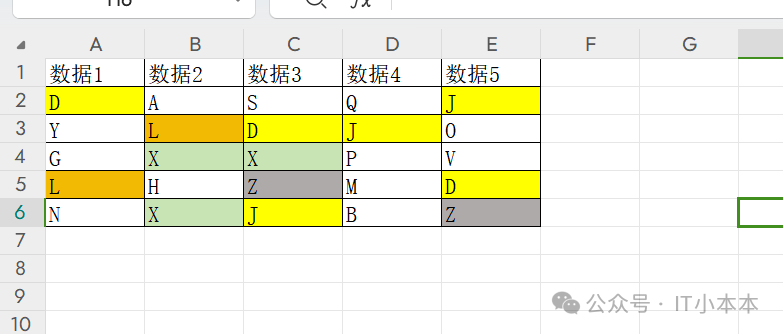
数据样例:👇
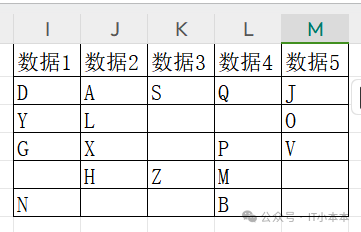
最终想要的结果:
一、解决办法
思路:处理逐个元素检查是否已经出现过,重复的元素用空字符串替换。
python
# 原始数据
data = [
['数据1', '数据2', '数据3', '数据4', '数据5'],
['D', 'A', 'S', 'Q', 'J'],
['Y', 'L', 'D', 'J', 'O'],
['G', 'X', 'X', 'P', 'V'],
['L', 'H', 'Z', 'M', 'D'],
['N', 'X', 'J', 'B', 'Z']
]
# 创建一个集合来存储已经出现过的值
seen = set()
# 处理数据
result = [data[0]] # 保留表头
for row in data[1:]:
new_row = []
for item in row:
if item not in seen:
new_row.append(item)
seen.add(item)
else:
new_row.append('')
result.append(new_row)
# 打印结果
for row in result:
print('\t'.join(row))
但在现实生活中我们可能都是直接读取excel,来获取数据,它的写法为:
python
import pandas as pd
# 读取 Excel 文件中的数据
file_path = '公式练习题原地去重.xlsx' # 设置要读取的 Excel 文件路径
df = pd.read_excel(file_path)
# 将数据转换为列表形式
data = df.values.tolist()
# 创建一个集合来存储已经出现过的值
seen = set()
# 处理数据
result = [df.columns.tolist()] # 保留表头,将列名转换为列表并放入结果列表中
for row in data:
new_row = []
for item in row:
if item not in seen:
# 如果当前元素不在已出现的集合中,将其添加到新行列表,并将其加入集合
new_row.append(item)
seen.add(item)
else:
# 如果当前元素已出现过,在新行列表中添加空字符串
new_row.append('')
result.append(new_row)
# 将结果转换回 DataFrame 并保存为新的 Excel 文件
result_df = pd.DataFrame(result[1:], columns=result[0])
result_df.to_excel('processed_output.xlsx', index=False)
# 打印结果(可选)
for row in result:
print('\t'.join([str(i) for i in row]))