Flink 大数据实战演练01
在学习大数据时可能会遇到自己一身本领,却苦于没有好的数据集,让自己有个完美的用武之地。自己造数据存在一些列问题。
-
数据不够真实
-
数据量不够,无法体现"大数据"优势
-
数据质量差无法评估分析效果
本系列主要内容
-
总体技术架构
-
数据介绍
-
分析目标
-
技术准备
-
实现细节
-
踩坑记录
总体技术架构
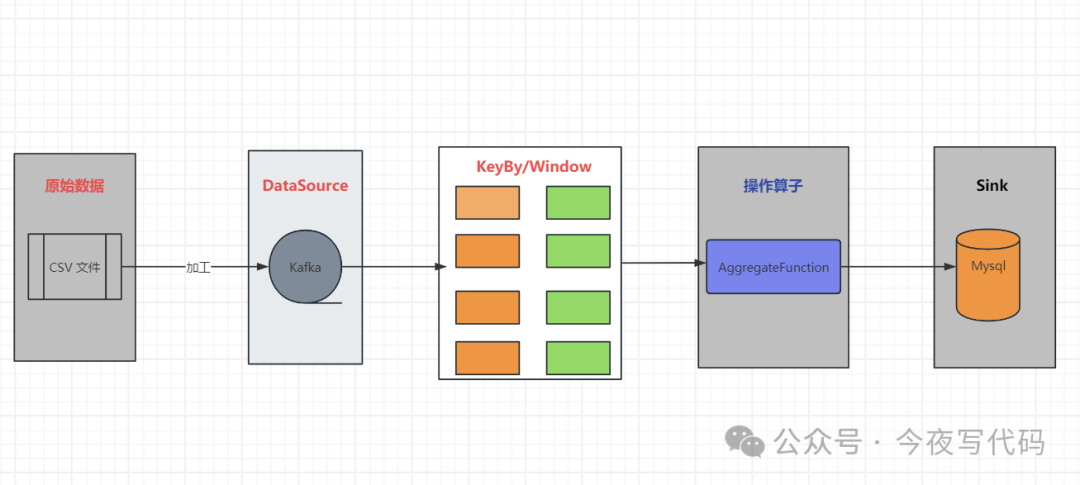
技术架构图
数据集介绍
-
数据来源 kaggle 官网有丰富的数据,可以选择感兴趣的进行处理
-
数据总量 1.6G , 总记录 1615940
原始数据中包含23列,以下是重要字段介绍
| 字段 | 描述 | 示例值 |
|---|---|---|
| Job Id | 1089843540111562 | |
| Experience | 工作年限 | 5 to 15 Years |
| Qualifications | 资历 | M.Tech |
| Salary Range | 薪资范围 | 99K |
| location | 位置 | Douglas |
| Country | 国家 | Isle of Man |
| Work Type | 工作类型 | Intern |
| Company Size | 公司规模 | 26801 |
| Job Posting Date | 岗位发布日期 | 2022-04-24 |
分析目标
先定一个小目标,分析不同年份,不同工作年限的平均薪资情况,以评估行情走势。(刚开始以跑通整个流程为主,后面再丰富不同的分析场景)
技术准备
CSV通常纯文本操作就可以解析,本文下载的原始文件中字符串包含一些分隔符,比如某单元格内容是 "Hello ,World" ,如果自己处理这些逻辑比较复杂, 我们需要一款好用的开源的CSV解析工具。
我们将原始数据加工发送到Kafka 中,分析任务用kafka作为数据源,每隔一段时间统计一次(比如一小时,甚至一天)。因此我们还可能用到Windows , Flink 一些聚合操作。我们将最终统计结果保存到数据库,我们可以自定义Sink ,也可以使用JDBC SinK
- CSV 解析
本文选用opencsv,解析csv文件。
XML
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.4</version>
</dependency>- Kafka Source 使用
引入依赖
XML
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.4</version>
</dependency>使用Demo
java
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(Constants.BOOTSTRAP_SERVER)
.setTopics(Constants.TOPIC)
.setGroupId(Constants.CONSUMER_GROUP)
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");- Window
考虑到数据不能被重复计算,因此我们选用Tumbling Window ,由于我们是每一天或者每小时处理一次,这里的时间是"机器时间",所以应当使用 ** TumblingProcessingTimeWindows ** 而非TumblingEventTimeWindows
聚合操作Function 我们选择AggregateFunction
- Sink
可以使用 JDBC Sink , 也可以简单自定义Sink 。
无论自定义Sink 还是使用已有的JDBC Sink,不可避免和JDBC相关API 打交道。(简单起见,不引入MyBatis 框架,也不使用Spring)
这些代码相信已经勾起大家沉睡的记忆
java
PreparedStatement ps = ...
ps.setString(1,value.getYear());
ps.setInt(2,value.getExperience());
ps.setInt(3,value.getCount());
double avgSalary = value.getSumSalary()/value.getCount();
ps.setDouble(4,avgSalary);
ps.setDouble(5,value.getSumSalary());项目结构
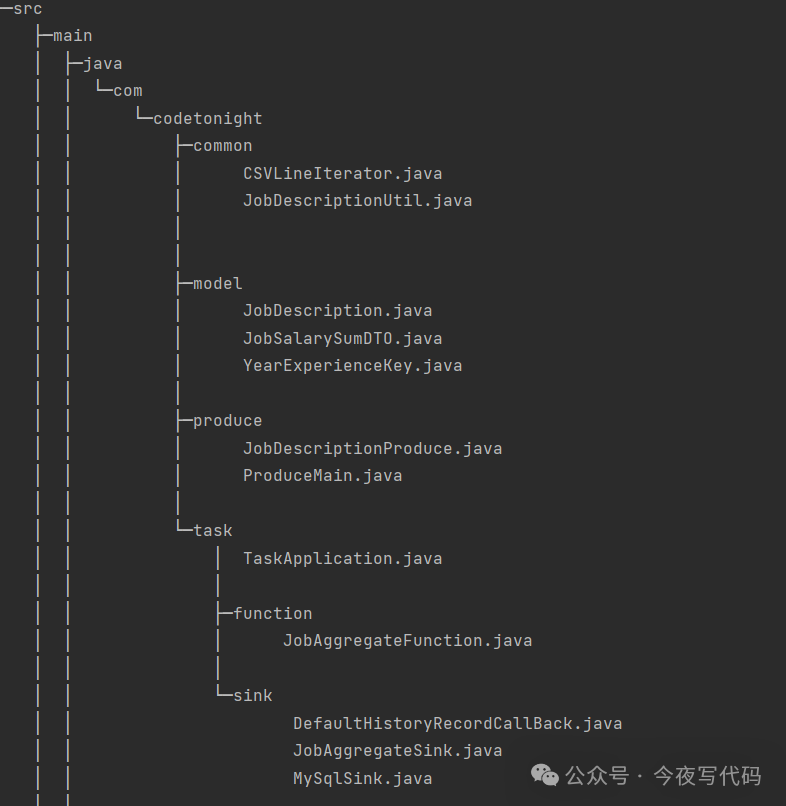
项目结构
最终分析结果示例数据
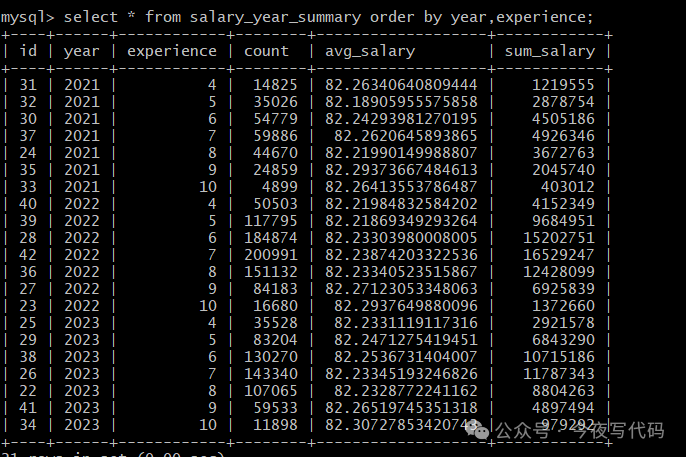
本文总结
限于篇幅本文主要确定总体技术架构,技术选型,下期继续实现细节和踩坑记录总结