🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨Github项目:https://github.com/alldatacenter/alldata
✨Gitee项目:https://gitee.com/alldatacenter/alldata
✨AllData官方手册:https://www.yuque.com/aolingdata/product
✨AllData正式环境:http://43.138.156.44:5173/ui_moat
摘要:本文聚焦于云原生数据平台(Cloudeon),详细阐述了其核心服务组件的扩展情况,具体涵盖以下新增服务:
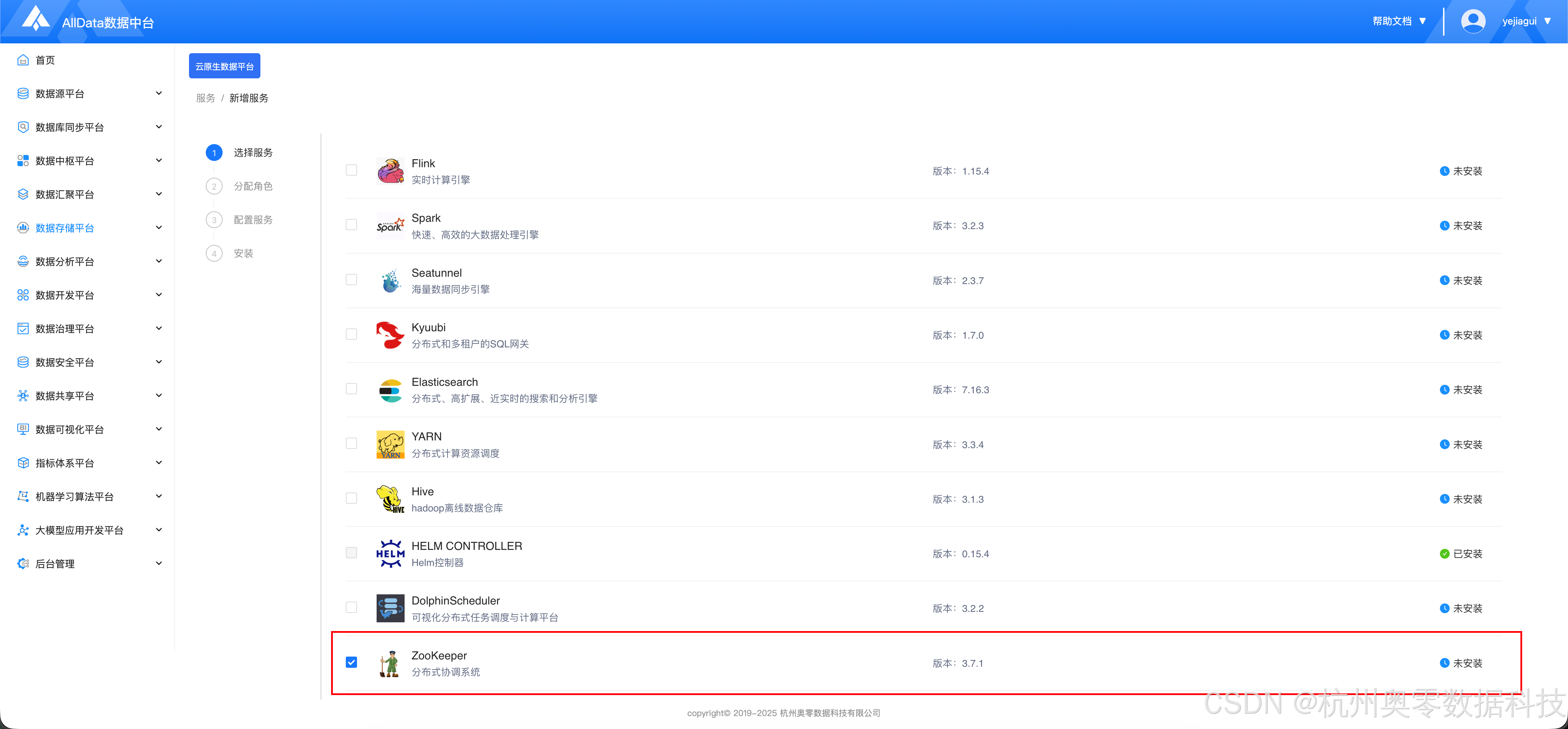
• 添加ZooKeeper服务
• 添加HDFS服务
• 添加FIink服务
• 添加YARN服务
• 添加doris服务

云原生数据平台基于开源项目CloudEon建设
- 基于开源项目CloudEon建设,简化kubernetes上大数据集群的运维管理,一款基于kubernetes的开源大数据平台,旨在为用户提供一种简单、高效、可扩展的大数据解决方案。
- CloudEon 将基于 Kubernetes的资源安装部署开源大数据组件,实现开源大数据平台的容器化运行,您可减少对于底层资源的运维关注。
- 功能特性快速搭建大数据集群容器化运行大数据服务支持监控告警等功能支持配置修改等功能自动化运维可视化管理界面
开源项目:https://github.com/dromara/CloudEon
更多教程可以参考官方教程文档:https://cloudeon.dromara.org/#/index
一、添加ZooKeeper服务
1.添加流程
1.1 进入新增服务页面,选择ZooKeeper
- 下滑到最下方,点击 "下一步"
1.2 分配角色
-
三节点
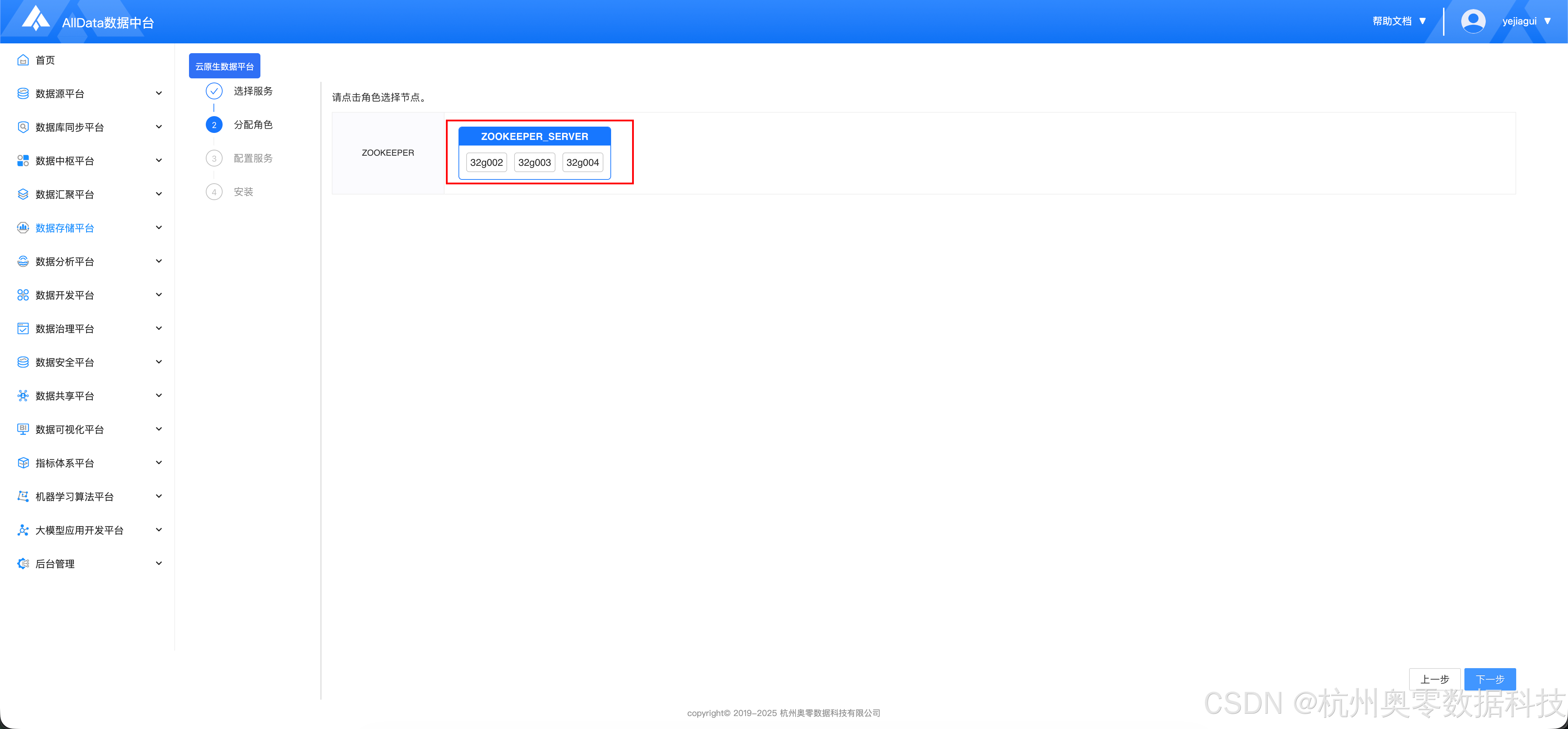
-
然后点击 "下一步"
1.3 初始化配置
- 默认配置即可
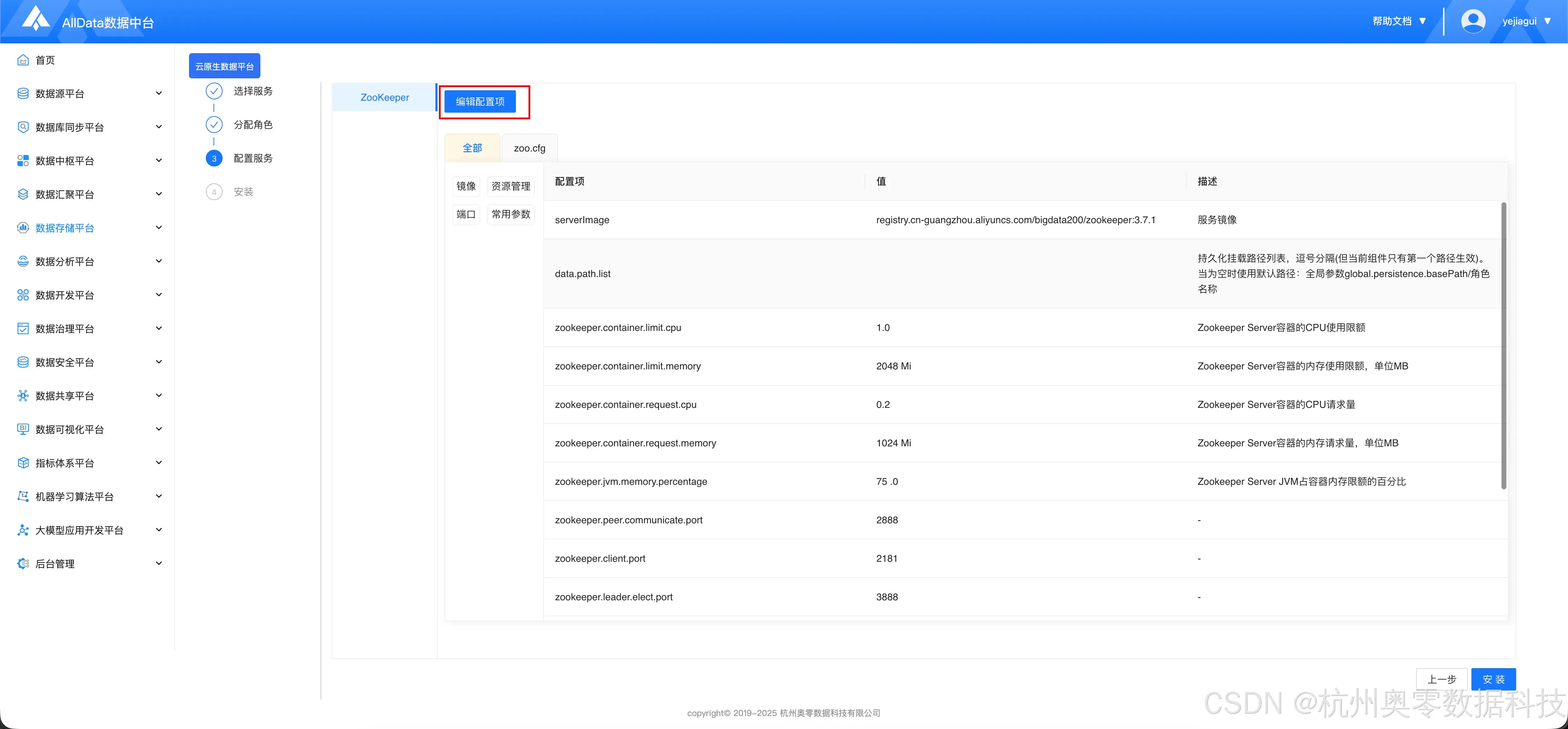
- 点击 "安装"
1.4 等待安装完成
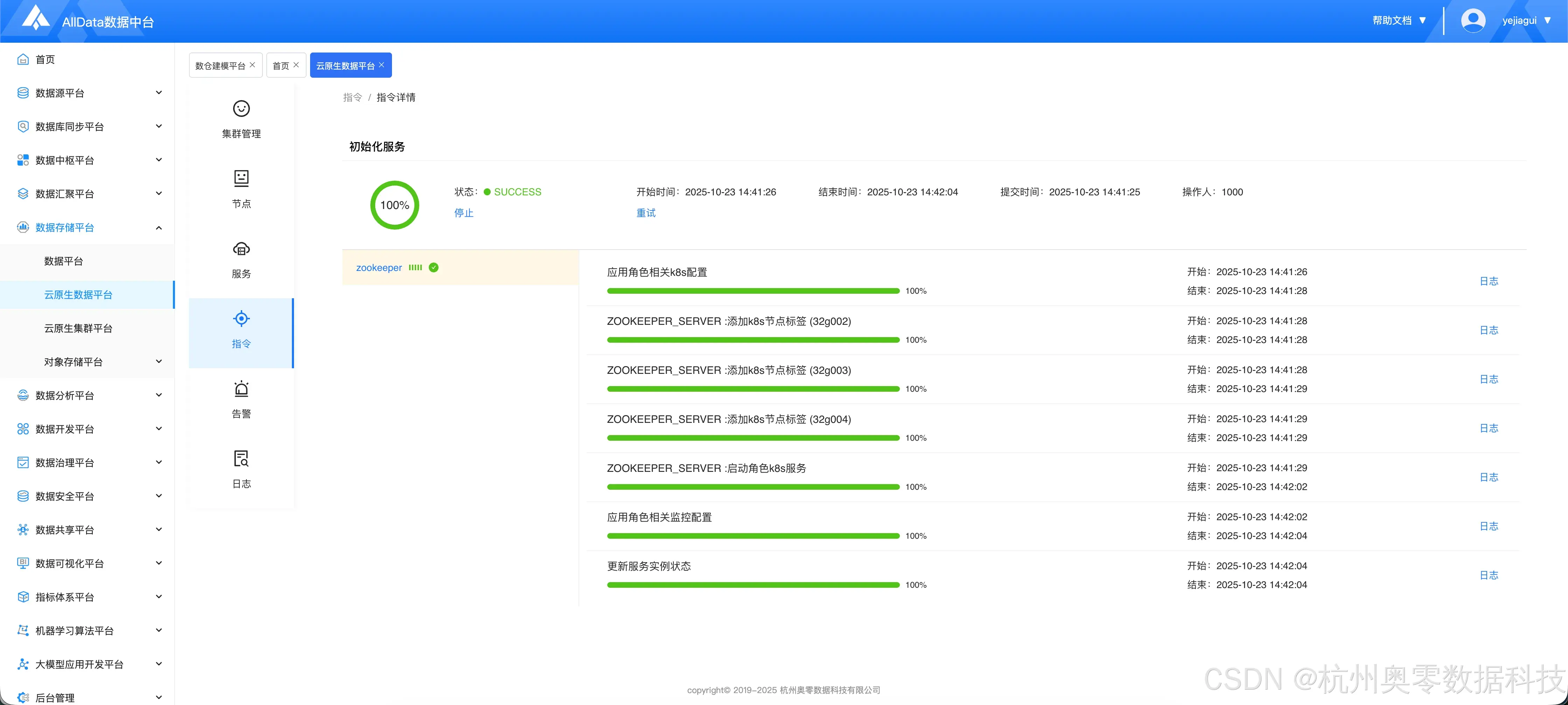
二、添加HDFS服务
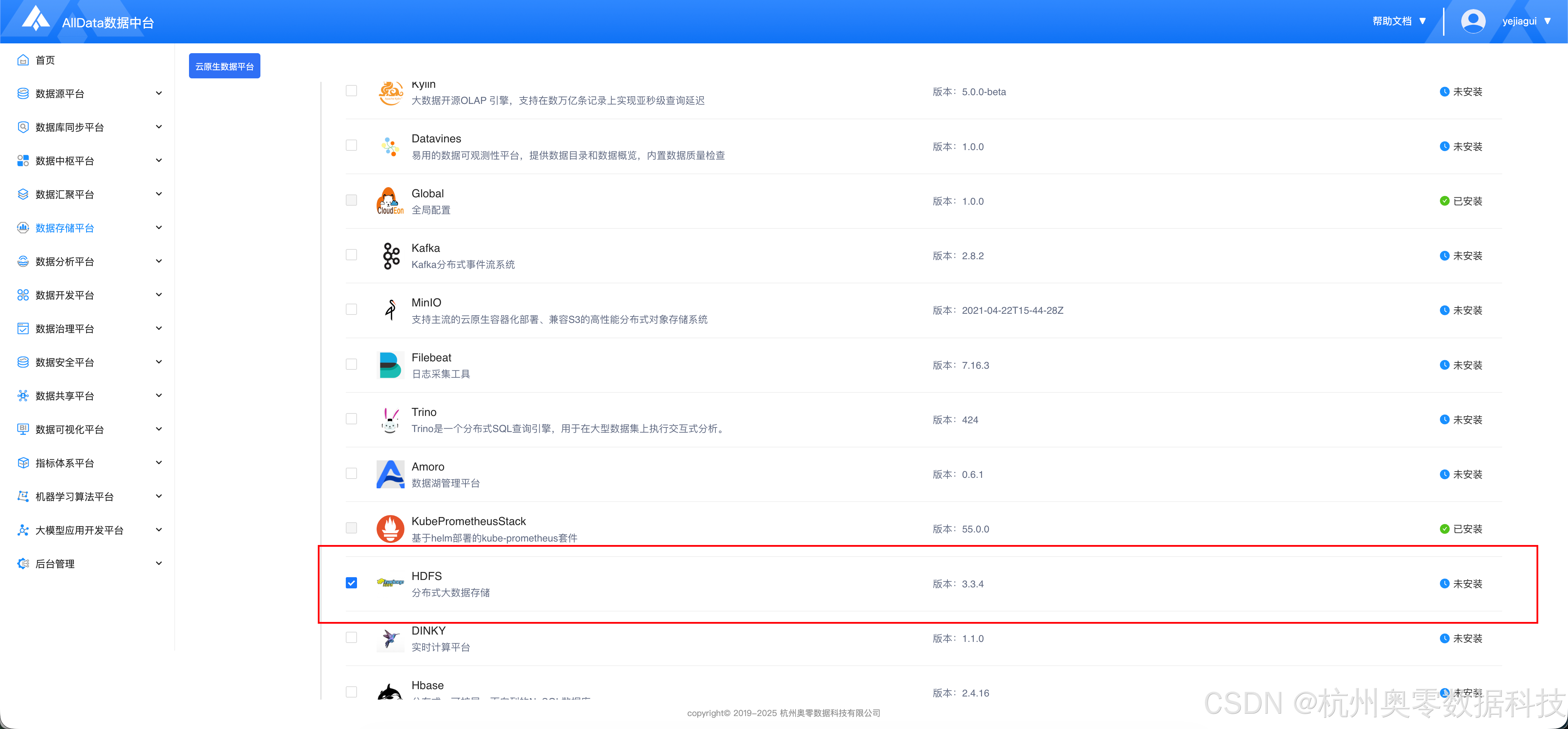
- 下滑到最下方,点击 "下一步"
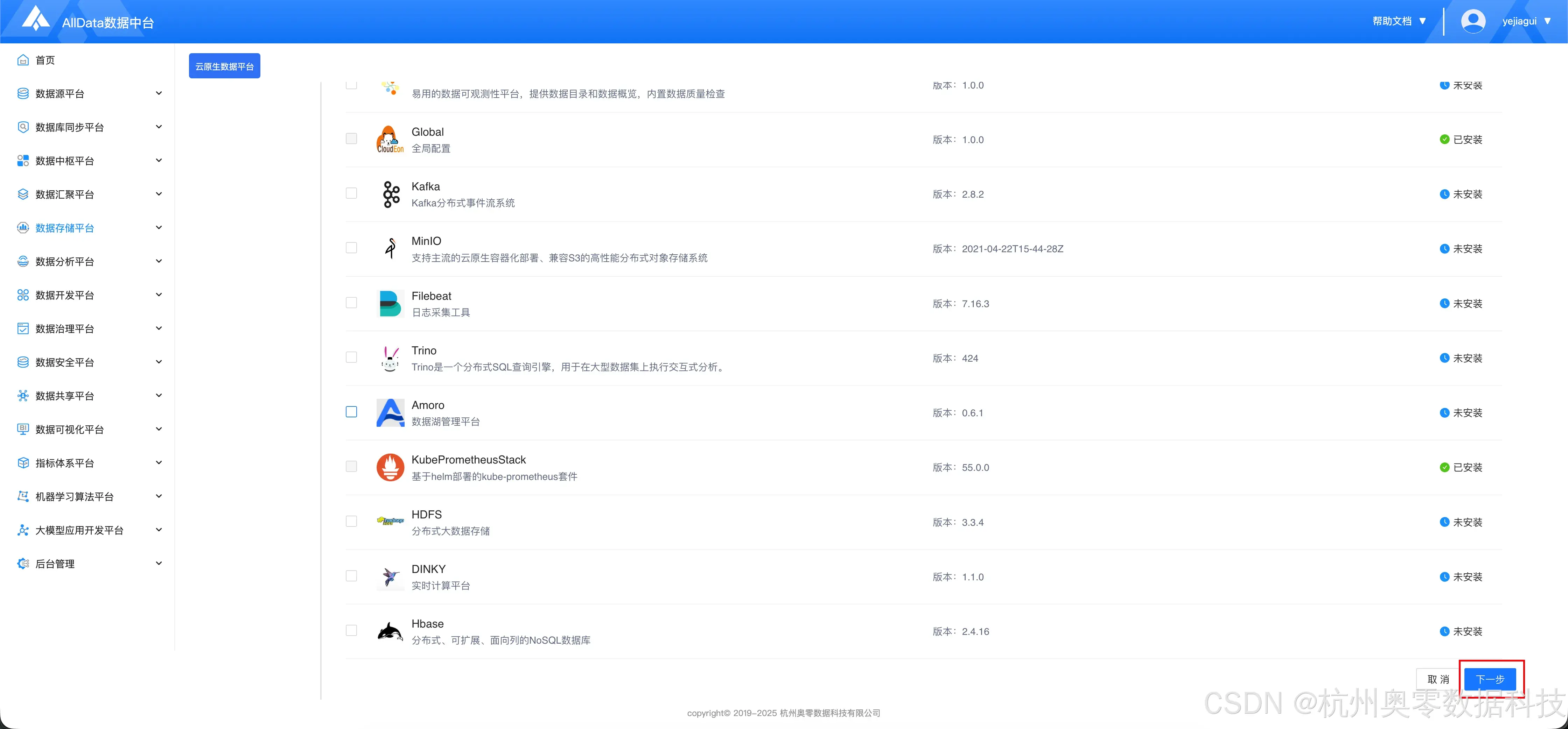
1.分配角色
- 配置相关节点,用户可根据实际情况自行修改
然后点击 "下一步"
2.初始化配置
- 默认配置即可,点击 "安装"
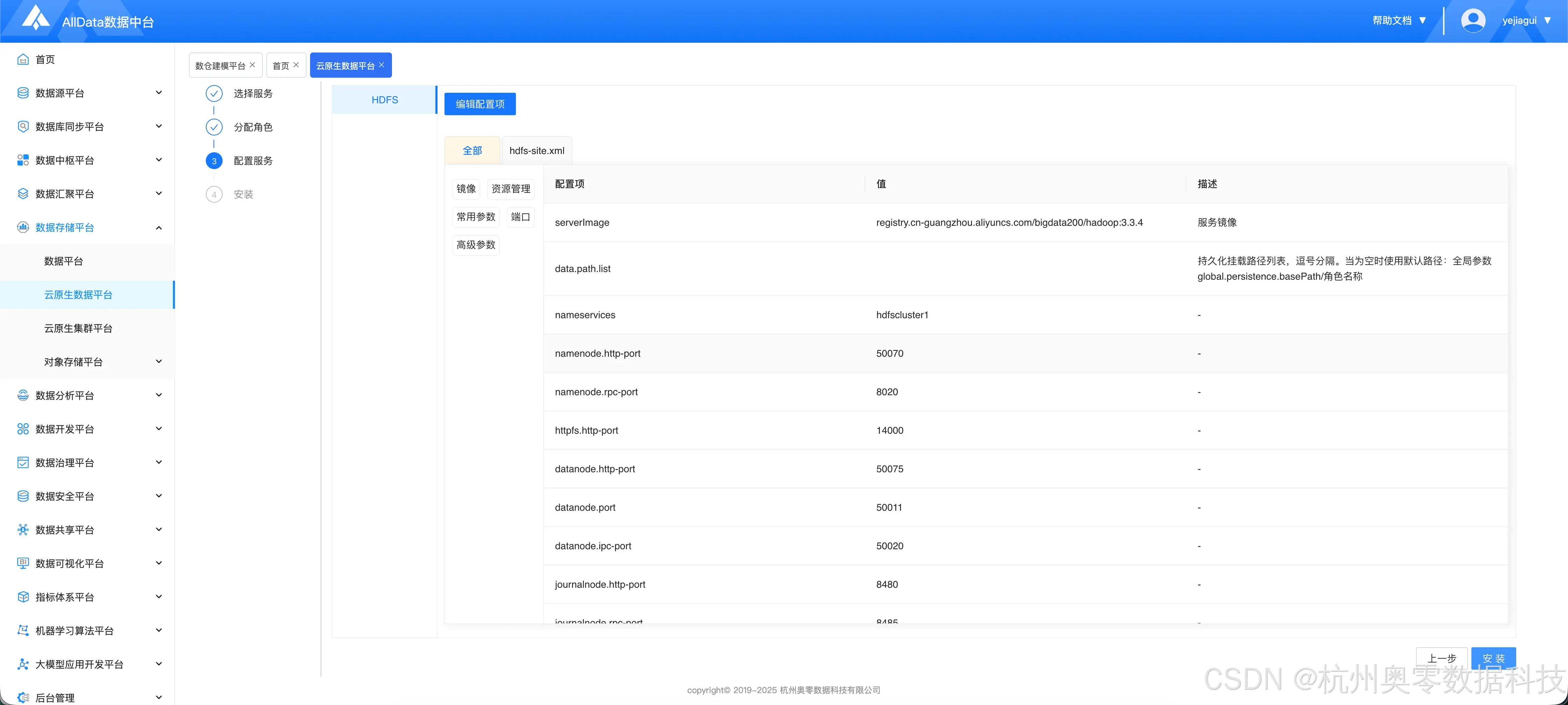
- 点击 "编辑配置项"
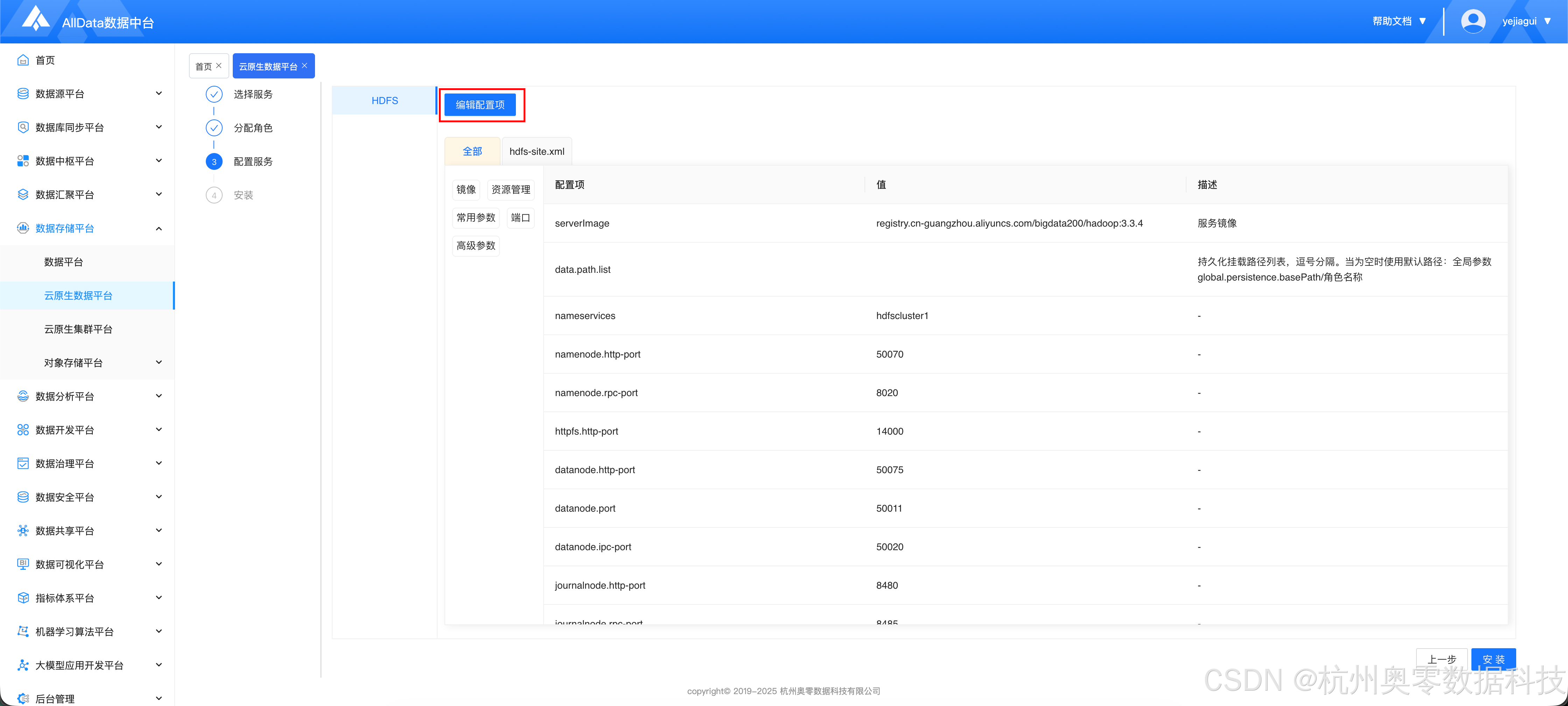
- 点击 "添加自定义配置"
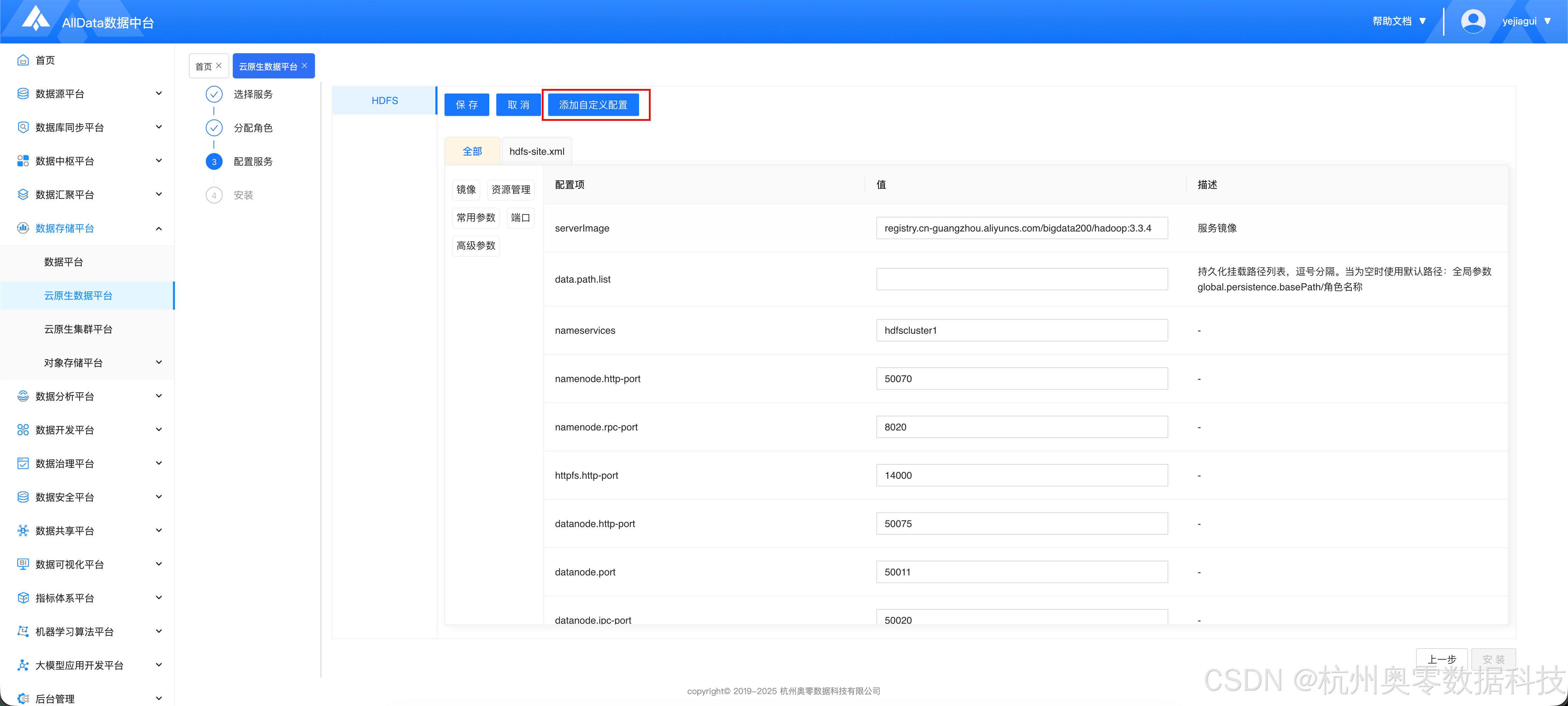
- 添加如下配
- dfs.namenode.http-address.hdfscluster1.nn1 = 0.0.0.0:50070
- dfs.namenode.http-address.hdfscluster1.nn2 = 0.0.0.0:50070
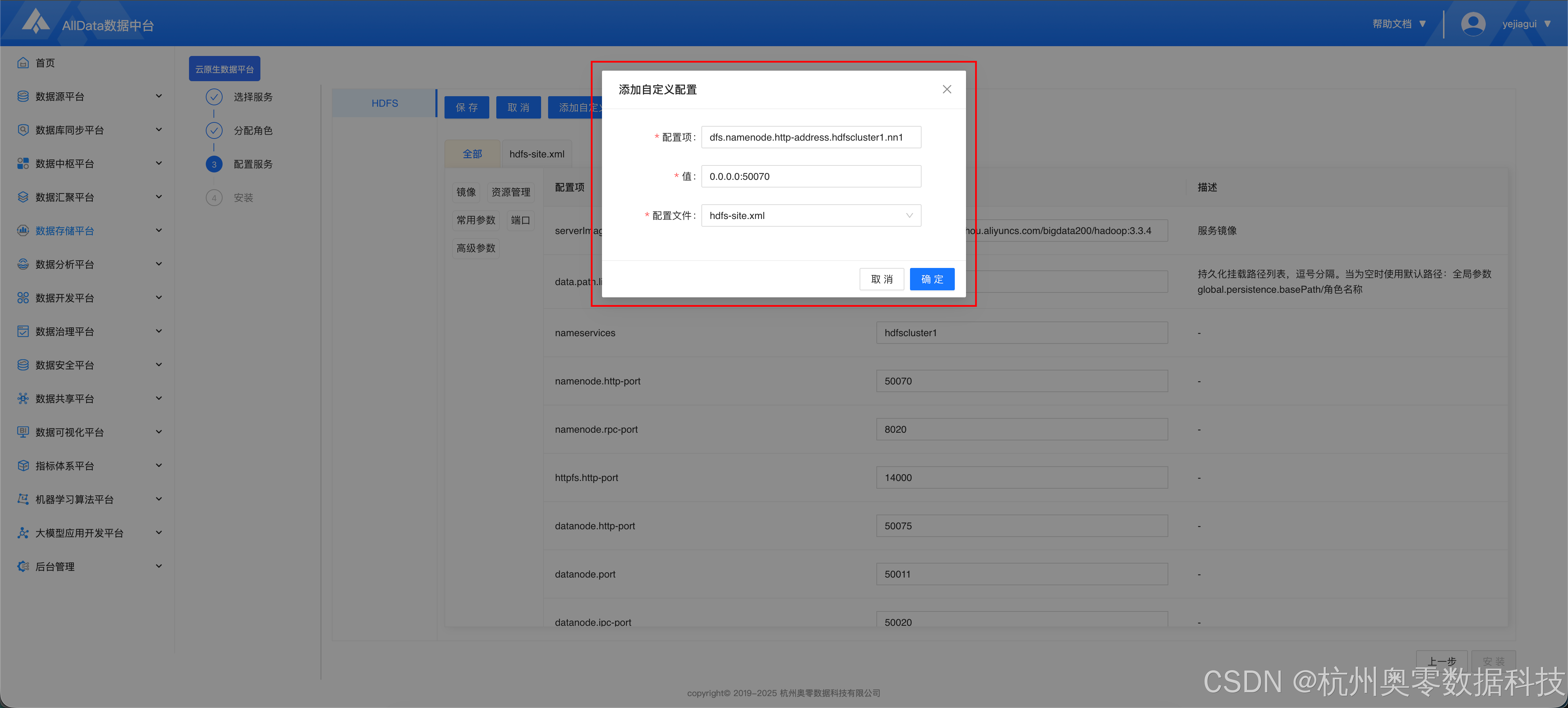
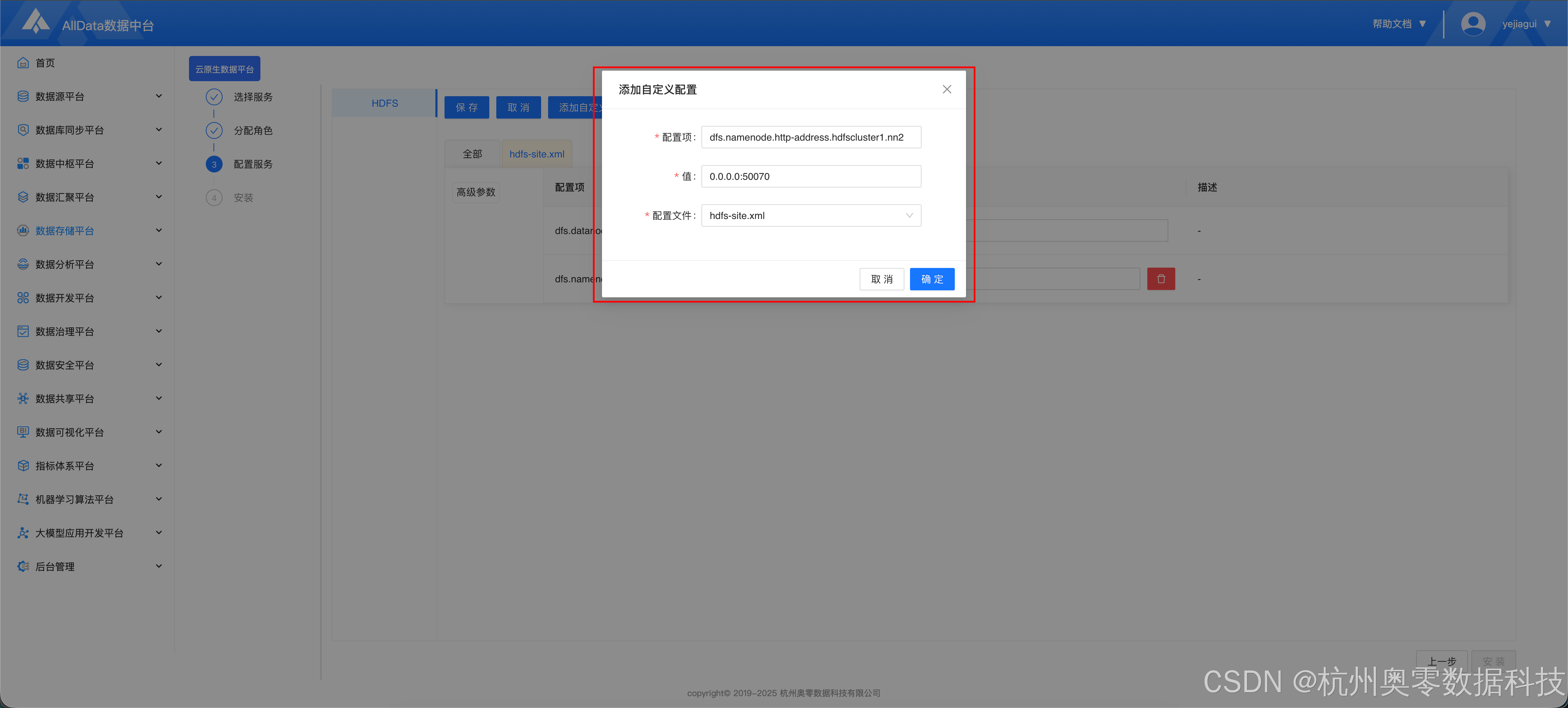
- 点击 "启动-安装"
3.等待安装完成
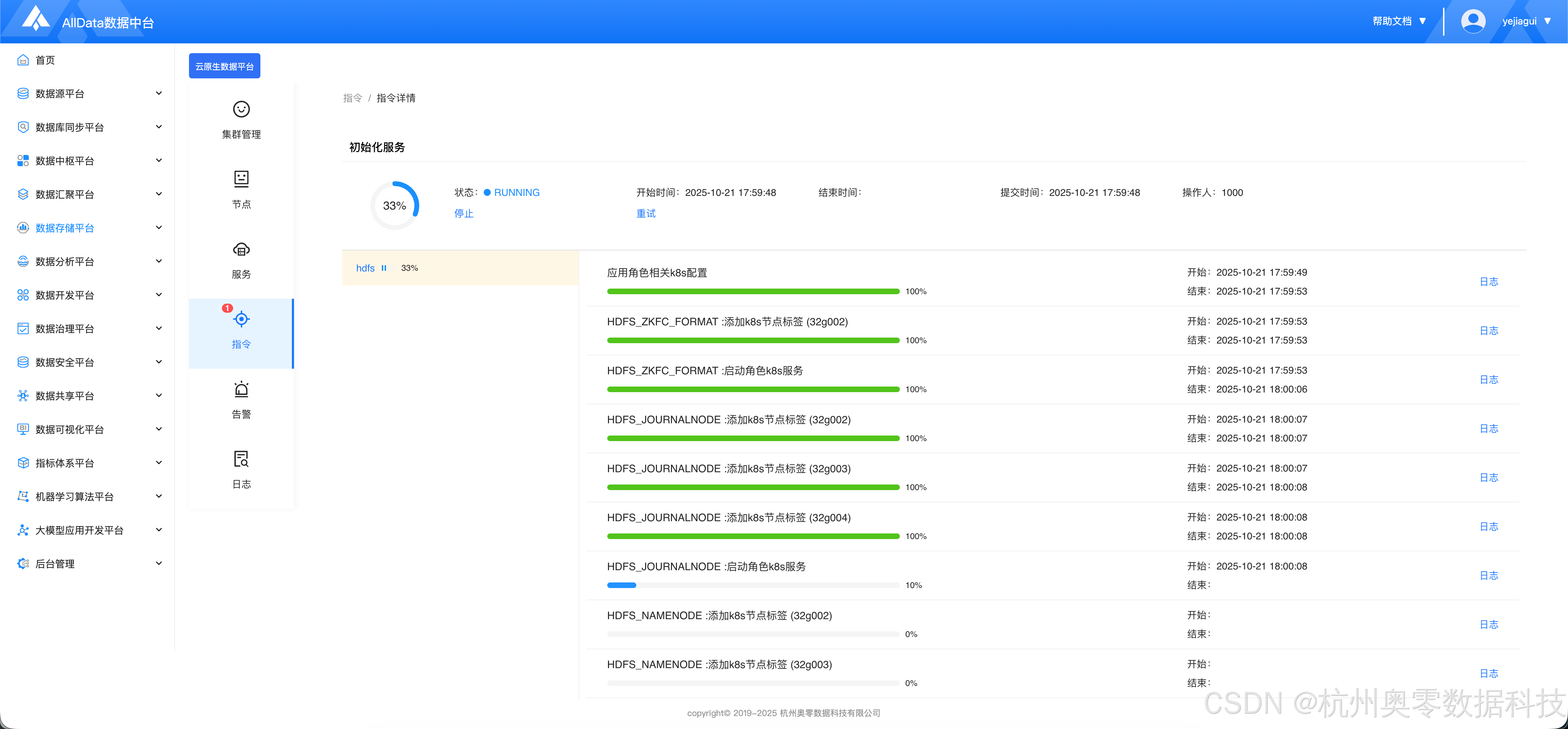
三、添加Flink服务
1.添加流程
1.1 进入新增服务页面,选择Flink
- 下滑到最下方,点击 "下一步"
1.2 分配角色
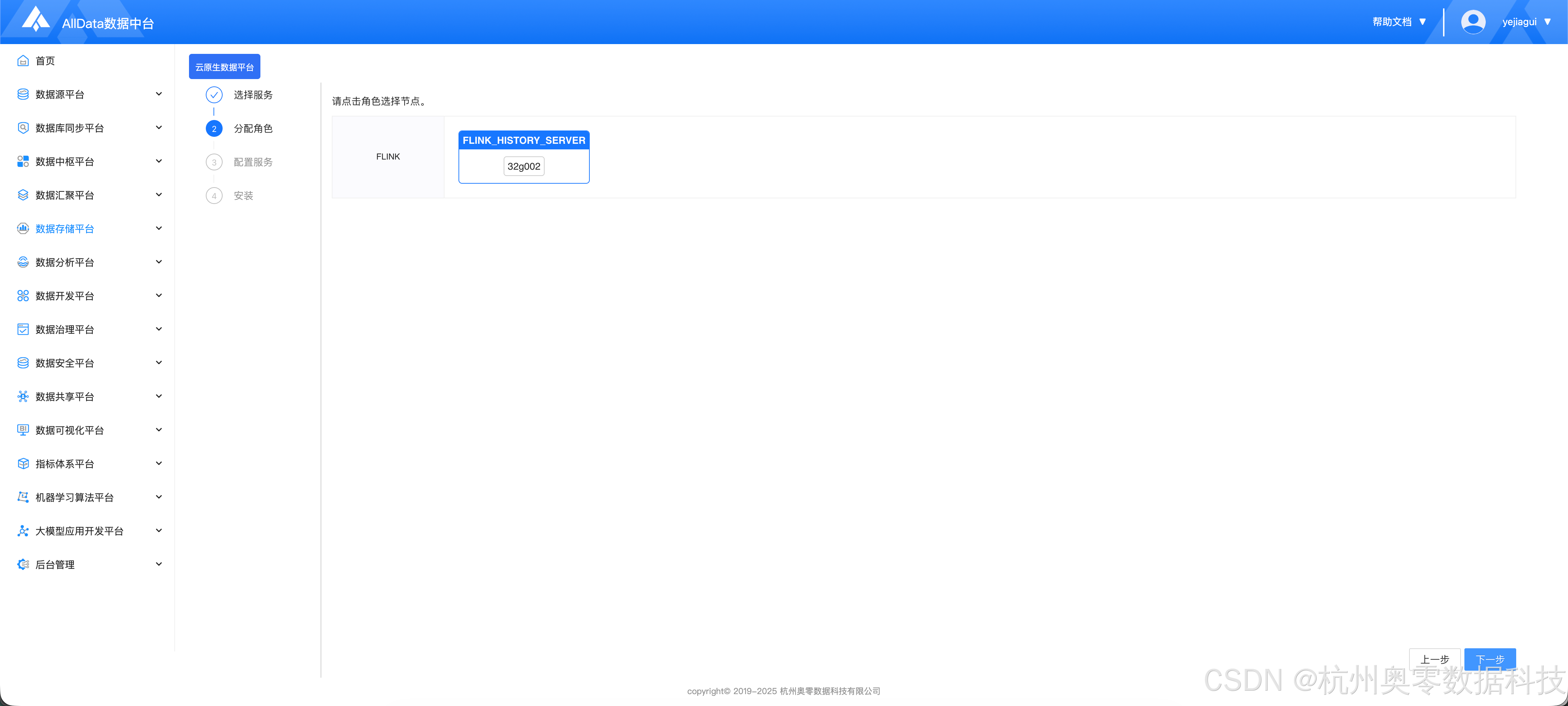
- 点击 "下一步"
1.3 初始化配置
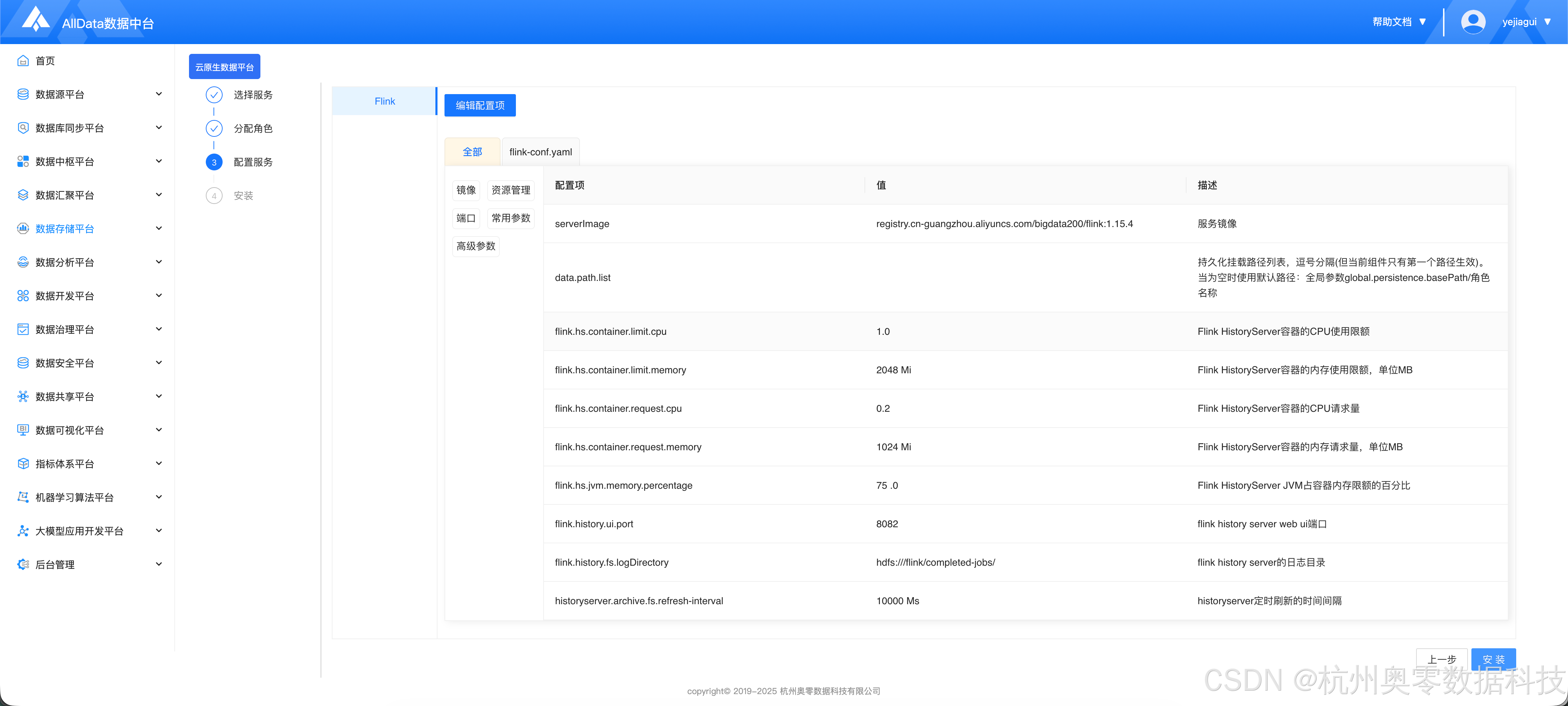
- 根据用户实际需求进行修改,无需求则按照默认即可
1.4 等待安装完成
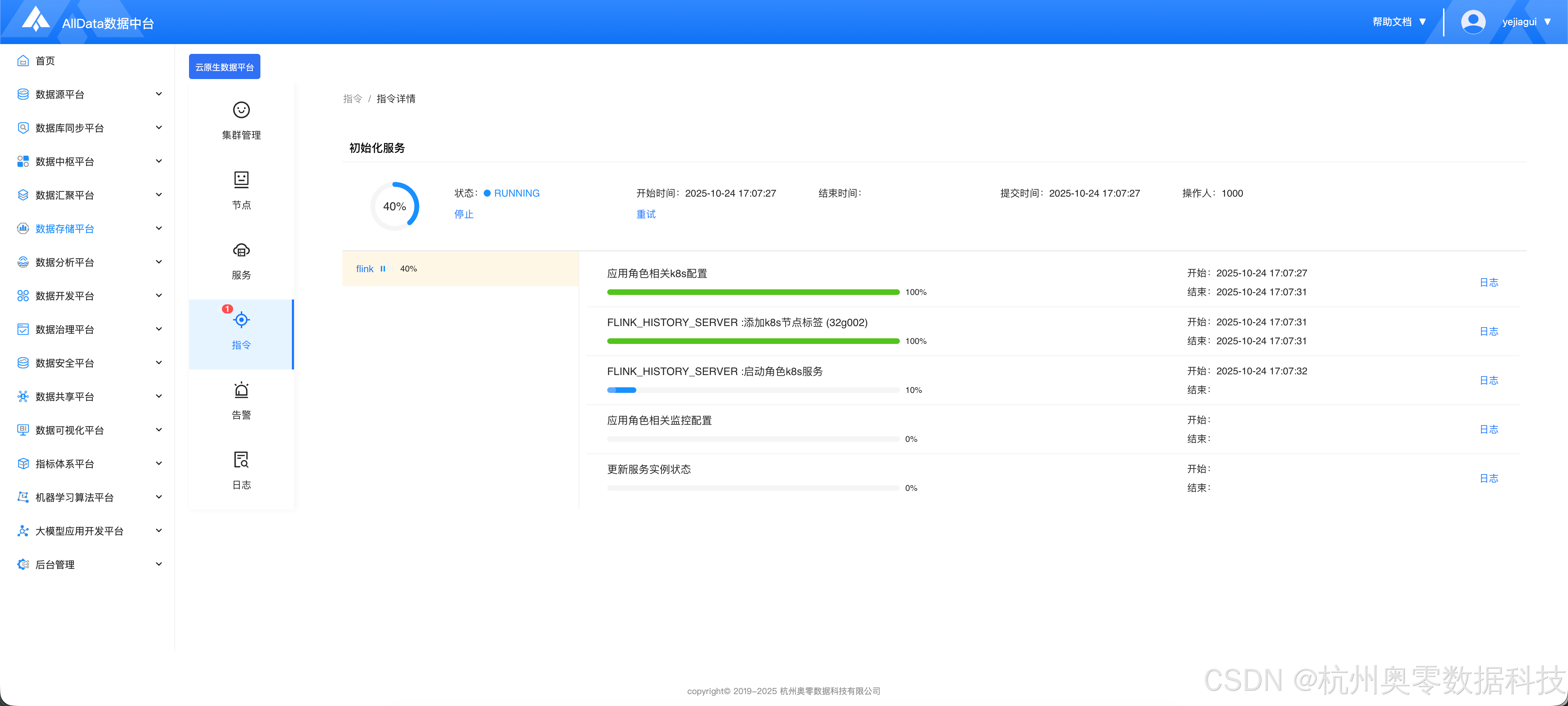
四、添加YARN服务
1.添加流程
1.1 进入新增服务页面,选择YARN
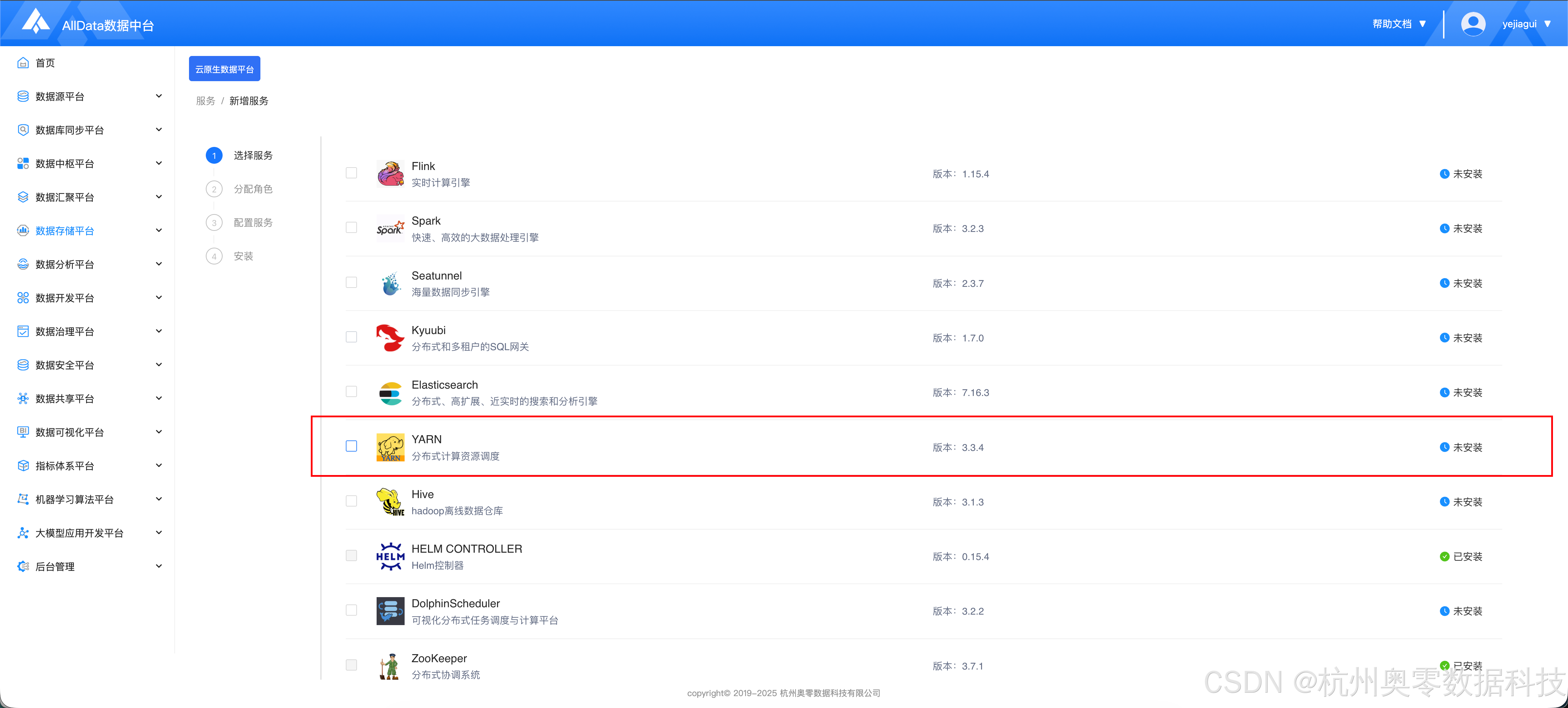
- 下滑到最下方,点击 "下一步"
1.2 分配角色
- 配置相关节点,用户可根据实际情况自行修改
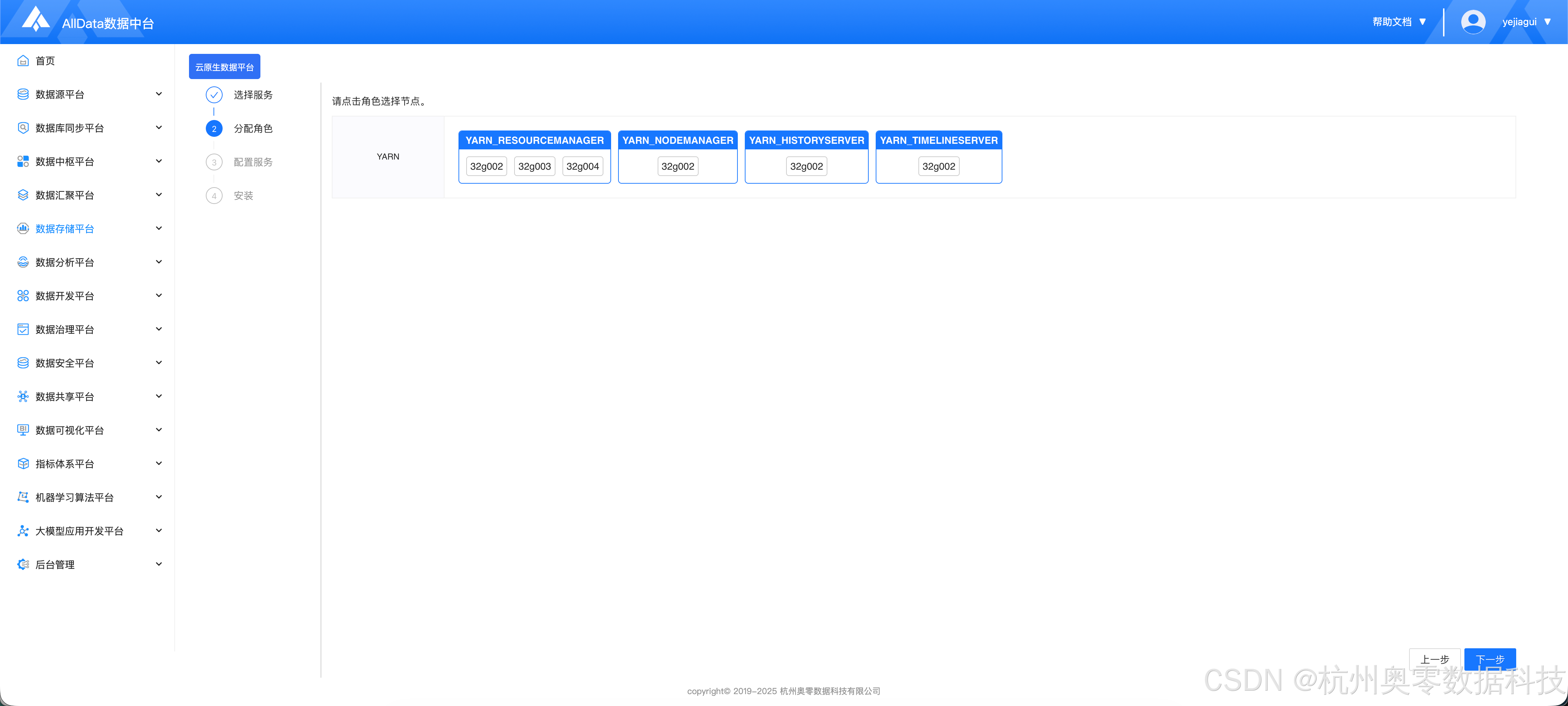
- 然后点击 "下一步"
1.3 初始化配置
- 默认配置即可,点击 "安装"
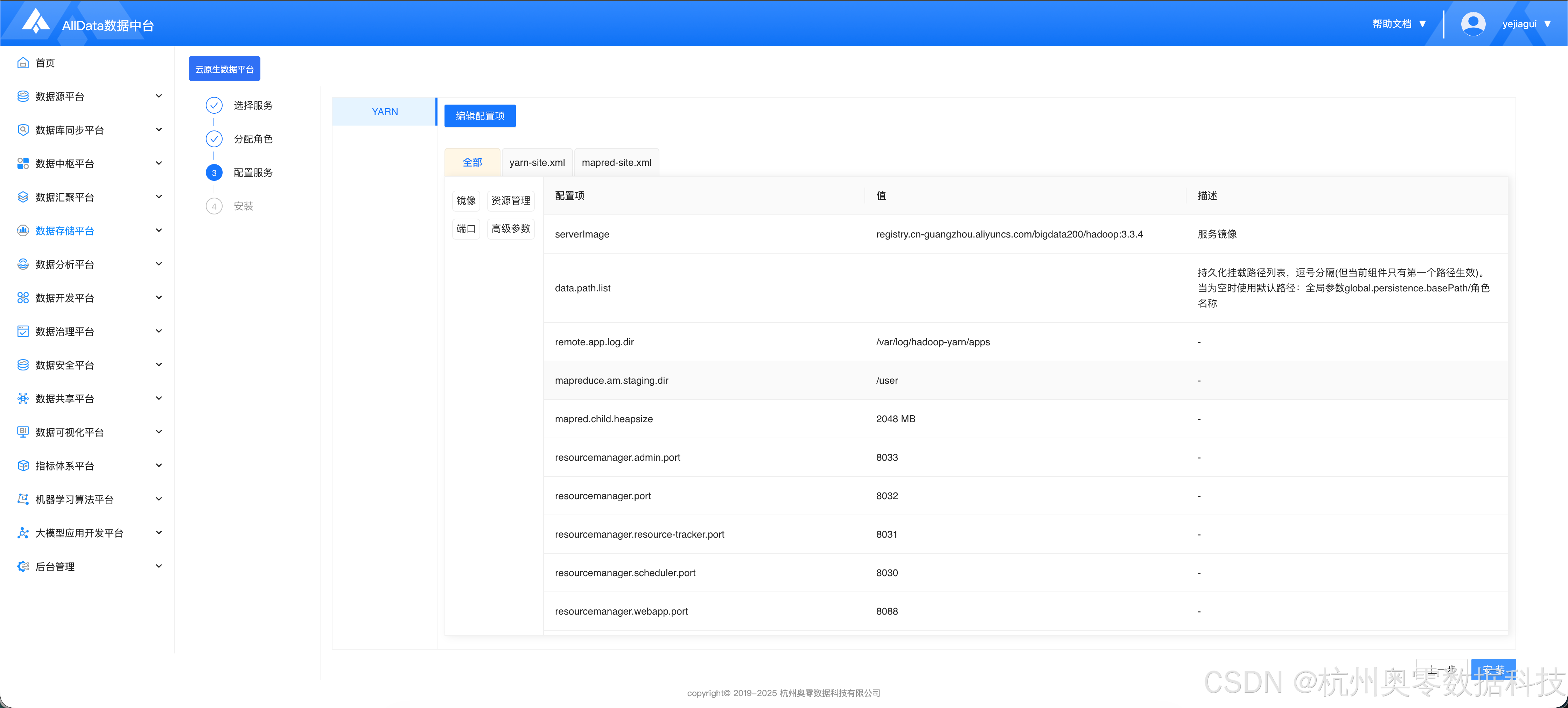
- 点击 "编辑配置项"
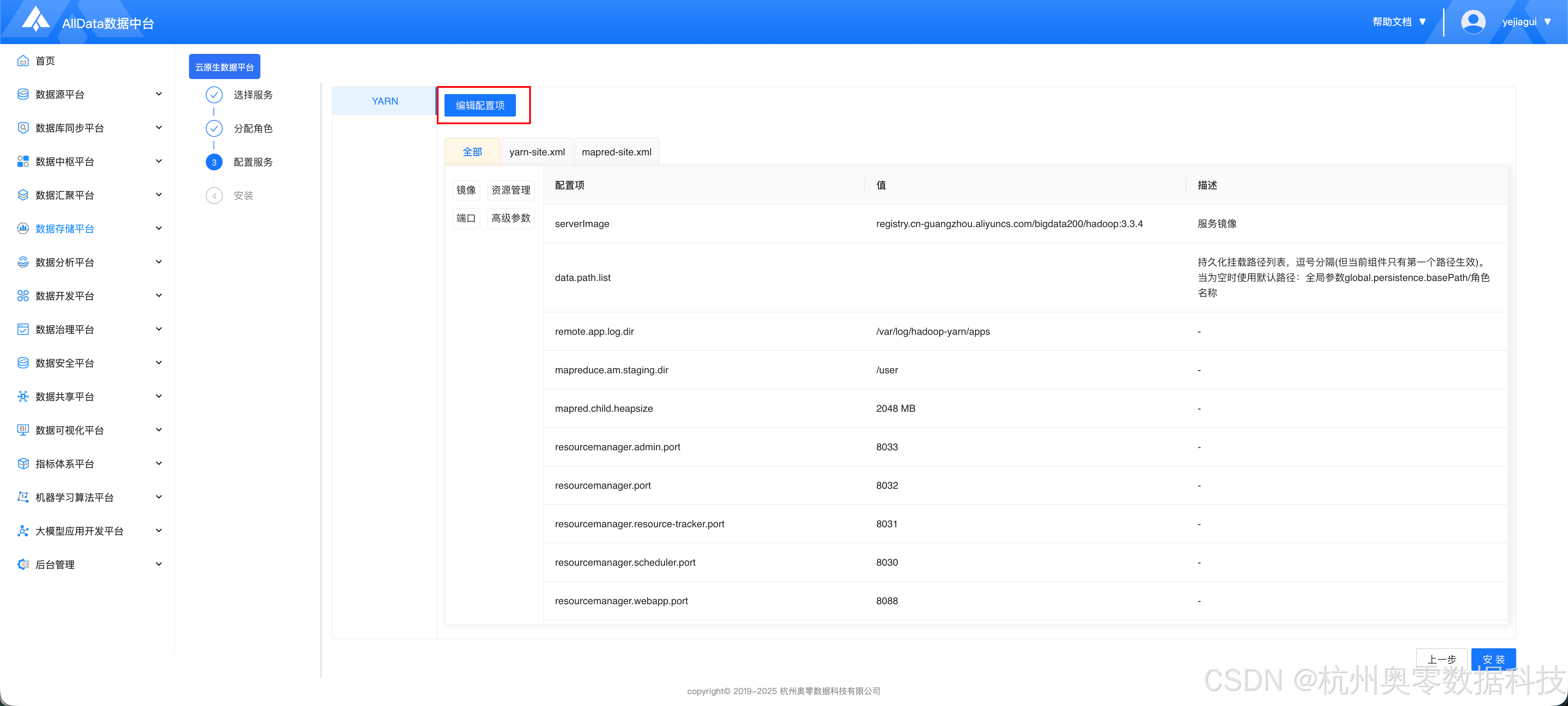
点击 "添加自定义配置"
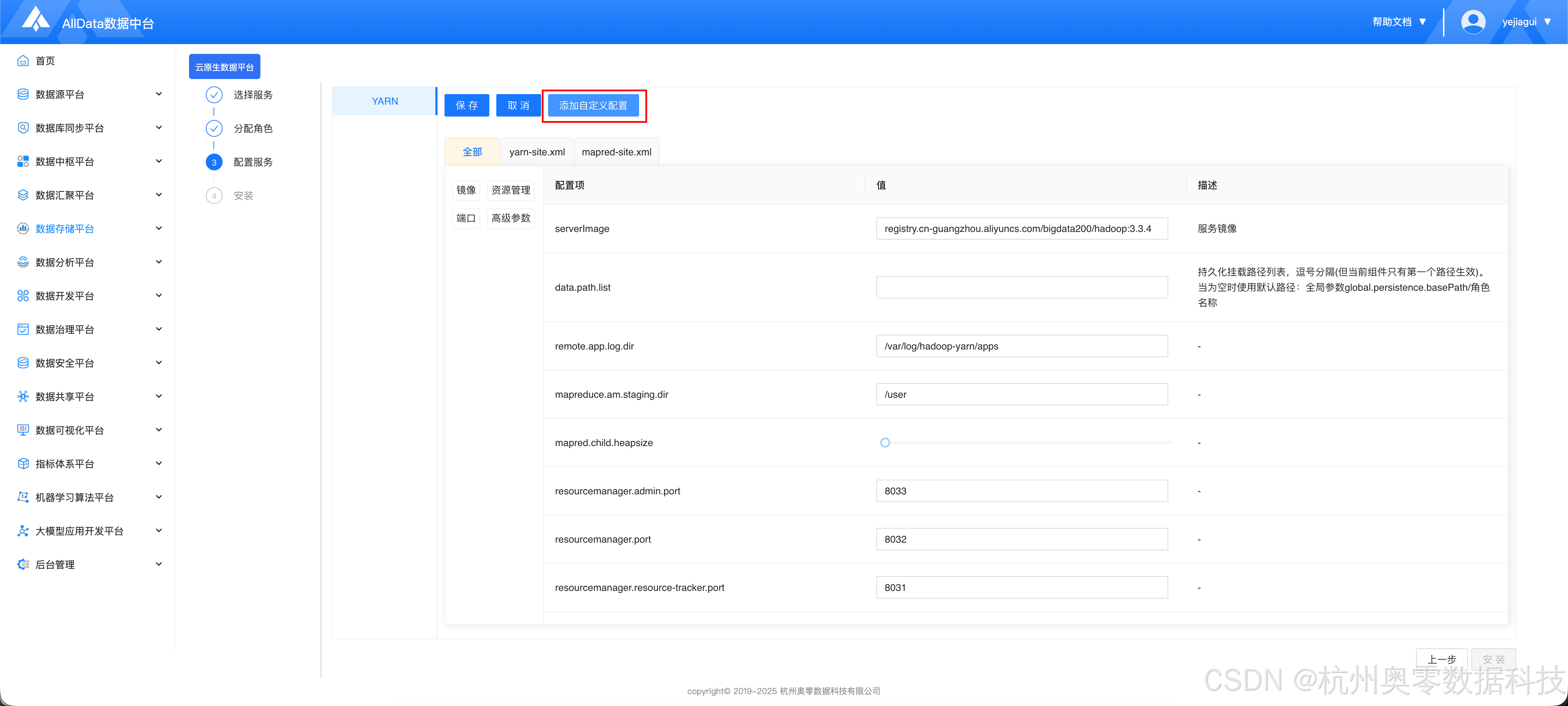
- 添加如下配置

- 点击 "确定 - 安装"
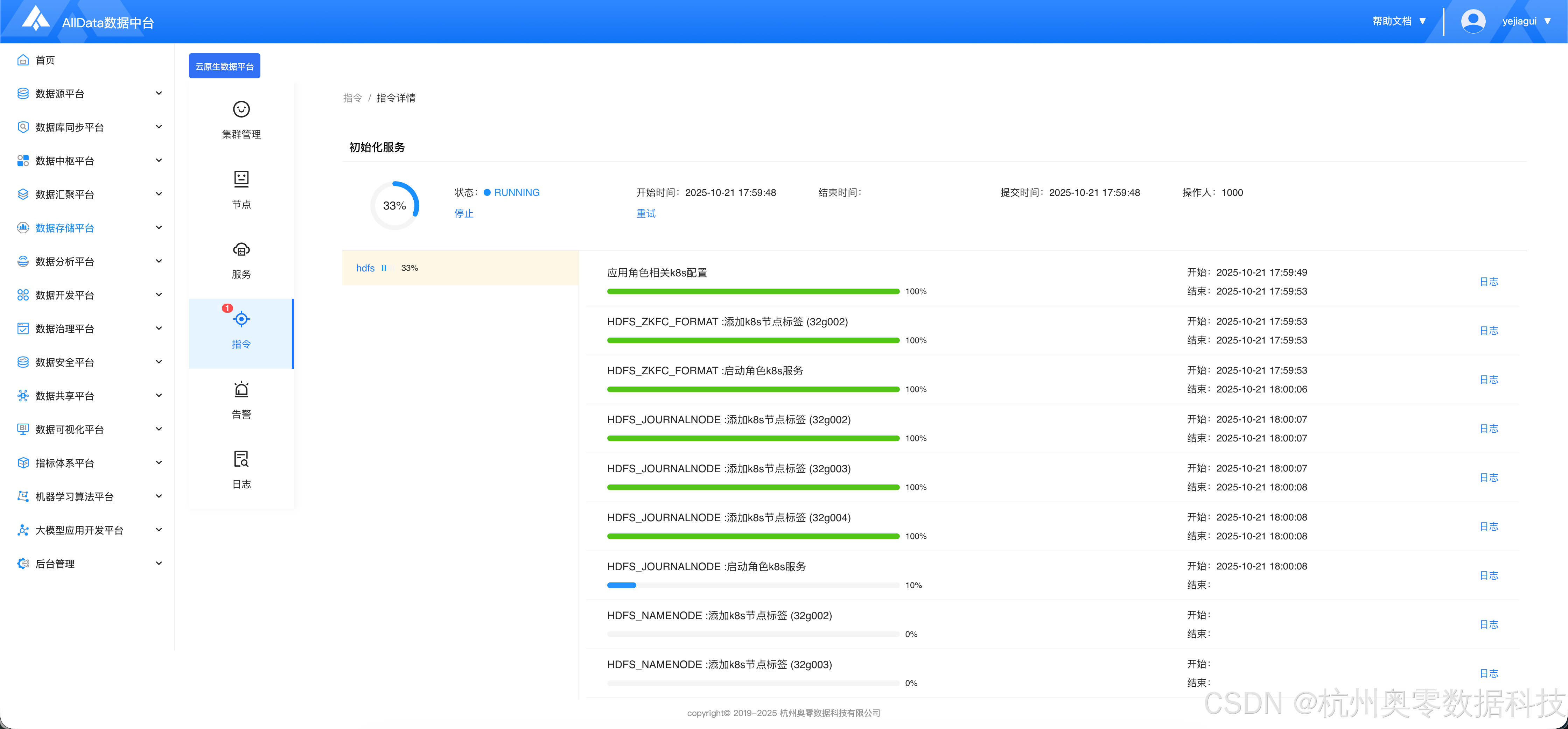
1.4 等待安装完成
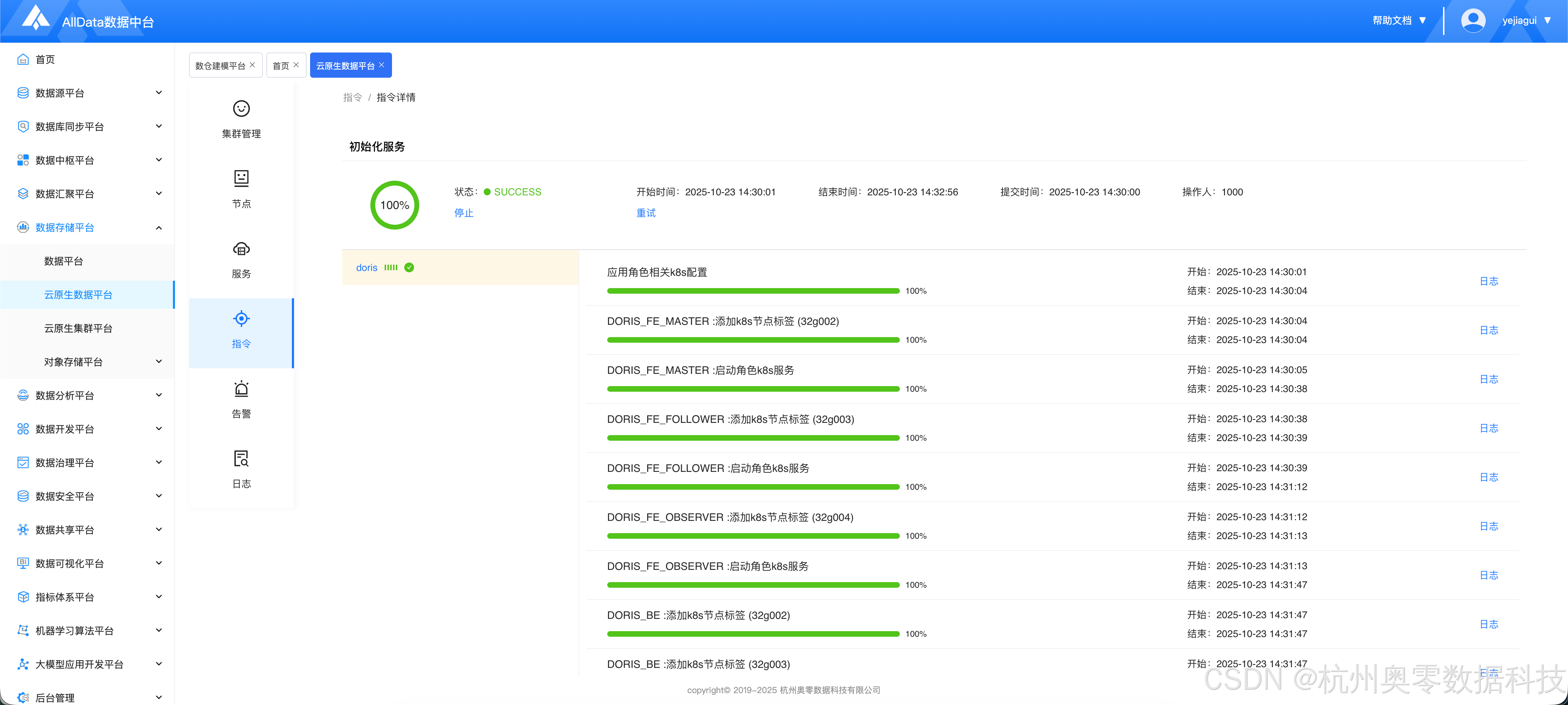
五、添加doris服务
1.添加流程
1.1 进入新增服务页面,选择Doris
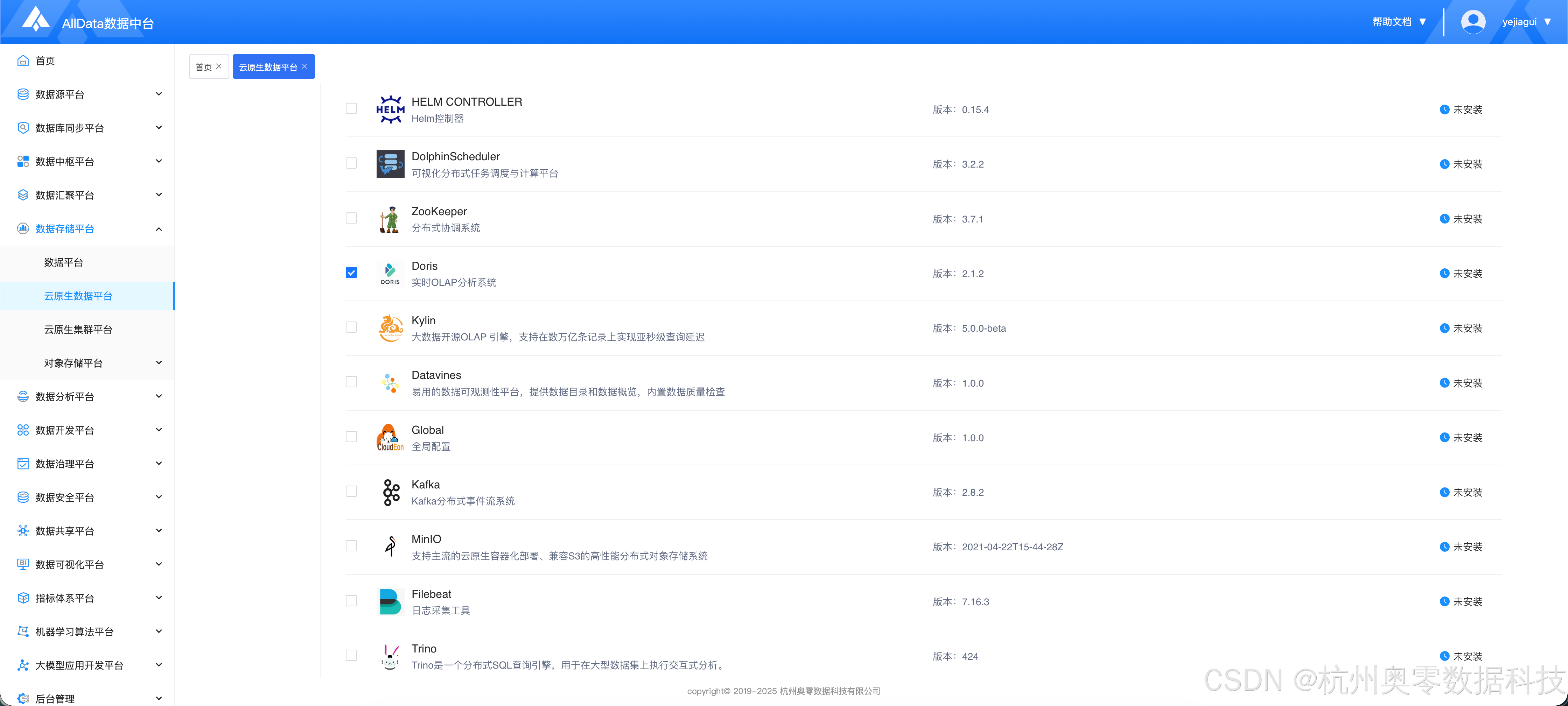
- 下滑到最下方,点击 "下一步"
1.2 分配角色
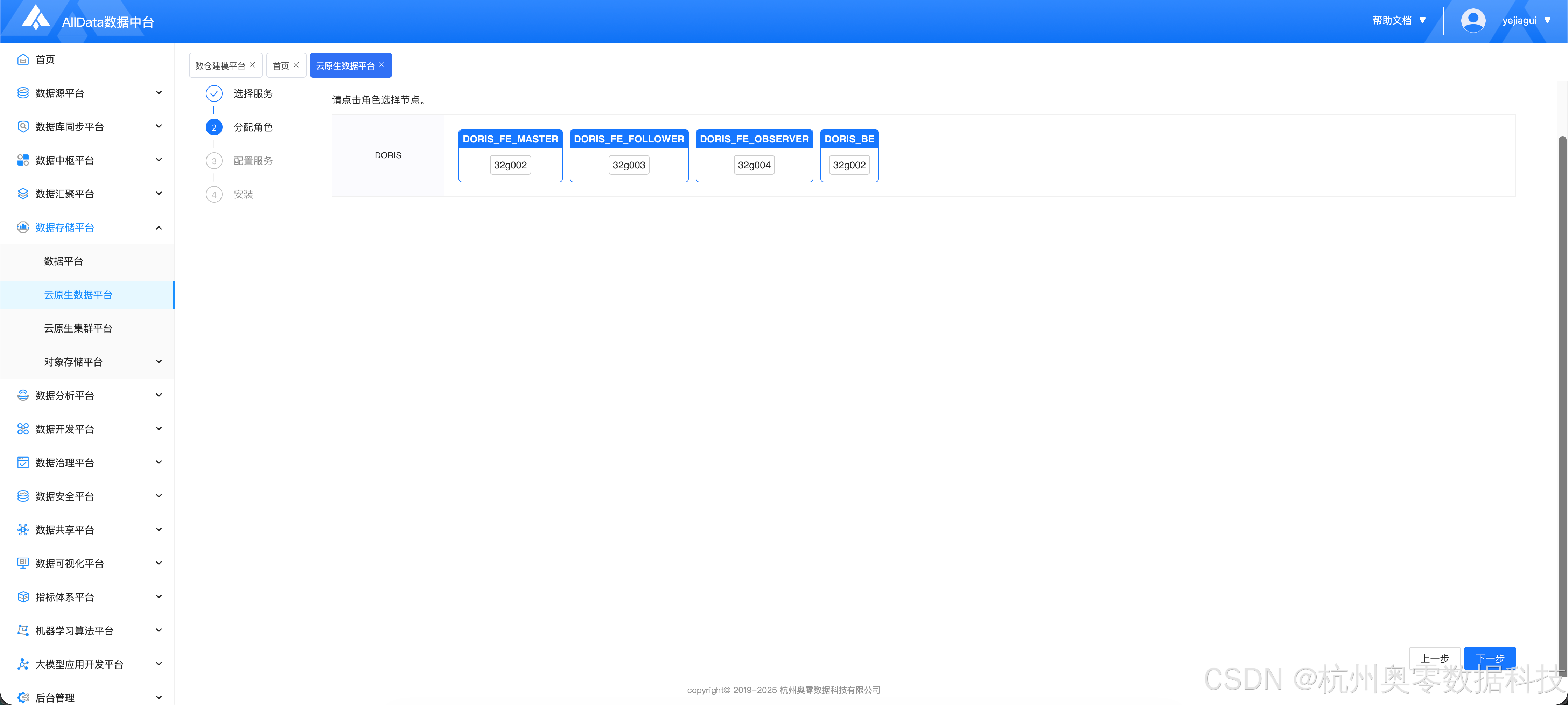
- 这里建议 master、follower、observer 角色为不同一个节点,否则容易发生端口冲突
1.3 初始化配置
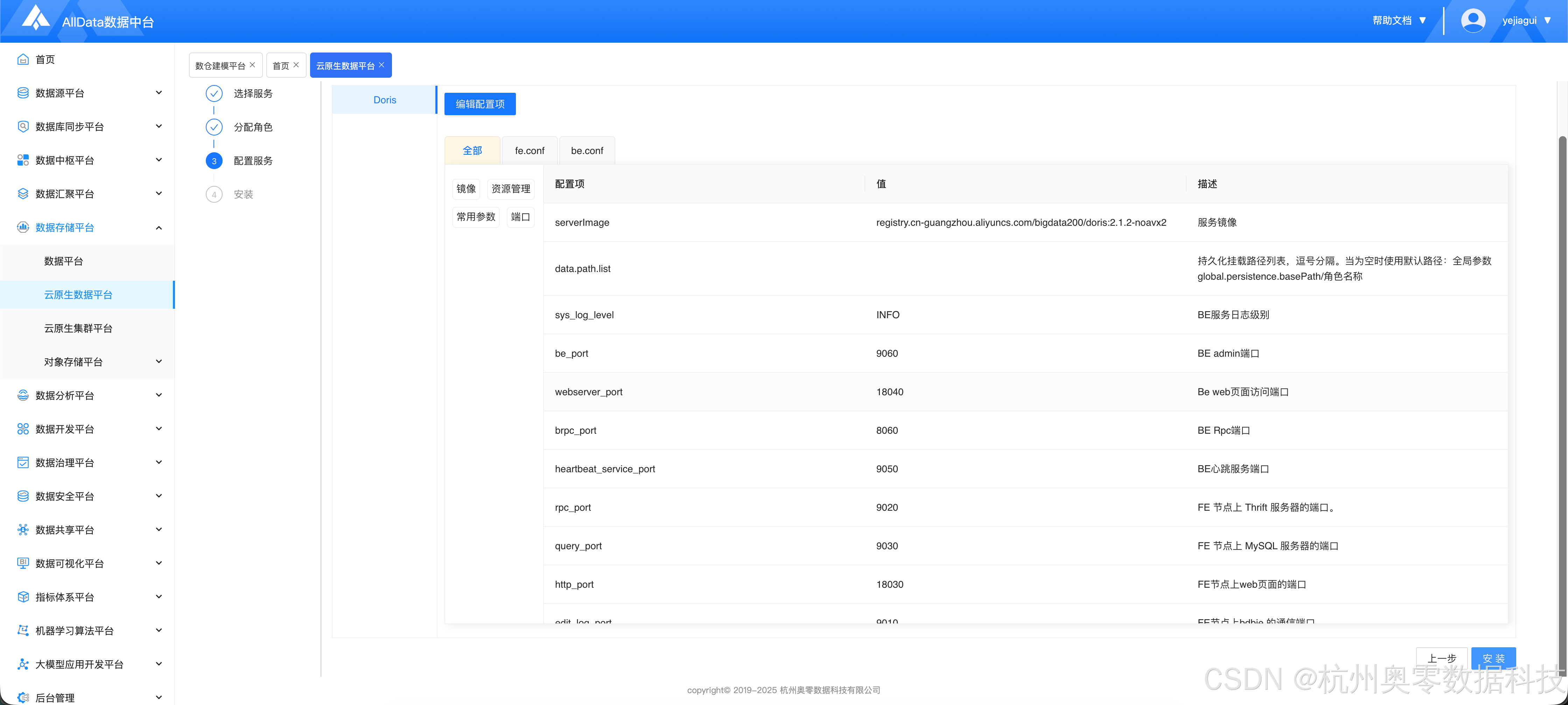
- 根据用户实际需求进行修改,无需求则按照默认即可
1.4 等待安装完成