目标:掌握更多命令行技巧和文本处理工具。
1. 管道和重定向
(1)输入输出重定向
- 输出重定向 (
>):将命令的输出写入到文件中,如果文件存在,则覆盖。
演示 :
- 输入重定向( <):将文件的内容作为命令的输入。
演示1:-w :计算output.txt 文件中的单词数

演示2:-l (统计 output.txt 文件中的行数)

- 追加重定向 (
>>):将命令的输出追加到文件末尾,不会覆盖文件内容。
演示:

(2)管道 (|)
管道将一个命令的输出作为另一个命令的输入,实现命令链的连接。
演示 : 在 output.txt 中查找包含 "Hello" 的行
2.文本处理工具
(1)grep:文本搜索工具
-
基本用法:
grep <pattern> <file> -
常用选项:
-i:忽略大小写-n:显示匹配的行号-v:显示不匹配的行
演示1 : 搜索 output.txt 文件中包含 "again" 的行
演示2 :-i : 搜索 output.txt 文件中包含 "Hello" 的行,忽略大小写
**演示3 :-n :**显示匹配的行号

**演示4 :-v :**显示不匹配的行

(2) sed:流编辑器
-
替换文本 :
sed 's/old/new/' <file> -
常用选项:
-i:直接修改文件内容g:全局替换
演示 1:将 output.txt 中的 "again" 替换为 "AGAIN",仅显示结果,不修改文件
注意 : output.txt 文件没有发生变化!
**演示2 : -i :**将 output.txt 中所有 "again" 替换为 "AGAIN" 并保存

(3) awk:文本处理工具
- 基本用法 :
awk '{print $1}' <file>,按列处理文本。
**演示 1 :**输出 output.txt 文件中每行的第1和第3列

**演示2 :**仅输出第3列值大于50的行的第1和第3列

3.文件查找和管理
(3) find:查找文件
-
基本用法:
find <path> -name <pattern> -
常用选项:
-type f:查找文件-type d:查找目录-size:按文件大小查找
演示1 : 在 /home/user 目录下查找所有 .txt 文件
**演示2 :**查找 /home/user 目录下大于1MB的文件

演示3 : 在 /home/user 目录下,查找所有子目录
该命令会列出 /home/user 目录及其子目录中所有的目录名称。

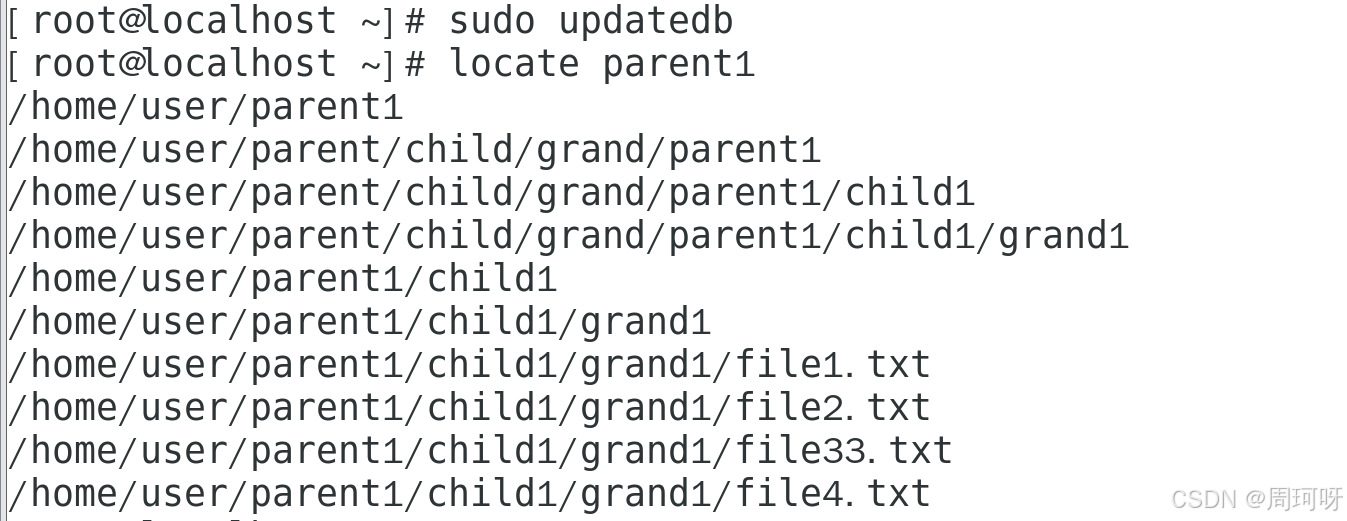
演示4 : 查找名称为 parent1 的目录:

演示5:查找包含"grand"字样的目录

(4) locate:快速查找文件
- 使用
locate查找文件,需要先更新数据库:
**演示 :**查找所有包含 "parent1" 的文件路径
4. 压缩和解压缩
(1)tar:打包和解包
-
打包文件 :
tar -cvf <archive.tar> <file/dir> -
解包文件 :
tar -xvf <archive.tar>
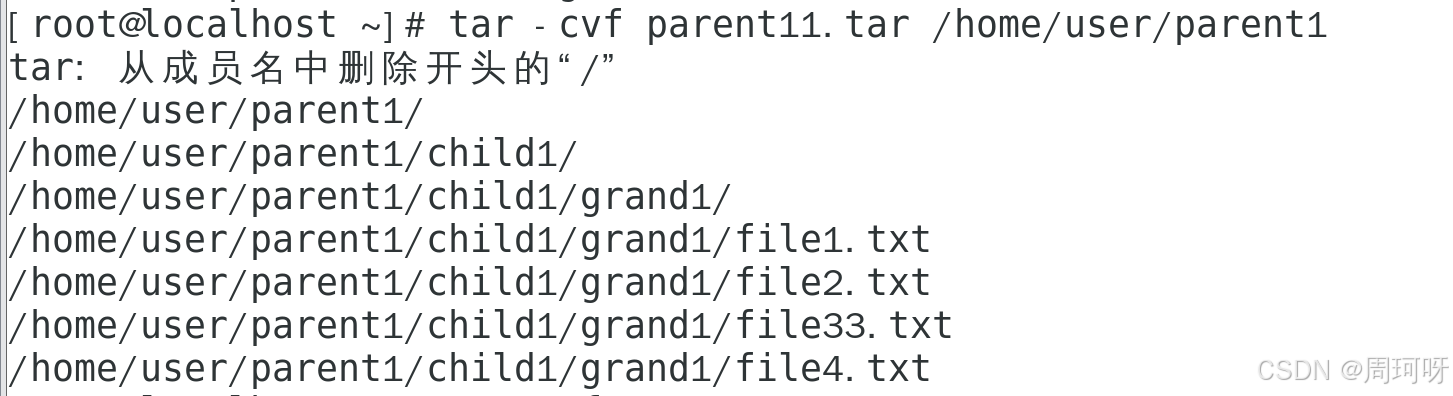
**演示1:**将 /home/user/parent1 目录打包为 parent11.tar
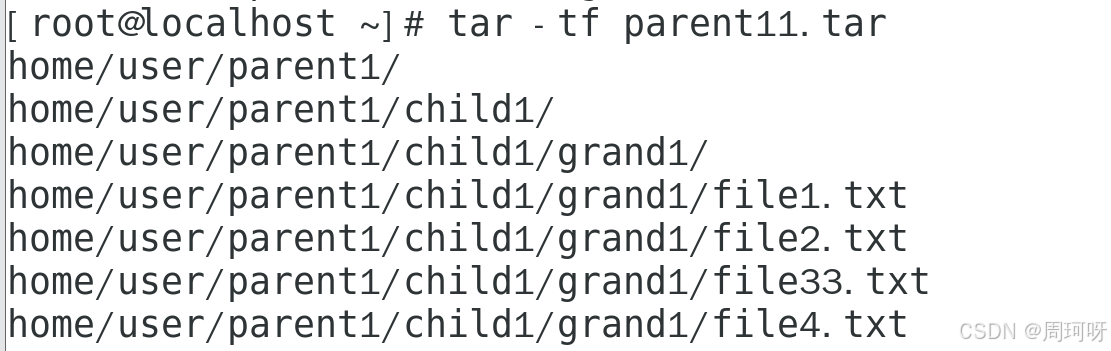
**演示2 :**使用 tar -tf parent11.tar 查看打包文件的内容
**演示3 :**解包 parent.tar 文件

(2)gzip 和 gunzip
- 压缩文件 :
gzip <file>
演示 1: 压缩 archive.tar,生成 archive.tar.gz 并查看

演示 2: 使用 tar -tf 查看 .tar.gz 文件内容
由于 parent11.tar.gz 是一个 .tar 文件经过 gzip 压缩后的产物,你可以使用 tar -tf 直接查看其中的内容,而不需要解压文件:
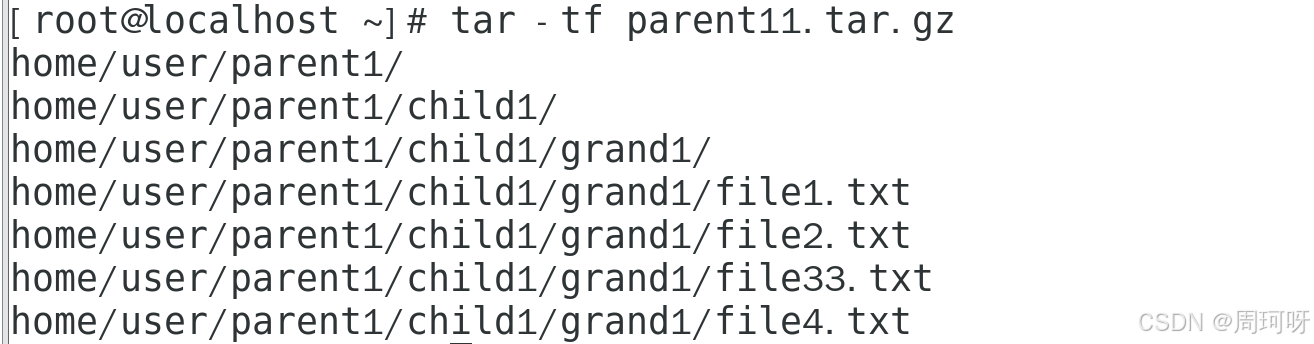
- 解压文件 :
gunzip <file.gz>
演示2 : 使用 gunzip 解压了 parent11.tar.gz 文件 并使用 tar -tf 命令查看parent11.tar
(3)zip 和 unzip
- 压缩文件 :
zip <archive.zip> <file>
演示 : 将 file1 和 file2 压缩为 File.zip
- 解压文件 :
unzip <archive.zip>
**演示 :**解压 File.zip 文件

PS : 因为我这里当前路径下已经有 file1.txt 和 file2.txt 了,所以在我执行 unzip File.zip 命令后,系统提示是否要替换 file1.txt 和 file2.txt。我这里选择了 y(yes)替换, unzip 将压缩包中的文件解压并覆盖当前目录中已有的 file1.txt 和 file2.txt 文件。
5. 基础的 Shell 脚本
(1)编写简单的 Shell 脚本
Shell 脚本通常以 .sh 为后缀,第一行包含 #!/bin/bash 表示使用 Bash 解释器。
- 示例脚本:
演示1 :
1.1 创建文件 script.sh
1.2 在 nano 编辑器中输入以下内容:
#!/bin/bash
echo "Hello, World!"
#!/bin/bash 指定了脚本使用 Bash 解释器。
echo "Hello, World!" 会输出 "Hello, World!"。
1.3 在 nano 中,按 Ctrl + O 保存文件,按 Enter 确认 。
1.4然后回车并按 Ctrl + X 退出编译器。
1.5 现在,文件 script.sh 已经存在,可以运行 chmod +x 来赋予执行权限:

1.6 赋予执行权限后,可以直接运行脚本:

(2)变量
- 定义变量:
2.1 使用 nano 编辑文件:

2.2 使用变量:

在 nano 中,按 Ctrl + O 保存文件,按 Enter 确认 。
然后回车并按 Ctrl + X 退出编译器。
2.3 运行脚本:

PS:
确保脚本有执行权限(如果之前没有执行过此操作):chmod +x script.sh
(3)条件语句(if)
- 基本格式:
演示1 : 使用 nano 编辑文件并输入
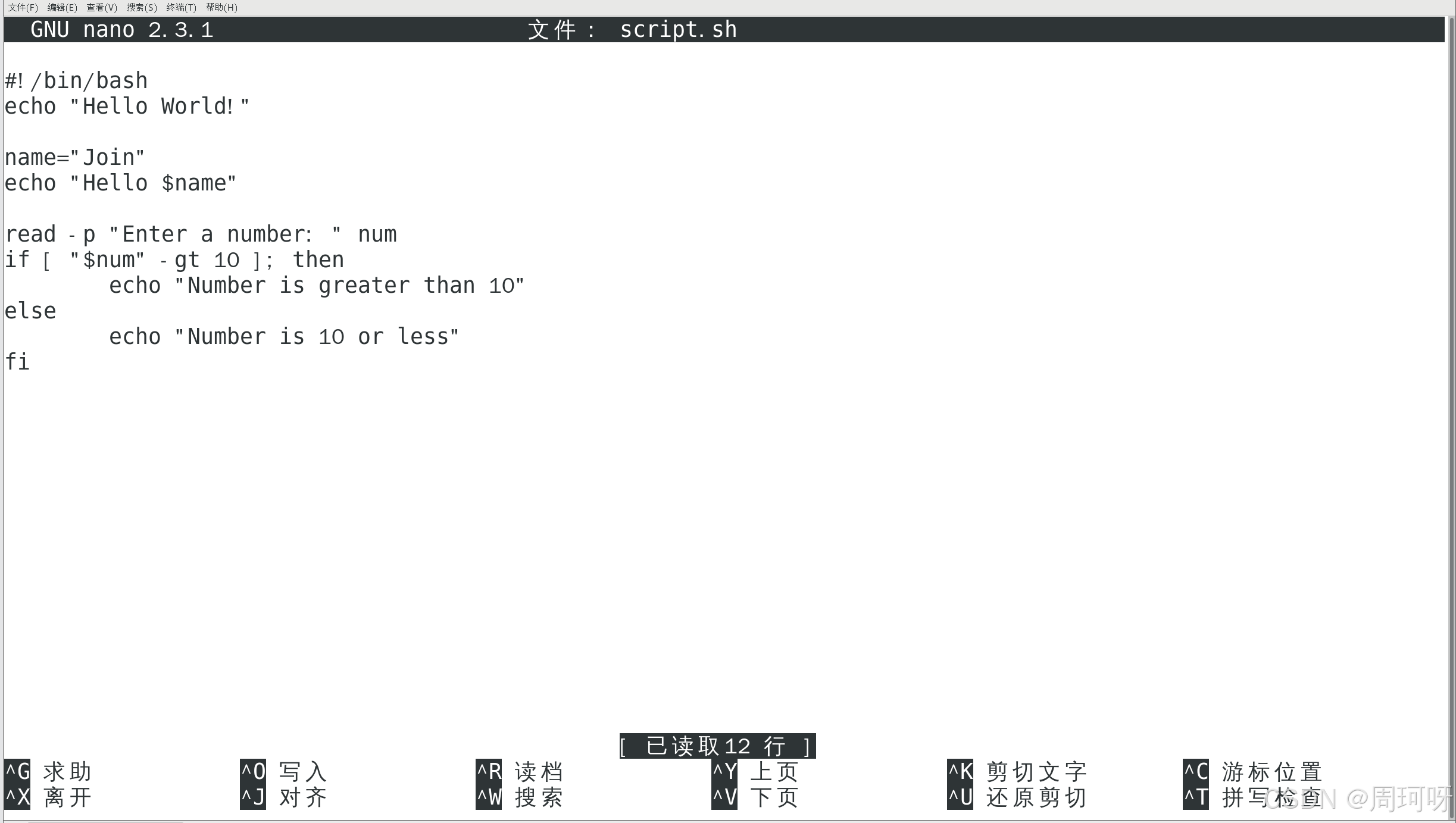
解释:
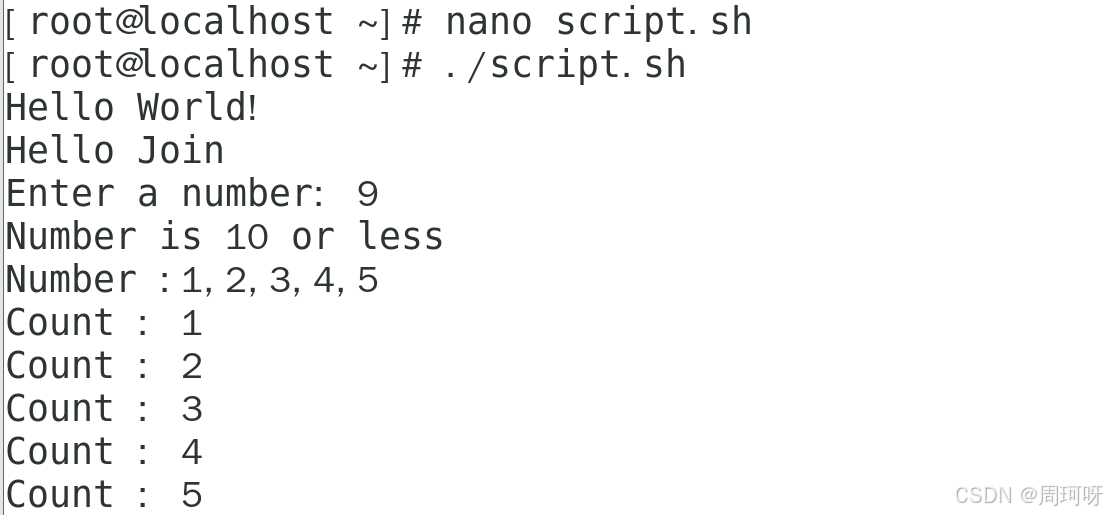
read -p "Enter a number: " num提示用户输入一个数字,并将其存储在num变量中。if [ $num -gt 10 ];:检查num是否大于 10。else:如果num不大于 10,则执行这一部分的代码。fi:结束条件语句。
PS: "$num" 的两边,一定要有空格!
演示2 : 输出示例

(4)循环
for 循环:
演示1 : 使用 nano 编辑文件并输入
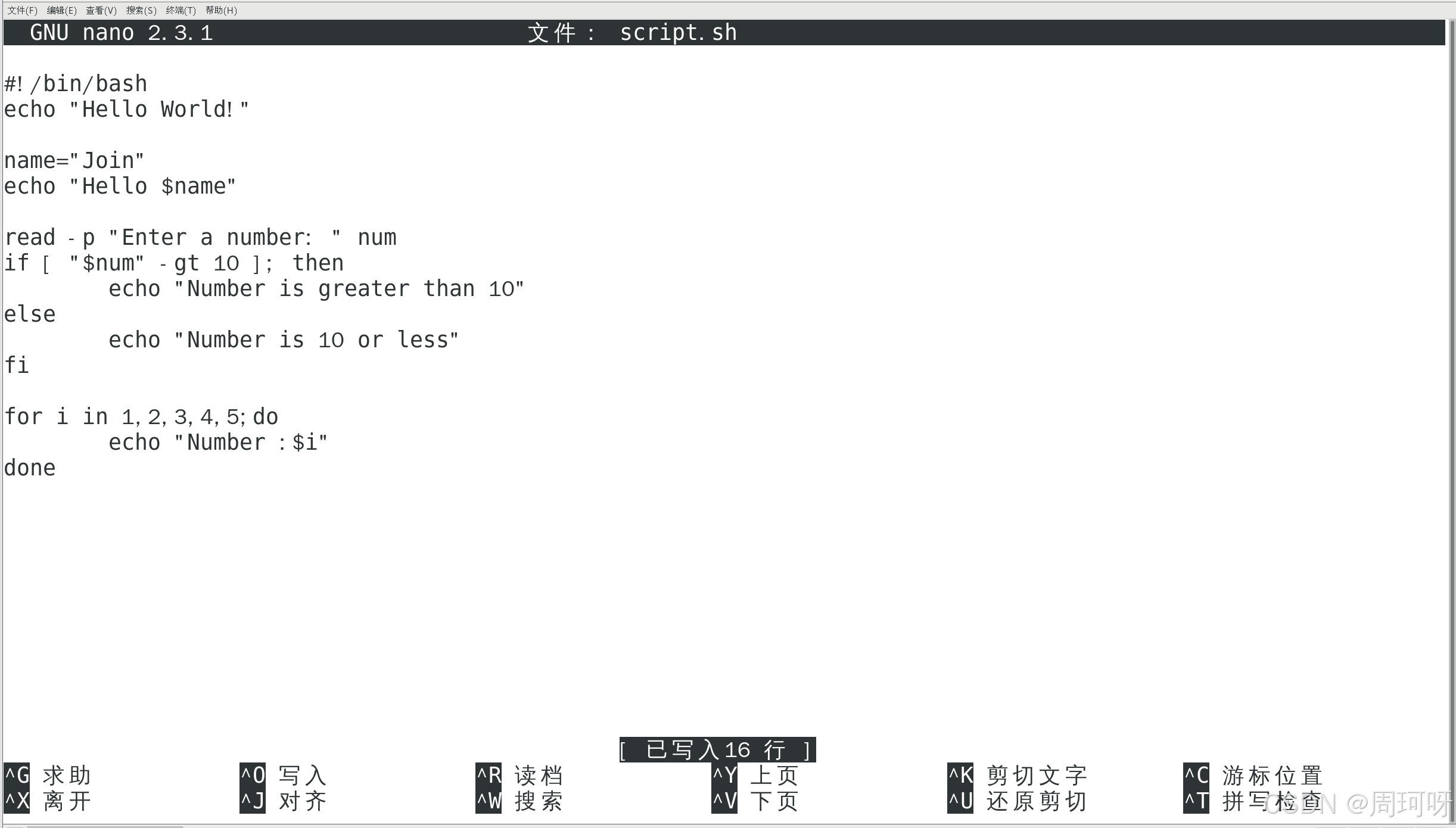
解释:
for i in 1 2 3 4 5;定义循环,变量i依次取 1 到 5 的值。do ... done包含了循环体的代码,echo "Number: $i"输出当前的i值。
演示2 : 输出示例

while 循环:
演示1 :使用 nano 编辑文件并输入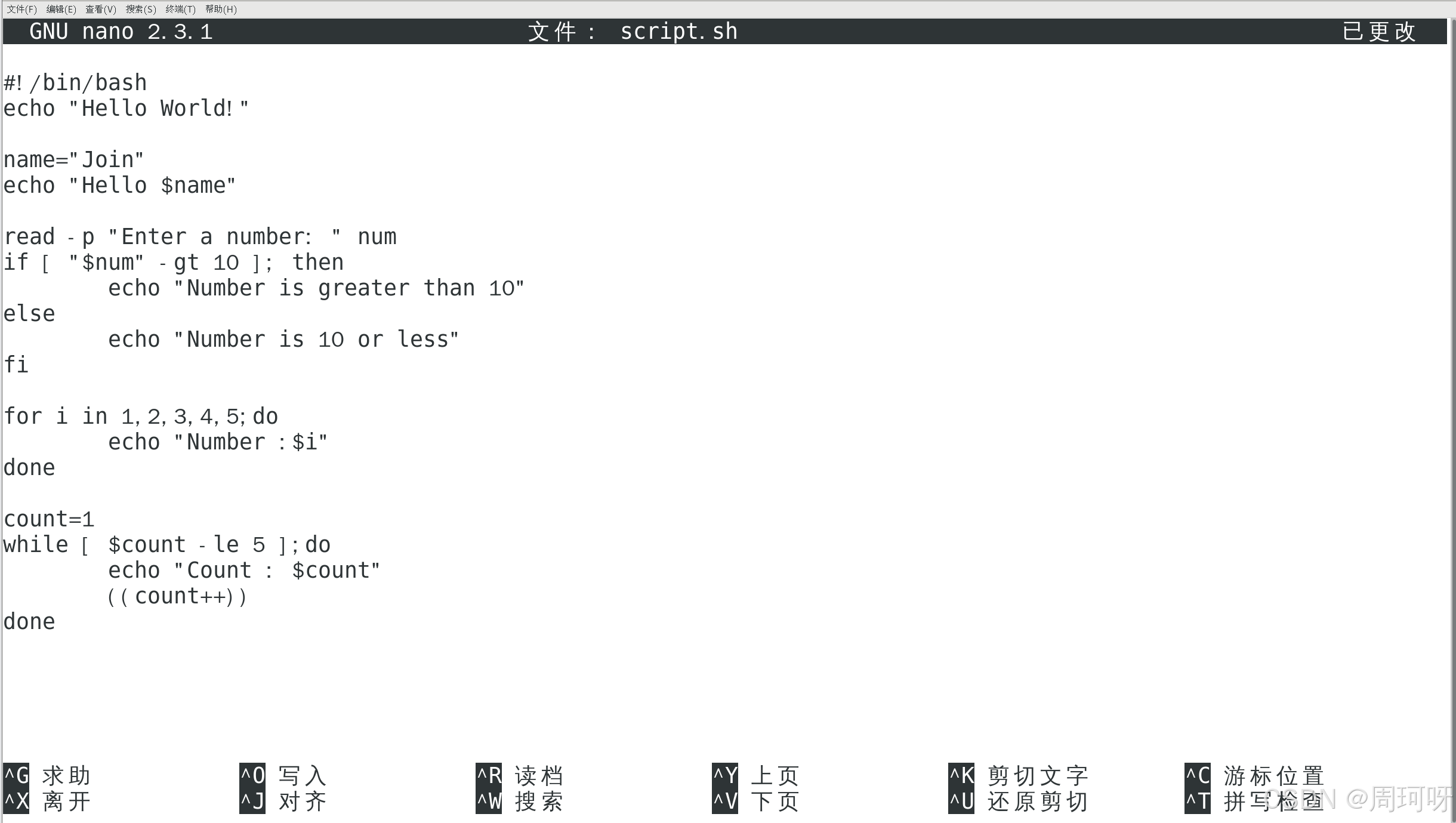
解释:
count=1初始化变量count为 1。while [ $count -le 5 ];:当count小于或等于 5 时,执行循环体中的代码。((count++)):将count增加 1。do ... done包含了循环体的代码,echo "Count: $count"输出当前的count值。
演示2 : 输出示例