第三章:超越基础------图像中的特征检测

上一篇《揭开计算机视觉的神秘面纱,原来机器是这样"看图"的!》
**本篇序言:**上一篇我们实现并训练了一个神经网络,成功让计算机"看懂"了图像。可以说,我们已经一只脚跨进了AI研发的大门。不过,虽然我们迈入了AI这个神秘的领域,实际上,我们还只是站在门槛边缘。这里面有太多复杂的东西,连2024年AI领域的诺贝尔人工智能奖得主都无法完全搞明白,因为神经网络实在太复杂了,一个人的能力根本无法解析它所学到的知识。今天这一篇,大家只需要记住两个关键概念:"卷积"和"池化"。"卷积"是神经网络自己用来从图片中抽取关键信息的一种方法,而"池化"则是人类为了减小计算量和降低硬件负担,专门设计来进一步缩小"卷积"处理后图像的大小。只要弄懂这两个概念,后面的一切就会清晰许多。
(点击关注作者,及时获取人工智能领域的核心知识更新。本文作者拥有长达8年的人工智能实际经验,能为您带来平时学不到的独特知识。)
在上一篇中,我们通过创建一个简单的神经网络,利用Fashion MNIST数据集的输入像素将图像与10个标签匹配,每个标签代表一种类型(或类别)的衣物。虽然 我们创建的网络在识别衣物类型方面做得不错,但还是有一个明显的不足。
我们的神经网络是在一些小的单色图像上进行训练的,每张图像中只包含一件衣物,并且那件衣物都位于图像中心。如果要进一步提升模型的能力,我们需要让它学会检测图像中的特征。比如,不再只是看图像中的原始像素,而是想办法把图像分解成它的基本元素。与其匹配原始像素,匹配这些元素会帮助我们更有效地识别图像中的内容。
回想一下我们在上一篇用到的Fashion MNIST数据集------在识别鞋子时,神经网络可能是因为看到图像底部聚集的许多深色像素,才判断那是鞋底的。但是,如果鞋子不再居中,或没有填满整个画面,这种逻辑就不适用了。
其中一种用来检测图像特征的方法,源自摄影和图像处理。如果你曾用过Photoshop或GIMP这样的工具来锐化图片,你实际上是在使用一种对图像像素进行操作的数学滤波器。这种滤波器的另一个叫法就是"卷积",而当你将这些卷积应用于神经网络时,就得到了大名鼎鼎的卷积神经网络(CNN)了。
在这一篇中,我们将学习如何使用卷积来检测图像中的特征,然后更深入地研究如何基于这些特征进行图像分类。我们还会探索通过图像增强来提取更多特征,使用迁移学习借鉴其他人训练好的特征,最后简单看看如何用"dropout"技术来优化你的模型。
卷积
简单来说,卷积就是一个权重滤波器,它会把一个像素与其周围的像素进行运算,得到一个新的像素值。举个例子,回想Fashion MNIST中的那张踝靴图像,看看图像中像素的数值变化,如图3-1所示。
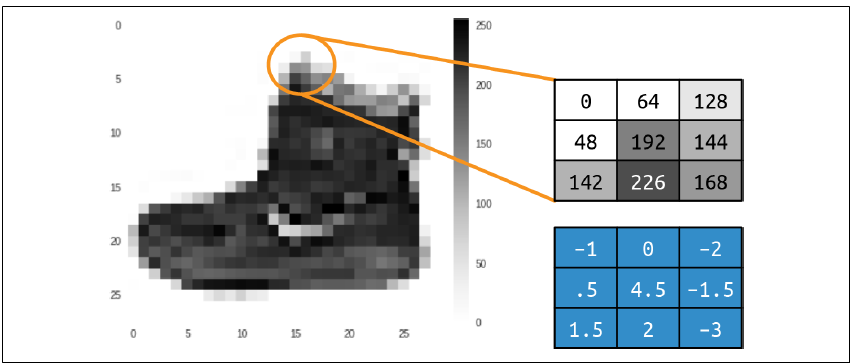
图3-1:带卷积处理的踝靴图像假设我们现在看的是一个图像中间的像素,它的值是192(记住Fashion MNIST的数据集是单色图像,像素值范围从0到255)。中间这个像素上面的像素值是0,左上角的是64,依此类推。
接着,我们定义一个3×3的滤波器,如下面展示的那样,滤波器的每个格子都有一个对应的值。我们要做的就是,把选中的像素和它周围的像素值分别乘以对应的滤波器值,然后把结果加起来,这个新的总和就是我们要替换的像素值。这个步骤会重复到图像中的每一个像素。
比如,当前像素的值是192,用滤波器处理后,新的像素值会是:
new_val = (-1 * 0) + (0 * 64) + (-2 * 128) +
(.5 * 48) + (4.5 * 192) + (-1.5 * 144) +
(1.5 * 142) + (2 * 226) + (-3 * 168)
结果是577,这就是新的像素值。用这个方法处理整张图像后,我们就得到了一个经过滤波器处理的图像。
接下来我们看看如果对一个更复杂的图像应用这个滤波器会有什么效果,比如SciPy自带的那个两个人爬楼梯的512×512的灰度图。用左边负值、右边正值的滤波器处理后,图像中大部分信息都会被移除,只有垂直线条保留下来。你可以看到图3-2的结果。
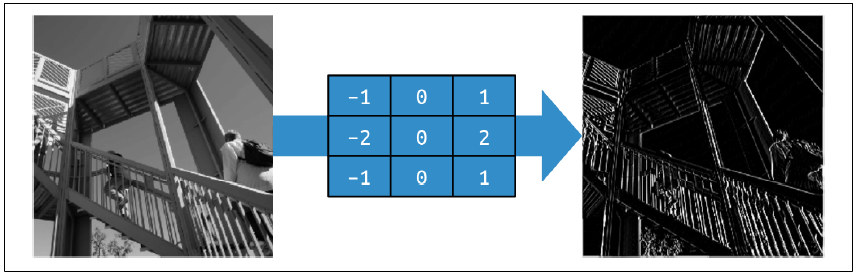
图3-2:使用滤波器提取垂直线条
类似地,如果稍微调整滤波器,能突出图像中的水平线条,如图3-3所示。
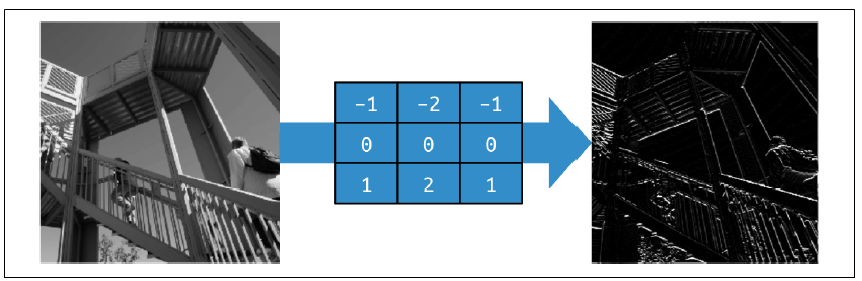
图3-3:使用滤波器提取水平线条这些例子告诉我们,使用滤波器不仅能提取出图像中的特征,还能减少图像中的冗余信息。随着时间的推移,我们可以学习到更适合匹配输入输出的滤波器。
池化(Pooling)
池化就是在保留图像内容的语义信息的同时,去掉一些像素。这个过程更容易通过视觉示例来理解。图3-4展示了最大池化的概念。
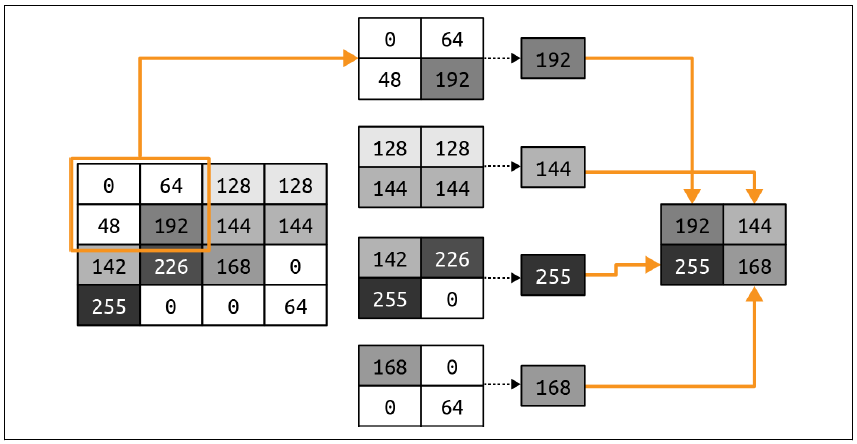
图3-4:展示最大池化
在这个例子里,左边的框代表单色图像中的像素。我们把这些像素分成2×2的小块,也就是把16个像素分成了四个2×2的小数组,称为"池"。然后,我们从每个小块里挑出最大值,再把这些最大值组合成一张新的图像。这样,左边的像素数量就减少了75%(从16个像素减少到4个),新图像由每个池的最大值构成。
图3-5展示了在应用最大池化后,图3-2中的Ascent图像,垂直线条得到了增强。

图3-5:经过垂直滤波和最大池化处理的Ascent图像
注意,经过滤波器处理的特征不仅得到了保留,而且还得到了进一步增强。另外,图像的尺寸从512×512缩小到了256×256,只有原来的四分之一大小。
此外,还有其他的池化方法,比如最小池化,它选择每个池中的最小像素值;还有平均池化,它取每个池的像素平均值。
本篇最讲了机器学习中的两个重要的概念:卷积和池化,下一篇我们将实现一个卷积神经网络以及探索它各层的功能。