数自适应实现自适应的跨模态整合,同时保持CLIP主干冻结 ;一种新颖的音视频提示机制,动态地用关键多模态信息丰富文本标签嵌入,增强对视频的上下文理解,并实现更精确的不同类别识别 ;以及一个不确定性驱动的特征蒸馏(UKD)模块,在音频缺失的情况下生成类似音视频的增强特征,确保鲁棒的异常检测性能(如图1所示)。总的来说,我们的AVadCLIP仅依赖于一小组可训练参数,有效地将CLIP的预训练知识转移到弱监督的音视频异常检测任务中。此外,通过采用基于数据不确定性建模的蒸馏策略,我们进一步将学习到的知识从我们的音视频异常检测器转移到单模态检测器,使在模态不完整的场景中能够进行鲁棒的异常检测。
总之,我们的主要贡献如下:
• 我们提出了一种利用音视频协作学习的WSVAD框架,借助CLIP的多模态对齐能力。通过引入轻量级自适应音视频融合机制,并通过基于提示的学习整合音视频信息,我们的方法在多模态环境下有效实现了CLIP驱动的鲁棒异常检测。
• 我们设计了一个不确定性驱动的特征蒸馏模块,将确定性估计转化为概率不确定性估计。这使得模型能够捕捉特征分布的方差,确保即使在单模态数据下也能保持鲁棒的异常检测性能。
• 在两个WSVAD数据集上的大量实验表明,我们的方法在音视频场景中取得了卓越的性能,同时在缺乏音频的条件下也能保持鲁棒的异常检测结果。
II. RELATED WORK
A. Video Anomaly Detection
近年来,视频异常检测已被广泛研究,现有方法大致可分为半监督和弱监督方法。其中,半监督方法主要依赖正常视频片段进行训练,并通过在推理过程中检测与学习到的正常模式的偏差来识别异常。这些方法通常采用自监督学习技术30--32,如重构33, 34或预测35, 36。基于重构的方法假设模型能够有效重构正常视频,而异常视频由于分布差异,会导致显著的重构误差。自编码器37, 38被广泛用于捕捉正常模式特征,重构误差作为异常指标。基于预测的方法39利用模型预测未来帧,根据预测误差检测异常。然而,半监督方法的一个关键限制是它们倾向于过度拟合正常模式,导致对未见异常的泛化能力较差。
相比之下,弱监督方法通常采用MIL框架,只需要视频级异常标签,显著降低了标注成本。经典工作DeepMIL12采用排序损失来区分正常和异常实例。此外,还提出了两阶段自训练策略来进一步增强检测,其中在MIL训练期间识别的高置信度异常区域作为二次细化阶段的伪标签40--42。随着视觉语言模型(VLMs)43的兴起,CLIP显示出卓越的跨模态能力,并越来越多地应用于WSVAD。VadCLIP21是第一个基于CLIP的WSVAD方法,通过文本和视觉提示整合文本先验,增强异常检测。在此基础上,TPWNG15通过两阶段方法改进特征学习。最近的研究趋势聚焦于大模型驱动的策略,例如无需训练的框架44, 45、时空异常检测46和开放场景异常检测47。多模态融合48的最新进展引入了强大的框架,结合了视觉和音频特征等多种模态。例如,AVCL49和DSRL50在利用视觉和音频线索改进异常检测方面显示出巨大潜力。
B. Audio-Visual Learning
音频与视觉信息的融合已成为多模态学习中的一个关键研究方向,因为它不仅能提升模型性能,还能促进对复杂场景的更深层次理解。在音视频融合的各个方面已取得显著进展51, 52。在音视频分割领域,研究人员旨在基于音视频线索精确分割发声物体。Chen等人53提出了一种新颖的信息样本挖掘方法用于音视频监督对比学习。Ma等人54引入了一种两阶段训练策略来解决音视频语义分割(AVSS)任务。在这些工作基础上,Guo等人55引入了一个新任务:开放词汇AVSS(OV-AVSS),将AVSS扩展到超越预定义标注标签的开放世界场景。
音视频事件定位旨在识别视觉和听觉事件的空间和时间位置,注意力机制被广泛用于模态融合。例如,He等人56提出了一种音视频协同引导注意力机制,而Xu等人57引入了一种音频引导的空间-通道注意力机制。相关任务包括音视频视频解析58, 59和音视频动作识别60。音视频异常检测25, 61也成为一个日益增长的研究热点。例如,Yu等人62应用自蒸馏模块将单模态视觉知识转移到音视频模型,减少噪声并弥合单模态和多模态特征之间的语义差距。类似地,Pang等人63提出了一种加权特征生成方法,利用视觉和听觉信息之间的相互引导,随后通过双线性池化实现有效的特征整合。
C. Large Models in Video Understanding
近年来,大型模型在视频理解任务的感知和推理方面展现出卓越的能力,极大地加速了从纯视觉模型向多模态视频理解框架的转变。代表性的视觉模型,如VideoMAE 64,采用掩码自监督学习来有效建模视频中的时空动态,促进了其在视频分类、动作识别和异常检测中的广泛应用。随着CLIP 18和ALIGN 65等视觉语言模型(VLMs)的成功,将语言先验融入视频理解已成为一个突出的研究趋势。这些模型通过联合图像-文本编码进行跨模态语义对齐,并已广泛应用于零样本动作识别、视频检索和开放词汇场景理解等任务。进一步的进展,包括X-CLIP 66和VideoCLIP 20,将时间建模引入VLM架构,显著提高了对长视频内容的语义理解。同时,基于VLM的视频推理任务正获得越来越多的关注。VL-T5 67和VideoChat 68等模型利用语言引导机制实现视频问答、事件解释和因果推理,从而大大拓宽了视频理解的范畴。
III. METHODOLOGY
A. Problem Statement
给定一个视频训练集 {Vi}\{V_i\}{Vi},其中每个视频 VVV 包含视觉信息和相应的音频信息,以及一个视频级标签 y∈RCy \in \mathbb{R}^Cy∈RC。这里,CCC 表示类别数量(包括正常类和各种异常类)。为了便于模型处理,我们使用视频编码器和音频编码器分别提取高级特征 Xv∈RN×dX^v \in \mathbb{R}^{N \times d}Xv∈RN×d 和 Xa∈RN×dX^a \in \mathbb{R}^{N \times d}Xa∈RN×d,其中 NNN 表示视频的时间长度(即帧数或片段数),ddd 表示特征维度。WSVAD 任务的目标是使用训练集中所有可用的 XvX^vXv、XaX^aXa 及其对应标签训练一个检测器,使模型能够准确判断测试样本中每一帧是否为异常,并识别具体的异常类别。
我们方法的整体流程如图 2 所示,首先使用专用编码器从视频和音频中提取特征,然后自适应地融合它们以进行多模态对应学习。我们将一个分类分支与基于 CLIP 的对齐方法相结合,使用音视频提示将细粒度的多模态信息注入到文本嵌入中。此外,还采用不确定性驱动的蒸馏来提高在模态不完整场景下的异常检测鲁棒性。
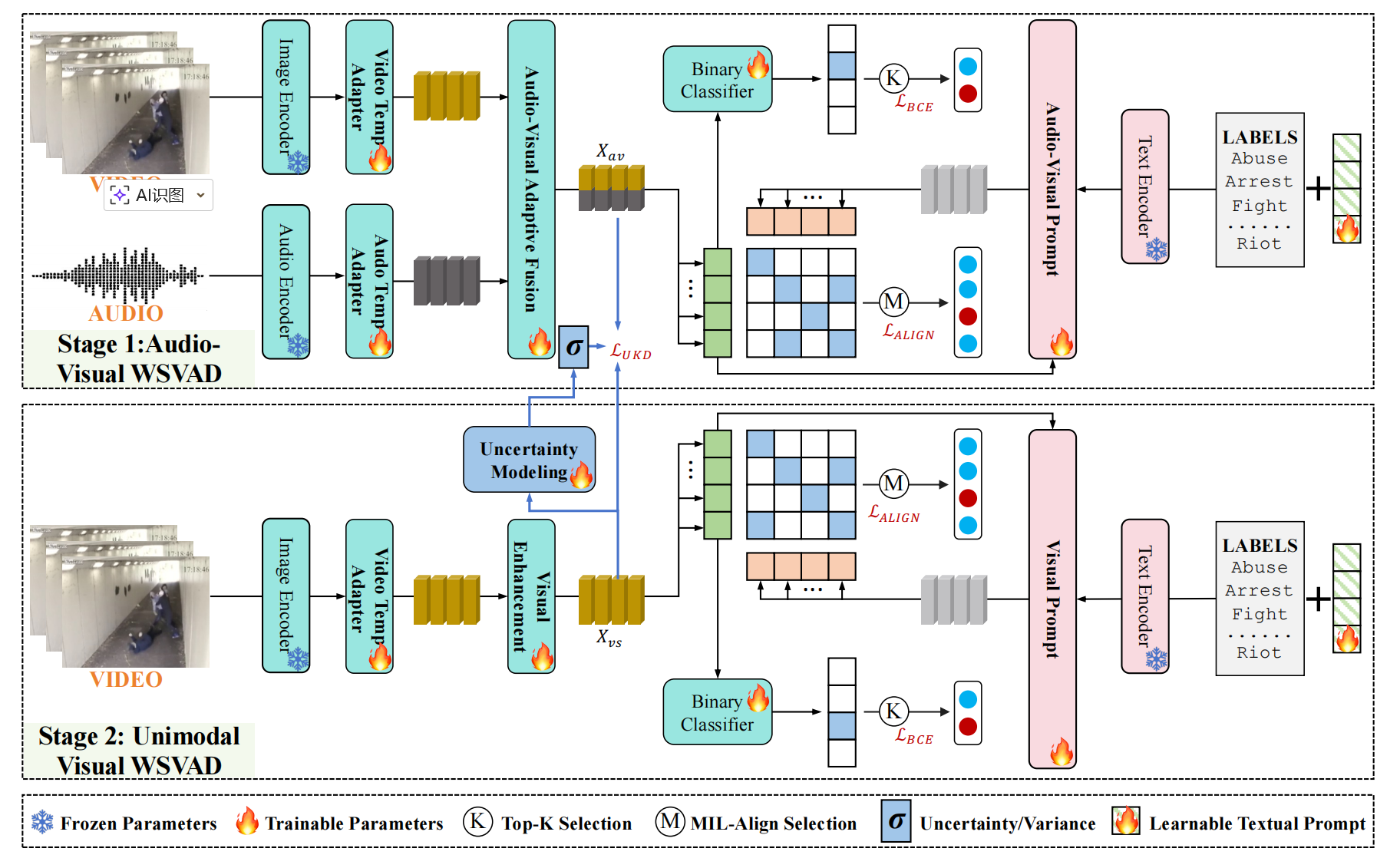
图2. 我们提出的AVadCLIP的流程图。我们的方法通过蒸馏支持多模态输入和仅视觉输入,通过提出的UKD策略实现鲁棒的视频异常检测。在整个框架中,预训练的CLIP主干保持完全冻结,只有少数模块是可训练的。这种设计允许将CLIP的知识高效、轻量地适应到音视频异常检测的特定任务中。
B. Video and Audio Encoders
视频编码器。利用CLIP强大的跨模态表示能力,我们将其图像编码器(ViT-B/16)用作视频编码器,这与C3D和I3D等传统模型形成对比,后者在捕捉语义关系方面效果较差。我们使用CLIP从采样的视频帧中提取特征,但为了解决CLIP在时间建模上的不足,我们引入了一个轻量级的时间模型,如图卷积网络(GCN)16和时间Transformer21,以捕捉时间依赖关系。这种方法确保了CLIP预训练知识能够有效地转移到WSVAD任务中。
音频编码器。对于音频特征提取,我们使用Wav2CLIP69,这是一个基于CLIP的模型,它将音频信号映射到与图像和文本相同的语义空间。音频首先被转换为频谱图,然后进行采样以匹配视频帧的数量。这些音频片段由Wav2CLIP处理以提取特征。为了捕捉上下文关系,我们应用了一个时间卷积层70,它对局部时间依赖关系进行建模,保留了音频模态内的关键动态。
C. Audio-Visual Adaptive Fusion
在多模态特征融合中,虽然视频和音频都包含有价值的语义信息,但它们的重要性往往因具体任务而异。受人类感知机制71的启发,我们的方法采用以视觉为中心、音频辅助的范式,其中视频特征作为主要模态,音频特征则补充和增强视觉信息。为了在保持原始CLIP模型在下游任务中的泛化能力的同时避免引入过多的可训练参数,我们设计了一种轻量级自适应融合机制,能够在不显著增加计算开销的情况下整合音频特征。我们在图3中展示了这种融合的结构。
具体来说,给定视频特征XvX^vXv和音频特征XaX^aXa,我们首先将它们连接起来获得联合表示Xa+v∈RN×2dX^{a+v} \in \mathbb{R}^{N \times 2d}Xa+v∈RN×2d,然后通过两个投影网络处理以生成自适应权重和残差特征。
第一个投影网络计算自适应融合权重WWW,该权重决定了音频在每个时间步的贡献72。这是通过线性变换后接sigmoid激活实现的:
W=Sigmoid(Linear(Xa+v))∈RN×d(1)W = \text{Sigmoid}(\text{Linear}(X^{a+v})) \in \mathbb{R}^{N \times d} \quad (1)W=Sigmoid(Linear(Xa+v))∈RN×d(1)
第二个投影网络负责残差映射,将Xa+vX^{a+v}Xa+v转换为残差特征XresX^{res}Xres,该特征编码了来自两个模态的融合信息:
Xres=Linear(GELU(Linear(Xa+v)))∈RN×d(2)X^{res} = \text{Linear}(\text{GELU}(\text{Linear}(X^{a+v}))) \in \mathbb{R}^{N \times d} \quad (2)Xres=Linear(GELU(Linear(Xa+v)))∈RN×d(2)
最后,通过自适应地将残差特征整合到原始视频特征中,得到融合表示XavX^{av}Xav:
Xav=Xv+W⊙Xres(3)X^{av} = X^v + W \odot X^{res} \quad (3)Xav=Xv+W⊙Xres(3)
其中⊙\odot⊙表示逐元素乘法。自适应权重WWW动态调整音频整合的程度,确保视频特征保持主导地位,而音频特征提供辅助信息。此外,残差映射通过捕捉非线性变换增强了融合表示的表达能力。通过引入自适应融合机制并保持轻量级设计,我们的融合方法有效地平衡了效率和表达能力,利用了视觉和音频模态的互补性,同时最小化了计算开销。
D. Dual Branch Framework with Prompts
我们采用一个双分支框架21来解决WSVAD任务,该框架由一个分类分支和一个对齐分支组成,能够有效利用音视频信息来提高检测准确性。分类分支包含一个轻量级二元分类器(如图3所示),该分类器以XavX^{av}Xav作为输入,直接预测帧级异常置信度AAA。对齐分支利用跨模态语义对齐机制,计算帧级特征与类别标签特征之间的相似度。为了获取类别标签表示,我们利用CLIP文本编码器,结合可学习的文本提示73和音视频提示来提取类别嵌入,确保视觉和文本模态之间的统一语义对齐。
给定一组预定义的类别标签(例如"正常"、"打架"),我们首先引入一个可学习的文本提示,然后将文本提示与类别标签连接,并将它们输入CLIP文本编码器以获得类别表示XcX^cXc。与手动定义的提示相比,可学习提示允许模型在训练过程中动态调整文本表示,使其更适合WSVAD的特定需求。此外,我们将音视频提示融入类别标签特征中,以额外的多模态信息丰富类别表示。
提出的音视频提示机制旨在动态地将实例级关键音视频信息注入文本标签以增强表示。具体来说,我们利用分类分支的异常置信度AAA和音视频特征XavX^{av}Xav生成视频级全局表示:
Xp=Norm(A⊤XavN)∈Rd(4)X^p = \text{Norm}\left(\frac{A^\top X^{av}}{N}\right) \in \mathbb{R}^d \quad (4)Xp=Norm(NA⊤Xav)∈Rd(4)
其中Norm表示归一化操作。接下来,我们计算类别表示XcX^cXc与全局表示XpX^pXp之间的相似度矩阵SpS^pSp,以衡量类别标签与视频之间的对齐程度:
Sp=Softmax(XcXp⊤)(5)S^p = \text{Softmax}(X^c {X^p}^\top) \quad (5)Sp=Softmax(XcXp⊤)(5)
基于SpS^pSp,我们生成增强的实例级音视频提示XmpX^{mp}Xmp:
Xmp=SpXav∈Rd(6)X^{mp} = S^p X^{av} \in \mathbb{R}^d \quad (6)Xmp=SpXav∈Rd(6)
这个操作通过计算全局音视频特征与类别标签之间的相似度,动态调整类别表示对不同视频实例的关注点,从而增强跨模态对齐。
然后,我们将XmpX^{mp}Xmp与类别表示XcX^cXc相加,经过前馈网络(FFN)变换和跳跃连接后,得到最终的实例特定类别嵌入XcpX^{cp}Xcp:
Xcp=FFN(ADD(Xmp,Xc))+Xc(7)X^{cp} = \text{FFN}(\text{ADD}(X^{mp}, X^c)) + X^c \quad (7)Xcp=FFN(ADD(Xmp,Xc))+Xc(7)
其中ADD表示逐元素相加。
这种双分支框架通过分类分支提供异常置信度,并通过带有类别信息的对齐分支细化类别识别,提高了鲁棒性并实现了细粒度的异常检测。
E. Optimization of Audio-Visual Model
对于分类分支,我们采用先前工作25中提出的Top-K机制,从正常和异常视频中分别选取前K个异常置信度值,并将其平均作为视频级别的预测。然后,我们使用预测结果与真实类别之间的二元交叉熵计算分类损失LBCEL_{BCE}LBCE。
对于对齐分支,应用MIL-Align机制21。我们计算一个对齐图MMM,反映帧级特征XavX^{av}Xav与所有类别嵌入XcpX^{cp}Xcp之间的相似度。对于MMM中的每一行,选择前K个相似度,并使用它们的平均值来量化视频与当前类别之间的对齐程度。这得到一个向量S={s1,...,sm}S = \{s_1, ..., s_m\}S={s1,...,sm},表示视频与所有可能类别之间的相似度。然后,多类预测计算如下:
pi=exp(si/τ)∑jexp(sj/τ)(8)p_i = \frac{\exp(s_i/\tau)}{\sum_j \exp(s_j/\tau)} \quad (8)pi=∑jexp(sj/τ)exp(si/τ)(8)
其中pip_ipi表示对第iii类的预测,τ\tauτ是温度缩放参数。然后,我们基于交叉熵计算LNCEL_{NCE}LNCE。此外,为了解决WSVAD中的类别不平衡问题(正常样本占主导,异常实例稀疏),我们采用focal loss74。最后,对齐分支的总损失LALIGNL_{ALIGN}LALIGN是LNCEL_{NCE}LNCE和LFOCALL_{FOCAL}LFOCAL的平均值。
F. Uncertainty-Driven Distillation
在WSVAD任务中,音频作为视频的补充模态,增强了检测准确性。然而,在实际场景中,音频可能不可用,导致性能下降。为了解决这个问题,我们应用知识蒸馏,使用预训练的多模态(视频+音频)教师模型来指导单模态(仅视频)学生模型,确保即使没有音频也能进行鲁棒的异常检测。传统的知识蒸馏方法通常假设知识是确定性转移的,采用均方误差(MSE)损失来使学生模型与教师模型的特征表示对齐。然而,这种方法未能考虑到音视频特征融合中固有的不确定性。在现实场景中,噪声音频或遮挡的视觉内容等因素可能在融合特征中引入失真,导致特征表示不准确和泛化能力下降。
为了克服这一点,我们提出了一种概率不确定性蒸馏策略75, 76,该策略在蒸馏过程中对数据不确定性进行建模,提高了学生模型在各种场景下的鲁棒性。具体来说,假设Xiav=Xivs+ϵσiX^{av}_i = X^{vs}_i + \epsilon\sigma_iXiav=Xivs+ϵσi,其中ϵ∼N(0,I)\epsilon \sim N(0, I)ϵ∼N(0,I),XvsX^{vs}Xvs表示学生模型生成的增强视觉特征,它是从XvX^vXv经过视觉增强网络(如图3所示)后得到的。此外,σi\sigma_iσi指的是第iii对特征之间的固有不确定性。然后,我们将观测建模为高斯似然函数,以更准确地量化特征蒸馏中的数据不确定性。音视频融合特征XiavX^{av}_iXiav与单模态特征XivsX^{vs}_iXivs之间的关系表述为:
p(Xiav∣Xivs,θ)=12πσi2exp(−∥Xiav−Xivs∥22σi2)(9)p(X^{av}_i|X^{vs}_i, \theta) = \frac{1}{\sqrt{2\pi\sigma_i^2}} \exp\left(-\frac{\|X^{av}_i - X^{vs}_i\|^2}{2\sigma_i^2}\right) \quad (9)p(Xiav∣Xivs,θ)=2πσi2 1exp(−2σi2∥Xiav−Xivs∥2)(9)
其中θ\thetaθ是模型的参数,为了最大化每对特征XiavX^{av}_iXiav和XivsX^{vs}_iXivs的似然,我们采用对数似然形式:
lnp(Xiav∣Xivs,θ)=−∥Xiav−Xivs∥22σi2−ln2πσi22(10)\ln p(X^{av}_i|X^{vs}_i, \theta) = -\frac{\|X^{av}_i - X^{vs}_i\|^2}{2\sigma_i^2} - \frac{\ln 2\pi\sigma_i^2}{2} \quad (10)lnp(Xiav∣Xivs,θ)=−2σi2∥Xiav−Xivs∥2−2ln2πσi2(10)
在实践中,我们设计一个网络分支(一个简单的三层卷积神经网络,如图3所示)来预测方差σi2\sigma_i^2σi2,并将似然最大化问题重新表述为损失函数的最小化。具体来说,我们采用不确定性加权的MSE损失:
LUKD=1L∑i=1L∥Xiav−Xivs∥2σi2+lnσi2(11)L_{UKD} = \frac{1}{L} \sum_{i=1}^{L} \left\\frac{\\\|X\^{av}_i - X\^{vs}_i\\\|\^2}{\\sigma_i\^2} + \\ln\\sigma_i\^2\\right \quad (11)LUKD=L1i=1∑Lσi2∥Xiav−Xivs∥2+lnσi2(11)
其中LLL表示特征对的数量,为了清晰起见,省略了常数项。
在蒸馏过程中,学生模型不仅从教师模型学习单模态特征XivsX^{vs}_iXivs,还考虑特征不确定性σi2\sigma_i^2σi2来优化其学习策略。具体来说,损失函数的第一项表示学生模型和教师模型之间的特征相似性,通过σi2\sigma_i^2σi2进行归一化。这为具有更高不确定性的特征分配较小的权重,从而避免对难以学习的信息过拟合。第二项作为正则化项,防止σi2\sigma_i^2σi2变得过小,确保有效的蒸馏。
最终,在推理阶段,我们只输入视频,并通过单模态学生模型进行异常检测,以应对音频缺失的场景。
IV. EXPERIMENTS
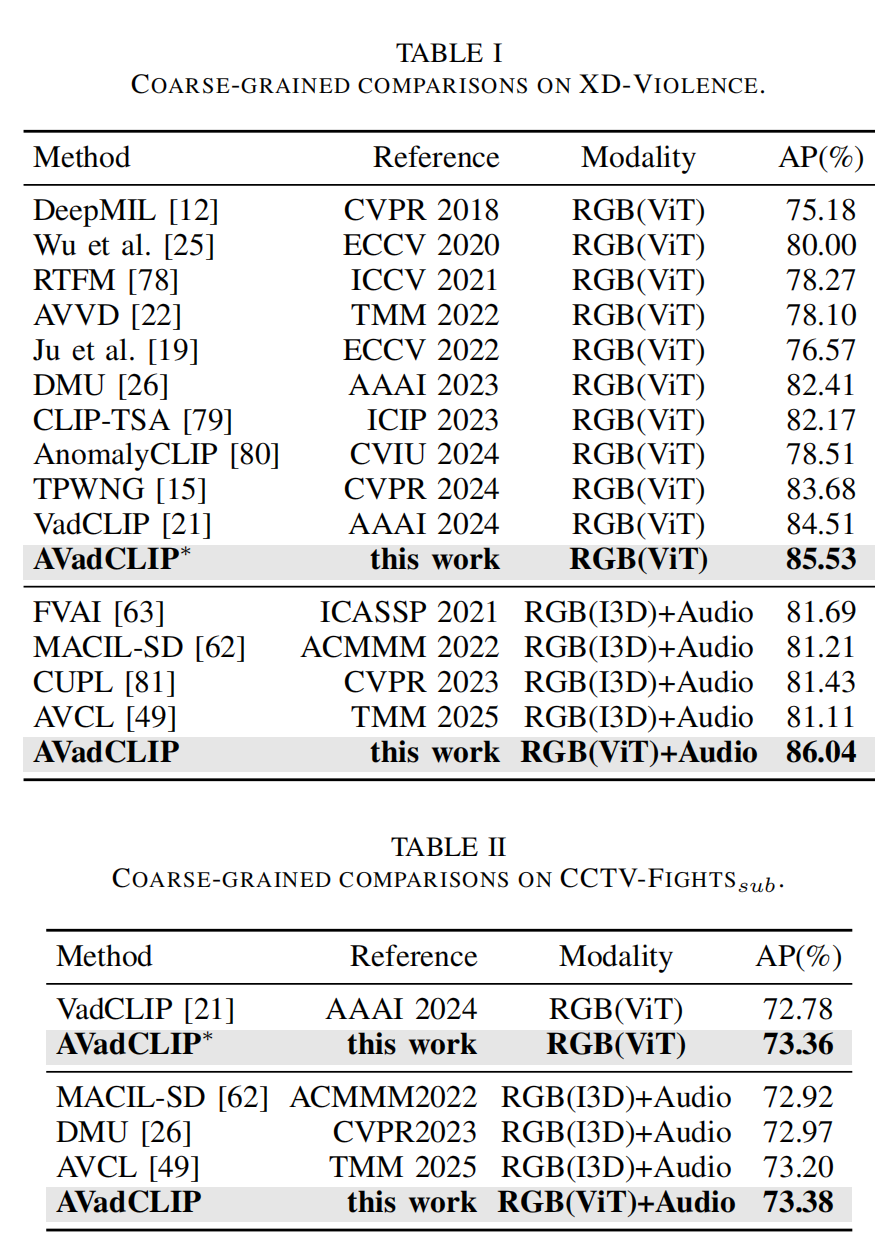
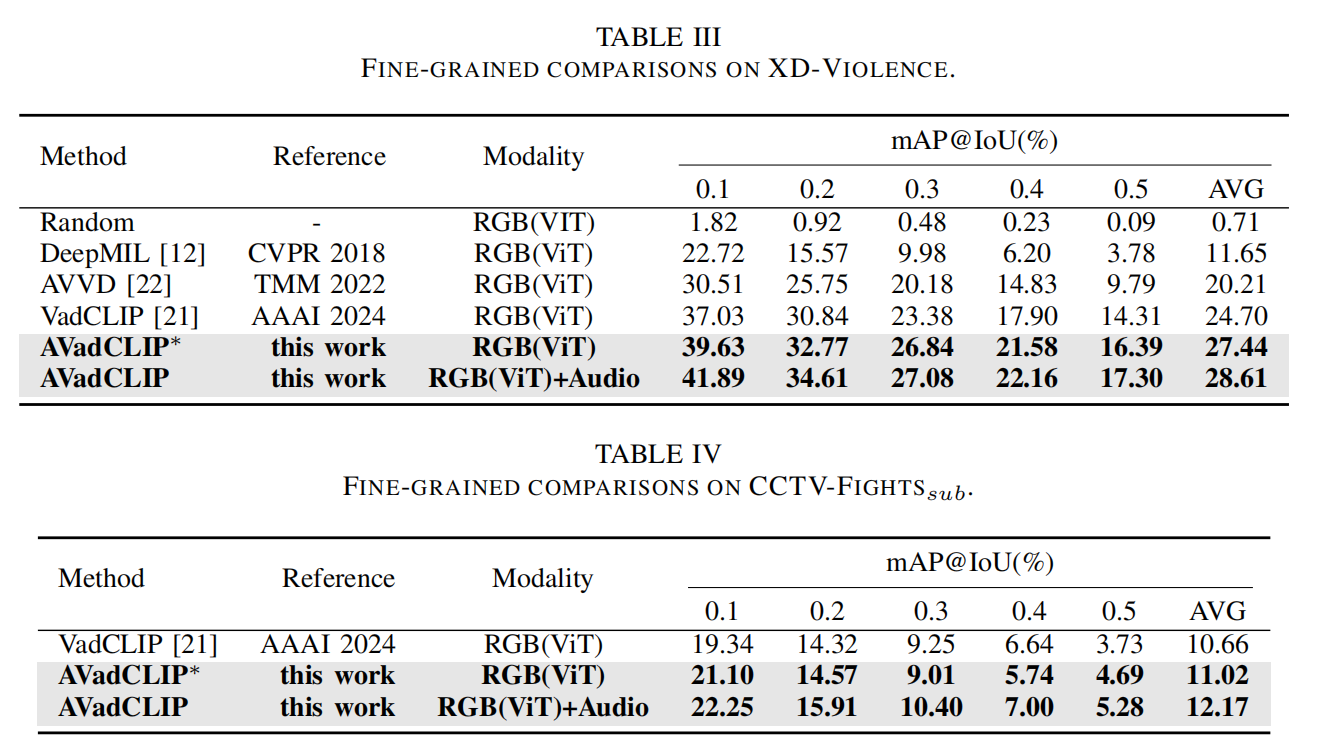
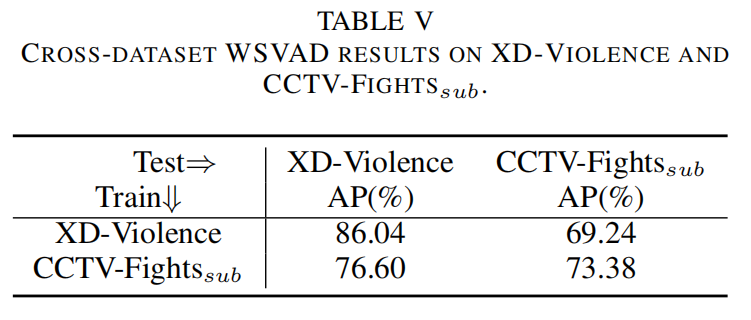
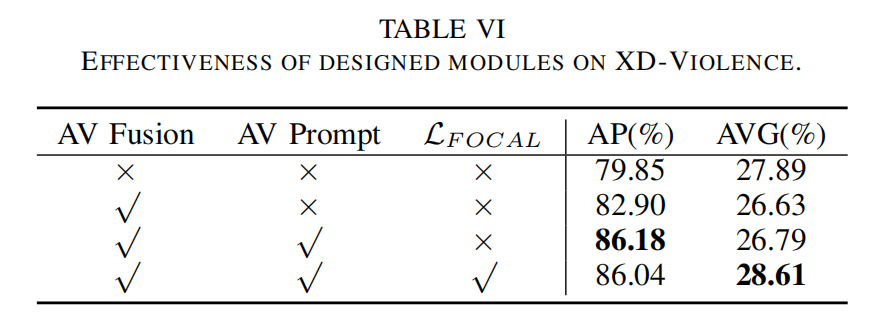
V. CONCLUSION
在这项工作中,我们提出了一种新颖的弱监督框架,利用音视频协作实现鲁棒的视频异常检测。利用CLIP强大的表示能力和跨模态对齐能力,我们在冻结的CLIP模型基础上设计了两个不同的模块,以实现高效的音视频协作和多模态异常检测。具体来说,为了无缝整合音视频信息,我们引入了一种轻量级融合机制,根据音频对辅助视觉信息的重要性自适应地生成融合权重。此外,我们提出了一种音视频提示策略,动态地用关键多模态特征细化文本嵌入,加强视频内容与相应文本标签之间的语义对齐。为了进一步增强在模态缺失场景中的鲁棒性,我们开发了一个不确定性驱动的蒸馏模块,从视觉输入中合成音视频表示,重点关注具有挑战性的特征。在两个基准测试上的实验结果表明,我们的框架有效地实现了视频-音频异常检测,并增强了模型在模态不完整场景中的鲁棒性。未来,我们将探索基于VLMs整合更多模态(如文本描述)以实现更鲁棒的视频异常检测。