用神经网络玩游戏
CartPole是OpenAI gym中的一个游戏测试,车上顶着一个自由摆动的杆子,实现杆子的平衡,杆子每次倒向一端车就开始移动让杆子保持动态直立的状态.

游戏地址:https://gymnasium.farama.org/env ... _control/cart_pole/
一、搭建游戏运行环境
bash
pip install swig
pip install gymnasium[box2d]
CartPole 环境内置在 gym 中,直接安装 gym 即可。其环境 id 是CartPole-v0 。Gym是一个研究和开发强化学习相关算法的仿真平台。简单来说OpenAI Gym提供了许多问题和环境(或游戏)的接口,而用户无需过多了解游戏的内部实现,通过简单地调用就可以用来测试和仿真。
bash
pip install gym
启动游戏完整代码:
python
import gym
# 创建 CartPole 环境
env = gym.make('CartPole-v1', render_mode="human") # 使用新版本时,需要指定 render_mode
# 重置环境,准备开始游戏
observation, info = env.reset()
for _ in range(1000):
# 随机选择一个动作(0或1)
action = env.action_space.sample()
# 应用动作到环境中,返回新的状态、奖励、完成标志和其他信息
observation, reward, done, truncated, info = env.step(action)
# 如果游戏结束或被截断,重置环境
if done or truncated:
observation, info = env.reset()
# 关闭游戏
env.close()可以看到游戏在自动运行。
二、手动控制
增加键盘操作:
python
# 获取键盘按键状态
keys = pygame.key.get_pressed()
# 默认动作为随机生成 0 或 1,除非检测到按键输入
if not keys[K_LEFT] and not keys[K_RIGHT]:
action = random.choice([0, 1]) # 随机选择 0 或 1
# 根据按键改变动作
if keys[K_LEFT]:
print("Left arrow pressed")
action = 0 # 向左移动
elif keys[K_RIGHT]:
print("Right arrow pressed")
action = 1 # 向右移动完整代码如下:
python
import gym
import pygame
from pygame.locals import K_LEFT, K_RIGHT, QUIT
import time
import random # 用于生成随机数
# 初始化 pygame
pygame.init()
# 设置帧率
FPS = 60
clock = pygame.time.Clock()
# 创建 CartPole 环境,使用 Gym 自带的渲染模式
env = gym.make('CartPole-v1', render_mode="human")
# 重置环境,准备开始游戏
observation, info = env.reset()
# 初始化游戏的运行标志
running = True
# 操作次数
action_count = 0
# 记录游戏开始的时间
start_time = time.time()
# 游戏循环
while running:
# 处理事件队列,检测关闭窗口操作
for event in pygame.event.get():
if event.type == QUIT: # 退出事件
running = False
time.sleep(0.3)
# 获取键盘按键状态
keys = pygame.key.get_pressed()
# 默认动作为随机生成 0 或 1,除非检测到按键输入
if not keys[K_LEFT] and not keys[K_RIGHT]:
action = random.choice([0, 1]) # 随机选择 0 或 1
# 根据按键改变动作
if keys[K_LEFT]:
print("Left arrow pressed")
action = 0 # 向左移动
elif keys[K_RIGHT]:
print("Right arrow pressed")
action = 1 # 向右移动
# 执行动作并更新环境状态
observation, reward, done, truncated, info = env.step(action)
# 每执行一次动作,增加操作次数
action_count += 1
# 渲染环境,减少渲染频率(每隔 10 帧渲染一次)
if action_count % 10 == 0:
env.render()
# 检查游戏是否结束
if done or truncated:
# 记录游戏结束的时间
end_time = time.time()
# 计算游戏持续的时间(秒)
elapsed_time = end_time - start_time
# 打印游戏信息
print(f"游戏结束!总共操作了 {action_count} 次,持续时间为 {elapsed_time:.2f} 秒")
# 重置环境
observation, info = env.reset()
# 重置计数器和时间
action_count = 0
start_time = time.time()
# 控制帧率,确保游戏速度合适
clock.tick(FPS) # 设置帧率为 60 帧/秒
# 关闭游戏环境和 pygame
env.close()
pygame.quit()最好成绩成功控制了57次。

三、用电脑控制
python
#电脑自嗨
if observation[2] <= 0:
action = 0
else:
action = 1电脑居然控制了59步。
四、用神经网络控制
1.训练神经网络
bash
pip install torch
python
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
# 设置设备(如果有GPU则使用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建 CartPole 环境
env = gym.make('CartPole-v1')
# 超参数
GAMMA = 0.99 # 折扣因子
EPSILON_START = 1.0 # 初始探索率
EPSILON_END = 0.01 # 最低探索率
EPSILON_DECAY = 0.995 # 探索率衰减
LEARNING_RATE = 0.001 # 学习率
MEMORY_SIZE = 10000 # 经验回放的容量
BATCH_SIZE = 64 # 批量大小
TARGET_UPDATE = 10 # 每隔多少步更新目标网络
TRAIN_TARGET_REWARD = 5000 # 训练停止目标:游戏持续达到 5000 步
# DQN 网络结构
class DQN(nn.Module):
def __init__(self, state_size, action_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 经验回放池
class ReplayMemory:
def __init__(self, capacity):
self.memory = deque(maxlen=capacity)
def push(self, experience):
self.memory.append(experience)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
# 选择动作的epsilon-greedy策略
def select_action(state, policy_net, epsilon, n_actions):
if random.random() < epsilon:
return random.randrange(n_actions) # 随机探索
else:
with torch.no_grad():
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
return policy_net(state).argmax(dim=1).item() # 利用网络选择最优动作
# 更新目标网络
def update_target_network(policy_net, target_net):
target_net.load_state_dict(policy_net.state_dict())
# 训练 DQN 网络
def optimize_model(policy_net, target_net, memory, optimizer):
if len(memory) < BATCH_SIZE:
return
# 从经验回放池中采样
experiences = memory.sample(BATCH_SIZE)
# 将经验解包为不同部分
states, actions, rewards, next_states, dones = zip(*experiences)
states = torch.tensor(states, dtype=torch.float32).to(device)
actions = torch.tensor(actions, dtype=torch.int64).unsqueeze(1).to(device)
rewards = torch.tensor(rewards, dtype=torch.float32).unsqueeze(1).to(device)
next_states = torch.tensor(next_states, dtype=torch.float32).to(device)
dones = torch.tensor(dones, dtype=torch.float32).unsqueeze(1).to(device)
# 当前 Q 值
q_values = policy_net(states).gather(1, actions)
# 下一个状态的最大 Q 值(目标网络)
with torch.no_grad():
max_next_q_values = target_net(next_states).max(1)[0].unsqueeze(1)
target_q_values = rewards + (GAMMA * max_next_q_values * (1 - dones))
# 计算损失
loss = nn.MSELoss()(q_values, target_q_values)
# 反向传播优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 初始化 DQN 网络和目标网络
n_actions = env.action_space.n
state_size = env.observation_space.shape[0]
policy_net = DQN(state_size, n_actions).to(device)
target_net = DQN(state_size, n_actions).to(device)
update_target_network(policy_net, target_net)
# 优化器
optimizer = optim.Adam(policy_net.parameters(), lr=LEARNING_RATE)
# 经验回放
memory = ReplayMemory(MEMORY_SIZE)
# 训练主循环
epsilon = EPSILON_START
num_episodes = 1000
for episode in range(num_episodes):
state, _ = env.reset()
done = False
total_steps = 0
total_reward = 0
while not done:
# 选择动作
action = select_action(state, policy_net, epsilon, n_actions)
# 执行动作
next_state, reward, done, truncated, _ = env.step(action)
total_steps += 1
total_reward += reward
# 如果游戏结束,则给负奖励
reward = reward if not done else -10
# 将经验存入回放池
memory.push((state, action, reward, next_state, done))
# 更新状态
state = next_state
# 训练模型
optimize_model(policy_net, target_net, memory, optimizer)
# 停止训练条件:游戏累计达到5000步,保存模型
if total_steps >= TRAIN_TARGET_REWARD:
print(f"Training completed after {episode+1} episodes, reaching {total_steps} steps.")
torch.save(policy_net.state_dict(), 'dqn_cartpole.pth')
break
# 每隔一定步数更新目标网络
if episode % TARGET_UPDATE == 0:
update_target_network(policy_net, target_net)
# epsilon衰减
epsilon = max(EPSILON_END, EPSILON_DECAY * epsilon)
print(f"Episode {episode + 1}/{num_episodes},total_steps:{total_steps}, Total Reward: {total_reward}")
# 检查是否已经达到目标
if total_steps >= TRAIN_TARGET_REWARD:
break
env.close()保存模型的代码:
python
# 训练结束后保存模型
if total_steps >= TRAIN_TARGET_REWARD:
print(f"Training completed after {episode+1} episodes, reaching {total_steps} steps.")
torch.save(policy_net.state_dict(), 'dqn_cartpole.pth')
break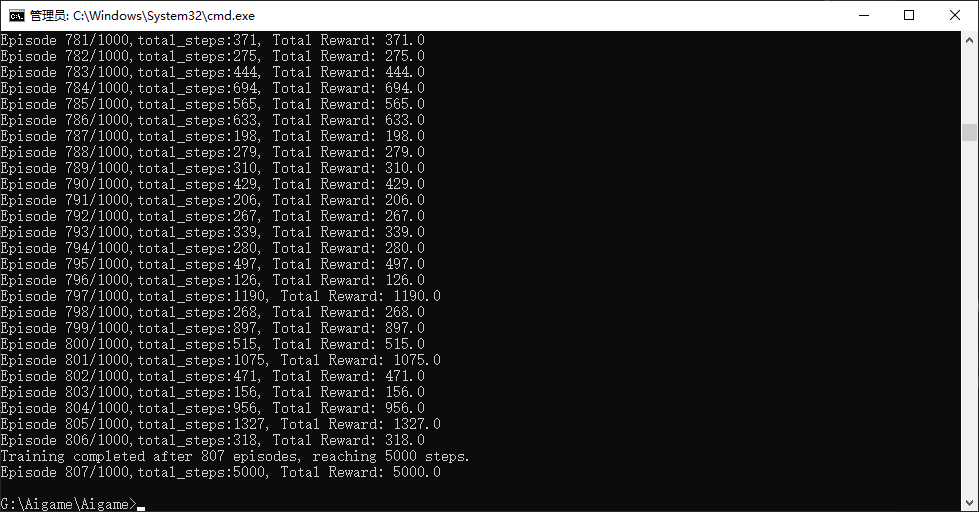
模型保存成功,大小6kb
2.使用神经网络控制游戏:
调用神经网络决策关键代码:
python
state_tensor = torch.tensor(observation, dtype=torch.float32).unsqueeze(0).to(device)
action = policy_net(state_tensor).argmax(dim=1).item()使用模型并调用神经网络控制完整代码如下:
python
import gym
import pygame
import torch
import torch.nn as nn
from pygame.locals import K_LEFT, K_RIGHT, QUIT
import time
import random # 用于生成随机数
# 设置设备(如果有GPU则使用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化 pygame
pygame.init()
# 设置帧率
FPS = 60
clock = pygame.time.Clock()
# 创建 CartPole 环境,使用 Gym 自带的渲染模式
env = gym.make('CartPole-v1', render_mode="human")
# 重置环境,准备开始游戏
observation, info = env.reset()
# 初始化游戏的运行标志
running = True
# 操作次数
action_count = 0
# 记录游戏开始的时间
start_time = time.time()
# DQN 网络结构
class DQN(nn.Module):
def __init__(self, state_size, action_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 初始化 DQN 网络和目标网络
n_actions = env.action_space.n
state_size = env.observation_space.shape[0]
# 加载模型并使用神经网络控制游戏
policy_net = DQN(state_size, n_actions).to(device)
# 加载训练好的模型权重
MODEL_PATH = 'dqn_cartpole.pth'
policy_net.load_state_dict(torch.load(MODEL_PATH))
# 设置为评估模式
policy_net.eval()
# 游戏循环
while running:
# 处理事件队列,检测关闭窗口操作
for event in pygame.event.get():
if event.type == QUIT: # 退出事件
running = False
time.sleep(0.3)
# 获取键盘按键状态
keys = pygame.key.get_pressed()
# 默认动作为随机生成 0 或 1,除非检测到按键输入
if not keys[K_LEFT] and not keys[K_RIGHT]:
action = random.choice([0, 1]) # 随机选择 0 或 1
# 根据按键改变动作
if keys[K_LEFT]:
print("Left arrow pressed")
action = 0 # 向左移动
elif keys[K_RIGHT]:
print("Right arrow pressed")
action = 1 # 向右移动
state_tensor = torch.tensor(observation, dtype=torch.float32).unsqueeze(0).to(device)
action = policy_net(state_tensor).argmax(dim=1).item()
# 执行动作并更新环境状态
observation, reward, done, truncated, info = env.step(action)
# 每执行一次动作,增加操作次数
action_count += 1
# 渲染环境,减少渲染频率(每隔 10 帧渲染一次)
if action_count % 10 == 0:
env.render()
# 检查游戏是否结束
if done or truncated:
# 记录游戏结束的时间
end_time = time.time()
# 计算游戏持续的时间(秒)
elapsed_time = end_time - start_time
# 打印游戏信息
print(f"游戏结束!总共操作了 {action_count} 次,持续时间为 {elapsed_time:.2f} 秒")
# 重置环境
observation, info = env.reset()
# 重置计数器和时间
action_count = 0
start_time = time.time()
# 控制帧率,确保游戏速度合适
clock.tick(FPS) # 设置帧率为 60 帧/秒
# 关闭游戏环境和 pygame
env.close()
pygame.quit()每次都能顺利通关

更详细:
用神经网络自动玩游戏
https://www.jinshuangshi.com/forum.php?mod=viewthread\&tid=353
(出处: 金双石科技)