K8S如何基于Istio重新实现微服务
- [认识 Istio](#认识 Istio)
- [Istio 实践](#Istio 实践)
- [使用 Istio 代理运行应用](#使用 Istio 代理运行应用)
- 跨服务跟踪和流量管理
-
- 内置的特性
- 流量管理
-
- [A/B 测试------Destination Rule 实践](#A/B 测试——Destination Rule 实践)
- DestinationRules
- [Shadowing---------Virtual Services 服务实践](#Shadowing———Virtual Services 服务实践)
- 认证和授权
-
- 断路器和舱壁模式
- [Istio 中的认证和授权](#Istio 中的认证和授权)
-
- [使用 Auth0 进行认证](#使用 Auth0 进行认证)
- [使用 Auth0 认证请求](#使用 Auth0 认证请求)
- [使用 Auth0 进行授权](#使用 Auth0 进行授权)
-
- [安装和配置 Auth0 授权](#安装和配置 Auth0 授权)
-
- [1. 创建Group](#1. 创建Group)
- [2. 添加 Group Claim 到 Access Token](#2. 添加 Group Claim 到 Access Token)
- [3. 在 Istio 中配置授权](#3. 在 Istio 中配置授权)
- [4. 配置常规的用户访问](#4. 配置常规的用户访问)
- [5. 配置 Moderator 用户访问](#5. 配置 Moderator 用户访问)
- 结论
- 参考链接
认识 Istio
前言
从单体架构迁移到基于微服务的应用时,会带来很多的挑战:
流量管理(Traffic management):超时、重试、负载均衡;
安全性(Security):终端用户的认证和授权;
可观察性(Observability):跟踪、监控和日志。
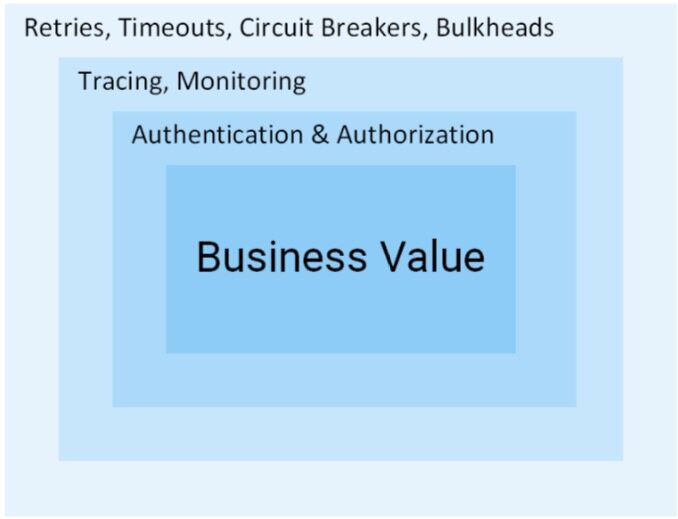
这些问题都可以在应用层解决,但不符合微服务的初衷,针对每个服务,所有的过程和努力必须都要再来一遍,每实现这些功能都会对公司的资源带来一定的压力。而且对我们来说,添加一个服务是一项巨大的任务。
Istio 的理念
Istio 是一个开源项目,由来自 Google、IBM 和 Lyft 团队协作开发,它为一组特定的问题提供了解决方案。
在没有 Istio 的时候,某个服务会直接发起对另一个服务的访问,如果出现失败,这个服务需要作出的处理包括重试、超时以及熔断等等。
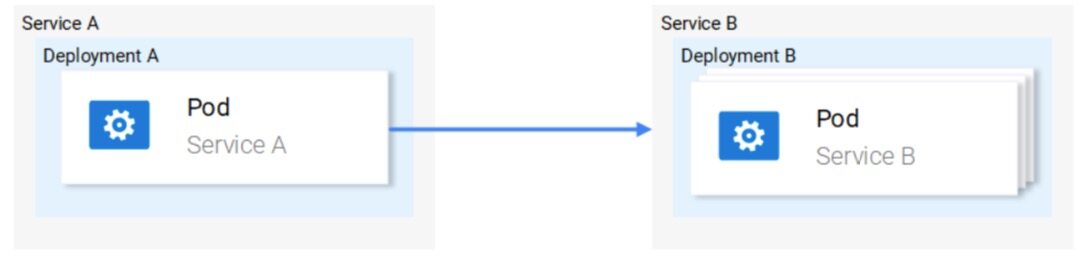
Istio 提供了一个非常巧妙的方案,它能够从服务中完全分离出来,通过只拦截所有的网络通信来发挥作用。能够实现如下功能:
容错:当请求失败和重试的时候,使用它能够理解的响应状态码;
金丝雀发布:只将特定百分比的请求转发到服务的新版本上;
监控和指标:统计服务响应所耗费的时间;
跟踪和可观察性:它在每个请求上添加了一个特殊的头部信息,并在集群中跟踪它们;
安全性:抽取 JWT Token 并对用户进行认证和授权。
Istio 的架构
Istio 会拦截所有的网络流量,并且会在每个 pod 上以 sidecar 的形式注入一个智能代理 ,从而能够应用一组特定的规则。让所有特性生效的代理是由**数据平面(Data Plane)组成的,而数据平面是由控制平面(Control Plane)**动态配置的。
数据平面
注入的代理能够让 Istio 很容易地满足我们的需求
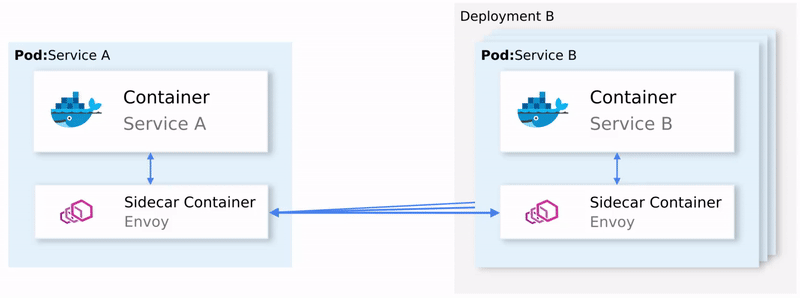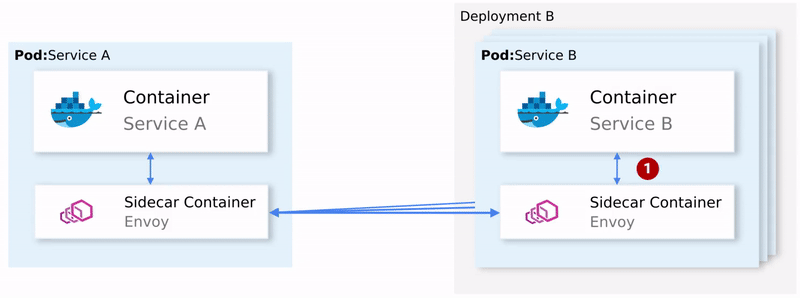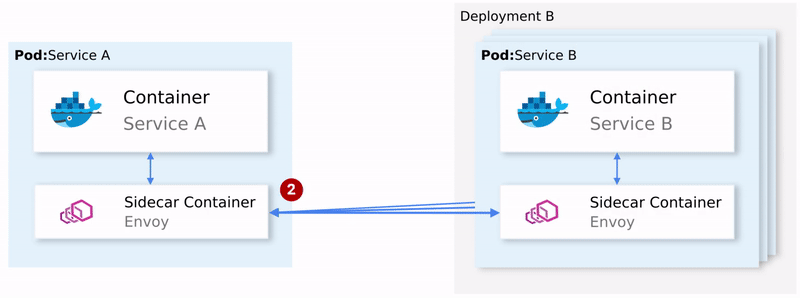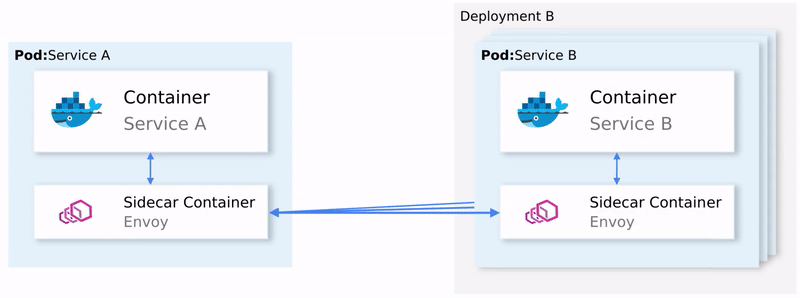
简单总结一下:
Envoy(数据平面) 发送请求给服务 B 的第一个实例,不过调用失败了;
Envoy Sidecar 会进行重试;(1)
失败的请求返回发起调用的代理;
开启断路器并在随后的请求中调用下一个服务。(2)
这意味着我们不需要使用额外的重试库,也不需要使用各种各样的语言实现断路器和服务发现功能。这些特性都是由 Istio 所提供的,我们不需要任何的代码修改。
它是一个适用于所有场景的解决方案吗?通常来讲,适用所有场景意味着难以非常好地适用任何场景。
控制平面
控制平面由三个组件组成:Pilot、Mixer 和 Citadel,它们组合配置 Envoy 以便于路由流量、执行策略和收集遥测数据。
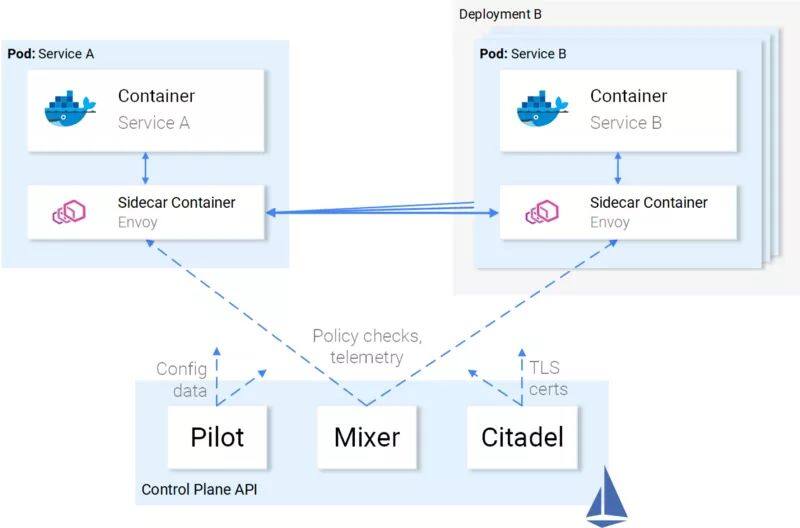
Envoy(也就是数据平面)会由 Istio 规定的Kubernetes自定义资源定义(Kubernetes Custom Resource Definition)来进行配置,这些定义是专门为了实现该目的的。这就是说,对你而言,它只是具有熟悉语法的 Kubernetes 资源而已。在创建之后,控制平面会获取到它,并将其用到 Envoy 上。
服务与 Istio 的关系
服务(Service)是 Kubernetes 中基础的网络抽象,而 Istio 作为服务网格,增强了服务的流量管理、安全、监控等能力,使得微服务架构更加可靠和可管理。
我们可以选取一个可运行的集群,在安装 Istio 组件之后,集群中的服务依然能够继续运行,我们可以按照相同的方式将组件移除掉,所有的事情都能正常运行,只不多我们失去了 Istio 所提供的功能而已。
Istio 实践
环境准备
我们需要搭建一个至少 4 vCPU 和 8 GB RAM 的集群。本文已经在如下的 Kubernetes 实现中测试通过:
Azure Kubernetes Service (AKS)
Digital Ocean (20天免费的Kubernetes链接)
创建完集群并使用 Kubernetes 命令行配置完访问权限后,我们就可以使用 Helm 包管理器安装 Istio 了。
安装 Helm
按照官方文档的描述在你的机器上安装 Helm 客户端。在下一节中,我们将会使用它来生成 Istio 安装模板。
安装Istio
从最新的发布版本下载 Istio 的资源,将其抽取到一个目录中,我们会将其称为istio-resources。
为了更容易地识别 Istio 资源,我们在 Kubernetes 集群中创建命名空间istio-system:
sh
$ kubectl create namespace istio-system切换至istio-resources并执行如下命令完成安装:
sh
$ helm template install/kubernetes/helm/istio \
--set global.mtls.enabled=false \
--set tracing.enabled=true \
--set kiali.enabled=true \
--set grafana.enabled=true \
--namespace istio-system > istio.yaml上述的命令会将 Istio 的核心组件打印到istio.yaml文件中。我们使用如下的参数对模板进行自定义:
global.mtls.enabled:将这个值设置为 false,保证我们这篇介绍文章能够只关注重点;
tracing.enabled:启用 jaeger 的请求跟踪功能;
kiali.enabled:在我们的集群中安装 Kiali,实现服务和流量的可视化;
grafana.enabled:安装 Grafana,实现收集指标的可视化。
注意:从 Istio 1.5 版本开始,global.mtls.enabled 被弃用,Istio 引入了更为灵活和细粒度的 mTLS 控制机制,使用 PeerAuthentication 和 DestinationRule 来配置不同命名空间或服务的 mTLS 策略。通过这些新机制,用户可以更好地控制某些服务或命名空间的加密策略,而不是全局统一开启或关闭。
创建istio资源
sh
kubectl apply -f istio.yaml执行如下的命令,然后等待istio- system命名空间中的所有 pod 均处于 Running 或 Completed 状态:
sh
kubectl get pods -n istio-system使用 Istio 代理运行应用
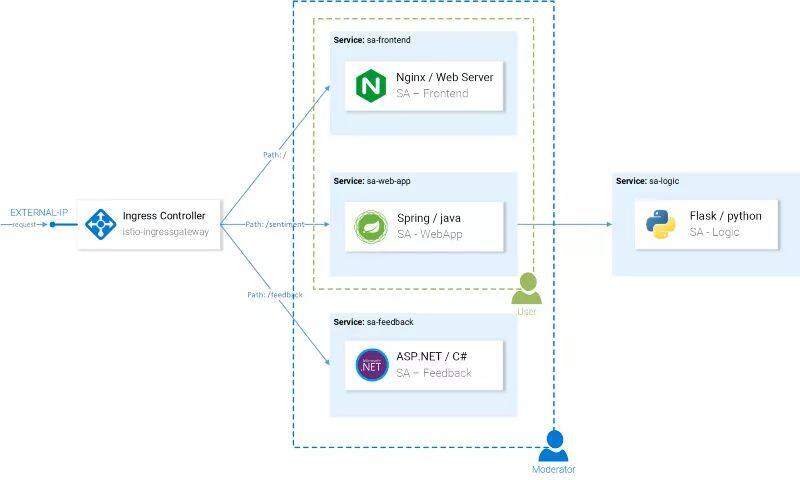
情感分析应用的架构
继续使用Kubernetes入门文章中的样例,它较为复杂,足以通过实践展示 Istio 的特性
这个应用由四个微服务组成:
SA-Frontend 服务:前端的 Reactjs 应用;
SA-WebApp 服务:处理情感分析的请求;
SA-Logic 服务:执行情感分析;
SA-Feedback 服务:接收用户关于分析精确性的反馈。
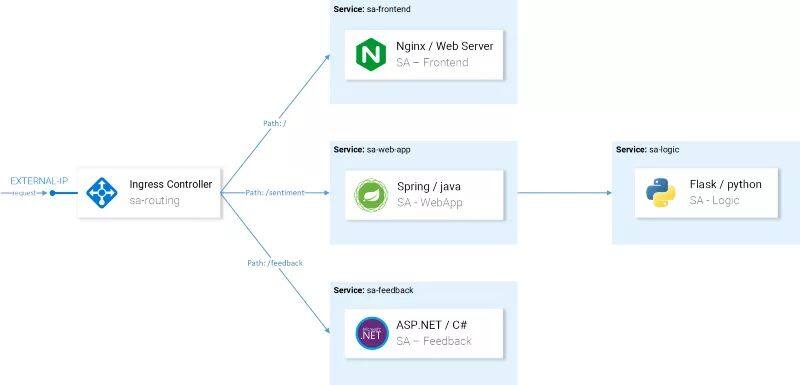
除了服务之外,我们还看到了 Ingress Controller,在 Kubernetes 中,它会将传入的请求路由至对应的服务,Istio 采用了类似的概念,名为 Ingress Gateway,在本文后续的内容中,我们将会对其进行介绍。
使用 Istio 代理运行应用
如果要要跟着本文一起练习的话,读者可以 clone 该 GitHub 仓库 istio-mastery,其中包含了适用于 Kubernetes 和 Istio 的应用程序与 manifest。
Sidecar 注入
注入可以自动或手动完成。如果要启用自动化的 Sidecar 注入,我们需要使用istio-injection=enabled来标记命名空间,这可以通过执行如下的命令来实现:
sh
$ kubectl label namespace default istio-injection=enabled
namespace/default labeled现在,默认命名空间中部署的所有 pod 都将会被注入 sidecar。切换至istio-mastery仓库的根目录,并执行如下的命令:
sh
$ kubectl apply -f resource-manifests/kube
persistentvolumeclaim/sqlite-pvc created
deployment.extensions/sa-feedback created
service/sa-feedback created
deployment.extensions/sa-frontend created
service/sa-frontend created
deployment.extensions/sa-logic created
service/sa-logic created
deployment.extensions/sa-web-app created
service/sa-web-app created执行如下的命令并检查 Ready 列,我们会看到"2/2",这表明第二个容器已经注入进来了。
sh
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
sa-feedback-55f5dc4d9c-c9wfv 2/2 Running 0 12m
sa-frontend-558f8986-hhkj9 2/2 Running 0 12m
sa-logic-568498cb4d-s9ngt 2/2 Running 0 12m
sa-web-app-599cf47c7c-s7cvd 2/2 Running 0 12m服务已经启动并运行了,每个容器都包含了 sidecar 代理。
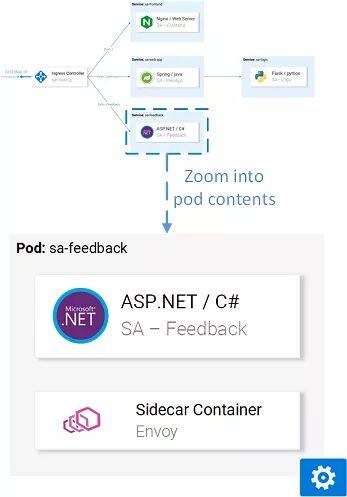
但是,要访问服务,我们需要允许传入的流量进入集群,也就是所谓的 Ingress 流量。
Ingress 网关
允许流量进入集群的一个最佳实践就是使用 Istio 的 Ingress 网关,它处于集群的边缘并且靠近传入的流量,它能够实现 Istio 的多项特性,比如路由、安全和监控。
在 Istio 安装的时候,Ingress 网关组件以及将其暴露给外部的服务已经安装到了集群中,可以通过如下的命令获取它的外部 IP:
sh
$ kubectl get svc -n istio-system -l istio=ingressgateway
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
istio-ingressgateway LoadBalancer 10.0.132.127 13.93.30.120 80:31380/TCP,443[...]在本文后续的内容中,我们将会通过该 IP(将其称为EXTERNAL-IP)访问应用程序,为了便利起见,我们通过下面的命令将其保存到变量中:
sh
$ EXTERNAL_IP=$(kubectl get svc -n istio-system \
-l app=istio-ingressgateway \
-o jsonpath='{.items[0].status.loadBalancer.ingress[0].ip}')如果你在浏览器中访问该 IP 的话,将会看到服务不可用的错误,默认情况下,在我们定义网关之前,Istio 会阻止所有传入的流量。
网关资源
网关是一种 Kubernetes 自定义资源定义(Kubernetes Custom Resource Definition),它是我们在集群中安装 Istio 时所定义的,借助它,我们能够指定允许传入流量的端口、协议和主机。
在我们的场景中,我们想要为所有主机开放 80 端口。我们可以通过如下的定义来进行配置:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: http-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"除了istio: ingressgateway选择器之外,所有配置项的含义均不言自明。通过使用这个选择器,我们可以指定哪个 Ingress 网关使用该配置,在我们的场景中,也就是在 Istio 安装时的默认 Ingress 网关控制器。
通过执行如下的命令,应用该配置:
sh
$ kubectl apply -f resource-manifests/istio/http-gateway.yaml
gateway.networking.istio.io "http-gateway" created网关允许我们访问 80 端口,但是它还不知道要将请求路由至何处,而这一功能是通过 Virtual Service 来实现的。
VirtualService 资源
VirtualService 能够指导 Ingress 网关如何路由允许进入集群的请求。
对于我们的应用来说,通过 http-gateway 的请求必须要路由至** sa-frontend、sa-web-app 和 sa-feedback 服务**。

现在,我们拆分一下应该路由至 SA-Frontend 的请求:
-
精确的路径"/"应该路由至 SA-Frontend 以便于获取 Index.html;
-
带有"/static/*"前缀的路径应该路由至 SA-Frontend,以便于获取前端所需的静态文件,比如级联样式表和 JavaScript 文件;
-
匹配正则表达式"^.*.(ico|png|jpg)$"的路径应该路由至 SA-Frontend,因为它代表的是页面展现所需的图片。
这样,我们就会得到如下的配置:
yaml
kind: VirtualService
metadata:
name: sa-external-services
spec:
hosts:
- "*"
gateways:
- http-gateway # 1
http:
- match:
- uri:
exact: /
- uri:
exact: /callback
- uri:
prefix: /static
- uri:
regex: '^.*\.(ico|png|jpg)$'
route:
- destination:
host: sa-frontend # 2
port:
number: 80这里的重点在于:
VirtualService 将会应用于通过 http-gateway 的请求;
destination 定义了请求要路由至哪个服务。
注意:上面的配置在sa-virtualservice-external.yaml文件中,它还包含了路由至 SA-WebApp 和 SA-Feedback 的配置,但是简洁期间,我们将其省略了。
通过执行如下的命令,应用 VirtualService:
sh
$ kubectl apply -f resource-manifests/istio/sa-virtualservice-external.yaml
virtualservice.networking.istio.io "sa-external-services" created注意:当我们应用该资源时(其实所有的 Istio 资源均如此),Kubernetes API Server 会创建一个新的事件,该事件会被 Istio 的控制平面接收到,然后会将新的配置应用到每个 pod 的 envoy 代理上。Ingress Gateway 控制器是 Control Plane 配置的另外一个 Envoy,如图所示。

现在,我们可以通过http://{{EXTERNAL-IP}}/访问情感分析应用了。如果你遇到 Not Found 状态的话,请不要担心,有时候配置生效并更新 envoy 缓存会耗费一点时间。
跨服务跟踪和流量管理
内置的特性
通过拦截所有的网络通信,Istio 能够得到一些指标和数据,这些指标和数据能够用来实现整个应用的可观察性。Kiali是一个开源的项目,它能够利用这些数据回答这样的问题:微服务是如何成为 Istio 服务网格的一部分的,它们是如何连接在一起的?
Kiali------可观察性
在安装 Istio 到我们的集群中之前,我们创建了一个用于 kiali 的 secret(还有另外一个用于 grafana),其中,我们将 user 和 password 都设置为 admin。要访问 Kiali 的 Admin UI,需要执行如下的命令:
sh
# 端口转发:在本地通过指定的端口访问运行在集群内的 Pod 上的服务 kiali
$ kubectl port-forward \
$(kubectl get pod -n istio-system -l app=kiali -o jsonpath='{.items[0].metadata.name}') \
-n istio-system 20001打开http://localhost:20001/并使用"admin"(不含引号)作为 user 和 password 进行登录。这里很有多有用的特性,比如检查 Istio 组件的配置、拦截网络请求和响应所收集的信息构建的可视化服务,比如"谁调用了谁?","哪个版本的服务出现了故障?"等等。在进入下一步章节学习使用 Grafana 可视化指标之前,请花一些时间检验 Kiali 的功能。
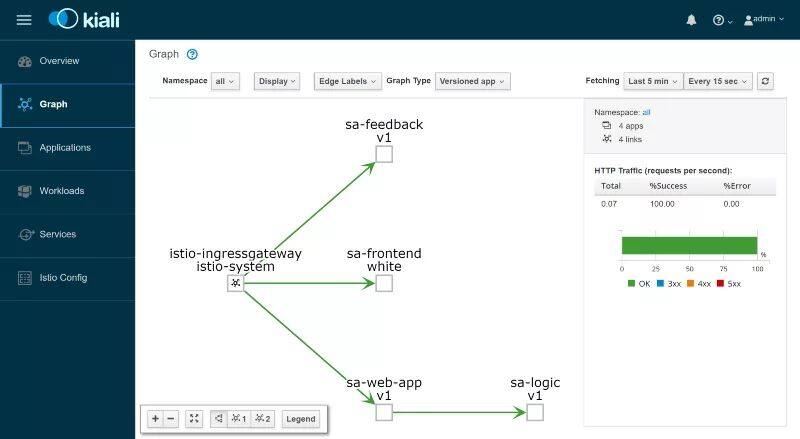
Grafana------指标可视化
Istio 收集到的指标被放到了 Prometheus 中,并使用 Grafana 进行可视化。要访问 Grafana 的 Admin UI,请执行如下的命令并打开http://localhost:3000。
sh
$ kubectl -n istio-system port-forward \
$(kubectl -n istio-system get pod -l app=grafana -o jsonpath='{.items[0].metadata.name}') 3000在左上角点击 Home 菜单,并选择 Istio Service Dashboard,然后选择 sa-web-app 打头的服务,这样我们就会看到收集到的指标,如下图所示:
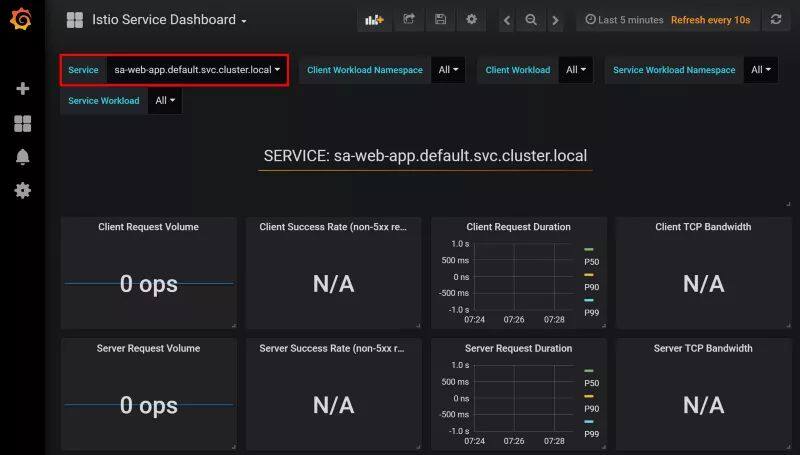
通过如下的命令,我们可以造一些负载出来:
sh
$ while true; do \
curl -i http://$EXTERNAL_IP/sentiment -H "Content-type: application/json" \
-d '{"sentence": "I love yogobella"}' \
sleep .8; donePrometheus 能够用来监控,Grafana 能用来对指标进行可视化,有了它们之后,我们就能知道随着时间的推移服务的性能、健康状况以及是否有升级和降级。
Jaeger------跟踪
我们需要跟踪系统的原因在于服务越多就越难以定位失败的原因。以下面图中这个简单的场景为例:

请求调用进来了,但是出现了失败,失败的原因是什么呢?是第一个服务失败还是第二个服务失败?两者都发生了异常,我们需要探查它们的日志。
这是微服务中一个非常普遍的问题,借助分布式的跟踪系统可以解决该问题,这种跟踪系统会在服务间传递一个唯一的 header 信息,然后这个信息会发送至分布式跟踪系统中,这样请求的跟踪信息就能汇总在一起了。
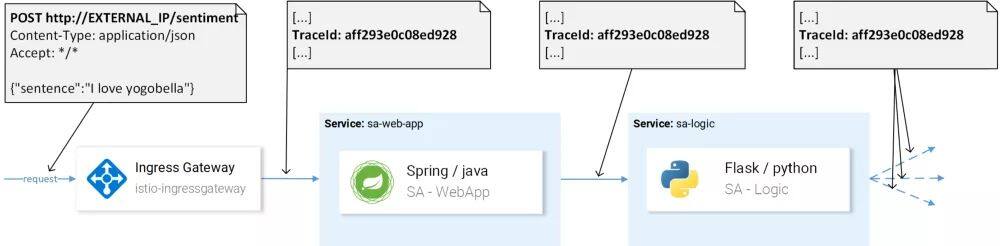
Istio 使用了 Jaeger Tracer,后者实现了 OpenTracing API,这是一个独立于供应商的框架。要访问 Jaegers UI,请执行如下的命令:
sh
$ kubectl port-forward -n istio-system \
$(kubectl get pod -n istio-system -l app=jaeger -o jsonpath='{.items[0].metadata.name}') 16686然后通过http://localhost:16686打开 UI,选择 sa-web-app 服务,如果服务没有出现在下拉列表中的话,那么在页面进行一些活动,并点击刷新。随后点击 Find Traces 按钮,它只会展现最近的 trace,选择任意一条记录,所有的跟踪信息将会分别展示,如图所示:
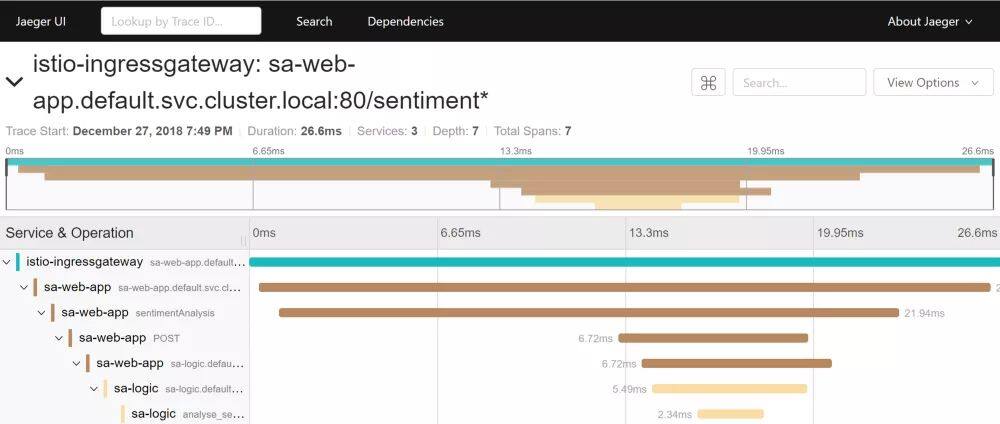
trace 展示了如下所述的信息:
-
传入 istio-ingressgateway 的请求(这是第一次与某个服务产生关联,所以会生成 Trace ID),随后网关将请求转发至 sa-web-app 服务;
-
在 sa-web-app 服务中,请求会被 Envoy 容器捕获并生成一个 span child(这就是我们能够在 trace 中看到它的原因),然后会被转发至 sa-web-app 应用。
-
在这里,sentimentAnalysis 方法会处理请求。这些 trace 是由应用生成的,这意味着需要对代码进行一些修改;
-
在此之后,会发起针对 sa-logic 的 POST 请求。sa-web-app 需要将 Trace ID 传播下去;
......
注意:在第 4 步,我们的应用需要获取 Istio 生成的 header 信息,并将其向下传递给下一个请求,如下面的图片所示。
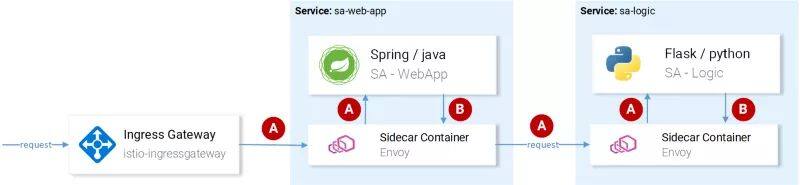
(A)Istio 传播 header 信息;
(B)服务传播 header 信息
Istio 承担了主要的工作,它会为传入的请求生成 header 信息、为每个 sidecar 创建新的 span 并传递 span,但是,如果我们的服务不同时传播这些 header 信息的话,那么我们就会丢失请求的完整跟踪信息。
要传播的 header 信息如下所示:
txt
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context尽管这是一个很简单的任务,但依然有很多的库在简化这个过程,例如,在 sa-web-app 服务中,RestTemplate 客户端就进行了 instrument 操作,这样的话,我们只需要在依赖中添加 Jaeger 和 OpenTracing 就能传播 header 信息了。
流量管理
借助 Envoy,Istio 能够提供为集群带来很多新功能:
动态请求路由 :金丝雀发布、A/B 测试
负载均衡 :简单一致的 Hash 均衡
故障恢复 :超时、重试、断路器
故障注入:延时、请求中断等。
在本文后面的内容中,我们将会在自己的应用中展示这些功能并在这个过程中介绍一些新的概念。我们要介绍的第一个概念就是 DestinationRules,并使用它们来实现 A/B 测试。
A/B 测试------Destination Rule 实践
A/B 测试适用于应用有两个版本的场景中(通常这些版本在视觉上有所差异),我们无法 100%确定哪个版本能够增加用户的交互,所以我们同时尝试这两个版本并收集指标。
sh
$ kubectl apply -f resource-manifests/kube/ab-testing/sa-frontend-green-deployment.yaml
deployment.extensions/sa-frontend-green created绿色版本的部署 manifest 有两点差异:
-
镜像基于不同的标签:istio-green;
-
pod 添加了version: green标记。
因为两个 deployment 都有app: sa-frontend标记,所以 virtual service sa-external-services在将请求路由至sa-frontend服务时,会转发到这两者上面,并且会使用 round robin 算法进行负载均衡,这样会导致下图所示的问题。
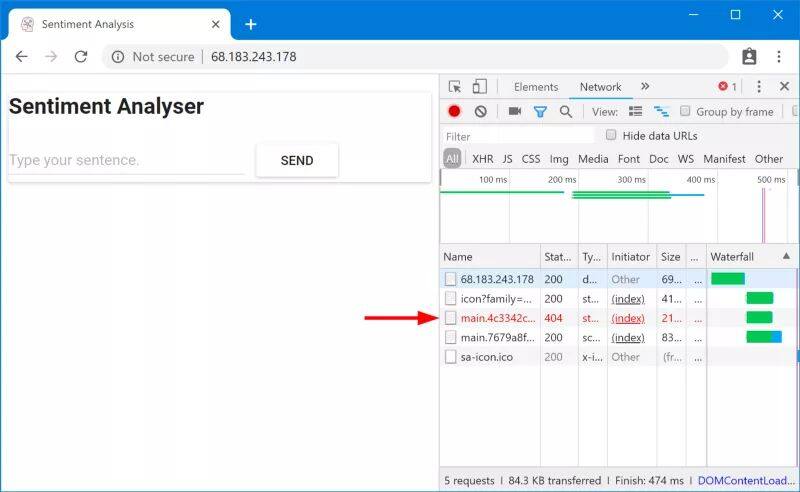
这里有文件没有找到的错误,这是因为在应用的不同版本中它们的名称不相同。我们验证一下:
sh
$ curl --silent http://$EXTERNAL_IP/ | tr '"' '\n' | grep main
/static/css/main.c7071b22.css
/static/js/main.059f8e9c.js
$ curl --silent http://$EXTERNAL_IP/ | tr '"' '\n' | grep main
/static/css/main.f87cd8c9.css
/static/js/main.f7659dbb.js也就是说,index.html在请求某个版本的静态文件时,被负载均衡到了另外一个版本的 pod 上了,这样的话,就会理解为其他文件不存在。这意味着,对我们的应用来说,如果想要正常运行的话,就要引入一种限制"为 index.html 提供服务的应用版本,必须也要为后续的请求提供服务"。
我们会使用一致性 Hash 负载均衡(Consistent Hash Loadbalancing)来达成这种效果,这个过程会将同一个客户端的请求转发至相同的后端实例中,在实现时,会使用一个预先定义的属性,如 HTTP header 信息。使用 DestionatioRules 就能够让这一切变成现实。
DestinationRules
在 VirtualService 将请求路由至正确的服务后,借助 DestinationRules 我们能够为面向该服务实例的流量指定策略,如图所示。
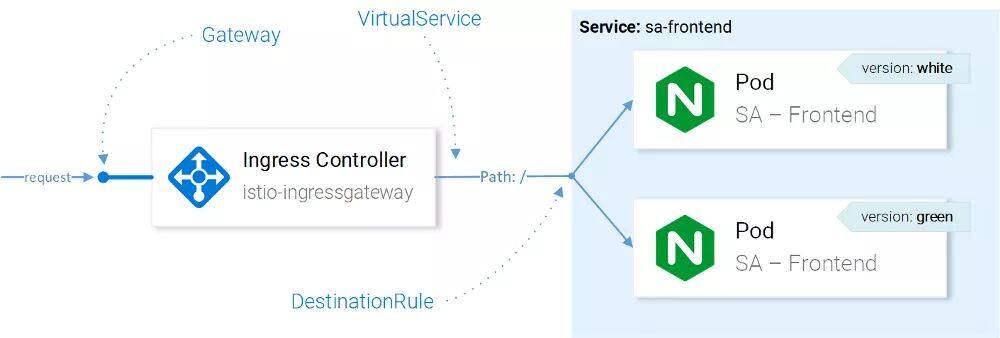
注意: 上图用非常易于理解的方式可视化地展现了 Istio 资源是如何影响网络流量的。但是,精确决定请求要发送至哪个实例是 Ingress Gateway 的 Envoy 完成的,它需要使用 CRD 来进行配置。
借助 Destination Rules 我们可以配置负载均衡使用一致哈希算法,从而确保相同的用户会由同一个服务实例提供响应。我们可以通过如下的配置实现这一点:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sa-frontend
spec:
host: sa-frontend
trafficPolicy:
loadBalancer:
consistentHash:
httpHeaderName: version # 11.根据"version"头信息的内容生成 consistentHash
执行如下的命令应用该配置:
sh
$ kubectl apply -f resource-manifests/istio/ab-testing/destinationrule-sa-frontend.yaml
destinationrule.networking.istio.io/sa-frontend created执行如下命令并校验在指定 version header 信息时会得到相同的文件:
sh
$ curl --silent -H "version: yogo" http://$EXTERNAL_IP/ | tr '"' '\n' | grep main注意:在浏览器中,你可以使用chrome扩展为 version 设置不同的值。
DestinationRules 有很多其他负载均衡的功能,关于其细节,请参考官方文档。
在更详细地探索 VirtualService 之前,通过如下的命令移除应用的 green 版本和 DestinationRules:
sh
$ kubectl delete -f resource-manifests/kube/ab-testing/sa-frontend-green-deployment.yaml
deployment.extensions "sa-frontend-green" deleted
$ kubectl delete -f resource-manifests/istio/ab-testing/destinationrule-sa-frontend.yaml
destinationrule.networking.istio.io "sa-frontend" deletedShadowing---------Virtual Services 服务实践
当我们想要在生产环境测试某项变更,但是不想影响终端用户的时候,可以使用影子(Shadowing)或镜像(Mirroring)技术,这样的话,我们能够将请求镜像至具有变更的第二个实例并对其进行评估。或者说更简单的场景,你的同事解决了一个最重要的缺陷,并提交了包含大量内容的 Pull Request,没人能够对其进行真正的审查。
为了测试这项特性,我们通过如下的命令创建 SA-Logic 的第二个实例(它是有缺陷的):
sh
$ kubectl apply -f resource-manifests/kube/shadowing/sa-logic-service.buggy.yaml执行下面的命令校验所有的版本除了app=sa-logic之外都带有对应版本的标记:
sh
$ kubectl get pods -l app=sa-logic --show-labels
NAME READY LABELS
sa-logic-568498cb4d-2sjwj 2/2 app=sa-logic,version=v1
sa-logic-568498cb4d-p4f8c 2/2 app=sa-logic,version=v1
sa-logic-buggy-76dff55847-2fl66 2/2 app=sa-logic,version=v2
sa-logic-buggy-76dff55847-kx8zz 2/2 app=sa-logic,version=v2因为sa-logic服务的目标是带有app=sa-logic标记的 pod,所以传入的请求会在所有的实例间进行负载均衡,如图所示:
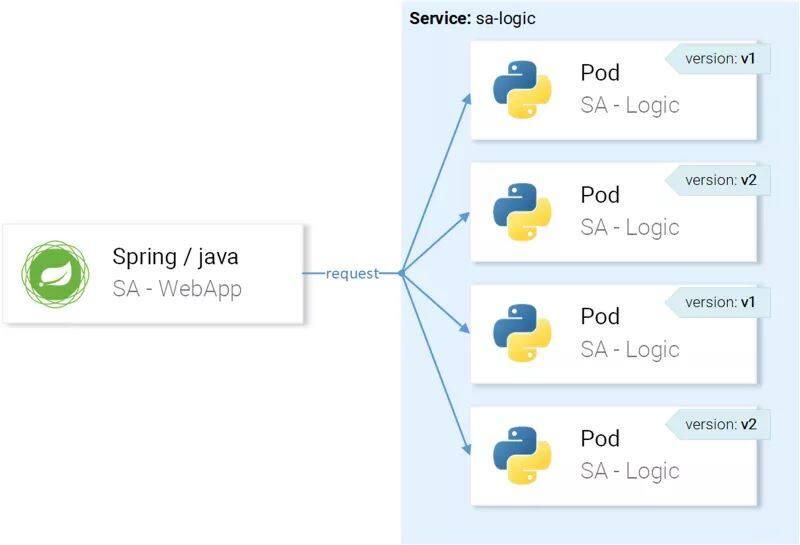
但是,我们想要将请求路由至 version v1 的实例并镜像至 version v2,如图所示:
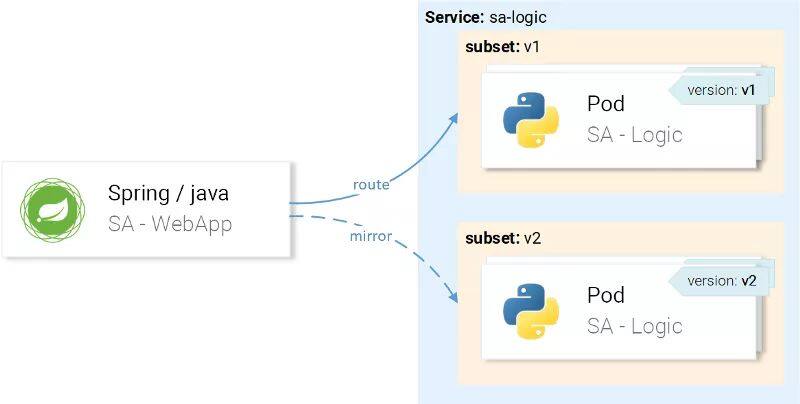
这可以通过组合使用 VirtualService 和 DestinationRule 来实现,Destination Rule 声明子集,而 VirtualService 路由至特定的子集。
通过 Destination Rule 声明子集
通过如下的配置定义子集:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sa-logic
spec:
host: sa-logic # 1
subsets:
- name: v1 # 2
labels:
version: v1 # 3
- name: v2
labels:
version: v2-
host 定义这个规则只适用于路由至 sa-logic 服务的请求;
-
当路由至子集实例时所使用子集名称;
-
以键值对形式定义的标记,将实例定义为子集的一部分。
通过执行如下的命令应用该配置:
sh
$ kubectl apply -f resource-manifests/istio/shadowing/sa-logic-subsets-destinationrule.yaml
destinationrule.networking.istio.io/sa-logic created在子集定义完之后,我们可以继续配置 VirtualService,让针对 sa-logic 的请求遵循如下的规则:
-
路由至名为 v1 的子集;
-
镜像至名为 v2 的子集。
可以通过如下的 VirtualService 实现:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
mirror:
host: sa-logic
subset: v2所有的配置都很具有表述性,我们不再赘述,接下来看一下它的实际效果:
sh
$ kubectl apply -f resource-manifests/istio/shadowing/sa-logic-subsets-shadowing-vs.yaml
virtualservice.networking.istio.io/sa-logic created通过执行如下命令生成一些负载:
sh
$ while true; do curl -v http://$EXTERNAL_IP/sentiment \
-H "Content-type: application/json" \
-d '{"sentence": "I love yogobella"}'; \
sleep .8; done在 Grafana 检查结果,你会发现有缺陷的版本会出现 60%的请求失败,但是这些失败都不会影响终端用户,因为他们是由当前活跃的服务来提供响应的。
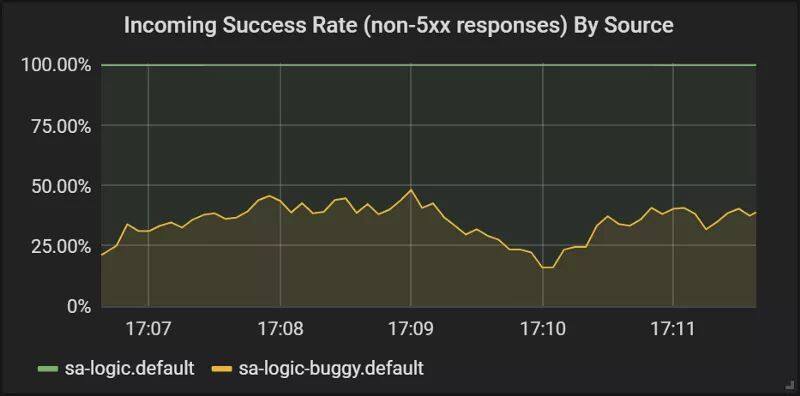
在本节中,我们第一次看到如何将 VirtualService 用到服务的 envoy 上,当 sa-web-app 发起对 sa-logic 的请求时,会经过 sidecar envoy,借助我们配置的 VirtualService,将会路由至 sa-logic 的 v1 子集并镜像至 v2 子集。
金丝雀部署
金丝雀(Canary)部署指的是让少量用户使用应用新版本的一个过程,借助这一过程能够验证新版本是否存在问题,然后能够确保以更高的质量发布给更多的受众。
继续使用sa-logic带有缺陷的子集来阐述金丝雀发布。
首先,我们大胆地将 20%的用户发送至带有缺陷的版本(这就是金丝雀发布),并将 80%的用户发送至正常的服务,这可以通过如下的 VirtualService 来实现:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
weight: 80 # 1
- destination:
host: sa-logic
subset: v2
weight: 20 # 1- 权重声明了请求要转发到目的地或目的地子集的百分比。
通过下面的命令,更新上述的sa-logic virtual service:
sh
$ kubectl apply -f resource-manifests/istio/canary/sa-logic-subsets-canary-vs.yaml
virtualservice.networking.istio.io/sa-logic configured我们马上可以看到有些请求失败了:
sh
$ while true; do \
curl -i http://$EXTERNAL_IP/sentiment -H "Content-type: application/json" \
-d '{"sentence": "I love yogobella"}' \
--silent -w "Time: %{time_total}s \t Status: %{http_code}\n" -o /dev/null; \
sleep .1; done
Time: 0.153075s Status: 200
Time: 0.137581s Status: 200
Time: 0.139345s Status: 200
Time: 30.291806s Status: 500VirtualServices 实现了金丝雀发布,借助这种方法,我们将潜在的损失降低到了用户群的 20%。非常好!现在,当我们对代码没有确切把握的时候,就可以使用 Shadowing 技术和金丝雀发布。
超时和重试
代码不仅仅会有缺陷,在"分布式计算的8个谬误"中,排名第一的就是"网络是可靠的"。网络实际上是不可靠的,这也是我们需要超时和重试的原因。
为了便于阐述,我们将会继续使用有缺陷版本的sa-logic,其中随机的失败模拟了网络的不可靠性。
带有缺陷的服务版本会有三分之一的概率在生成响应时耗费过长的时间,三分之一的概率遇到服务器内部错误,其余的请求均能正常完成。
为了降低这些缺陷的影响并给用户带来更好的用户体验,我们会采取如下的措施:
-
如果服务耗时超过了 8 秒钟,将会超时;
-
对于失败的请求进行重试。
可以通过如下的资源定义来实现:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
weight: 50
- destination:
host: sa-logic
subset: v2
weight: 50
timeout: 8s # 请求有 8 秒钟的超时;
retries:
attempts: 3 # 它会尝试 3 次;
perTryTimeout: 3s # 如果耗时超过 3 秒钟就将本次尝试标记为失败。这是一种优化:用户的等待不会超过 8 秒钟,如果失败的话,我们将会重试三次,这样的话增加了获取成功响应的概率。
通过如下命令应用更新后的配置:
sh
$ kubectl apply -f resource-manifests/istio/retries/sa-logic-retries-timeouts-vs.yaml
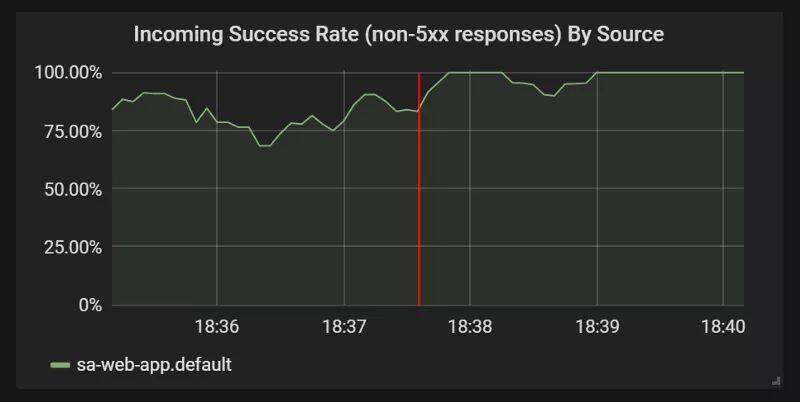
virtualservice.networking.istio.io/sa-logic configured查阅 Grafana 中的图表,看成功率是否有所提升
在进入下一节之前,通过如下命令移除掉sa-logic-buggy和 VirtualService:
sh
$ kubectl delete deployment sa-logic-buggy
deployment.extensions "sa-logic-buggy" deleted
$ kubectl delete virtualservice sa-logic
virtualservice.networking.istio.io "sa-logic" deleted认证和授权
断路器和舱壁模式
在微服务架构中,有两个重要的模式,它们能够让服务实现自愈的效果。
- 断路器模式(Circuit Breake)
能够阻止请求发送到不健康的服务实例上,这样的话,服务能够进行恢复,同时,客户端的请求将会转发到服务的健康实例上(增加了成功率)。
- 舱壁模式(Bulkhead Pattern)
会隔离失败,避免整个系统宕机,举例来说,服务 B 处于有问题的状态,另外一个服务(服务 B 的客户端)往服务 B 发送请求将会导致客户端耗尽线程池,从而不能为其他请求提供服务(即便其他的请求与服务 B 毫无关系也是如此)。
这里我不再展示这些模式的实现了,因为我迫不及待想要分享认证和授权的功能,这些模式的实现你可以参考官方文档。
Istio 中的认证和授权
Istio 将认证和授权从我们的服务中剥离了出去,并将其委托给了 Envoy 代理,这意味着当请求抵达我们的服务时,它们已经经过了认证和授权,我们只需要编写提供业务价值的代码就可以了。
使用 Auth0 进行认证
我们会使用 Auth0 作为身份识别和访问管理的服务器,它有一个试用方案,对我来说非常便利,我非常喜欢它!这也就是说,相同的理念可以用于任意的OpenID Connect实现,比如 KeyCloak、IdentityServer 等等。
首先,使用预设账号导航至Auth0 Portal,在 Applications > Default App 下创建一个租户,并记住 Domain,如下所示:
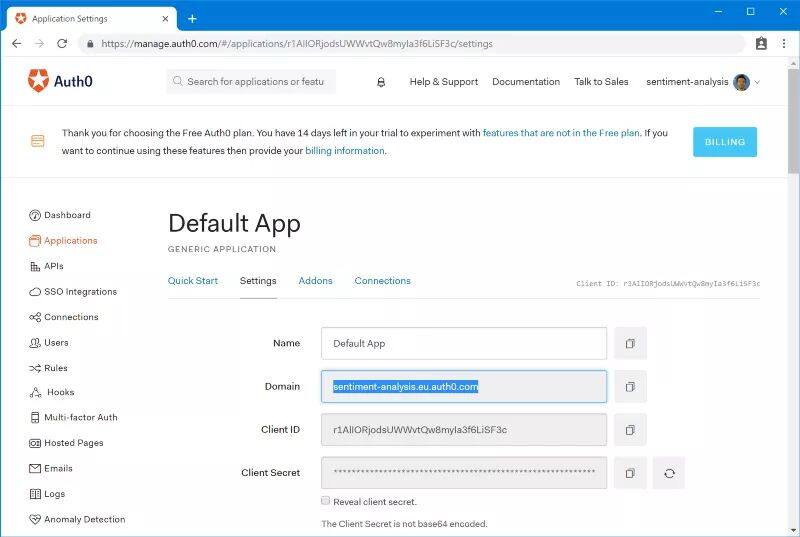
更新resource-manifests/istio/security/auth-policy.yaml文件,以便于使用该 Domain:
yaml
apiVersion: authentication.istio.io/v1alpha1
kind: Policy
metadata:
name: auth-policy
spec:
targets:
- name: sa-web-app
- name: sa-feedback
origins:
- jwt:
issuer: "https://{YOUR_DOMAIN}/"
jwksUri: "https://{YOUR_DOMAIN}/.well-known/jwks.json"
principalBinding: USE_ORIGIN借助该资源,Pilot 将会配置 envoy 在将请求转发至 sa-web-app 和 sa-feedback 服务之前进行认证。同时,它不会将该规则应用于服务sa-frontend的 envoy,这样的话,前端能够不用进行认证。为了应用该策略,我们需要执行如下命令:
sh
$ kubectl apply -f resource-manifests/istio/security/auth-policy.yaml
policy.authentication.istio.io "auth-policy" created回到页面并发送一个请求,我们将会看到 401 Unauthorized,现在,我们让来自前端的用户使用 Auth0 进行认证。
使用 Auth0 认证请求
要认证终端用户的请求,我们需要在 Auth0 中创建一个 API,它代表了经过认证的服务,比如评论、详情和评级。为了创建这样的 API,我们需要导航至 Auth0 Portal > APIs > Create API,如下图所示:
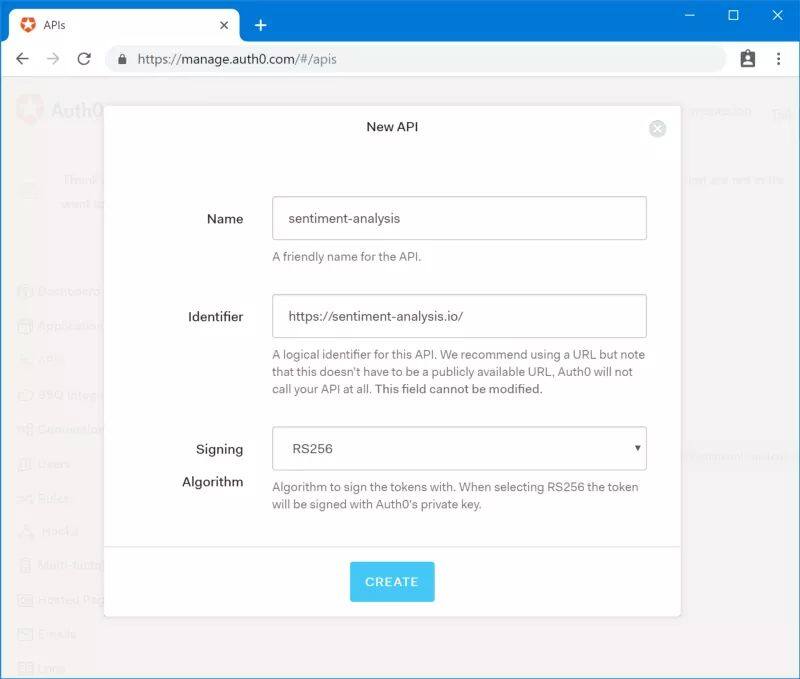
这里重要的信息是 Identifier,在随后的脚本中,我们会以如下的形式进行使用:
- Audience: {YOUR_AUDIENCE}
其余所需的细节在 Auth0 Portal 的 Applications 下进行配置,选择自动创建的 Test Application,其名称与 API 相同。
这里需要注意:
Domain: {YOUR_DOMAIN}
Client Id: {YOUR_CLIENT_ID}
在 Test Application 中向下滚动至 Allowed Callback URLs 文本域,在这里我们可以指定在认证完成后要转发到哪个 URL,在我们的场景中,应该是:
html
http://{EXTERNAL_IP}/callback在 Allowed Logout URLs 中添加如下的 URL:
html
http://{EXTERNAL_IP}/logout接下来,我们更新前端。
更新前端
切换至仓库的 auth0 分支。在这个分支中,前端包含了将用户转发至 Auth0 进行认证的代码变更,并在发送至其他服务的请求中包含了 JWT Token,如下所示:
js
analyzeSentence() {
fetch('/sentiment', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${auth.getAccessToken()}` // Access Token
},
body: JSON.stringify({ sentence: this.textField.getValue() })
})
.then(response => response.json())
.then(data => this.setState(data));
}为了更新前端以便于使用租户的详细信息,我们导航至sa-frontend/src/services/Auth.js文件并替换如下的值,也就是在前文中我提醒注意的地方:
js
const Config = {
clientID: '{YOUR_CLIENT_ID}',
domain:'{YOUR_DOMAIN}',
audience: '{YOUR_AUDIENCE}',
ingressIP: '{EXTERNAL_IP}' // Used to redirect after authentication
}应用已经就绪了,在如下的命令指定 docker user id,然后构建和部署变更:
sh
$ docker build -f sa-frontend/Dockerfile \
-t {DOCKER_USER_ID}/sentiment-analysis-frontend:istio-auth0 sa-frontend
$ docker push {DOCKER_USER_ID}/sentiment-analysis-frontend:istio-auth0
$ kubectl set image deployment/sa-frontend \
sa-frontend={DOCKER_USER_ID}/sentiment-analysis-frontend:istio-auth0我们可以尝试运行一下应用。访问的时候,你会被导航至 Auth0,在这里必要要登录(或注册),再次之后会重新转发会页面,这时候就可以发送认证后的请求了。如果你使用之前的 curl 命令的话,将会遇到 401 状态码,表明请求没有经过授权。
接下来,我们更进一步,对请求进行授权。
使用 Auth0 进行授权
认证能够让我们知道用户是谁,但是我们需要授权信息才能得知他们能够访问哪些内容。Istio 也提供了这样的工具。
作为样例,我们会创建两组用户(如图所示):
Users:只能访问 SA-WebApp 和 SA-Frontend 服务;
Moderators:能够访问所有的三个服务。
为了创建用户组,我们需要使用 Auth0 Authorization 扩展,随后借助 Istio,我们为它们提供不同级别的访问权限。
安装和配置 Auth0 授权
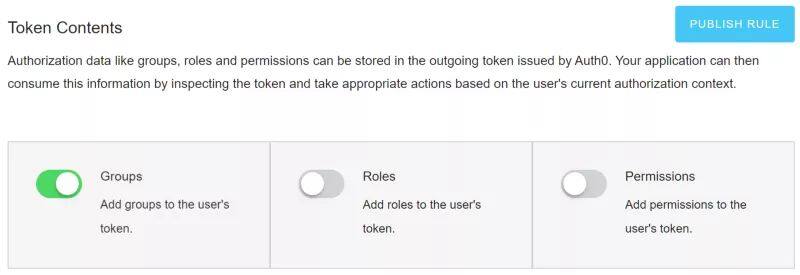
在 Auth0 Portal 中,切换至 Extensions,并安装"Auth0 Authorization"扩展。安装之后,切换至 Authorization Extension 并点击右上角你的租户并选择"Configuration"选项进行配置。启用组并点击"Publish rule"按钮。
1. 创建Group
在 Authorization Extension 中,导航至 Groups 并创建 Moderators 组。我们会将所有已认证过的用户视为普通的 User,这样的话,就没有必要额外再建立一个组了。
选择 Moderators 组并点击 Add Members,然后添加你的主账号。请将一些用户不放到任何的组中,以便于检验禁止他们访问(你可以通过 Auth0 Portal > Users > Create User 手动注册新用户)。
2. 添加 Group Claim 到 Access Token
用户现在已经添加到组中了,但是这些信息还没有反映到 Access Token 中。为了确保 OpenID Connect 的一致性,同时又能返回组,我们需要在 token 中添加自定义的命名空间声明。这可以通过 Auth0 规则来实现。
要在 Auth0 Portal 中创建规则,我们需要导航至 Rules,点击"Create Rule",并从模板中选择一个 empty rule。
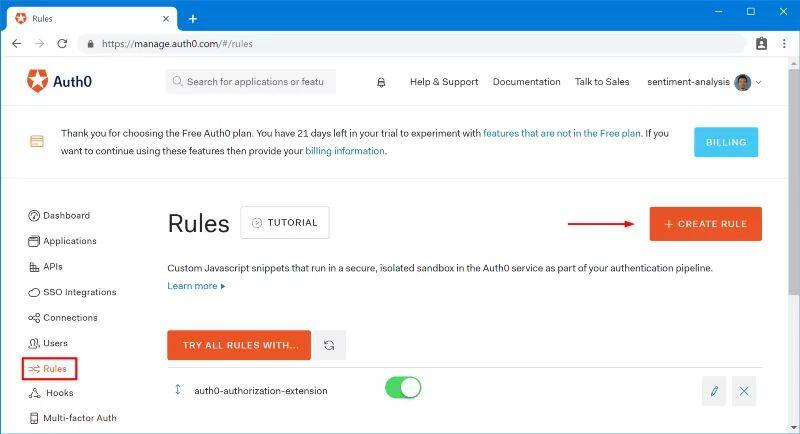
粘贴如下的代码并将规则命名为"Add Group Claim"。
js
function (user, context, callback) {
context.accessToken['https://sa.io/group'] = user.groups[0];
return callback(null, user, context);
}注意: 这个规则会获取 Authorization Extension 中定义的第一个用户组,并将其添加到 access token 中,作为自定义命名空间的声明。
回到 Rules 页面,确保我们按照如下顺序有了两个角色:
-
auth0-authorization-extension
-
Add Group Claim
这里的顺序是非常重要的,因为组的字段会由auth0-authorization-extension异步获取,然后由第二个规则将其添加为命名空间声明,这将会形成如下的 access token:
json
{
"https://sa.io/group": "Moderators",
"iss": "https://bookinfo.eu.auth0.com/",
"sub": "google-oauth2|196405271625531691872"
// [shortened for brevity]
}现在,我们**必须配置 Envoy 代理,从而能够在返回的 access token 中抽取https://sa.io/group声明的组**。这是下一部分的主题,我们马上来看一下。
3. 在 Istio 中配置授权
为了实现授权,我们为 Istio 启用 RBAC。为了实现这一点,要将如下的配置用到 Mesh 中:
yaml
apiVersion: "rbac.istio.io/v1alpha1"
kind: RbacConfig
metadata:
name: default
spec:
mode: 'ON_WITH_INCLUSION' # 仅为"Inclusion"字段中的服务和命名空间启用 RBAC;
inclusion:
services: # 包含如下服务。
- "sa-frontend.default.svc.cluster.local"
- "sa-web-app.default.svc.cluster.local"
- "sa-feedback.default.svc.cluster.local"执行如下命令,应用该配置:
sh
$ kubectl apply -f resource-manifests\istio\security\enable-rbac.yaml
rbacconfig.rbac.istio.io "default" created现在,所有的服务都需要基于角色的访问控制(Role-Based Access Control),换句话说,访问所有的服务都会遭到拒绝并且响应中会包含"RBAC: access denied"。我们下一节的主题就是启用对授权用户的访问。
4. 配置常规的用户访问
所有的用户应该都能访问 SA-Frontend 和 SA-WebApp 服务,这是通过如下的 Istio 资源实现的:
ServiceRole:指定用户具有的权限;
ServiceRoleBinding:指定 ServiceRole 应用到哪些用户上。
对于常规用户,我们允许访问指定的服务:
yaml
apiVersion: "rbac.istio.io/v1alpha1"
kind: ServiceRole
metadata:
name: regular-user
namespace: default
spec:
rules:
- services:
- "sa-frontend.default.svc.cluster.local"
- "sa-web-app.default.svc.cluster.local"
paths: ["*"]
methods: ["*"]然后,借助 regular-user-binding,我们将该 ServiceRole 应用到页面的所有访问者上:
yaml
apiVersion: "rbac.istio.io/v1alpha1"
kind: ServiceRoleBinding
metadata:
name: regular-user-binding
namespace: default
spec:
subjects:
- user: "*"
roleRef:
kind: ServiceRole
name: "regular-user"这里所说的所有用户,是不是意味着未认证的用户也能访问 SA WebApp 呢?并非如此,该策略依然会检查 JWT token 的合法性。
通过如下命令,应用该配置:
sh
$ kubectl apply -f resource-manifests/istio/security/user-role.yaml
servicerole.rbac.istio.io/regular-user created
servicerolebinding.rbac.istio.io/regular-user-binding created5. 配置 Moderator 用户访问
对于 Moderator,我们想要启用对所有服务的访问:
yaml
apiVersion: "rbac.istio.io/v1alpha1"
kind: ServiceRole
metadata:
name: mod-user
namespace: default
spec:
rules:
- services: ["*"]
paths: ["*"]
methods: ["*"]但是,我们只想要绑定 Access Token 中https://sa.io/group声明的值为 Moderators 的用户。
yaml
apiVersion: "rbac.istio.io/v1alpha1"
kind: ServiceRoleBinding
metadata:
name: mod-user-binding
namespace: default
spec:
subjects:
- properties:
request.auth.claims[https://sa.io/group]: "Moderators"
roleRef:
kind: ServiceRole
name: "mod-user"要应用该配置,需要执行下述命令:
sh
$ kubectl apply -f resource-manifests/istio/security/mod-role.yaml
servicerole.rbac.istio.io/mod-user unchanged servicerolebinding.rbac.istio.io/mod-user-binding unchangedEnvoy 中会有缓存,所以授权规则可能需要几分钟之后才能生效,在此之后,我们就可以校验 Users 和 Moderators 会有不同级别的访问权限。
坦白讲,你见过像这样毫不费力就能构建可扩展的认证和授权吗,还有比这更简单的过程吗?反正我是没有见过!接下来,我们总结一下得到的结论。
结论
想象不到吧?我们将其称为怪兽(Beast-io),因为它确实太强大了。借助它,我们能够:
-
实现服务的可观察性,借助 Kiali,我们能够回答哪个服务在运行、它们的表现如何以及它们是如何关联在一起的;
-
借助 Prometheus 和 Grafana,能够实现指标收集和可视化,完全是开箱即用的;
-
使用 Jaeger(德语中猎人的意思)实现请求跟踪;
-
对网络流量的完整且细粒度控制,能够实现金丝雀部署、A/B 测试和影子镜像;
-
很容易实现重试、超时和断路器;
-
极大地减少了为集群引入新服务的开销;
-
为各种语言编写的微服务添加了认证和授权功能,服务端代码无需任何修改。
有个这个 Beastio,我们就能让团队真正地提供业务价值,并将资源聚焦在领域问题上,不用再担心服务的开销,让服务真正做到"微型化"。