1.前言
随着国内各大行业数字化改造步伐的加快,异构数据库数据同步的需求场景越来越多。
异构数据库同步,就是将不同类型、不同结构的数据库之间的数据进行同步处理,以确保数据在不同数据库之间的一致性。比如,将当前数据库的数据迁移到其他类型的数据库中,或者将当前数据库中的数据实时备份到另一个数据库,从而提升数据的安全性和可靠性。
华为云提供了DRS服务,该服务涵盖了异构数据库之间的迁移、同步、灾备、订阅、录制回放等功能。目前DRS支持超过20种关系型和非关系型数据库作为源端,其中就包括了GaussDB。以GaussDB作为源数据库的DRS数据同步的原理如下图所示。
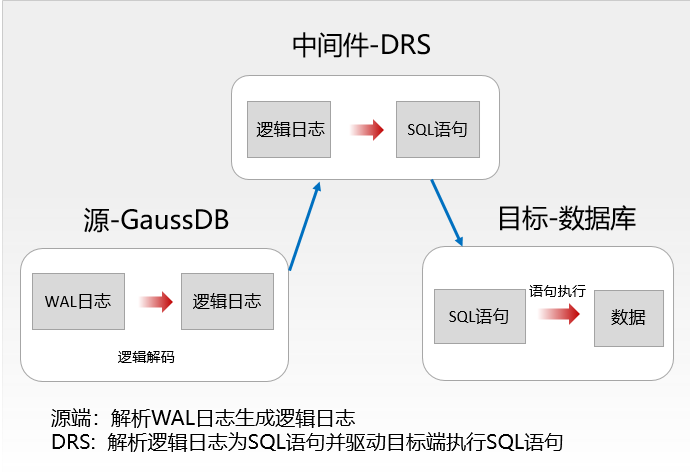
DRS驱动源端数据库GaussDB实时解析WAL日志,生成逻辑日志,随后DRS服务接收并解析逻辑日志,将其转换为目标数据库的SQL语句,并驱动目标数据库执行SQL语句,该过程被称为逻辑复制。
对于源端数据库来说,核心要解决的问题是如何将WAL日志转换成逻辑日志,该过程叫逻辑解码。本文我们将为大家介绍GaussDB逻辑解码的技术原理。
2. GaussDB逻辑解码
WAL日志包含数据库中发生的所有数据变更,包括插入、更新和删除等操作,同时还包含了诸多数据库内部细节和特有实现。
逻辑解码用于将WAL日志解析为易于理解和处理的逻辑日志格式,包括JSON、二进制或者固定的text格式。用户和逻辑复制工具(如DRS)可以根据自身需求来解析和处理这些逻辑日志。
当启用逻辑解码时,GaussDB除了将每个事务的基本操作写入WAL日志,还会将少量的解码辅助信息(例如csn快照,用于解码阶段的可见性判断)记录到WAL日志中,以支持逻辑解码过程。同时还需要创建一个逻辑复制槽。逻辑复制槽的作用是阻止数据库将已落盘的WAL日志删除,并防止解码所需的系统表记录被清理。
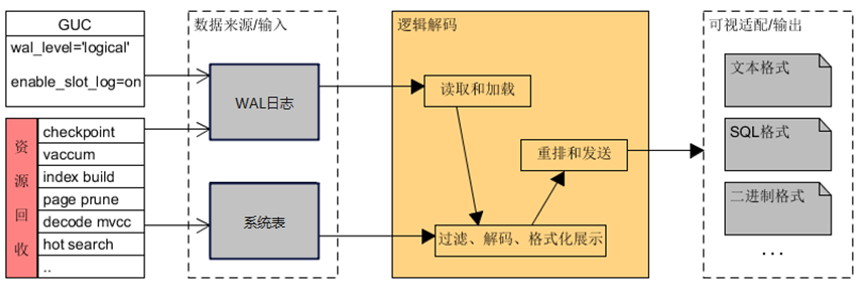
如上图所示,逻辑解码主要包括数据来源、读取/加载、解码、重排/发送几个模块。WAL日志和系统表中存储的表的元数据是逻辑解码的内容来源。逻辑解码从WAL日志捕获用户表DML的变更记录,依据其中的物理存储标识(block number和offset等)和提交序列号(csn),加载系统表对应时刻表的元数据,再将物理变更记录中强耦合的内部信息转换为用户可理解的表内容,生成和数据库实现无关的逻辑变更记录,最后重排和发送逻辑变更记录。
GaussDB逻辑解码有两种方式,分别为串行解码和并行解码。
串行解码流程分为读取、解码、发送三个步骤,整个串行解码流程均在同一个线程内完成,其中解码的耗时占据全流程的70%以上。串行解码性能约3-5M/s,而并行解码是通过多线程并行执行的方式,极大压缩了解码过程耗时。因为串行解码效率较低,我们不推荐使用串行解码,而是推荐效率更高的并行解码,而且当前通过华为云DRS服务启动的GaussDB逻辑解码任务均为并行解码,下面我们重点介绍并行解码。
3. 并行解码
并行解码是通过多线程并发执行来提升逻辑解码性能。
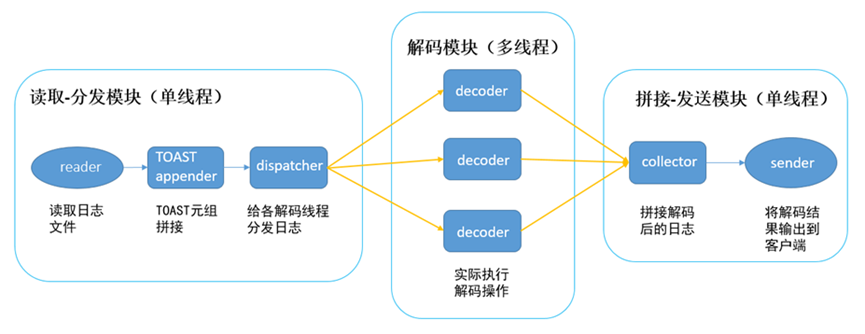
如上图所示,并行逻辑解码包含三类线程:
Reader 线程
读取WAL日志,抽取业务DML操作以及解码辅助信息对应的record,构建LogicalLogChange内存对象,如果该条DML涉及toast数据,还需要将toast数据拼接到该dml操作的LogicalLogChange对象中,然后按照日志序列号(LSN,WAL日志的唯一标识符,是一个有序值)顺序轮流分发到解码输入队列。
如果解码到了DDL,DDL更新了系统表,Reader线程此时会失效localsyscache,并将失效消息加入Decoder线程输入队列中,广播通知Decoder线程失效本地缓存。后续decoder线程在解码到失效消息时,同样会对线程内的localsyscache作失效处理。
Decoder 线程
从解码输入队列获取LogicalLogChange对象,根据日志版本内容加载数据表的元信息,将日志中的物理数据转换成表名、列名、列数据等用户易理解的逻辑数据,解码后的内容存放在LogicalLog内存对象中,并将LogicalLog对象加入到解码输出队列。
前面介绍到,Reader线程在将LogicalLogChange对象入队时是按LSN序将其放入解码输入队列,decoder解码完成后也会将LogicalLog按LSN需放入解码输出队列,供后面的Sender线程读取。
Sender 线程
按照DML日志生成顺序,从解码输出队列拿取LogicalLog对象,根据每个对象的事务ID构建hash桶,按照每个LogicalLog对象在解码输出队列中的顺序(队列中已按LSN序排序),把同一个事务的LogicalLog对象,归类到对应的hash桶中,再以事务的提交顺序把每个事务的所有LogicalLog对象发送给逻辑日志接收端(例如DRS)。
并行解码可按需配置解码并发度,并发度参数取值范围为1-20,最大可配置20个并发解码线程。
GaussDB并行解码能极大地提升解码性能。典型tpcc场景下,解码速率可达到100MB/s。
4. DDL解码
GaussDB逻辑解码支持DDL解码。如果GaussDB开启了逻辑解码,则会在DDL SQL执行阶段对DDL语句的解析树进行解析,解析的结果组装为Json格式的字符串(示例),并新增一种WAL日志类型,用于将该Json字符串写入WAL日志。逻辑解码线程解析到该WAL日志类型时,按照原Json格式输出DDL的解码逻辑日志。
DDL语句alter table t1 add column col3 varchar(64)的Json格式解码结果如下:
{
"JDDL": {
"fmt": "ALTER %{object_type}s %{if_exists}s %{identity}D %{subcmds:, }s",
"subcmds": [
{
"fmt": "ADD COLUMN %{definition}s",
"definition": {
"fmt": "%{name}I %{column_type}T",
"name": "col3",
"column_type": {
"typmod": "(64)",
"typarray": false,
"type_name": "varchar",
"schema_name": "pg_catalog"
}
}
}
],
"identity": {
"object_name": "t1",
"schema_name": "public"
},
"if_exists": "",
"object_type": "TABLE"
}
}5.多版本数据字典与指定位点解码
逻辑解码在解码DML过程中依赖表的元数据信息,因此需要访问系统表(也叫数据字典),这种解码模式也叫online catalog模式。GaussDB将系统表信息缓存在syscache中,当DDL语句更新了系统表时,需要对syscache进行失效处理。执行DDL时会往WAL中写一条失效消息日志,逻辑解码的每个线程都在本线程内保存了一份syscache的副本,即localcache。解码到失效消息日志时,会对localcache做相应的失效处理。
online catalog模式的逻辑解码依赖表的历史元数据信息,因此需要利用逻辑复制槽来保留系统表的旧版本元组。如果想对任意历史日志进行指定位点解码,逻辑解码依赖的系统表旧版本元组需要需要一直保留,这样会严重影响数据库的性能。
因此,GaussDB单独增加了一套逻辑解码专用的系统表,叫作逻辑解码多版本数据字典。逻辑解码多版本数据字典参考内核系统表,表结构与内核系统表结构基本保持一致,保留了解码过程中表的元数据的所有历史版本,并单独实现了清理机制。
新安装的实例会自动创建好逻辑解码多版本数据字典,非新安装的实例,首次初始化逻辑解码多版本数据字典时,需要调用一个系统函数进行初始化,该系统函数将内核系统表的数据同步到逻辑解码多版本数据字典中。当DDL语句执行完,事务提交前,往内核系统表插入元数据的同时往逻辑解码多版本数据字典插入元数据。
解码的时候,解码线程根据当前csn快照,从逻辑解码多版本数据字典中将元数据信息读取到localcache缓存中使用。同时逻辑解码实现了多版本数据字典清理的定时任务,通过guc参数,配置保留时间,将超过保留时间的元组删除。而且,通过该guc参数,我们可以保留任意时间的旧元组,从而在不影响数据库性能的基础上实现从指定位点(即WAL的物理位置)进行逻辑解码,位点可以是包括归档WAL日志在内的任意位置。

通过这种单独增加一套逻辑解码多版本数据字典的方式,可以将逻辑解码与内核系统表解耦,内核系统表无需为逻辑解码保留大量的旧版本元组,保障了内核的运行性能。
6.分布式CN解码
GaussDB支持分布式解码能力。分布式解码又分为直连DN解码与CN解码。直连DN解码即不通过CN,解码工具直接连接到DN节点上进行DN解码,该解码方式和集中式解码原理一致,只能解本DN分片的数据。分布式解码主要是指对CN进行解码,可以完整解码整个集群的增量数据。
事务提交顺序(CommitCSN)代表事务完成的先后顺序。对于有依赖的两个事务,后执行事务的CommitCSN大于先执行事务的CommitCSN。分布式逻辑解码按照事务提交顺序有序返回事务的逻辑日志。
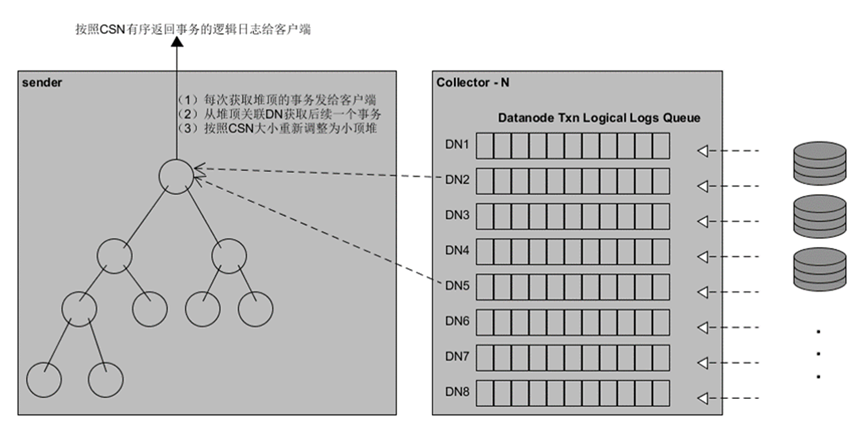
如图所示,DN各自按照事务提交顺序返回局部事务的逻辑日志,CN通过堆排序协调汇总来自各DN的事务逻辑日志,按堆排序的顺序输出逻辑日志。相比于直连DN解码,具有链路数少、能保证强一致性、易用性强等优点。
7. 总结
GaussDB内核提供的逻辑解码技术,配合DRS服务,可以实现异构数据库之间的逻辑复制。GaussDB逻辑解码不仅支持DML解码,还支持DDL解码,极大提高了逻辑复制的易用性。支持独立的多版本数据字典模式进行解码,并支持指定位点解码与数据找回。通过开启并行解码,可以极大提高WAL日志解码速率,保证数据同步的高性能。