
两个观察
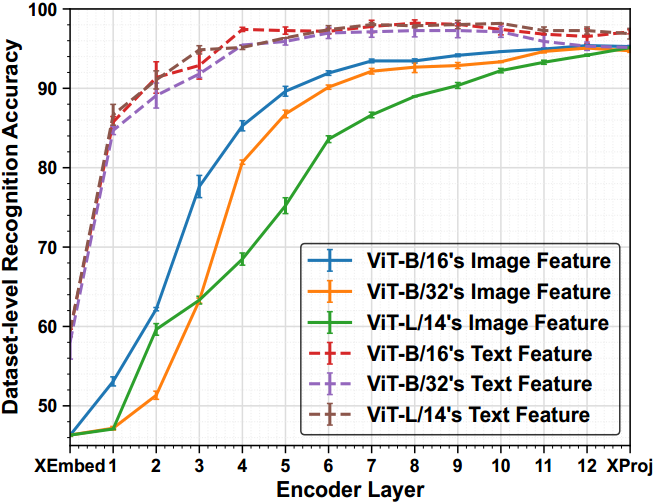
图1所示。各种基于transformer的CLIP模型中不同层的数据集级识别精度。这个实验是为了确定样本属于哪个数据集。我们用不同的种子运行了三次,并报告了每层识别精度的平均值和标准差。 X E m b e d XEmbed XEmbed是指变压器块之前的文本或图像嵌入层(即自关注层和前馈层13), X P r o j XProj XProj是指文本或图像投影层。注意,本实验仅使用来自所有数据集的训练样例进行评估。
如图1所示,我们有两个观测:
Observation-1。在预训练的文本和图像编码器中,较高的层包含可区分的数据集特定表示,而较低的层包含跨不同数据集的可通用表示。 这些结果表明,为下游任务调整高层比低层更容易,冻结低层比高层可以保存更多的可泛化知识。
Observation-2。在大多数情况下,文本特征,因为它们是用语义类别名称编码的,在数据集中比视觉特征更容易区分。此外,低层的文本和图像特征之间的间隙比高层的更大 。因此,我们认为在文本和图像特征之间对齐较低的层比在较高的层之间对齐更困难,特别是在有限的训练样本下进行调优。
Macro Design(宏观的设计)

新的适配器 A \mathcal{A} A(在下一节中详细介绍)被部分添加到图像和文本编码器的几个更高层中 。形式上,对于图像编码器 V \mathcal{V} V,我们从第 k k k个transformer块中添加适配器 A v \mathcal{A}^v Av
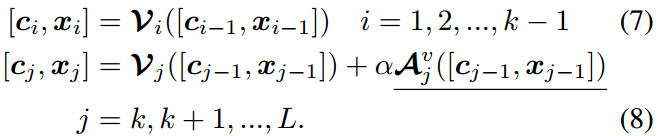
这里,++下划线++ 表示可训练的块。 α \alpha α是任务特定知识和一般预训练知识之间的平衡系数。显然, α = 0 \alpha=0 α=0在不集成任何额外知识的情况下退化为原始transformer块。同样,我们在文本编码器 τ \tau τ上增加适配器 A t \mathcal{A}^t At
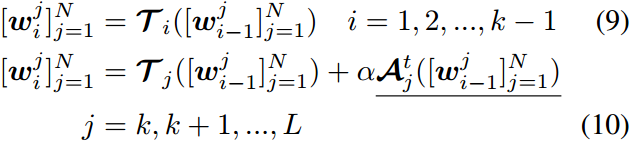
Micro Design(微观设计)
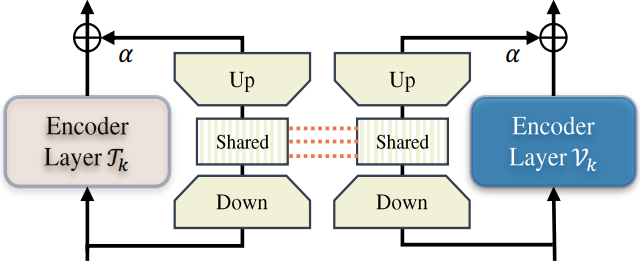
该单元首先使用单独的投影层将每个分支输入投影到具有相同尺寸的特征中。然后,使用一个共享投影层来聚合这些双峰信号,然后使用一个单独的层来匹配每个分支的输出维度。形式上,这个过程可以概括如下:
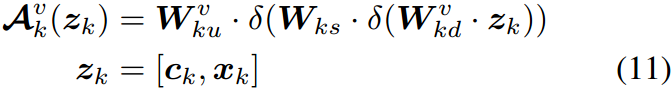
一个类似的过程被添加到文本编码器如下:
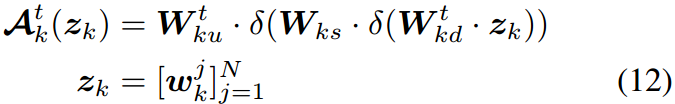
其中, W k w \bm W_{kw} Wkw和 W k d \bm W_{kd} Wkd是图所示的第 k k k个"上"和"下"投影层,其中模态分支用上标突出显示。 W k s \bm W_{ks} Wks是第 k k k个投影层,由Eq.(11)和Eq.(12)中的不同分支共享。重要的是,共享投影作为两个模态之间的桥梁,允许梯度相互传播,从而更好地对齐不同的模态信号。
实验
me:简单的改动,但效果真的很好啊。
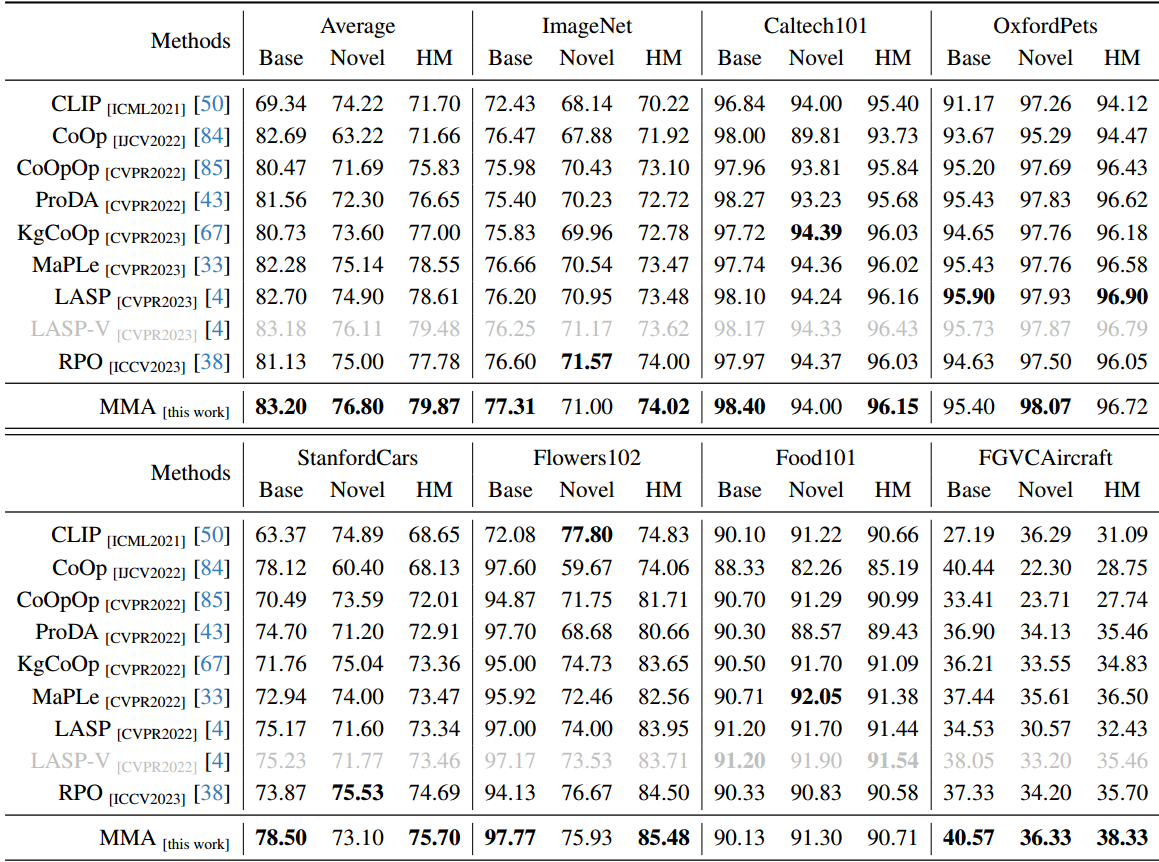
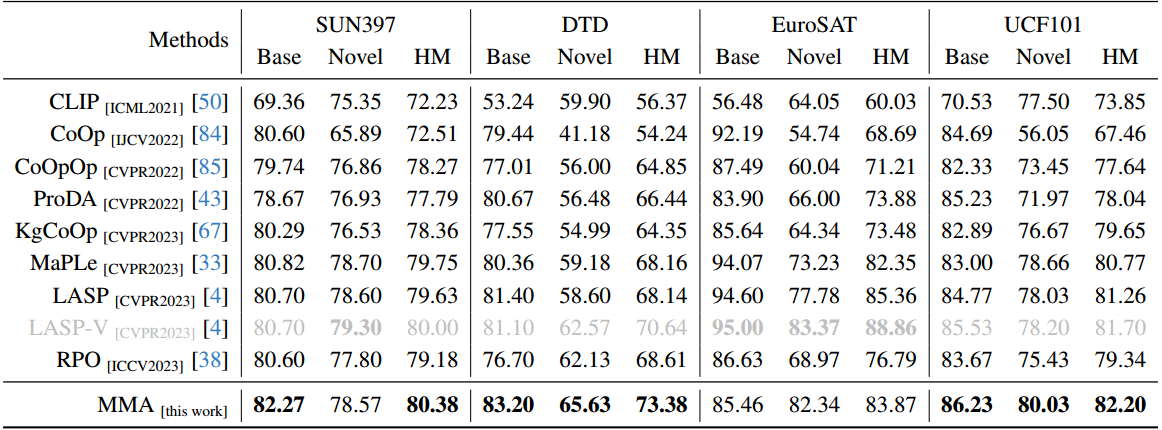
结论
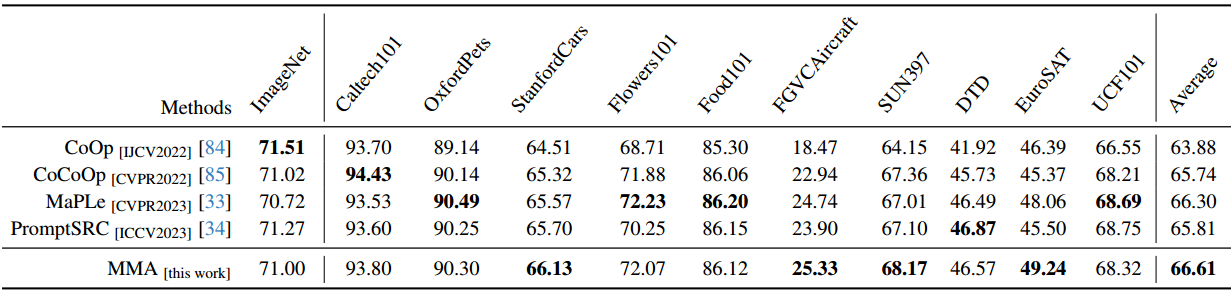
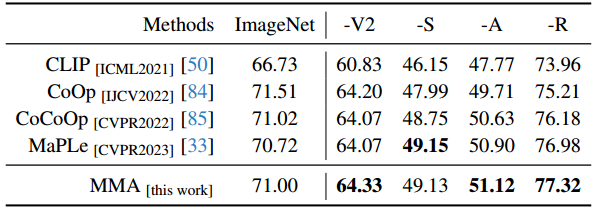
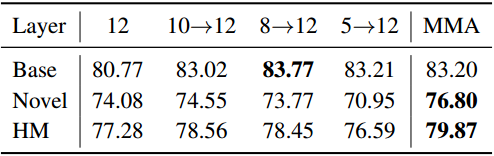
以CLIP为例50的大规模VLM对下游任务的适应提出了一个巨大的挑战,主要是因为可训练参数的数量庞大,而可用训练样本的规模有限。在本文中,我们提出了一种针对视觉和语言分支设计的多模态适配器(MMA),以增强其各自表示之间的一致性。我们系统地分析了视觉和语言分支跨数据集的特征的判别性和泛化性,因为这两个特征在迁移学习中起着重要的作用,特别是在少样本设置中。基于我们的分析,我们有选择地将MMA引入到特定的更高的transformer层,以实现区分和泛化之间的最佳平衡。我们通过三个代表性任务来评估我们方法的有效性:对新类别的泛化,对新目标数据集的适应,以及看不见的领域转移。与其他先进方法的比较表明,我们的综合性能在所有三种类型的评估中都取得了卓越的表现。
参考资料
论文下载(CVPR 2024)
