TL;DR:我们需要一个新的框架、胶水层,来帮助我们适配生成式 AI 的输出,以及解决流式数据传输的问题。
在过去几个月里,我们一直在项目上探索:如何设计更好的架构,以将业务流程和开发流程中的各类智能体结合起来,进一步释放生成式 AI 的潜力?诸如于面向 IDE、DevOps、Team AI 等多个不同消费端的智能体。
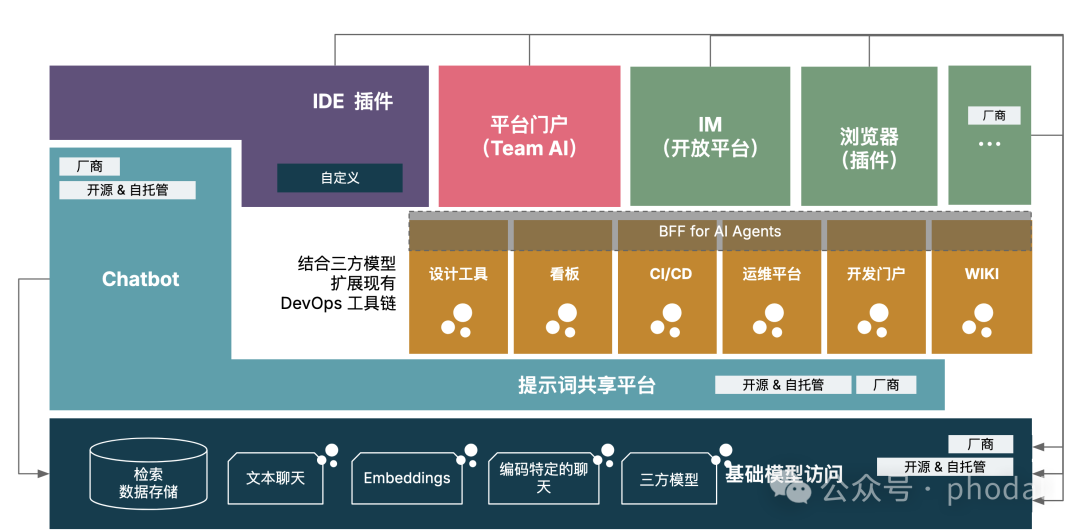
在这个过程中,浮现了一种新的架构模式:流式 BFF。
流式 BFF(Streaming Backend for Frontend) 是一种适用于 AI 原生架构的胶水层,旨在解决 HTTP API 与智能体协同过程中的数据流处理和接口不一致等问题。
引子 0:生成式 AI 时代的架构演进
在先前的文章里《LLM 优先的软件架构》里,我们介绍了四个原则:用户意图导向设计 、上下文感知、原子能力映射、语言 API。而那篇《语言接口:探索大模型优先架构的新一代 API 设计》中,我们介绍了 自然语言即 DSL、实时文本流 DSL、本地函数动态代理等模式。这些模式为我们开发 AI 原生应用带来了新的思路。
在过去构建 AI 辅助研发应用时,除了应用内置的各类编码智能体之外,我们的重点还放在云端智能体的集成上,旨在提升整体效率和智能化水平。这些智能体包含:
-
AI 平台智能体。如部署在类 Dify 平台上的智能体
-
三方智能体服务。即提供智能体功能的其它服务
-
系统内智能体。即可以通过函数调用的内部智能体
而由于生成式 AI 的输出方式:类似于打字机效果,字符逐字词输出。在这种限制了交互体验的场景下,主流的智能体提供的都是流式输出方式。这种流式传输的实现通常依赖于Server-Sent Events(SSE)技术,它允许服务端主动向客户端推送消息,建立长连接后,服务端可以源源不断地向客户端推送消息, 从而实现流式输出。
引子 1:降低 Streaming Hell 带来的影响

当客户端直接调用大模型时,通常只需发出一个简单的请求即可获取完整的响应。然而,当我们在服务端通过流式方式(例如 Server-Sent Events, SSE)处理数据时, 情况变得更加复杂。每当增加一层服务或代理时,流式数据处理的负担都会传递给下一层。这种层层累积的复杂性,我们称之为 Streaming Hell。
其带来的挑战有:持续连接的开销 、多层流式传递的传染效应 、资源管理的复杂性 、错误传播和恢复 等。要解决 Streaming Hell,我们需要采用一些策略:
-
流式处理标准化:定义统一的接口和协议,使各层服务能够一致高效地处理流式数据。
-
异步与事件驱动架构:采用异步或事件驱动架构,减少对同步流式处理的依赖,提高扩展性和响应速度。
-
减少层级依赖:尽量减少不必要的服务调用层次,避免每一层服务都直接处理流式数据。
-
流式数据聚合:在必要时对流式数据进行聚合和处理,以减少不必要的传递层次,优化系统性能。
-
错误处理与重试机制:设计健壮的错误处理和重试机制,确保当某一层服务出现错误时能够进行自动恢复或降级。
通过有效的设计,我们可以减少 Streaming Hell 带来的复杂性,并提高系统的可靠性和可维护性。
引子 2:智能体应用架构面临的新挑战

在业务系统集成这些智能体时,系统的架构需要随之演进,以适应流式输出的要求。例如,后端服务需要支持流式响应,前端应用则需要能够处理和展示这种渐进式的数据流。
挑战 1:统一多模型接口,简化数据传输与解析
在我们构建面向普通用户的开源应用,如 ClickPrompt、AutoDev 和 Shire 时,需要支持不同大语言模型的接口。由于用户可能选择不同的模型供应商, 这就要求我们能够兼容多种模型接口。在 AutoDev 时代,我们主要采用兼容 OpenAI 格式的接口,并且可以支持大量的自定义数据格式, 如采用 JsonPath 从 $.choices[0].message.delta.content 获取文本。
而在非公开 API 场景下,这种基于 JSON 格式的接口存在一些挑战:
-
解析耗时:JSON 格式需要在应用中进行解析,这会消耗额外的处理时间和资源。
-
数据传输量大:在某些场景下,我们只需要传输文本内容,而不需要整个 JSON 对象,这导致了不必要的数据传输。
所以在时,我们通常会考虑简化接口、统一接口格式、优化数据传输等方式来提升系统的性能和用户体验。
挑战 2:智能体接口不一致
相似的,当我们有 AI 平台等不同的智能体提供商时,由于不同的智能体通常有各自独特的接口规范,通常会导致接口与处理方式不一致。例如,在 Dify 平台中:
-
在 Completion 场景下,输出为
$.answer。 -
在 Workflow 场景下,输出为
$.data.outputs,且outputs本身也是一个对象。
这种接口的不一致性在多智能体协同工作时增加了前端处理的复杂度。而为了更好的兼容不同的智能体,通用的方式是引入一层映射机制,将不同智能体的输出统一为一致的文本格式。
挑战 3:与传统 API 服务的不同步
在 Web 2.0 时代,API 的响应速度至关重要。为了提高响应速度,我们采用了请求缓存、DNS 缓存以及 CDN 缓存等多种优化手段。然而,当前服务端使用的是 SSE(Server-Sent Events)技术,以逐字生成的方式传输数据,这与传统 API 的即时响应模式存在显著差异。
尽管 SSE 不是长连接,但仍需考虑其对服务器资源的消耗。此外,生成式 AI 本身的响应速度有限,这进一步影响了系统整体的响应时间。同时, 前端在处理流式数据时,需要更高的处理能力和更复杂的逻辑来管理和展示逐步生成的数据流。
流式 BFF:AI 原生架构下的协同模式

传统的 BFF 模式关注为特定的前端应用定制后端服务,以满足前端的特定需求。在 AI 原生应用中,由于生成式 AI 的特性以及多个智能体需要协同工作, 我们需要对 BFF 进行扩展,支持流式数据和实时处理。
定义流式 BFF
模式 :流式 BFF(Streaming Backend for Frontend) 是一种适用于 AI 原生架构的胶水层,旨在解决 HTTP API 与智能体协同过程中的数据流处理和接口不一致等问题。
意图:通过在胶水层,统一智能体接口,处理不同客户端的智能体协同,以简化系统的开发和使用。
适合场景:当且仅当系统中,存在不同的客户端,并且这些客户端需要与多个智能体协同工作时。
示例:在构建生成式 AI 辅助研发应用时,存在 IDE、DevOps 平台、IM 应用、团队 AI 入口等多个客户端,多个客户端之间需要部分相同、但是又有所 不同的智能体。
通常来说,流式 BFF 的核心特性包括:
-
统一接口:封装并标准化不同智能体的接口,提供一致的数据格式,简化前端开发。
-
流式处理:支持实时数据流,能够处理生成式 AI 逐步产生的数据,实现边生成边传输,提升用户体验。
-
实时过滤:在数据流中实时检测和过滤敏感信息,保障系统安全和合规性。
-
协调传统 API:与传统的 API 服务高效协同,解决响应速度和数据同步问题。
当然,随着我们对流式 BFF 的进一步探索,我们相信流式 BFF 还有更多的潜力等待挖掘。
我们需要怎样的流式 BFF?
尽管,当前我们初步思考了流式 BFF 的一种可能性,然而如何去构建这样的工具,依旧是一个未知的领域,还需要进一步的沉淀和探索。我们的早先版本是基于 Vercel 的 AI.js SDK 配合 Next.js 来构建的原型,由于 AI.js 提供了非常好的流式接口支持,与此同时,JavaScript/TypeScript 灵活的 any 特性 也使得我们能够快速地构建出一个流式 BFF。
协调不一致性
BFF 的本质在于协调前端与后端的交互,尤其是在面对复杂服务生态时,BFF 已经很好地解决了与传统 API 的一致性问题。它通过提供一层抽象, 统一了多个后端服务的调用方式。在实时处理场景下,我们更需要关注如何提供外部或第三方服务的接口,而不是构建全新的架构。因此,流式 BFF 的核心问题应该聚焦于如何在接口层面上实现统一,同时通过流式处理确保实时数据传输的稳定性和高效性。
内建主流大模型的支持
得益于 Vercel 的 AI SDK,我们能够轻松地为 BFF 内建对主流大模型的支持。Vercel 的 AI SDK 针对多个大模型(如 OpenAI、Anthropic、LlamaIndex 等) 进行了适配,提供了流式接口,使得我们能够无缝地集成不同的 AI 模型,并通过统一的流式处理机制来响应这些模型的数据。
一个典型的流式模型处理模式如下:
go
export function toDataStream(
stream: AsyncIterable<EngineResponse>,
callbacks?: AIStreamCallbacksAndOptions,
) {
return toReadableStream(stream)
.pipeThrough(createCallbacksTransformer(callbacks))
.pipeThrough(createStreamDataTransformer());
}在这种设计模式下,我们可以轻松处理来自不同模型的流式响应,确保数据传输的连贯性和一致性。
动态的流式接口转换
在处理生成式 AI API 的流式数据时,通常我们会接收到以下几类数据:
-
event,如 ping 等事件。 -
data:JSON 数据。 -
结束标志,如
[DONE]、tts_message_end或message_end。
在实际应用中,通过 JSONPath 或类似的工具,流式 BFF 可以根据不同 API 的返回内容动态调整数据处理方式,确保每个流式响应能够快速转换为前端可用的格式。
我们需要考虑在流式 BFF 中引入这种动态接口转换机制,以应对不同智能体的流式响应。
总结
生成式 AI 原生架构要求我们重新审视传统后端模式。流式 BFF 为智能体接口不一致、与传统 API 不同步等问题提供了有效的解决方案。通过统一接口、 流式处理、实时过滤及 API 协同,流式 BFF 能提升系统的可靠性和响应速度。