本文为您介绍如何在开发者本地环境中运行和调试包含阿里云实时计算Flink版连接器的作业,以便快速验证代码的正确性,快速定位和解决问题,并节省云上成本。
背景信息
当您在IntelliJ IDEA中运行和调试Flink作业,如果其包含了阿里云实时计算Flink版的商业版连接器依赖,可能会遇到无法找到连接器相关类的运行错误。例如,运行含有大数据计算服务MaxCompute连接器的作业时出现如下异常:
Caused by: java.lang.ClassNotFoundException: com.alibaba.ververica.connectors.odps.newsource.split.OdpsSourceSplitSerializer
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)该异常是由于连接器默认JAR包中缺少部分运行类,您可以通过执行下列步骤来添加这些缺失的类,从而能够在IntelliJ IDEA中运行或调试作业。
步骤一:添加作业配置中的依赖
首先从Maven中央仓库下载包含运行类的uber JAR包。例如对于大数据计算服务MaxCompute使用的依赖ververica-connector-odps,以1.17-vvr-8.0.4-1版本为例,可以在Maven仓库对应目录下看到后缀为uber.jar的ververica-connector-odps-1.17-vvr-8.0.4-1-uber.jar,将其下载到本地目录。
其次在代码中创建环境时增加配置pipeline.classpaths为uber jar路径,若有多个连接器依赖,使用分号隔开,例如file:///path/to/a-uber.jar;file:///path/to/b-uber.jar(对于Windows需要加相应磁盘分区,例如file:///D:/path/to/a-uber.jar;file:///E:/path/to/b-uber.jar)。DataStream API作业通过如下代码配置:
Configuration conf = new Configuration();
conf.setString("pipeline.classpaths", "file://" + "uber jar绝对路径");
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(conf);Table API作业通过如下代码进行配置:
Configuration conf = new Configuration();
conf.setString("pipeline.classpaths", "file://" + "uber jar绝对路径");
EnvironmentSettings envSettings =
EnvironmentSettings.newInstance().withConfiguration(conf).build();
TableEnvironment tEnv = TableEnvironment.create(envSettings);重要
该新增的pipeline.classpaths配置需要在作业打包上传到阿里云实时计算Flink版之前删除。
步骤二:配置运行所需要的ClassLoader JAR包
为了使Flink能够加载连接器的运行类,还需添加ClassLoader JAR包。首先下载ververica-classloader-1.15-vvr-6.0-SNAPSHOT.jar至本地。
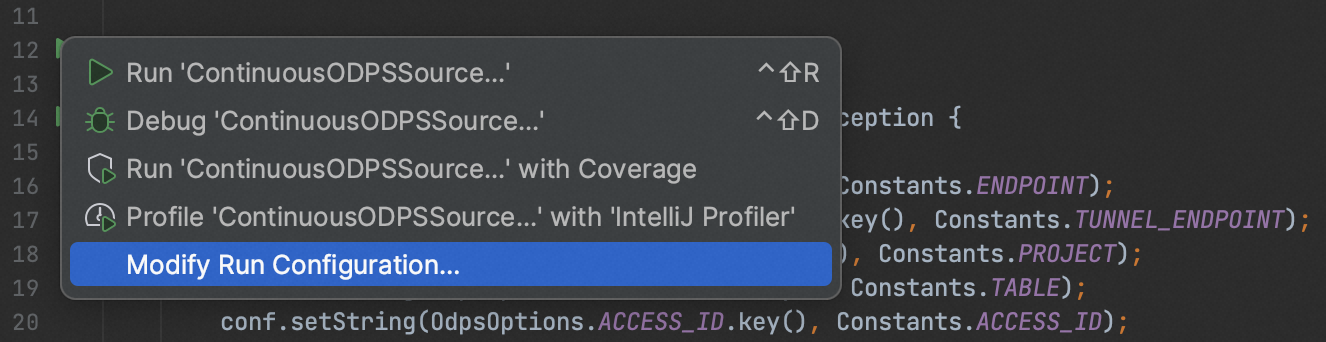
以Inteillij IDEA为例,对作业的本地运行配置进行修改。点击入口类左侧的绿色图标展开菜单栏,并选择"修改运行配置":
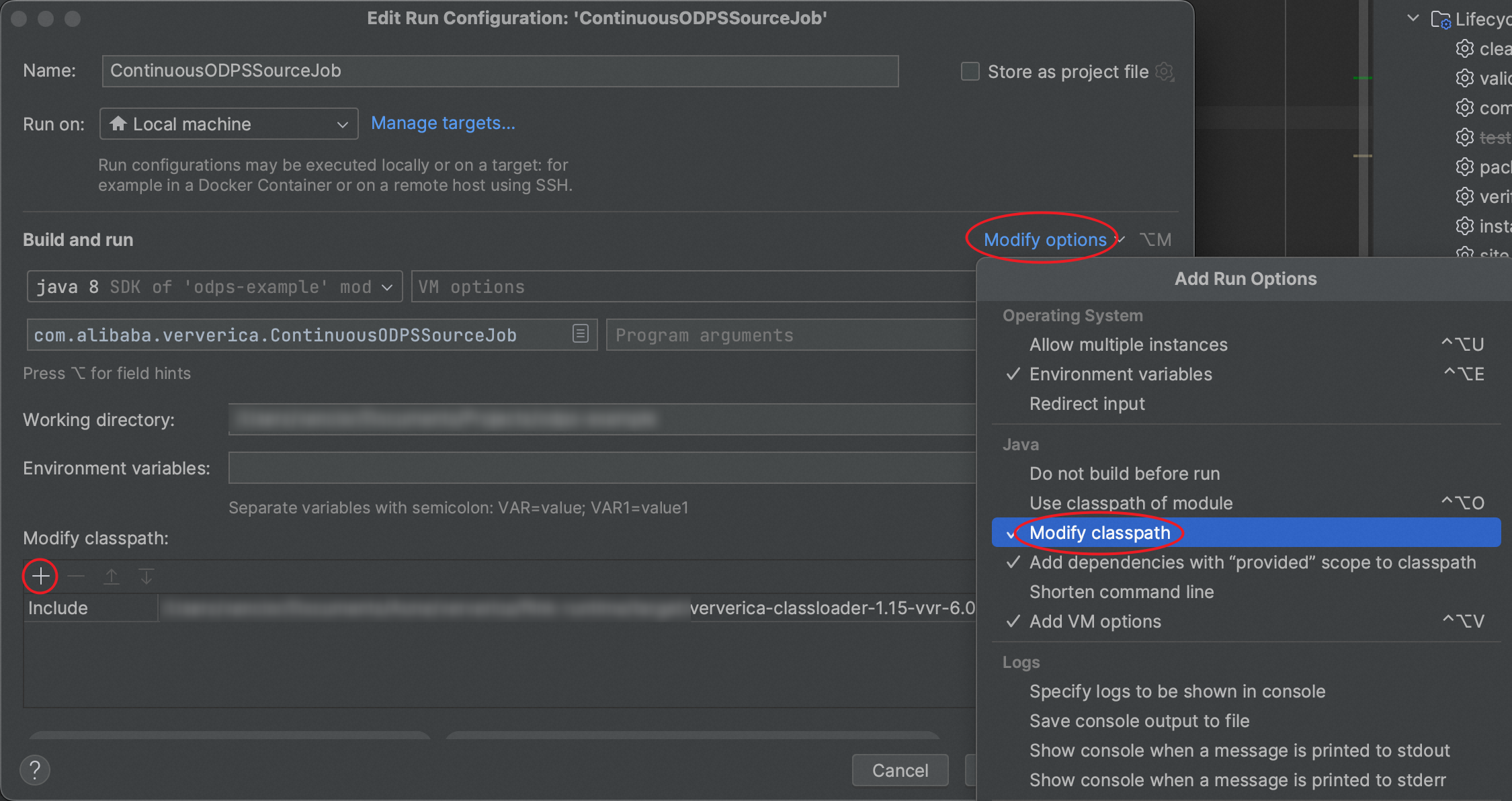
在打开的运行配置窗口中,点击"Modify options",勾选"Modify classpath",在窗口下方会增加"Modify classpath"一栏,点击"+"号选择上文下载的ClassLoader JAR包,并保存该运行配置。
步骤三:运行或调试
在IntelliJ IDEA界面右上角的运行面板中,切换到刚才保存的运行配置,即可进行本地运行或调试。
如果提示缺少一些常见的Flink类无法执行,例如org.apache.flink.configuration.Configuration,需要在"Modify options"处勾选"Add dependencies with provided scope to classpath"。